# 十二、使用 TensorFlow 自定義模型并訓練
> 譯者:[@SeanCheney](https://www.jianshu.com/u/130f76596b02)
目前為止,我們只是使用了 TensorFlow 的高級 API —— tf.keras,它的功能很強大:搭建了各種神經網絡架構,包括回歸、分類網絡、Wide & Deep 網絡、自歸一化網絡,使用了各種方法,包括批歸一化、dropout 和學習率調度。事實上,你在實際案例中 95%碰到的情況只需要 tf.keras 就足夠了(和 tf.data,見第 13 章)。現在來深入學習 TensorFlow 的低級 Python API。當你需要實現自定義損失函數、自定義標準、層、模型、初始化器、正則器、權重約束時,就需要低級 API 了。甚至有時需要全面控制訓練過程,例如使用特殊變換或對約束梯度時。這一章就會討論這些問題,還會學習如何使用 TensorFlow 的自動圖生成特征提升自定義模型和訓練算法。首先,先來快速學習下 TensorFlow。
> 筆記:TensorFlow 2.0(beta)是 2019 年六月發布的,相比前代更易使用。本書第一版使用的是 TF 1,這一版使用的是 TF 2。
## TensorFlow 速覽
TensorFlow 是一個強大的數值計算庫,特別適合做和微調大規模機器學習(但也可以用來做其它的重型計算)。TensorFlow 是谷歌大腦團隊開發的,支持了谷歌的許多大規模服務,包括谷歌云對話、谷歌圖片和谷歌搜索。TensorFlow 是 2015 年 11 月開源的,(按文章引用、公司采用、GitHub 星數)是目前最流行的深度學習庫。無數的項目是用 TensorFlow 來做各種機器學習任務,包括圖片分類、自然語言處理、推薦系統和時間序列預測。TensorFlow 提供的功能如下:
* TensorFlow 的核心與 NumPy 很像,但 TensorFlow 支持 GPU;
* TensorFlow 支持(多設備和服務器)分布式計算;
* TensorFlow 使用了即時 JIT 編譯器對計算速度和內存使用優化。編譯器的工作是從 Python 函數提取出計算圖,然后對計算圖優化(比如剪切無用的節點),最后高效運行(比如自動并行運行獨立任務);
* 計算圖可以導出為遷移形式,因此可以在一個環境中訓練一個 TensorFlow 模型(比如使用 Python 或 Linux),然后在另一個環境中運行(比如在安卓設備上用 Java 運行);
* TensorFlow 實現了自動微分,并提供了一些高效的優化器,比如 RMSProp 和 NAdam,因此可以容易的最小化各種損失函數。
基于上面這些特點,TensorFlow 還提供了許多其他功能:最重要的是 tf.keras,還有數據加載和預處理操作(tf.data,tf.io 等等),圖片處理操作(tf.image),信號處理操作(tf.signal),等等(圖 12-1 總結了 TensorFlow 的 Python API)
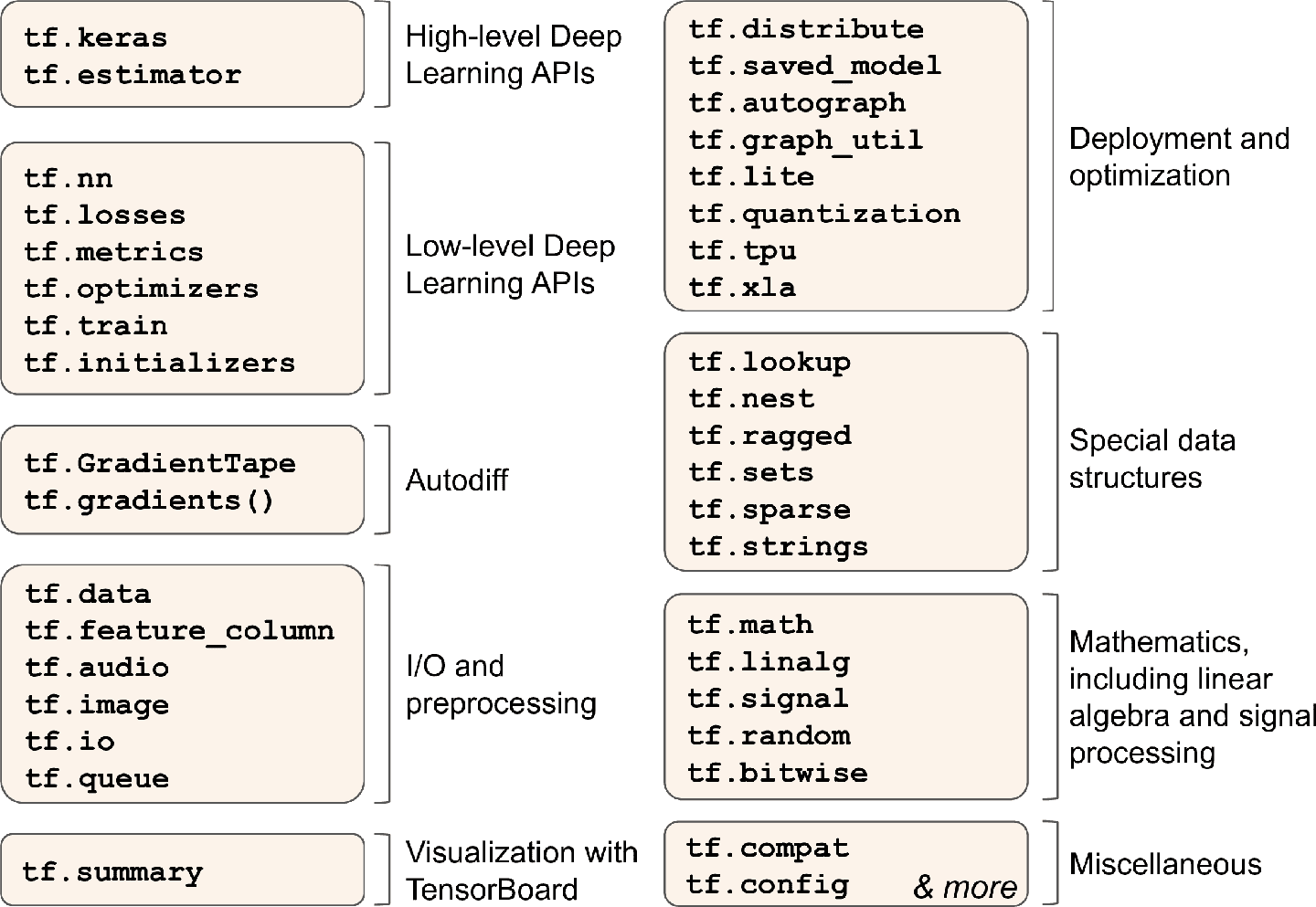圖 12-1 TensorFlow 的 Python API
> 提示:這一章會介紹 TensorFlow API 的多個包和函數,但來不及介紹全部,所以讀者最好自己花點時間好好看看 API。TensorFlow 的 API 十分豐富,且文檔詳實。
TensorFlow 的低級操作都是用高效的 C++實現的。許多操作有多個實現,稱為`核`:每個核對應一個具體的設備型號,比如 CPU、GPU,甚至 TPU(張量處理單元)。GPU 通過將任務分成小塊,在多個 GPU 線程中并行運行,可以極大提高提高計算的速度。TPU 更快:TPU 是自定義的 ASIC 芯片,專門用來做深度學習運算的(第 19 章會討論適合使用 GPU 和 TPU)。
TensorFlow 的架構見圖 12-2。大多數時候你的代碼使用高級 API 就夠了(特別是 tf.keras 和 tf.data),但如果需要更大的靈活性,就需要使用低級 Python API,來直接處理張量。TensorFlow 也支持其它語言的 API。任何情況下,甚至是跨設備和機器的情況下,TensorFlow 的執行引擎都會負責高效運行。
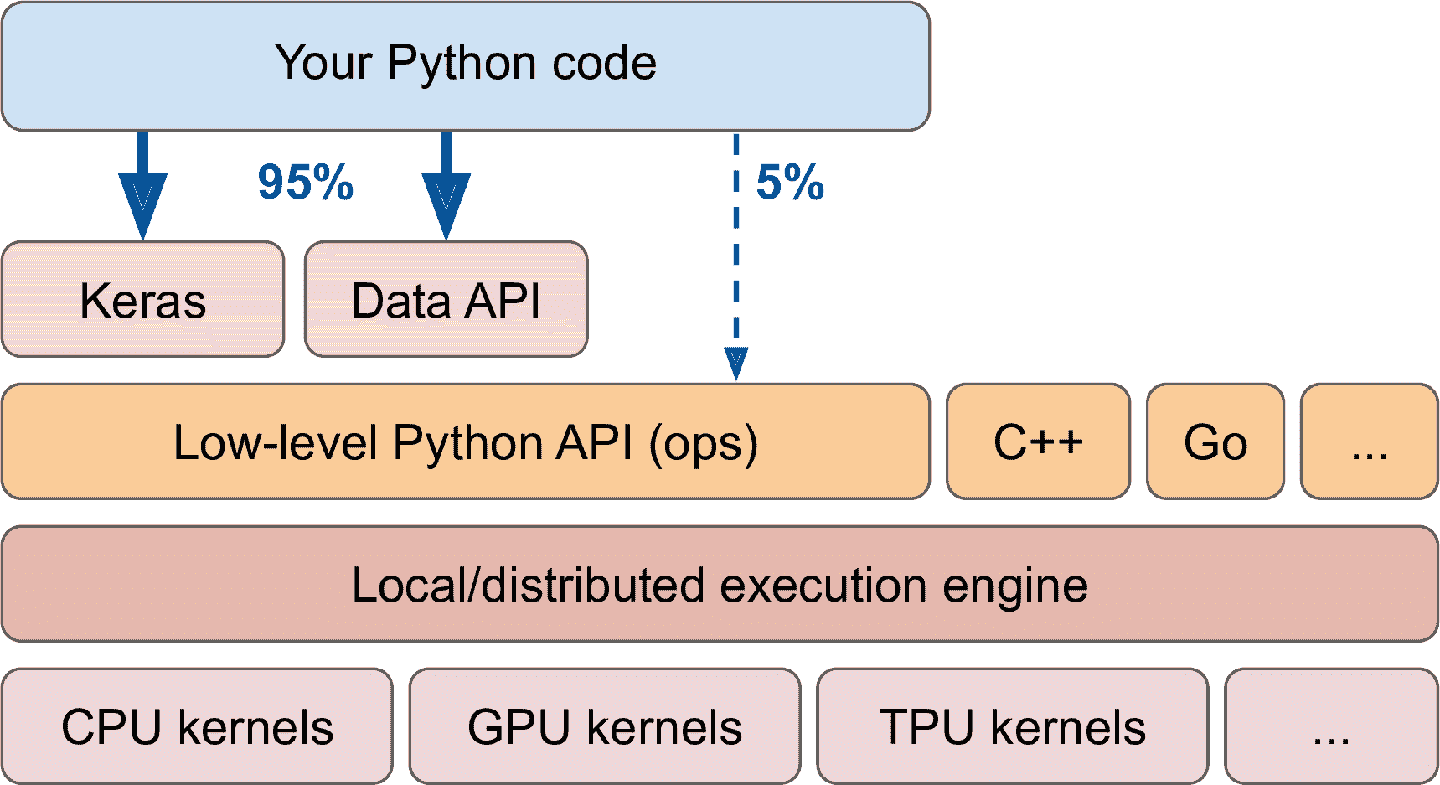圖 12-2 TensorFlow 的架構
