# 十四、使用卷積神經網絡實現深度計算機視覺
> 譯者:[@SeanCheney](https://www.jianshu.com/u/130f76596b02)
盡管 IBM 的深藍超級計算機在 1996 年擊敗了國際象棋世界冠軍加里·卡斯帕羅夫,但直到最近計算機才能從圖片中認出小狗,或是識別出說話時的單詞。為什么這些任務對人類反而毫不費力呢?原因在于,感知過程不屬于人的自我意識,而是屬于專業的視覺、聽覺和其它大腦感官模塊。當感官信息抵達意識時,信息已經具有高級特征了:例如,當你看一張小狗的圖片時,不能選擇不可能,也不能回避的小狗的可愛。你解釋不了你是如何識別出來的:小狗就是在圖片中。因此,我們不能相信主觀經驗:感知并不簡單,要明白其中的原理,必須探究感官模塊。
卷積神經網絡(CNN)起源于人們對大腦視神經的研究,自從 1980 年代,CNN 就被用于圖像識別了。最近幾年,得益于算力提高、訓練數據大增,以及第 11 章中介紹過的訓練深度網絡的技巧,CNN 在一些非常復雜的視覺任務上取得了超出人類表現的進步。CNN 支撐了圖片搜索、無人駕駛汽車、自動視頻分類,等等。另外,CNN 也不再限于視覺,比如:語音識別和自然語言處理,但這一章只介紹視覺應用。
本章會介紹 CNN 的起源,CNN 的基本組件以及 TensorFlow 和 Keras 實現方法。然后會討論一些優秀的 CNN 架構,和一些其它的視覺任務,比如目標識別(分類圖片中的多個物體,然后畫框)、語義分割(按照目標,對每個像素做分類)。
## 視神經結構
David H. Hubel 和 Torsten Wiesel 在 1958 年和 1959 年在貓的身上做了一系列研究,對視神經中樞做了研究(并在 1981 年榮獲了諾貝爾生理學或醫學獎)。特別的,他們指出視神經中的許多神經元都有一個局部感受野(local receptive field),也就是說,這些神經元只對有限視覺區域的刺激作反應(見圖 14-1,五個神經元的局部感受野由虛線表示)。不同神經元的感受野或許是重合的,拼在一起就形成了完整的視覺區域。
另外,David H. Hubel 和 Torsten Wiesel 指出,有些神經元只對橫線有反應,而其它神經元可能對其它方向的線有反應(兩個神經元可能有同樣的感受野,但是只能對不同防線的線有反應)。他們還注意到,一些神經元有更大的感受野,可以處理更復雜的圖案,復雜圖案是由低級圖案構成的。這些發現啟發人們,高級神經元是基于周邊附近低級神經元的輸出(圖 14-1 中,每個神經元只是連著前一層的幾個神經元)。這樣的架構可以監測出視覺區域中各種復雜的圖案。
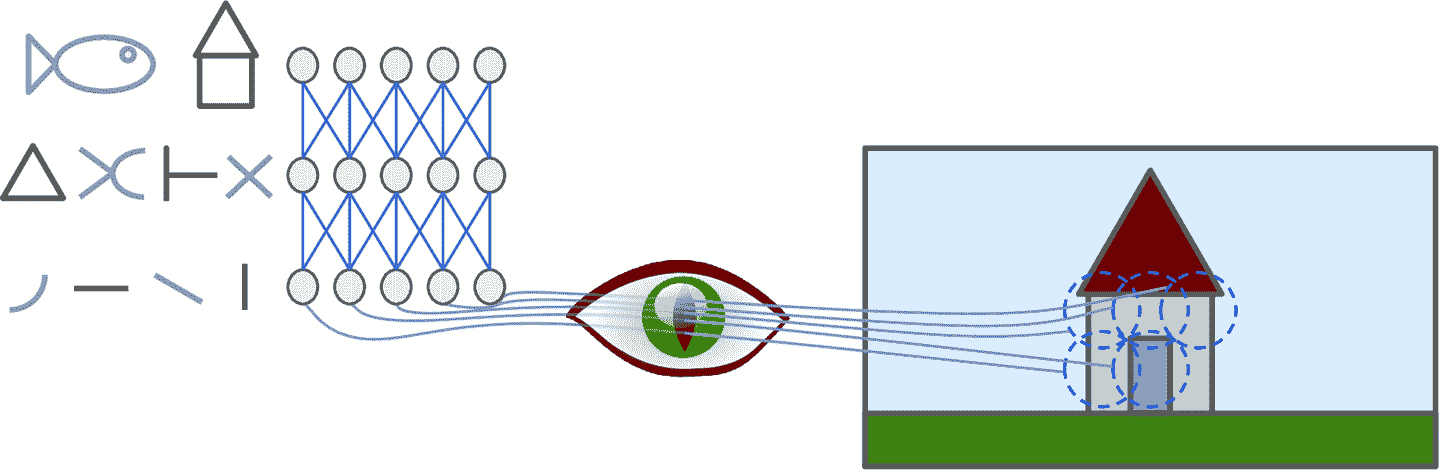圖 14-1 視神經中生物神經元可以對感受野中的圖案作反應;當視神經信號上升時,神經元可以反應出更大感受野中的更為復雜的圖案
對視神經的研究在 1980 年啟發了[神經認知學](https://links.jianshu.com/go?to=https%3A%2F%2Fwww.cs.princeton.edu%2Fcourses%2Farchive%2Fspr08%2Fcos598B%2FReadings%2FFukushima1980.pdf),后者逐漸演變成了今天的卷積神經網絡。Yann LeCun 等人再 1998 年發表了一篇里程碑式的論文,提出了著名的 LeNet-5 架構,被銀行廣泛用來識別手寫支票的數字。這個架構中的一些組件,我們已經學過了,比如全連接層、sigmod 激活函數,但 CNN 還引入了兩個新組件:卷積層和池化層。
> 筆記:為什么不使用全連接層的深度神經網絡來做圖像識別呢?這是因為,盡管這種方案在小圖片(比如 MNIST)任務上表現不錯,但由于參數過多,在大圖片任務上表現不佳。舉個例子,一張 100 × 100 像素的圖片總共有 10000 個像素點,如果第一層有 1000 個神經元(如此少的神經元,已經限制信息的傳輸量了),那么就會有 1000 萬個連接。這僅僅是第一層的情況。CNN 是通過部分連接層和權重共享解決這個問題的。
## 卷積層
卷積層是 CNN 最重要的組成部分:第一個卷積層的神經元,不是與圖片中的每個像素點都連接,而是只連著局部感受野的像素(見圖 14-2)。同理,第二個卷積層中的每個神經元也只是連著第一層中一個小方形內的神經元。這種架構可以讓第一個隱藏層聚焦于小的低級特征,然后在下一層組成大而高級的特征,等等。這種層級式的結構在真實世界的圖片很常見,這是 CNN 能在圖片識別上取得如此成功的原因之一。
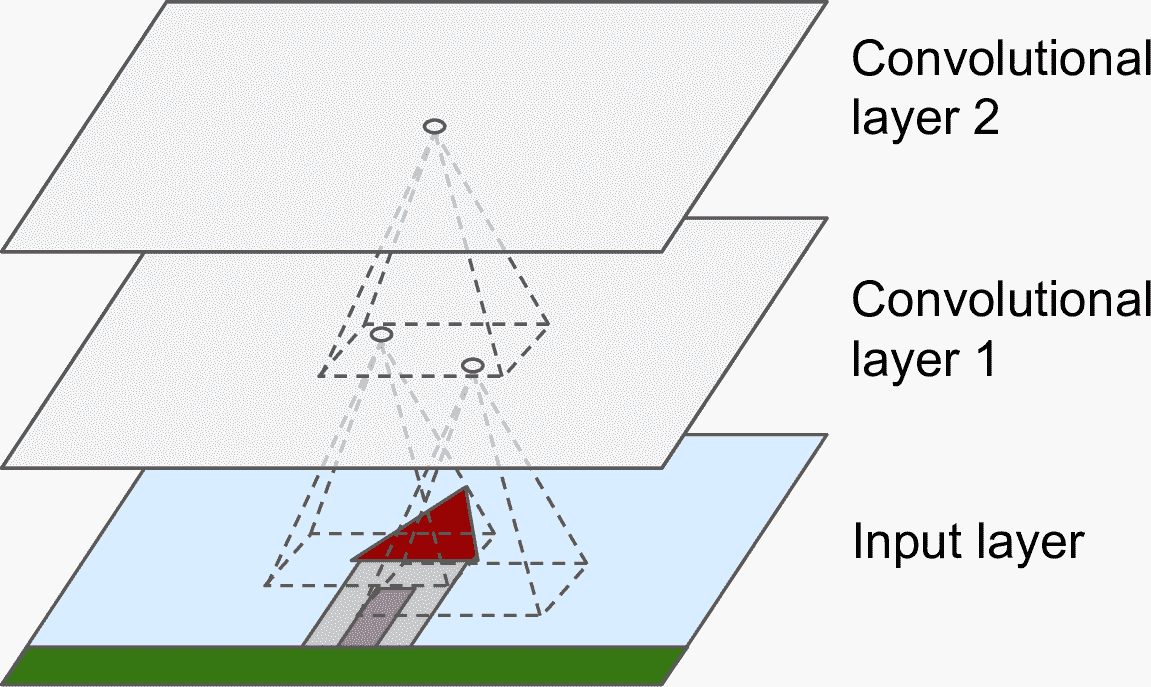圖 14-2 有方形局部感受野的 CNN 層
> 筆記:我們目前所學過的所有多層神經網絡的層,都是由一長串神經元組成的,所以在將圖片輸入給神經網絡之前,必須將圖片打平成 1D 的。在 CNN 中,每個層都是 2D 的,更容易將神經元和輸入做匹配。
位于給定層第`i`行、第`j`列的神經元,和前一層的第`i`行到第`i + fh – 1`行、第`j`列到第`j + fw – 1`列的輸出相連,f<sub>h</sub>和 f<sub>w</sub>是感受野的高度和寬度(見圖 14-3)。為了讓卷積層能和前一層有相同的高度和寬度,通常給輸入加上 0,見圖,這被稱為零填充(zero padding)。
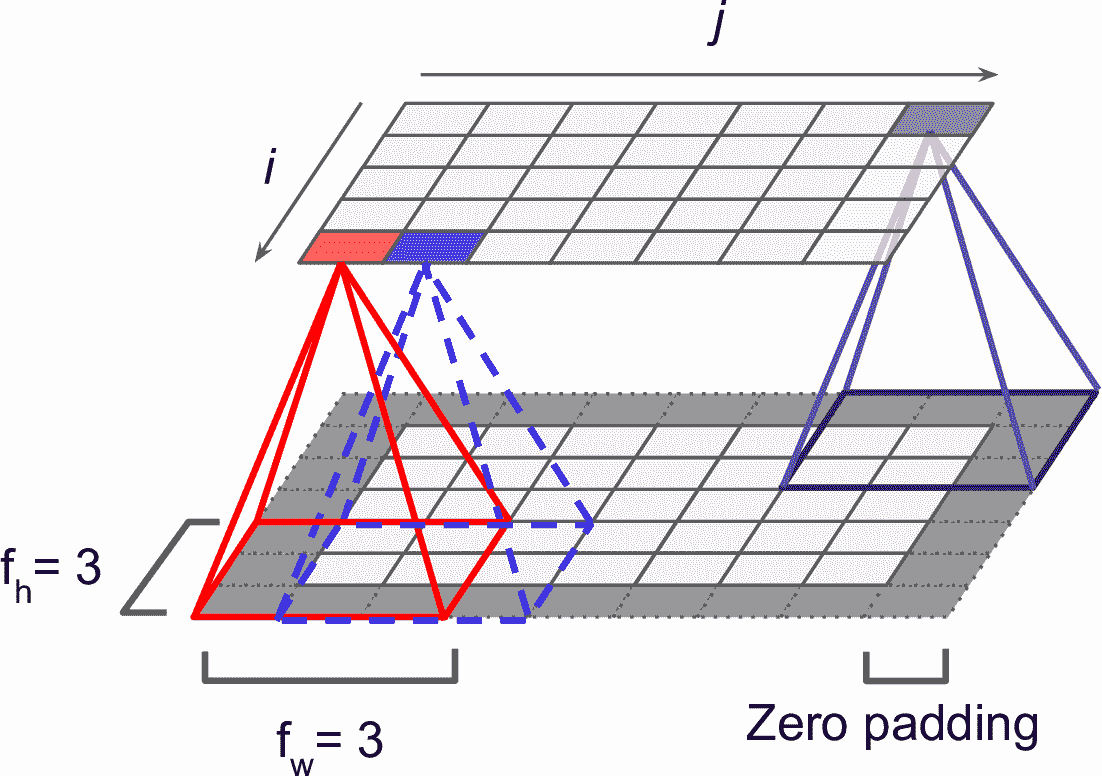圖 14-3 卷積層和零填充的連接
也可以通過間隔感受野,將大輸入層和小卷積層連接起來,見圖 14-4。這么做可以極大降低模型的計算復雜度。一個感受野到下一個感受野的便宜距離稱為步長。在圖中,5 × 7 的輸入層(加上零填充),連接著一個 3 × 4 的層,使用 3 × 3 的感受野,步長是 2(這個例子中,寬和高的步長都是 2,但也可以不同)。位于上層第`i`行、第`j`列的神經元,連接著前一層的第`i × sh`到`i × sh + fh – 1`行、第`j × sw`到`j × sw + fw – 1`列的神經元的輸出,s<sub>h</sub>和 s<sub>w</sub>分別是垂直和水平步長。
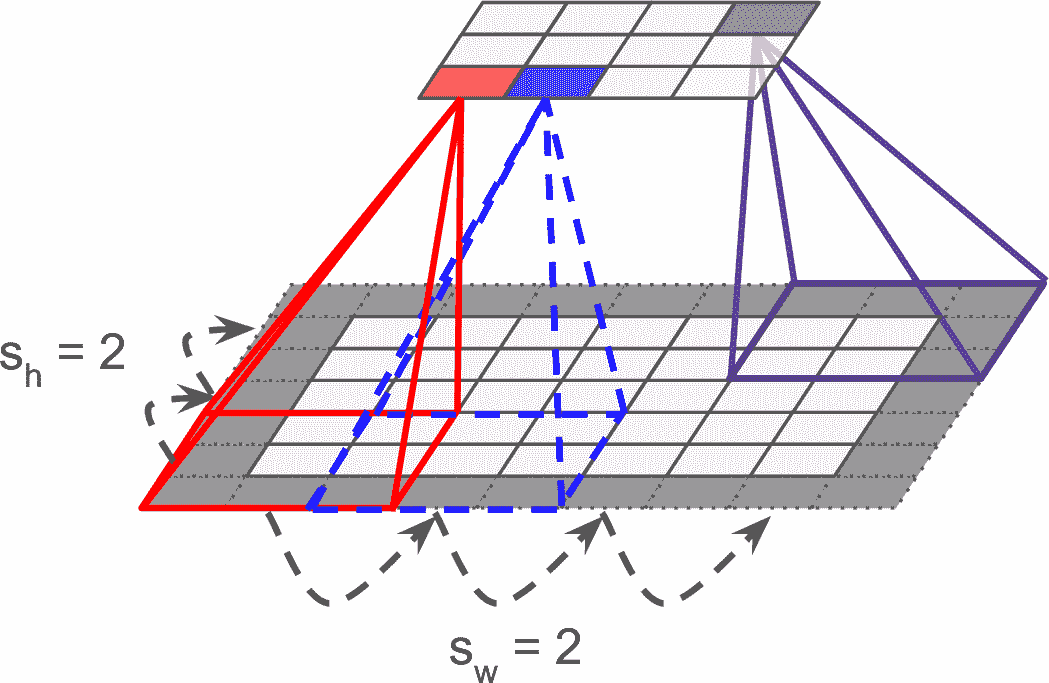圖 14-2 使用大小為 2 的步長降維
### 過濾器
神經元的權重可以表示為感受野大小的圖片。例如,圖 14-5 展示了兩套可能的權重(稱為權重,或卷積核)。第一個是黑色的方形,中央有垂直白線(7 × 7 的矩陣,除了中間的豎線都是 1,其它地方是 0);使用這個矩陣,神經元只能注意到中間的垂直線(因為其它地方都乘以 0 了)。第二個過濾器也是黑色的方形,但是中間是水平的白線。使用這個權重的神經元只會注意中間的白色水平線。
如果卷積層的所有神經元使用同樣的垂直過濾器(和同樣的偏置項),給神經網絡輸入圖 14-5 中最底下的圖片,卷積層輸出的是左上的圖片。可以看到,圖中垂直的白線得到了加強,其余部分變模糊了。相似的,右上的圖是所有神經元都是用水平線過濾器的結果,水平的白線加強了,其余模糊了。因此,一層的全部神經元都用一個過濾器,就能輸出一個特征映射(feature map),特征映射可以高亮圖片中最為激活過濾器的區域。當然,不用手動定義過濾器:卷積層在訓練中可以自動學習對任務最有用的過濾器,上面的層則可以將簡單圖案組合為復雜圖案。
圖 14-5 應用兩個不同的過濾器,得到兩張不同的特征映射
### 堆疊多個特征映射
簡單起見,前面都是將每個卷積層的輸出用 2D 層來表示的,但真實的卷積層可能有多個過濾器(過濾器數量由你確定),每個過濾器會輸出一個特征映射,所以表示成 3D 更準確(見圖 14-6)。每個特征映射的每個像素有一個神經元,同一特征映射中的所有神經元有同樣的參數(即,同樣的權重和偏置項)。不同特征映射的神經元的參數不同。神經元的感受野和之前描述的相同,但擴展到了前面所有的特征映射。總而言之,一個卷積層同時對輸入數據應用多個可訓練過濾器,使其可以檢測出輸入的任何地方的多個特征。
> 筆記:同一特征映射中的所有神經元共享一套參數,極大地減少了模型的參數量。當 CNN 認識了一個位置的圖案,就可以在任何其它位置識別出來。相反的,當常規 DNN 學會一個圖案,只能在特定位置識別出來。
輸入圖像也是有多個子層構成的:每個顏色通道,一個子層。通常是三個:紅,綠,藍(RGB)。灰度圖只有一個通道,但有些圖可能有多個通道 —— 例如,衛星圖片可以捕捉到更多的光譜頻率(比如紅外線)。
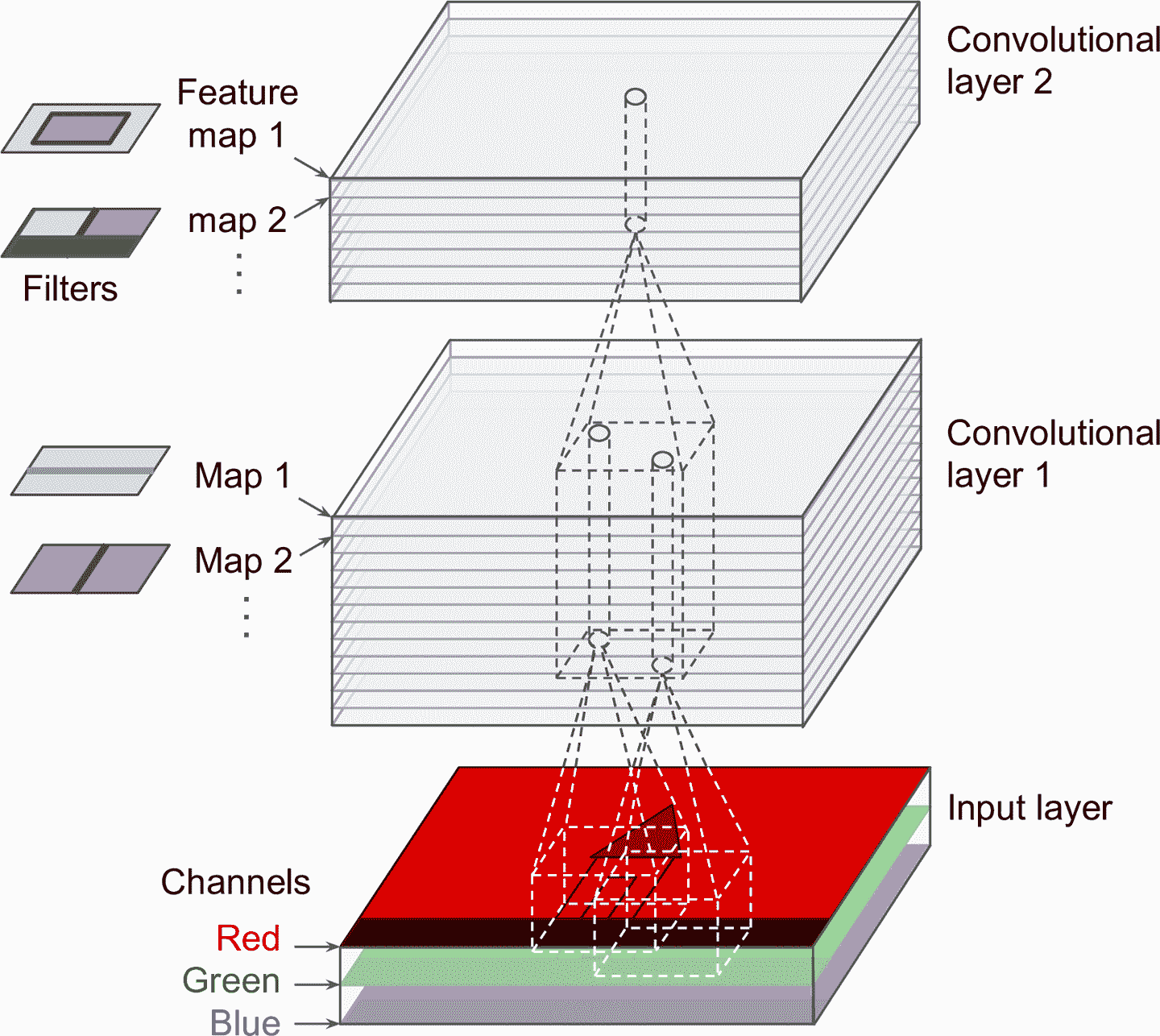圖 14-6 有多個特征映射的卷積層,有三個顏色通道的圖像
特別的,位于卷積層`l`的特征映射`k`的第`i`行、第`j`列的神經元,它連接的是前一層`l-1`的`i × sh`到`i × sh + fh – 1`行、`j × sw`到`j × sw + fw – 1`列的所有特征映射。不同特征映射中,位于相同`i`行、`j`列的神經元,連接著前一層相同的神經元。
等式 14-1 用一個大等式總結了前面的知識:如何計算卷積層中給定神經元的輸出。因為索引過多,這個等式不太好看,它所做的其實就是計算所有輸入的加權和,再加上偏置項。
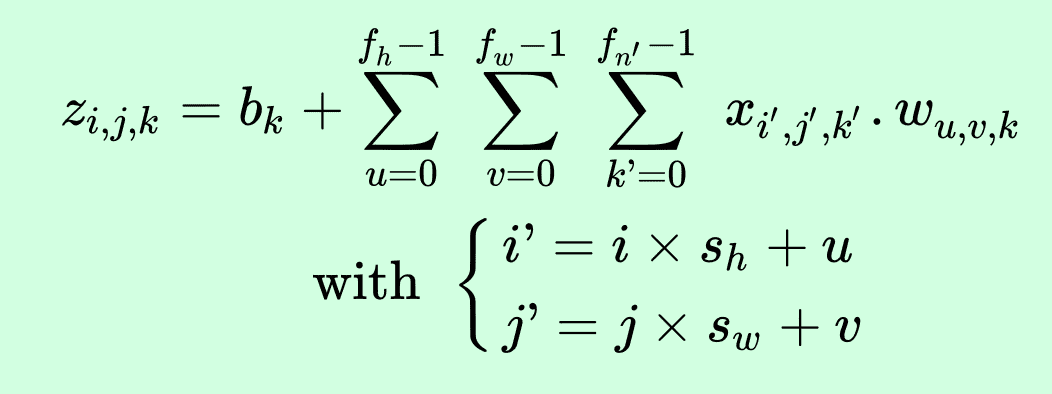等式 14-1 計算卷積層中給定神經元的輸出
在這個等式中:
* z<sub>i, j, k</sub>是卷積層`l`中第`i`行、第`j`列、特征映射`k`的輸出。
* s<sub>h</sub> 和 s<sub>w</sub> 是垂直和水平步長,f<sub>h</sub> 和 f<sub>w</sub> 是感受野的高和寬,f<sub>n'</sub>是前一層`l-1`的特征映射數。
* x<sub>i', j', k'</sub>是卷積層`l-1`中第`i'`行、第`j'`列、特征映射`k'`的輸出(如果前一層是輸入層,則為通道`k'`)。
* b<sub>k</sub>是特征映射`k`的偏置項。可以將其想象成一個旋鈕,可以調節特征映射 k 的明亮度。
* w<sub>u, v, k′ ,k</sub>是層`l`的特征映射`k`的任意神經元,和位于行`u`、列`v`(相對于神經元的感受野)、特征映射`k'`的輸入,兩者之間的連接權重。
