# 七、集成學習和隨機森林
> 譯者:[@friedhelm739](https://github.com/friedhelm739)
>
> 校對者:[@飛龍](https://github.com/wizardforcel)、[@PeterHo](https://github.com/PeterHo)、[@yanmengk](https://github.com/yanmengk)、[@XinQiu](https://github.com/xinqiu)、[@YuWang](https://github.com/bigeyex)
假設你去隨機問很多人一個很復雜的問題,然后把它們的答案合并起來。通常情況下你會發現這個合并的答案比一個專家的答案要好。這就叫做*群體智慧*。同樣的,如果你合并了一組分類器的預測(像分類或者回歸),你也會得到一個比單一分類器更好的預測結果。這一組分類器就叫做集成;因此,這個技術就叫做集成學習,一個集成學習算法就叫做集成方法。
例如,你可以訓練一組決策樹分類器,每一個都在一個隨機的訓練集上。為了去做預測,你必須得到所有單一樹的預測值,然后通過投票(例如第六章的練習)來預測類別。例如一種決策樹的集成就叫做隨機森林,它除了簡單之外也是現今存在的最強大的機器學習算法之一。
向我們在第二章討論的一樣,我們會在一個項目快結束的時候使用集成算法,一旦你建立了一些好的分類器,就把他們合并為一個更好的分類器。事實上,在機器學習競賽中獲得勝利的算法經常會包含一些集成方法。
在本章中我們會討論一下特別著名的集成方法,包括 *bagging, boosting, stacking*,和其他一些算法。我們也會討論隨機森林。
## 投票分類
假設你已經訓練了一些分類器,每一個都有 80% 的準確率。你可能有了一個邏輯斯蒂回歸、或一個 SVM、或一個隨機森林,或者一個 KNN,或許還有更多(詳見圖 7-1)

一個非常簡單去創建一個更好的分類器的方法就是去整合每一個分類器的預測然后經過投票去預測分類。這種分類器就叫做硬投票分類器(詳見圖 7-2)。
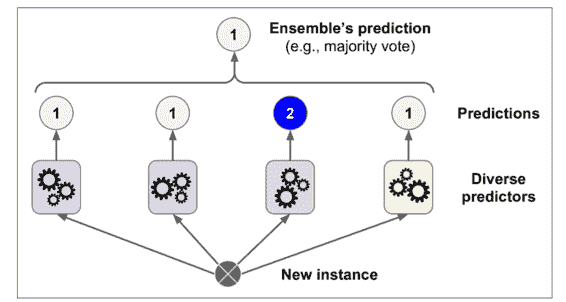
令人驚奇的是這種投票分類器得出的結果經常會比集成中最好的一個分類器結果更好。事實上,即使每一個分類器都是一個弱學習器(意味著它們也就比瞎猜好點),集成后仍然是一個強學習器(高準確率),只要有足夠數量的弱學習者,他們就足夠多樣化。
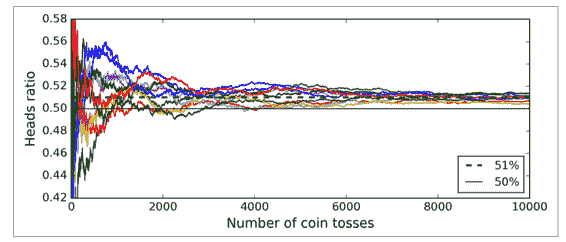
這怎么可能?接下來的分析將幫助你解決這個疑問。假設你有一個有偏差的硬幣,他有 51% 的幾率為正面,49% 的幾率為背面。如果你實驗 1000 次,你會得到差不多 510 次正面,490 次背面,因此大多數都是正面。如果你用數學計算,你會發現在實驗 1000 次后,正面概率為 51% 的人比例為 75%。你實驗的次數越多,正面的比例越大(例如你試驗了 10000 次,總體比例可能性就會達到 97%)。這是因為*大數定律* :當你一直用硬幣實驗時,正面的比例會越來越接近 51%。圖 7-3 展示了始終有偏差的硬幣實驗。你可以看到當實驗次數上升時,正面的概率接近于 51%。最終所有 10 種實驗都會收斂到 51%,它們都大于 50%。
同樣的,假設你創建了一個包含 1000 個分類器的集成模型,其中每個分類器的正確率只有 51%(僅比瞎猜好一點點)。如果你用投票去預測類別,你可能得到 75% 的準確率!然而,這僅僅在所有的分類器都獨立運行的很好、不會發生有相關性的錯誤的情況下才會這樣,然而每一個分類器都在同一個數據集上訓練,導致其很可能會發生這樣的錯誤。他們可能會犯同一種錯誤,所以也會有很多票投給了錯誤類別導致集成的準確率下降。
如果使每一個分類器都獨立自主的分類,那么集成模型會工作的很好。去得到多樣的分類器的方法之一就是用完全不同的算法,這會使它們會做出不同種類的錯誤,這會提高集成的正確率
接下來的代碼創建和訓練了在 sklearn 中的投票分類器。這個分類器由三個不同的分類器組成(訓練集是第五章中的 moons 數據集):
```python
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.ensemble import VotingClassifier
>>> from sklearn.linear_model import LogisticRegression
>>> from sklearn.svm import SVC
>>> log_clf = LogisticRegression()
>>> rnd_clf = RandomForestClassifier()