TensorFlow 不僅可以運行在 Windows、Linux 和 macOS 上,也可以運行在移動設備上(使用 TensorFlow Lite),包括 iOS 和安卓(見第 19 章)。如果不想使用 Python API,還可以使用 C++、Java、Go 和 Swift 的 API。甚至還有 JavaScript 的實現 TensorFlow.js,它可以直接在瀏覽器中運行。
TensorFlow 不只有這些庫。TensorFlow 處于一套可擴展的生態系統庫的核心位置。首先,TensorBoard 可以用來可視化。其次,TensorFlow Extended(TFX),是谷歌推出的用來生產化的庫,包括:數據確認、預處理、模型分析和服務(使用 TF Serving,見第 19 章)。谷歌的 TensorFlow Hub 上可以方便下載和復用預訓練好的神經網絡。你還可以從 TensorFlow 的 model garden([https://github.com/tensorflow/models/](https://links.jianshu.com/go?to=https%3A%2F%2Fgithub.com%2Ftensorflow%2Fmodels%2F))獲取許多神經網絡架構,其中一些是預訓練好的。[TensorFlow Resources](https://links.jianshu.com/go?to=https%3A%2F%2Fwww.tensorflow.org%2Fresources) 和 [*https://github.com/jtoy/awesome-tensorflow*](https://links.jianshu.com/go?to=https%3A%2F%2Fgithub.com%2Fjtoy%2Fawesome-tensorflow)上有更多的資源。你可以在 GitHub 上找到數百個 TensorFlow 項目,無論干什么都可以方便地找到現成的代碼。
> 提示:越來越多的 ML 論文都附帶了實現過程,一些甚至帶有預訓練模型。可以在[*https://paperswithcode.com/*](https://links.jianshu.com/go?to=https%3A%2F%2Fpaperswithcode.com%2F)找到。
最后,TensorFlow 有一支熱忱滿滿的開發者團隊,也有龐大的社區。要是想問技術問題,可以去[*http://stackoverflow.com/*](https://links.jianshu.com/go?to=http%3A%2F%2Fstackoverflow.com%2F)
,問題上打上 tensorflow 和 python 標簽。還可以在[GitHub](https://links.jianshu.com/go?to=https%3A%2F%2Fgithub.com%2Ftensorflow%2Ftensorflow)上提 bug 和新功能。一般的討論可以去谷歌群組([https://groups.google.com/a/tensorflow.org/forum/](https://links.jianshu.com/go?to=https%3A%2F%2Fgroups.google.com%2Fa%2Ftensorflow.org%2Fforum%2F))。
下面開始寫代碼!
## 像 NumPy 一樣使用 TensorFlow
TensorFlow 的 API 是圍繞張量(tensor)展開的,從一個操作流動(flow)到另一個操作,所以名字叫做 TensorFlow。張量通常是一個多維數組(就像 NumPy 的`ndarray`),但也可以是標量(即簡單值,比如 42)。張量對于自定義的損失函數、標準、層等等非常重要,接下來學習如何創建和操作張量。
### 張量和運算
使用`tf.constant()`創建張量。例如,下面的張量表示的是兩行三列的浮點數矩陣:
```py
>>> tf.constant([[1., 2., 3.], [4., 5., 6.]]) # matrix
<tf.Tensor: id=0, shape=(2, 3), dtype=float32, numpy=
array([[1., 2., 3.],
[4., 5., 6.]], dtype=float32)>
>>> tf.constant(42) # 標量
<tf.Tensor: id=1, shape=(), dtype=int32, numpy=42>
```
就像`ndarray`一樣,`tf.Tensor`也有形狀和數據類型(`dtype`):
```py
>>> t = tf.constant([[1., 2., 3.], [4., 5., 6.]])