### TensorFlow 實現
在 TensorFlow 中,每張輸入圖片通常都是用形狀為`[高度,寬度,通道]`的 3D 張量表示的。一個小批次則為 4D 張量,形狀是`[批次大小,高度,寬度,通道]`。卷積層的權重是 4D 張量,形狀是 [f<sub>h</sub>, f<sub>w</sub>, f<sub>n′</sub>, f<sub>n</sub>] 。卷積層的偏置項是 1D 張量,形狀是 [f<sub>n</sub>] 。
看一個簡單的例子。下面的代碼使用 Scikit-Learn 的`load_sample_image()`加載了兩張圖片,一張是中國的寺廟,另一張是花,創建了兩個過濾器,應用到了兩張圖片上,最后展示了一張特征映射:
```py
from sklearn.datasets import load_sample_image
# 加載樣本圖片
china = load_sample_image("china.jpg") / 255
flower = load_sample_image("flower.jpg") / 255
images = np.array([china, flower])
batch_size, height, width, channels = images.shape
# 創建兩個過濾器
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # 垂直線
filters[3, :, :, 1] = 1 # 水平線
outputs = tf.nn.conv2d(images, filters, strides=1, padding="same")
plt.imshow(outputs[0, :, :, 1], cmap="gray") # 畫出第 1 張圖的第 2 個特征映射
plt.show()
```
逐行看下代碼:
* 每個顏色通道的像素強度是用 0 到 255 來表示的,所以直接除以 255,將其縮放到區間 0 到 1 內。
* 然后創建了兩個 7 × 7 的過濾器(一個有垂直正中白線,另一個有水平正中白線)。
* 使用`tf.nn.conv2d()`函數,將過濾器應用到兩張圖片上。這個例子中使用了零填充(`padding="same"`),步長是 1。
* 最后,畫出一個特征映射(相似與圖 14-5 中的右上圖)。
`tf.nn.conv2d()`函數這一行,再多說說:
* `images`是一個輸入的小批次(4D 張量)。
* `filters`是過濾器的集合(也是 4D 張量)。
* `strides`等于 1,也可以是包含 4 個元素的 1D 數組,中間的兩個元素是垂直和水平步長(s<sub>h</sub> 和 s<sub>w</sub>),第一個和最后一個元素現在必須是 1。以后可以用來指定批次步長(跳過實例)和通道步長(跳過前一層的特征映射或通道)。
* `padding`必須是`"same"`或`"valid"`:
* 如果設為`"same"`,卷積層會使用零填充。輸出的大小是輸入神經元的數量除以步長,再取整。例如:如果輸入大小是 13,步長是 5(見圖 14-7),則輸出大小是 3(13 / 5 = 2.6,再向上圓整為 3),零填充盡量在輸入上平均添加。當`strides=1`時,層的輸出會和輸入有相同的空間維度(寬和高),這就是`same`的來歷。
* 如果設為`"valid"`,卷積層就不使用零填充,取決于步長,可能會忽略圖片的輸入圖片的底部或右側的行和列,見圖 14-7(簡單舉例,只是顯示了水平維度)。這意味著每個神經元的感受野位于嚴格確定的圖片中的位置(不會越界),這就是`valid`的來歷。
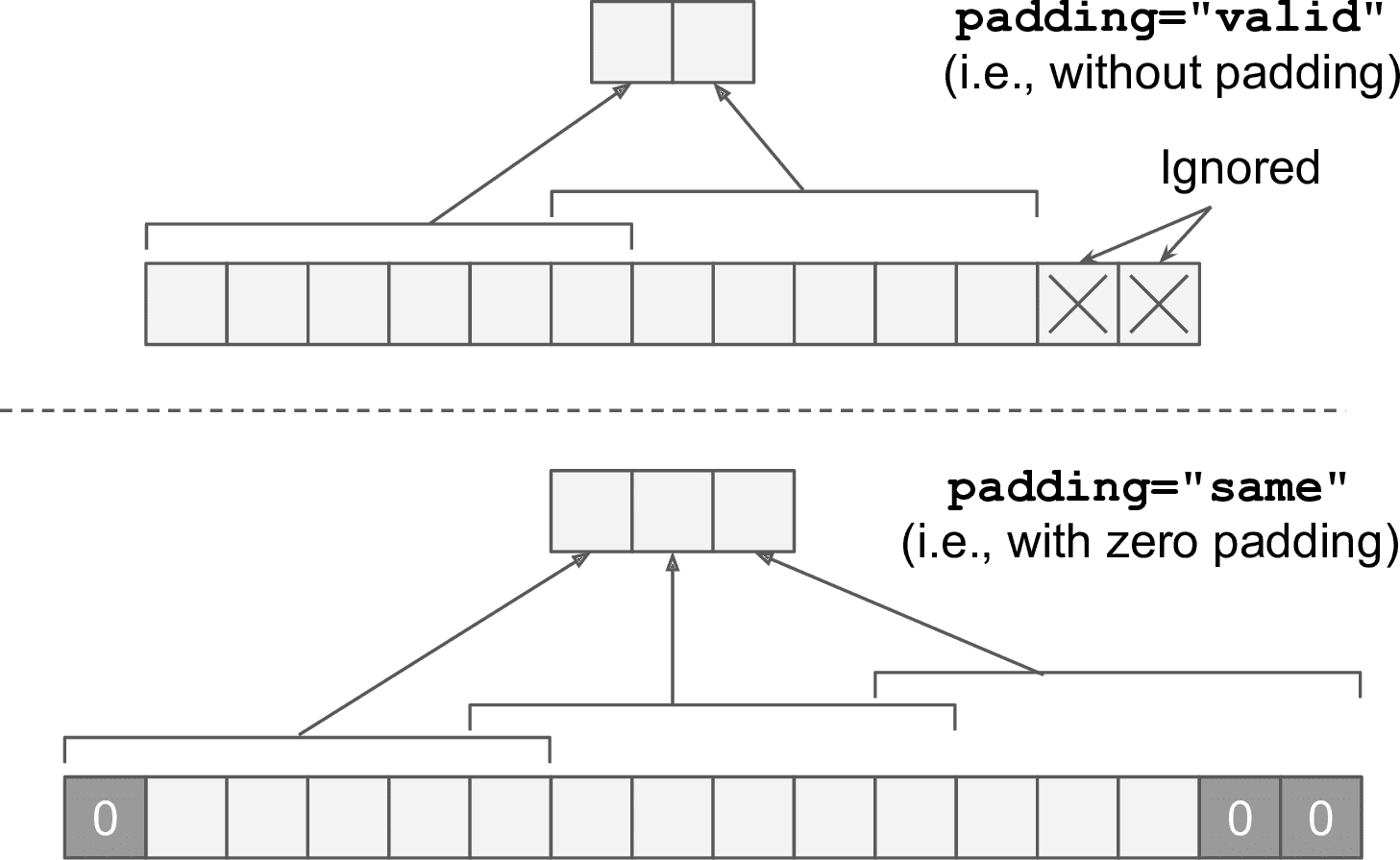圖 14-7 Padding="same” 或 “valid”(輸入寬度 13,過濾器寬度 6,步長 5)
這個例子中,我們手動定義了過濾器,但在真正的 CNN 中,一般將過濾器定義為可以訓練的變量,好讓神經網絡學習哪個過濾器的效果最好。使用`keras.layers.Conv2D`層:
```py
conv = keras.layers.Conv2D(filters=32, kernel_size=3, strides=1,
padding="same", activation="relu")
```
這段代碼創建了一個有 32 個過濾器的`Conv2D`層,每個過濾器的形狀是 3 × 3,步長為 1(水平垂直都是 1),和`"same"`填充,輸出使用 ReLU 激活函數。可以看到,卷積層的超參數不多:選擇過濾器的數量,過濾器的高和寬,步長和填充類型。和以前一樣,可以使用交叉驗證來找到合適的超參數值,但很耗時間。后面會討論常見的 CNN 架構,可以告訴你如何挑選超參數的值。
### 內存需求
CNN 的另一個問題是卷積層需要很高的內存。特別是在訓練時,因為反向傳播需要所有前向傳播的中間值。
比如,一個有 5 × 5 個過濾器的卷積層,輸出 200 個特征映射,大小為 150 × 100,步長為 1,零填充。如果如數是 150 × 100 的 RGB 圖片(三通道),則參數總數是(5 × 5 × 3 + 1) × 200 = 15200,加 1 是考慮偏置項。相對于全連接層,參數少很多了。但是 200 個特征映射,每個都包含 150 × 100 個神經元,每個神經元都需要計算 5 × 5 × 3 = 75 個輸入的權重和:總共是 2.25 億個浮點數乘法運算。雖然比全連接層少點,但也很耗費算力。另外,如果特征映射用的是 32 位浮點數,則卷積層輸出要占用 200 × 150 × 100 × 32 = 96 百萬比特(12MB)的內存。這僅僅是一個實例,如果訓練批次有 100 個實例,則要使用 1.2 GB 的內存。
在做推斷時(即,對新實例做預測),下一層計算完,前一層占用的內存就可以釋放掉內存,所以只需要兩個連續層的內存就夠了。但在訓練時,前向傳播期間的所有結果都要保存下來以為反向傳播使用,所以消耗的內存是所有層的內存占用總和。
> 提示:如果因為內存不夠發生訓練終端,可以降低批次大小。另外,可以使用步長降低緯度,或去掉幾層。或者,你可以使用 16 位浮點數,而不是 32 位浮點數。或者,可以將 CNN 分布在多臺設備上。
接下來,看看 CNN 的第二個組成部分:池化層。
## 池化層
明白卷積層的原理了,池化層就容易多了。池化層的目的是對輸入圖片做降采樣(即,收縮),以降低計算負載、內存消耗和參數的數量(降低過擬合)。
和卷積層一樣,池化層中的每個神經元也是之和前一層的感受野里的有限個神經元相連。和前面一樣,必須定義感受野的大小、步長和填充類型。但是,池化神經元沒有權重,它所要做的是使用聚合函數,比如最大或平均,對輸入做聚合。圖 14-8 展示了最為常用的最大池化層。在這個例子中,使用了一個 2 × 2 的池化核,步長為 2,沒有填充。只有感受野中的最大值才能進入下一層,其它的就丟棄了。例如,在圖 14-8 左下角的感受野中,輸入值是 1、5、3、2,所以只有最大值 5 進入了下一層。因為步長是 2,輸出圖的高度和寬度是輸入圖的一半(因為沒有用填充,向下圓整)。
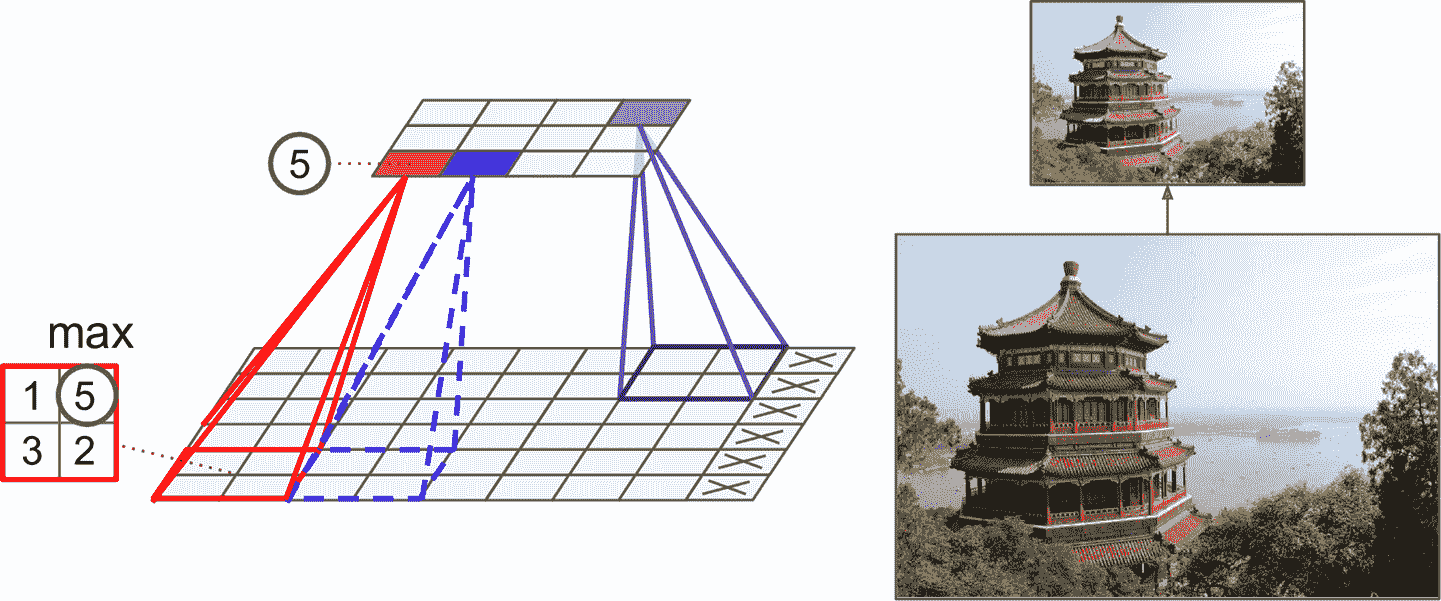圖 14-8 最大池化層(2 × 2 的池化核,步長為 2,沒有填充)
> 筆記:池化層通常獨立工作在每個通道上,所以輸出深度和輸入深度相同。
除了可以減少計算、內存消耗、參數數量,最大池化層還可以帶來對小偏移的不變性,見圖 14-9。假設亮像素比暗像素的值小,用 2 × 2 核、步長為 2 的最大池化層處理三張圖(A、B、C)。圖 B 和 C 的圖案與 A 相同,只是分別向右移動了一個和兩個像素。可以看到,A、B 經過池化層處理后的結果相同,這就是所謂的平移不變性。對于圖片 C,輸出有所不同:向右偏移了一個像素(但仍然有 50%沒變)。在 CNN 中每隔幾層就插入一個最大池化層,可以帶來更大程度的平移不變性。另外,最大池化層還能帶來一定程度的旋轉不變性和縮放不變性。當預測不需要考慮平移、旋轉和縮放時,比如分類任務,不變性可以有一定益處。
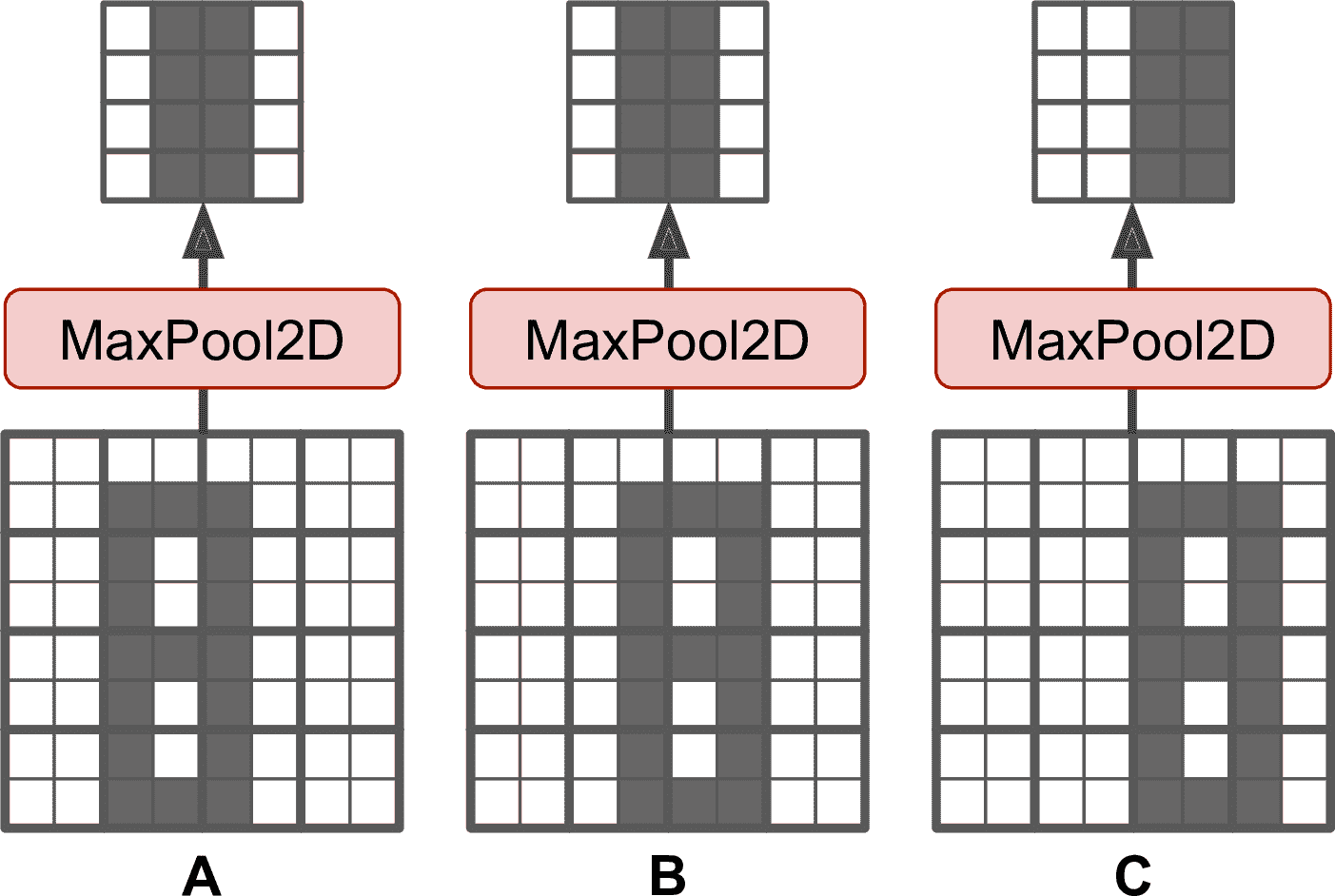圖 14-9 小平移不變性
但是,最大池化層也有缺點。首先,池化層破壞了信息:即使感受野的核是 2 × 2,步長是 2,輸出在兩個方向上都損失了一半,總共損失了 75%的信息。對于某些任務,不變性不可取。比如語義分割(將像素按照對象分類):如果輸入圖片向右平移了一個像素,輸出也應該向右平移一個降速。此時強調的就是等價:輸入發生小變化,則輸出也要有對應的小變化。
### TensorFlow 實現
用 TensorFlow 實現最大池化層很簡單。下面的代碼實現了最大池化層,核是 2 × 2。步長默認等于核的大小,所以步長是 2(水平和垂直步長都是 2)。默認使用`"valid"`填充:
```py
max_pool = keras.layers.MaxPool2D(pool_size=2)
```
要創建平均池化層,則使用`AvgPool2D`。平均池化層和最大池化層很相似,但計算的是感受野的平均值。平均池化層在過去很流行,但最近人們使用最大池化層更多,因為最大池化層的效果更好。初看很奇怪,因為計算平均值比最大值損失的信息要少。但是從反面看,最大值保留了最強特征,去除了無意義的特征,可以讓下一層獲得更清楚的信息。另外,最大池化層提供了更強的平移不變性,所需計算也更少。
池化層還可以沿著深度方向做計算。這可以讓 CNN 學習到不同特征的不變性。比如。CNN 可以學習多個過濾器,每個過濾器檢測一個相同的圖案的不同旋轉(比如手寫字,見圖 14-10),深度池化層可以使輸出相同。CNN 還能學習其它的不變性:厚度、明亮度、扭曲、顏色,等等。
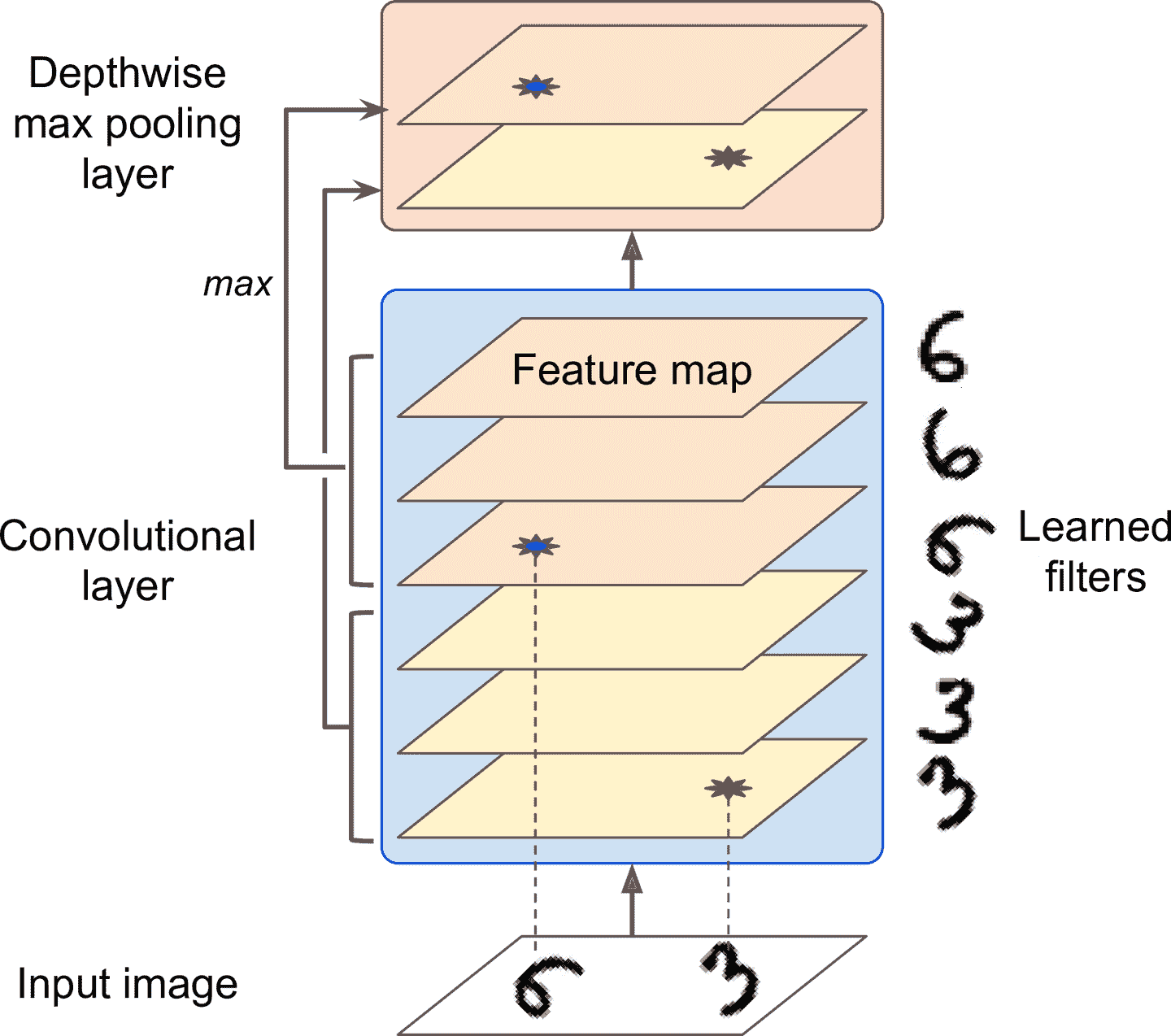圖 14-10 深度最大池化層可以讓 CNN 學習到多種不變性
