
## 20 SynchronousQueue 源碼解析
## 引導語
SynchronousQueue 是比較獨特的隊列,其本身是沒有容量大小,比如我放一個數據到隊列中,我是不能夠立馬返回的,我必須等待別人把我放進去的數據消費掉了,才能夠返回。SynchronousQueue 在消息隊列技術中間件中被大量使用,本文就來從底層實現來看下 SynchronousQueue 到底是如何做到的。
### 1 整體架構
SynchronousQueue 的整體設計比較抽象,在內部抽象出了兩種算法實現,一種是先入先出的隊列,一種是后入先出的堆棧,兩種算法被兩個內部類實現,而直接對外的 put,take 方法的實現就非常簡單,都是直接調用兩個內部類的 transfer 方法進行實現,整體的調用關系如下圖所示:
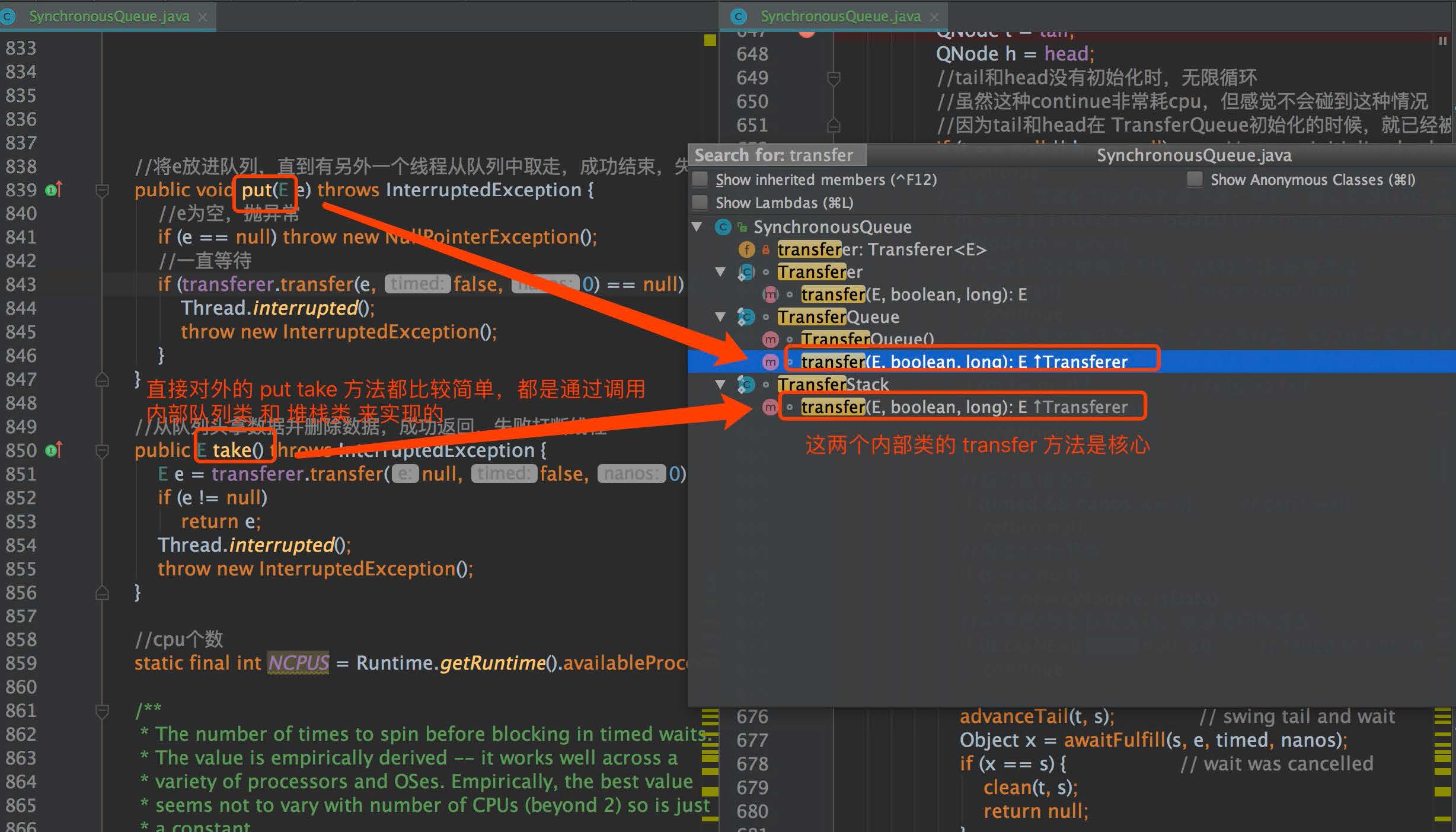
#### 1.1 類注釋
源碼的類注釋往往能給我帶來很多疑問和有用的信息,我們來看下類注釋都說了什么:
1. 隊列不存儲數據,所以沒有大小,也無法迭代;
2. 插入操作的返回必須等待另一個線程完成對應數據的刪除操作,反之亦然;
3. 隊列由兩種數據結構組成,分別是后入先出的堆棧和先入先出的隊列,堆棧是非公平的,隊列是公平的。
看到類注釋,大家是不是有一些疑問,比如第二點是如何做到的?堆棧又是如何實現的呢?接下來我們一點一點揭曉。
#### 1.2 類圖
SynchronousQueue 整體類圖和 LinkedBlockingQueue 相似,都是實現了 BlockingQueue 接口,但因為其不儲存數據結構,有一些方法是沒有實現的,比如說 isEmpty、size、contains、remove 和迭代等方法,這些方法都是默認實現,如下截圖:
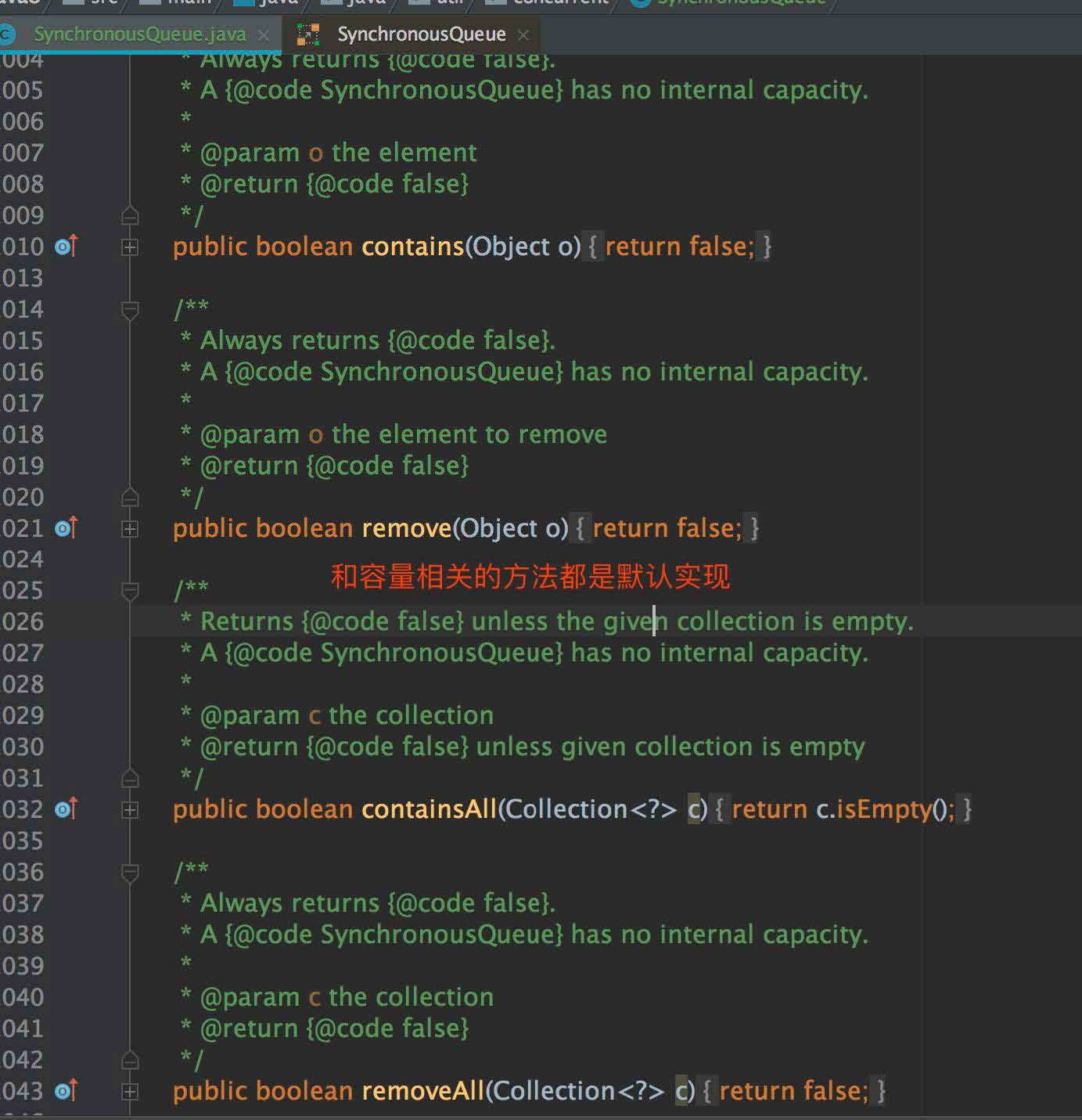
#### 1.3 結構細節
SynchronousQueue 底層結構和其它隊列完全不同,有著獨特的兩種數據結構:隊列和堆棧,我們一起來看下數據結構:
```
// 堆棧和隊列共同的接口 // 負責執行 put or take
abstract static class Transferer<E> { // e 為空的,會直接返回特殊值,不為空會傳遞給消費者 // timed 為 true,說明會有超時時間 abstract E transfer(E e, boolean timed, long nanos); } // 堆棧 后入先出 非公平 // Scherer-Scott 算法 static final class TransferStack<E> extends Transferer<E> { } // 隊列 先入先出 公平 static final class TransferQueue<E> extends Transferer<E> { } private transient volatile Transferer<E> transferer; // 無參構造器默認為非公平的 public SynchronousQueue(boolean fair) { transferer = fair ? new TransferQueue<E>() : new TransferStack<E>(); }
```
從源碼中我們可以得到幾點:
1. 堆棧和隊列都有一個共同的接口,叫做 Transferer,該接口有個方法:transfer,該方法很神奇,會承擔 take 和 put 的雙重功能;
