# 一、機器學習概覽
> 譯者:[@SeanCheney](https://www.jianshu.com/u/130f76596b02)
>
> 校對者:[@Lisanaaa](https://github.com/Lisanaaa)、[@飛龍](https://github.com/wizardforcel)、[@yanmengk](https://github.com/yanmengk)、[@Liu Shangfeng](https://github.com/codershangfeng)
大多數人聽到“機器學習”,往往會在腦海中勾勒出一個機器人:一個可靠的管家,或是一個可怕的終結者,這取決于你問的是誰。但是機器學習并不是未來的幻想,它已經來到我們身邊了。事實上,一些特定領域已經應用機器學習幾十年了,比如光學字符識別 (Optical Character Recognition,OCR)。但是直到 1990 年代,第一個影響了數億人的機器學習應用才真正成熟,它就是垃圾郵件過濾器(spam filter)。雖然并不是一個有自我意識的天網系統(Skynet),垃圾郵件過濾器從技術上是符合機器學習的(它可以很好地進行學習,用戶幾乎不用再標記某個郵件為垃圾郵件)。后來出現了更多的數以百計的機器學習產品,支撐了更多你經常使用的產品和功能,從推薦系統到語音識別。
機器學習的起點和終點分別是什么呢?確切的講,機器進行學習是什么意思?如果我下載了一份維基百科的拷貝,我的電腦就真的學會了什么嗎?它馬上就變聰明了嗎?在本章中,我們首先會澄清機器學習到底是什么,以及為什么你要使用它。
然后,在我們出發去探索機器學習新大陸之前,我們要觀察下地圖,以便知道這片大陸上的主要地區和最明顯的地標:監督學習 vs 非監督學習,在線學習 vs 批量學習,基于實例 vs 基于模型學習。然后,我們會學習一個典型的機器學習項目的工作流程,討論可能碰到的難點,以及如何評估和微調一個機器學習系統。
這一章介紹了大量每個數據科學家需要牢記在心的基礎概念(和習語)。第一章只是概覽(唯一不含有代碼的一章),相當簡單,但你要確保每一點都搞明白了,再繼續進行學習本書其余章節。端起一杯咖啡,開始學習吧!
> 提示:如果你已經知道了機器學習的所有基礎概念,可以直接翻到第 2 章。如果你不確認,可以嘗試回答本章末尾列出的問題,然后再繼續。
# 什么是機器學習?
機器學習是通過編程讓計算機從數據中進行學習的科學(和藝術)。
下面是一個更廣義的概念:
機器學習是讓計算機具有學習的能力,無需進行明確編程。 —— 亞瑟·薩繆爾,1959
和一個工程性的概念:
計算機程序利用經驗 E 學習任務 T,性能是 P,如果針對任務 T 的性能 P 隨著經驗 E 不斷增長,則稱為機器學習。 —— 湯姆·米切爾,1997
例如,你的垃圾郵件過濾器就是一個機器學習程序,它可以根據垃圾郵件(比如,用戶標記的垃圾郵件)和普通郵件(非垃圾郵件,也稱作 ham)學習標記垃圾郵件。用來進行學習的樣例稱作訓練集。每個訓練樣例稱作訓練實例(或樣本)。在這個例子中,任務 T 就是標記新郵件是否是垃圾郵件,經驗 E 是訓練數據,性能 P 需要定義:例如,可以使用正確分類的比例。這個性能指標稱為準確率,通常用在分類任務中。
如果你下載了一份維基百科的拷貝,你的電腦雖然有了很多數據,但不會馬上變得聰明起來。因此,這不是機器學習。
# 為什么使用機器學習?
思考一下,你會如何使用傳統的編程技術寫一個垃圾郵件過濾器(圖 1-1):
1. 你先觀察下垃圾郵件一般都是什么樣子。你可能注意到一些詞或短語(比如 4U、credit card、free、amazing)在郵件主題中頻繁出現,也許還注意到發件人名字、郵件正文的格式,等等。
2. 你為觀察到的規律寫了一個檢測算法,如果檢測到了這些規律,程序就會標記郵件為垃圾郵件。
3. 測試程序,重復第 1 步和第 2 步,直到滿足要求。
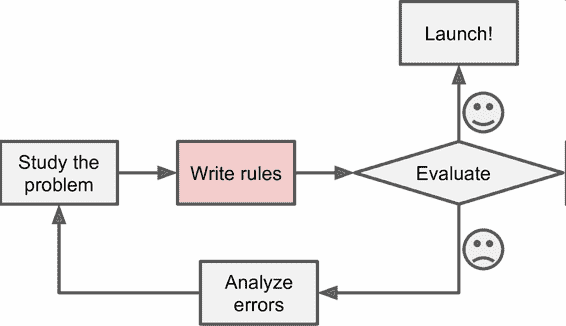
圖 1-1 傳統方法
這個問題并不簡單,你的程序很可能會變成一長串復雜的規則—— 這樣就會很難維護。
相反的,基于機器學習技術的垃圾郵件過濾器會自動學習哪個詞和短語是垃圾郵件的預測值,通過與普通郵件比較,檢測垃圾郵件中反常頻次的詞語格式(圖 1-2)。這個程序短得多,更易維護,也更精確。
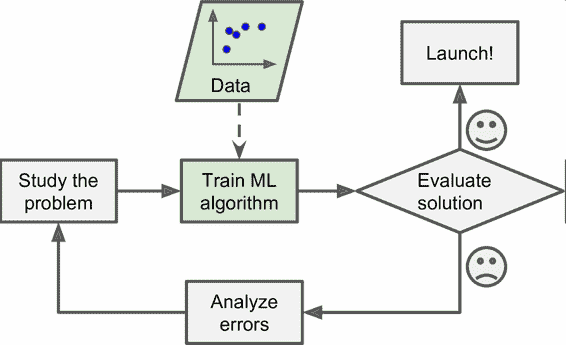
圖 1-2 機器學習方法
進而,如果發送垃圾郵件的人發現所有包含“4U”的郵件都被屏蔽了,可能會轉而使用“For U”。使用傳統方法的垃圾郵件過濾器需要更新以標記“For U”。如果發送垃圾郵件的人持續更改,你就需要被動地不停地寫入新規則。
相反的,基于機器學習的垃圾郵件過濾器會自動注意到“For U”在用戶手動標記垃圾郵件中的反常頻繁性,然后就能自動標記垃圾郵件而無需干預了(圖 1-3)。
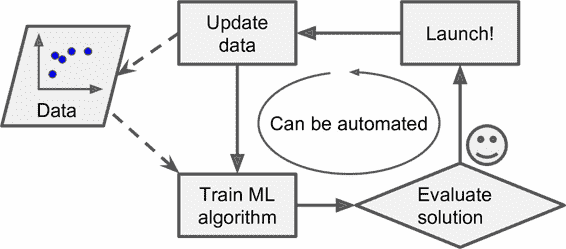
圖 1-3 自動適應改變