>>> svm_clf = SVC()
>>> voting_clf = VotingClassifier(estimators=[('lr', log_clf), ('rf', rnd_clf),
>>> ('svc', svm_clf)],voting='hard')
>>> voting_clf.fit(X_train, y_train)
```
讓我們看一下在測試集上的準確率:
```python
>>> from sklearn.metrics import accuracy_score
>>> for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
>>> clf.fit(X_train, y_train)
>>> y_pred = clf.predict(X_test)
>>> print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
LogisticRegression 0.864
RandomForestClassifier 0.872
SVC 0.888
VotingClassifier 0.896
```
你看!投票分類器比其他單獨的分類器表現的都要好。
如果所有的分類器都能夠預測類別的概率(例如他們有一個`predict_proba()`方法),那么你就可以讓 sklearn 以最高的類概率來預測這個類,平均在所有的分類器上。這種方式叫做軟投票。他經常比硬投票表現的更好,因為它給予高自信的投票更大的權重。你可以通過把`voting="hard"`設置為`voting="soft"`來保證分類器可以預測類別概率。然而這不是 SVC 類的分類器默認的選項,所以你需要把它的`probability hyperparameter`設置為`True`(這會使 SVC 使用交叉驗證去預測類別概率,其降低了訓練速度,但會添加`predict_proba()`方法)。如果你修改了之前的代碼去使用軟投票,你會發現投票分類器正確率高達 91%
## Bagging 和 Pasting
就像之前講到的,可以通過使用不同的訓練算法去得到一些不同的分類器。另一種方法就是對每一個分類器都使用相同的訓練算法,但是在不同的訓練集上去訓練它們。有放回采樣被稱為裝袋(*Bagging*,是 *bootstrap aggregating* 的縮寫)。無放回采樣稱為粘貼(*pasting*)。
換句話說,Bagging 和 Pasting 都允許在多個分類器上對訓練集進行多次采樣,但只有 Bagging 允許對同一種分類器上對訓練集進行進行多次采樣。采樣和訓練過程如圖 7-4 所示。
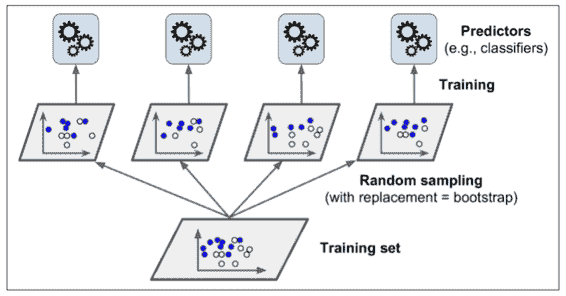
當所有的分類器被訓練后,集成可以通過對所有分類器結果的簡單聚合來對新的實例進行預測。聚合函數通常對分類是*統計模式*(例如硬投票分類器)或者對回歸是平均。每一個單獨的分類器在如果在原始訓練集上都是高偏差,但是聚合降低了偏差和方差。通常情況下,集成的結果是有一個相似的偏差,但是對比與在原始訓練集上的單一分類器來講有更小的方差。
正如你在圖 7-4 上所看到的,分類器可以通過不同的 CPU 核或其他的服務器一起被訓練。相似的,分類器也可以一起被制作。這就是為什么 Bagging 和 Pasting 是如此流行的原因之一:它們的可擴展性很好。
### 在 sklearn 中的 Bagging 和 Pasting
sklearn 為 Bagging 和 Pasting 提供了一個簡單的 API:`BaggingClassifier`類(或者對于回歸可以是`BaggingRegressor`。接下來的代碼訓練了一個 500 個決策樹分類器的集成,每一個都是在數據集上有放回采樣 100 個訓練實例下進行訓練(這是 Bagging 的例子,如果你想嘗試 Pasting,就設置`bootstrap=False`)。`n_jobs`參數告訴 sklearn 用于訓練和預測所需要 CPU 核的數量。(-1 代表著 sklearn 會使用所有空閑核):
```python
>>>from sklearn.ensemble import BaggingClassifier
>>>from sklearn.tree import DecisionTreeClassifier
>>>bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
>>> max_samples=100, bootstrap=True, n_jobs=-1)
>>>bag_clf.fit(X_train, y_train)