2. 在我們初始化的時候,是可以選擇是使用堆棧還是隊列的,如果你不選擇,默認的就是堆棧,類注釋中也說明了這一點,堆棧的效率比隊列更高。
接下來我們來看下堆棧和隊列的具體實現。
### 2 非公平的堆棧
#### 2.1 堆棧的結構
首先我們來介紹下堆棧的整體結構,如下:
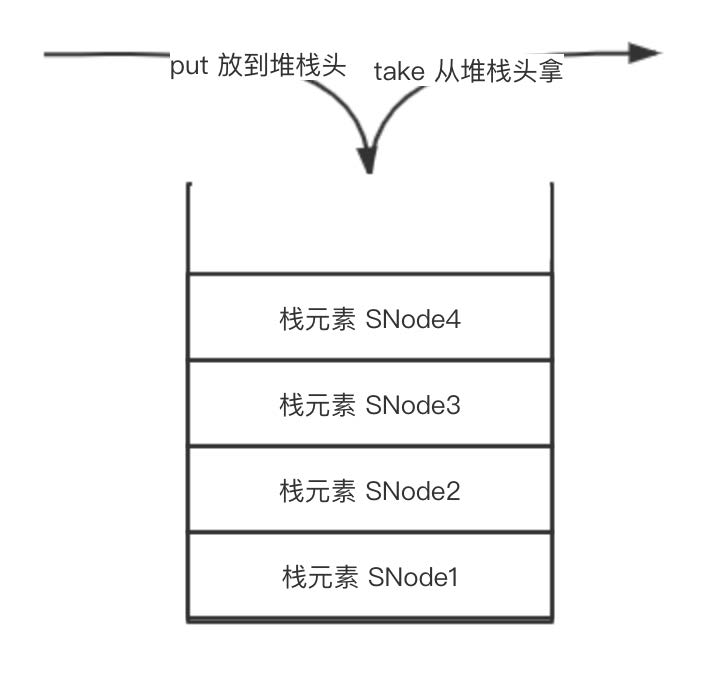
從上圖中我們可以看到,我們有一個大的堆棧池,池的開口叫做堆棧頭,put 的時候,就往堆棧池中放數據。take 的時候,就從堆棧池中拿數據,兩者操作都是在堆棧頭上操作數據,從圖中可以看到,越靠近堆棧頭,數據越新,所以每次 take 的時候,都會拿到堆棧頭的最新數據,這就是我們說的后入先出,也就是非公平的。
圖中 SNode 就是源碼中棧元素的表示,我們看下源碼:
```
static final class SNode { // 棧的下一個,就是被當前棧壓在下面的棧元素 volatile SNode next; // 節點匹配,用來判斷阻塞棧元素能被喚醒的時機 // 比如我們先執行 take,此時隊列中沒有數據,take 被阻塞了,棧元素為 SNode1 // 當有 put 操作時,會把當前 put 的棧元素賦值給 SNode1 的 match 屬性,并喚醒 take 操作 // 當 take 被喚醒,發現 SNode1 的 match 屬性有值時,就能拿到 put 進來的數據,從而返回 volatile SNode match; // 棧元素的阻塞是通過線程阻塞來實現的,waiter 為阻塞的線程 volatile Thread waiter; // 未投遞的消息,或者未消費的消息 Object item; }
```
#### 2.2 入棧和出棧
入棧指的是使用 put 等方法,把數據放到堆棧池中,出棧指的使用 take 等方法,把數據從堆棧池中拿出來,操作的對象都是堆棧頭,雖然兩者的一個是從堆棧頭拿數據,一個是放數據,但底層實現的方法卻是同一個,源碼如下:
```
// transfer 方法思路比較復雜,因為 take 和 put 兩個方法都揉在了一起 @SuppressWarnings("unchecked") E transfer(E e, boolean timed, long nanos) { SNode s = null; // constructed/reused as needed // e 為空,說明是 take 方法,不為空是 put 方法 int mode = (e == null) ? REQUEST : DATA; // 自旋 for (;;) { // 拿出頭節點,有幾種情況
// 1
:頭節點為空,說明隊列中還沒有數據 // 2:頭節點不為空,并且是 take 類型的,說明頭節點線程正等著拿數據。 // 3:頭節點不為空,并且是 put 類型的,說明頭節點線程正等著放數據。 SNode h = head; // 棧頭為空,說明隊列中還沒有數據。 // 棧頭不為空,并且棧頭的類型和本次操作一致,比如都是 put,那么就把 // 本次 put 操作放到該棧頭的前面即可,讓本次 put 能夠先執行 if (h == null || h.mode == mode) { // empty or same-mode // 設置了超時時間,并且 e 進棧或者出棧要超時了, // 就會丟棄本次操作,返回 null 值。 // 如果棧頭此時被取消了,丟棄棧頭,取下一個節點繼續消費 if (timed && nanos <= 0) { // can't wait // 棧頭操作被取消 if (h != null && h.isCancelled()) // 丟棄棧頭,把棧頭后一個元素作為棧頭 casHead(h, h.next); // pop cancelled node //棧頭是空的,直接返回 null else return null; // 沒有超時,直接把 e 作為新的棧頭 } else if (casHead(h, s = snode(s, e, h, mode))) { // e 等待出棧,一種是空隊列 take,一種是 put SNode m = awaitFulfill(s, timed, nanos); if (m == s) { // wait was cancelled clean(s); return null; } // 本來 s 是棧頭的,現在 s 不是棧頭了,s 后面又來了一個數,把新的數據作為棧頭 if ((h = head) != null && h.next == s) casHead(h, s.next); // help s's fulfiller return (E) ((mode == REQUEST) ? m.item : s.item);
} // 棧頭正在等待其他線程 put 或 take // 比如棧頭正在阻塞,并且是 put 類型,而此次操作正好是 take 類型,走此處 } else if (!isFulfilling(h.mode)) { // try to fulfill // 棧頭已經被取消,把下一個元素作為棧頭 if (h.isCancelled()) // already cancelled casHead(h, h.next); // pop and retry // snode 方法第三個參數 h 代表棧頭,賦值給 s 的 next 屬性 else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) { for (;;) { // loop until matched or waiters disappear // m 就是棧頭,通過上面 snode 方法剛剛賦值 SNode m = s.next; // m is s's match if (m == null) { // all waiters are gone casHead(s, null); // pop fulfill node s = null; // use new node next time break; // restart main loop } SNode mn = m.next; // tryMatch 非常重要的方法,兩個作用: // 1 喚醒被阻塞的棧頭 m,2 把當前節點 s 賦值給 m 的 match 屬性 // 這樣棧頭 m 被喚醒時,就能從 m.match 中得到本次操作 s // 其中 s.item 記錄著本次的操作節點,也就是記錄本次操作的數據 if (m.tryMatch(s)) { casHead(s, mn); // pop both s and m return (E) ((mode == REQUEST) ? m.item : s.item); } else // lost match s.casNext(m, mn); // help unlink } } } else { // help a fulfiller SNode m = h.next; // m is h's match if (m == null) // waiter is gone