機器學習的另一個優點是善于處理對于傳統方法太復雜或是沒有已知算法的問題。例如,對于語言識別:假如想寫一個可以識別“one”和“two”的簡單程序。你可能注意到“two”起始是一個高音(“T”),所以可以寫一個可以測量高音強度的算法,用它區分 one 和 two。很明顯,這個方法不能推廣到嘈雜環境下的數百萬人的數千詞匯、數十種語言。(現在)最佳的方法是根據大量單詞的錄音,寫一個可以自我學習的算法。
最后,機器學習可以幫助人類進行學習(圖 1-4):可以檢查機器學習算法已經掌握了什么(盡管對于某些算法,這樣做會有點麻煩)。例如,當垃圾郵件過濾器被訓練了足夠多的垃圾郵件,就可以用它列出垃圾郵件預測值的單詞和單詞組合列表。有時,可能會發現不引人關注的關聯或新趨勢,有助于對問題更好的理解。
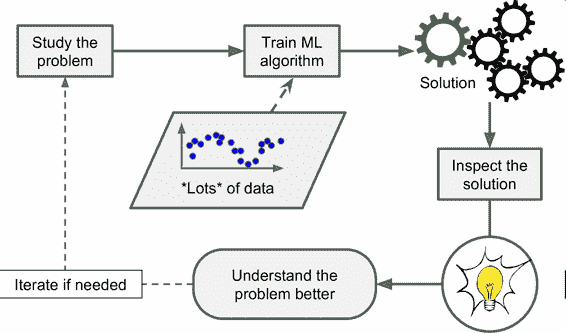
圖 1-4 機器學習可以幫助人類學習
使用機器學習方法挖掘大量數據,可以發現并不顯著的規律。這稱作數據挖掘。
總結一下,機器學習善于:
* ? 需要進行大量手工調整或需要擁有長串規則才能解決的問題:機器學習算法通常可以簡化代碼、提高性能。
* 問題復雜,傳統方法難以解決:最好的機器學習方法可以找到解決方案。
* 環境有波動:機器學習算法可以適應新數據。
* 洞察復雜問題和大量數據。
# 機器學習系統的類型
機器學習有多種類型,可以根據如下規則進行分類:
* 是否在人類監督下進行訓練(監督,非監督,半監督和強化學習)
* 是否可以動態漸進學習(在線學習 vs 批量學習)
* 它們是否只是通過簡單地比較新的數據點和已知的數據點,還是在訓練數據中進行模式識別,以建立一個預測模型,就像科學家所做的那樣(基于實例學習 vs 基于模型學習)
規則并不僅限于以上的,你可以將他們進行組合。例如,一個先進的垃圾郵件過濾器可以使用神經網絡模型動態進行學習,用垃圾郵件和普通郵件進行訓練。這就讓它成了一個在線、基于模型、監督學習系統。
下面更仔細地學習這些規則。
## 監督/非監督學習
機器學習可以根據訓練時監督的量和類型進行分類。主要有四類:監督學習、非監督學習、半監督學習和強化學習。
### 監督學習
在監督學習中,用來訓練算法的訓練數據包含了答案,稱為標簽(圖 1-5)。
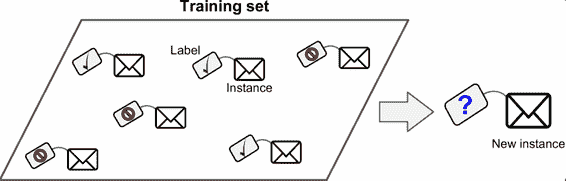
圖 1-5 用于監督學習(比如垃圾郵件分類)的加了標簽的訓練集
一個典型的監督學習任務是分類。垃圾郵件過濾器就是一個很好的例子:用許多帶有歸類(垃圾郵件或普通郵件)的郵件樣本進行訓練,過濾器必須還能對新郵件進行分類。
另一個典型任務是預測目標數值,例如給出一些特征(里程數、車齡、品牌等等)稱作預測值,來預測一輛汽車的價格。這類任務稱作回歸(圖 1-6)。要訓練這個系統,你需要給出大量汽車樣本,包括它們的預測值和標簽(即,它們的價格)。
> 注解:在機器學習中,一個屬性就是一個數據類型(例如,“里程數”),取決于具體問題一個特征會有多個含義,但通常是屬性加上它的值(例如,“里程數`=15000`”)。許多人是不區分地使用屬性和特征。
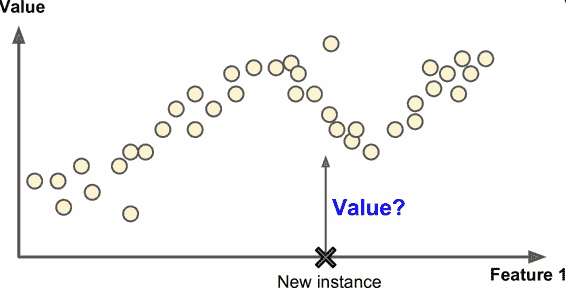
圖 1-6 回歸
注意,一些回歸算法也可以用來進行分類,反之亦然。例如,邏輯回歸通常用來進行分類,它可以生成一個歸屬某一類的可能性的值(例如,20% 幾率為垃圾郵件)。
下面是一些重要的監督學習算法(本書都有介紹):
* K 近鄰算法
* 線性回歸
* 邏輯回歸
* 支持向量機(SVM)
* 決策樹和隨機森林
* 神經網絡
## 非監督學習
在非監督學習中,你可能猜到了,訓練數據是沒有加標簽的(圖 1-7)。系統在沒有老師的條件下進行學習。

圖 1-7 非監督學習的一個不加標簽的訓練集
下面是一些最重要的非監督學習算法(我們會在第 8 章介紹降維):
* **聚類**
K 均值
層次聚類分析(Hierarchical Cluster Analysis,HCA)
期望最大值
* **可視化和降維**
主成分分析(Principal Component Analysis,PCA)
核主成分分析
局部線性嵌入(Locally-Linear Embedding,LLE)
t-分布鄰域嵌入算法(t-distributed Stochastic Neighbor Embedding,t-SNE)
* **關聯性規則學習**
Apriori 算法
Eclat 算法
例如,假設你有一份關于你的博客訪客的大量數據。你想運行一個聚類算法,檢測相似訪客的分組(圖 1-8)。你不會告訴算法某個訪客屬于哪一類:它會自己找出關系,無需幫助。例如,算法可能注意到 40% 的訪客是喜歡漫畫書的男性,通常是晚上訪問,20% 是科幻愛好者,他們是在周末訪問等等。如果你使用層次聚類分析,它可能還會細分每個分組為更小的組。這可以幫助你為每個分組定位博文。
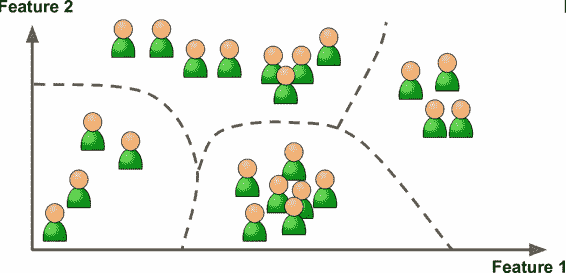
圖 1-8 聚類
可視化算法也是極佳的非監督學習案例:給算法大量復雜的且不加標簽的數據,算法輸出數據的 2D 或 3D 圖像(圖 1-9)。算法會試圖保留數據的結構(即嘗試保留輸入的獨立聚類,避免在圖像中重疊),這樣就可以明白數據是如何組織起來的,也許還能發現隱藏的規律。
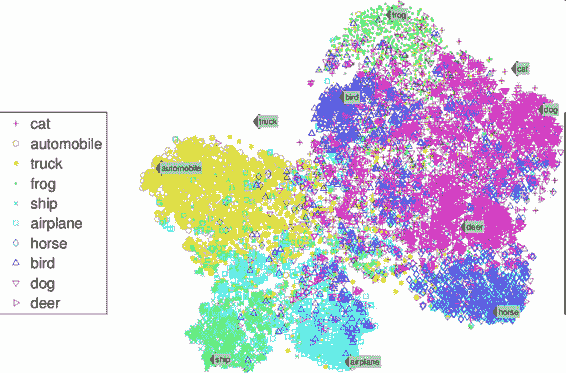
