
## 16 ConcurrentHashMap 源碼解析和設計思路
## 引導語
當我們碰到線程不安全場景下,需要使用 Map 的時候,我們第一個想到的 API 估計就是 ConcurrentHashMap,ConcurrentHashMap 內部封裝了鎖和各種數據結構來保證訪問 Map 是線程安全的,接下來我們一一來看下,和 HashMap 相比,多了哪些數據結構,又是如何保證線程安全的。
### 1 類注釋
我們從類注釋上大概可以得到如下信息:
1. 所有的操作都是線程安全的,我們在使用時,無需再加鎖;
2. 多個線程同時進行 put、remove 等操作時并不會阻塞,可以同時進行,和 HashTable 不同,HashTable 在操作時,會鎖住整個 Map;
3. 迭代過程中,即使 Map 結構被修改,也不會拋 ConcurrentModificationException 異常;
4. 除了數組 + 鏈表 + 紅黑樹的基本結構外,新增了轉移節點,是為了保證擴容時的線程安全的節點;
5. 提供了很多 Stream 流式方法,比如說:forEach、search、reduce 等等。
從類注釋中,我們可以看出 ConcurrentHashMap 和 HashMap 相比,新增了轉移節點的數據結構,至于底層如何實現線程安全,轉移節點的具體細節,暫且看不出來,接下來我們細看源碼。
### 2 結構
雖然 ConcurrentHashMap 的底層數據結構,和方法的實現細節和 HashMap 大體一致,但兩者在類結構上卻沒有任何關聯,我們看下 ConcurrentHashMap 的類圖:
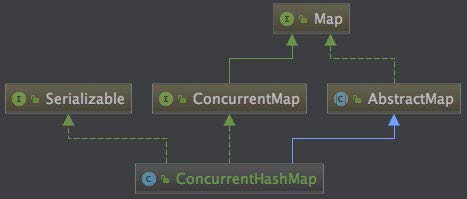
看 ConcurrentHashMap 源碼,我們會發現很多方法和代碼和 HashMap 很相似,有的同學可能會問,為什么不繼承 HashMap 呢?繼承的確是個好辦法,但尷尬的是,ConcurrentHashMap 都是在方法中間進行一些加鎖操作,也就是說加鎖把方法切割了,繼承就很難解決這個問題。
ConcurrentHashMap 和 HashMap 兩者的相同之處:
1. 數組、鏈表結構幾乎相同,所以底層對數據結構的操作思路是相同的(只是思路相同,底層實現不同);
2. 都實現了 Map 接口,繼承了 AbstractMap 抽象類,所以大多數的方法也都是相同的,HashMap 有的方法,ConcurrentHashMap 幾乎都有,所以當我們需要從 HashMap 切換到 ConcurrentHashMap 時,無需關心兩者之間的兼容問題。
不同之處:
1. 紅黑樹結構略有不同,HashMap 的紅黑樹中的節點叫做 TreeNode,TreeNode 不僅僅有屬性,還維護著紅黑樹的結構,比如說查找,新增等等;ConcurrentHashMap 中紅黑樹被拆
分成兩塊,
TreeNode 僅僅維護的屬性和查找功能,新增了 TreeBin,來維護紅黑樹結構,并負責根節點的加鎖和解鎖; 2.