>>>y_pred = bag_clf.predict(X_test)
```
如果基分類器可以預測類別概率(例如它擁有`predict_proba()`方法),那么`BaggingClassifier`會自動的運行軟投票,這是決策樹分類器的情況。
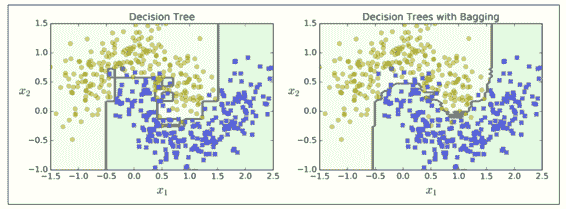
圖 7-5 對比了單一決策樹的決策邊界和 Bagging 集成 500 個樹的決策邊界,兩者都在 moons 數據集上訓練。正如你所看到的,集成的分類比起單一決策樹的分類產生情況更好:集成有一個可比較的偏差但是有一個較小的方差(它在訓練集上的錯誤數目大致相同,但決策邊界較不規則)。
Bootstrap 在每個預測器被訓練的子集中引入了更多的分集,所以 Bagging 結束時的偏差比 Pasting 更高,但這也意味著預測因子最終變得不相關,從而減少了集合的方差。總體而言,Bagging 通常會導致更好的模型,這就解釋了為什么它通常是首選的。然而,如果你有空閑時間和 CPU 功率,可以使用交叉驗證來評估 Bagging 和 Pasting 哪一個更好。
### Out-of-Bag 評價
對于 Bagging 來說,一些實例可能被一些分類器重復采樣,但其他的有可能不會被采樣。`BaggingClassifier`默認采樣。`BaggingClassifier`默認是有放回的采樣`m`個實例 (`bootstrap=True`),其中`m`是訓練集的大小,這意味著平均下來只有 63%的訓練實例被每個分類器采樣,剩下的 37%個沒有被采樣的訓練實例就叫做 *Out-of-Bag* 實例。注意對于每一個的分類器它們的 37% 不是相同的。
因為在訓練中分類器從來沒有看到過 oob 實例,所以它可以在這些實例上進行評估,而不需要單獨的驗證集或交叉驗證。你可以拿出每一個分類器的 oob 來評估集成本身。
在 sklearn 中,你可以在訓練后需要創建一個`BaggingClassifier`來自動評估時設置`oob_score=True`來自動評估。接下來的代碼展示了這個操作。評估結果通過變量`oob_score_`來顯示:
```python
>>> bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,bootstrap=True, n_jobs=-1, oob_score=True)
>>> bag_clf.fit(X_train, y_train)
>>> bag_clf.oob_score_
0.93066666666666664
```
根據這個 obb 評估,`BaggingClassifier`可以再測試集上達到 93.1%的準確率,讓我們修改一下:
```python
>>> from sklearn.metrics import accuracy_score
>>> y_pred = bag_clf.predict(X_test)
>>> accuracy_score(y_test, y_pred)
0.93600000000000005
```
我們在測試集上得到了 93.6% 的準確率,足夠接近了!
對于每個訓練實例 oob 決策函數也可通過`oob_decision_function_`變量來展示。在這種情況下(當基決策器有`predict_proba()`時)決策函數會對每個訓練實例返回類別概率。例如,oob 評估預測第二個訓練實例有 60.6% 的概率屬于正類(39.4% 屬于負類):
```python
>>> bag_clf.oob_decision_function_
array([[ 0., 1.], [ 0.60588235, 0.39411765],[ 1., 0. ],
... [ 1. , 0. ],[ 0., 1.],[ 0.48958333, 0.51041667]])
```
## 隨機貼片與隨機子空間
`BaggingClassifier`也支持采樣特征。它被兩個超參數`max_features`和`bootstrap_features`控制。他們的工作方式和`max_samples`和`bootstrap`一樣,但這是對于特征采樣而不是實例采樣。因此,每一個分類器都會被在隨機的輸入特征內進行訓練。
當你在處理高維度輸入下(例如圖片)此方法尤其有效。對訓練實例和特征的采樣被叫做隨機貼片。保留了所有的訓練實例(例如`bootstrap=False`和`max_samples=1.0`),但是對特征采樣(`bootstrap_features=True`并且/或者`max_features`小于 1.0)叫做隨機子空間。
采樣特征導致更多的預測多樣性,用高偏差換低方差。