圖 1-9 t-SNE 可視化案例,突出了聚類(注:注意動物是與汽車分開的,馬和鹿很近、與鳥距離遠,以此類推)
與此有關聯的任務是降維,降維的目的是簡化數據、但是不能失去大部分信息。做法之一是合并若干相關的特征。例如,汽車的里程數與車齡高度相關,降維算法就會將它們合并成一個,表示汽車的磨損。這叫做特征提取。
> 提示:在用訓練集訓練機器學習算法(比如監督學習算法)時,最好對訓練集進行降維。這樣可以運行的更快,占用的硬盤和內存空間更少,有些情況下性能也更好。
另一個重要的非監督任務是異常檢測(anomaly detection) —— 例如,檢測異常的信用卡轉賬以防欺詐,檢測制造缺陷,或者在訓練之前自動從訓練數據集去除異常值。異常檢測的系統使用正常值訓練的,當它碰到一個新實例,它可以判斷這個新實例是像正常值還是異常值(圖 1-10)。

圖 1-10 異常檢測
最后,另一個常見的非監督任務是關聯規則學習,它的目標是挖掘大量數據以發現屬性間有趣的關系。例如,假設你擁有一個超市。在銷售日志上運行關聯規則,可能發現買了燒烤醬和薯片的人也會買牛排。因此,你可以將這些商品放在一起。
## 半監督學習
一些算法可以處理部分帶標簽的訓練數據,通常是大量不帶標簽數據加上小部分帶標簽數據。這稱作半監督學習(圖 1-11)。
一些圖片存儲服務,比如 Google Photos,是半監督學習的好例子。一旦你上傳了所有家庭相片,它就能自動識別到人物 A 出現在了相片 1、5、11 中,另一個人 B 出現在了相片 2、5、7 中。這是算法的非監督部分(聚類)。現在系統需要的就是你告訴它這兩個人是誰。只要給每個人一個標簽,算法就可以命名每張照片中的每個人,特別適合搜索照片。
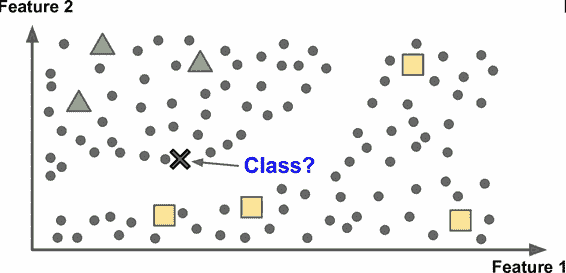
圖 1-11 半監督學習
多數半監督學習算法是非監督和監督算法的結合。例如,深度信念網絡(deep belief networks)是基于被稱為互相疊加的受限玻爾茲曼機(restricted Boltzmann machines,RBM)的非監督組件。RBM 是先用非監督方法進行訓練,再用監督學習方法對整個系統進行微調。
## 強化學習
強化學習非常不同。學習系統在這里被稱為智能體(agent),可以對環境進行觀察、選擇和執行動作,并獲得獎勵作為回報(負獎勵是懲罰,見圖 1-12)。然后它必須自己學習哪個是最佳方法(稱為策略,policy),以得到長久的最大獎勵。策略決定了智能體在給定情況下應該采取的行動。
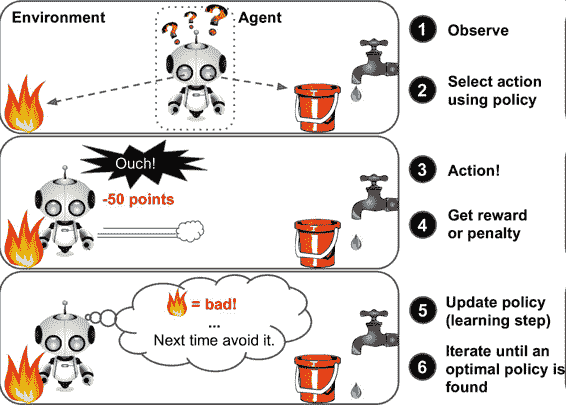
圖 1-12 強化學習
例如,許多機器人運行強化學習算法以學習如何行走。DeepMind 的 AlphaGo 也是強化學習的例子:它在 2016 年三月擊敗了世界圍棋冠軍李世石(譯者注:2017 年五月,AlphaGo 又擊敗了世界排名第一的柯潔)。它是通過分析數百萬盤棋局學習制勝策略,然后自己和自己下棋。要注意,在比賽中機器學習是關閉的;AlphaGo 只是使用它學會的策略。
# 批量和在線學習
另一個用來分類機器學習的準則是,它是否能從導入的數據流進行持續學習。
## 批量學習
在批量學習中,系統不能進行持續學習:必須用所有可用數據進行訓練。這通常會占用大量時間和計算資源,所以一般是線下做的。首先是進行訓練,然后部署在生產環境且停止學習,它只是使用已經學到的策略。這稱為離線學習。
如果你想讓一個批量學習系統明白新數據(例如垃圾郵件的新類型),就需要從頭訓練一個系統的新版本,使用全部數據集(不僅有新數據也有老數據),然后停掉老系統,換上新系統。
幸運的是,訓練、評估、部署一套機器學習的系統的整個過程可以自動進行(見圖 1-3),所以即便是批量學習也可以適應改變。只要有需要,就可以方便地更新數據、訓練一個新版本。
這個方法很簡單,通常可以滿足需求,但是用全部數據集進行訓練會花費大量時間,所以一般是每 24 小時或每周訓練一個新系統。如果系統需要快速適應變化的數據(比如,預測股價變化),就需要一個響應更及時的方案。
另外,用全部數據訓練需要大量計算資源(CPU、內存空間、磁盤空間、磁盤 I/O、網絡 I/O 等等)。如果你有大量數據,并讓系統每天自動從頭開始訓練,就會開銷很大。如果數據量巨大,甚至無法使用批量學習算法。
最后,如果你的系統需要自動學習,但是資源有限(比如,一臺智能手機或火星車),攜帶大量訓練數據、每天花費數小時的大量資源進行訓練是不實際的。
幸運的是,對于上面這些情況,還有一個更佳的方案可以進行持續學習。
## 在線學習
在在線學習中,是用數據實例持續地進行訓練,可以一次一個或一次幾個實例(稱為小批量)。每個學習步驟都很快且廉價,所以系統可以動態地學習收到的最新數據(見圖 1-13)。
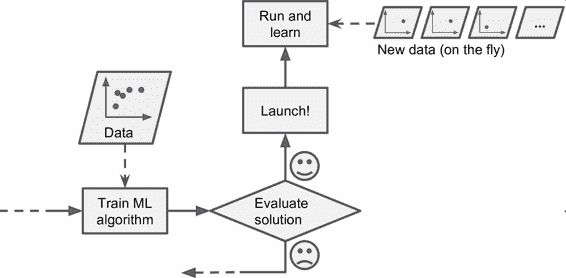
圖 1-13 在線學習
在線學習很適合系統接收連續流的數據(比如,股票價格),且需要自動對改變作出調整。如果計算資源有限,在線學習是一個不錯的方案:一旦在線學習系統學習了新的數據實例,它就不再需要這些數據了,所以扔掉這些數據(除非你想滾回到之前的一個狀態,再次使用數據)。這樣可以節省大量的空間。
