# 十九、規模化訓練和部署 TensorFlow 模型
> 譯者:[@SeanCheney](https://www.jianshu.com/u/130f76596b02)
有了能做出驚人預測的模型之后,要做什么呢?當然是部署生產了。這只要用模型運行一批數據就成,可能需要寫一個腳本讓模型每夜都跑著。但是,現實通常會更復雜。系統基礎組件都可能需要這個模型用于實時數據,這種情況需要將模型包裝成網絡服務:這樣的話,任何組件都可以通過 REST API 詢問模型。隨著時間的推移,你需要用新數據重新訓練模型,更新生產版本。必須處理好模型版本,平穩地過渡到新版本,碰到問題的話需要回滾,也許要并行運行多個版本做 AB 測試。如果產品很成功,你的服務可能每秒會有大量查詢,系統必須提升負載能力。提升負載能力的方法之一,是使用 TF Serving,通過自己的硬件或通過云服務,比如 Google Cloud API 平臺。TF Serving 能高效服務化模型,優雅處理模型過渡,等等。如果使用云平臺,還能獲得其它功能,比如強大的監督工具。
另外,如果有很多訓練數據和計算密集型模型,則訓練時間可能很長。如果產品需要快速迭代,這么長的訓練時間是不可接受的(例如,新聞推薦系統總是推薦上個星期的新聞)。更重要的,過長的訓練時間會讓你沒有時間試驗新想法。在機器學習中(其它領域也是),很難提前知道哪個想法有效,所以應該盡量多、盡量快嘗試。加速訓練的方法之一是使用 GPU 或 TPU。要進一步加快,可以在多個機器上訓練,每臺機器上都有硬件加速。TensorFlow 的 Distribution Strategies API 可以輕松實現多機訓練。
本章我們會介紹如何部署模型,先是 TF Serving,然后是 Google Cloud AI 平臺。還會快速瀏覽如何將模型部署到移動 app、嵌入式設備和網頁應用上。最后,會討論如何用 GPU 加速訓練、使用 Distribution Strategies API 做多機訓練。
## TensorFlow 模型服務化
訓練好 TensorFlow 模型之后,就可以在 Python 代碼中使用了:如果是 tf.keras 模型,調用`predict()`模型就成。但隨著基礎架構擴張,最好是將模型包裝在服務中,它的唯一目的是做預測,其它組件查詢就成(比如使用 REST 或 gRPC API)。這樣就將模型和其它組件解耦,可以方便地切換模型或擴展服務(獨立于其它組件),做 AB 測試,確保所有組件都是依賴同一個模型版本。還可以簡化測試和開發,等等。可以使用任何技術做微服務(例如,使用 Flask),但有了 TF Serving,為什么還要重復造輪子呢?
### 使用 TensorFlow Serving
TF Serving 是一個非常高效,經過實戰檢測的模型服務,是用 C++寫成的。可以支持高負載,服務多個模型版本,并監督模型倉庫,自動部署最新版本,等等(見 19-1)。
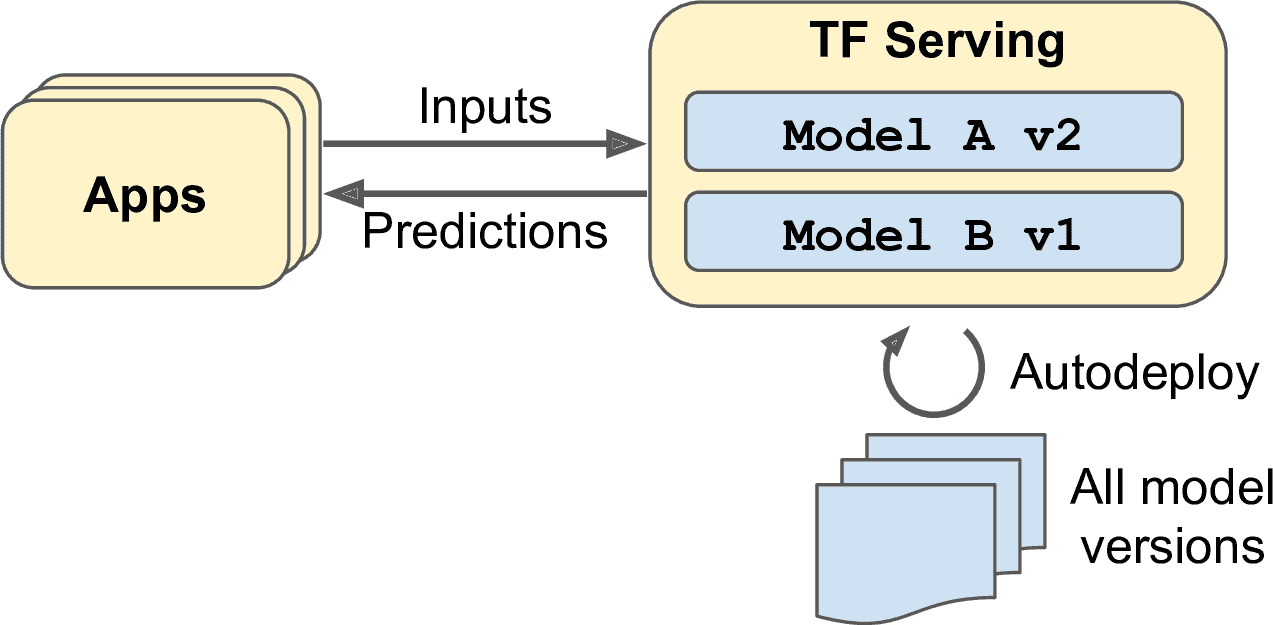圖 19-1 TF Serving 可以服務多個多個模型,并自動部署每個模型的最新版本
假設你已經用 tf.keras 訓練了一個 MNIST 模型,要將模型部署到 TF Serving。第一件事是輸出模型到 TensorFlow 的 SavedModel 格式。
### 輸出 SavedModel
TensorFlow 提供了簡便的函數`tf.saved_model.save()`,將模型輸出為 SavedModel 格式。只需傳入模型,配置名字、版本號,這個函數就能保存模型的計算圖和權重:
```py
model = keras.models.Sequential([...])
model.compile([...])
history = model.fit([...])
model_version = "0001"
model_name = "my_mnist_model"
model_path = os.path.join(model_name, model_version)
tf.saved_model.save(model, model_path)
```
通常將預處理層包含在最終模型里,這樣部署在生產中,就能接收真實數據。這樣可以避免在應用中單獨做預處理。將預處理和模型綁定,還能防止兩者不匹配。
> 警告:因為 SavedModel 保存了計算圖,所以只支持基于 TensorFlow 運算的模型,不支持`tf.py_function()`運算(它包裝了任意 Python 代碼)。也不支持動態 tf.keras 模型(見附錄 G),因為這些模型不能轉換成計算圖。動態模型需要用其它工具(例如,Flask)服務化。
SavedModel 表示了模型版本。它被保存為一個包含`saved_model.pb`文件的目錄,它定義了計算圖(表示為序列化協議緩存),變量子目錄包含了變量值。對于含有大量權重的模型,這些變量值可能分割在多個文件中。SavedModel 還有一個 assets 子目錄,包含著其余數據,比如詞典文件、類名、一些模型的樣本實例。目錄結構如下(這個例子中,沒有使用 assets):
```py
my_mnist_model
└── 0001
├── assets
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
```
可以使用函數`tf.saved_model.load()`加載 SavedModel。但是,返回的對象不是 Keras 模型:是 SavedModel,包括計算圖和變量值。可以像函數一樣做預測(輸入是張量,還要設置參數`training`,通常設為`False`):
```py
saved_model = tf.saved_model.load(model_path)
y_pred = saved_model(X_new, training=False)
```
另外,可以將 SavedModel 的預測函數包裝進 Keras 模型:
```py
inputs = keras.layers.Input(shape=...)
outputs = saved_model(inputs, training=False)
model = keras.models.Model(inputs=[inputs], outputs=[outputs])
y_pred = model.predict(X_new)
```
TensorFlow 還有一個命令行工具`saved_model_cli`,用于檢查 SavedModel:
```py
$ export ML_PATH="$HOME/ml" # point to this project, wherever it is
$ cd $ML_PATH
$ saved_model_cli show --dir my_mnist_model/0001 --all
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['__saved_model_init_op']:
[...]
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['flatten_input'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 28, 28)
name: serving_default_flatten_input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['dense_1'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 10)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predict
```
SavedModel 包含一個或多個元圖。元圖是計算圖加上了函數簽名定義(包括輸入、輸出名,類型和形狀)。每個元圖可以用一組標簽做標識。例如,可以用一個元圖包含所有的計算圖,包括訓練運算(例如,這個元圖的標簽是`"train"`)。但是,當你將 tf.keras 模型傳給函數`tf.saved_model.save()`,默認存儲的是一個簡化的 SavedModel:保存一個元圖,標簽是`"serve"`,包含兩個簽名定義,一個初始化函數(`__saved_model_init_op`)和一個默認的服務函數(`serving_default`)。保存 tf.keras 模型時,默認服務函數對應模型的`call()`函數。
`saved_model_cli`也可以用來做預測(用于測試,不是生產)。假設有一個 NumPy 數組(`X_new`),包含三張用于預測的手寫數字圖片。首先將其輸出為 NumPy 的`npy`格式:
```py
np.save("my_mnist_tests.npy", X_new)
```
然后,如下使用`saved_model_cli`命令:
```py
$ saved_model_cli run --dir my_mnist_model/0001 --tag_set serve \
--signature_def serving_default \
--inputs flatten_input=my_mnist_tests.npy
[...] Result for output key dense_1:
[[1.1739199e-04 1.1239604e-07 6.0210604e-04 [...] 3.9471846e-04]
[1.2294615e-03 2.9207937e-05 9.8599273e-01 [...] 1.1113169e-07]
[6.4066830e-05 9.6359509e-01 9.0598064e-03 [...] 4.2495009e-04]]
```
輸出包含 3 個實例的 10 個類的概率。現在有了可以工作的 SavedModel,下一步是安裝 TF Serving。
### 安裝 TensorFlow Serving
有多種方式安裝 TF Serving:使用 Docker 鏡像、使用系統的包管理器、從源代碼安裝,等等。我們使用 Docker 安裝的方法,這是 TensorFlow 團隊高度推薦的方法,不僅安裝容易,不會擾亂系統,性能也很好。需要先安裝 Docker。然后下載官方 TF Serving 的 Docker 鏡像:
```py
$ docker pull tensorflow/serving
```
創建一個 Docker 容器運行鏡像:
```py
$ docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v "$ML_PATH/my_mnist_model:/models/my_mnist_model" \
-e MODEL_NAME=my_mnist_model \
tensorflow/serving
[...]
2019-06-01 [...] loaded servable version {name: my_mnist_model version: 1}
2019-06-01 [...] Running gRPC ModelServer at 0.0.0.0:8500 ...
2019-06-01 [...] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 237] RAW: Entering the event loop ...
```
這樣,TF Serving 就運行起來了。它加載了 MNIST 模型(版本 1),通過 gRPC(端口 8500)和 REST(端口 8501)運行。下面是命令行選項的含義:
`-it`
使容器可交互(Ctrl-C 關閉),展示服務器的輸出。
`--rm`
停止時刪除容器。但不刪除鏡像。
`-p 8500:8500`
將 Docker 引擎將主機的 TCP 端口 8500 轉發到容器的 TCP 端口 8500。默認時,TF Serving 使用這個端口服務 gRPC API。
`-p 8501:8501`
將 Docker 引擎將主機的 TCP 端口 8501 轉發到容器的 TCP 端口 8501。默認時,TF Serving 使用這個端口服務 REST API。
`-v "$ML_PATH/my_mnist_model:/models/my_mnist_model"`
使主機的`$ML_PATH/my_mnist_model`路徑對容器的路徑`/models/mnist_model`開放。在 Windows 上,可能需要將`/`替換為`\`。
`-e MODEL_NAME=my_mnist_model`
將容器的`MODEL_NAME`環境變量,讓 TF Serving 知道要服務哪個模型。默認時,它會在路徑`/models`查詢,并會自動服務最新版本。
`tensorflow/serving`
鏡像名。
現在回到 Python 查詢服務,先使用 REST API,然后使用 gRPC API。
### 用 REST API 查詢 TF Serving
先創建查詢。必須包含想要調用的函數簽名的名字,和輸入數據:
```py
import json
input_data_json = json.dumps({
"signature_name": "serving_default",
"instances": X_new.tolist(),
})
```
注意,json 格式是 100%基于文本的,因此`X_new`NumPy 數組要轉換為 Python 列表,然后 json 格式化:
```py
>>> input_data_json
'{"signature_name": "serving_default", "instances": [[[0.0, 0.0, 0.0, [...]
0.3294117647058824, 0.725490196078431, [...very long], 0.0, 0.0, 0.0, 0.0]]]}'
```
通過發送 HTTP POST 請求,將數據發送給 TF Serving。使用`requests`就成:
```py
import requests
SERVER_URL = 'http://localhost:8501/v1/models/my_mnist_model:predict'
response = requests.post(SERVER_URL, data=input_data_json)
response.raise_for_status() # raise an exception in case of error
response = response.json()
```
響應是一個字典,唯一的鍵是`"predictions"`,它對應的值是預測列表。這是一個 Python 列表,將其轉換為 NumPy 數組,小數點保留兩位:
```py
>>> y_proba = np.array(response["predictions"])
>>> y_proba.round(2)
array([[0\. , 0\. , 0\. , 0\. , 0\. , 0\. , 0\. , 1\. , 0\. , 0\. ],
[0\. , 0\. , 0.99, 0.01, 0\. , 0\. , 0\. , 0\. , 0\. , 0\. ],
[0\. , 0.96, 0.01, 0\. , 0\. , 0\. , 0\. , 0.01, 0.01, 0\. ]])
```
現在就有預測了。模型 100%肯定第一張圖是類 7,99%肯定第二張圖是類 2,96%肯定第三章圖是類 1。
REST API 既優雅又簡單,當輸入輸出數據不大時,可以工作的很好。另外,客戶端無需其它依賴就能做 REST 請求,其它協議不一定成。但是,REST 是基于 JSON 的,JSON 又是基于文本的,很冗長。例如,必須將 NumPy 數組轉換為 Python 列表,每個浮點數都轉換成了字符串。這樣效率很低,序列化/反序列化很費時,負載大小也高:浮點數要表示為 15 個字符,32 位浮點數要超過 120 比特。這樣在傳輸大 NumPy 數組時,會造成高延遲和高帶寬消耗。所以轉而使用 gRPC。
> 提示:當傳輸大量數據時,(如果客戶端支持)最好使用 gRPC API,因為它是基于壓縮二進制格式和高效通信協議(基于 HTTP/2 框架)。
### 用 gRPC API 查詢 TF Serving
gRPC API 的輸入是序列化的`PredictRequest`協議緩存,輸出是序列化的`PredictResponse`協議緩存。這些協議緩存是`tensorflow-serving-api`庫的一部分(通過 pip 安裝)。首先,創建請求:
```py
from tensorflow_serving.apis.predict_pb2 import PredictRequest
request = PredictRequest()
request.model_spec.name = model_name
request.model_spec.signature_name = "serving_default"
input_name = model.input_names[0]
request.inputs[input_name].CopyFrom(tf.make_tensor_proto(X_new))
```
這段代碼創建了`PredictRequest`協議緩存,填充了需求字段,包括模型名(之前定義的),想要調用的函數簽名,最后是輸入數據,形式是`Tensor`協議緩存。`tf.make_tensor_proto()`函數創建了一個基于給定張量或 NumPy 數組(`X_new`)的`Tensor`協議緩存。接著,向服務器發送請求,得到響應(需要用 pip 安裝`grpcio`庫):
```py
import grpc
from tensorflow_serving.apis import prediction_service_pb2_grpc
channel = grpc.insecure_channel('localhost:8500')
predict_service = prediction_service_pb2_grpc.PredictionServiceStub(channel)
response = predict_service.Predict(request, timeout=10.0)
```
這段代碼很簡單:引入包之后,創建一個 gRPC 通信通道,主機是 localhost,端口是 8500,然后用這個通道創建 gRPC 服務,并發送請求,超時時間是 10 秒(因為是同步的,收到響應前是阻塞的)。在這個例子中,通道是不安全的(沒有加密和認證),但 gRPC 和 TensorFlow Serving 也支持 SSL/TLS 安全通道。
然后,將`PredictResponse`協議緩存轉換為張量:
```py
output_name = model.output_names[0]
outputs_proto = response.outputs[output_name]
y_proba = tf.make_ndarray(outputs_proto)
```
如果運行這段代碼,打印`y_proba.numpy().round(2)`。會得到和之前完全相同的結果。
### 部署新模型版本
現在創建一個新版本模型,將 SavedModel 輸出到路徑`my_mnist_model/0002`:
```py
model = keras.models.Sequential([...])
model.compile([...])
history = model.fit([...])
model_version = "0002"
model_name = "my_mnist_model"
model_path = os.path.join(model_name, model_version)
tf.saved_model.save(model, model_path)
```
每隔一段時間(可配置),TensorFlow Serving 會檢查新的模型版本。如果找到新版本,會自動過渡:默認的,會用上一個模型回復掛起的請求,用新版本模型處理新請求。掛起請求都答復后,前一模型版本就不加載了。可以在 TensorFlow 日志中查看:
```py
[...]
reserved resources to load servable {name: my_mnist_model version: 2}
[...]