## 隨機森林
正如我們所討論的,隨機森林是決策樹的一種集成,通常是通過 bagging 方法(有時是 pasting 方法)進行訓練,通常用`max_samples`設置為訓練集的大小。與建立一個`BaggingClassifier`然后把它放入 *DecisionTreeClassifier* 相反,你可以使用更方便的也是對決策樹優化夠的`RandomForestClassifier`(對于回歸是`RandomForestRegressor`)。接下來的代碼訓練了帶有 500 個樹(每個被限制為 16 葉子結點)的決策森林,使用所有空閑的 CPU 核:
```python
>>>from sklearn.ensemble import RandomForestClassifier
>>>rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1)
>>>rnd_clf.fit(X_train, y_train)
>>>y_pred_rf = rnd_clf.predict(X_test)
```
除了一些例外,`RandomForestClassifier`使用`DecisionTreeClassifier`的所有超參數(決定數怎么生長),把`BaggingClassifier`的超參數加起來來控制集成本身。
隨機森林算法在樹生長時引入了額外的隨機;與在節點分裂時需要找到最好分裂特征相反(詳見第六章),它在一個隨機的特征集中找最好的特征。它導致了樹的差異性,并且再一次用高偏差換低方差,總的來說是一個更好的模型。以下是`BaggingClassifier`大致相當于之前的`randomforestclassifier`:
```python
>>>bag_clf = BaggingClassifier(DecisionTreeClassifier(splitter="random", max_leaf_nodes=16),n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1)
```
### 極端隨機樹
當你在隨機森林上生長樹時,在每個結點分裂時只考慮隨機特征集上的特征(正如之前討論過的一樣)。相比于找到更好的特征我們可以通過使用對特征使用隨機閾值使樹更加隨機(像規則決策樹一樣)。
這種極端隨機的樹被簡稱為 *Extremely Randomized Trees*(極端隨機樹),或者更簡單的稱為 *Extra-Tree*。再一次用高偏差換低方差。它還使得 *Extra-Tree* 比規則的隨機森林更快地訓練,因為在每個節點上找到每個特征的最佳閾值是生長樹最耗時的任務之一。
你可以使用 sklearn 的`ExtraTreesClassifier`來創建一個 *Extra-Tree* 分類器。他的 API 跟`RandomForestClassifier`是相同的,相似的, *ExtraTreesRegressor* 跟`RandomForestRegressor`也是相同的 API。
我們很難去分辨`ExtraTreesClassifier`和`RandomForestClassifier`到底哪個更好。通常情況下是通過交叉驗證來比較它們(使用網格搜索調整超參數)。
### 特征重要度
最后,如果你觀察一個單一決策樹,重要的特征會出現在更靠近根部的位置,而不重要的特征會經常出現在靠近葉子的位置。因此我們可以通過計算一個特征在森林的全部樹中出現的平均深度來預測特征的重要性。sklearn 在訓練后會自動計算每個特征的重要度。你可以通過`feature_importances_`變量來查看結果。例如如下代碼在 iris 數據集(第四章介紹)上訓練了一個`RandomForestClassifier`模型,然后輸出了每個特征的重要性。看來,最重要的特征是花瓣長度(44%)和寬度(42%),而萼片長度和寬度相對比較是不重要的(分別為 11% 和 2%):
```python
>>> from sklearn.datasets import load_iris
>>> iris = load_iris()
>>> rnd_clf = RandomForestClassifier(n_estimators=500, n_jobs=-1)
>>> rnd_clf.fit(iris["data"], iris["target"])
>>> for name, score in zip(iris["feature_names"], rnd_clf.feature_importances_):
>>> print(name, score)