新增 ForwardingNode (轉移)節點,擴容的時候會使用到,通過使用該節點,來保證擴容時的線程安全。
### 3 put
ConcurrentHashMap 在 put 方法上的整體思路和 HashMap 相同,但在線程安全方面寫了很多保障的代碼,我們先來看下大體思路:
1. 如果數組為空,初始化,初始化完成之后,走 2;
2. 計算當前槽點有沒有值,沒有值的話,cas 創建,失敗繼續自旋(for 死循環),直到成功,槽點有值的話,走 3;
3. 如果槽點是轉移節點(正在擴容),就會一直自旋等待擴容完成之后再新增,不是轉移節點走 4;
4. 槽點有值的,先鎖定當前槽點,保證其余線程不能操作,如果是鏈表,新增值到鏈表的尾部,如果是紅黑樹,使用紅黑樹新增的方法新增;
5. 新增完成之后 check 需不需要擴容,需要的話去擴容。
具體源碼如下:
```
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); //計算hash int hash = spread(key.hashCode()); int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh;
//table是空的,進行初始化 if (tab == null || (n = tab.length) == 0) tab = initTable(); //如果當前索引位置沒有值,直接創建 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //cas 在 i 位置創建新的元素,當 i 位置是空時,即能創建成功,結束for自循,否則繼續自旋 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } //如果當前槽點是轉移節點,表示該槽點正在擴容,就會一直等待擴容完成 //轉移節點的 hash 值是固定的,都是 MOVED else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); //槽點上有值的 else { V oldVal = null; //鎖定當前槽點,其余線程不能操作,保證了安全 synchronized (f) { //這里再次判斷 i 索引位置的數據沒有被修改 //binCount 被賦值的話,說明走到了修改表的過程里面 if (tabAt(tab, i) == f) { //鏈表 if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; //值有的話,直接返回 if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; //把新增的元素賦值到鏈表的最后,退出自旋 if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } //紅黑樹,這里沒有使用 TreeNode,使用的是 TreeBin,TreeNode 只是紅黑樹的一個節點 //TreeBin 持有紅黑樹的引用,并且會對其加鎖,保證其操作的線程安全 else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; //滿足if的話,把老的值給oldVal //在putTreeVal方法里面,在給紅黑樹重新著色旋轉的時候 //會鎖住紅黑樹的根節點 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } //binCount不為空,并且 oldVal 有值的情況,說明已經新增成功了
if (binCount != 0) { // 鏈表是否需要轉化成紅黑樹 if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; //這一步幾乎走不到。槽點已經上鎖,只有在紅黑樹或者鏈表新增失敗的時候 //才會走到這里,這兩者新增都是自旋的,幾乎不會失敗 break; } } } //check 容器是否需要擴容,如果需要去擴容,調用 transfer 方法去擴容 //如果已經在擴容中了,check有無完成 addCount(1L, binCount); return null; }
```
源碼中都有非常詳細的注釋,就不解釋了,我們重點說一下,ConcurrentHashMap 在 put 過程中,采用了哪些手段來保證線程安全。
#### 3.1 數組初始化時的線程安全
數組初始化時,首先通過自旋來保證一定可以初始化成功,然后通過 CAS 設置 SIZECTL 變量的值,來保證同一時刻只能有一個線程對數組進行初始化,CAS 成功之后,還會再次判斷當前數組是否已經初始化完成,如果已經初始化完成,就不會再次初始化,通過自旋 + CAS + 雙重 check 等手段保證了數組初始化時的線程安全,源碼如下:
```
//初始化 table,通過對 sizeCtl 的變量賦值來保證數組只能被初始化一次 private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; //通過自旋保證初始化成功