在線學習算法也適用于在超大數據集(一臺計算機不足以用于存儲它)上訓練系統(這稱作核外學習,*out-of-core* learning)。算法每次只加載部分數據,用這些數據進行訓練,然后重復這個過程,直到使用完所有數據(見圖 1-14)。
> 警告:這個整個過程通常是離線完成的(即,不在部署的系統上),所以在線學習這個名字會讓人疑惑。可以把它想成持續學習。

圖 1-14 使用在線學習處理大量數據集
在線學習系統的一個重要參數是,它們可以多快地適應數據的改變:這被稱為學習速率。如果你設定一個高學習速率,系統就可以快速適應新數據,但是也會快速忘記老數據(你可不想讓垃圾郵件過濾器只標記最新的垃圾郵件種類)。相反的,如果你設定的學習速率低,系統的惰性就會強:即,它學的更慢,但對新數據中的噪聲或沒有代表性的數據點結果不那么敏感。
在線學習的挑戰之一是,如果壞數據被用來進行訓練,系統的性能就會逐漸下滑。如果這是一個部署的系統,用戶就會注意到。例如,壞數據可能來自失靈的傳感器或機器人,或某人向搜索引擎傳入垃圾信息以提高搜索排名。要減小這種風險,你需要密集監測,如果檢測到性能下降,要快速關閉(或是滾回到一個之前的狀態)。你可能還要監測輸入數據,對反常數據做出反應(比如,使用異常檢測算法)。
# 基于實例 vs 基于模型學習
另一種分類機器學習的方法是判斷它們是如何進行歸納推廣的。大多機器學習任務是關于預測的。這意味著給定一定數量的訓練樣本,系統需要能推廣到之前沒見到過的樣本。對訓練數據集有很好的性能還不夠,真正的目標是對新實例預測的性能。
有兩種主要的歸納方法:基于實例學習和基于模型學習。
## 基于實例學習
也許最簡單的學習形式就是用記憶學習。如果用這種方法做一個垃圾郵件檢測器,只需標記所有和用戶標記的垃圾郵件相同的郵件 —— 這個方法不差,但肯定不是最好的。
不僅能標記和已知的垃圾郵件相同的郵件,你的垃圾郵件過濾器也要能標記類似垃圾郵件的郵件。這就需要測量兩封郵件的相似性。一個(簡單的)相似度測量方法是統計兩封郵件包含的相同單詞的數量。如果一封郵件含有許多垃圾郵件中的詞,就會被標記為垃圾郵件。
這被稱作基于實例學習:系統先用記憶學習案例,然后使用相似度測量推廣到新的例子(圖 1-15)。
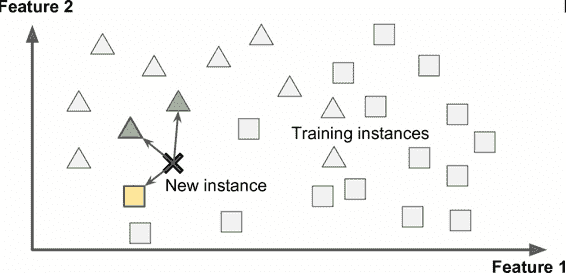
圖 1-15 基于實例學習
## 基于模型學習
另一種從樣本集進行歸納的方法是建立這些樣本的模型,然后使用這個模型進行預測。這稱作基于模型學習(圖 1-16)。
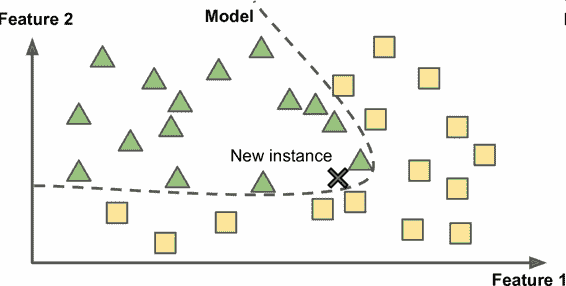
圖 1-16 基于模型學習
例如,你想知道錢是否能讓人快樂,你從 [OECD 網站](http://stats.oecd.org/index.aspx?DataSetCode=BLI)下載了 Better Life Index 指數數據,還從 [IMF](http://www.imf.org/external/pubs/ft/weo/2016/01/weodata/weorept.aspx?pr.x=32&pr.y=8&sy=2015&ey=2015&scsm=1&ssd=1&sort=country&ds=.&br=1&c=512%2C668%2C914%2C672%2C612%2C946%2C614%2C137%2C311%2C962%2C213%2C674%2C911%2C676%2C193%2C548%2C122%2C556%2C912%2C678%2C313%2C181%2C419%2C867%2C513%2C682%2C316%2C684%2C913%2C273%2C124%2C868%2C339%2C921%2C638%2C948%2C514%2C943%2C218%2C686%2C963%2C688%2C616%2C518%2C223%2C728%2C516%2C558%2C918%2C138%2C748%2C196%2C618%2C278%2C624%2C692%2C522%2C694%2C622%2C142%2C156%2C449%2C626%2C564%2C628%2C565%2C228%2C283%2C924%2C853%2C233%2C288%2C632%2C293%2C636%2C566%2C634%2C964%2C238%2C182%2C662%2C453%2C960%2C968%2C423%2C922%2C935%2C714%2C128%2C862%2C611%2C135%2C321%2C716%2C243%2C456%2C248%2C722%2C469%2C942%2C253%2C718%2C642%2C724%2C643%2C576%2C939%2C936%2C644%2C961%2C819%2C813%2C172%2C199%2C132%2C733%2C646%2C184%2C648%2C524%2C915%2C361%2C134%2C362%2C652%2C364%2C174%2C732%2C328%2C366%2C258%2C734%2C656%2C144%2C654%2C146%2C336%2C463%2C263%2C528%2C268%2C923%2C532%2C738%2C944%2C578%2C176%2C537%2C534%2C742%2C536%2C866%2C429%2C369%2C433%2C744%2C178%2C186%2C436%2C925%2C136%2C869%2C343%2C746%2C158%2C926%2C439%2C466%2C916%2C112%2C664%2C111%2C826%2C298%2C542%2C927%2C967%2C846%2C443%2C299%2C917%2C582%2C544%2C474%2C941%2C754%2C446%2C698%2C666&s=NGDPDPC&grp=0&a=) 下載了人均 GDP 數據。表 1-1 展示了摘要。