>>> t.shape
TensorShape([2, 3])
>>> t.dtype
tf.float32
```
索引和 NumPy 中很像:
```py
>>> t[:, 1:]
<tf.Tensor: id=5, shape=(2, 2), dtype=float32, numpy=
array([[2., 3.],
[5., 6.]], dtype=float32)>
>>> t[..., 1, tf.newaxis]
<tf.Tensor: id=15, shape=(2, 1), dtype=float32, numpy=
array([[2.],
[5.]], dtype=float32)>
```
最重要的,所有張量運算都可以執行:
```py
>>> t + 10
<tf.Tensor: id=18, shape=(2, 3), dtype=float32, numpy=
array([[11., 12., 13.],
[14., 15., 16.]], dtype=float32)>
>>> tf.square(t)
<tf.Tensor: id=20, shape=(2, 3), dtype=float32, numpy=
array([[ 1., 4., 9.],
[16., 25., 36.]], dtype=float32)>
>>> t @ tf.transpose(t)
<tf.Tensor: id=24, shape=(2, 2), dtype=float32, numpy=
array([[14., 32.],
[32., 77.]], dtype=float32)>
```
可以看到,`t + 10`等同于調用`tf.add(t, 10)`,`-`和`*`也支持。`@`運算符是在 Python3.5 中出現的,用于矩陣乘法,等同于調用函數`tf.matmul()`。
可以在 tf 中找到所有基本的數學運算(`tf.add()`、`tf.multiply()`、`tf.square()`、`tf.exp()`、`tf.sqrt()`),以及 NumPy 中的大部分運算(比如`tf.reshape()`、`tf.squeeze()`、`tf.tile()`)。一些 tf 中的函數與 NumPy 中不同,例如,`tf.reduce_mean()`、`tf.reduce_sum()`、`tf.reduce_max()`、`tf.math.log()`等同于`np.mean()`、`np.sum()`、`np.max()`和`np.log()`。當函數名不同時,通常都是有原因的。例如,TensorFlow 中必須使用`tf.transpose(t)`,不能像 NumPy 中那樣使用`t.T`。原因是函數`tf.transpose(t)`所做的和 NumPy 的屬性`T`并不完全相同:在 TensorFlow 中,是使用轉置數據的復制來生成張量的,而在 NumPy 中,`t.T`是數據的轉置視圖。相似的,`tf.reduce_sum()`操作之所以這么命名,是因為它的 GPU 核(即 GPU 實現)所采用的 reduce 算法不能保證元素相加的順序,因為 32 位的浮點數精度有限,每次調用的結果可能會有細微的不同。`tf.reduce_mean()`也是這樣(`tf.reduce_max()`結果是確定的)。
> 筆記:許多函數和類都有假名。比如,`tf.add()`和`tf.math.add()`是相同的。這可以讓 TensorFlow 對于最常用的操作有簡潔的名字,同時包可以有序安置。
> Keras 的低級 API
> Keras API 有自己的低級 API,位于`keras.backend`,包括:函數`square()`、`exp()`、`sqrt()`。在`tf.keras`中,這些函數通常通常只是調用對應的 TensorFlow 操作。如果你想寫一些可以遷移到其它 Keras 實現上,就應該使用這些 Keras 函數。但是這些函數不多,所以這本書里就直接使用 TensorFlow 的運算了。下面是一個簡單的使用了`keras.backend`的例子,簡記為`k`:
>
> ```py
> >>> from tensorflow import keras
> >>> K = keras.backend
> >>> K.square(K.transpose(t)) + 10
> <tf.Tensor: id=39, shape=(3, 2), dtype=float32, numpy=
> array([[11., 26.],
> [14., 35.],
> [19., 46.]], dtype=float32)>
> ```
### 張量和 NumPy
張量和 NumPy 融合地非常好:使用 NumPy 數組可以創建張量,張量也可以創建 NumPy 數組。可以在 NumPy 數組上運行 TensorFlow 運算,也可以在張量上運行 NumPy 運算:
```py
>>> a = np.array([2., 4., 5.])
>>> tf.constant(a)
<tf.Tensor: id=111, shape=(3,), dtype=float64, numpy=array([2., 4., 5.])>
>>> t.numpy() # 或 np.array(t)
array([[1., 2., 3.],
[4., 5., 6.]], dtype=float32)
>>> tf.square(a)
<tf.Tensor: id=116, shape=(3,), dtype=float64, numpy=array([4., 16., 25.])>
>>> np.square(t)
array([[ 1., 4., 9.],
[16., 25., 36.]], dtype=float32)
```
> 警告:NumPy 默認使用 64 位精度,TensorFlow 默認用 32 位精度。這是因為 32 位精度通常對于神經網絡就足夠了,另外運行地更快,使用的內存更少。因此當你用 NumPy 數組創建張量時,一定要設置`dtype=tf.float32`。
### 類型轉換
類型轉換對性能的影響非常大,并且如果類型轉換是自動完成的,不容易被注意到。為了避免這樣,TensorFlow 不會自動做任何類型轉換:只是如果用不兼容的類型執行了張量運算,TensorFlow 就會報異常。例如,不能用浮點型張量與整數型張量相加,也不能將 32 位張量與 64 位張量相加:
```py
>>> tf.constant(2.) + tf.constant(40)
Traceback[...]InvalidArgumentError[...]expected to be a float[...]
>>> tf.constant(2.) + tf.constant(40., dtype=tf.float64)
Traceback[...]InvalidArgumentError[...]expected to be a double[...]
```
這點可能一開始有點惱人,但是有其存在的理由。如果真的需要轉換類型,可以使用`tf.cast()`:
```py
>>> t2 = tf.constant(40., dtype=tf.float64)
>>> tf.constant(2.0) + tf.cast(t2, tf.float32)
<tf.Tensor: id=136, shape=(), dtype=float32, numpy=42.0>
```
### 變量
到目前為止看到的`tf.Tensor`值都是不能修改的。意味著不能使用常規張量實現神經網絡的權重,因為權重必須要能被反向傳播調整。另外,其它的參數也需要隨著時間調整(比如,動量優化器要跟蹤過去的梯度)。此時需要的是`tf.Variable`:
```py
>>> v = tf.Variable([[1., 2., 3.], [4., 5., 6.]])
>>> v
<tf.Variable 'Variable:0' shape=(2, 3) dtype=float32, numpy=
array([[1., 2., 3.],
[4., 5., 6.]], dtype=float32)>
```
`tf.Variable`和`tf.Tensor`很像:可以運行同樣的運算,可以配合 NumPy 使用,也要注意類型。可以使用`assign()`方法對其就地修改(或`assign_add()`、`assign_sub()`)。使用切片的`assign()`方法可以修改獨立的切片(直接賦值行不通),或使用`scatter_update()`、`scatter_nd_update()`方法:
```py
v.assign(2 * v) # => [[2., 4., 6.], [8., 10., 12.]]
v[0, 1].assign(42) # => [[2., 42., 6.], [8., 10., 12.]]
v[:, 2].assign([0., 1.]) # => [[2., 42., 0.], [8., 10., 1.]]
v.scatter_nd_update(indices=[[0, 0], [1, 2]], updates=[100., 200.])
# => [[100., 42., 0.], [8., 10., 200.]]
```
> 筆記:在實踐中,很少需要手動創建變量,因為 Keras 有`add_weight()`方法可以自動來做。另外,模型參數通常會直接通過優化器更新,因此很少需要手動更新。
### 其它數據結構
TensorFlow 還支持其它幾種數據結構,如下(可以參考 notebook 的 Tensors and Operations 部分,或附錄的 F):
稀疏張量(`tf.SparseTensor`)
高效表示含有許多 0 的張量。`tf.sparse`包含有對稀疏張量的運算。
張量數組(`tf.TensorArray`)
是張量的列表。有默認固定大小,但也可以做成動態的。列表中的張量必須形狀相同,數據類型也相同。
嵌套張量(`tf.RaggedTensor`)
張量列表的靜態列表,張量的形狀和數據結構相同。`tf.ragged`包里有嵌套張量的運算。
字符串張量
類型是`tf.string`的常規張量,是字節串而不是 Unicode 字符串,因此如果你用 Unicode 字符串(比如,Python3 字符串 café)創建了一個字符串張量,就會自動被轉換為 UTF-8(b"caf\xc3\xa9")。另外,也可以用`tf.int32`類型的張量表示 Unicode 字符串,其中每項表示一個 Unicode 碼(比如,`[99, 97, 102, 233]`)。`tf.strings`包里有字節串和 Unicode 字符串的運算,以及二者轉換的運算。要注意`tf.string`是原子性的,也就是說它的長度不出現在張量的形狀中,一旦將其轉換成了 Unicode 張量(即,含有 Unicode 碼的`tf.int32`張量),長度才出現在形狀中。
集合
表示為常規張量(或稀疏張量)。例如`tf.constant([[1, 2], [3, 4]])`表示兩個集合{1, 2}和{3, 4}。通常,用張量的最后一個軸的矢量表示集合。集合運算可以用`tf.sets`包。
隊列
用來在多個步驟之間保存張量。TensorFlow 提供了多種隊列。先進先出(FIFO)隊列 FIFOQueue,優先級隊列 PriorityQueue,隨機隊列 RandomShuffleQueue,通過填充的不同形狀的批次項隊列 PaddingFIFOQueue。這些隊列都在`tf.queue`包中。
有了張量、運算、變量和各種數據結構,就可以開始自定義模型和訓練算法啦!