Keras 沒有深度方向最大池化層,但 TensorFlow 的低級 API 有:使用`tf.nn.max_pool()`,指定核的大小、步長(4 元素的元組):元組的前三個值應該是 1,表明沿批次、高度、寬度的步長是 1;最后一個值,是深度方向的步長 —— 比如 3(深度步長必須可以整除輸入深度;如果前一個層有 20 個特征映射,步長 3 就不成):
```py
output = tf.nn.max_pool(images,
ksize=(1, 1, 1, 3),
strides=(1, 1, 1, 3),
padding="valid")
```
如果想將這個層添加到 Keras 模型中,可以將其包裝進`Lambda`層(或創建一個自定義 Keras 層):
```py
depth_pool = keras.layers.Lambda(
lambda X: tf.nn.max_pool(X, ksize=(1, 1, 1, 3), strides=(1, 1, 1, 3),
padding="valid"))
```
最后一中常見的池化層是全局平均池化層。它的原理非常不同:它計算整個特征映射的平均值(就像是平均池化層的核的大小和輸入的空間維度一樣)。這意味著,全局平均池化層對于每個實例的每個特征映射,只輸出一個值。雖然這么做對信息的破壞性很大,卻可以用來做輸出層,后面會看到例子。創建全局平均池化層的方法如下:
```py
global_avg_pool = keras.layers.GlobalAvgPool2D()
```
它等同于下面的`Lambda`層:
```py
global_avg_pool = keras.layers.Lambda(lambda X: tf.reduce_mean(X, axis=[1, 2]))
```
介紹完 CNN 的組件之后,來看看如何將它們組合起來。
## CNN 架構
CNN 的典型架構是將幾個卷積層疊起來(每個卷積層后面跟著一個 ReLU 層),然后再疊一個池化層,然后再疊幾個卷積層(+ReLU),接著再一個池化層,以此類推。圖片在流經神經網絡的過程中,變得越來越小,但得益于卷積層,卻變得越來越深(特征映射變多了),見圖 14-11。在 CNN 的頂部,還有一個常規的前饋神經網絡,由幾個全連接層(+ReLU)組成,最終層輸出預測(比如,一個輸出類型概率的 softmax 層)。
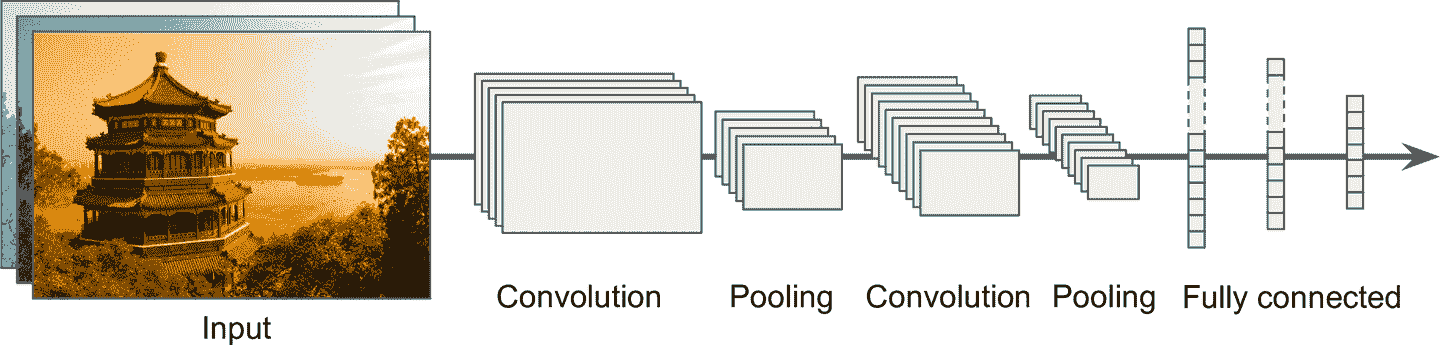圖 14-11 典型的 CNN 架構
> 提示:常犯的錯誤之一,是使用過大的卷積核。例如,要使用一個卷積層的核是 5 × 5,再加上兩個核為 3 × 3 的層:這樣參數不多,計算也不多,通常效果也更好。第一個卷積層是例外:可以有更大的卷積核(例如 5 × 5),步長為 2 或更大:這樣可以降低圖片的空間維度,也沒有損失很多信息。
下面的例子用一個簡單的 CNN 來處理 Fashion MNIST 數據集(第 10 章介紹過):
```py
model = keras.models.Sequential([
keras.layers.Conv2D(64, 7, activation="relu", padding="same",
input_shape=[28, 28, 1]),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(256, 3, activation="relu", padding="same"),
keras.layers.Conv2D(256, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(64, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(10, activation="softmax")
])
```
逐行看下代碼:
* 第一層使用了 64 個相當大的過濾器(7 × 7),但沒有用步長,因為輸入圖片不大。還設置了`input_shape=[28, 28, 1]`,因為圖片是 28 × 28 像素的,且是單通道(即,灰度)。
* 接著,使用了一個最大池化層,核大小為 2.
* 接著,重復做兩次同樣的結構:兩個卷積層,跟著一個最大池化層。對于大圖片,這個結構可以重復更多次(重復次數是超參數)。
* 要注意,隨著 CNN 向著輸出層的靠近,過濾器的數量一直在提高(一開始是 64,然后是 128,然后是 256):這是因為低級特征的數量通常不多(比如,小圓圈或水平線),但將其組合成為高級特征的方式很多。通常的做法是在每個池化層之后,將過濾器的數量翻倍:因為池化層對空間維度除以了 2,因此可以將特征映射的數量翻倍,且不用擔心參數數量、內存消耗、算力的增長。
* 然后是全連接網絡,由兩個隱藏緊密層和一個緊密輸出層組成。要注意,必須要打平輸入,因為緊密層的每個實例必須是 1D 數組。還加入了兩個 dropout 層,丟失率為 50%,以降低過擬合。
這個 CNN 可以在測試集上達到 92%的準確率。雖然不是頂尖水平,但也相當好了,效果比第 10 章用的方法好得多。
過去幾年,這個基礎架構的變體發展迅猛,取得了驚人的進步。衡量進步的一個指標是 ILSVRC [ImageNet challenge](https://links.jianshu.com/go?to=http%3A%2F%2Fimage-net.org%2F)的誤差率。在六年期間,這項賽事的前五誤差率從 26%降低到了 2.3%。前五誤差率的意思是,預測結果的前 5 個最高概率的圖片不包含正確結果的比例。測試圖片相當大(256 個像素),有 1000 個類,一些圖的差別很細微(比如區分 120 種狗的品種)。學習 ImageNet 冠軍代碼是學習 CNN 的好方法。
我們先看看經典的 LeNet-5 架構(1998),然后看看三個 ILSVRC 競賽的冠軍:AlexNet(2012)、GoogLeNet(2014)、ResNet(2015)。
### LeNet-5
[LeNet-5](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Flenet5) 也許是最廣為人知的 CNN 架構。前面提到過,它是由 Yann LeCun 在 1998 年創造出來的,被廣泛用于手寫字識別(MNIST)。它的結構如下:
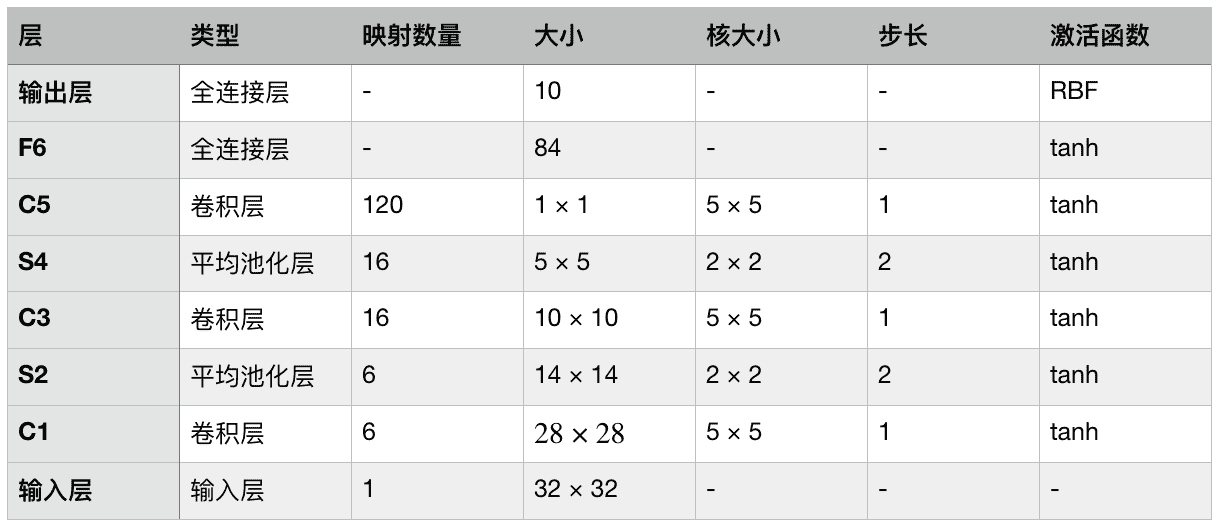表 14-1 LeNet-5 架構
有一些點需要注意:
* MNIST 圖片是 28 × 28 像素的,但在輸入給神經網絡之前,做了零填充,成為 32 × 32 像素,并做了歸一化。后面的層不用使用任何填充,這就是為什么當圖片在網絡中傳播時,圖片大小持續縮小。
* 平均池化層比一般的稍微復雜點:每個神經元計算輸入的平均值,然后將記過乘以一個可學習的系數(每個映射一個系數),在加上一個可學習的偏置項(也是每個映射一個),最后使用激活函數。
* C3 層映射中的大部分神經元,只與 S2 層映射三個或四個神經元全連接(而不是 6 個)。
* 輸出層有點特殊:不是計算輸入和權重矢量的矩陣積,而是每個神經元輸出輸入矢量和權重矢量的歐氏距離的平方。每個輸出衡量圖片屬于每個數字類的概率程度。這里適用交叉熵損失函數,因為對錯誤預測懲罰更多,可以產生更大的梯度,收斂更快。
Yann LeCun 的 [網站](https://links.jianshu.com/go?to=http%3A%2F%2Fyann.lecun.com%2Fexdb%2Flenet%2Findex.html)展示了 LeNet-5 做數字分類的例子。
### AlexNet
[AlexNet CNN 架構](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2F80)以極大優勢,贏得了 2012 ImageNet ILSVRC 冠軍:它的 Top-5 誤差率達到了 17%,第二名只有 26%!它是由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 發明的。AlexNet 和 LeNet-5 很相似,只是更大更深,是首個將卷積層堆疊起來的網絡,而不是在每個卷積層上再加一個池化層。表 14-2 展示了其架構:
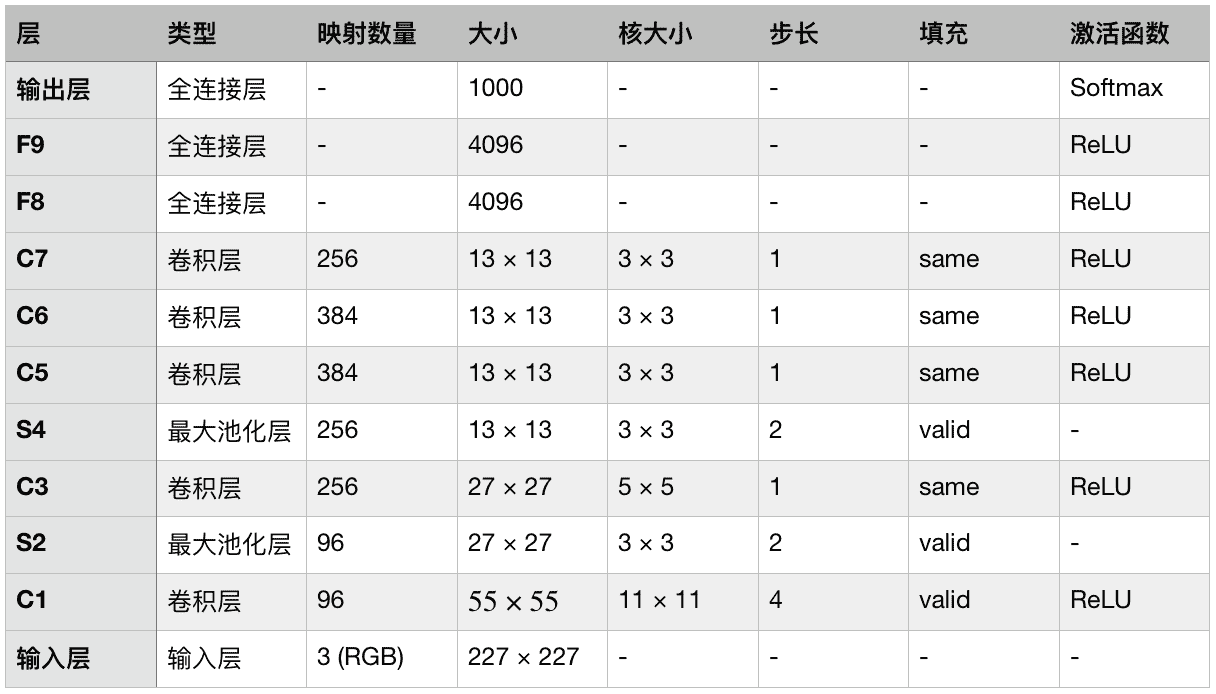表 14-2 AlexNet 架構
為了降低過擬合,作者使用了兩種正則方法。首先,F8 和 F9 層使用了 dropout,丟棄率為 50%。其次,他們通過隨機距離偏移訓練圖片、水平翻轉、改變亮度,做了數據增強。
> 數據增強
>
> 數據增強是通過生成許多訓練實例的真實變種,來人為增大訓練集。因為可以降低過擬合,成為了一種正則化方法。生成出來的實例越真實越好:最理想的情況,人們無法區分增強圖片是原生的還是增強過的。簡單的添加白噪聲沒有用,增強修改要是可以學習的(白噪聲不可學習)。
>
> 例如,可以輕微偏移、旋轉、縮放原生圖,再添加到訓練集中(見圖 14-12)。這么做可以使模型對位置、方向和物體在圖中的大小,有更高的容忍度。如果想讓模型對不同光度有容忍度,可以生成對比度不同的照片。通常,還可以水平翻轉圖片(文字不成、不對稱物體也不成)。通過這些變換,可以極大的增大訓練集。
>
> 圖 14-12 從原生圖生成新的訓練實例
AlexNet 還在 C1 和 C3 層的 ReLU 之后,使用了強大的歸一化方法,稱為局部響應歸一化(LRN):激活最強的神經元抑制了相同位置的相鄰特征映射的神經元(這樣的競爭性激活也在生物神經元上觀察到了)。這么做可以讓不同的特征映射專業化,特征范圍更廣,提升泛化能力。等式 14-2 展示了如何使用 LRN。
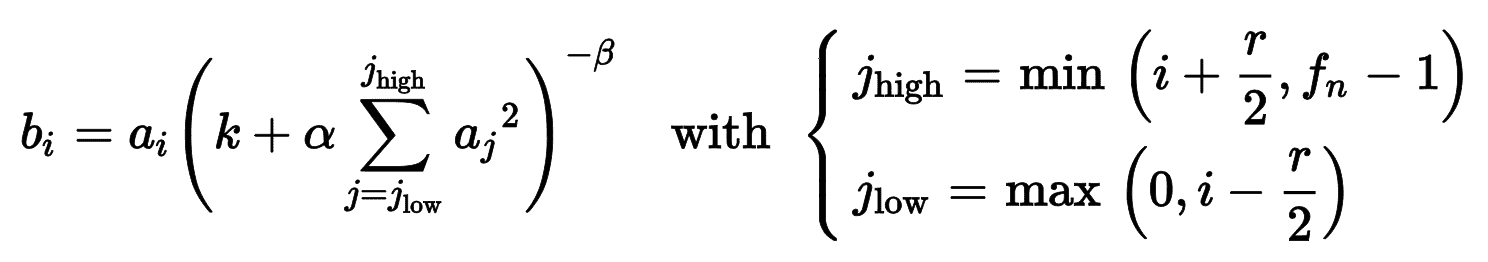等式 14-2 局部響應歸一化(LRN)
這這個等式中:
* b<sub>I</sub>是特征映射`i`的行`u`列`v`的神經元的歸一化輸出(注意等始中沒有出現行`u`列`v`)。
* a<sub>I</sub>是 ReLu 之后,歸一化之前的激活函數。
* k、α、β和 r 是超參。k 是偏置項,r 是深度半徑。
* f<sub>n</sub>是特征映射的數量。