表 1-1 錢會使人幸福嗎?
用一些國家的數據畫圖(圖 1-17)。
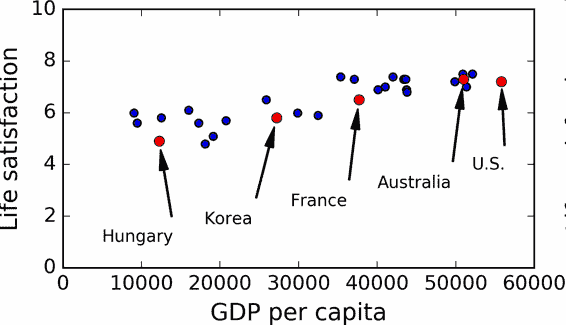
圖 1-17 你看到趨勢了嗎?
確實能看到趨勢!盡管數據有噪聲(即,部分隨機),看起來生活滿意度是隨著人均 GDP 的增長線性提高的。所以,你決定生活滿意度建模為人均 GDP 的線性函數。這一步稱作模型選擇:你選一個生活滿意度的線性模型,只有一個屬性,人均 GDP(公式 1-1)。
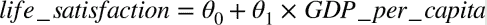
公式 1-1 一個簡單的線性模型
這個模型有兩個參數`θ0`和`θ1`。通過調整這兩個參數,你可以使你的模型表示任何線性函數,見圖 1-18。
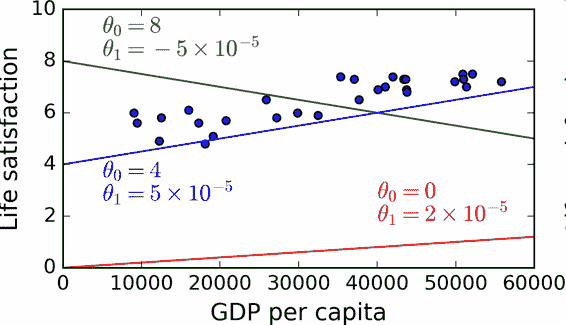
圖 1-18 幾個可能的線性模型
在使用模型之前,你需要確定`θ0`和`θ1`。如何能知道哪個值可以使模型的性能最佳呢?要回答這個問題,你需要指定性能的量度。你可以定義一個實用函數(或擬合函數)用來測量模型是否夠好,或者你可以定義一個代價函數來測量模型有多差。對于線性回歸問題,人們一般是用代價函數測量線性模型的預測值和訓練樣本之間的距離差,目標是使距離差最小。
接下來就是線性回歸算法,你用訓練樣本訓練算法,算法找到使線性模型最擬合數據的參數。這稱作模型訓練。在我們的例子中,算法得到的參數值是`θ0=4.85`和`θ1=4.91×10–5`。
現在模型已經最緊密地擬合到訓練數據了,見圖 1-19。
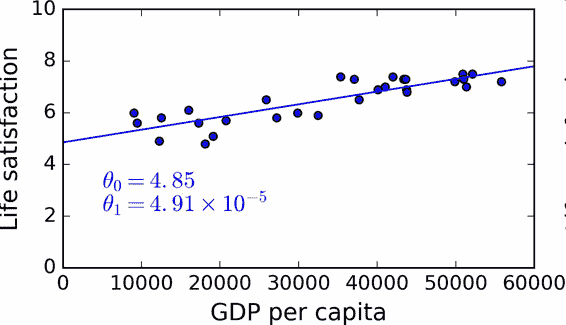
圖 1-19 最佳擬合訓練數據的線性模型
最后,可以準備運行模型進行預測了。例如,假如你想知道塞浦路斯人有多幸福,但 OECD 沒有它的數據。幸運的是,你可以用模型進行預測:查詢塞浦路斯的人均 GDP,為 22587 美元,然后應用模型得到生活滿意度,后者的值在`4.85 + 22,587 × 4.91 × 10-5 = 5.96`左右。
為了激起你的興趣,案例 1-1 展示了加載數據、準備、創建散點圖的 Python 代碼,然后訓練線性模型并進行預測。
案例 1-1,使用 Scikit-Learn 訓練并運行線性模型。
```python
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn
# 加載數據
oecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter='\t',
encoding='latin1', na_values="n/a")
# 準備數據
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# 可視化數據
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
# 選擇線性模型
lin_reg_model = sklearn.linear_model.LinearRegression()
# 訓練模型
lin_reg_model.fit(X, y)
# 對塞浦路斯進行預測
X_new = [[22587]] # 塞浦路斯的人均 GDP
print(lin_reg_model.predict(X_new)) # outputs [[ 5.96242338]]
```
> 注解:如果你之前接觸過基于實例學習算法,你會發現斯洛文尼亞的人均 GDP(20732 美元)和塞浦路斯差距很小,OECD 數據上斯洛文尼亞的生活滿意度是 5.7,就可以預測塞浦路斯的生活滿意度也是 5.7。如果放大一下范圍,看一下接下來兩個臨近的國家,你會發現葡萄牙和西班牙的生活滿意度分別是 5.1 和 6.5。對這三個值進行平均得到 5.77,就和基于模型的預測值很接近。這個簡單的算法叫做 k 近鄰回歸(這個例子中,`k=3`)。
>
> 在前面的代碼中替換線性回歸模型為 K 近鄰模型,只需更換下面一行:
>
> ```py
> clf = sklearn.linear_model.LinearRegression()
>
> ```
>
> 為:
>
> ```py
> clf = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
>
> ```
如果一切順利,你的模型就可以作出好的預測。如果不能,你可能需要使用更多的屬性(就業率、健康、空氣污染等等),獲取更多更好的訓練數據,或選擇一個更好的模型(比如,多項式回歸模型)。