## 自定義模型和訓練算法
先從簡單又常見的任務開始,創建一個自定義的損失函數。
### 自定義損失函數
假如你想訓練一個回歸模型,但訓練集有噪音。你當然可以通過清除或修正異常值來清理數據集,但是這樣還不夠:數據集還是有噪音。此時,該用什么損失函數呢?均方差可能對大誤差懲罰過重,導致模型不準確。均絕對值誤差不會對異常值懲罰過重,但訓練可能要比較長的時間才能收斂,訓練模型也可能不準確。此時使用 Huber 損失(第 10 章介紹過)就比 MSE 好多了。目前官方 Keras API 中沒有 Huber 損失,但 tf.keras 有(使用類`keras.losses.Huber`的實例)。就算 tf.keras 沒有,實現也不難!只需創建一個函數,參數是標簽和預測值,使用 TensorFlow 運算計算每個實例的損失:
```py
def huber_fn(y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < 1
squared_loss = tf.square(error) / 2
linear_loss = tf.abs(error) - 0.5
return tf.where(is_small_error, squared_loss, linear_loss)
```
> 警告:要提高性能,應該像這個例子使用矢量。另外,如果想利用 TensorFlow 的圖特性,則只能使用 TensorFlow 運算。
最好返回一個包含實例的張量,其中每個實例都有一個損失,而不是返回平均損失。這么做的話,Keras 可以在需要時,使用類權重或樣本權重(見第 10 章)。
現在,編譯 Keras 模型時,就可以使用 Huber 損失來訓練了:
```py
model.compile(loss=huber_fn, optimizer="nadam")
model.fit(X_train, y_train, [...])
```
僅此而已!對于訓練中的每個批次,Keras 會調用函數`huber_fn()`計算損失,用損失來做梯度下降。另外,Keras 會從一開始跟蹤總損失,并展示平均損失。
在保存這個模型時,這個自定義損失會發生什么呢?
### 保存并加載包含自定義組件的模型
因為 Keras 可以保存函數名,保存含有自定義損失函數的模型也不成問題。當加載模型時,你需要提供一個字典,這個字典可以將函數名和真正的函數映射起來。一般說來,當加載一個含有自定義對象的模型時,你需要將名字映射到對象上:
```py
model = keras.models.load_model("my_model_with_a_custom_loss.h5",
custom_objects={"huber_fn": huber_fn})
```
對于剛剛的代碼,在-1 和 1 之間的誤差被認為是“小”誤差。如果要改變閾值呢?一個解決方法是創建一個函數,它可以產生一個可配置的損失函數:
```py
def create_huber(threshold=1.0):
def huber_fn(y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < threshold
squared_loss = tf.square(error) / 2
linear_loss = threshold * tf.abs(error) - threshold**2 / 2
return tf.where(is_small_error, squared_loss, linear_loss)
return huber_fn
model.compile(loss=create_huber(2.0), optimizer="nadam")
```
但在保存模型時,`threshold`不能被保存。這意味在加載模型時(注意,給 Keras 的函數名是“Huber_fn”,不是創造這個函數的函數名),必須要指定`threshold`的值:
```py
model = keras.models.load_model("my_model_with_a_custom_loss_threshold_2.h5",
custom_objects={"huber_fn": create_huber(2.0)})
```
要解決這個問題,可以創建一個`keras.losses.Loss`類的子類,然后實現`get_config()`方法:
```py
class HuberLoss(keras.losses.Loss):
def __init__(self, threshold=1.0, **kwargs):
self.threshold = threshold
super().__init__(**kwargs)
def call(self, y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < self.threshold
squared_loss = tf.square(error) / 2
linear_loss = self.threshold * tf.abs(error) - self.threshold**2 / 2
return tf.where(is_small_error, squared_loss, linear_loss)
def get_config(self):
base_config = super().get_config()
return {**base_config, "threshold": self.threshold}
```
> 警告:Keras API 目前只使用子類來定義層、模型、調回和正則器。如果使用子類創建其它組件(比如損失、指標、初始化器或約束),它們不能遷移到其它 Keras 實現上。可能 Keras API 經過更新,就會支持所有組件了。
逐行看下這段代碼:
* 構造器接收`**kwargs`,并將其傳遞給父構造器,父構造器負責處理超參數:損失的`name`,要使用的、用于將單個實例的損失匯總的`reduction`算法。默認情況下是`"sum_over_batch_size"`,意思是損失是各個實例的損失之和,如果有樣本權重,則做權重加權,再除以批次大小(不是除以權重之和,所以不是加權平均)。其它可能的值是`"sum"`和`None`。
* `call()`方法接受標簽和預測值,計算所有實例的損失,并返回。
* `get_config()`方法返回一個字典,將每個超參數映射到值上。它首先調用父類的`get_config()`方法,然后將新的超參數加入字典(`{**x}語法是 Python 3.5 引入的`)。
當編譯模型時,可以使用這個類的實例:
```py
model.compile(loss=HuberLoss(2.), optimizer="nadam")
```
保存模型時,閾值會一起保存;加載模型時,只需將類名映射到具體的類上:
```py
model = keras.models.load_model("my_model_with_a_custom_loss_class.h5",
custom_objects={"HuberLoss": HuberLoss})
```
保存模型時,Keras 調用損失實例的`get_config()`方法,將配置以 JSON 的形式保存在 HDF5 中。當加載模型時,會調用`HuberLoss`類的`from_config()`方法:這個方法是父類`Loss`實現的,創建一個類`Loss`的實例,將`**config`傳遞給構造器。
### 自定義激活函數、初始化器、正則器和約束
Keras 的大多數功能,比如損失、正則器、約束、初始化器、指標、激活函數、層,甚至是完整的模型,都可以用相似的方法做自定義。大多數時候,需要寫一個簡單的函數,帶有合適的輸入和輸出。下面的例子是自定義激活函數(等價于`keras.activations.softplus()`或`tf.nn.softplus()`),自定義 Glorot 初始化器(等價于`keras.initializers.glorot_normal()`),自定義?<sub>1</sub>正則化器(等價于`keras.regularizers.l1(0.01)`),可以保證權重都是正值的自定義約束(等價于`equivalent to keras.constraints.nonneg()`或`tf.nn.relu()`):
```py
def my_softplus(z): # return value is just tf.nn.softplus(z)
return tf.math.log(tf.exp(z) + 1.0)
def my_glorot_initializer(shape, dtype=tf.float32):
stddev = tf.sqrt(2\. / (shape[0] + shape[1]))
return tf.random.normal(shape, stddev=stddev, dtype=dtype)
def my_l1_regularizer(weights):
return tf.reduce_sum(tf.abs(0.01 * weights))
def my_positive_weights(weights): # return value is just tf.nn.relu(weights)
return tf.where(weights < 0., tf.zeros_like(weights), weights)
```
可以看到,參數取決于自定義函數的類型。這些自定義函數可以如常使用,例如:
```py
layer = keras.layers.Dense(30, activation=my_softplus,
kernel_initializer=my_glorot_initializer,
kernel_regularizer=my_l1_regularizer,
kernel_constraint=my_positive_weights)
```
激活函數會應用到這個`Dense`層的輸出上,結果會傳遞到下一層。層的權重會使用初始化器的返回值。在每個訓練步驟,權重會傳遞給正則化函數以計算正則損失,這個損失會與主損失相加,得到訓練的最終損失。最后,會在每個訓練步驟結束后調用約束函數,經過約束的權重會替換層的權重。
如果函數有需要連同模型一起保存的超參數,需要對相應的類做子類,比如`keras.regularizers.Regularizer`,`keras.constraints.Constraint`,`keras.initializers.Initializer`,或 `keras.layers.Layer`(任意層,包括激活函數)。就像前面的自定義損失一樣,下面是一個簡單的?<sub>1</sub>正則類,可以保存它的超參數`factor`(這次不必調用其父構造器或`get_config()`方法,因為它們不是父類定義的):
```py
class MyL1Regularizer(keras.regularizers.Regularizer):
def __init__(self, factor):
self.factor = factor
def __call__(self, weights):
return tf.reduce_sum(tf.abs(self.factor * weights))
def get_config(self):
return {"factor": self.factor}
```
注意,你必須要實現損失、層(包括激活函數)和模型的`call()`方法,或正則化器、初始化器和約束的`__call__()`方法。對于指標,處理方法有所不同。
### 自定義指標
損失和指標的概念是不一樣的:梯度下降使用損失(比如交叉熵損失)來訓練模型,因此損失必須是可微分的(至少是在評估點可微分),梯度不能在所有地方都是 0。另外,就算損失比較難解釋也沒有關系。相反的,指標(比如準確率)是用來評估模型的:指標的解釋性一定要好,可以是不可微分的,或者可以在任何地方的梯度都是 0。