casHead(h, null); // pop fulfilling node else { SNode mn = m.next; if (m.tryMatch(h)) // help match casHead(h, mn); // pop both h and m else // lost match h.casNext(m, mn); // help unlink } } } }
```
從源碼中密密麻麻的注釋,我們就可以看出來此方法比較復雜,我們總結一下大概的操作思路:
1. 判斷是 put 方法還是 take 方法;
2. 判斷棧頭數據是否為空,如果為空或者棧頭的操作和本次操作一致,是的話走 3,否則走 5;
3. 判斷操作有無設置超時時間,如果設置了超時時間并且已經超時,返回 null,否則走 4;
4. 如果棧頭為空,把當前操作設置成棧頭,或者棧頭不為空,但棧頭的操作和本次操作相同,也把當前操作設置成棧頭,并看看其它線程能否滿足自己,不能滿足則阻塞自己。比如當前操作是 take,但隊列中沒有數據,則阻塞自己;
5. 如果棧頭已經是阻塞住的,需要別人喚醒的,判斷當前操作能否喚醒棧頭,可以喚醒走 6,否則走 4;
6. 把自己當作一個節點,賦值到棧頭的 match 屬性上,并喚醒棧頭節點;
7. 棧頭被喚醒后,拿到 match 屬性,就是把自己喚醒的節點的信息,返回。
在整個過程中,有一個節點阻塞的方法,實現原理如下:
```
SNode awaitFulfill(SNode s, boolean timed, long nanos) { // deadline 死亡時間,如果設置了超時時間的話,死亡時間等于當前時間 + 超時時間,否則就是 0
final long deadline = timed ? System.nanoTime() + nanos : 0L; Thread w = Thread.currentThread(); // 自旋的次數,如果設置了超時時間,會自旋 32 次,否則自旋 512 次。 // 比如本次操作是 take 操作,自選次數后,仍沒有其他線程 put 數據進來 // 就會阻塞,有超時時間的,會阻塞固定的時間,否則一致阻塞下去 int spins = (shouldSpin(s) ? (timed ? maxTimedSpins : maxUntimedSpins) : 0); for (;;) { // 當前線程有無被打斷,如果過了超時時間,當前線程就會被打斷 if (w.isInterrupted()) s.tryCancel(); SNode m = s.match; if (m != null) return m; if (timed) { nanos = deadline - System.nanoTime(); // 超時了,取消當前線程的等待操作 if (nanos <= 0L) { s.tryCancel(); continue; } } // 自選次數減少 1 if (spins > 0) spins = shouldSpin(s) ? (spins-1) : 0; // 把當前線程設置成 waiter,主要是通過線程來完成阻塞和喚醒 else if (s.waiter == null) s.waiter = w; // establish waiter so can park next iter else if (!timed) // 通過 park 進行阻塞,這個我們在鎖章節中會說明 LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold) LockSupport.parkNanos(this, nanos); } }