sepal length (cm) 0.112492250999
sepal width (cm) 0.0231192882825
petal length (cm) 0.441030464364
petal width (cm) 0.423357996355
```
相似的,如果你在 MNIST 數據及上訓練隨機森林分類器(在第三章上介紹),然后畫出每個像素的重要性,你可以得到圖 7-6 的圖片。

隨機森林可以非常方便快速得了解哪些特征實際上是重要的,特別是你需要進行特征選擇的時候。
## 提升
提升(Boosting,最初稱為*假設增強*)指的是可以將幾個弱學習者組合成強學習者的集成方法。對于大多數的提升方法的思想就是按順序去訓練分類器,每一個都要嘗試修正前面的分類。現如今已經有很多的提升方法了,但最著名的就是 *Adaboost*(適應性提升,是 *Adaptive Boosting* 的簡稱) 和 *Gradient Boosting*(梯度提升)。讓我們先從 *Adaboost* 說起。
### Adaboost
使一個新的分類器去修正之前分類結果的方法就是對之前分類結果不對的訓練實例多加關注。這導致新的預測因子越來越多地聚焦于這種情況。這是 *Adaboost* 使用的技術。
舉個例子,去構建一個 Adaboost 分類器,第一個基分類器(例如一個決策樹)被訓練然后在訓練集上做預測,在誤分類訓練實例上的權重就增加了。第二個分類機使用更新過的權重然后再一次訓練,權重更新,以此類推(詳見圖 7-7)
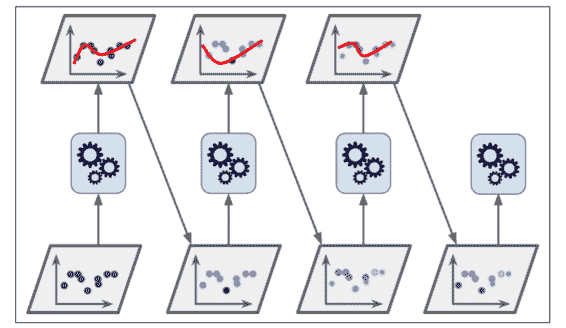
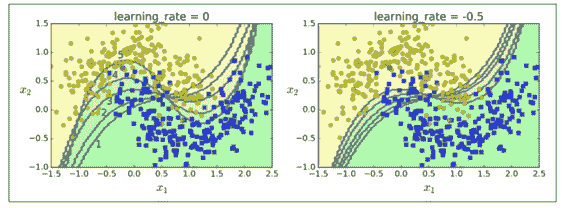
圖 7-8 顯示連續五次預測的 moons 數據集的決策邊界(在本例中,每一個分類器都是高度正則化帶有 RBF 核的 SVM)。第一個分類器誤分類了很多實例,所以它們的權重被提升了。第二個分類器因此對這些誤分類的實例分類效果更好,以此類推。右邊的圖代表了除了學習率減半外(誤分類實例權重每次迭代上升一半)相同的預測序列。你可以看出,序列學習技術與梯度下降很相似,除了調整單個預測因子的參數以最小化代價函數之外,AdaBoost 增加了集合的預測器,逐漸使其更好。
一旦所有的分類器都被訓練后,除了分類器根據整個訓練集上的準確率被賦予的權重外,集成預測就非常像 Bagging 和 Pasting 了。
序列學習技術的一個重要的缺點就是:它不能被并行化(只能按步驟),因為每個分類器只能在之前的分類器已經被訓練和評價后再進行訓練。因此,它不像 Bagging 和 Pasting 一樣。
讓我們詳細看一下 Adaboost 算法。每一個實例的權重`wi`初始都被設為`1/m`第一個分類器被訓練,然后他的權重誤差率`r1`在訓練集上算出,詳見公式 7-1。
公式 7-1:第`j`個分類器的權重誤差率

其中  是第`j`個分類器對于第`i`實例的預測。
分類器的權重  隨后用公式 7-2 計算出來。其中`η`是超參數學習率(默認為 1)。分類器準確率越高,它的權重就越高。如果它只是瞎猜,那么它的權重會趨近于 0。然而,如果它總是出錯(比瞎猜的幾率都低),它的權重會使負數。
公式 7-2:分類器權重
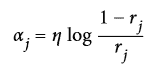
接下來實例的權重會按照公式 7-3 更新:誤分類的實例權重會被提升。
公式 7-3 權重更新規則
對于`i=1, 2, ..., m`
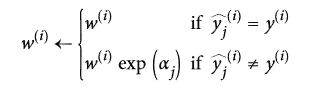
隨后所有實例的權重都被歸一化(例如被  整除)
最后,一個新的分類器通過更新過的權重訓練,整個過程被重復(新的分類器權重被計算,實例的權重被更新,隨后另一個分類器被訓練,以此類推)。當規定的分類器數量達到或者最好的分類器被找到后算法就會停止。
為了進行預測,Adaboost 通過分類器權重  簡單的計算了所有的分類器和權重。預測類別會是權重投票中主要的類別。(詳見公式 7-4)
公式 7-4: Adaboost 分類器
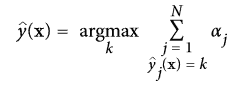
其中`N`是分類器的數量。
sklearn 通常使用 Adaboost 的多分類版本 *SAMME*(這就代表了 *分段加建模使用多類指數損失函數*)。如果只有兩類別,那么 *SAMME* 是與 Adaboost 相同的。如果分類器可以預測類別概率(例如如果它們有`predict_proba()`),如果 sklearn 可以使用 *SAMME* 叫做`SAMME.R`的變量(R 代表“REAL”),這種依賴于類別概率的通常比依賴于分類器的更好。