例如,如果 r=2,且神經元有強激活,能抑制其他相鄰上下特征映射的神經元的激活。
在 AlexNet 中,超參數是這么設置的:r = 2,α = 0.00002,β = 0.75,k = 1。可以通過`tf.nn.local_response_normalization()`函數實現,要想用在 Keras 模型中,可以包裝進`Lambda`層。
AlexNet 的一個變體是[*ZF Net*](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fzfnet),是由 Matthew Zeiler 和 Rob Fergus 發明的,贏得了 2013 年的 ILSVRC。它本質上是對 AlexNet 做了一些超參數的調節(特征映射數、核大小,步長,等等)。
### GoogLeNet
[GoogLeNet 架構](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2F81)是 Google Research 的 Christian Szegedy 及其同事發明的,贏得了 ILSVRC 2014 冠軍,top-5 誤差率降低到了 7%以內。能取得這么大的進步,很大的原因是它的網絡比之前的 CNN 更深(見圖 14-14)。這歸功于被稱為創始模塊(inception module)的子網絡,它可以讓 GoogLeNet 可以用更高的效率使用參數:實際上,GoogLeNet 的參數量比 AlexNet 小 10 倍(大約是 600 萬,而不是 AlexNet 的 6000 萬)。
圖 14-13 展示了一個創始模塊的架構。“3 × 3 + 1(S)”的意思是層使用的核是 3 × 3,步長是 1,`"same"`填充。先復制輸入信號,然后輸入給 4 個不同的層。所有卷積層使用 ReLU 激活函數。注意,第二套卷積層使用了不同的核大小(1 × 1、3 × 3、5 × 5),可以讓其捕捉不同程度的圖案。還有,每個單一層的步長都是 1,都是零填充(最大池化層也同樣),因此它們的輸出和輸入有同樣的高度和寬度。這可以讓所有輸出在最終深度連接層,可以沿著深度方向連起來(即,將四套卷積層的所有特征映射堆疊起來)。這個連接層可以使用用`tf.concat()`實現,其`axis=3`(深度方向的軸)。
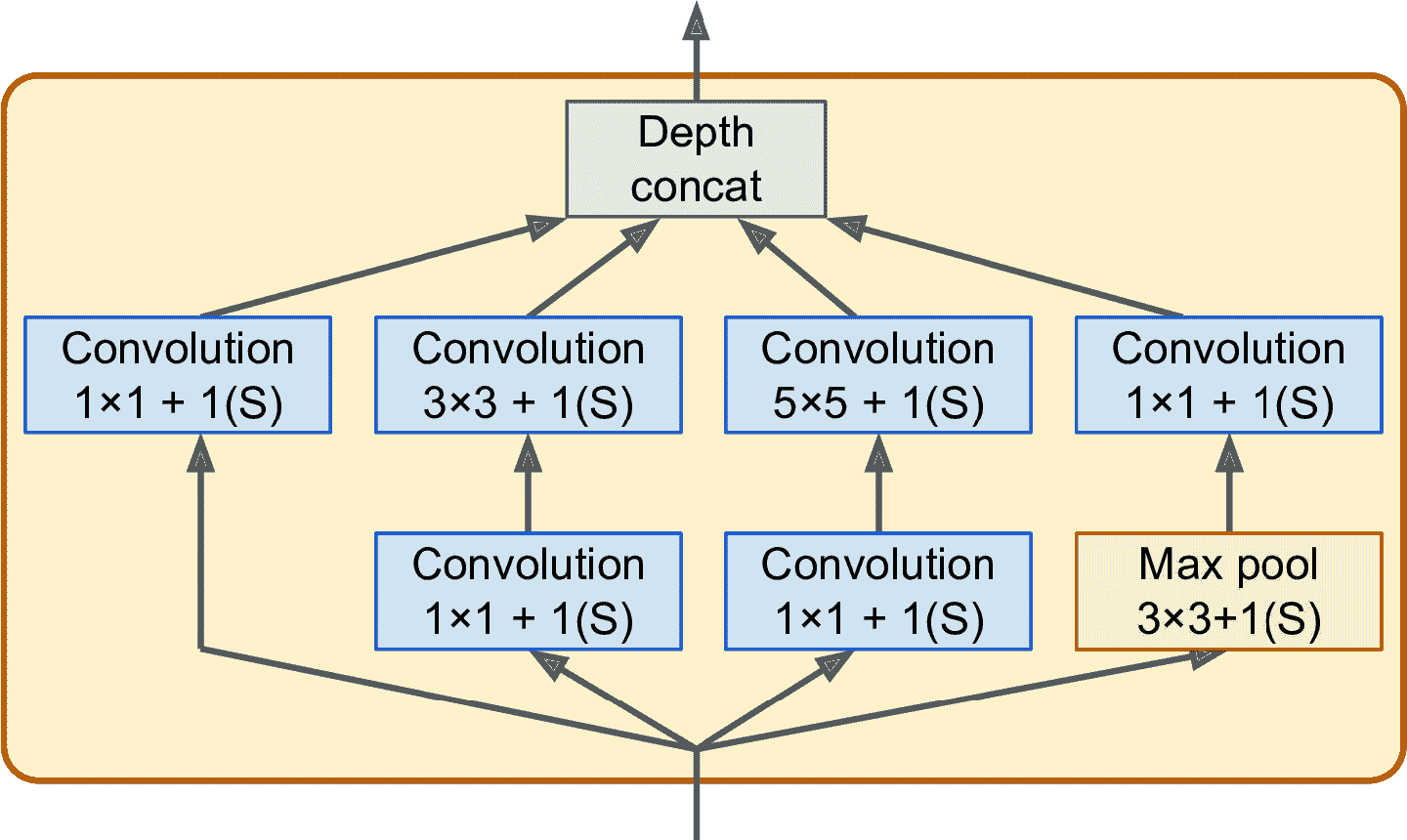圖 14-13 創始模塊
為什么創始模塊有核為 1 × 1 的卷積層呢?這些層捕捉不到任何圖案,因為只能觀察一個像素?事實上,這些層有三個目的:
* 盡管不能捕捉空間圖案,但可以捕捉沿深度方向的圖案。
* 這些曾輸出的特征映射比輸入少,是作為瓶頸層來使用的,意味它們可以降低維度。這樣可以減少計算和參數量、加快訓練,提高泛化能力。
* 每一對卷積層([1 × 1, 3 × 3] 和 [1 × 1, 5 × 5])就像一個強大的單一卷積層,可以捕捉到更復雜的圖案。事實上,這對卷積層可以掃過兩層神經網絡。
總而言之,可以將整個創始模塊當做一個卷積層,可以輸出捕捉到不同程度、更多復雜圖案的特征映射。
> 警告:每個卷積層的卷積核的數量是一個超參數。但是,這意味著每添加一個創始層,就多了 6 個超參數。
來看下 GoogLeNet 的架構(見圖 14-14)。每個卷積層、每個池化層輸出的特征映射的數量,展示在核大小的前面。因為比較深,只好擺成三列。GoogLeNet 實際是一列,一共包括九個創始模塊(帶有陀螺標志)。創始模塊中的六個數表示模塊中的每個卷積層輸出的特征映射數(和圖 14-13 的順序相同)。注意所有卷積層使用 ReLU 激活函數。
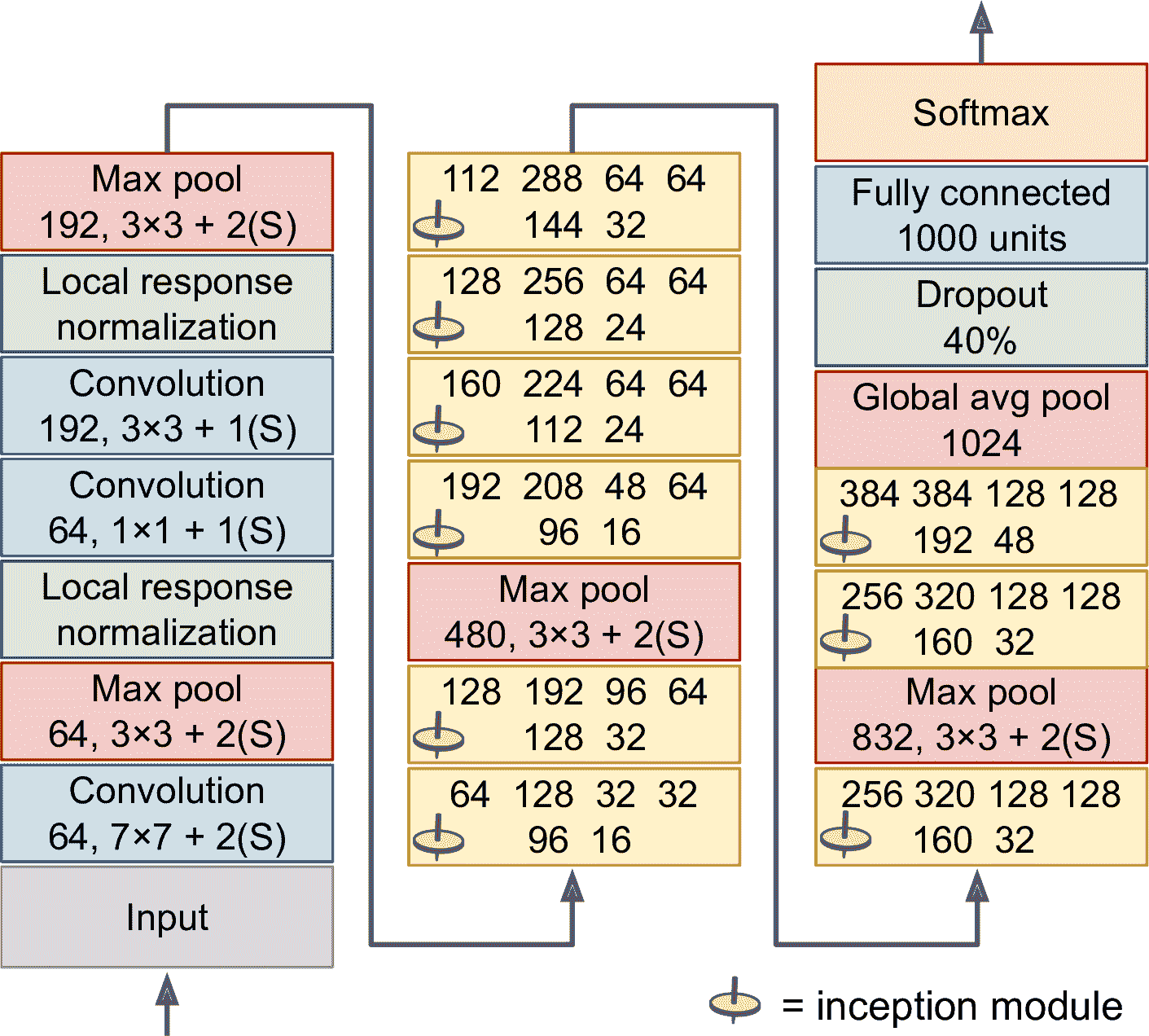圖 14-14 GoogLeNet 的架構
這個網絡的結構如下:
* 前兩個層將圖片的高和寬除以了 4(所以面積除以了 16),以減少計算。第一層使用的核很大,可以保留大部分信息。
* 接下來,局部響應歸一化層可以保證前面的層可以學到許多特征。
* 后面跟著兩個卷積層,前面一層作為瓶頸層。可以將這兩層作為一個卷積層。
* 然后,又是一個局部響應歸一化層。
* 接著,最大池化層將圖片的高度和寬度除以 2,以加快計算。
* 然后,是九個創始模塊,中間插入了兩個最大池化層,用來降維提速。
* 接著,全局平均池化層輸出每個特征映射的平均值:可以丟棄任何留下的空間信息,可以這么做是因為此時留下的空間信息也不多了。事實上 GoogLeNet 的輸入圖片一般是 224 × 224 像素的,經過 5 個最大池化層后,每個池化層將高和寬除以 2,特征映射降為 7 × 7。另外,這是一個分類任務,不是定位任務,所以對象在哪無所謂。得益于該層降低了維度,就不用的網絡的頂部(像 AlexNet 那樣)加幾個全連接層了,這么做可以極大減少參數數量,降低過擬合。
* 最后幾層很明白:dropout 層用來正則,全連接層(因為有 1000 個類,所以有 1000 個單元)和 softmax 激活函數用來產生估計類的概率。
架構圖經過輕微的簡化:原始 GoogLeNet 架構還包括兩個輔助的分類器,位于第三和第六創始模塊的上方。它們都是由一個平均池化層、一個卷積層、兩個全連接層和一個 softmax 激活層組成。在訓練中,它們的損失(縮減 70%)被添加到總損失中。它們的目標是對抗梯度消失,對網絡做正則。但是,后來的研究顯示它們的作用很小。
Google 的研究者后來又提出了幾個 GoogLeNet 的變體,包括 Inception-v3 和 Inception-v4,使用的創始模塊略微不同,性能更好。
### VGGNet
ILSVRC 2014 年的亞軍是[VGGNet](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2F83),作者是來自牛津大學 Visual Geometry Group(VGC)的 Karen Simonyan 和 Andrew Zisserman。VGGNet 的架構簡單而經典,2 或 3 個卷積層和 1 個池化層,然后又是 2 或 3 個卷積層和 1 個池化層,以此類推(總共達到 16 或 19 個卷積層)。最終加上一個有兩個隱藏層和輸出層的緊密網絡。VGGNet 只用 3 × 3 的過濾器,但數量很多。
### ResNet
何凱明使用[*Residual Network* (或 *ResNet*)](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2F82)贏得了 ILSVRC 2015 的冠軍,top-5 誤差率降低到了 3.6%以下。ResNet 的使用了極深的卷積網絡,共 152 層(其它的變體有 1450 或 152 層)。反映了一個總體趨勢:模型變得越來越深,參數越來越少。訓練這樣的深度網絡的方法是使用跳連接(也被稱為快捷連接):輸入信號添加到更高層的輸出上。
當訓練神經網絡時,目標是使網絡可以對目標函數`h(x)`建模。如果將輸入`x`添加給網絡的輸出(即,添加一個跳連接),則網絡就要對`f(x) = h(x) – x`建模,而不是`h(x)`。這被稱為殘差學習(見圖 14-15)。
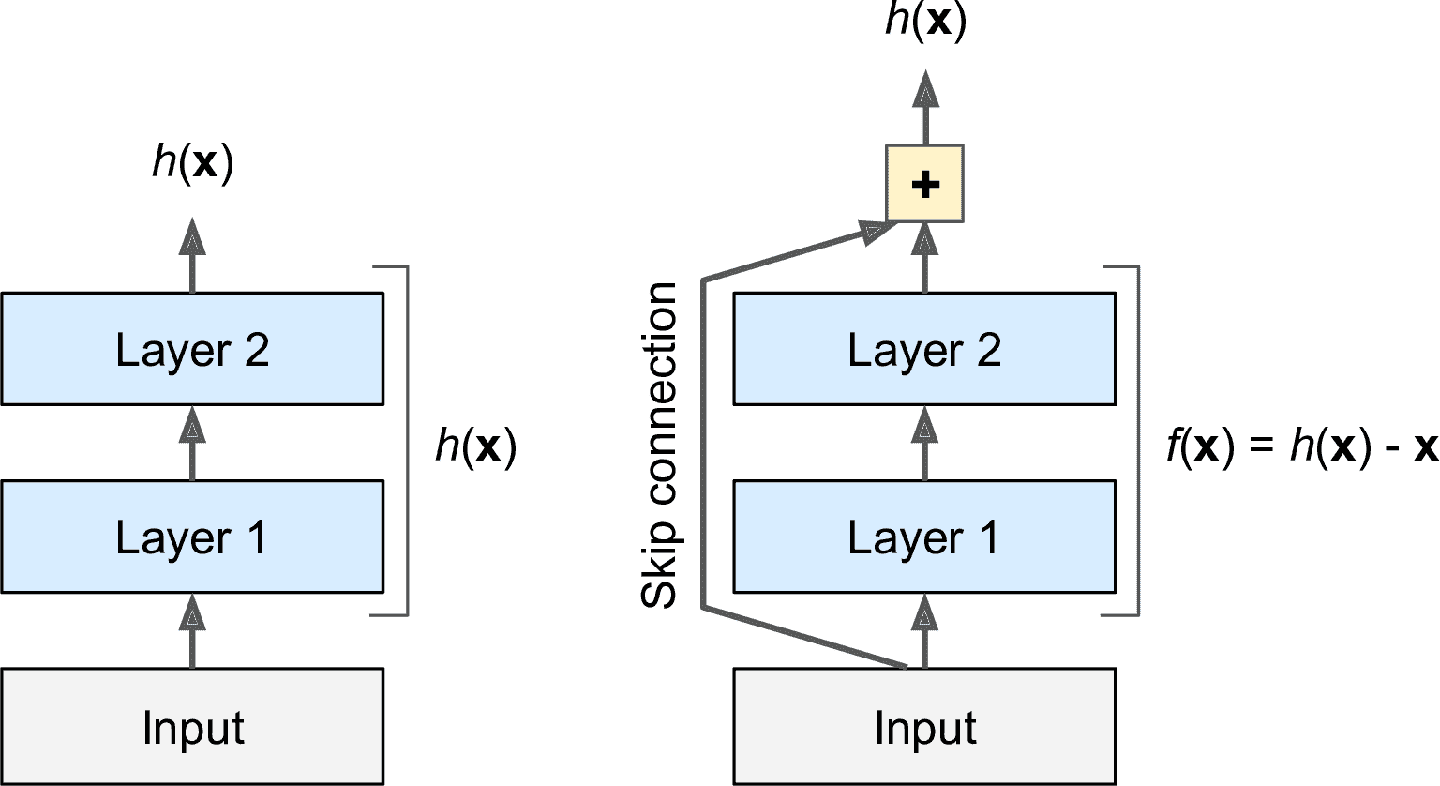圖 14-15 殘差學習
初始化一個常規神經網絡時,它的權重接近于零,所以輸出值也接近于零。如果添加跳連接,網絡就會輸出一個輸入的復制;換句話說,網絡一開始是對恒等函數建模。如果目標函數與恒等函數很接近(通常會如此),就能極大的加快訓練。
另外,如果添加多個跳連接,就算有的層還沒學習,網絡也能正常運作(見圖 14-16)。多虧了跳連接,信號可以在整個網絡中流動。深度殘差網絡,可以被當做殘差單元(RU)的堆疊,其中每個殘差單元是一個有跳連接的小神經網絡。
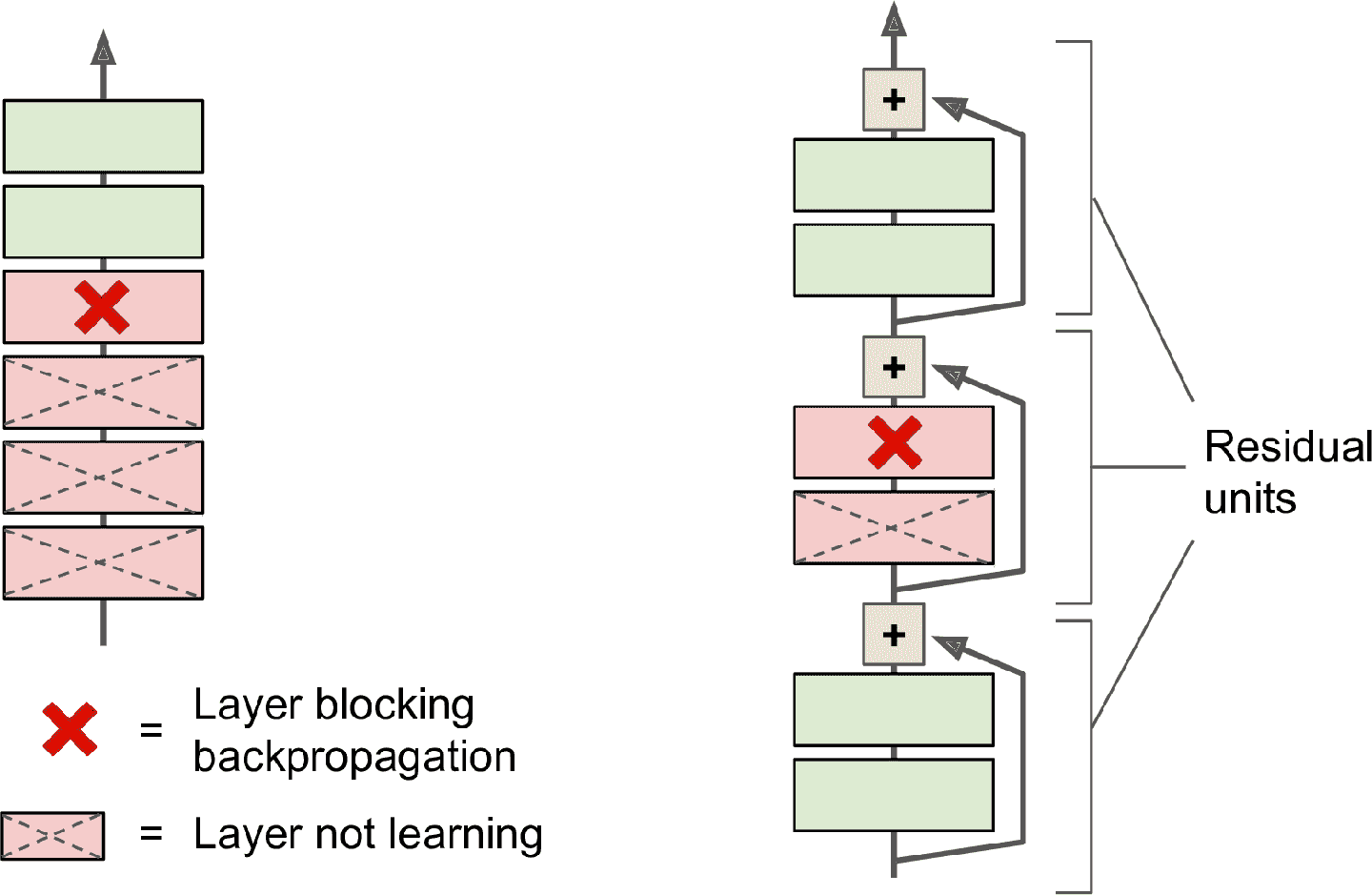圖 14-16 常規神經網絡(左)和深度殘差網絡(右)
來看看 ResNet 的架構(見圖 14-17)。特別簡單。開頭和結尾都很像 GoogLeNet(只是沒有的 dropout 層),中間是非常深的殘差單元的堆砌。每個殘差單元由兩個卷積層(沒有池化層!)組成,有批歸一化和 ReLU 激活,使用 3 × 3 的核,保留空間維度(步長等于 1,零填充)。
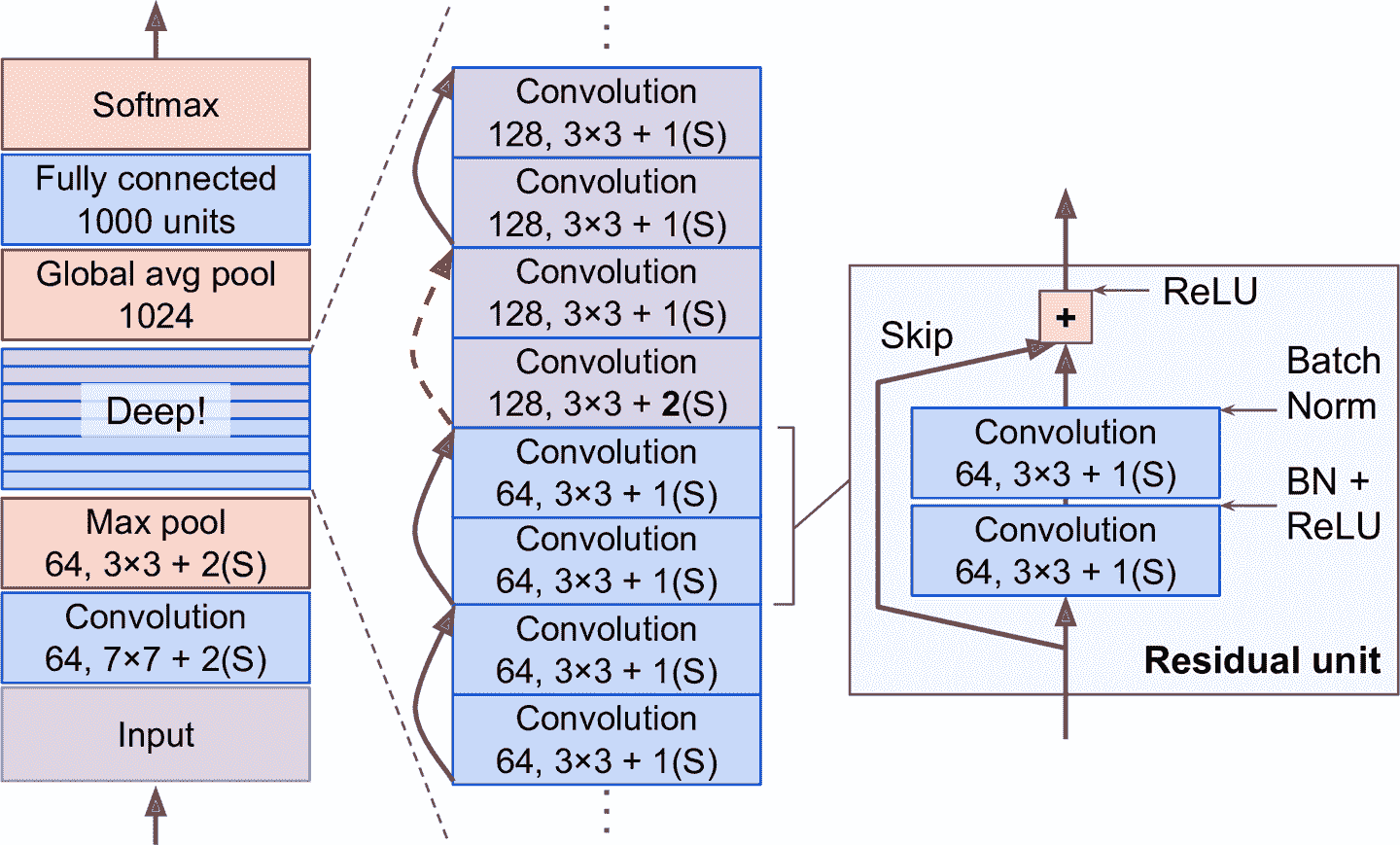圖 14-17 ResNet 架構
注意到,每經過幾個殘差單元,特征映射的數量就會翻倍,同時高度和寬度都減半()卷積層的步長為 2。發生這種情況時,因為形狀不同(見圖 14-17 中虛線的跳連接),輸入不能直接添加到殘差單元的輸出上。要解決這個問題,輸入要經過一個 1 × 1 的卷積層,步長為 2,特征映射數不變(見圖 14-18)。
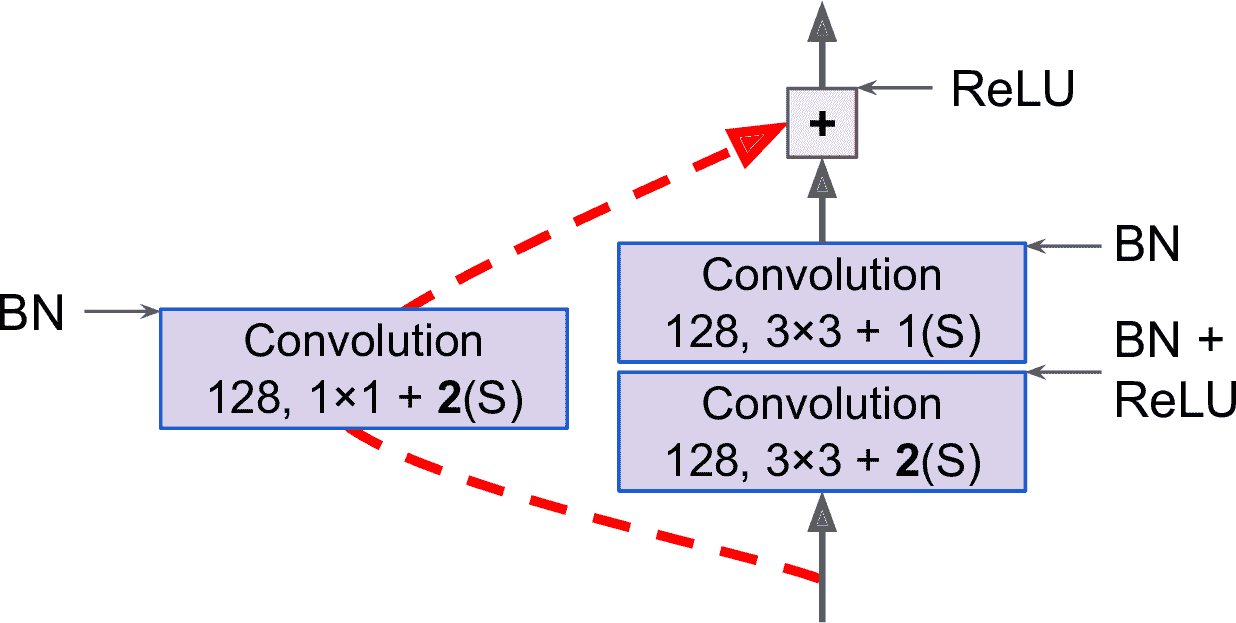圖 14-18 改變特征映射大小和深度時的跳連接
ResNet-34 是有 34 個層(只是計數了卷積層和全連接層)的 ResNet,有 3 個輸出 64 個特征映射的殘差單元,4 個輸出 128 個特征映射的殘差單元,6 個輸出 256 個特征映射的殘差單元,3 個輸出 512 個特征映射的殘差單元。本章后面會實現這個網絡。
ResNet 通常比這個架構要深,比如 ResNet-152,使用了不同的殘差單元。不是用 3 × 3 的輸出 256 個特征映射的卷積層,而是用三個卷積層:第一是 1 × 1 的卷積層,只有 64 個特征映射(少 4 倍),作為瓶頸層使用;然后是 1 × 1 的卷積層,有 64 個特征映射;最后是另一個 1 × 1 的卷積層,有 256 個特征映射,恢復原始深度。ResNet-152 含有 3 個這樣輸出 256 個映射的殘差單元,8 個輸出 512 個映射的殘差單元,36 個輸出 1024 個映射的殘差單元,最后是 3 個輸出 2048 個映射的殘差單元。
> 筆記:Google 的[Inception-v4](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2F84)融合了 GoogLeNet 和 ResNet,使 ImageNet 的 top-5 誤差率降低到接近 3%。