總結一下:
* 研究數據
* 選擇模型
* 用訓練數據進行訓練(即,學習算法搜尋模型參數值,使代價函數最小)
* 最后,使用模型對新案例進行預測(這稱作推斷),但愿這個模型推廣效果不差
這就是一個典型的機器學習項目。在第 2 章中,你會第一手地接觸一個完整的項目。
我們已經學習了許多關于基礎的內容:你現在知道了機器學習是關于什么的、為什么它這么有用、最常見的機器學習的分類、典型的項目工作流程。現在,讓我們看一看學習中會發生什么錯誤,導致不能做出準確的預測。
# 機器學習的主要挑戰
簡而言之,因為你的主要任務是選擇一個學習算法并用一些數據進行訓練,會導致錯誤的兩件事就是“錯誤的算法”和“錯誤的數據”。我們從錯誤的數據開始。
## 訓練數據量不足
要讓一個蹣跚學步的孩子知道什么是蘋果,需要做的就是指著一個蘋果說“蘋果”(可能需要重復這個過程幾次)。現在這個孩子就能認識所有形狀和顏色的蘋果。真是個天才!
機器學習還達不到這個程度;需要大量數據,才能讓多數機器學習算法正常工作。即便對于非常簡單的問題,一般也需要數千的樣本,對于復雜的問題,比如圖像或語音識別,你可能需要數百萬的樣本(除非你能重復使用部分存在的模型)。
> 數據的不可思議的有效性
>
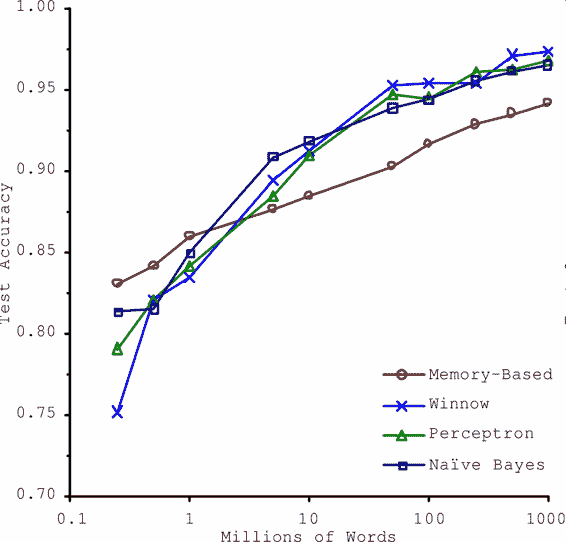
> 在一篇 2001 年發表的[著名論文](http://ucrel.lancs.ac.uk/acl/P/P01/P01-1005.pdf)中,微軟研究員 Michele Banko 和 Eric Brill 展示了不同的機器學習算法,包括非常簡單的算法,一旦有了大量數據進行訓練,在進行去除語言歧義的測試中幾乎有相同的性能(見圖 1-20)。
>
> 
>
> 圖 1-20 數據和算法的重要性對比
>
> 論文作者說:“結果說明,我們可能需要重新考慮在算法開發 vs 語料庫發展上花費時間和金錢的取舍。”
>
> 對于復雜問題,數據比算法更重要的主張在 2009 年由 Norvig 發表的論文[《The Unreasonable Effectiveness of Data》](https://link.jianshu.com?t=http%3A%2F%2Fstatic.googleusercontent.com%2Fmedia%2Fresearch.google.com%2Ffr%2F%2Fpubs%2Farchive%2F35179.pdf)得到了進一步的推廣。但是,應該注意到,小型和中型的數據集仍然是非常常見的,獲得額外的訓練數據并不總是輕易和廉價的,所以不要拋棄算法。
## 沒有代表性的訓練數據
為了更好地進行歸納推廣,讓訓練數據對新數據具有代表性是非常重要的。無論你用的是基于實例學習或基于模型學習,這點都很重要。
例如,我們之前用來訓練線性模型的國家集合不夠具有代表性:缺少了一些國家。圖 1-21 展示了添加這些缺失國家之后的數據。
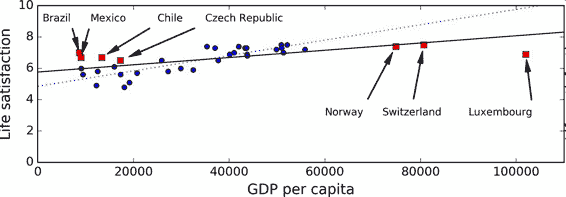
圖 1-21 一個更具代表性的訓練樣本
如果你用這份數據訓練線性模型,得到的是實線,舊模型用虛線表示。可以看到,添加幾個國家不僅可以顯著地改變模型,它還說明如此簡單的線性模型可能永遠不會達到很好的性能。貌似非常富裕的國家沒有中等富裕的國家快樂(事實上,非常富裕的國家看起來更不快樂),相反的,一些貧窮的國家看上去比富裕的國家還幸福。
使用了沒有代表性的數據集,我們訓練了一個不可能得到準確預測的模型,特別是對于非常貧窮和非常富裕的國家。
使用具有代表性的訓練集對于推廣到新案例是非常重要的。但是做起來比說起來要難:如果樣本太小,就會有樣本噪聲(即,會有一定概率包含沒有代表性的數據),但是即使是非常大的樣本也可能沒有代表性,如果取樣方法錯誤的話。這叫做樣本偏差。
> 一個樣本偏差的著名案例
>
> 也許關于樣本偏差最有名的案例發生在 1936 年蘭登和羅斯福的美國大選:《文學文摘》做了一個非常大的民調,給 1000 萬人郵寄了調查信。得到了 240 萬回信,非常有信心地預測蘭登會以 57% 贏得大選。然而,羅斯福贏得了 62% 的選票。錯誤發生在《文學文摘》的取樣方法:
>
> * 首先,為了獲取發信地址,《文學文摘》使用了電話黃頁、雜志訂閱用戶、俱樂部會員等相似的列表。所有這些列表都偏向于富裕人群,他們都傾向于投票給共和黨(即蘭登)。
> * 第二,只有 25% 的回答了調研。這就又一次引入了樣本偏差,它排除了不關心政治的人、不喜歡《文學文摘》的人,和其它關鍵人群。這種特殊的樣本偏差稱作無應答偏差。
>
> 下面是另一個例子:假如你想創建一個能識別放克音樂(Funk Music, 別名騷樂)視頻的系統。建立訓練集的方法之一是在 YouTube 上搜索“放克音樂”,使用搜索到的視頻。但是這樣就假定了 YouTube 的搜索引擎返回的視頻集,是對 YouTube 上的所有放克音樂有代表性的。事實上,搜索結果可能更偏向于流行歌手(如果你居住在巴西,你會得到許多“funk carioca”視頻,它們和 James Brown 的截然不同)。從另一方面來講,你還能怎么得到一個大的訓練集呢?