```
從節點阻塞代碼中,我們可以發現,其阻塞的策略,并不是一上來就阻塞住,而是在自旋一定次數后,仍然沒有其它線程來滿足自己的要求時,才會真正的阻塞住。
### 3 公平的隊列
首先我們來看一下隊列中的每個元素的組成:
```
/** 隊列頭 */ transient volatile QNode head; /** 隊列尾 */ transient volatile QNode tail; // 隊列的元素 static final class QNode { // 當前元素的下一個元素 volatile QNode next; // 當前元素的值,如果當前元素被阻塞住了,等其他線程來喚醒自己時,其他線程 // 會把自己 set 到 item 里面 volatile Object item; // CAS'ed to or from null // 可以阻塞住的當前線程 volatile Thread waiter; // to control park/unpark // true 是 put,false 是 take final boolean isData; }
```
公平的隊列主要使用的是 TransferQueue 內部類的 transfer 方法,我們一起來看下源碼:
```
E transfer(E e, boolean timed, long nanos) { QNode s = null; // constructed/reused as needed // true 是 put,false 是 get boolean isData = (e != null); for (;;) { // 隊列頭和尾的臨時變量,隊列是空的時候,t=h QNode t = tail; QNode h = head; // tail 和 head 沒有初始化時,無限循環 // 雖然這種 continue 非常耗cpu,但感覺不會碰到這種情況 // 因為 tail 和 head 在 TransferQueue 初始化的時候,就已經被賦值空節點了 if (t == null || h == null) continue; // 首尾節點相同,說明是空隊列 // 或者尾節點的操作和當前節點操作一致 if (h == t || t.isData == isData) { QNode tn = t.next; // 當 t 不是 tail 時,說明 tail 已經被修改過了 // 因為 tail 沒有被修改的情況下,t 和 tail 必然相等 // 因為前面剛剛執行賦值操作: t = tail if (t != tail) continue; // 隊尾后面的值還不為空,t 還不是隊尾,直接把 tn 賦值給 t,這是一步加強校驗。 if (tn != null) { advanceTail(t, tn); continue; } //超時直接返回 null if (timed && nanos <= 0) // can't wait return null;