### Xception
另一個 GoogLeNet 架構的變體是[Xception](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fxception)(Xception 的意思是極限創始,Extreme Inception)。它是由 Fran?ois Chollet(Keras 的作者)在 2016 年提出的,Xception 在大型視覺任務(3.5 億張圖、1.7 萬個類)上超越了 Inception-v3。和 Inception-v4 很像,Xception 融合了 GoogLeNet 和 ResNet,但將創始模塊替換成了一個特殊類型的層,稱為深度可分卷積層(或簡稱為可分卷積層)。深度可分卷積層在以前的 CNN 中出現過,但不像 Xception 這樣處于核心。常規卷積層使用過濾器同時獲取空間圖案(比如,橢圓)和交叉通道圖案(比如,嘴+鼻子+眼睛=臉),可分卷積層的假設是空間圖案和交叉通道圖案可以分別建模(見圖 14-19)。因此,可分卷積層包括兩部分:第一個部分對于每個輸入特征映射使用單空間過濾器,第二個部分只針對交叉通道圖案 —— 就是一個過濾器為 1 × 1 的常規卷積層。
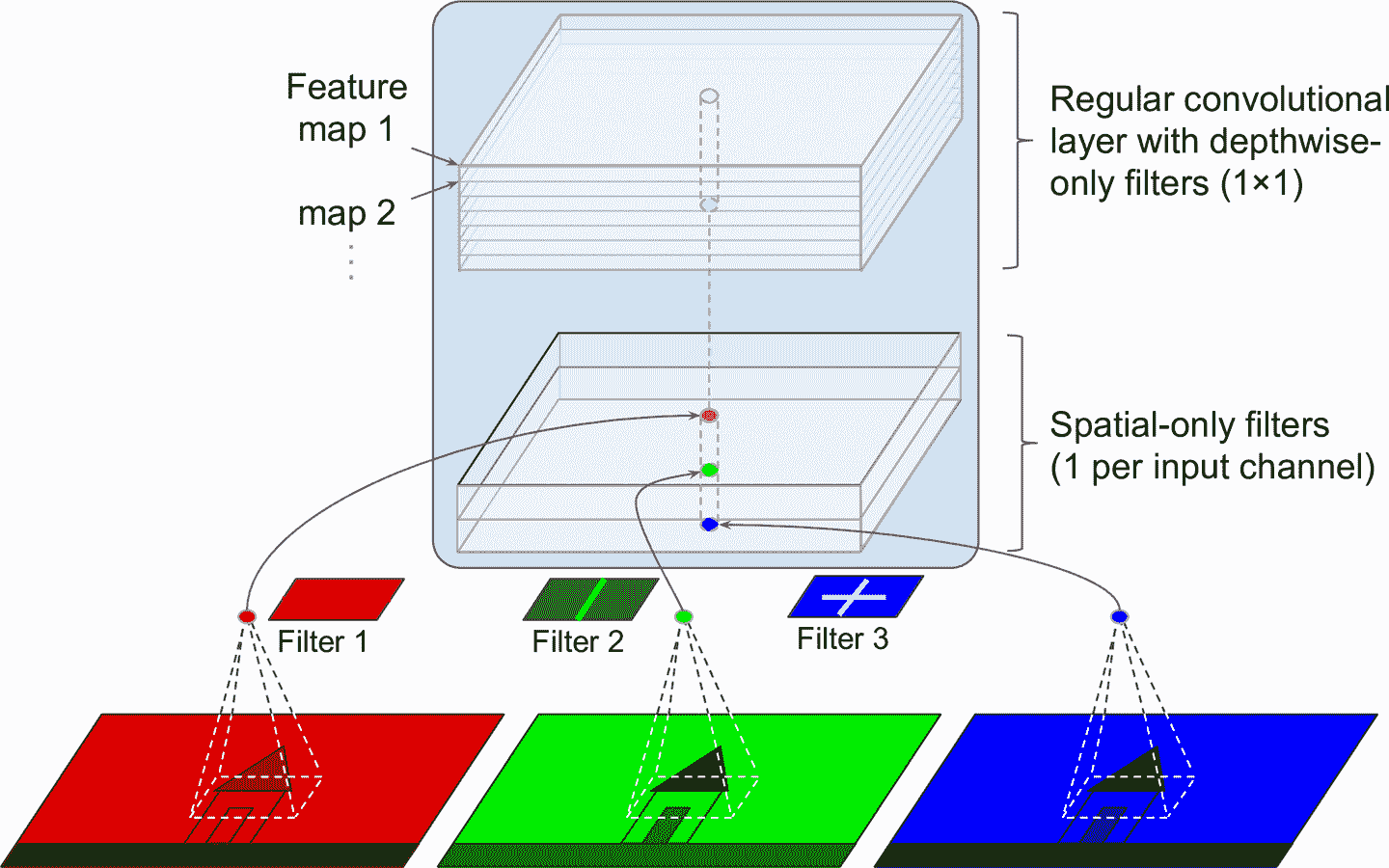圖 14-19 深度可分卷積層
因為可分卷積層對每個輸入通道只有一個空間過濾器,要避免在通道不多的層之后使用可分卷積層,比如輸入層(這就是圖 14-19 要展示的)。出于這個原因,Xception 架構一開始有 2 個常規卷積層,但剩下的架構都使用可分卷積層(共 34 個),加上一些最大池化層和常規的末端層(全局平均池化層和緊密輸出層)。
為什么 Xception 是 GoogLeNet 的變體呢,因為它并沒有創始模塊?正像前面討論的,創始模塊含有過濾器為 1 × 1 的卷積層:只針對交叉通道圖案。但是,它們上面的常規卷積層既針對空間、也針對交叉通道圖案。所以可以將創始模塊作為常規卷積層和可分卷積層的中間狀態。在實際中,可分卷積層表現更好。
> 提示:相比于常規卷積層,可分卷積層使用的參數、內存、算力更少,性能也更好,所以應默認使用后者(除了通道不多的層)。
ILSVRC 2016 的冠軍是香港中文大學的 CUImage 團隊。他們結合使用了多種不同的技術,包括復雜的對象識別系統,稱為[GBD-Net](https://links.jianshu.com/go?to=https%3A%2F%2Farxiv.org%2Fabs%2F1610.02579),top-5 誤差率達到 3%以下。盡管結果很經驗,但方案相對于 ResNet 過于復雜。另外,一年后,另一個簡單得多的架構取得了更好的結果。
### SENet
ILSVRC 2017 年的冠軍是擠壓-激活網絡([Squeeze-and-Excitation Network (SENet)](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fsenet))。這個架構拓展了之前的創始模塊和 ResNet,提高了性能。SENet 的 top-5 誤差率達到了驚人的 2.25%。經過拓展之后的版本分別稱為 SE-創始模塊和 SE-ResNet。性能提升來自于 SENet 在原始架構的每個單元(比如創始模塊或殘差單元)上添加了一個小的神經網絡,稱為 SE 塊,見圖 14-20。
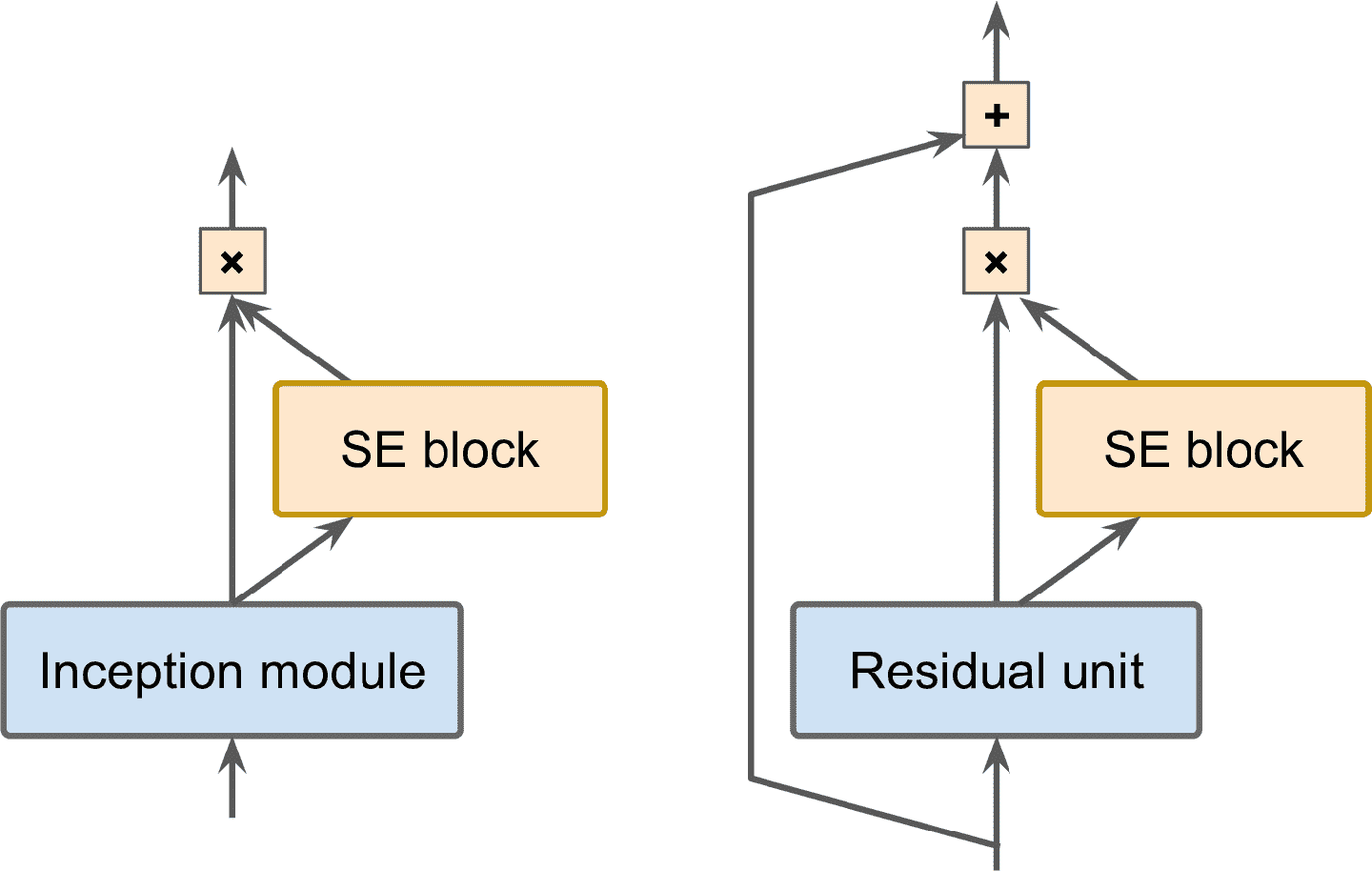圖 14-20 SE-創始模塊(左)和 SE-ResNet(右)
SE 分析了單元輸出,只針對深度方向,它能學習到哪些特征總是一起活躍的。然后根據這個信息,重新調整特征映射,見圖 14-21。例如,SE 可以學習到嘴、鼻子、眼睛經常同時出現在圖片中:如果你看見了罪和鼻子,通常是期待看見眼睛。所以,如果 SE 塊發向嘴和鼻子的特征映射有強激活,但眼睛的特征映射沒有強激活,就會提升眼睛的特征映射(更準確的,會降低無關的特征映射)。如果眼睛和其它東西搞混了,特征映射重調可以解決模糊性。
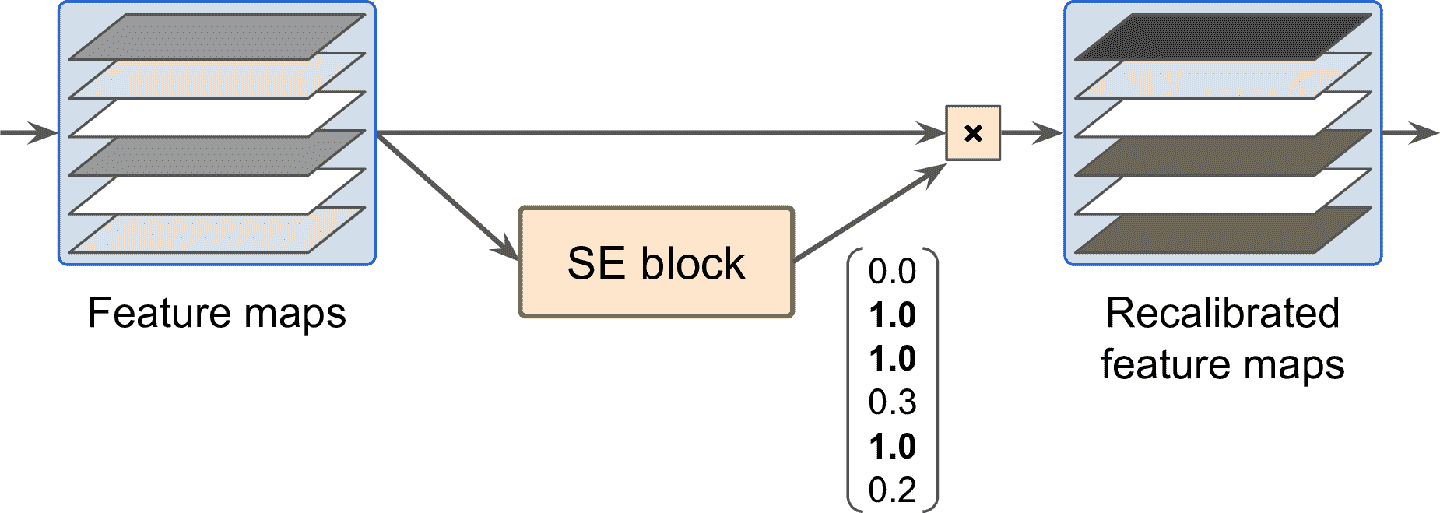圖 14-21 SE 快做特征重調
SE 塊由三層組成:一個全局平均池化層、一個使用 ReLU 的隱含緊密層、一個使用 sigmoid 的緊密輸出層(見圖 14-22)。
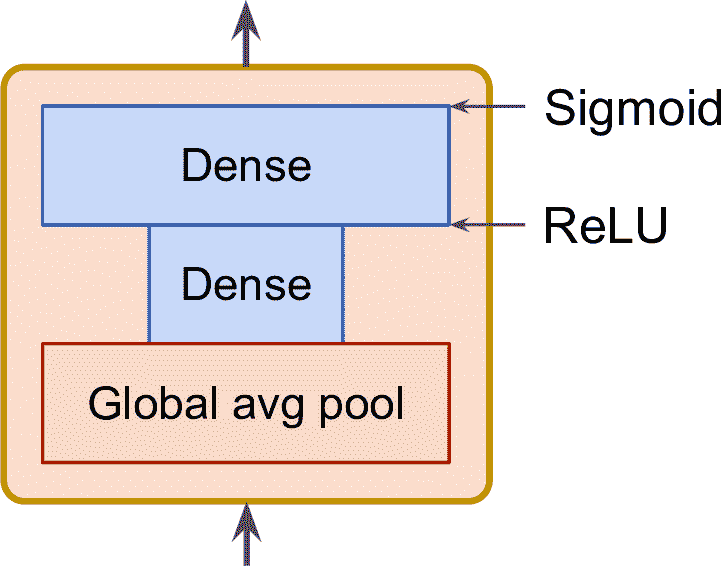圖 14-22 SE 塊的結構
和之前一樣,全局平均池化層計算每個特征映射的平均激活:例如,如果它的輸入包括 256 個特征映射,就會輸出 256 個數,表示對每個過濾器的整體響應水平。下一個層是“擠壓”步驟:這個層的神經元數遠小于 256,通常是小于特征映射數的 16 倍(比如 16 個神經元)—— 因此 256 個數被壓縮金小矢量中(16 維)。這是特征響應的地位矢量表征(即,嵌入)。這一步作為瓶頸,能讓 SE 塊強行學習特征組合的通用表征(第 17 章會再次接觸這個原理)。最后,輸出層使用這個嵌入,輸出一個重調矢量,每個特征映射(比如,256)包含一個數,都位于 0 和 1 之間。然后,特征映射乘以這個重調矢量,所以無關特征(其重調分數小)就被弱化了,就剩下相關特征(重調分數接近于 1)了。
## 用 Karas 實現 ResNet-34 CNN
目前為止介紹的大多數 CNN 架構的實現并不難(但經常需要加載預訓練網絡)。接下來用 Keras 實現 ResNet-34。首先,創建`ResidualUnit`層:
```py
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation="relu", **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
keras.layers.Conv2D(filters, 3, strides=strides,
padding="same", use_bias=False),
keras.layers.BatchNormalization(),
self.activation,
keras.layers.Conv2D(filters, 3, strides=1,
padding="same", use_bias=False),
keras.layers.BatchNormalization()]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
keras.layers.Conv2D(filters, 1, strides=strides,
padding="same", use_bias=False),
keras.layers.BatchNormalization()]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)
```
可以看到,這段代碼和圖 14-18 很接近。在構造器中,創建了所有需要的層:主要的層位于圖中右側,跳躍層位于左側(只有當步長大于 1 時需要)。在`call()`方法中,我們讓輸入經過主層和跳躍層,然后將輸出相加,再應用激活函數。
然后,使用`Sequential`模型搭建 ResNet-34,ResNet-34 就是一連串層的組合(將每個殘差單元作為一個單一層):
```py
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(64, 7, strides=2, input_shape=[224, 224, 3],
padding="same", use_bias=False))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("relu"))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same"))
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation="softmax"))
```
這段代碼中唯一麻煩的地方,就是添加`ResidualUnit`層的循環部分:前 3 個 RU 有 64 個過濾器,接下來的 4 個 RU 有 128 個過濾器,以此類推。如果過濾器數和前一 RU 層相同,則步長為 1,否則為 2。然后添加`ResidualUnit`,然后更新`prev_filters`。
不到 40 行代碼就能搭建出 ILSVRC 2015 年冠軍模型,既體現出 ResNet 的優美,也展現了 Keras API 的表達力。實現其他 CNN 架構也不困難。但是 Keras 內置了其中一些架構,一起嘗試下。
## 使用 Keras 的預訓練模型
通常來講,不用手動實現 GoogLeNet 或 ResNet 這樣的標準模型,因為`keras.applications`中已經包含這些預訓練模型了,只需一行代碼就成。例如,要加載在 ImageNet 上預訓練的 ResNet-50 模型,使用下面的代碼就行:
```py
model = keras.applications.resnet50.ResNet50(weights="imagenet")
```
僅此而已!這樣就能穿件一個 ResNet-50 模型,并下載在 ImageNet 上預訓練的權重。要使用它,首先要保證圖片有正確的大小。ResNet-50 模型要用 224 × 224 像素的圖片(其它模型可能是 299 × 299),所以使用 TensorFlow 的`tf.image.resize()`函數來縮放圖片:
```py
images_resized = tf.image.resize(images, [224, 224])
```
> 提示:`tf.image.resize()`不會保留寬高比。如果需要,可以裁剪圖片為合適的寬高比之后,再進行縮放。兩步可以通過`tf.image.crop_and_resize()`來實現。