Reading SavedModel from: /models/my_mnist_model/0002
Reading meta graph with tags { serve }
Successfully loaded servable version {name: my_mnist_model version: 2}
Quiescing servable version {name: my_mnist_model version: 1}
Done quiescing servable version {name: my_mnist_model version: 1}
Unloading servable version {name: my_mnist_model version: 1}
```
這個方法提供了平滑的過渡,但會使用很多內存(尤其是 GPU 內存,這是最大的限制)。在這個例子中,可以配置 TF Serving,用前一模型版本處理所有掛起的請求,再加載使用新模型版本。這樣配置可以防止在同一時刻加載,但會中斷服務一小段時間。
可以看到,TF Serving 使部署新模型變得很簡單。另外,如果發現版本 2 效果不如預期,只要刪除路徑`my_mnist_model/0002 directory`就能滾回到版本 1。
> 提示:TF Serving 的另一個功能是自動批次化,要使用的話,可以在啟動時使用選項`--enable_batching`。當 TF Serving 在短時間內收到多個請求時(延遲是可配置的),可以自動做批次化,然后再使用模型。這樣能利用 GPU 提升性能。模型返回預測之后,TF Serving 會將每個預測返回給正確的客戶端。通過提高批次延遲(見選項`--batching_parameters_file`),可以獲得更高的吞吐量。
如果每秒想做盡量多的查詢,可以將 TF Serving 部署在多個服務器上,并對查詢做負載均衡(見圖 19-2)。這需要將 TF Serving 容器部署在多個服務器上。一種方法是使用 Kubernetes,這是一個開源工具,用于在多個服務器上做容器編排。如果你不想購買、維護、升級所有機器,可以使用云平臺比如亞馬遜 AWS、Microsoft Azure、Google Cloud Platform、IBM 云、阿里云、Oracle 云,或其它 Platform-as-a-Service (PaaS)。管理所有虛擬機、做容器編排(就算有 Kubernetes 的幫助),處理 TF Serving 配置、微調和監控,也是件很耗時的工作。幸好,一些服務提供商可以幫你完成所有工作。本章我們會使用 Google Cloud AI Platform,因為它是唯一帶有 TPU 的平臺,支持 TensorFlow 2,還有其它 AI 服務(比如,AutoML、Vision API、Natural Language API),也是我最熟悉的。也存在其它服務提供商,比如 Amazon AWS SageMaker 和 Microsoft AI Platform,它們也支持 TensorFlow 模型。
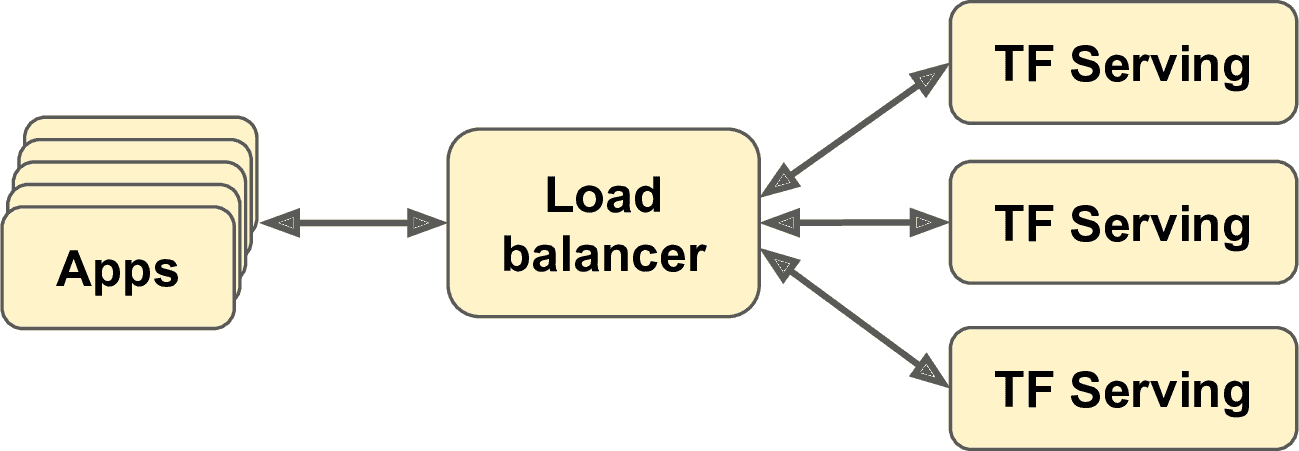圖 19-2 用負載均衡提升 TF Serving
現在,在云上部署 MNIST 模型。
### 在 GCP AI 上創建預測服務
在部署模型之前,有一些設置要做:
1. 登錄 Google 賬戶,到[Google Cloud Platform (GCP) 控制臺](https://links.jianshu.com/go?to=https%3A%2F%2Fconsole.cloud.google.com%2F)(見圖 19-3)。如果沒有 Google 賬戶,需要創建一個。
圖 19-3 Google Cloud Platform 控制臺
2. 如果是第一次使用 GCP,需要閱讀、同意條款。寫作本書時,新用戶可以免費試用,包括價值$300 的 GCP 點數,可以使用 12 個月。本章只需一點點 GCP 點數就夠。選擇試用之后,需要創建支付信息,需要輸入信用卡賬號:這只是為了驗證(避免人們薅羊毛),不必支付。根據需求,激活升級賬戶。
3. 如果不能用試用賬戶,就得掏錢了 T_T 。
4. GCP 中的每個資源都屬于一個項目。包括所有的虛擬機,存儲的文件,和運行的訓練任務。創建賬戶時,GCP 會自動給你創建一個項目,名字是“My First Project”。可以在項目設置改名。在導航欄選擇 IAM & admin → Settings,改名,然后保存。項目有一個唯一 ID 和數字。創建項目時,可以選擇項目 ID,選好 ID 后后面就不能修改了。項目數字是自動生成的,不能修改。如果你想創建一個新項目,點擊 New Project,輸入項目 ID。
> 警告:不用時一定注意關掉所有服務,否則跑幾天或幾個月,可能花費巨大。
5. 有了 GCP 賬戶和支付信息之后,就可以使用服務了。首先需要的 Google Cloud Storage (GCS):用來存儲 SavedModels,訓練數據,等等。在導航欄,選擇 Storage → Browser。所有的文件會存入一個或多個 bucket 中。點擊 Create Bucket,選擇 bucket 名(可能需要先激活 Storage API)。GCS 對 bucket 使用了單一全局的命名空間,所以像“machine-learning”這樣的名字,可能用不了。確保 bucket 名符合 DNS 命名規則,因為 bucket 名會用到 DNS 記錄中。另外,bucket 名是公開的,不要放私人信息。通常用域名或公司名作為前綴,保證唯一性,或使用隨機數字作為名字。選擇存放 bucket 的地方,其它選項用默認就行。然后點擊 Create。
6. 上傳之前創建的`my_mnist_model`(包括一個或多個版本)到 bucket 中。要這么做,在 GCS Browser,點擊 bucket,拖動 my_mnist_model 文件夾到 bucket 中(見圖 19-4)。另外,可以點擊“Upload folder”,選在要上傳的 my_mnist_model 文件夾。默認時,SavedModel 最大是 250MB,可以請求更大的值。
圖 19-4 上傳 SavedModel 到 Google Cloud Storage
7. 配置 AI Platform(以前的名字是 ML Engine),讓 AI Platform 知道要使用哪個模型和版本。在導航欄,下滾到 Artificial Intelligence,點擊 AI Platform → Models。點擊 Activate API(可能需要幾分鐘),然后點擊“Create model”。填寫模型細節說明(見圖 19-5),點擊創建。
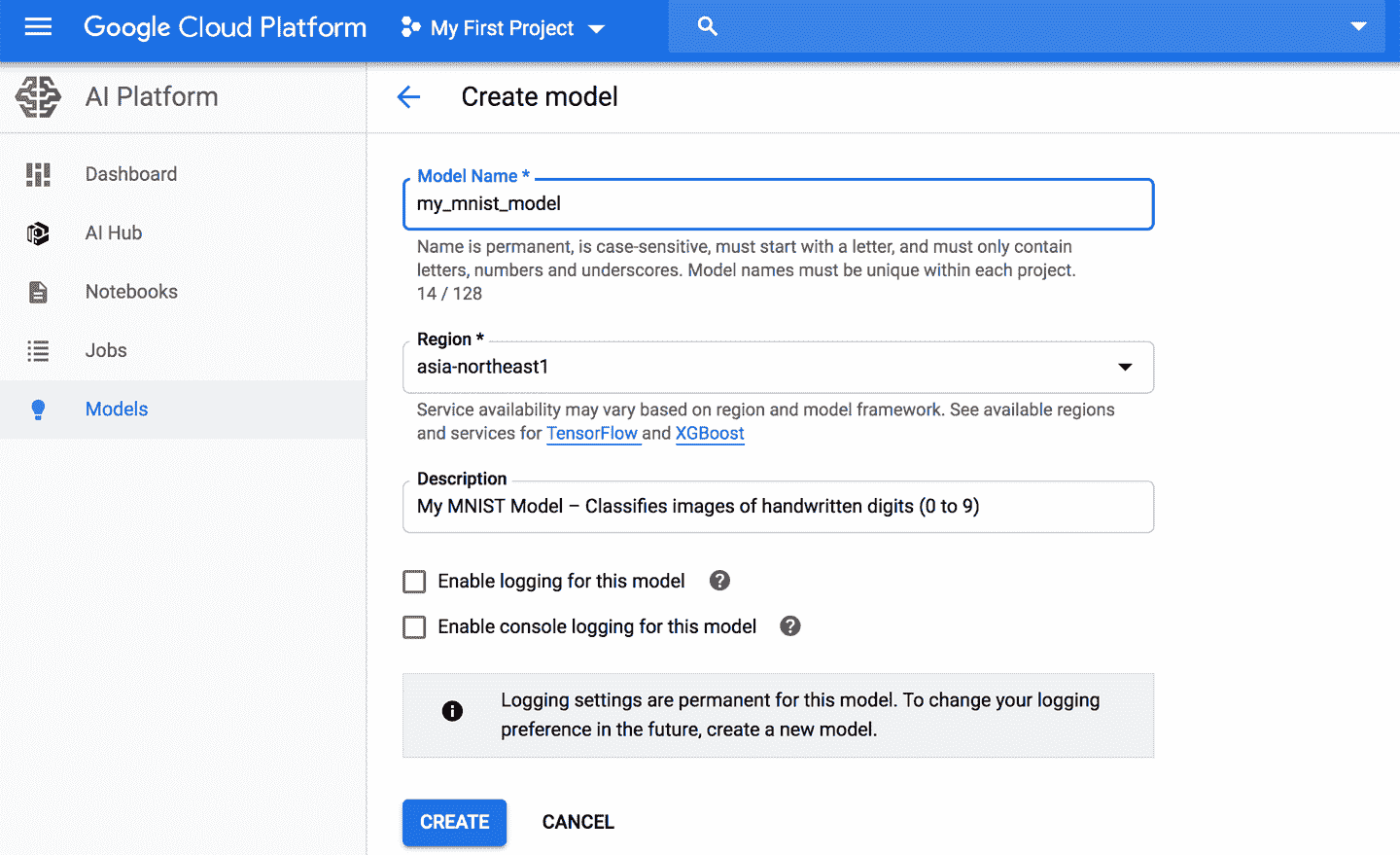圖 19-5 在 Google Cloud AI Platform 創建新模型
8. AI Platform 有了模型,需要創建模型版本。在模型列表中,點擊創建的模型,然后點擊“Create version”,填入版本細節說明(見圖 19-6):設置名字,說明,Python 版本(3.5 或以上),框架(TensorFlow),框架版本(2.0,或 1.13),ML 運行時版本(2.0,或 1.13),機器類型(選擇“Single core CPU”),模型的 GCS 路徑(真實版本文件夾的完整路徑,比如,[gs://my-mnist-model-bucket/my_mnist_model/0002/](https://links.jianshu.com/go?to=gs%3A%2F%2Fmy-mnist-model-bucket%2Fmy_mnist_model%2F0002%2F)),擴展(選擇 automatic),TF Serving 容器的最小運行數(留空就成)。然后點擊 Save。
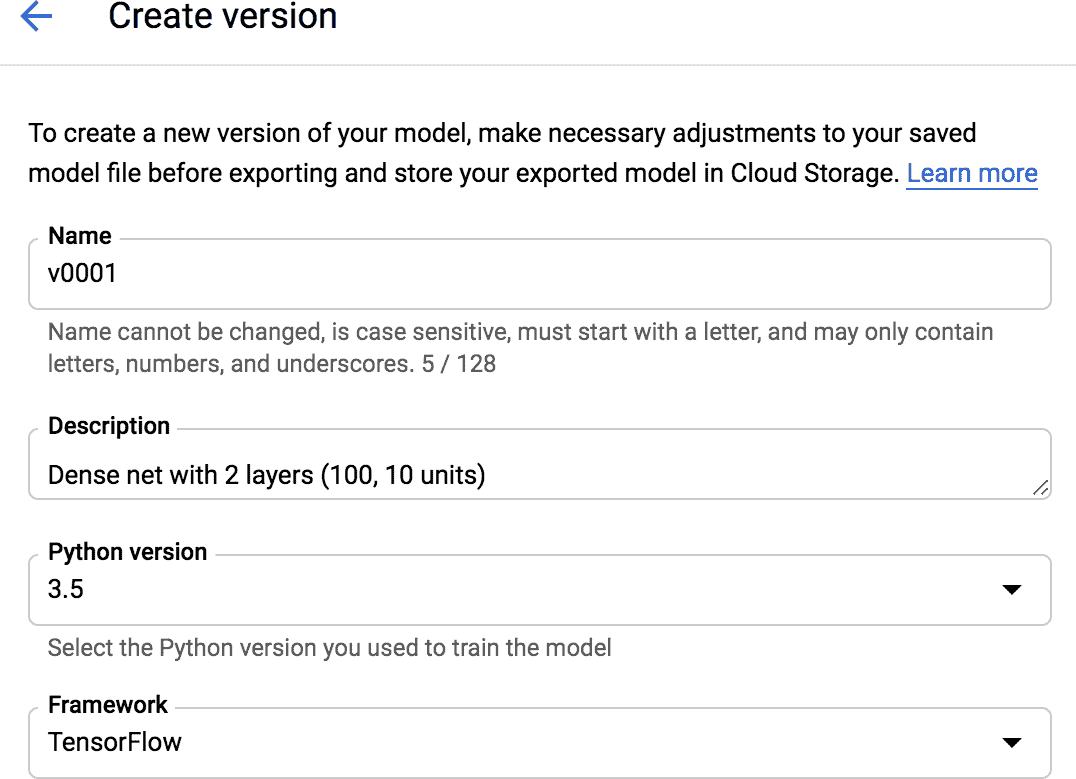圖 19-6 在 Google Cloud AI Platform 上創建一個新模型版本
恭喜,這樣就將第一個模型部署在云上了。因為選擇的是自動擴展,當每秒查詢數上升時,AI Platform 會啟動更多 TF Serving 容器,并會對查詢做負載均衡。如果 QPS 下降,就會關閉容器。所以花費直接和 QPS 關聯(還和選擇的機器類型和存儲在 GCS 的數據量有關)。這個定價機制特別適合偶爾使用的用戶,有使用波峰的服務,也適合初創企業。
> 筆記:如果不使用預測服務,AI Platform 會停止所有容器。這意味著,只用支付存儲費用就成(每月每 GB 幾美分)。當查詢服務時,AI Platform 會啟動 TF Serving 容器,啟動需要幾秒鐘。如果延遲太長,可以將最小容器數設為 1。當然,這樣花費會高。
現在查詢預測服務。
### 使用預測服務
在底層,AI Platform 就是運行 TF Serving,所以原理上,如果知道要查詢的 url,可以使用之前的代碼。就是有一個問題:GCP 還負責加密和認證。加密是基于 SSL/TLS,認證是基于 token:每次請求必須向服務端發送秘密認證。所以在代碼使用預測服務(或其它 GCP 服務)之前,必需要有 token。后面會講如果獲取 token,首先配置認證,使應用獲得 GCP 的響應訪問權限。有兩種認證方法:
* 應用(即,客戶端)可以用 Google 登錄和密碼信息做認證。使用密碼,可以讓應用獲得 GCP 的同等權限。另外,不能將密碼部署在應用中,否則會被盜。總之,不要選擇這種方法,它只使用極少場合(例如,當應用需要訪問用戶的 GCP 賬戶)。
* 客戶端代碼可以用 service account 驗證。這個賬戶代表一個應用,不是用戶。權限十分有限。推薦這種方法。
因此,給應用創建一個服務賬戶:在導航欄,逐次 IAM & admin → Service accounts,點擊 Create Service Account,填表(服務賬戶名、ID、描述),點擊創建(見圖 19-7)。然后,給這個賬戶一些訪問權限。選擇 ML Engine Developer 角色:這可以讓服務賬戶做預測,沒其它另外權限。或者,可以給服務賬戶添加用戶訪問權限(當 GCP 用戶屬于組織時很常用,可以讓組織內的其它用戶部署基于服務賬戶的應用,或者管理服務賬戶)、接著,點擊 Create Key,輸出私鑰,選擇 JSON,點擊 Create。這樣就能下載 JSON 格式的私鑰了。
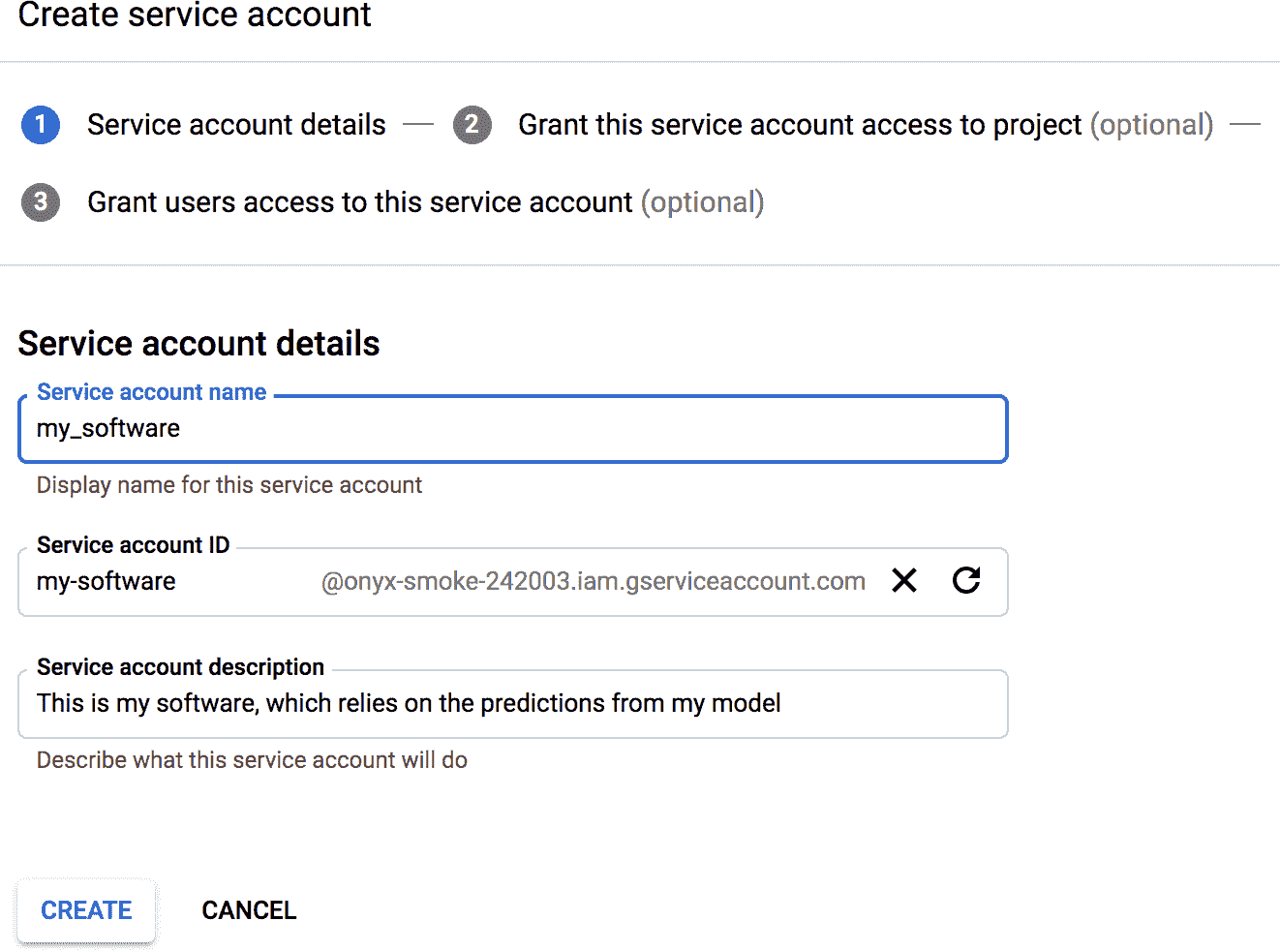圖 19-7 在 Google IAM 中創建一個新的服務賬戶
現在寫一個小腳本來查詢預測服務。Google 提供了幾個庫,用于簡化服務訪問:
Google API Client Library