while ((tab = table) == null || tab.length == 0) { // 小于 0 代表有線程正在初始化,釋放當前 CPU 的調度權,重新發起鎖的競爭 if ((sc = sizeCtl) < 0) Thread.yield(); // lost initialization race; just spin // CAS 賦值保證當前只有一個線程在初始化,-1 代表當前只有一個線程能初始化 // 保證了數組的初始化的安全性 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { try { // 很有可能執行到這里的時候,table 已經不為空了,這里是雙重 check if ((tab = table) == null || tab.length == 0) { // 進行初始化 int n = (sc > 0) ? sc : DEFAULT_CAPACITY; @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = tab = nt; sc = n - (n >>> 2); } } finally { sizeCtl = sc; } break; } } return tab; }
```
3.2 新增槽點值時的線程安全
此時為了保證線程安全,做了四處優化:
1. 通過自旋死循環保證一定可以新增成功。
在新增之前,通過 for (Node[] tab = table;;) 這樣的死循環來保證新增一定可以成功,一旦新增成功,就可以退出當前死循環,新增失敗的話,會重復新增的步驟,直到新增成功為止。
2. 當前槽點為空時,通過 CAS 新增。
Java 這里的寫法非常嚴謹,沒有在判斷槽點為空的情況下直接賦值,因為在判斷槽點為空和賦值的瞬間,很有可能槽點已經被其他線程賦值了,所以我們采用 CAS 算法,能夠保證槽點為空的情況下賦值成功,如果恰好槽點已經被其他線程賦值,當前 CAS 操作失敗,會再次執行 for 自旋,再走槽點有值的 put 流程,這里就是自旋 + CAS 的結合。
3. 當前槽點有值,鎖住當前槽點。
put 時,如果當前槽點有值,就是 key 的 hash 沖突的情況,此時槽點上可能是鏈表或紅黑樹,我們通過鎖住槽點,來保證同一時刻只會有一個線程能對槽點進行修改,截圖如下:

4. 紅黑樹旋轉時,鎖住紅黑樹的根節點,保證同一時刻,當前紅黑樹只能被一個線程旋轉,代碼截圖如下:
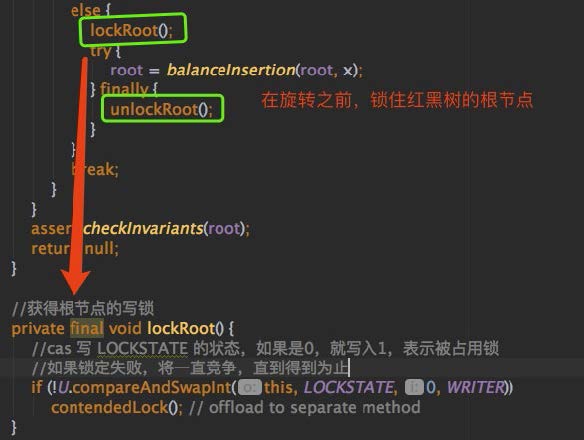
通過以上 4 點,保證了在各種情況下的新增(不考慮擴容的情況下),都是線程安全的,通過自旋 + CAS + 鎖三大姿勢,實現的很巧妙,值得我們借鑒。
#### 3.3 擴容時的線程安全
ConcurrentHashMap 的擴容時機和 HashMap 相同,都是在 put 方法的最后一步檢查是否需要擴容,如果需要則進行擴容,但兩者擴容的過程完全不同,ConcurrentHashMap 擴容的方法叫做 transfer,從 put 方法的 addCount 方法進去,就能找到 transfer 方法,transfer 方法的主要思路是:
1. 首先需要把老數組的值全部拷貝到擴容之后的新數組上,先從數組的隊尾開始拷貝;
2. 拷貝數組的槽點時,先把原數組槽點鎖住,保證原數組槽點不能操作,成功拷貝到新數組時,把原數組槽點賦值為轉移節點;
3. 這時如果有新數據正好需要 put 到此槽點時,發現槽點為轉移節點,就會一直等待,所以在擴容完成之前,該槽點對應的數據是不會發生變化的;
4. 從數組的尾部拷貝到頭部,每拷貝成功一次,就把原數組中的節點設置成轉移節點;
5. 直到所有數組數據都拷貝到新數組時,直接把新數組整個賦值給數組容器,拷貝完成。
關鍵源碼如下:
```
// 擴容主要分 2 步,第一新建新的空數組,第二移動拷貝每個元素到新數組中去 // tab:原數組,nextTab:新數組 private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { // 老數組的長度 int n = tab.length, stride; if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; // subdivide range // 如果新數組為空,初始化,大小為原數組的兩倍,n << 1 if (nextTab == null) { // initiating try { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; nextTab = nt; } catch (Throwable ex) { // try to cope with OOME sizeCtl = Integer.MAX_VALUE; return; } nextTable = nextTab; transferIndex = n; } // 新數組的長度 int nextn = nextTab.length;