預訓練模型的圖片要經過特別的預處理。在某些情況下,要求輸入是 0 到 1,有時是-1 到 1,等等。每個模型提供了一個`preprocess_input()`函數,來對圖片做預處理。這些函數假定像素值的范圍是 0 到 255,因此需要乘以 255(因為之前將圖片縮減到 0 和 1 之間):
```py
inputs = keras.applications.resnet50.preprocess_input(images_resized * 255)
```
現在就可以用預訓練模型做預測了:
```py
Y_proba = model.predict(inputs)
```
和通常一樣,輸出`Y_proba`是一個矩陣,每行是一張圖片,每列是一個類(這個例子中有 1000 類)。如果想展示 top K 預測,要使用`decode_predictions()`函數,將每個預測出的類的名字和概率包括進來。對于每張圖片,返回 top K 預測的數組,每個預測表示為包含類標識符、名字和置信度的數組:
```py
top_K = keras.applications.resnet50.decode_predictions(Y_proba, top=3)
for image_index in range(len(images)):
print("Image #{}".format(image_index))
for class_id, name, y_proba in top_K[image_index]:
print(" {} - {:12s} {:.2f}%".format(class_id, name, y_proba * 100))
print()
```
輸出如下:
```py
Image #0
n03877845 - palace 42.87%
n02825657 - bell_cote 40.57%
n03781244 - monastery 14.56%
Image #1
n04522168 - vase 46.83%
n07930864 - cup 7.78%
n11939491 - daisy 4.87%
```
正確的類(monastery 和 daisy)出現在 top3 的結果中。考慮到,這是從 1000 個類中挑出來的,結果相當不錯。
可以看到,使用預訓練模型,可以非常容易的創建出一個效果相當不錯的圖片分類器。`keras.applications`中其它視覺模型還有幾種 ResNet 的變體,GoogLeNet 的變體(比如 Inception-v3 和 Xception),VGGNet 的變體,MobileNet 和 MobileNetV2(移動設備使用的輕量模型)。
如果要使用的圖片分類器不是給 ImageNet 圖片做分類的呢?這時,還是可以使用預訓練模型來做遷移學習。
## 使用預訓練模型做遷移學習
如果想創建一個圖片分類器,但沒有足夠的訓練數據,使用預訓練模型的低層通常是不錯的主意,就像第 11 章討論過的那樣。例如,使用預訓練的 Xception 模型訓練一個分類花的圖片的模型。首先,使用 TensorFlow Datasets 加載數據集(見 13 章):
```py
import tensorflow_datasets as tfds
dataset, info = tfds.load("tf_flowers", as_supervised=True, with_info=True)
dataset_size = info.splits["train"].num_examples # 3670
class_names = info.features["label"].names # ["dandelion", "daisy", ...]
n_classes = info.features["label"].num_classes # 5
```
可以通過設定`with_info=True`來獲取數據集信息。這里,獲取到了數據集的大小和類名。但是,這里只有`"train"`訓練集,沒有測試集和驗證集,所以需要分割訓練集。TF Datasets 提供了一個 API 來做這項工作。比如,使用數據集的前 10%作為測試集,接著的 15%來做驗證集,剩下的 75%來做訓練集:
```py
test_split, valid_split, train_split = tfds.Split.TRAIN.subsplit([10, 15, 75])
test_set = tfds.load("tf_flowers", split=test_split, as_supervised=True)
valid_set = tfds.load("tf_flowers", split=valid_split, as_supervised=True)
train_set = tfds.load("tf_flowers", split=train_split, as_supervised=True)
```
然后,必須要預處理圖片。CNN 的要求是 224 × 224 的圖片,所以需要縮放。還要使用 Xception 的`preprocess_input()`函數來預處理圖片:
```py
def preprocess(image, label):
resized_image = tf.image.resize(image, [224, 224])
final_image = keras.applications.xception.preprocess_input(resized_image)
return final_image, label
```
對三個數據集使用這個預處理函數,打散訓練集,給所有的數據集添加批次和預提取:
```py
batch_size = 32
train_set = train_set.shuffle(1000)
train_set = train_set.map(preprocess).batch(batch_size).prefetch(1)
valid_set = valid_set.map(preprocess).batch(batch_size).prefetch(1)
test_set = test_set.map(preprocess).batch(batch_size).prefetch(1)
```
如果想做數據增強,可以修改訓練集的預處理函數,給訓練圖片添加一些轉換。例如,使用`tf.image.random_crop()`隨機裁剪圖片,使用`tf.image.random_flip_left_right()`做隨機水平翻轉,等等(參考 notebook 的“使用預訓練模型做遷移學習”部分)。
> 提示:`keras.preprocessing.image.ImageDataGenerator`可以方便地從硬盤加載圖片,并用多種方式來增強:偏移、旋轉、縮放、翻轉、裁剪,或使用任何你想做的轉換。對于簡單項目,這么做很方便。但是,使用 tf.data 管道的好處更多:從任何數據源高效讀取圖片(例如,并行);操作數據集;如果基于`tf.image`運算編寫預處理函數,既可以用在 tf.data 管道中,也可以用在生產部署的模型中(見第 19 章)。
然后加載一個在 ImageNet 上預訓練的 Xception 模型。通過設定`include_top=False`,排除模型的頂層:排除了全局平均池化層和緊密輸出層。我們然后根據基本模型的輸出,添加自己的全局平均池化層,然后添加緊密輸出層(沒有一個類就有一個單元,使用 softmax 激活函數)。最后,創建 Keras 模型:
```py
base_model = keras.applications.xception.Xception(weights="imagenet",
include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
output = keras.layers.Dense(n_classes, activation="softmax")(avg)
model = keras.Model(inputs=base_model.input, outputs=output)
```
第 11 章介紹過,最好凍結預訓練層的權重,至少在訓練初期如此:
```py
for layer in base_model.layers:
layer.trainable = False
```
> 筆記:因為我們的模型直接使用了基本模型的層,而不是`base_model`對象,設置`base_model.trainable=False`沒有任何效果。
最后,編譯模型,開始訓練:
```py
optimizer = keras.optimizers.SGD(lr=0.2, momentum=0.9, decay=0.01)
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(train_set, epochs=5, validation_data=valid_set)
```
> 警告:訓練過程非常慢,除非使用 GPU。如果沒有 GPU,應該在 Colab 中運行本章的 notebook,使用 GPU 運行時(是免費的!)。見指導,[*https://github.com/ageron/handson-ml2*](https://links.jianshu.com/go?to=https%3A%2F%2Fgithub.com%2Fageron%2Fhandson-ml2)。
模型訓練幾個周期之后,它的驗證準確率應該可以達到 75-80%,然后就沒什么提升了。這意味著上層訓練的差不多了,此時可以解凍所有層(或只是解凍上邊的層),然后繼續訓練(別忘在冷凍和解凍層是編譯模型)。此時使用小得多的學習率,以避免破壞預訓練的權重:
```py
for layer in base_model.layers:
layer.trainable = True
optimizer = keras.optimizers.SGD(lr=0.01, momentum=0.9, decay=0.001)
model.compile(...)
history = model.fit(...)