* 基于[*OAuth 2.0*](https://links.jianshu.com/go?to=https%3A%2F%2Foauth.net%2F)和 REST。可以使用所有 GCP 服務,包括 AI Platform。可以用 pip 安裝:庫名叫做`google-api-python-client`。
Google Cloud Client Libraries
* 稍高級的庫:每個負責一個特別的服務,比如 GCS、Google BigQuery、Google Cloud Natural Language、Google Cloud Vision。所有這些庫都可以用 pip 安裝(比如,GCS 客戶端庫是`google-cloud-storage`)。如果有可用的客戶端庫,最好不用 Google API 客戶端,因為前者性能更好。
在寫作本書的時候,AI Platform 還沒有客戶端庫,所以我們使用 Google API 客戶端庫。這需要使用服務賬戶的私鑰;設定`GOOGLE_APPLICATION_CREDENTIALS`環境參數就成,可以在啟動腳本之前,或在如下的腳本中:
```py
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "my_service_account_key.json"
```
> 筆記:如果將應用部署到 Google Cloud Engine (GCE)的虛擬機上,或 Google Cloud Kubernetes Engine 的容器中,或 Google Cloud App Engine 的網頁應用上,或者 Google Cloud Functions 的微服務,如果沒有設置`GOOGLE_APPLICATION_CREDENTIALS`環境參數,會使用默認的服務賬戶(比如,如果在 GCE 上運行應用,就用默認 GCE 服務賬戶)。
然后,必須創建一個包裝了預測服務訪問的資源對象:
```py
import googleapiclient.discovery
project_id = "onyx-smoke-242003" # change this to your project ID
model_id = "my_mnist_model"
model_path = "projects/{}/models/{}".format(project_id, model_id)
ml_resource = googleapiclient.discovery.build("ml", "v1").projects()
```
可以將`/versions/0001`(或其它版本號),追加到`model_path`,指定想要查詢的版本:這么做可以用來 A/B 測試,或在推廣前在小范圍用戶做試驗。然后,寫一個小函數,使用資源對象調用預測服務,獲取預測結果:
```py
def predict(X):
input_data_json = {"signature_name": "serving_default",
"instances": X.tolist()}
request = ml_resource.predict(name=model_path, body=input_data_json)
response = request.execute()
if "error" in response:
raise RuntimeError(response["error"])
return np.array([pred[output_name] for pred in response["predictions"]])
```
這個函數接收包含圖片的 NumPy 數組,然后準備成字典,客戶端庫再將其轉換為 JSON 格式。然后準備預測請求,并執行;如果響應有錯誤,就拋出異常;沒有錯誤的話,就提取出每個實例的預測結果,綁定成 NumPy 數組。如下:
```py
>>> Y_probas = predict(X_new)
>>> np.round(Y_probas, 2)
array([[0\. , 0\. , 0\. , 0\. , 0\. , 0\. , 0\. , 1\. , 0\. , 0\. ],
[0\. , 0\. , 0.99, 0.01, 0\. , 0\. , 0\. , 0\. , 0\. , 0\. ],
[0\. , 0.96, 0.01, 0\. , 0\. , 0\. , 0\. , 0.01, 0.01, 0\. ]])
```
現在,就在云上部署好預測服務了,可以根據 QPS 自動擴展,可以從任何地方安全訪問。另外,如果不使用的話,就基本不產生費用:只要每月對每個 GB 支付幾美分。可以用[Google Stackdriver](https://links.jianshu.com/go?to=https%3A%2F%2Fcloud.google.com%2Fstackdriver%2F)獲得詳細日志。
如果將模型部署到移動 app,或嵌入式設備,該怎么做呢?
## 將模型嵌入到移動或嵌入式設備
如果需要將模型部署到移動或嵌入式設備上,大模型的下載時間太長,占用內存和 CPU 太多,這會是 app 響應太慢,設備發熱,消耗電量。要避免這種情況,要使用對移動設備友好、輕量、高效的模型,但又不犧牲太多準確度。[TFLite](https://links.jianshu.com/go?to=https%3A%2F%2Ftensorflow.org%2Flite)庫提供了一些部署到移動設備和嵌入式設備的 app 的工具,有三個主要目標:
* 減小模型大小,縮短下載時間,降低占用內存。
* 降低每次預測的計算量,減少延遲、電量消耗和發熱。
* 針對設備具體限制調整模型。
要降低模型大小,TFLite 的模型轉換器可以將 SavedModel 轉換為基于[FlatBuffers](https://links.jianshu.com/go?to=https%3A%2F%2Fgoogle.github.io%2Fflatbuffers%2F)的輕量格式。這是一種高效的跨平臺序列化庫(有點類似協議緩存),最初是 Google 開發用于游戲的。FlatBuffers 可以直接加載進內存,無需預處理:這樣可以減少加載時間和內存占用。一旦模型加載到了移動或嵌入設備上,TFLite 解釋器會執行它并做預測。下面的代碼將 SavedModel 轉換成了 FlatBuffer,并存為了`.tflite`文件:
```py
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_path)
tflite_model = converter.convert()
with open("converted_model.tflite", "wb") as f:
f.write(tflite_model)
```
> 提示:還可以使用`from_keras_model()`將 tf.keras 模型直接轉變為 FlatBuffer。
轉換器還優化了模型,做了壓縮,降低了延遲。刪減了所有預測用不到的運算(比如訓練運算),并優化了可能的計算;例如,3×a + 4×a + 5×a 被壓縮為(3 + 4 + 5)×a。還將可能的運算融合。例如,批歸一化作為加法和乘法融合到了前一層。要想知道 TFLite 能優化到什么程度,下載[一個預訓練 TFLite 模型](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Flitemodels),解壓縮,然后打開[Netron 圖可視化工具](https://links.jianshu.com/go?to=https%3A%2F%2Flutzroeder.github.io%2Fnetron%2F),然后上傳`.pb`文件,查看原始模型。這是一個龐大復雜的圖。接著,打開優化過的`.tflite`模型,并查看。
另一種減小模型的(不是使用更小的神經網絡架構)方法是使用更小的位寬(bit-width):例如,如果使用半浮點(16 位),而不是常規浮點(32 位),模型大小就能減小到一半,準確率會下降一點。另外,訓練會更快,GPU 內存使用只有一半。
TFLite 的轉換器可以做的更好,可以將模型的權重量化變為小數點固定的 8 位整數。相比為 32 位浮點數,可以將模型大小減為四分之一。最簡單的方法是后訓練量化:在訓練之后做量化,使用對稱量化方法。找到最大絕對權重值,m,然后將浮點范圍-m 到+m 古錠刀固定浮點(整數)范圍-127 到 127。例如(見圖 19-8),如果權重范圍是-1.5 到+0.8,則字節-127、0.0、+127 對應的是-1.5、0、+1.5。使用對稱量化時,0.0 總是映射到 0(另外,字節值+68 到+127 不會使用,因為超過了最大對應的浮點數+0.8)。
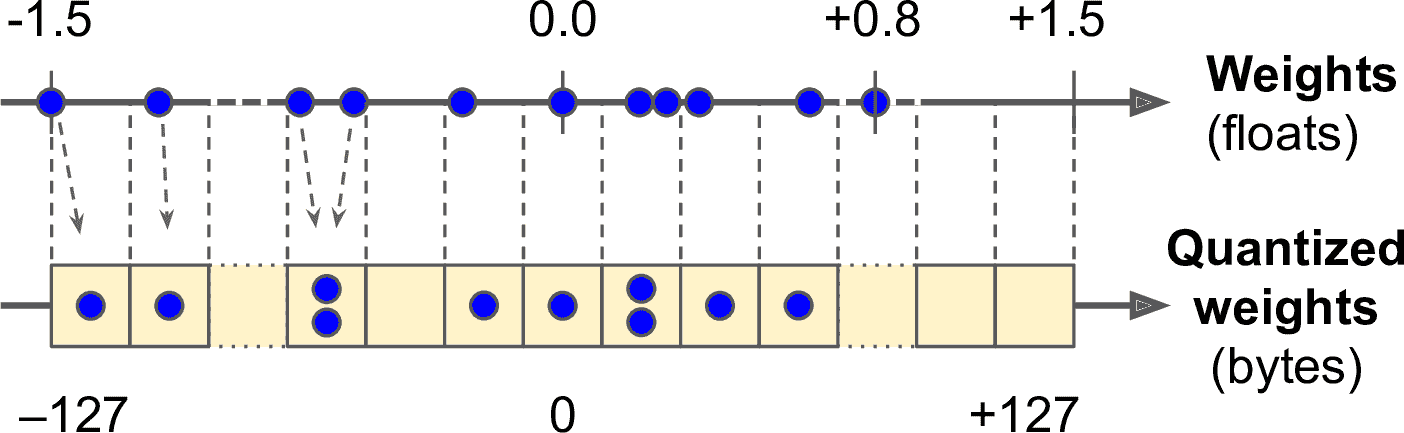圖 19-8 從 32 位浮點數到 8 位整數,使用對稱量化
要使用后訓練量化,只要在調用`convert()`前,將`OPTIMIZE_FOR_SIZE`添加到轉換器優化的列表中:
```py
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
```
這種方法可以極大地減小模型,下載和存儲更快。但是,運行時量化過的權重會轉換為浮點數(復原的浮點數與原始的不同,但偏差不大)。為了避免總是重新計算,緩存復原的浮點數,所以并沒有減少內存使用。計算速度沒有降低。
降低延遲和能量消耗的最高效的方法也是量化激活函數,讓計算只用整數進行,沒有浮點數運算。就算使用相同的位寬(例如,32 位整數,而不是 32 位浮點數),整數使用更少的 CPU 循環,耗能更少,熱量更低。如果你還降低了位寬(例如,降到 8 位整數),速度提升會更多。另外,一些神經網絡加速設備(比如邊緣 TPU),只能處理整數,因此全量化權重和激活函數是必須的。后訓練處理就成;需要校準步驟找到激活的最大絕對值,所以需要給 TFLite 提供一個訓練樣本,模型就能處理數據,并測量量化需要的激活數據(這一步很快)。
量化最主要的問題是準確率的損失:等同于給權重和激活添加了噪音。如果準確率下降太多,則需要使用*偽量化*。這意味著,給模型添加假量化運算,使模型忽略訓練中的量化噪音;最終的權重會對量化更魯棒。另外,校準步驟可以在訓練中自動進行,可以簡化整個過程。
解釋過了 TFLite 的核心概念,但要真正給移動 app 或嵌入式程序寫代碼需要另外一本書。幸好,可以看這本書[《TinyML: Machine Learning with TensorFlow on Arduino and Ultra-Low Power Micro-Controllers》](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Ftinyml),作者是 Pete Warden,他是 TFLite 團隊 leader,另一位作者是 Daniel Situnayake。
> 瀏覽器中的 TensorFlow