但是,在多數情況下,定義一個自定義指標函數和定義一個自定義損失函數是完全一樣的。事實上,剛才創建的 Huber 損失函數也可以用來當指標(持久化也是同樣的,只需要保存函數名“Huber_fn”就成):
```py
model.compile(loss="mse", optimizer="nadam", metrics=[create_huber(2.0)])
```
對于訓練中的每個批次,Keras 能計算該指標,并跟蹤自周期開始的指標平均值。大多數時候,這樣沒有問題。但會有例外!比如,考慮一個二元分類器的準確性。第 3 章介紹過,準確率是真正值除以正預測數(包括真正值和假正值)。假設模型在第一個批次做了 5 個正預測,其中 4 個是正確的,準確率就是 80%。再假設模型在第二個批次做了 3 次正預測,但沒有一個預測對,則準確率是 0%。如果對這兩個準確率做平均,則平均值是 40%。但它不是模型在兩個批次上的準確率!事實上,真正值總共有 4 個,正預測有 8 個,整體的準確率是 50%。我們需要的是一個能跟蹤真正值和正預測數的對象,用該對象計算準確率。這就是類`keras.metrics.Precision`所做的:
```py
>>> precision = keras.metrics.Precision()
>>> precision([0, 1, 1, 1, 0, 1, 0, 1], [1, 1, 0, 1, 0, 1, 0, 1])
<tf.Tensor: id=581729, shape=(), dtype=float32, numpy=0.8>
>>> precision([0, 1, 0, 0, 1, 0, 1, 1], [1, 0, 1, 1, 0, 0, 0, 0])
<tf.Tensor: id=581780, shape=(), dtype=float32, numpy=0.5>
```
在這個例子中,我們創建了一個`Precision`對象,然后將其用作函數,將第一個批次的標簽和預測傳給它,然后傳第二個批次的數據(這里也可以傳樣本權重)。數據和前面的真正值和正預測一樣。第一個批次之后,正確率是 80%;第二個批次之后,正確率是 50%(這是完整過程的準確率,不是第二個批次的準確率)。這叫做流式指標(或者靜態指標),因為他是一個批次接一個批次,逐次更新的。
任何時候,可以調用`result()`方法獲取指標的當前值。還可以通過`variables`屬性,查看指標的變量(跟蹤正預測和負預測的數量),還可以用`reset_states()`方法重置變量:
```py
>>> p.result()
<tf.Tensor: id=581794, shape=(), dtype=float32, numpy=0.5>
>>> p.variables
[<tf.Variable 'true_positives:0' [...] numpy=array([4.], dtype=float32)>,
<tf.Variable 'false_positives:0' [...] numpy=array([4.], dtype=float32)>]
>>> p.reset_states() # both variables get reset to 0.0
```
如果想創建一個這樣的流式指標,可以創建一個`keras.metrics.Metric`類的子類。下面的例子跟蹤了完整的 Huber 損失,以及實例的數量。當查詢結果時,就能返回比例值,該值就是平均 Huber 損失:
```py
class HuberMetric(keras.metrics.Metric):
def __init__(self, threshold=1.0, **kwargs):
super().__init__(**kwargs) # handles base args (e.g., dtype)
self.threshold = threshold
self.huber_fn = create_huber(threshold)
self.total = self.add_weight("total", initializer="zeros")
self.count = self.add_weight("count", initializer="zeros")
def update_state(self, y_true, y_pred, sample_weight=None):
metric = self.huber_fn(y_true, y_pred)
self.total.assign_add(tf.reduce_sum(metric))
self.count.assign_add(tf.cast(tf.size(y_true), tf.float32))
def result(self):
return self.total / self.count
def get_config(self):
base_config = super().get_config()
return {**base_config, "threshold": self.threshold}
```
逐行看下代碼:
* 構造器使用`add_weight()`方法來創建用來跟蹤多個批次的變量 —— 在這個例子中,就是 Huber 損失的和(`total`)和實例的數量(`count`)。如果愿意的話,可以手動創建變量。Keras 會跟中任何被設為屬性的`tf.Variable`(更一般的講,任何“可追蹤對象”,比如層和模型)。
* 當將這個類的實例當做函數使用時會調用`update_state()`方法(正如`Precision`對象)。它能用每個批次的標簽和預測值(還有樣本權重,但這個例子忽略了樣本權重)來更新變量。
* `result()`方法計算并返回最終值,在這個例子中,是返回所有實例的平均 Huber 損失。當你將指標用作函數時,`update_state()`方法先被調用,然后調用`result()`方法,最后返回輸出。
* 還實現了`get_config()`方法,用以確保`threshold`和模型一起存儲。
* `reset_states()`方法默認將所有值重置為 0.0(也可以改為其它值)。
> 筆記:Keras 能無縫處理變量持久化。
當用簡單函數定義指標時,Keras 會在每個批次自動調用它,還能跟蹤平均值,就和剛才的手工處理一模一樣。因此,`HuberMetric`類的唯一好處是`threshold`可以進行保存。當然,一些指標,比如準確率,不能簡單的平均化;對于這些例子,只能實現一個流式指標。
創建好了流式指標,再創建自定義層就很簡單了。
### 自定義層
有時候你可能想搭建一個架構,但 TensorFlow 沒有提供默認實現。這種情況下,就需要創建自定義層。否則只能搭建出的架構會是簡單重復的,包含相同且重復的層塊,每個層塊實際上就是一個層而已。比如,如果模型的層順序是 A、B、C、A、B、C、A、B、C,則完全可以創建一個包含 A、B、C 的自定義層 D,模型就可以簡化為 D、D、D。
如何創建自定義層呢?首先,一些層沒有權重,比如`keras.layers.Flatten`或`keras.layers.ReLU`。如果想創建一個沒有任何權重的自定義層,最簡單的方法是協議個函數,將其包裝進`keras.layers.Lambda`層。比如,下面的層會對輸入做指數運算:
```py
exponential_layer = keras.layers.Lambda(lambda x: tf.exp(x))
```
這個自定義層可以像任何其它層一樣使用 Sequential API、Functional API 或 Subclassing API。你還可以將其用作激活函數(或者使用`activation=tf.exp`,`activation=keras.activations.exponential`,或者`activation="exponential"`)。當預測值的數量級不同時,指數層有時用在回歸模型的輸出層。
你可能猜到了,要創建自定義狀態層(即,有權重的層),需要創建`keras.layers.Layer`類的子類。例如,下面的類實現了一個緊密層的簡化版本:
```py
class MyDense(keras.layers.Layer):
def __init__(self, units, activation=None, **kwargs):
super().__init__(**kwargs)
self.units = units
self.activation = keras.activations.get(activation)
def build(self, batch_input_shape):
self.kernel = self.add_weight(
name="kernel", shape=[batch_input_shape[-1], self.units],
initializer="glorot_normal")
self.bias = self.add_weight(
name="bias", shape=[self.units], initializer="zeros")
super().build(batch_input_shape) # must be at the end
def call(self, X):
return self.activation(X @ self.kernel + self.bias)
def compute_output_shape(self, batch_input_shape):
return tf.TensorShape(batch_input_shape.as_list()[:-1] + [self.units])
def get_config(self):
base_config = super().get_config()
return {**base_config, "units": self.units,
"activation": keras.activations.serialize(self.activation)}
```
逐行看下代碼:
* 構造器將所有超參數作為參數(這個例子中,是`units`和`activation`),更重要的,它還接收一個`**kwargs`參數。接著初始化了父類,傳給父類`kwargs`:它負責標準參數,比如`input_shape`、`trainable`和`name`。然后將超參數存為屬性,使用`keras.activations.get()`函數(這個函數接收函數、標準字符串,比如“relu”、“selu”、或“None”),將`activation`參數轉換為合適的激活函數。
* `build()`方法通過對每個權重調用`add_weight()`方法,創建層的變量。層第一次被使用時,調用`build()`方法。此時,Keras 能知道該層輸入的形狀,并傳入`build()`方法,這對創建權重是必要的。例如,需要知道前一層的神經元數量,來創建連接權重矩陣(即,`"kernel"`):對應的是輸入的最后一維的大小。在`build()`方法最后(也只是在最后),必須調用父類的`build()`方法:這步告訴 Keras 這個層建好了(或者設定`self.built=True`)。
* `call()`方法執行預想操作。在這個例子中,計算了輸入`X`和層的核的矩陣乘法,加上了偏置矢量,對結果使用了激活函數,得到了該層的輸出。
* `compute_output_shape()`方法只是返回了該層輸出的形狀。在這個例子中,輸出和輸入的形狀相同,除了最后一維被替換成了層的神經元數。在 tf.keras 中,形狀是`tf.TensorShape`類的實例,可以用`as_list()`轉換為 Python 列表。
* `get_config()`方法和前面的自定義類很像。注意是通過調用`keras.activations.serialize()`,保存了激活函數的完整配置。
現在,就可以像其它層一樣,使用`MyDense`層了!