```
訓練要花不少時間,最終在測試集上的準確率可以達到 95%。有個模型,就可以訓練出驚艷的圖片分類器了!計算機視覺除了分類,還有其它任務,比如,想知道花在圖片中的位置,該怎么做呢?
## 分類和定位
第 10 章討論過,定位圖片中的物體可以表達為一個回歸任務:預測物體的范圍框,一個常見的方法是預測物體中心的水平和垂直坐標,和其高度和寬度。不需要大改模型,只要再添加一個有四個單元的緊密輸出層(通常是在全局平均池化層的上面),可以用 MSE 損失訓練:
```py
base_model = keras.applications.xception.Xception(weights="imagenet",
include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
class_output = keras.layers.Dense(n_classes, activation="softmax")(avg)
loc_output = keras.layers.Dense(4)(avg)
model = keras.Model(inputs=base_model.input,
outputs=[class_output, loc_output])
model.compile(loss=["sparse_categorical_crossentropy", "mse"],
loss_weights=[0.8, 0.2], # depends on what you care most about
optimizer=optimizer, metrics=["accuracy"])
```
但現在有一個問題:花數據集中沒有圍繞花的邊框。因此,我們需要自己加上。這通常是機器學習任務中最難的部分:獲取標簽。一個好主意是花點時間來找合適的工具。給圖片加邊框,可供使用的開源圖片打標簽工具包括 VGG Image Annotator,、LabelImg,、OpenLabeler 或 ImgLab,或是商業工具,比如 LabelBox 或 Supervisely。還可以考慮眾包平臺,比如如果有很多圖片要標注的話,可以使用 Amazon Mechanical Turk。但是,建立眾包平臺、準備數據格式、監督、保證質量,要做不少工作。如果只有幾千張圖片要打標簽,又不是頻繁來做,最好選擇自己來做。Adriana Kovashka 等人寫了一篇實用的計算機視覺方面的關于眾包的[論文](https://links.jianshu.com/go?to=https%3A%2F%2Farxiv.org%2Fabs%2F1611.02145),建議讀一讀。
假設你已經給每張圖片的花都獲得了邊框。你需要創建一個數據集,它的項是預處理好的圖片的批次,加上類標簽和邊框。每項應該是一個元組,格式是`(images, (class_labels, bounding_boxes))`。然后就可以準備訓練模型了!
> 提示:邊框應該做歸一化,讓中心的橫坐標、縱坐標、寬度和高度的范圍變成 0 到 1 之間。另外,最好是預測高和寬的平方根,而不是直接預測高和寬:大邊框的 10 像素的誤差,相比于小邊框的 10 像素的誤差,不會懲罰那么大。
MSE 作為損失函數來訓練模型效果很好,但不是評估模型預測邊框的好指標。最常見的指標是交并比(Intersection over Union (IoU)):預測邊框與目標邊框的重疊部分,除以兩者的并集(見圖 14-23)。在 tf,keras 中,交并比是用`tf.keras.metrics.MeanIoU`類來實現的。
圖 14-23 交并比指標
完成了分類并定位單一物體,但如果圖片中有多個物體該怎么辦呢(常見于花數據集)?
## 目標檢測
分類并定位圖片中的多個物體的任務被稱為目標檢測。幾年之前,使用的方法還是用定位單一目標的 CNN,然后將其在圖片上滑動,見圖 14-24。在這個例子中,圖片被分成了 6 × 8 的網格,CNN(粗黑實線矩形)的范圍是 3 × 3。 當 CNN 查看圖片的左上部分時,檢測到了最左邊的玫瑰花,向右滑動一格,檢測到的還是同樣的花。又滑動一格,檢測到了最上的花,再向右一格,檢測到的還是最上面的花。你可以繼續滑動 CNN,查看所有 3 × 3 的區域。另外,因為目標的大小不同,還需要用不同大小的 CNN 來觀察。例如,檢測完了所有 3 × 3 的區域,可以繼續用 4 × 4 的區域來檢測。
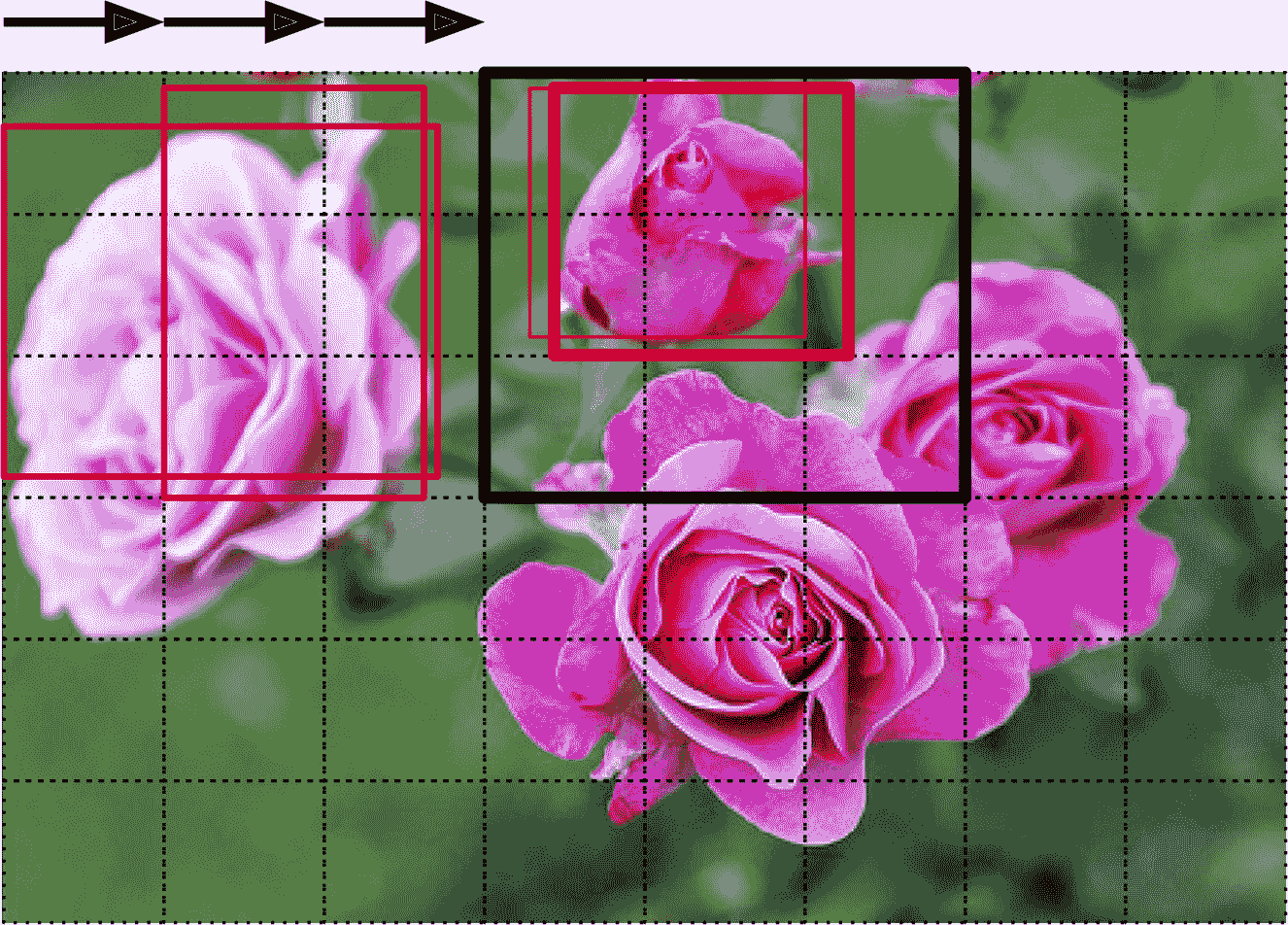圖 14-24 通過滑動 CNN 來檢測多個目標
這個方法非常簡單易懂,但是也看到了,它會在不同位置、多次檢測到同樣的目標。需要后處理,去除沒用的邊框,常見的方法是非極大值抑制(non-max suppression)。步驟如下:
1. 首先,給 CNN 添加另一個對象性輸出,來估計花確實出現在圖片中的概率(或者,可以添加一個“沒有花”的類,但通常不好使)。必須要使用 sigmoid 激活函數,可以用二元交叉熵損失函數來訓練。然后刪掉對象性分數低于某閾值的所有邊框:這樣能刪掉所有不包含花的邊框。
2. 找到對象性分數最高的邊框,然后刪掉所有其它與之大面積重疊的邊框(例如,IoU 大于 60%)。例如,在圖 14-24 中,最大對象性分數的邊框出現在最上面花的粗賓匡(對象性分數用邊框的粗細來表示)。另一個邊框和這個邊框重合很多,所以將其刪除。
3. 重復這兩個步驟,直到沒有可以刪除的邊框。
用這個簡單的方法來做目標檢測的效果相當不錯,但需要運行 CNN 好幾次,所以很慢。幸好,有一個更快的方法來滑動 CNN:使用全卷積網絡(fully convolutional network,FCN)。
### 全卷積層
FCN 是 Jonathan Long 在 2015 年的一篇[論文](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Ffcn)匯總提出的,用于語義分割(根據所屬目標,對圖片中的每個像素點進行分類)。作者指出,可以用卷積層替換 CNN 頂部的緊密層。要搞明白,看一個例子:假設一個 200 個神經元的緊密層,位于卷積層的上邊,卷積層輸出 100 個特征映射,每個大小是 7 × 7(這是特征映射的大小,不是核大小)。每個神經元會計算卷積層的 100 × 7 × 7 個激活結果的加權和(加上偏置項)。現在將緊密層替換為卷積層,有 200 個過濾器,每個大小為 7 × 7,`"valid"`填充。這個層能輸出 200 個特征映射,每個是 1 × 1(因為核大小等于輸入特征映射的大小,并且使用的是`"valid"`填充)。換句話說,會產生 200 個數,和緊密層一樣;如果仔細觀察卷積層的計算,會發現這些書和緊密層輸出的數一模一樣。唯一不同的地方,緊密層的輸出的張量形狀是 [批次大小, 200],而卷積層的輸出的張量形狀是 [批次大小, 1, 1, 200]。
> 提示:要將緊密層變成卷積層,卷積層中的過濾器的數量,必須等于緊密層的神經元數,過濾器大小必須等于輸入特征映射的大小,必須使用`"valid"`填充。步長可以是 1 或以上。
為什么這點這么重要?緊密層需要的是一個具體的輸入大小(因為它的每個輸入特征都有一個權重),卷積層卻可以處理任意大小的圖片(但是,它也希望輸入有一個確定的通道數,因為每個核對每個輸入通道包含一套不同的權重集合)。因為 FCN 只包含卷積層(和池化層,屬性相同),所以可以在任何大小的圖片上訓練和運行。
舉個例子,假設已經訓練好了一個用于分類和定位的 CNN。圖片大小是 224 × 224,輸出 10 個數:輸出 0 到 4 經過 softmax 激活函數,給出類的概率;輸出 5 經過邏輯激活函數,給出對象性分數;輸出 6 到 9 不經過任何激活函數,表示邊框的中心坐標、高和寬。
現在可以將緊密層轉換為卷積層。事實上,不需要再次訓練,只需將緊密層的權重復制到卷積層中。另外,可以在訓練前,將 CNN 轉換成 FCN。
當輸入圖片為 224 × 224 時(見圖 14-25 的左邊),假設輸出層前面的最后一個卷積層(也被稱為瓶頸層)輸出 7 × 7 的特征映射。如果 FCN 的輸入圖片是 448 × 448(見圖 14-25 的右邊),瓶頸層會輸出 14 × 14 的特征映射。因為緊密輸出層被替換成了 10 個使用大小為 7 × 7 的過濾器的卷積層,`"valid"`填充,步長為 1,輸出會有 10 個特征映射,每個大小為 8 × 8(因為 14 – 7 + 1 = 8)。換句話說,FCN 只會處理整張圖片一次,會輸出 8 × 8 的網格,每個格子有 10 個數(5 個類概率,1 個對象性分數,4 個邊框參數)。就像之前滑動 CNN 那樣,每行滑動 8 步,每列滑動 8 步。再形象的講一下,將原始圖片切分成 14 × 14 的網格,然后用 7 × 7 的窗口在上面滑動,窗口會有 8 × 8 = 64 個可能的位置,也就是 64 個預測。但是,FCN 方法又非常高效,因為只需觀察圖片一次。事實上,“只看一次”(You Only Look Once,YOLO)是一個非常流行的目標檢測架構的名字,下面介紹。
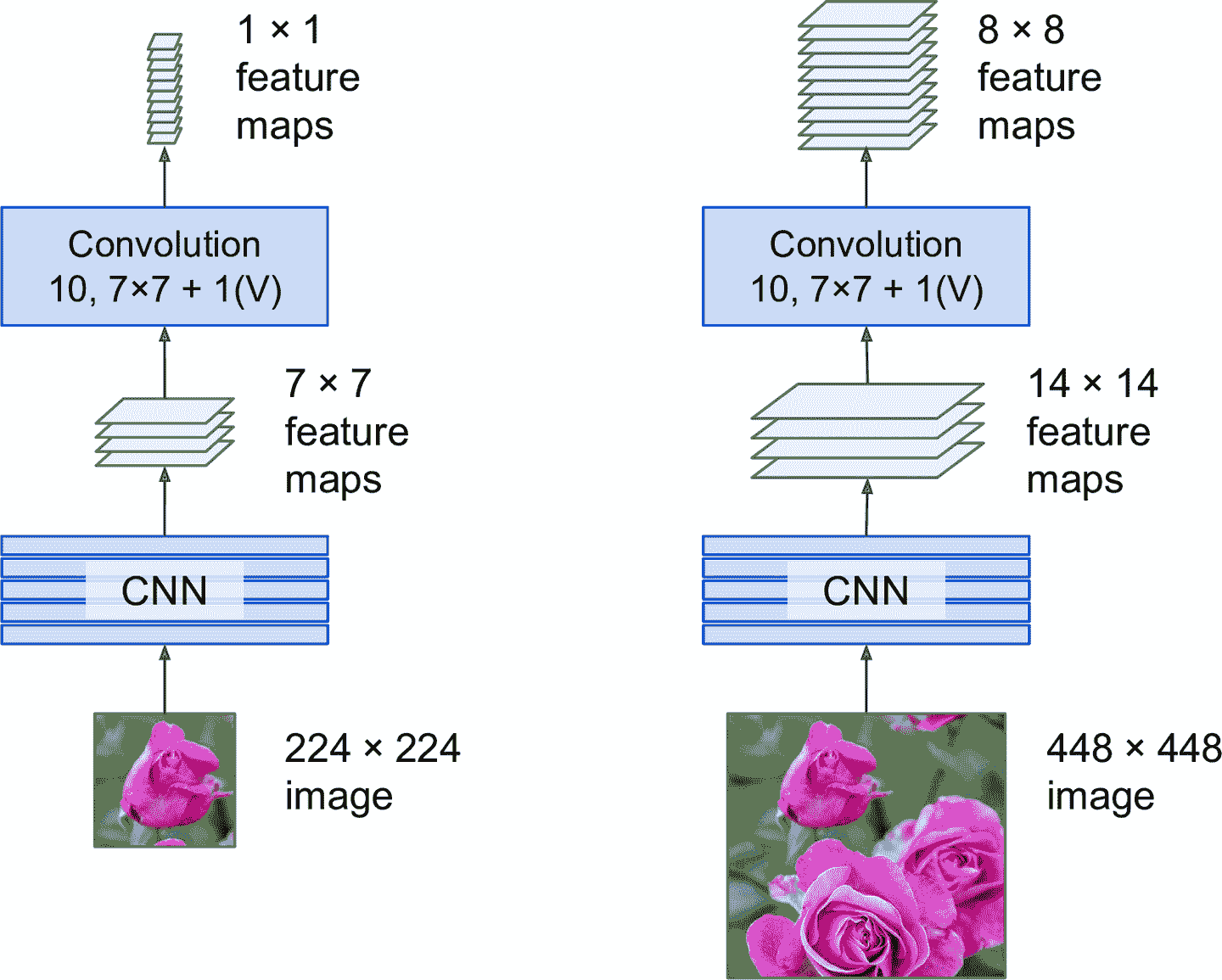圖 14-25 相同的 FCN 處理小圖片(左)和大圖片(右)
### 只看一次(YOLO)
YOLO 是一個非常快且準確的目標檢測框架,是 Joseph Redmon 在 2015 年的一篇[論文](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fyolo)中提出的,2016 年優化為[YOLOv2](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fyolo2),2018 年優化為[YOLOv3](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fyolo3)。速度快到甚至可以在實時視頻中運行,可以看 Redmon 的這個[例子(要翻墻)](https://links.jianshu.com/go?to=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DMPU2HistivI)。
YOLOv3 的架構和之前討論過的很像,只有一些重要的不同點:
* 每個網格輸出 5 個邊框(不是 1 個),每個邊框都有一個對象性得分。每個網格還輸出 20 個類概率,是在 PASCAL VOC 數據集上訓練的,這個數據集有 20 個類。每個網格一共有 45 個數:5 個邊框,每個 4 個坐標參數,加上 5 個對象性分數,加上 20 個類概率。
* YOLOv3 不是預測邊框的絕對坐標,而是預測相對于網格坐標的偏置量,(0, 0)是網格的左上角,(1, 1)是網格的右下角。對于每個網格,YOLOv3 是被訓練為只能預測中心位于網格的邊框(邊框通常比網格大得多)。YOLOv3 對邊框坐標使用邏輯激活函數,以保證其在 0 到 1 之間。
* 開始訓練神經網絡之前,YOLOv3 找了 5 個代表性邊框維度,稱為錨定框(anchor box)(或稱為前邊框)。它們是通過 K-Means 算法(見第 9 章)對訓練集邊框的高和寬計算得到的。例如,如果訓練圖片包含許多行人,一個錨定框就會獲取行人的基本維度。然后當神經網絡對每個網格預測 5 個邊框時,實際是預測如何縮放每個錨定框。比如,假設一個錨定框是 100 個像素高,50 個像素寬,神經網絡可能的預測是垂直放大到 1.5 倍,水平縮小為 0.9 倍。結果是 150 × 45 的邊框。更準確的,對于每個網格和每個錨定框,神經網絡預測其垂直和水平縮放參數的對數。有了錨定框,可以更容易預測出邊框,因為可以更快的學到邊框的樣子,速度也會更快。