## 低質量數據
很明顯,如果訓練集中的錯誤、異常值和噪聲(錯誤測量引入的)太多,系統檢測出潛在規律的難度就會變大,性能就會降低。花費時間對訓練數據進行清理是十分重要的。事實上,大多數據科學家的一大部分時間是做清洗工作的。例如:
* 如果一些實例是明顯的異常值,最好刪掉它們或嘗試手工修改錯誤;
* 如果一些實例缺少特征(比如,你的 5% 的顧客沒有說明年齡),你必須決定是否忽略這個屬性、忽略這些實例、填入缺失值(比如,年齡中位數),或者訓練一個含有這個特征的模型和一個不含有這個特征的模型,等等。
## 不相關的特征
俗語說:如果進來的是垃圾,那么出去的也是垃圾。你的系統只有在訓練數據包含足夠相關特征、非相關特征不多的情況下,才能進行學習。機器學習項目成功的關鍵之一是用好的特征進行訓練。這個過程稱作特征工程,包括:
* 特征選擇:在所有存在的特征中選取最有用的特征進行訓練。
* 特征提取:組合存在的特征,生成一個更有用的特征(如前面看到的,可以使用降維算法)。
* 收集新數據創建新特征。
現在,我們已經看過了許多壞數據的例子,接下來看幾個壞算法的例子。
## 過擬合訓練數據
如果你在外國游玩,當地的出租車司機多收了你的錢。你可能會說這個國家所有的出租車司機都是小偷。過度歸納是我們人類經常做的,如果我們不小心,機器也會犯同樣的錯誤。在機器學習中,這稱作過擬合:意思是說,模型在訓練數據上表現很好,但是推廣效果不好。
圖 1-22 展示了一個高階多項式生活滿意度模型,它大大過擬合了訓練數據。即使它比簡單線性模型在訓練數據上表現更好,你會相信它的預測嗎?
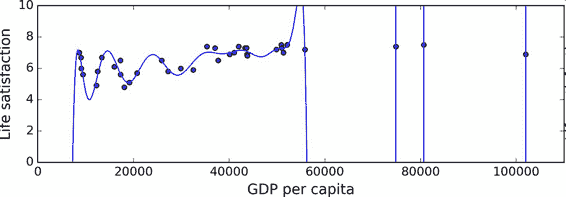
圖 1-22 過擬合訓練數據
復雜的模型,比如深度神經網絡,可以檢測數據中的細微規律,但是如果訓練集有噪聲,或者訓練集太小(太小會引入樣本噪聲),模型就會去檢測噪聲本身的規律。很明顯,這些規律不能推廣到新實例。例如,假如你用更多的屬性訓練生活滿意度模型,包括不包含信息的屬性,比如國家的名字。如此一來,復雜的模型可能會檢測出訓練集中名字有 w 字母的國家的生活滿意度大于 7:新西蘭(7.3),挪威(7.4),瑞典(7.2)和瑞士(7.5)。你能相信這個 W-滿意度法則推廣到盧旺達和津巴布韋嗎?很明顯,這個規律只是訓練集數據中偶然出現的,但是模型不能判斷這個規律是真實的、還是噪聲的結果。
> 警告:過擬合發生在相對于訓練數據的量和噪聲,模型過于復雜的情況。可能的解決方案有:
>
> * 簡化模型,可以通過選擇一個參數更少的模型(比如使用線性模型,而不是高階多項式模型)、減少訓練數據的屬性數、或限制一下模型
> * 收集更多的訓練數據
> * 減小訓練數據的噪聲(比如,修改數據錯誤和去除異常值)
限定一個模型以讓它更簡單并且降低過擬合的風險被稱作正則化(regularization)。例如,我們之前定義的線性模型有兩個參數,`θ0`和`θ1`。它給了學習算法兩個自由度以讓模型適應訓練數據:可以調整截距`θ0`和斜率`θ1`。如果強制`θ1=0`,算法就只剩一個自由度,擬合數據就會更為困難:它所能做的只是將擬合曲線上下移動去盡可能地靠近訓練實例,結果會在平均值附近。這就是一個非常簡單的模型!如果我們允許算法可以修改`θ1`,但是只能在一個很小的范圍內修改,算法的自由度就會介于 1 和 2 之間。它要比兩個自由度的模型簡單,比 1 個自由度的模型要復雜。你的目標是在完美擬合數據和保持模型簡單性上找到平衡,確保算法的推廣效果。
圖 1-23 展示了三個模型:虛線表示用一些缺失國家的數據訓練的原始模型,短劃線是我們的第二個用所有國家訓練的模型,實線模型的訓練數據和第一個相同,但進行了正則化限制。你可以看到正則化強制模型有一個小的斜率,它對訓練數據的擬合不是那么好,但是對新樣本的推廣效果好。
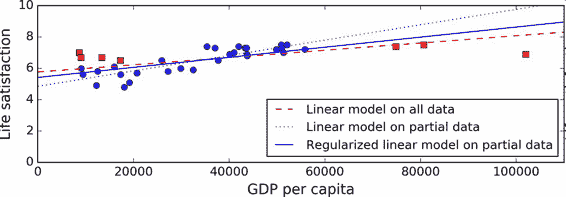
圖 1-23 正則化降低了過度擬合的風險
正則化的度可以用一個超參數(hyperparameter)控制。超參數是一個學習算法的參數(而不是模型的)。這樣,它是不會被學習算法本身影響的,它優于訓練,在訓練中是保持不變的。如果你設定的超參數非常大,就會得到一個幾乎是平的模型(斜率接近于 0);這種學習算法幾乎肯定不會過擬合訓練數據,但是也很難得到一個好的解。調節超參數是創建機器學習算法非常重要的一部分(下一章你會看到一個詳細的例子)。
## 欠擬合訓練數據
你可能猜到了,欠擬合是和過擬合相對的:當你的模型過于簡單時就會發生。例如,生活滿意度的線性模型傾向于欠擬合;現實要比這個模型復雜的多,所以預測很難準確,即使在訓練樣本上也很難準確。
解決這個問題的選項包括:
* 選擇一個更強大的模型,帶有更多參數
* 用更好的特征訓練學習算法(特征工程)
* 減小對模型的限制(比如,減小正則化超參數)
## 回顧
現在,你已經知道了很多關于機器學習的知識。然而,學過了這么多概念,你可能會感到有些迷失,所以讓我們退回去,回顧一下重要的:
* 機器學習是讓機器通過學習數據對某些任務做得更好,而不使用確定的代碼規則。
* 有許多不同類型的機器學習系統:監督或非監督,批量或在線,基于實例或基于模型,等等。
* ? 在機器學習項目中,我們從訓練集中收集數據,然后對學習算法進行訓練。如果算法是基于模型的,就調節一些參數,讓模型擬合到訓練集(即,對訓練集本身作出好的預測),然后希望它對新樣本也能有好預測。如果算法是基于實例的,就是用記憶學習樣本,然后用相似度推廣到新實例。
* 如果訓練集太小、數據沒有代表性、含有噪聲、或摻有不相關的特征(垃圾進,垃圾出),系統的性能不會好。最后,模型不能太簡單(會發生欠擬合)或太復雜(會發生過擬合)。
還差最后一個主題要學習:訓練完了一個模型,你不只希望將它推廣到新樣本。如果你想評估它,那么還需要作出必要的微調。一起來看一看。
# 測試和確認
要知道一個模型推廣到新樣本的效果,唯一的辦法就是真正的進行試驗。一種方法是將模型部署到生產環境,觀察它的性能。這么做可以,但是如果模型的性能很差,就會引起用戶抱怨 —— 這不是最好的方法。
更好的選項是將你的數據分成兩個集合:訓練集和測試集。正如它們的名字,用訓練集進行訓練,用測試集進行測試。對新樣本的錯誤率稱作推廣錯誤(或樣本外錯誤),通過模型對測試集的評估,你可以預估這個錯誤。這個值可以告訴你,你的模型對新樣本的性能。
如果訓練錯誤率低(即,你的模型在訓練集上錯誤不多),但是推廣錯誤率高,意味著模型對訓練數據過擬合。
> 提示:一般使用 80% 的數據進行訓練,保留 20%用于測試。
因此,評估一個模型很簡單:只要使用測試集。現在假設你在兩個模型之間猶豫不決(比如一個線性模型和一個多項式模型):如何做決定呢?一種方法是兩個都訓練,,然后比較在測試集上的效果。
現在假設線性模型的效果更好,但是你想做一些正則化以避免過擬合。問題是:如何選擇正則化超參數的值?一種選項是用 100 個不同的超參數訓練 100 個不同的模型。假設你發現最佳的超參數的推廣錯誤率最低,比如只有 5%。然后就選用這個模型作為生產環境,但是實際中性能不佳,誤差率達到了 15%。發生了什么呢?
答案在于,你在測試集上多次測量了推廣誤差率,調整了模型和超參數,以使模型最適合這個集合。這意味著模型對新數據的性能不會高。
這個問題通常的解決方案是,再保留一個集合,稱作驗證集合。用訓練集和多個超參數訓練多個模型,選擇在驗證集上有最佳性能的模型和超參數。當你對模型滿意時,用測試集再做最后一次測試,以得到推廣誤差率的預估。
為了避免“浪費”過多訓練數據在驗證集上,通常的辦法是使用交叉驗證:訓練集分成互補的子集,每個模型用不同的子集訓練,再用剩下的子集驗證。一旦確定模型類型和超參數,最終的模型使用這些超參數和全部的訓練集進行訓練,用測試集得到推廣誤差率。
> 沒有免費午餐公理
>
> 模型是觀察的簡化版本。簡化意味著舍棄無法進行推廣的表面細節。但是,要確定舍棄什么數據、保留什么數據,必須要做假設。例如,線性模型的假設是數據基本上是線性的,實例和模型直線間的距離只是噪音,可以放心忽略。
>
> 在一篇 1996 年的[著名論文](https://www.zabaras.com/Courses/BayesianComputing/Papers/lack_of_a_priori_distinctions_wolpert.pdf)中,David Wolpert 證明,如果完全不對數據做假設,就沒有理由選擇一個模型而不選另一個。這稱作沒有免費午餐(NFL)公理。對于一些數據集,最佳模型是線性模型,而對其它數據集是神經網絡。沒有一個模型可以保證效果更好(如這個公理的名字所示)。確信的唯一方法就是測試所有的模型。因為這是不可能的,實際中就必須要做一些對數據合理的假設,只評估幾個合理的模型。例如,對于簡單任務,你可能是用不同程度的正則化評估線性模型,對于復雜問題,你可能要評估幾個神經網絡模型。
# 練習
本章中,我們學習了一些機器學習中最為重要的概念。下一章,我們會更加深入,并寫一些代碼。開始下章之前,確保你能回答下面的問題:
1. 如何定義機器學習?
2. 機器學習可以解決的四類問題?
3. 什么是帶標簽的訓練集?
4. 最常見的兩個監督任務是什么?
5. 指出四個常見的非監督任務?
6. 要讓一個機器人能在各種未知地形行走,你會采用什么機器學習算法?
7. 要對你的顧客進行分組,你會采用哪類算法?
8. 垃圾郵件檢測是監督學習問題,還是非監督學習問題?
9. 什么是在線學習系統?
10. 什么是核外學習?
11. 什么學習算法是用相似度做預測?
12. 模型參數和學習算法的超參數的區別是什么?
13. 基于模型學習的算法搜尋的是什么?最成功的策略是什么?基于模型學習如何做預測?
14. 機器學習的四個主要挑戰是什么?
15. 如果模型在訓練集上表現好,但推廣到新實例表現差,問題是什么?給出三個可能的解決方案。
16. 什么是測試集,為什么要使用它?
17. 驗證集的目的是什么?
18. 如果用測試集調節超參數,會發生什么?
19. 什么是交叉驗證,為什么它比驗證集好?
練習答案見附錄 A。