> 筆記:一般情況下,可以忽略`compute_output_shape()`方法,因為 tf.keras 能自動推斷輸出的形狀,除非層是動態的(后面會看到動態層)。在其它 Keras 實現中,要么需要`compute_output_shape()`方法,要么默認輸出形狀和輸入形狀相同。
要創建一個有多個輸入(比如`Concatenate`)的層,`call()`方法的參數應該是包含所有輸入的元組。相似的,`compute_output_shape()`方法的參數應該是一個包含每個輸入的批次形狀的元組。要創建一個有多輸出的層,`call()`方法要返回輸出的列表,`compute_output_shape()`方法要返回批次輸出形狀的列表(每個輸出一個形狀)。例如,下面的層有兩個輸入和三個輸出:
```py
class MyMultiLayer(keras.layers.Layer):
def call(self, X):
X1, X2 = X
return [X1 + X2, X1 * X2, X1 / X2]
def compute_output_shape(self, batch_input_shape):
b1, b2 = batch_input_shape
return [b1, b1, b1] # 可能需要處理廣播規則
```
這個層現在就可以像其它層一樣使用了,但只能使用 Functional 和 Subclassing API,Sequential API 不成(只能使用單輸入和單輸出的層)。
如果你的層需要在訓練和測試時有不同的行為(比如,如果使用`Dropout` 或 `BatchNormalization`層),那么必須給`call()`方法加上`training`參數,用這個參數確定該做什么。比如,創建一個在訓練中(為了正則)添加高斯造影的層,但不改動訓練(Keras 有一個層做了同樣的事,`keras.layers.GaussianNoise`):
```py
class MyGaussianNoise(keras.layers.Layer):
def __init__(self, stddev, **kwargs):
super().__init__(**kwargs)
self.stddev = stddev
def call(self, X, training=None):
if training:
noise = tf.random.normal(tf.shape(X), stddev=self.stddev)
return X + noise
else:
return X
def compute_output_shape(self, batch_input_shape):
return batch_input_shape
```
上面這些就能讓你創建自定義層了!接下來看看如何創建自定義模型。
### 自定義模型
第 10 章在討論 Subclassing API 時,接觸過創建自定義模型的類。說白了:創建`keras.Model`類的子類,創建層和變量,用`call()`方法完成模型想做的任何事。假設你想搭建一個圖 12-3 中的模型。
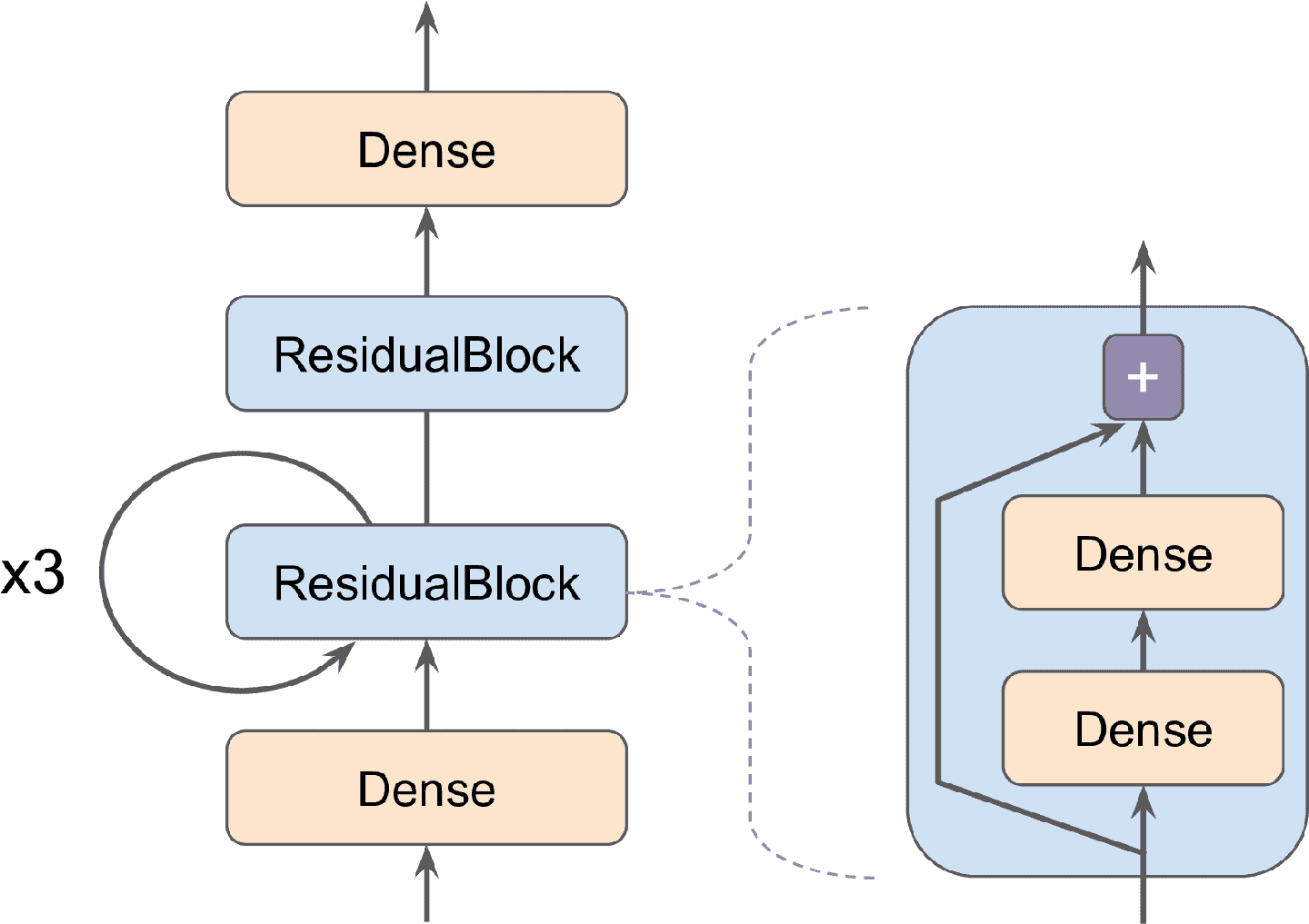圖 12-3 自定義模型案例:包含殘差塊層,殘塊層含有跳連接
輸入先進入一個緊密層,然后進入包含兩個緊密層和一個添加操作的殘差塊(第 14 章會看見,殘差塊將輸入和輸出相加),經過 3 次同樣的殘差塊,再通過第二個殘差塊,最終結果通過一個緊密輸出層。這個模型沒什么意義,只是一個搭建任意結構(包含循環和跳連接)模型的例子。要實現這個模型,最好先創建`ResidualBlock`層,因為這個層要用好幾次:
```py
class ResidualBlock(keras.layers.Layer):
def __init__(self, n_layers, n_neurons, **kwargs):
super().__init__(**kwargs)
self.hidden = [keras.layers.Dense(n_neurons, activation="elu",
kernel_initializer="he_normal")
for _ in range(n_layers)]
def call(self, inputs):
Z = inputs
for layer in self.hidden:
Z = layer(Z)
return inputs + Z
```
這個層稍微有點特殊,因為它包含了其它層。用 Keras 來實現:自動檢測`hidden`屬性包含可追蹤對象(即,層),內含層的變量可以自動添加到整層的變量列表中。類的其它部分很好懂。接下來,使用 Subclassing API 定義模型:
```py
class ResidualRegressor(keras.Model):
def __init__(self, output_dim, **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(30, activation="elu",
kernel_initializer="he_normal")
self.block1 = ResidualBlock(2, 30)
self.block2 = ResidualBlock(2, 30)
self.out = keras.layers.Dense(output_dim)
def call(self, inputs):
Z = self.hidden1(inputs)
for _ in range(1 + 3):
Z = self.block1(Z)
Z = self.block2(Z)
return self.out(Z)
```
在構造器中創建層,在`call()`方法中使用。這個模型可以像其它模型那樣來使用(編譯、擬合、評估、預測)。如果你還想使用`save()`方法保存模型,使用`keras.models.load_model()`方法加載模型,則必須在`ResidualBlock`類和`ResidualRegressor`類中實現`get_config()`方法。另外,可以使用`save_weights()`方法和`load_weights()`方法保存和加載權重。
`Model`類是`Layer`類的子類,因此模型可以像層一樣定義和使用。但是模型還有一些其它的功能,包括`compile()`、`fit()`、`evaluate()` 和`predict()`(還有一些變量),還有`get_layers()`方法(它能通過名字或序號返回模型的任意層)、`save()`方法(支持`keras.models.load_model()`和`keras.models.clone_model()`)。
> 提示:如果模型提供的功能比層多,為什么不講每一個層定義為模型呢?技術上當然可以這么做,但對內部組件和模型(即,層或可重復使用的層塊)加以區別,可以更加清晰。前者應該是`Layer`類的子類,后者應該是`Model`類的子類。
掌握了上面的方法,你就可以使用 Sequential API、Functional API、Subclassing API 搭建幾乎任何文章上的模型了。為什么是“幾乎”?因為還有些內容需要掌握:首先,如何基于模型內部定義損失或指標,第二,如何搭建自定義訓練循環。
### 基于模型內部的損失和指標
前面的自定義損失和指標都是基于標簽和預測(或者還有樣本權重)。有時,你可能想基于模型的其它部分定義損失,比如隱藏層的權重或激活函數。這么做,可以是處于正則的目的,或監督模型的內部。
要基于模型內部自定義損失,需要先做基于這些組件的計算,然后將結果傳遞給`add_loss()`方法。例如,自定義一個包含五個隱藏層加一個輸出層的回歸 MLP 模型。這個自定義模型基于上層的隱藏層,還有一個輔助的輸出。和輔助輸出關聯的損失,被稱為重建損失(見第 17 章):它是重建和輸入的均方差。通過將重建誤差添加到主損失上,可以鼓勵模型通過隱藏層保留盡量多的信息,即便是那些對回歸任務沒有直接幫助的信息。在實際中,重建損失有助于提高泛化能力(它是一個正則損失)。下面是含有自定義重建損失的自定義模型:
```py
class ReconstructingRegressor(keras.Model):
def __init__(self, output_dim, **kwargs):
super().__init__(**kwargs)
self.hidden = [keras.layers.Dense(30, activation="selu",
kernel_initializer="lecun_normal")
for _ in range(5)]
self.out = keras.layers.Dense(output_dim)
def build(self, batch_input_shape):
n_inputs = batch_input_shape[-1]
self.reconstruct = keras.layers.Dense(n_inputs)
super().build(batch_input_shape)
def call(self, inputs):
Z = inputs
for layer in self.hidden:
Z = layer(Z)
reconstruction = self.reconstruct(Z)
recon_loss = tf.reduce_mean(tf.square(reconstruction - inputs))
self.add_loss(0.05 * recon_loss)
return self.out(Z)
```
逐行看下代碼:
* 構造器搭建了一個有五個緊密層和一個緊密輸出層的 DNN。
* `build()`方法創建了另一個緊密層,可以重建模型的輸入。必須要在這里創建`build()`方法的原因,是單元的數量必須等于輸入數,而輸入數在調用`build()`方法之前是不知道的。
* `call()`方法處理所有五個隱藏層的輸入,然后將結果傳給重建層,重建層產生重建。
* `call()`方法然后計算重建損失(重建和輸入的均方差),然后使用`add_loss()`方法,將其加到模型的損失列表上。注意,這里對重建損失乘以了 0.05(這是個可調節的超參數),做了縮小,以確保重建損失不主導主損失。
* 最后,`call()`方法將隱藏層的輸出傳遞給輸出層,然后返回輸出。
相似的,可以加上一個基于模型內部的自定義指標。例如,可以在構造器中創建一個`keras.metrics.Mean`對象,然后在`call()`方法中調用它,傳遞給它`recon_loss`,最后通過`add_metric()`方法,將其添加到模型上。使用這種方式,在訓練模型時,Keras 能展示每個周期的平均損失(損失是主損失加上 0,05 乘以重建損失),和平均重建誤差。兩者都會在訓練過程中下降:
```py
Epoch 1/5
11610/11610 [=============] [...] loss: 4.3092 - reconstruction_error: 1.7360
Epoch 2/5
11610/11610 [=============] [...] loss: 1.1232 - reconstruction_error: 0.8964
[...]
```
在超過 99%的情況中,前面所討論的內容已經足夠搭建你想要的模型了,就算是包含復雜架構、損失和指標也行。但是,在某些極端情況,你還需要自定義訓練循環。介紹之前,先來看看 TensorFlow 如何自動計算梯度。
### 使用自動微分計算梯度
要搞懂如何使用自動微分自動計算梯度,來看一個例子:
```py
def f(w1, w2):
return 3 * w1 ** 2 + 2 * w1 * w2
```
如果你會微積分,就能算出這個函數對`w1`的偏導是`6 * w1 + 2 * w2`,還能算出它對`w2`的偏導是`2 * w1`。例如,在點`(w1, w2) = (5, 3)`,這兩個偏導數分別是 36 和 10,在這個點的梯度矢量就是(36, 10)。但對于神經網絡來說,函數會復雜得多,可能會有上完個參數,用手算偏導幾乎是不可能的任務。一個解決方法是計算每個偏導的大概值,通過調節參數,查看輸出的變化:
```py
>>> w1, w2 = 5, 3
>>> eps = 1e-6
>>> (f(w1 + eps, w2) - f(w1, w2)) / eps
36.000003007075065
>>> (f(w1, w2 + eps) - f(w1, w2)) / eps
10.000000003174137
```
這種方法很容易實現,但只是大概。重要的是,需要對每個參數至少要調用一次`f()`(不是至少兩次,因為可以只計算一次`f(w1, w2)`)。這樣,對于大神經網絡,就不怎么可控。所以,應該使用自動微分。TensorFlow 的實現很簡單:
```py
w1, w2 = tf.Variable(5.), tf.Variable(3.)
with tf.GradientTape() as tape:
z = f(w1, w2)
gradients = tape.gradient(z, [w1, w2])
```
先定義了兩個變量`w1` 和 `w2`,然后創建了一個`tf.GradientTape`上下文,它能自動記錄變臉的每個操作,最后使用它算出結果`z`關于兩個變量`[w1, w2]`的梯度。TensorFlow 計算的梯度如下:
```py
>>> gradients
[<tf.Tensor: id=828234, shape=(), dtype=float32, numpy=36.0>,
<tf.Tensor: id=828229, shape=(), dtype=float32, numpy=10.0>]
```
很好!不僅結果是正確的(準確度只受浮點誤差限制),`gradient()`方法只逆向算了一次,無論有多少個變量,效率很高。
> 提示:為了節省內存,只將嚴格的最小值放在`tf.GradientTape()`中。另外,通過`在 tf.GradientTape()`中創建一個`tape.stop_recording()`來暫停記錄。
當調用記錄器的`gradient()`方法時,記錄器會自動清零,所以調用兩次`gradient()`就會報錯:
```py
with tf.GradientTape() as tape:
z = f(w1, w2)
dz_dw1 = tape.gradient(z, w1) # => tensor 36.0
dz_dw2 = tape.gradient(z, w2) # 運行時錯誤
```
如果需要調用`gradient()`一次以上,比續將記錄器持久化,并在每次用完之后刪除,釋放資源:
```py
with tf.GradientTape(persistent=True) as tape:
z = f(w1, w2)
dz_dw1 = tape.gradient(z, w1) # => tensor 36.0
dz_dw2 = tape.gradient(z, w2) # => tensor 10.0, works fine now!
del tape
```
默認情況下,記錄器只會跟蹤包含變量的操作,所以如果是計算`z`的梯度,`z`和變量沒關系,結果就會是 None:
```py
c1, c2 = tf.constant(5.), tf.constant(3.)
with tf.GradientTape() as tape:
z = f(c1, c2)
gradients = tape.gradient(z, [c1, c2]) # returns [None, None]
```
但是,你也可以強制記錄器監視任何你想監視的張量,將它們當做變量來計算梯度:
```py
with tf.GradientTape() as tape:
tape.watch(c1)
tape.watch(c2)
z = f(c1, c2)
gradients = tape.gradient(z, [c1, c2]) # returns [tensor 36., tensor 10.]