// 代表轉移節點,如果原數組上是轉移節點,說明該節點正在被擴容 ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); boolean advance = true; boolean finishing = false; // to ensure sweep before committing nextTab // 無限自旋,i 的值會從原數組的最大值開始,慢慢遞減到 0 for (int i = 0, bound = 0;;) { Node<K,V> f; int fh; while (advance) { int nextIndex, nextBound; // 結束循環的標志 if (--i >= bound || finishing) advance = false; // 已經拷貝完成 else if ((nextIndex = transferIndex) <= 0) { i = -1; advance = false; } // 每次減少 i 的值 else if (U.compareAndSwapInt (this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { bound = nextBound; i = nextIndex - 1; advance = false; } } // if 任意條件滿足說明拷貝結束了 if (i < 0 || i >= n || i + n >= nextn) { int sc; // 拷貝結束,直接賦值,因為每次拷貝完一個節點,都在原數組上放轉移節點,所以拷貝完成的節點的數據一定不會再發生變化。
//
原數組發現是轉移節點,是不會操作的,會一直等待轉移節點消失之后在進行操作。 // 也就是說數組節點一旦被標記為轉移節點,是不會再發生任何變動的,所以不會有任何線程安全的問題 // 所以此處直接賦值,沒有任何問題。 if (finishing) { nextTable = null; table = nextTab; sizeCtl = (n << 1) - (n >>> 1); return; } if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; finishing = advance = true; i = n; // recheck before commit } } else if ((f = tabAt(tab, i)) == null) advance = casTabAt(tab, i, null, fwd); else if ((fh = f.hash) == MOVED) advance = true; // already processed else { synchronized (f) { // 進行節點的拷貝 if (tabAt(tab, i) == f) { Node<K,V> ln, hn; if (fh >= 0) { int runBit = fh & n; Node<K,V> lastRun = f; for (Node<K,V> p = f.next; p != null; p = p.next) { int b = p.hash & n; if (b != runBit) { runBit = b;
lastRun = p; } } if (runBit == 0) { ln = lastRun; hn = null; } else { hn = lastRun; ln = null; } // 如果節點只有單個數據,直接拷貝,如果是鏈表,循環多次組成鏈表拷貝 for (Node<K,V> p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val; if ((ph & n) == 0) ln = new Node<K,V>(ph, pk, pv, ln); else hn = new Node<K,V>(ph, pk, pv, hn); } // 在新數組位置上放置拷貝的值 setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); // 在老數組位置上放上 ForwardingNode 節點 // put 時,發現是 ForwardingNode 節點,就不會再動這個節點的數據了 setTabAt(tab, i, fwd); advance = true; } // 紅黑樹的拷貝 else if (f instanceof TreeBin) { // 紅黑樹的拷貝工作,同 HashMap 的內容,代碼忽略 …………
// 在老數組位置上放上 ForwardingNode 節點 setTabAt(tab, i, fwd); advance = true; } } } } } }
```
擴容中的關鍵點,就是如何保證是線程安全的,小結有如下幾點:
1. 拷貝槽點時,會把原數組的槽點鎖住;
2. 拷貝成功之后,會把原數組的槽點設置成轉移節點,這樣如果有數據需要 put 到該節點時,發現該槽點是轉移節點,會一直等待,直到擴容成功之后,才能繼續 put,可以參考 put 方法中的 helpTransfer 方法;
3. 從尾到頭進行拷貝,拷貝成功就把原數組的槽點設置成轉移節點。