//構造node節點 if (s == null) s = new QNode(e, isData); //如果把 e 放到隊尾失敗,繼續遞歸放進去 if (!t.casNext(null, s)) // failed to link in continue; advanceTail(t, s); // swing tail and wait // 阻塞住自己 Object x = awaitFulfill(s, e, timed, nanos); if (x == s) { // wait was cancelled clean(t, s); return null; } if (!s.isOffList()) { // not already unlinked advanceHead(t, s); // unlink if head if (x != null) // and forget fields s.item = s; s.waiter = null; } return (x != null) ? (E)x : e; // 隊列不為空,并且當前操作和隊尾不一致 // 也就是說當前操作是隊尾是對應的操作 // 比如說隊尾是因為 take 被阻塞的,那么當前操作必然是 put } else { // complementary-mode // 如果是第一次執行,此處的 m 代表就是 tail // 也就是這行代碼體現出隊列的公平,每次操作時,從頭開始按照順序進行操作 QNode m = h.next; // node to fulfill if (t != tail || m == null || h != head) continue; // inconsistent read
Object x = m.item; if (isData == (x != null) || // m already fulfilled x == m || // m cancelled // m 代表棧頭 // 這里把當前的操作值賦值給阻塞住的 m 的 item 屬性 // 這樣 m 被釋放時,就可得到此次操作的值 !m.casItem(x, e)) { // lost CAS advanceHead(h, m); // dequeue and retry continue; } // 當前操作放到隊頭 advanceHead(h, m); // successfully fulfilled // 釋放隊頭阻塞節點 LockSupport.unpark(m.waiter); return (x != null) ? (E)x : e; } } }
```
源碼比較復雜,我們需要搞清楚的是,線程被阻塞住后,當前線程是如何把自己的數據傳給阻塞線程的。為了方便說明,我們假設線程 1 往隊列中 take 數據 ,被阻塞住了,變成阻塞線程 A ,然后線程 2 開始往隊列中 put 數據 B,大致的流程是這樣的:
1. 線程 1 從隊列中拿數據,發現隊列中沒有數據,于是被阻塞,成為 A ;
2. 線程 2 往隊尾 put 數據,會從隊尾往前找到第一個被阻塞的節點,假設此時能找到的就是節點 A,然后線程 B 把將 put 的數據放到節點 A 的 item 屬性里面,并喚醒線程 1;
3. 線程 1 被喚醒后,就能從 A.item 里面拿到線程 2 put 的數據了,線程 1 成功返回。
從這個過程中,我們能看出公平主要體現在,每次 put 數據的時候,都 put 到隊尾上,而每次拿數據時,并不是直接從堆頭拿數據,而是從隊尾往前尋找第一個被阻塞的線程,這樣就會按照順序釋放被阻塞的線程。