接下來的代碼訓練了使用 sklearn 的`AdaBoostClassifier`基于 200 個決策樹樁 Adaboost 分類器(正如你說期待的,對于回歸也有`AdaBoostRegressor`)。一個決策樹樁是`max_depth=1`的決策樹-換句話說,是一個單一的決策節點加上兩個葉子結點。這就是`AdaBoostClassifier`的默認基分類器:
```python
>>>from sklearn.ensemble import AdaBoostClassifier
>>>ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1), n_estimators=200,algorithm="SAMME.R", learning_rate=0.5)
>>>ada_clf.fit(X_train, y_train)
```
如果你的 Adaboost 集成過擬合了訓練集,你可以嘗試減少基分類器的數量或者對基分類器使用更強的正則化。
### 梯度提升
另一個非常著名的提升算法是梯度提升。與 Adaboost 一樣,梯度提升也是通過向集成中逐步增加分類器運行的,每一個分類器都修正之前的分類結果。然而,它并不像 Adaboost 那樣每一次迭代都更改實例的權重,這個方法是去使用新的分類器去擬合前面分類器預測的*殘差* 。
讓我們通過一個使用決策樹當做基分類器的簡單的回歸例子(回歸當然也可以使用梯度提升)。這被叫做梯度提升回歸樹(GBRT,*Gradient Tree Boosting* 或者 *Gradient Boosted Regression Trees*)。首先我們用`DecisionTreeRegressor`去擬合訓練集(例如一個有噪二次訓練集):
```python
>>>from sklearn.tree import DecisionTreeRegressor
>>>tree_reg1 = DecisionTreeRegressor(max_depth=2)
>>>tree_reg1.fit(X, y)
```
現在在第一個分類器的殘差上訓練第二個分類器:
```python
>>>y2 = y - tree_reg1.predict(X)
>>>tree_reg2 = DecisionTreeRegressor(max_depth=2)
>>>tree_reg2.fit(X, y2)
```
隨后在第二個分類器的殘差上訓練第三個分類器:
```python
>>>y3 = y2 - tree_reg1.predict(X)
>>>tree_reg3 = DecisionTreeRegressor(max_depth=2)
>>>tree_reg3.fit(X, y3)
```
現在我們有了一個包含三個回歸器的集成。它可以通過集成所有樹的預測來在一個新的實例上進行預測。
```python
>>>y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
```
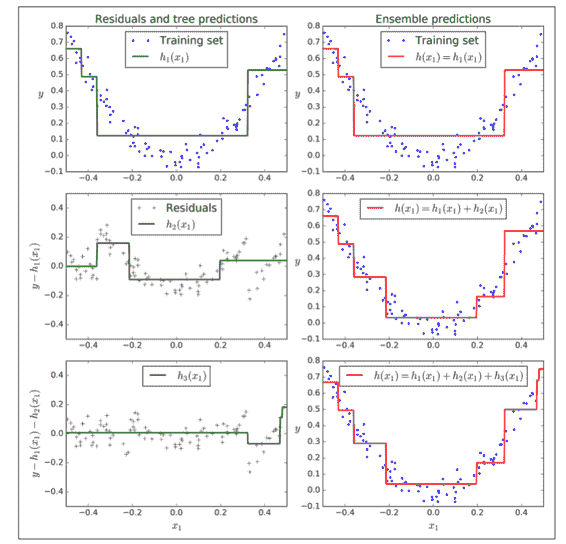
圖 7-9 在左欄展示了這三個樹的預測,在右欄展示了集成的預測。在第一行,集成只有一個樹,所以它與第一個樹的預測相似。在第二行,一個新的樹在第一個樹的殘差上進行訓練。在右邊欄可以看出集成的預測等于前兩個樹預測的和。相同的,在第三行另一個樹在第二個數的殘差上訓練。你可以看到集成的預測會變的更好。
我們可以使用 sklean 中的`GradientBoostingRegressor`來訓練 GBRT 集成。與`RandomForestClassifier`相似,它也有超參數去控制決策樹的生長(例如`max_depth`,`min_samples_leaf`等等),也有超參數去控制集成訓練,例如基分類器的數量(`n_estimators`)。接下來的代碼創建了與之前相同的集成:
```python
>>>from sklearn.ensemble import GradientBoostingRegressor
>>>gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0)
>>>gbrt.fit(X, y)
```
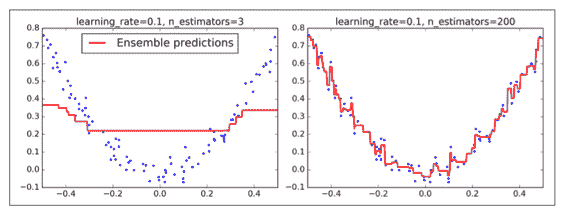
超參數`learning_rate` 確立了每個樹的貢獻。如果你把它設置為一個很小的樹,例如 0.1,在集成中就需要更多的樹去擬合訓練集,但預測通常會更好。這個正則化技術叫做 *shrinkage*。圖 7-10 展示了兩個在低學習率上訓練的 GBRT 集成:其中左面是一個沒有足夠樹去擬合訓練集的樹,右面是有過多的樹過擬合訓練集的樹。