> 如果想在網站中使用模型,讓用戶直接在瀏覽器中使用,該怎么做呢?使用場景很多,如下:
>
> * 用戶連接是間斷或緩慢的,所以在客戶端一側直接運行模型,可以讓網站更可靠。
> * 如果想最快的獲得響應(比如,在線游戲)。在客戶端做查詢肯定能降低延遲,使網站響應更快。
> * 當網站服務是基于一些用戶隱私數據時,在客戶端做預測可以使用戶數據不出用戶機器,可以保護隱私。
>
> 對于所有這些情況,可以將模型輸出為特殊格式,用[TensorFlow.js js 庫](https://links.jianshu.com/go?to=https%3A%2F%2Ftensorflow.org%2Fjs)來加載。這個庫可以用模型直接在用戶的瀏覽器運行。TensorFlow.js 項目包括工具`tensorflowjs_converter`,它可以將 SavedModel 或 Keras 模型文件轉換為 TensorFlow.js Layers 格式:這是一個路徑包含了一組二進制格式的共享權重文件,和文件`model.json`,它描述了模型架構和穩重文件的鏈接。這個格式經過優化,可以快速在網頁上下載。用戶可以用 TensorFlow.js 庫下載模型并做預測。下面的代碼片段是個例子:
>
> ```py
> import * as tf from '@tensorflow/tfjs';
> const model = await tf.loadLayersModel('https://example.com/tfjs/model.json');
> const image = tf.fromPixels(webcamElement);
> const prediction = model.predict(image);
> ```
>
> TensorFlow.js 也是需要一本書來講解。可以參考[《Practical Deep Learning for Cloud, Mobile, and Edge》](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Ftfjsbook)
接下來,來學習使用 GPU 加速計算。
## 使用 GPU 加速計算
第 11 章,我們討論了幾種可以提高訓練速度的方法:更好的權重初始化、批歸一化、優化器,等等。但即使用了這些方法,在單機上用單 CPU 訓練龐大的神經網絡,仍需要幾天甚至幾周。
本節,我們會使用 GPU 加速訓練,還會學習如何將計算分布在多臺設備上,包括 CPU 和多 GPU 設備(見圖 19-9)。本章后面還會討論在多臺服務器做分布式計算。
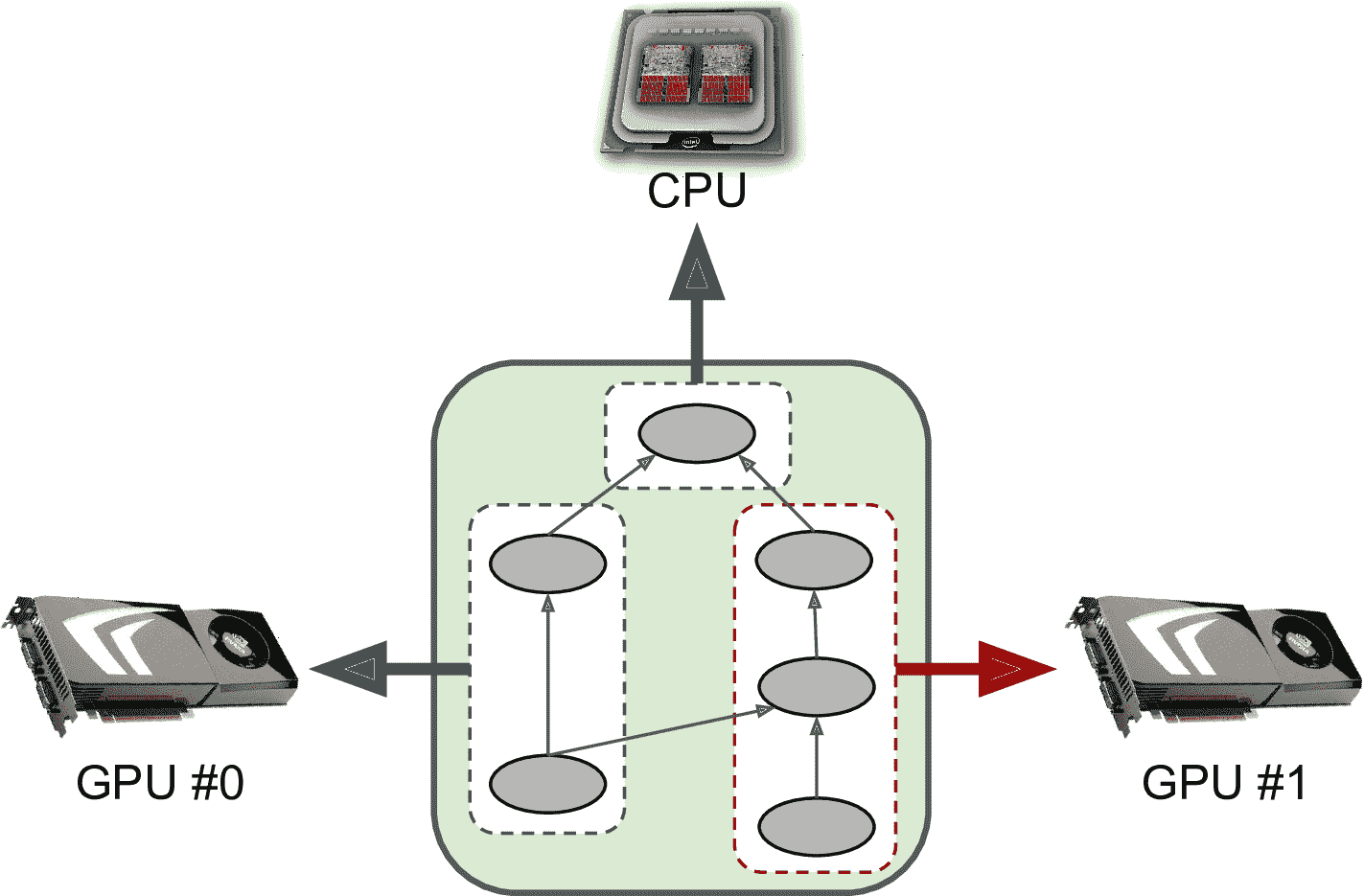圖 19-9 在多臺設備上并行執行 TensorFlow 計算圖
有了 GPU,可以將幾天幾周的訓練,減少到幾分鐘或幾小時。這樣不僅能節省大量時間,還可以試驗更多模型,用新數據重新訓練模型。
> 提示:給電腦加上一塊 GPU 顯卡,通常可以提升性能。事實上,對于大多數情況,這樣就足夠了:根本不需要多臺機器。例如,因為網絡通信延遲,單臺機器+GPU 比多臺機器+八塊 GPU 同樣快。相似的,使用一塊強大的 GPU 通常比極快性能一般的 GPU 要強。
首先,就是弄一塊 GPU。有兩種方法:要么自己買一塊 GPU,或者使用裝有 GPU 的云虛擬機。我們使用第一種方法。
### 買 GPU
如果想買一快 GPU 顯卡,最好花點時間研究下。Tim Dettmers 寫了一篇[博客](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2F66)幫你選擇,并且他經常更新:建議仔細讀讀。寫作本書時,TensorFlow 只支持[Nvidia 顯卡,且 CUDA 3.5+](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fcudagpus)(也支持 Google TPU),后面可能會支持更多廠家。另外,盡管 TCP 現在只在 GCP 上可用,以后可能會開售 TPU 卡。總之,查閱 TensorFlow 文檔查看支持什么設備。
如果買了 Nvidia 顯卡,需要安裝驅動和庫。包括 CUDA 庫,可以讓開發者使用支持 CUDA 的 GPU 做各種運算(不僅是圖形加速),還有 CUDA 深度神經網絡庫(cuDNN),一個 GPU 加速庫。cuDNN 提供了常見 DNN 計算的優化實現,比如激活層、歸一化、前向和反向卷積、池化。它是 Nvidia 的深度學習 SDK 的一部分(要創建 Nvidia 開發者賬戶才能下載)。TensorFlow 使用 CUDA 和 cuDNN 控制 GPU 加速計算(見圖 19-10)。
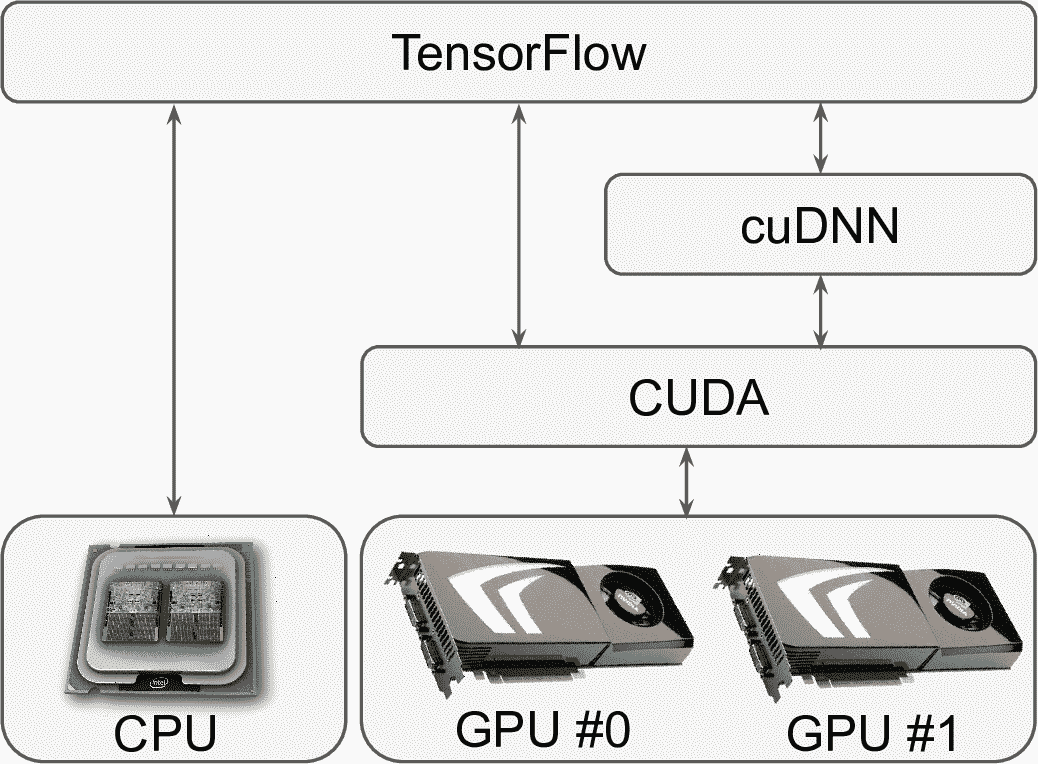圖 19-10 TensorFlow 使用 CUDA 和 cuDNN 控制 GPU,加速 DNN
安裝好 GPU 和需要的庫之后,可以使用`nvidia-smi`命令檢測 CUDA 是否正確安裝好,和每塊卡的運行:
```py
$ nvidia-smi
Sun Jun 2 10:05:22 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.67 Driver Version: 410.79 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 61C P8 17W / 70W | 0MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
```
寫作本書時,你還需要安裝 GPU 版本的 TensorFlow(即,`tensorflow-gpu`庫);但是,趨勢是將 CPU 版本和 GPU 版本合二為一,所以記得查看文檔。因為安裝每個庫又長又容易出錯,TensorFlow 還提供了一個 Docker 鏡像,里面都裝好了。但是為了讓 Docker 容器能訪問 GPU,還需要在主機上安裝 Nvidia 驅動。
要檢測 TensorFlow 是否連接 GPU,如下檢測:
```py
>>> import tensorflow as tf
>>> tf.test.is_gpu_available()
True
>>> tf.test.gpu_device_name()
'/device:GPU:0'
>>> tf.config.experimental.list_physical_devices(device_type='GPU')
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
```
`is_gpu_available()`檢測是否有可用的 GPU。函數`gpu_device_name()`給了第一個 GPU 名字:默認時,運算就運行在這塊 GPU 上。函數`list_physical_devices()`返回了可用 GPU 設備的列表(這個例子中只有一個)。
現在,如果你不想花費時間和錢在 GPU 上,就使用云上的 GPU VM。
### 使用帶有 GPU 的虛擬機
所有主流的云平臺都提供 GPU 虛擬機,一些預先配置了驅動和庫(包括 TensorFlow)。Google Cloud Platform 使用了各種 GPU 額度:沒有 Google 認證,不能創建 GPU 虛擬機。默認時,GPU 額度是 0,所以使用不了 GPU 虛擬機。因此,第一件事是請求更高的額度。在 GCP 控制臺,在導航欄 IAM & admin → Quotas。點擊 Metric。點擊 None,解鎖所有地點,然后搜索 GPU,選擇 GPU(所有區域),查看對應的額度。如果額度是 0(或額度不足),則查看旁邊的框,點擊 Edit quotas。填入需求的信息,點擊 Submit request。可能需要幾個小時(活幾天),額度請求才能被處理。默認時,每個區域每種 GPU 類型有 GPU 的額度。可以請求提高這些額度:點擊 Metric,選擇 None,解鎖所有指標,搜索 GPU,選擇想要的 GPU 類型(比如,NVIDIA P4 GPUs)。然后點擊 Location,點擊 None 解鎖所有指標,點擊想要的地點;選擇相鄰的框,點擊 Edit quotas,發出請求。
GPU 額度請求通過后,就可以使用 Google Cloud AI Platform 的深度學習虛擬機鏡像創建帶有 GPU 的虛擬機了:到[*https://homl.info/dlvm*](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fdlvm),點擊 View Console,然后點擊 Launch on Compute Engine,填寫虛擬機配置表。注意一些地區沒有全類型的 GPU,一些地區則沒有 GPU(改變地區查看)。框架一定要選 TensorFlow 2.0,并要勾選“Install NVIDIA GPU driver automatically on first startup”。最好勾選“Enable access to JupyterLab via URL instead of SSH”:這可以在 GPU VM 上運行 Jupyter notebook。創建好 VM 之后,下滑導航欄到 Artificial Intelligence,點擊 AI Platform → Notebooks。notebook 實例出現在列表中(可能需要幾分鐘,點擊 Refresh 刷新),點擊鏈接 Open JupyterLab。這樣就能再 VM 上打開 JupyterLab,并連接瀏覽器了。你可以在 VM 上創建 notebook,運行任意代碼,并享受 GPU 加速。
如果你想快速測試或與同事分享 notebook,最好使用 Colaboratory。
### Colaboratory
使用 GPU VM 最簡單便宜的方法是使用 Colaboratory(或 Colab)。它是免費的,[*https://colab.research.google.com/*](https://links.jianshu.com/go?to=https%3A%2F%2Fcolab.research.google.com%2F)上創建 Python 3 notebook 就成:這會在 Google Drive 上創建一個 Jupyter notebook(或者打開 GitHub、Google Drive 上的 notebook,或上傳自己的 notebook)。Colab 的用戶界面和 Jupyter notebook 很像,除了還能像普通 Google 文檔一樣分享,還有一些其它細微差別(比如,通過代碼加特殊注釋,你可以創建的方便小工具)。