### 4 總結
SynchronousQueue 源碼比較復雜,建議大家進行源碼的 debug 來學習源碼,為大家準備了調試類:SynchronousQueueDemo,大家可以下載源碼自己調試一下,這樣學起來應該會更加輕松一點。
- 前言
- 第1章 基礎
- 01 開篇詞:為什么學習本專欄
- 02 String、Long 源碼解析和面試題
- 03 Java 常用關鍵字理解
- 04 Arrays、Collections、Objects 常用方法源碼解析
- 第2章 集合
- 05 ArrayList 源碼解析和設計思路
- 06 LinkedList 源碼解析
- 07 List 源碼會問哪些面試題
- 08 HashMap 源碼解析
- 09 TreeMap 和 LinkedHashMap 核心源碼解析
- 10 Map源碼會問哪些面試題
- 11 HashSet、TreeSet 源碼解析
- 12 彰顯細節:看集合源碼對我們實際工作的幫助和應用
- 13 差異對比:集合在 Java 7 和 8 有何不同和改進
- 14 簡化工作:Guava Lists Maps 實際工作運用和源碼
- 第3章 并發集合類
- 15 CopyOnWriteArrayList 源碼解析和設計思路
- 16 ConcurrentHashMap 源碼解析和設計思路
- 17 并發 List、Map源碼面試題
- 18 場景集合:并發 List、Map的應用場景
- 第4章 隊列
- 19 LinkedBlockingQueue 源碼解析
- 20 SynchronousQueue 源碼解析
- 21 DelayQueue 源碼解析
- 22 ArrayBlockingQueue 源碼解析
- 23 隊列在源碼方面的面試題
- 24 舉一反三:隊列在 Java 其它源碼中的應用
- 25 整體設計:隊列設計思想、工作中使用場景
- 26 驚嘆面試官:由淺入深手寫隊列
- 第5章 線程
- 27 Thread 源碼解析
- 28 Future、ExecutorService 源碼解析
- 29 押寶線程源碼面試題
- 第6章 鎖
- 30 AbstractQueuedSynchronizer 源碼解析(上)
- 31 AbstractQueuedSynchronizer 源碼解析(下)
- 32 ReentrantLock 源碼解析
- 33 CountDownLatch、Atomic 等其它源碼解析
- 34 只求問倒:連環相扣系列鎖面試題
- 35 經驗總結:各種鎖在工作中使用場景和細節
- 36 從容不迫:重寫鎖的設計結構和細節
- 第7章 線程池
- 37 ThreadPoolExecutor 源碼解析
- 38 線程池源碼面試題
- 39 經驗總結:不同場景,如何使用線程池
- 40 打動面試官:線程池流程編排中的運用實戰
- 第8章 Lambda 流
- 41 突破難點:如何看 Lambda 源碼
- 42 常用的 Lambda 表達式使用場景解析和應用
- 第9章 其他
- 43 ThreadLocal 源碼解析
- 44 場景實戰:ThreadLocal 在上下文傳值場景下的實踐
- 45 Socket 源碼及面試題
- 46 ServerSocket 源碼及面試題
- 47 工作實戰:Socket 結合線程池的使用
- 第10章 專欄總結
- 48 一起看過的 Java 源碼和面試真題