為了找到樹的最優數量,你可以使用早停技術(第四章討論)。最簡單使用這個技術的方法就是使用`staged_predict()`:它在訓練的每個階段(用一棵樹,兩棵樹等)返回一個迭代器。接下來的代碼用 120 個樹訓練了一個 GBRT 集成,然后在訓練的每個階段驗證錯誤以找到樹的最佳數量,最后使用 GBRT 樹的最優數量訓練另一個集成:
```python
>>>import numpy as np
>>>from sklearn.model_selection import train_test_split
>>>from sklearn.metrics import mean_squared_error
>>>X_train, X_val, y_train, y_val = train_test_split(X, y)
>>>gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120)
>>>gbrt.fit(X_train, y_train)
>>>errors = [mean_squared_error(y_val, y_pred)
for y_pred in gbrt.staged_predict(X_val)]
>>>bst_n_estimators = np.argmin(errors)
>>>gbrt_best = GradientBoostingRegressor(max_depth=2,n_estimators=bst_n_estimators)
>>>gbrt_best.fit(X_train, y_train)
```
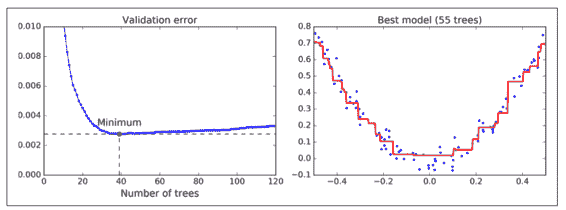
驗證錯誤在圖 7-11 的左面展示,最優模型預測被展示在右面。
你也可以早早的停止訓練來實現早停(與先在一大堆樹中訓練,然后再回頭去找最優數目相反)。你可以通過設置`warm_start=True`來實現 ,這使得當`fit()`方法被調用時 sklearn 保留現有樹,并允許增量訓練。接下來的代碼在當一行中的五次迭代驗證錯誤沒有改善時會停止訓練:
```python
>>>gbrt = GradientBoostingRegressor(max_depth=2, warm_start=True)
min_val_error = float("inf")
error_going_up = 0
for n_estimators in range(1, 120):
gbrt.n_estimators = n_estimators
gbrt.fit(X_train, y_train)
y_pred = gbrt.predict(X_val)
val_error = mean_squared_error(y_val, y_pred)
if val_error < min_val_error:
min_val_error = val_error
error_going_up = 0
else:
error_going_up += 1
if error_going_up == 5:
break # early stopping
```
`GradientBoostingRegressor`也支持指定用于訓練每棵樹的訓練實例比例的超參數`subsample`。例如如果`subsample=0.25`,那么每個樹都會在 25% 隨機選擇的訓練實例上訓練。你現在也能猜出來,這也是個高偏差換低方差的作用。它同樣也加速了訓練。這個技術叫做*隨機梯度提升*。
也可能對其他損失函數使用梯度提升。這是由損失超參數控制(見 sklearn 文檔)。
## Stacking
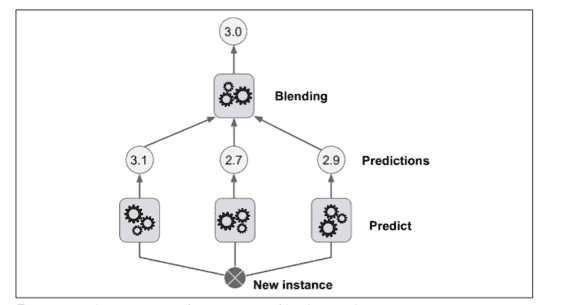
本章討論的最后一個集成方法叫做 *Stacking*(*stacked generalization* 的縮寫)。這個算法基于一個簡單的想法:不使用瑣碎的函數(如硬投票)來聚合集合中所有分類器的預測,我們為什么不訓練一個模型來執行這個聚合?圖 7-12 展示了這樣一個在新的回歸實例上預測的集成。底部三個分類器每一個都有不同的值(3.1,2.7 和 2.9),然后最后一個分類器(叫做 *blender* 或者 *meta learner* )把這三個分類器的結果當做輸入然后做出最終決策(3.0)。
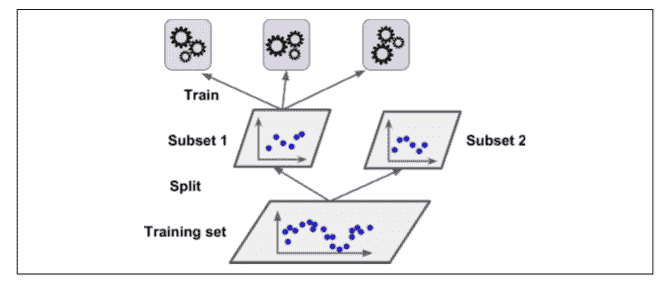
為了訓練這個 *blender* ,一個通用的方法是采用保持集。讓我們看看它怎么工作。首先,訓練集被分為兩個子集,第一個子集被用作訓練第一層(詳見圖 7-13).