當你打開 Colab notebook,它是在一個免費的 Google VM 上運行,被稱為 Colab Runtime。Runtime 默認是只有 CPU 的,但可以到 Runtime → “Change runtime type”,在 Hardware accelerator 下拉欄選取 GPU,然后點擊保存。事實上,你還可以選取 TPU(沒錯,可以免費試用 TPU)。
如果用同一個 Runtime 類型運行多個 Colab notebook(見圖 19-11),notebook 會使用相同的 Colab Runtime。如果一個 notebook 寫入了文件,其它 notebook 就能讀取這個文件。如果運行黑客的文件,可能讀取隱私數據。密碼也會泄露給黑客。另外,如果你在 Colab Runtime 安裝一個庫,其它 notebook 也會有這個庫。缺點是庫的版本必須相同。
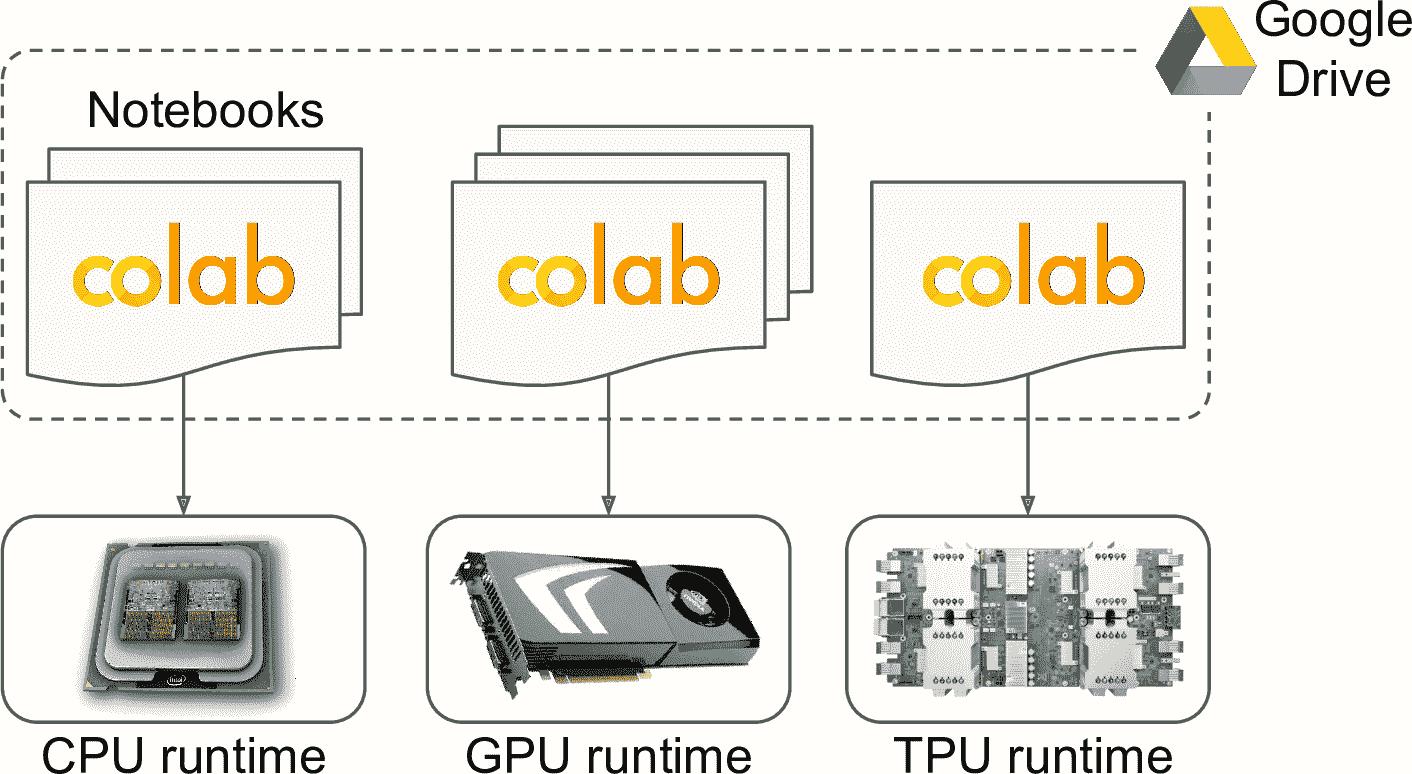圖 19-11 Colab Runtime 和 notebook
Colab 也有一些限制:就像 FAQ 寫到,Colaboratory 的目的是交互使用,長時間背景的計算,尤其是在 GPU 上的,會被停掉。不要用 Colab 做加密貨幣挖礦。如果一定時間沒有用(~30 分鐘),網頁界面就會自動斷開連接。當你重新連接 Colab Runtime,可能就重置了,所以一定記著下載重要數據。即使從來沒有斷開連接,Colab Runtime 會自動在 12 個小時后斷開連接,因為它不是用來做長時間運行的。盡管有這些限制,它仍是一個絕好的測試工具,可以快速獲取結果,和同事協作。
### 管理 GPU 內存
TensorFlow 默認會在第一次計算時,使用可用 GPU 的所有內存。這么做是為了限制 GPU 內存碎片化。如果啟動第二個 TensorFlow 程序(或任意需要 GPU 的程序),就會很快消耗掉所有內存。這種情況很少見,因為大部分時候是只跑一個 TensorFlow 程序:訓練腳本,TF Serving 節點,或 Jupyter notebook。如果因為某種原因(比如,用同一臺機器訓練兩個不同的模型)要跑多個程序,需要根據進程平分 GPU 內存。
如果機器上有多塊 GPU,解決方法是分配給每個進程。要這么做,可以設定`CUDA_VISIBLE_DEVICES`環境變量,讓每個進程只看到對應的 GPU。還要設置`CUDA_DEVICE_ORDER`環境變量為`PCI_BUS_ID`,保證每個 ID 對應到相同的 GPU 卡。你可以啟動兩個程序,給每個程序分配一個 GPU,在兩個獨立的終端執行下面的命令:
```py
$ CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0,1 python3 program_1.py
# and in another terminal:
$ CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=3,2 python3 program_2.py
```
程序 1 能看到 GPU 卡 0 和 1,`/gpu:0` 和 `/gpu:1`。程序 2 只能看到 GPU 卡 2 和 3,`/gpu:1` 和 `/gpu:0`(注意順序)。一切工作正常(見圖 19-12)。當然,還可以用 Python 定義這些環境變量,`os.environ["CUDA_DEVICE_ORDER"]`和`os.environ["CUDA_VISIBLE_DEVICES"]`,只要使用 TensorFlow 前這么做就成。
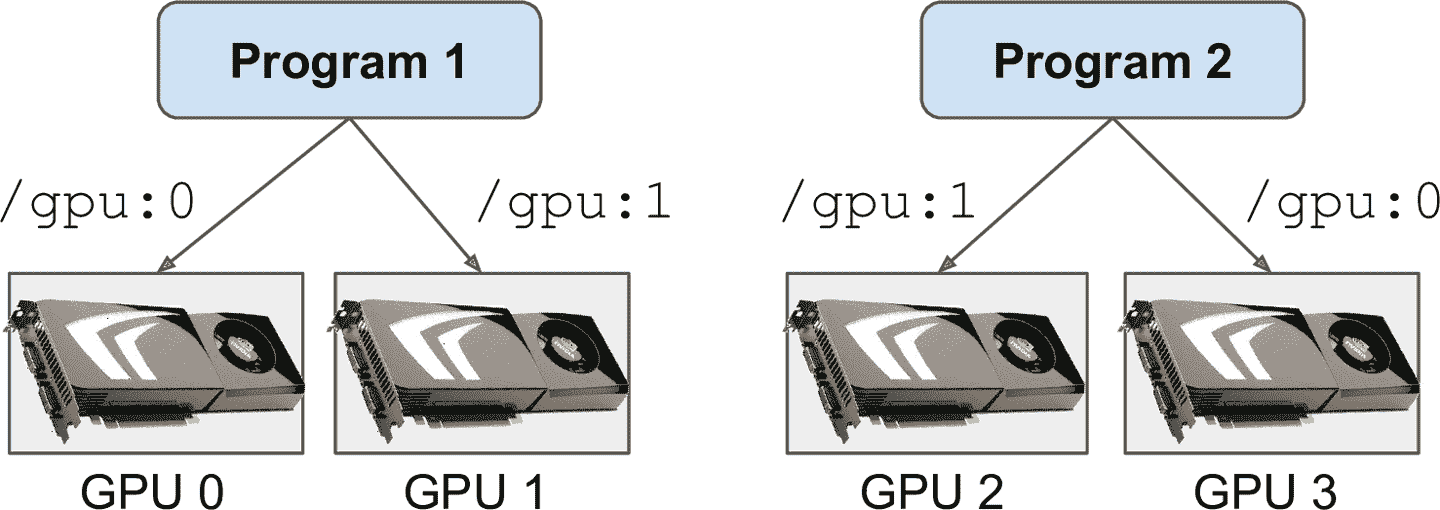圖 19-12 每個程序有兩個 GPU
另一個方法是告訴 TensorFlow 使用具體量的 GPU 內存。這必須在引入 TensorFlow 之后就這么做。例如,要讓 TensorFlow 只使用每個 GPU 的 2G 內存,你必須創建虛擬 GPU 設備(也被稱為邏輯 GPU 設備)每個物理 GPU 設備的內存限制為 2G(即,2048MB):
```py
for gpu in tf.config.experimental.list_physical_devices("GPU"):
tf.config.experimental.set_virtual_device_configuration(
gpu,
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=2048)])
```
現在(假設有 4 個 GPU,每個最少 4GB)兩個程序就可以并行運行了,每個都使用這四個 GPU(見圖 19-13)。
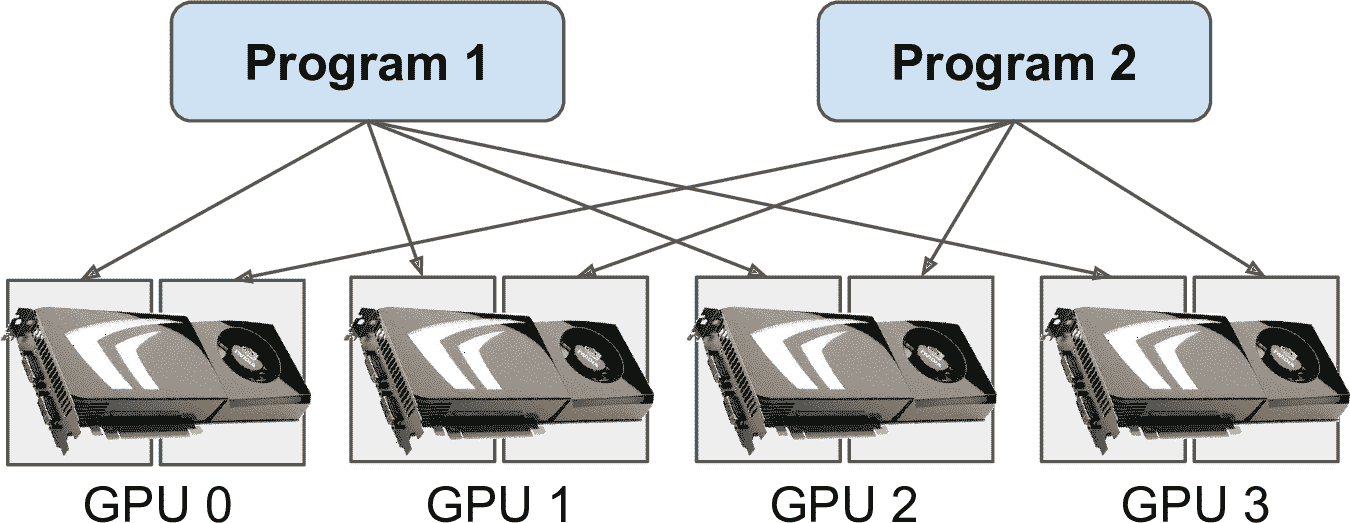圖 19-13 每個程序都可以使用 4 個 GPU,每個 GPU 使用 2GB
如果兩個程序都運行時使用`nvidia-smi`命令,可以看到每個進程用了 2GB 的 GPU 內存:
```py
$ nvidia-smi
[...]
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 2373 C /usr/bin/python3 2241MiB |
| 0 2533 C /usr/bin/python3 2241MiB |
| 1 2373 C /usr/bin/python3 2241MiB |
| 1 2533 C /usr/bin/python3 2241MiB |
[...]
```
另一種方法是讓 TensorFlow 只在需要內存時再使用(必須在引入 TensorFlow 后就這么做):
```py
for gpu in tf.config.experimental.list_physical_devices("GPU"):
tf.config.experimental.set_memory_growth(gpu, True)
```
另一種這么做的方法是設置環境變量`TF_FORCE_GPU_ALLOW_GROWTH`為`true`。這么設置后,TensorFlow 不會釋放獲取的內存(避免內存碎片化),直到程序結束。這種方法無法保證確定的行為(比如,一個程序內存超標會導致另一個程序崩潰),所以在生產中,最好使用前面的方法。但是,有時這個方法是有用的:例如,當用機器運行多個 Jupyter notebook,其中一些使用 TensorFlow。這就是為什么在 Colab Runtime 中將環境變量`TF_FORCE_GPU_ALLOW_GROWTH`設為`true`。
最后,在某些情況下,你可能想將 GPU 分為兩個或多個虛擬 GPU —— 例如,如果你想測試一個分發算法。下面的代碼將第一個 GPU 分成了兩個虛擬 GPU,每個有 2GB(必須引入 TensorFlow 之后就這么做):
```py
physical_gpus = tf.config.experimental.list_physical_devices("GPU")
tf.config.experimental.set_virtual_device_configuration(
physical_gpus[0],
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=2048),
tf.config.experimental.VirtualDeviceConfiguration(memory_limit=2048)])
```
這兩個虛擬 GPU 被稱為`/gpu:0` 和 `/gpu:1`,可以像真正獨立的 GPU 一樣做運算和變量。下面來看 TensorFlow 如何確定安置變量和執行運算。
### 在設備上安置運算和變量
TensorFlow [白皮書](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2F67)介紹了一種友好的動態安置器算法,可以自動在多個可用設備上部署運算,可以測量計算時間,輸入輸出張量的大小,每個設備的可用內存,傳入傳出設備的通信延遲,用戶提示。但在實際中,這個算法不怎么高效,所以 TensorFlow 團隊放棄了動態安置器。
但是,tf.keras 和 tf.data 通常可以很好地安置運算和變量(例如,在 GPU 上做計算,CPU 上做預處理)。如果想要更多的控制,還可以手動在每個設備上安置運算和變量:
* 將預處理運算放到 CPU 上,將神經網絡運算放到 GPU 上。
* GPU 的通信帶寬通常不高,所以要避免 GPU 的不必要的數據傳輸。
* 給機器添加更多 CPU 內存通常簡單又便宜,但 GPU 內存通常是焊接上去的:是昂貴且有限的,所以如果變量在訓練中用不到,一定要放到 CPU 上(例如,數據集通常屬于 CPU)。
默認下,所有變量和運算會安置在第一塊 GPU 上(`/gpu:0`),除了沒有 GPU 核的變量和運算:這些要放到 CPU 上(`/cpu:0`)。張量或變量的屬性`device`告訴了它所在的設備:
```py
>>> a = tf.Variable(42.0)
>>> a.device
'/job:localhost/replica:0/task:0/device:GPU:0'
>>> b = tf.Variable(42)
>>> b.device
'/job:localhost/replica:0/task:0/device:CPU:0'
```
現在,可以放心地忽略前綴`/job:localhost/replica:0/task:0`(它可以讓你在使用 TensorFlow 集群時,在其它機器上安置運算;本章后面會討論工作、復制和任務)。可以看到,第一個變量放到 GPU 0 上,這是默認設備。但是,第二個變量放到 CPU 上:這是因為整數變量(或整數張量運算)沒有 GPU 核。
如果想把運算放到另一臺非默認設備上,使用`tf.device()`上下文:
```py
>>> with tf.device("/cpu:0"):
... c = tf.Variable(42.0)
...
>>> c.device
'/job:localhost/replica:0/task:0/device:CPU:0'
```
> 筆記:CPU 總是被當做單獨的設備(`/cpu:0`),即使你的電腦有多個 CPU 核。如果有多線程核,任意安置在 CPU 上的運算都可以并行運行。
如果在不存在設備或沒有核的設備安置運算和變量,就會拋出異常。但是,在某些情況下,你可能只想用 CPU;例如,如果程序可以在 CPU 和 GPU 上運行,可以讓 TensorFlow 在只有 CPU 的機器上忽略`tf.device("/gpu:*")`。要這么做,在引入 TensorFlow 后,可以調用 tf.config.set_soft_device_placement(`True`):安置請求失敗時,TensorFlow 會返回默認的安置規則(即,如果有 GPU 和,默認就是 GPU 0,否則就是 CPU 0)。
TensorFlow 是如何在多臺設備上執行這些運算的呢?