* 神經網絡是用不同規模的圖片來訓練的:每隔幾個批次,網絡就隨機調訓新照片維度(從 330 × 330 到 608 × 608 像素)。這可以讓網絡學到不同的規模。另外,還可以在不同規模上使用 YOLOv3:小圖比大圖快但準確性差。
還可能有些有意思的創新,比如使用跳連接來恢復一些在 CNN 中損失的空間分辨率,后面討論語義分割時會討論。在 2016 年的這篇論文中,作者介紹了使用層級分類的 YOLO9000 模型:模型預測視覺層級(稱為詞樹,WordTree)中的每個節點的概率。這可以讓網絡用高置信度預測圖片表示的是什么,比如狗,即便不知道狗的品種。建議閱讀這三篇論文:不僅文筆不錯,還給出不少精彩的例子,介紹深度學習系統是如何一點一滴進步的。
> 平均精度均值(mean Average Precision,mAP)
>
> 目標檢測中非常常見的指標是平均精度均值。“平均均值”聽起來啰嗦了。要弄明白這個指標,返回到第 3 章中的兩個分類指標:精確率和召回率。取舍關系:召回率越高,精確率就越低。可以在精確率/召回率曲線上看到。將這條曲線歸納為一個數,可以計算曲線下面積(AUC)。但精確率/召回率曲線上有些部分,當精確率上升時,召回率也上升,特別是當召回率較低時(可以在圖 3-5 的頂部看到)。這就是產生 mAP 的激勵之一。
>
> 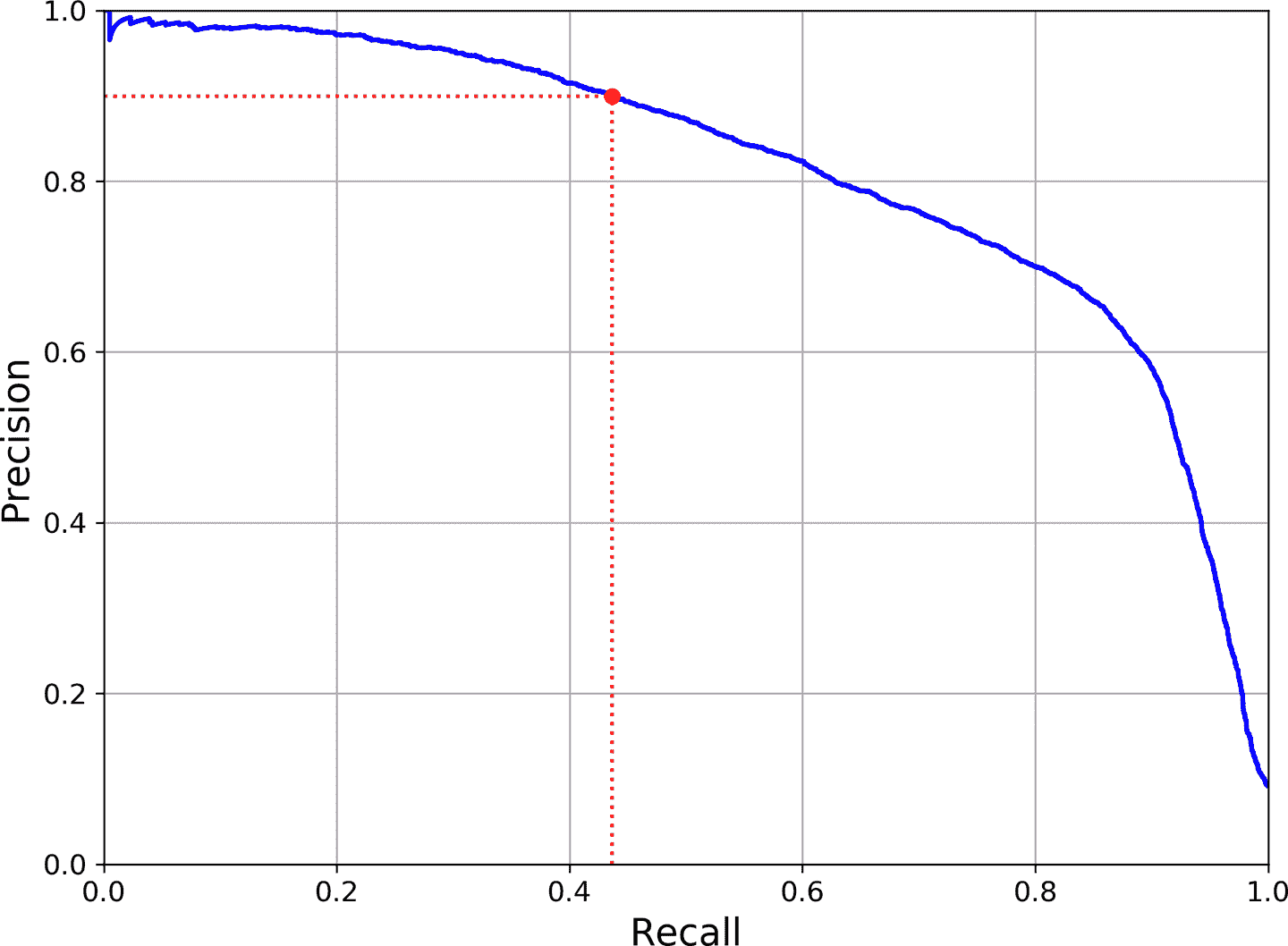圖 3-5 精確率 vs 召回率
>
> 假設當召回率為 10%時,分類器的精確率是 90%,召回率為 20%時,精確率是 96%。這里就沒有取舍關系:使用召回率為 20%的分類器就好,因為此時精確率更高。所以當召回率至少有 10%時,需要找到最高精確率,即 96%。因此,一個衡量模型性能的方法是計算召回率至少為 0%時,計算最大精確率,再計算召回率至少為 10%時的最大精確率,再計算召回率至少為 20%時的最大精確率,以此類推。最后計算這些最大精確率的平均值,這個指標稱為平均精確率(Average Precision (AP))。當有超過兩個類時,可以計算每個類的 AP,然后計算平均 AP(即,mAP)。就是這樣!
>
> 在目標檢測中,還有另外一個復雜度:如果系統檢測到了正確的類,但是定位錯了(即,邊框不對)?當然不能將其作為正預測。一種方法是定義 IOU 閾值:例如,只有當 IOU 超過 0.5 時,預測才是正確的。相應的 mAP 表示為 mAP@0.5(或 mAP@50%,或 AP<sub>50</sub>)。在一些比賽中(比如 PASCAL VOC 競賽),就是這么做的。在其它比賽中(比如,COCO),mAP 是用不同 IOU 閾值(0.50, 0.55, 0.60, …, 0.95)計算的。最終指標是所有這些 mAP 的均值(表示為 AP@[.50:.95] 或 AP@[.50:0.05:.95]),這是均值的均值。
一些 YOLO 的 TensorFlow 實現可以在 GitHub 上找到。可以看看[Zihao Zang 用 TensorFlow 2 實現的項目](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fyolotf2)。TensorFlow Models 項目中還有其它目標檢測模型;一些還傳到了 TF Hub,比如[SSD](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fssd)和[Faster-RCNN](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Ffasterrcnn),這兩個都很流行。SSD 也是一個“一次”檢測模型,類似于 YOLO。Faster R-CNN 復雜一些:圖片先經過 CNN,然后輸出經過區域提議網絡(Region Proposal Network,RPN),RPN 對邊框做處理,更容易圈住目標。根據 CNN 的裁剪輸出,每個邊框都運行這一個分類器。
檢測系統的選擇取決于許多因素:速度、準確率、預訓練模型是否可用、訓練時間、復雜度,等等。論文中有許多指標表格,但測試環境的變數很多。技術進步也很快,很難比較出哪個更適合大多數人,并且有效期可以長過幾個月。
## 語義分割
在語義分割中,每個像素根據其所屬的目標來進行分類(例如,路、汽車、行人、建筑物,等等),見圖 14-26。注意,相同類的不同目標是不做區分的。例如,分割圖片的右側的所有自行車被歸類為一坨像素。這個任務的難點是當圖片經過常規 CNN 時,會逐漸丟失空間分辨率(因為有的層的步長大于 1);因此,常規的 CNN 可以檢測出圖片的左下有一個人,但不知道準確的位置。
和目標檢測一樣,有多種方法來解決這個問題,其中一些比較復雜。但是,之前說過,Jonathan Long 等人在 2015 年的一篇論文中提出樂意簡單的方法。作者先將預訓練的 CNN 轉變為 FCN,CNN 使用 32 的總步長(即,將所有大于 1 的步長相加)作用到輸入圖片上,最后一層的輸出特征映射比輸入圖片小 32 倍。這樣過于粗糙,所以添加了一個單獨的上采樣層,將分辨率乘以 32。
圖 14-26 語義分割
有幾種上采樣(增加圖片大小)的方法,比如雙線性插值,但只在×4 或 ×8 時好用。Jonathan Long 等人使用了轉置卷積層:等價于,先在圖片中插入空白的行和列(都是 0),然后做一次常規卷積(見圖 14-27)。或者,有人將其考慮為常規卷積層,使用分數步長(比如,圖 14-27 中是 1/2)。轉置卷積層一開始的表現和線性插值很像,但因為是可訓練的,在訓練中會變得更好。在 tf.keras 中,可以使用`Conv2DTranspose`層。
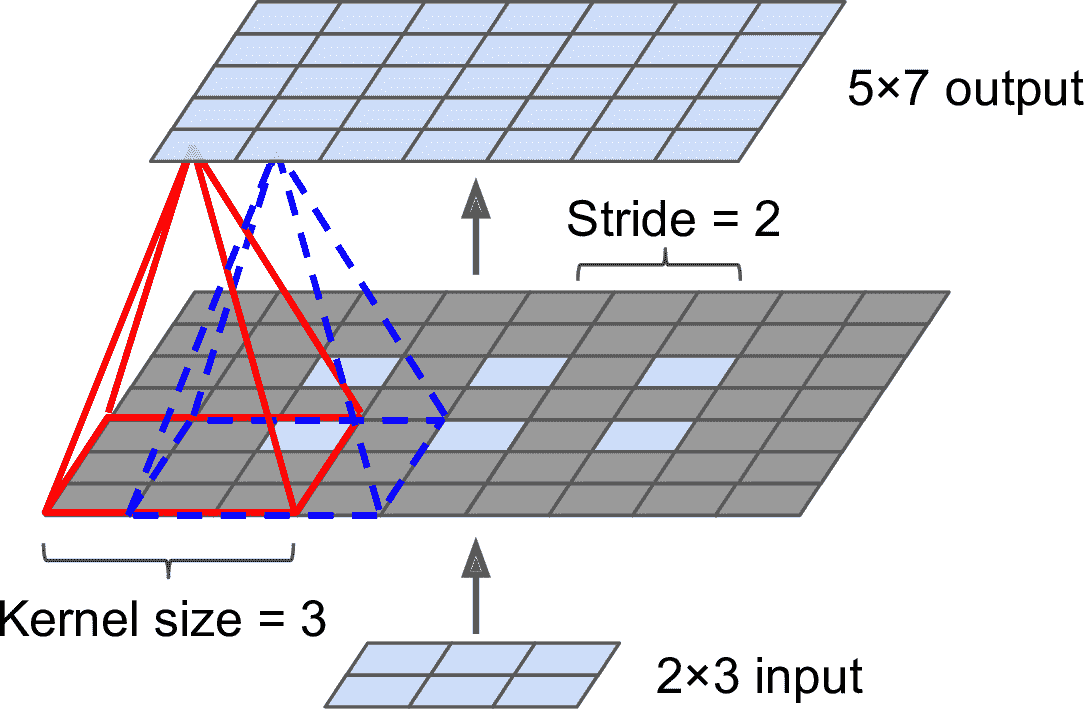圖 14-27 使用轉置卷積層做上采樣
> 筆記:在轉置卷積層中,步長定義為輸入圖片被拉伸的倍數,而不是過濾器步長。所以步長越大,輸出也就越大(和卷積層或池化層不同)。
> TensorFlow 卷積運算
>
> TensorFlow 還提供了一些其它類型的卷積層:
>
> `keras.layers.Conv1D`:為 1D 輸入創建卷積層,比如時間序列或文本,第 15 章會見到。
>
> `keras.layers.Conv3D`:為 3D 輸入創建卷積層,比如 3D PET 掃描。
>
> `dilation_rate`:將任何卷積層的`dilation_rate`超參數設為 2 或更大,可以創建有孔卷積層。等價于常規卷積層,加上一個膨脹的、插入了空白行和列的過濾器。例如,一個 1 × 3 的過濾器`[[1,2,3]]`,膨脹 4 倍,就變成了`[[1, 0, 0, 0, 2, 0, 0, 0, 3]]`。這可以讓卷積層有一個更大的感受野,卻沒有增加計算量和額外的參數。
>
> `tf.nn.depthwise_conv2d()`:可以用來創建深度方向卷積層(但需要自己創建參數)。它將每個過濾器應用到每個獨立的輸入通道上。因此,因此,如果有 f<sub>n</sub>個過濾器和 f<sub>n'</sub>個輸入通道,就會輸出 f<sub>n</sub>×f<sub>n'</sub>個特征映射。
這個方法行得通,但還是不夠準確。要做的更好,作者從低層開始就添加了跳連接:例如,他們使用因子 2(而不是 32)對輸出圖片做上采樣,然后添加一個低層的輸出。然后對結果做因子為 16 的上采樣,總的上采樣因子為 32(見圖 14-28)。這樣可以恢復一些在早期池化中丟失的空間分辨率。在他們的最優架構中,他們使用了兩個相似的跳連接,以從更低層恢復更小的細節。
總之,原始 CNN 的輸出又經過了下面的步驟:上采樣×2,加上一個低層的輸出(形狀相同),上采樣×2,加上一個更低層的輸出,最后上采樣×8。甚至可以放大,超過原圖大小:這個方法可以用來提高圖片的分辨率,這個技術成為超-分辨率。
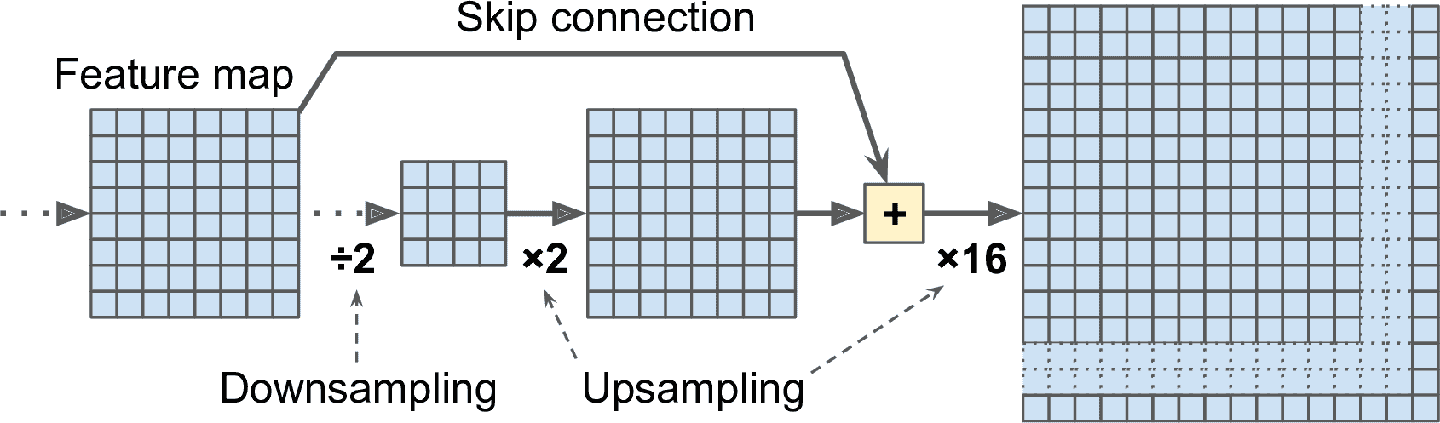圖 14-28 跳連接可以從低層恢復一些空間分辨率
許多 GitHub 倉庫提供了語義分割的 TensorFlow 實現,還可以在 TensorFlow Models 中找到預訓練的實例分割模型。實例分割和語義分割類似,但不是將相同類的所有物體合并成一坨,而是將每個目標都分開(可以將每輛自行車都分開)。目前,TensorFlow Models 中可用的實例分割時基于 Mask R-CNN 架構的,是在 2017 年的一篇[論文](https://links.jianshu.com/go?to=https%3A%2F%2Farxiv.org%2Fabs%2F1703.06870)中提出的:通過給每個邊框做一個像素罩,拓展 Faster R-CNN 模型。所以不僅能得到邊框,還能獲得邊框中像素的像素罩。
可以發現,深度計算機視覺領域既寬廣又發展迅速,每年都會產生新的架構,都是基于卷積神經網絡的。最近幾年進步驚人,研究者們現在正聚焦于越來越難的問題,比如對抗學習(可以讓網絡對具有欺騙性的圖片更有抵抗力),可解釋性(理解為什么網絡做出這樣的分類),實時圖像生成(見第 17 章),一次學習(觀察一次,就能認出目標呃系統)。一些人在探索全新的架構,比如 Geoffrey Hinton 的[膠囊網絡](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fcapsnet)(見[視頻](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fcapsnetvideos),notebook 中有對應的代碼)。下一章會介紹如何用循環神經網絡和卷積神經網絡來處理序列數據,比如時間序列。
## 練習
1. 對于圖片分類,CNN 相對于全連接 DNN 的優勢是什么?
2. 考慮一個 CNN,有 3 個卷積層,每個都是 3 × 3 的核,步長為 2,零填充。最低的層輸出 100 個特征映射,中間的輸出 200 個特征映射,最上面的輸出 400 個。輸入圖片是 200 × 300 像素的 RGB 圖。這個 CNN 的總參數量是多少?如果使用 32 位浮點數,做與測試需要多少內存?批次是 50 張圖片,訓練時的內存消耗是多少?
3. 如果訓練 CNN 時 GPU 內存不夠,解決該問題的 5 種方法是什么?
4. 為什么使用最大池化層,而不是同樣步長的卷積層?
5. 為什么使用局部響應歸一化層?
6. AlexNet 想對于 LeNet-5 的創新在哪里?GoogLeNet、ResNet、SENet、Xception 的創新又是什么?
7. 什么是全卷積網絡?如何將緊密層轉變為卷積層?
8. 語義分割的主要技術難點是什么?
9. 從零搭建你的 CNN,并在 MNIST 上達到盡可能高的準確率。
10. 使用遷移學習來做大圖片分類,經過下面步驟:
a. 創建每個類至少有 100 張圖片的訓練集。例如,你可以用自己的圖片基于地點來分類(沙灘、山、城市,等等),或者使用現成的數據集(比如從 TensorFlow Datasets)。
b. 將其分成訓練集、驗證集、訓練集。
c. 搭建輸入管道,包括必要的預處理操作,最好加上數據增強。
d. 在這個數據集上,微調預訓練模型。
11. 嘗試下 TensorFlow 的[風格遷移教程](https://links.jianshu.com/go?to=https%3A%2F%2Fhoml.info%2Fstyletuto)。用深度學習生成藝術作品很有趣。