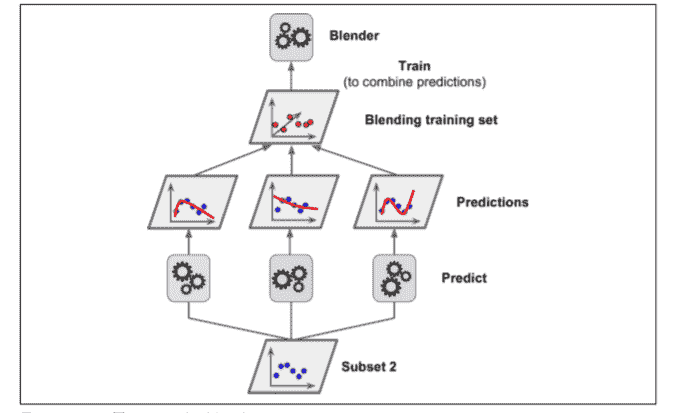
接下來,第一層的分類器被用來預測第二個子集(保持集)(詳見 7-14)。這確保了預測結果很“干凈”,因為這些分類器在訓練的時候沒有使用過這些實例。現在對在保持集中的每一個實例都有三個預測值。我們現在可以使用這些預測結果作為輸入特征來創建一個新的訓練集(這使得這個訓練集是三維的),并且保持目標數值不變。隨后 *blender* 在這個新的訓練集上訓練,因此,它學會了預測第一層預測的目標值。
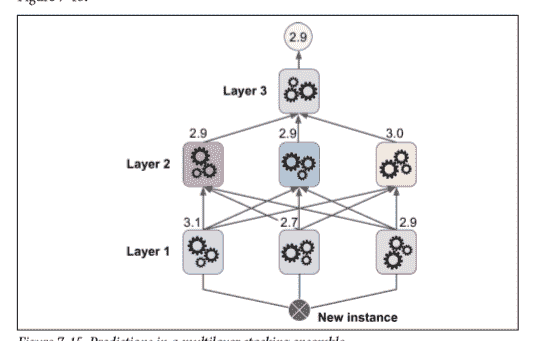
顯然我們可以用這種方法訓練不同的 *blender* (例如一個線性回歸,另一個是隨機森林等等):我們得到了一層 *blender* 。訣竅是將訓練集分成三個子集:第一個子集用來訓練第一層,第二個子集用來創建訓練第二層的訓練集(使用第一層分類器的預測值),第三個子集被用來創建訓練第三層的訓練集(使用第二層分類器的預測值)。以上步驟做完了,我們可以通過逐個遍歷每個層來預測一個新的實例。詳見圖 7-15.
然而不幸的是,sklearn 并不直接支持 stacking ,但是你自己組建是很容易的(看接下來的練習)。或者你也可以使用開源的項目例如 *brew* (網址為 <https://github.com/viisar/brew>)
## 練習
1. 如果你在相同訓練集上訓練 5 個不同的模型,它們都有 95% 的準確率,那么你是否可以通過組合這個模型來得到更好的結果?如果可以那怎么做呢?如果不可以請給出理由。
2. 軟投票和硬投票分類器之間有什么區別?
3. 是否有可能通過分配多個服務器來加速 bagging 集成系統的訓練?pasting 集成,boosting 集成,隨機森林,或 stacking 集成怎么樣?
4. out-of-bag 評價的好處是什么?
5. 是什么使 Extra-Tree 比規則隨機森林更隨機呢?這個額外的隨機有什么幫助呢?那這個 Extra-Tree 比規則隨機森林誰更快呢?
6. 如果你的 Adaboost 模型欠擬合,那么你需要怎么調整超參數?
7. 如果你的梯度提升過擬合,那么你應該調高還是調低學習率呢?
8. 導入 MNIST 數據(第三章中介紹),把它切分進一個訓練集,一個驗證集,和一個測試集(例如 40000 個實例進行訓練,10000 個進行驗證,10000 個進行測試)。然后訓練多個分類器,例如一個隨機森林分類器,一個 Extra-Tree 分類器和一個 SVM。接下來,嘗試將它們組合成集成,使用軟或硬投票分類器來勝過驗證集上的所有集合。一旦找到了,就在測試集上實驗。與單個分類器相比,它的性能有多好?
9. 從練習 8 中運行個體分類器來對驗證集進行預測,并創建一個新的訓練集并生成預測:每個訓練實例是一個向量,包含來自所有分類器的圖像的預測集,目標是圖像類別。祝賀你,你剛剛訓練了一個 *blender* ,和分類器一起組成了一個疊加組合!現在讓我們來評估測試集上的集合。對于測試集中的每個圖像,用所有分類器進行預測,然后將預測饋送到 *blender* 以獲得集合的預測。它與你早期訓練過的投票分類器相比如何?
練習的答案都在附錄 A 上。