### 在多臺設備上并行執行
第 12 章介紹過,使用 TF Functions 的好處之一是并行運算。當 TensorFlow 運行 TF Functions 時,它先分析計算圖,找到需要計算的運算,統計需要的依賴。TensorFlow 接著將每個零依賴的運算(即,每個源運算)添加到運行設備的計算隊列(見圖 19-14)。計算好一個運算后,每個運算的依賴計數器就被刪掉。當運算的依賴計數器為零時,就被推進設備的計算隊列。TensorFlow 評估完所有需要的節點后,就返回輸出。
圖 19-14 TensorFlow 計算圖的并行執行
CPU 評估隊列的運算被發送給稱為`inter-op`的線程池。如果 CPU 有多個核,這些運算能高效并行計算。一些運算有多線程 CPU 核:這些核被分成多個子運算,放到另一個計算隊列中,發到第二個被稱為`intra-op`的線程池(多核 CPU 核共享)。總之,多個運算和自運算可以用不同的 CPU 核并行計算。
對于 GPU,事情簡單一些。GPU 計算隊列中的運算是順序計算的。但是,大多數運算有多線程 GPU 核,使用 TensorFlow 依賴的庫實現,比如 CUDA 和 cuDNN。這些實現有其自己的線程池,通常會用盡可能多的 GPU 線程(這就是為什么不需要`inter-op`線程池:每個運算已經使用 GPU 線程了)。
例如,見圖 19-14,運算 A、B、C 是源運算,所以可以立即執行。運算 A 和 B 在 CPU 上,所以發到 CPU 計算隊列,然后發到`inter-op`線程池,然后立即并行執行。運算 A 有多線程核:計算分成三個部分,在`intra-op`線程池內并行執行。運算 C 進入 GPU 0 的計算隊列,在這個例子中,它的 GPU 核使用 cuDNN,它管理自己的`intra-op`線程池,在多個 GPU 線程計算。假設 C 最先完成。D 和 E 的依賴計數器下降為 0,兩個運算都推到 GPU 0 的計算隊列,順序執行。C 只計算一次,即使 D 和 E 依賴它。假設 B 第二個結束。F 的依賴計數器從 4 降到 3,因為不是 0,所以霉運運行。當 A、D、E 都完成,F 的依賴計數器降到 0,被推到 CPU 的計算隊列并計算。最后,TensorFlow 返回輸出。
TensorFlow 的另一個奇妙的地方是當 TF Function 修改靜態資源時,比如變量:它能確保執行順序匹配代碼順序,即使不存在明確的依賴。例如,如果 TF Function 包含`v.assign_add(1)`,后面是`v.assign(v * 2)`,TensorFlow 會保證是按照這個順序執行。
> 提示:通過調用`tf.config.threading.set_inter_op_parallelism_threads()`,可以控制`inter-op`線程池的線程數。要設置`intra-op`的線程數,使用`tf.config.threading.set_intra_op_parallelism_threads()`。如果不想讓 TensorFlow 占用所有的 CPU 核,或是只想單線程,就可以這么設置。
有了上面這些知識,就可以利用 GPU 在任何設備上做任何運算了。下面是可以做的事:
* 在獨自的 GPU 上,并行訓練幾個模型:給每個模型寫一個訓練腳本,并行訓練,設置`CUDA_DEVICE_ORDER`和`CUDA_VISIBLE_DEVICES`,讓每個腳本只看到一個 GPU。這么做很適合超參數調節,因為可以用不同的超參數并行訓練。如果一臺電腦有兩個 GPU,單 GPU 可以一小時訓練一個模型,兩個 GPU 就可以訓練兩個模型。
* 在單 GPU 上訓練模型,在 CPU 上并行做預處理,用數據集的`prefetch()`方法,給 GPU 提前準備批次數據。
* 如果模型接收兩張圖片作為輸入,用兩個 CNN 做處理,將不同的 CNN 放到不同的 GPU 上會更快。
* 創建高效的集成學習:將不同訓練好的模型放到不同的 GPU 上,使預測更快,得到最后的預測結果。
如果想用多個 GPU 訓練一個模型該怎么做呢?
## 在多臺設備上訓練模型
有兩種方法可以利用多臺設備訓練單一模型:模型并行,將模型分成多臺設備上的子部分;和數據并行,模型復制在多臺設備上,每個模型用數據的一部分訓練。下面來看這兩種方法。
### 模型并行
前面我們都是在單一設備上訓練單一神經網絡。如果想在多臺設備上訓練一個神經網絡,該怎么做呢?這需要將模型分成獨立的部分,在不同的設備上運行。但是,模型并行有點麻煩,且取決于神經網絡的架構。對于全連接網絡,這種方法就沒有什么提升(見圖 19-15)。直觀上,一種容易的分割的方法是將模型的每一層放到不同的設備上,但是這樣行不通,因為每層都要等待前一層的輸出,才能計算。所以或許可以垂直分割 —— 例如,每層的左邊放在一臺設備上,右邊放到另一臺設備上。這樣好了一點,兩個部分能并行工作了,但是每層還需要另一半的輸出,所以設備間的交叉通信量很大(見虛線)。這就抵消了并行計算的好處,因為通信太慢(尤其是 GPU 在不同機器上)。
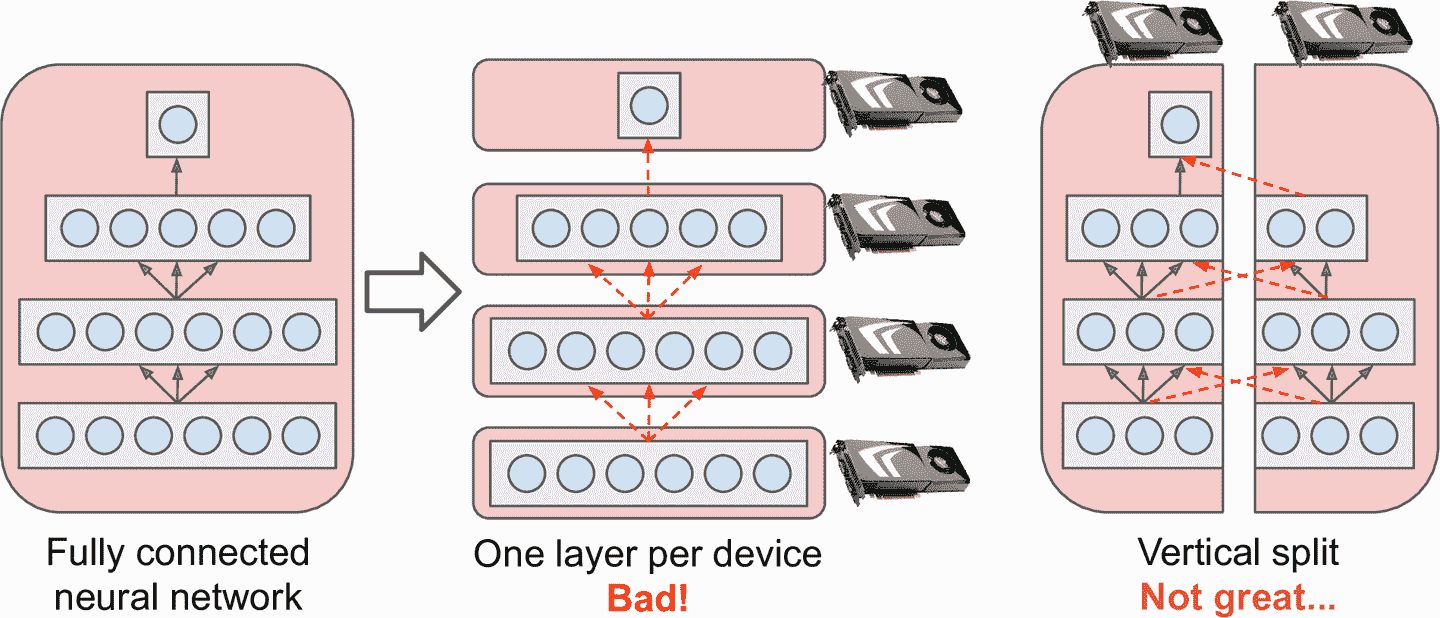圖 19-15 分割全連接神經網絡
一些神經網絡架構,比如卷積神經網絡,包括淺層的部分連接層,更容易分割在不同設備上(見圖 19-16)。
圖 19-16 分割部分連接神經網絡
深度循環神經網絡更容易分割在多個 GPU 上。如果水平分割,將每層放到不同設備上,輸入要處理的序列,在第一個時間步,只有一臺設備是激活的(計算序列的第一個值),在第二步,兩個設備激活(第二層處理第一層的輸出,同時,第一層處理第二個值),隨著信號傳播到輸出層,所有設備就同時激活了(圖 19-17)。這么做,仍然有設備間通信,但因為每個神經元相對復雜,并行運行多個神經元的好處(原理上)超過了通信損失。但是,在實際中,將一摞 LSTM 運行在一個 GPU 上會更快。
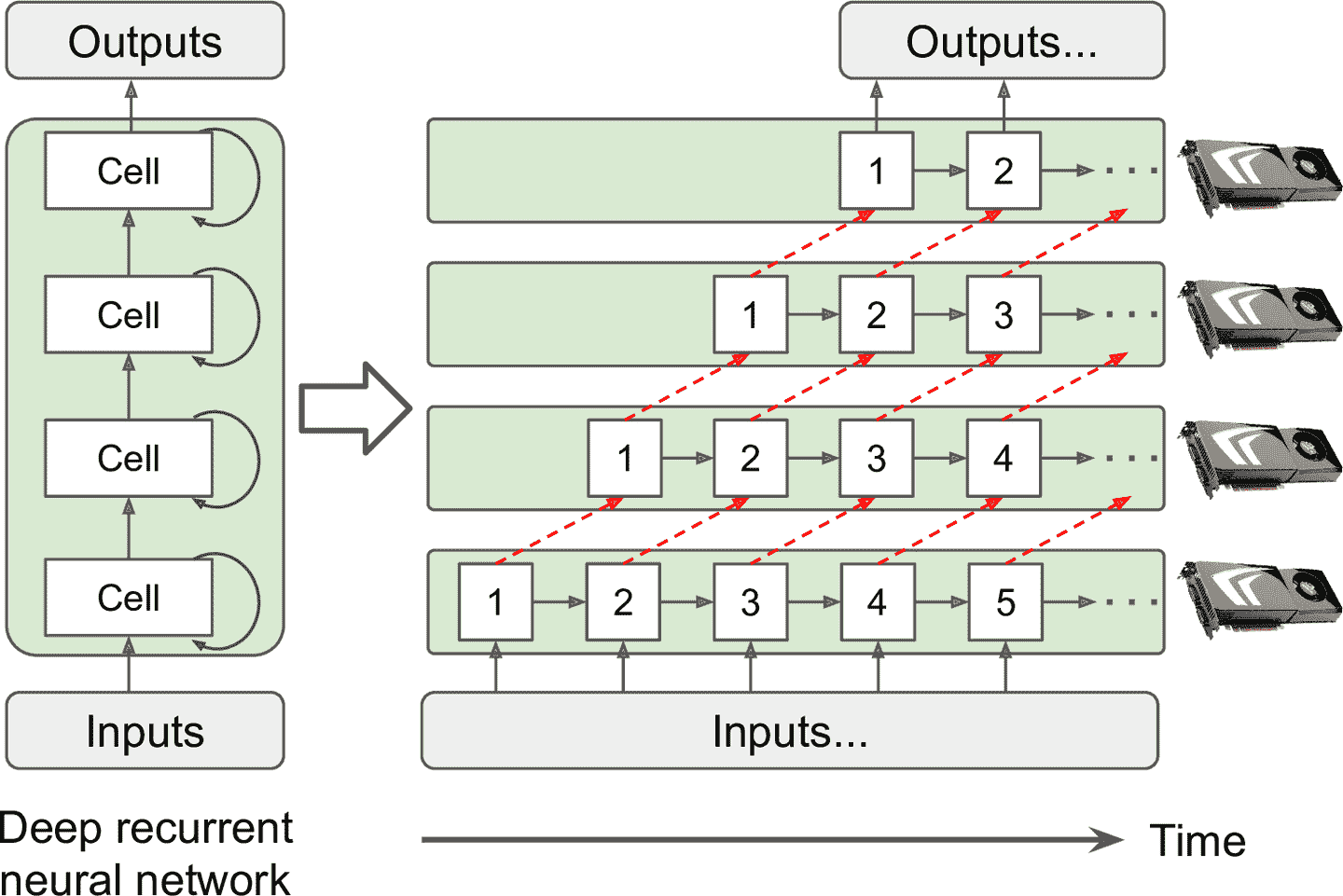圖 19-17 分割深度循環網絡
總之,模型并行可以提高計算,訓練一些類型的神經網絡,但不是所有的,還需要特殊處理和調節,比如保證通信盡量在計算量大的機器內。下面來看更為簡單高效的數據并行。
### 數據并行
另一種并行訓練神經網絡的方法,是將神經網絡復制到每個設備上,同時訓練每個復制,使用不同的訓練批次。每個模型復制的計算的梯度被平均,結果用來更新模型參數。這種方法叫做數據并行。這種方法有許多變種,我們看看其中一些重要的。
#### 使用鏡像策略做數據并行
可能最簡單的方法是所有 GPU 上的模型參數完全鏡像,參數更新也一樣。這么做,所有模型復制是完全一樣的。這被稱為鏡像策略,很高效,尤其是使用一臺機器時(見圖 19-18)。
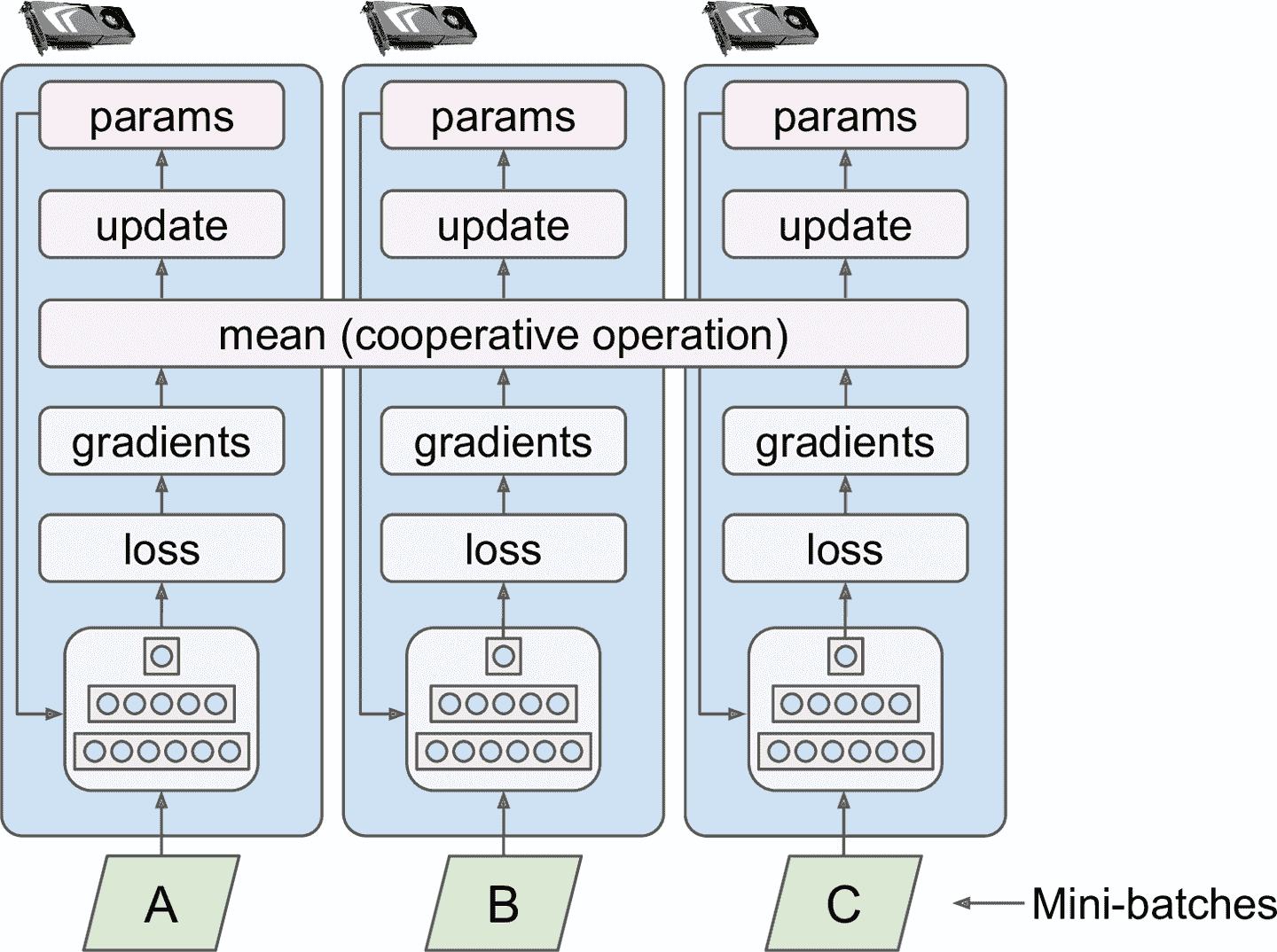圖 19-18 用鏡像策略做數據并行