4. 等擴容拷貝都完成之后,直接把新數組的值賦值給數組容器,之前等待 put 的數據才能繼續 put。
擴容方法還是很有意思的,通過在原數組上設置轉移節點,put 時碰到轉移節點時會等待擴容成功之后才能 put 的策略,來保證了整個擴容過程中肯定是線程安全的,因為數組的槽點一旦被設置成轉移節點,在沒有擴容完成之前,是無法進行操作的。
### 4 get
ConcurrentHashMap 讀的話,就比較簡單,先獲取數組的下標,然后通過判斷數組下標的 key 是否和我們的 key 相等,相等的話直接返回,如果下標的槽點是鏈表或紅黑樹的話,分別調用相應的查找數據的方法,整體思路和 HashMap 很像,源碼如下:
```
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; //計算hashcode int h = spread(key.hashCode()); //不是空的數組 && 并且當前索引的槽點數據不是空的 //否則該key對應的值不存在,返回null if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { //槽點第一個值和key相等,直接返回 if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } //如果是紅黑樹或者轉移節點,使用對應的find方法 else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; //如果是鏈表,遍歷查找 while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }
```
### 5 總結
本文摘取 ConcurrentHashMap 兩個核心的方法講解了一下,特別是 put 方法,采取了很多手段來保證了線程安全,是平時面試時的重中之重,大家可以嘗試 debug 來調試一下源碼,其他方法感興趣的話,可以嘗試去 GitHub 上去查看源碼。
- 前言
- 第1章 基礎
- 01 開篇詞:為什么學習本專欄
- 02 String、Long 源碼解析和面試題
- 03 Java 常用關鍵字理解
- 04 Arrays、Collections、Objects 常用方法源碼解析
- 第2章 集合
- 05 ArrayList 源碼解析和設計思路
- 06 LinkedList 源碼解析
- 07 List 源碼會問哪些面試題
- 08 HashMap 源碼解析
- 09 TreeMap 和 LinkedHashMap 核心源碼解析
- 10 Map源碼會問哪些面試題
- 11 HashSet、TreeSet 源碼解析
- 12 彰顯細節:看集合源碼對我們實際工作的幫助和應用
- 13 差異對比:集合在 Java 7 和 8 有何不同和改進
- 14 簡化工作:Guava Lists Maps 實際工作運用和源碼
- 第3章 并發集合類
- 15 CopyOnWriteArrayList 源碼解析和設計思路
- 16 ConcurrentHashMap 源碼解析和設計思路
- 17 并發 List、Map源碼面試題
- 18 場景集合:并發 List、Map的應用場景
- 第4章 隊列
- 19 LinkedBlockingQueue 源碼解析
- 20 SynchronousQueue 源碼解析
- 21 DelayQueue 源碼解析
- 22 ArrayBlockingQueue 源碼解析
- 23 隊列在源碼方面的面試題
- 24 舉一反三:隊列在 Java 其它源碼中的應用
- 25 整體設計:隊列設計思想、工作中使用場景
- 26 驚嘆面試官:由淺入深手寫隊列
- 第5章 線程
- 27 Thread 源碼解析
- 28 Future、ExecutorService 源碼解析
- 29 押寶線程源碼面試題
- 第6章 鎖
- 30 AbstractQueuedSynchronizer 源碼解析(上)
- 31 AbstractQueuedSynchronizer 源碼解析(下)
- 32 ReentrantLock 源碼解析
- 33 CountDownLatch、Atomic 等其它源碼解析
- 34 只求問倒:連環相扣系列鎖面試題
- 35 經驗總結:各種鎖在工作中使用場景和細節
- 36 從容不迫:重寫鎖的設計結構和細節
- 第7章 線程池
- 37 ThreadPoolExecutor 源碼解析
- 38 線程池源碼面試題
- 39 經驗總結:不同場景,如何使用線程池
- 40 打動面試官:線程池流程編排中的運用實戰
- 第8章 Lambda 流
- 41 突破難點:如何看 Lambda 源碼
- 42 常用的 Lambda 表達式使用場景解析和應用
- 第9章 其他
- 43 ThreadLocal 源碼解析
- 44 場景實戰:ThreadLocal 在上下文傳值場景下的實踐
- 45 Socket 源碼及面試題
- 46 ServerSocket 源碼及面試題
- 47 工作實戰:Socket 結合線程池的使用
- 第10章 專欄總結
- 48 一起看過的 Java 源碼和面試真題