這種方法的麻煩之處是如何高效計算所有 GPU 的平均梯度,并將梯度分不到所有 GPU 上。這可以使用 AllReduce 算法,這是一種用多個節點齊心協力做 reduce 運算(比如,計算平均值,總和,最大值)的算法,還能讓所有節點獲得相同的最終結果。幸好,這個算法是現成的。
#### 集中參數數據并行
另一種方法是將模型參數存儲在做計算的 GPU(稱為 worker)的外部,例如放在 CPU 上(見圖 19-19)。在分布式環境中,可以將所有參數放到一個或多個只有 CPU 的服務器上(稱為參數服務器),它的唯一作用是存儲和更新參數。
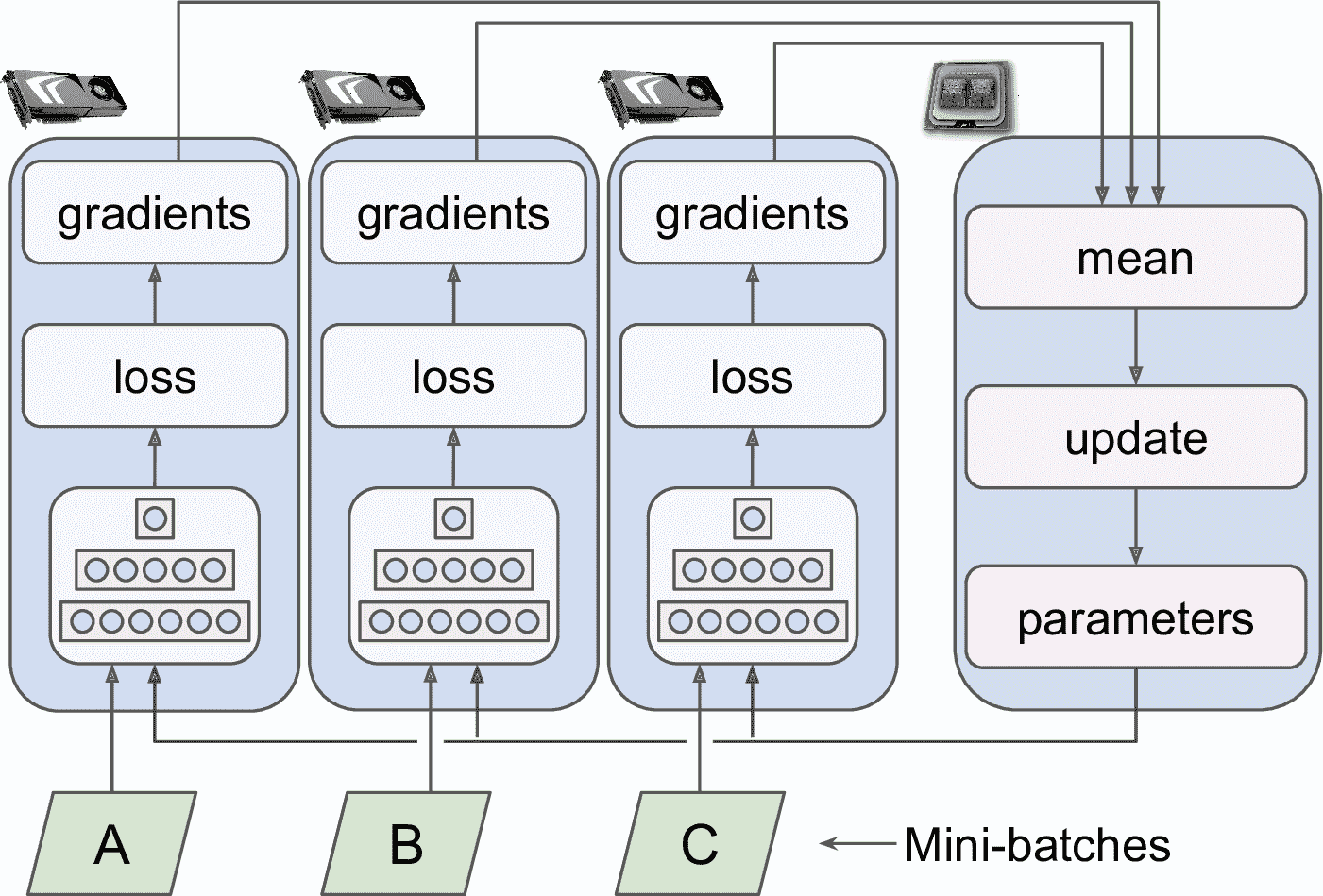圖 19-19 集中參數數據并行
鏡像策略數據并行只能使用同步參數更新,而集中數據并行可以使用同步和異步更新兩種方法。看看這兩種方法的優點和缺點。
##### *同步更新*
同步更新中,累加器必須等待所有梯度都可用了,才計算平均梯度,再將其傳給優化器,更新模型參數。當模型復制計算完梯度后,它必須等待參數更新,才能處理下一個批次。缺點是一些設備可能比一些設備慢,所以其它設備必須等待。另外,參數要同時復制到每臺設備上(應用梯度之后),可能會飽和參數服務器的帶寬。
> 提示:要降低每步的等待時間,可以忽略速度慢的模型復制的梯度(大概~10%)。例如,可以運行 20 個模型復制,只累加最快的 18 個,最慢的 2 個忽略。參數更新好后,前 18 個復制就能立即工作,不用等待 2 個最慢的。這樣的設置被描述為 18 個復制加 2 個閑置復制。
##### *異步更新*
異步更新中,每當復制計算完了梯度,它就立即用其更新模型參數。沒有累加過程(去掉了圖 19-19 中的平均步驟),沒有同步。模型復制彼此獨立工作。因為無需等待,這種方法每分鐘可以運行更多訓練步。另外,盡管參數仍然需要復制到每臺設備上,都是每臺設備在不同時間進行的,帶寬飽和風險降低了。
異步更新的數據并行是不錯的方法,因為簡單易行,沒有同步延遲,對帶寬的更佳利用。當模型復制根據一些參數值完成了梯度計算,這些參數會被其它復制更新幾次(如果有 N 個復制,平均時 N-1 次),且不能保證計算好的梯度指向正確的方向(見圖 19-20)。如果梯度過期,被稱為陳舊梯度:它們會減慢收斂,引入噪音和抖動(學習曲線可能包含暫時的震動),或者會使訓練算法發散。
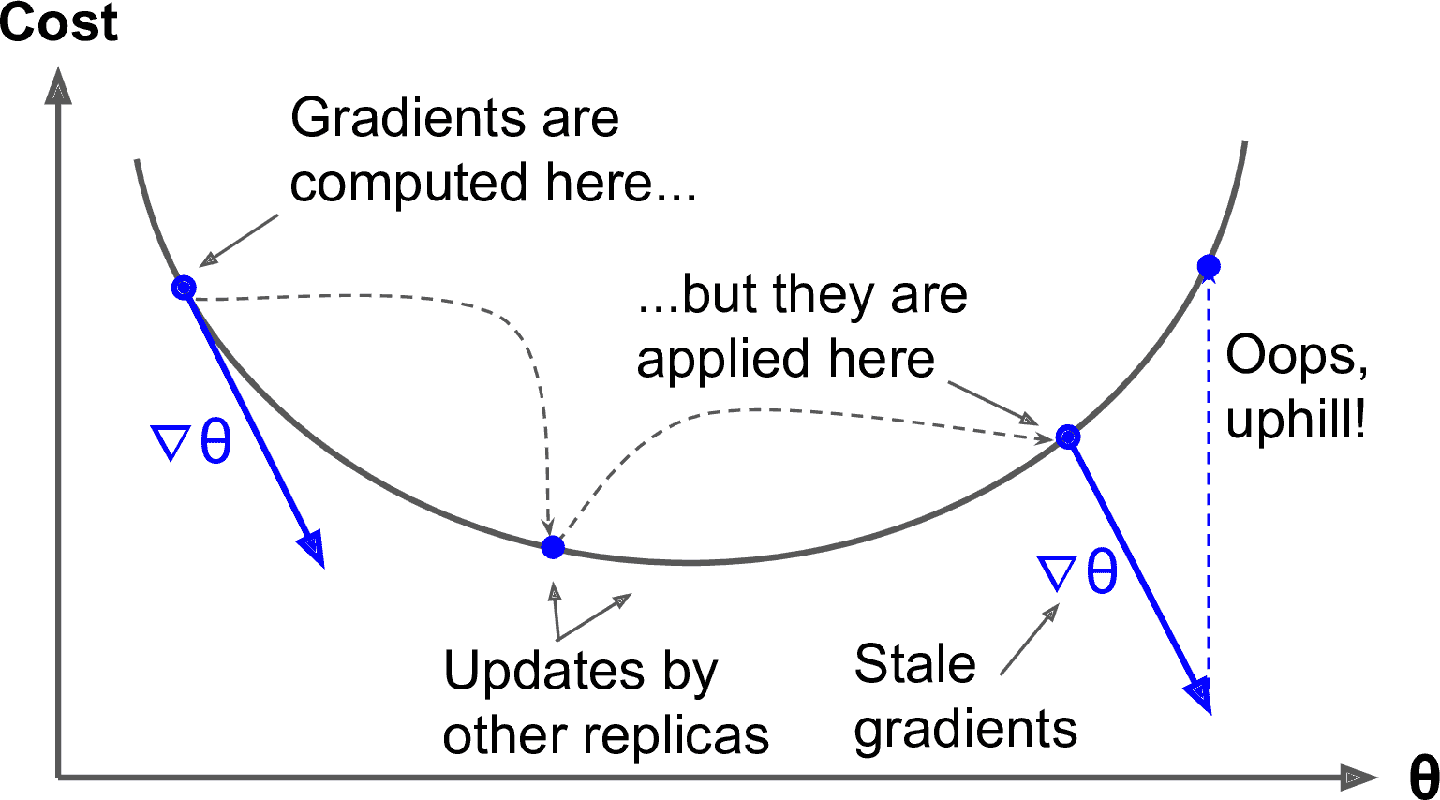圖 19-20 使用異步更新時會導致陳舊梯度
有幾種方法可以減少陳舊梯度的壞處:
* 降低學習率。
* 丟棄陳舊梯度或使其變小。
* 調整批次大小。
* 只用一個復制進行前幾個周期(被稱為熱身階段)。陳舊梯度在訓練初始階段的破壞最大,當梯度很大且沒有落入損失函數的山谷時,不同的復制會將參數推向不同方向。
[Google Brain 團隊在 2016 年發表了一篇論文](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2F68),測量了幾種方法,發現用閑置復制的同步更新比異步更新更加高效,收斂更快,模型效果更好。但是,這仍是一個活躍的研究領域,所以不要排除異步更新。
#### 帶寬飽和
無論使用同步還是異步更新,集中式參數都需要模型復制和參數模型在每個訓練步開始階段的通信,以及在訓練步的后期和梯度在其它方向的通信。相似的,在使用鏡像策略時,每個 GPU 生成的梯度需要和其它 GPU 分享。想好,總是存在臨界點,添加額外的 GPU 不能提高性能,因為 GPU 內存數據通信的壞處抵消了計算負載的降低。超過這點,添加更多 GPU 反而使帶寬更糟,會減慢訓練。
> 提示:對于一些相對小、用大訓練數據訓練得到的模型,最好用單機大內存帶寬單 GPU 訓練。
帶寬飽和對于大緊密模型更加嚴重,因為有許多參數和梯度要傳輸。對于小模型和大的系數模型,不那么嚴重(但沒怎么利用并行計算),大多數參數是 0,可以高效計算。Jeff Dean,Google Brain 的發起者和領導,指明用 50 個 GPU 分布計算緊密模型,可以加速 25-40 倍;用 500 個 GPU 訓練系數模型,可以加速 300 倍。可以看到,稀疏模型擴展更好。下面是一些具體例子:
* 神經機器翻譯:8 個 GPU,加速 6 倍
* Inception/ImageNet:50 個 GPU,加速 32 倍
* RankBrain:500 個 GPU,加速 300 倍
緊密模型使用幾十塊 GPU,稀疏模型使用幾百塊 GPU,就達到了帶寬瓶頸。許多研究都在研究這個問題(使用 peer-to-peer 架構,而不是集中式架構,做模型壓縮,優化通信時間和內容,等等),接下來幾年,神經網絡并行計算會取得很多成果。
同時,為了解決飽和問題,最好使用一些強大的 GPU,而不是大量一般的 GPU,最好將 GPU 集中在有內網的服務器中。還可以將浮點數精度從 32 位(`tf.float32`)降到 16 位(`tf.bfloat16`)。這可以減少一般的數據傳輸量,通常不會影響收斂和性能。最后,如果使用集中參數,可以將參數切片到多臺參數服務器上:增加參數服務器可以降低網絡負載,降低貸款飽和的風險。
下面就用多個 GPU 訓練模型。
### 使用 Distribution Strategies API 做規模訓練
許多模型都可以用單一 GPU 或 CPU 來訓練。但如果訓練太慢,可以將其分布到同一臺機器上的多個 GPU 上。如果還是太慢,可以換成更強大的 GPU,或添加更多的 GPU。如果模型要做重計算(比如大矩陣乘法),強大的 GPU 算的更快,你還可以嘗試 Google Cloud AI Platform 的 TPU,它運行這種模型通常更快。如果加不了 GPU,也使不了 TPU(例如,TPU 沒有提升,或你想使用自己的硬件架構),則你可以嘗試在多臺服務器上訓練,每臺都有多個 GPU(如果這還不成,最后一種方法是添加并行模型,但需要更多嘗試)。本節,我們會學習如何規模化訓練模型,從單機多 GPU 開始(或 TPU),然后是多機多 GPU。
幸好,TensorFlow 有一個非常簡單的 API 做這項工作:Distribution Strategies API。要用多個 GPU 訓練 Keras 模型(先用單機),用鏡像策略的數據并行,創建一個對象`MirroredStrategy`,調用它的`scope()`方法,獲取分布上下文,在上下文中包裝模型的創建和編譯。然后正常調用模型的`fit()`方法:
```py
distribution = tf.distribute.MirroredStrategy()
with distribution.scope():
mirrored_model = tf.keras.Sequential([...])
mirrored_model.compile([...])
batch_size = 100 # must be divisible by the number of replicas
history = mirrored_model.fit(X_train, y_train, epochs=10)
```
在底層,tf.keras 是分布式的,所以在這個`MirroredStrategy`上下文中,它知道要復制所有變量和運算到可用的 GPU 上。`fit()`方法,可以自動對所有模型復制分割訓練批次,所以批次大小要可以被模型復制的數量整除。就是這樣。比用一個 GPU,這么訓練會快很多,而且代碼變動很少。
訓練好模型后,就可以做預測了:調用`predict()`方法,就能自動在模型復制上分割批次,并行做預測(批次大小要能被模型復制的數量整除)。如果調用模型的`save()`方法,會像常規模型那樣保存。所以加載時,在單設備上(默認是 GPU 0,如果沒有 GPU,就是 CPU),就和常規模型一樣。如果想加載模型,并在可用設備上運行,必須在分布上下文中調用`keras.models.load_model()`:
```py
with distribution.scope():
mirrored_model = keras.models.load_model("my_mnist_model.h5")
```
如果只想使用 GPU 設備的一部分,可以將列表傳給`MirroredStrategy`的構造器:
```py
distribution = tf.distribute.MirroredStrategy(["/gpu:0", "/gpu:1"])
```
默認時,`MirroredStrategy`類使用 NVIDIA Collective Communications 庫(NCCL)做 AllReduce 平均值運算,但可以設置`tf.distribute.HierarchicalCopyAllReduce`類的實例,或`tf.distribute.ReductionToOneDevice`類的實例的`cross_device_ops`參數,換其它的庫。默認的 NCCL 是基于類`tf.distribute.NcclAllReduce`,它通常很快,但一來 GPU 的數量和類型,所以也可以試試其它選項。
如果想用集中參數的數據并行,將`MirroredStrategy`替換為`CentralStorageStrategy`:
```py
distribution = tf.distribute.experimental.CentralStorageStrategy()
```
你還可以設置`compute_devices`,指定作為 worker 的設備(默認會使用所有的 GPU),還可以通過設置`parameter_device`,指定存儲參數的設備(默認使用 CPU,或 GPU,如果只有一個 GPU 的話)。
下面看看如何用 TensorFlow 集群訓練模型。
### 用 TensorFlow 集群訓練模型
TensorFlow 集群是一組并行運行的 TensorFlow 進程,通常是在不同機器上,彼此通信完成工作 —— 例如,訓練或執行神經網絡。集群中的每個 TF 進程被稱為任務 task,或 TF 服務器。它有 IP 地址,端口和類型(也被稱為角色 role 或工作 job)。類型可以是`"worker"`、`"chief"`、`"ps"`(參數服務器 parameter server)、`"evaluator"`:
* 每個 worker 執行計算,通常是在有一個或多個 GPU 的機器上。
* chief 也做計算,也做其它工作,比如寫 TensorBoard 日志或存儲檢查點。集群中只有一個 chief。如果沒有指定 chief,第一個 worker 就是 chief。
* parameter server 只保留變量值的軌跡,通常是在只有 CPU 的機器上。這個類型的任務只使用`ParameterServerStrategy`。
* evaluator 只做評估。
要啟動 TensorFlow 集群,必須先指定。要定義每個任務的 IP 地址,TCP 端口,類型。例如,下面的集群配置定義了集群有三種任務(兩個 worker 一個 parameter server,見圖 19-21)。集群配置是一個字典,每個 job 一個鍵,值是任務地址(IP:port)列表:
```py
cluster_spec = {
"worker": [
"machine-a.example.com:2222", # /job:worker/task:0
"machine-b.example.com:2222" # /job:worker/task:1
],
"ps": ["machine-a.example.com:2221"] # /job:ps/task:0
}
```
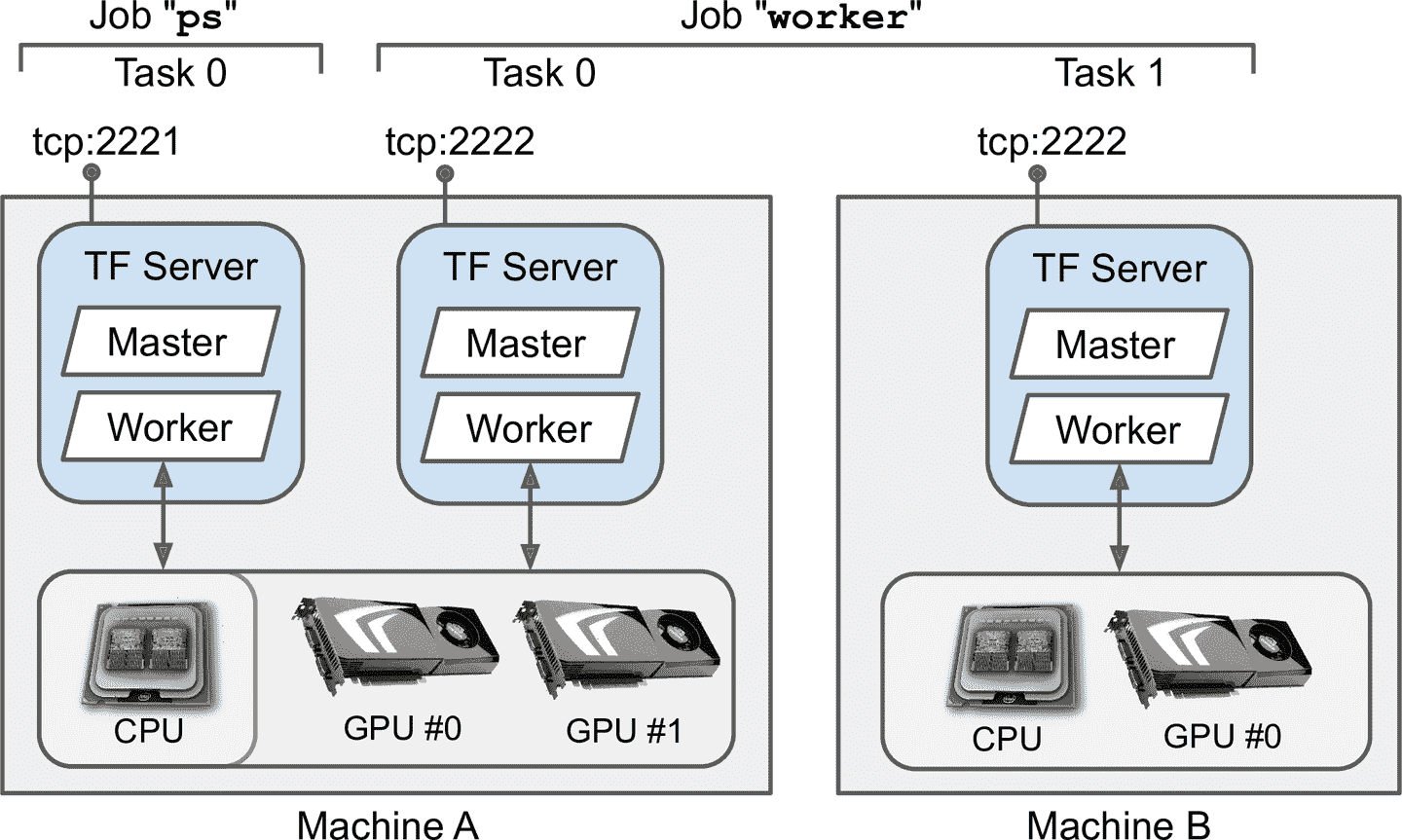圖 19-21 TensorFlow 集群
通常,每臺機器只有一個任務,但這個例子說明,如果愿意,可以在一臺機器上部署多個任務(如果有相同的 GPU,要確保 GPU 內存分配好)。
> 警告:默認,集群中的每個任務都可能與其它任務通信,所以要配置好防火墻確保這些機器端口的通信(如果每臺機器用相同的端口,就簡單一些)。
啟動任務時,必須將集群配置給它,還要告訴它類型和索引(例如,worker 0)。配置最簡單的方法(集群配置和當前任務的類型和索引)是在啟動 TensorFlow 前,設置環境變量`TF_CONFIG`。這是一個 JSON 編碼的字典,包含集群配置(在鍵`"cluster"`下)、類型、任務索引(在鍵`"task"`下)。例如。下面的環境變量`TF_CONFIG`使用了剛才定義的集群,啟動的任務是第一個 worker:
```py
import os
import json
os.environ["TF_CONFIG"] = json.dumps({
"cluster": cluster_spec,
"task": {"type": "worker", "index": 0}
})
```
> 提示:通常要在 Python 外面定義環境變量`TF_CONFIG`,代碼不用包含當前任務的類型和索引(這樣可以讓所有 worker 使用相同的代碼)。
現在用集群訓練一個模型。先用鏡像策略。首先,給每個任務設定環境參數`TF_CONFIG`。因為沒有參數服務器(去除集群配置中的 ps 鍵),所以通常每臺機器只有一個 worker。還要保證每個任務的索引不同。最后,在每個 worker 上運行下面的訓練代碼:
```py
distribution = tf.distribute.experimental.MultiWorkerMirroredStrategy()
with distribution.scope():
mirrored_model = tf.keras.Sequential([...])
mirrored_model.compile([...])
batch_size = 100 # must be divisible by the number of replicas
history = mirrored_model.fit(X_train, y_train, epochs=10)
```
這就是前面用的代碼,只是這次我們使用的是`MultiWorkerMirroredStrategy`(未來版本中,`MirroredStrategy`可能既處理單機又處理多機)。當在第一個 worker 上運行腳本時,它會阻塞所有 AllReduce 步驟,最后一個 worker 啟動后,訓練就開始了。可以看到 worker 以相同的速度前進(因為每步使用的同步)。
你可以從兩個 AllReduce 實現選擇做分布策略:基于 gRPC 的 AllReduce 算法用于網絡通信,和 NCCL 實現。最佳算法取決于 worker 的數量、GPU 的數量和類型和網絡。默認,TensorFlow 會選擇最佳算法,但是如果想強制使用某種算法,將`CollectiveCommunication.RING`或`CollectiveCommunication.NCCL`(出自`tf.distribute.experimental`)傳給策略構造器。
如果想用帶有參數服務器的異步數據并行,可以將策略變為`ParameterServerStrategy`,添加一個或多個參數服務器,給每個任務配置`TF_CONFIG`。盡管 worker 是異步的,每個 worker 的復制是同步工作的。
最后,如果你能用 Google Cloud 的 TPU,可以如下創建`TPUStrategy`:
```py
resolver = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.tpu.experimental.initialize_tpu_system(resolver)
tpu_strategy = tf.distribute.experimental.TPUStrategy(resolver)
```
> 提示:如果是研究員,可以免費試用 TPU,見[*https://tensorflow.org/tfrc*](https://links.jianshu.com/go?to=https%3A%2F%2Ftensorflow.org%2Ftfrc)。
現在就可以在多機多 GPU 訓練模型了。如果想訓練一個大模型,需要多個 GPU 多臺服務器,要么買機器,要么買云虛擬機。云服務更便宜,
### 在 Google Cloud AI Platform 上訓練大任務
如果你想用 Google AI Platform,可以用相同的代碼部署訓練任務,平臺會管理 GPU VM。
要啟動任務,你需要命令行工具`gcloud`,它屬于[Google Cloud SDK](https://links.jianshu.com/go?to=https%3A%2F%2Fcloud.google.com%2Fsdk%2F)。可以在自己的機器上安裝 SDK,或在 GCP 上使用 Google Cloud Shell。這是可以在瀏覽器中使用的終端;運行在免費的 Linux VM(Debian)上,SDK 已經安裝配置好了。Cloud Shell 可以在 GCP 上任何地方使用:只要點擊頁面右上的圖標 Activate Cloud Shell(見圖 19-22)。
圖 19-22 啟動 Google Cloud Shell
如果想在自己機器上安裝 SDK,需要運行`gcloud init`啟動:需要登錄 GCP 準許權限,選擇想要的 GCP 項目,還有想運行的地區。`gcloud`命令可以使用 GCP 所有功能。不用每次訪問網頁接口,可以寫腳本開啟或停止虛擬機、部署模型或做任意 GCP 動作。
運行訓練任務之前,你需要寫訓練代碼,和之前的分布設置一樣(例如,使用`ParameterServerStrategy`)。AI 平臺會為每個 VM 設置`TF_CONFIG`。做好之后,就可以在 TF 集群部署運行了,命令行如下:
```py
$ gcloud ai-platform jobs submit training my_job_20190531_164700 \
--region asia-southeast1 \
--scale-tier PREMIUM_1 \
--runtime-version 2.0 \
--python-version 3.5 \
--package-path /my_project/src/trainer \
--module-name trainer.task \
--staging-bucket gs://my-staging-bucket \
--job-dir gs://my-mnist-model-bucket/trained_model \
--
--my-extra-argument1 foo --my-extra-argument2 bar
```
瀏覽這些選項。命令行啟動名為`my_job_20190531_164700`的訓練任務,地區是`asia-southeast1`,級別是`PREMIUM_1`:對應 20 個 worker 和 11 個參數服務器(查看[其它等級](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fscaletiers)
)。所有 VM 基于 AI Platform’s 2.0 運行時(VM 配置包括 TensorFlow 2.0 和其它包)和 Python 3.5。訓練代碼位于字典`/my_project/src/trainer`,命令`gcloud`會自動綁定 pip 包,并上傳到 GCS 的`gs://my-staging-bucket`。然后,AI Platform 會啟動幾個 VM,部署這些包,運行`trainer.task`模塊。最后,參數`--job-dir`和其它參數(即,分隔符`--`后面的參數)會傳給訓練程序:主任務會使用參數`--job-dir`在 GCS 上保存模型,在這個例子中,是在`gs://my-mnist-model-bucket/trained_model`。就是這樣。在 GCP 控制臺中,你可以打開導航欄,下滑到 Artificial Intelligence,打開 AI Platform → Jobs。可以看到在運行的任務,如果點擊,可以看到圖展示了每個任務的 CPU、GPU 和 RAM。點擊 View Logs,可以使用 Stackdriver 查看詳細日志。
> 筆記:如果將訓練數據放到 GCS 上,可以創建`tf.data.TextLineDataset`或`tf.data.TFRecordDataset`來訪問:用 GCS 路徑作為文件名(例如,`gs://my-data-bucket/my_data_001.csv`)。這些數據集依賴包`tf.io.gfile`訪問文件:支持本地文件和 GCS 文件(要保證服務賬號可以使用 GCS)。
如果想探索幾個超參數的值,可以用參數指定超參數值,執行多個任務。但是,日過想探索許多超參數,最好使用 AI Platform 的超參數調節服務。
### 在 AI Platform 上做黑盒超參數調節
AI Platform 提供了強大的貝葉斯優化超參數調節服務,稱為[Google Vizier](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fvizier)。要使用,創建任務時要傳入 YAML 配置文件(`--config tuning.yaml`)。例如,可能如下:
```py
trainingInput:
hyperparameters:
goal: MAXIMIZE
hyperparameterMetricTag: accuracy
maxTrials: 10
maxParallelTrials: 2
params:
- parameterName: n_layers
type: INTEGER
minValue: 10
maxValue: 100
scaleType: UNIT_LINEAR_SCALE
- parameterName: momentum
type: DOUBLE
minValue: 0.1
maxValue: 1.0
scaleType: UNIT_LOG_SCALE
```
它告訴 AI Platform,我們的目的是最大化指標`"accuracy"`,任務會做最多 10 次試驗(每次試驗都從零開始訓練),最多并行運行 2 個試驗。我們想調節兩個超參數:`n_layers`(10 到 100 間的整數),和`momentum`(0.1 和 1.0 之間的浮點數)。參數`scaleType`指明了先驗:`UNIT_LINEAR_SCALE`是扁平先驗(即,沒有先驗偏好),`UNIT_LOG_SCALE`的先驗是最優值靠近最大值(其它可能的先驗是`UNIT_REVERSE_LOG_SCALE`,最佳值靠近最小值)。
`n_layers`和`momentum`參數會作為命令行參數傳給訓練代碼。問題是訓練代碼如何將指標傳回給 AI Platform,以便決定下一個試驗使用什么超參數?AI Platform 會監督輸出目錄(通過`--job-dir`指定)的每個包含指標`"accuracy"`概括的事件文件(或是其它`hyperparameterMetricTag`指定的名字),讀取這些值。訓練代碼使用`TensorBoard()`調回,就可以開始了。
任務完成后,每次試驗中使用的超參數值和結果準確率會顯示在任務的輸出中(在 AI Platform → Jobs page)。
> 筆記:AI Platform 還可以用于在大量數據上執行模型:每個 worker 從 GCS 讀取部分數據,做預測,并保存在 GCS 上。
現在就可以用各種分布策略規模化創建先進的神經網絡架構了,可以用自己的機器,也可以用云 —— 還可以用高效貝葉斯優化微調超參數。
## 練習
1. SavedModel 包含什么?如何檢查內容?
2. 什么時候使用 TF Serving?它有什么特點?可以用什么工具部署 TF Serving?
3. 如何在多個 TF Serving 實例上部署模型?
4. 為什么使用 gRPC API 而不是 REST API,查詢 TF Serving 模型?
5. 在移動和嵌入設備上運行,TFLite 減小模型的大小有什么方法?
6. 什么是偽量化訓練,有什么用?
7. 什么是模型并行和數據并行?為什么推薦后者?
8. 在多臺服務器上訓練模型時,可以使用什么分布策略?如何進行選擇?
9. 訓練模型(或任意模型),部署到 TF Serving 或 Google Cloud AI Platform 上。寫客戶端代碼,用 REST API 或 gRPC API 做查詢。更新模型,部署新版本。客戶端現在查詢新版本。回滾到第一個版本。
10. 用一臺機器多個 GPU、`MirroredStrategy`策略,訓練模型(如果沒有 GPU,可以使用帶有 GPU 的 Colaboratory,創建兩個虛擬 GPU)。再用`CentralStorageStrategy`訓練一次,比較訓練時間。
11. 在 Google Cloud AI Platform 訓練一個小模型,使用黑盒超參數調節。
參考答案見附錄 A。