```
在某些情況下,這么做會有幫助,比如當輸入的波動很小,而激活函數結果波動很大時,要實現一個正則損失,就可以這么做:損失會基于激活函數結果,激活函數結果會基于輸入。因為輸入不是變量,就需要記錄器監視輸入。
大多數時候,梯度記錄器被用來計算單一值(通常是損失)的梯度。這就是自動微分發揮長度的地方了。因為自動微分只需要一次向前傳播一次向后傳播,就能計算所有梯度。如果你想計算一個矢量的梯度,比如一個包含多個損失的矢量,TensorFlow 就會計算矢量和的梯度。因此,如果你需要計算單個梯度的話(比如每個損失相對于模型參數的梯度),你必須調用記錄器的`jabobian()`方法:它能做反向模式的自動微分,一次計算完矢量中的所有損失(默認是并行的)。甚至還可以計算二級偏導,但在實際中用的不多(見 notebook 中的“自動微分計算梯度部分”)。
某些情況下,你可能想讓梯度在部分神經網絡停止傳播。要這么做的話,必須使用`tf.stop_gradient()`函數。它能在前向傳播中(比如`tf.identity()`)返回輸入,并能阻止梯度反向傳播(就像常量一樣):
```py
def f(w1, w2):
return 3 * w1 ** 2 + tf.stop_gradient(2 * w1 * w2)
with tf.GradientTape() as tape:
z = f(w1, w2) # same result as without stop_gradient()
gradients = tape.gradient(z, [w1, w2]) # => returns [tensor 30., None]
```
最后,在計算梯度時可能還會碰到數值問題。例如,如果對于很大的輸入,計算`my_softplus()`函數的梯度,結果會是 NaN:
```py
>>> x = tf.Variable([100.])
>>> with tf.GradientTape() as tape:
... z = my_softplus(x)
...
>>> tape.gradient(z, [x])
<tf.Tensor: [...] numpy=array([nan], dtype=float32)>
```
這是因為使用自動微分計算這個函數的梯度,會有些數值方面的難點:因為浮點數的精度誤差,自動微分最后會變成無窮除以無窮(結果是 NaN)。幸好,softplus 函數的導數是`1 / (1 + 1 / exp(x))`,它是數值穩定的。接著,讓 TensorFlow 使用這個穩定的函數,通過裝飾器`@tf.custom_gradient`計算`my_softplus()`的梯度,既返回正常輸出,也返回計算導數的函數(注意:它會接收的輸入是反向傳播的梯度;根據鏈式規則,應該乘以函數的梯度):
```py
@tf.custom_gradient
def my_better_softplus(z):
exp = tf.exp(z)
def my_softplus_gradients(grad):
return grad / (1 + 1 / exp)
return tf.math.log(exp + 1), my_softplus_gradients
```
計算好了`my_better_softplus()`的梯度,就算對于特別大的輸入值,也能得到正確的結果(但是,因為指數運算,主輸出還是會發生爆炸;繞過的方法是,當輸出很大時,使用`tf.where()`返回輸入)。
祝賀你!現在你就可以計算任何函數的梯度(只要函數在計算點可微就行),甚至可以阻止反向傳播,還能寫自己的梯度函數!TensorFlow 的靈活性還能讓你編寫自定義的訓練循環。
### 自定義訓練循環
在某些特殊情況下,`fit()`方法可能不夠靈活。例如,第 10 章討論過的 Wide & Deep 論文使用了兩個優化器:一個用于寬路線,一個用于深路線。因為`fit()`方法智能使用一個優化器(編譯時設置的優化器),要實現這篇論文就需要寫自定義循環。
你可能還想寫自定義的訓練循環,只是想讓訓練過程更加可控(也許你對`fit()`方法的細節并不確定)。但是,自定義訓練循環會讓代碼變長、更容易出錯、也難以維護。
> 提示:除非真的需要自定義,最好還是使用`fit()`方法,而不是自定義訓練循環,特別是當你是在一個團隊之中時。
首先,搭建一個簡單的模型。不用編譯,因為是要手動處理訓練循環:
```py
l2_reg = keras.regularizers.l2(0.05)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="elu", kernel_initializer="he_normal",
kernel_regularizer=l2_reg),
keras.layers.Dense(1, kernel_regularizer=l2_reg)
])
```
接著,創建一個小函數,它能從訓練集隨機采樣一個批次的實例(第 13 章會討論更便捷的 Data API):
```py
def random_batch(X, y, batch_size=32):
idx = np.random.randint(len(X), size=batch_size)
return X[idx], y[idx]
```
再定義一個可以展示訓練狀態的函數,包括步驟數、總步驟數、平均損失(用`Mean`指標計算),和其它指標:
```py
def print_status_bar(iteration, total, loss, metrics=None):
metrics = " - ".join(["{}: {:.4f}".format(m.name, m.result())
for m in [loss] + (metrics or [])])
end = "" if iteration < total else "\n"
print("\r{}/{} - ".format(iteration, total) + metrics,
end=end)
```
這段代碼不難,除非你對 Python 字符串的`{:.4f}`不熟:它的作用是保留四位小數。使用`\r`(回車)和`end=""`連用,保證狀態條總是打印在一條線上。notebook 中,`print_status_bar()`函數包括進度條,也可以使用`tqdm`庫。
有了這些準備,就可以開干了!首先,我們定義超參數、選擇優化器、損失函數和指標(這個例子中是 MAE):
```py
n_epochs = 5
batch_size = 32
n_steps = len(X_train) // batch_size
optimizer = keras.optimizers.Nadam(lr=0.01)
loss_fn = keras.losses.mean_squared_error
mean_loss = keras.metrics.Mean()
metrics = [keras.metrics.MeanAbsoluteError()]
```
可以搭建自定義循環了:
```py
for epoch in range(1, n_epochs + 1):
print("Epoch {}/{}".format(epoch, n_epochs))
for step in range(1, n_steps + 1):
X_batch, y_batch = random_batch(X_train_scaled, y_train)
with tf.GradientTape() as tape:
y_pred = model(X_batch, training=True)
main_loss = tf.reduce_mean(loss_fn(y_batch, y_pred))
loss = tf.add_n([main_loss] + model.losses)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
mean_loss(loss)
for metric in metrics:
metric(y_batch, y_pred)
print_status_bar(step * batch_size, len(y_train), mean_loss, metrics)
print_status_bar(len(y_train), len(y_train), mean_loss, metrics)
for metric in [mean_loss] + metrics:
metric.reset_states()
```
逐行看下代碼:
* 創建了兩個嵌套循環:一個是給周期的,一個是給周期里面的批次的。
* 然后從訓練集隨機批次采樣。
* 在`tf.GradientTape()`內部,對一個批次做了預測(將模型用作函數),計算其損失:損失等于主損失加上其它損失(在這個模型中,每層有一個正則損失)。因為`mean_squared_error()`函數給每個實例返回一個損失,使用`tf.reduce_mean()`計算平均值(如果愿意的話,每個實例可以用不同的權重)。正則損失已經轉變為單個的標量,所以只需求和就成(使用`tf.add_n()`,它能將相同形狀和數據類型的張量求和)。
* 接著,讓記錄器計算損失相對于每個可訓練變量的梯度(不是所有的變量!),然后用優化器對梯度做梯度下降。
* 然后,更新(當前周期)平均損失和平均指標,顯示狀態條。
* 在每個周期結束后,再次展示狀態條,使其完整,然后換行,重置平均損失和平均指標。
如果設定優化器的`clipnorm`或`clipvalue`超參數,就可以自動重置。如果你想對梯度做任何其它變換,在調用`apply_gradients()`方法之前,做變換就行。
如果你對模型添加了權重約束(例如,添加層時設置`kernel_constraint`或`bias_constraint`),你需要在`apply_gradients()`之后,更新訓練循環,以應用這些約束:
```py
for variable in model.variables:
if variable.constraint is not None:
variable.assign(variable.constraint(variable))
```
最重要的,這個訓練循環沒有處理訓練和測試過程中,行為不一樣的層(例如,`BatchNormalization`或`Dropout`)。要處理的話,需要調用模型,令`training=True`,并傳播到需要這么設置的每一層。
可以看到,有這么多步驟都要做對才成,很容易出錯。但另一方面,訓練的控制權完全在你手里。
現在你知道如何自定義模型中的任何部分了,也知道如何訓練算法了,接下來看看如何使用 TensorFlow 的自動圖生成特征:它能顯著提高自定義代碼的速度,并且還是可遷移的(見第 19 章)。
## TensorFlow 的函數和圖
在 TensorFlow 1 中,圖是繞不過去的(同時圖也很復雜),因為圖是 TensorFlow 的 API 的核心。在 TensorFlow 2 中,圖還在,但不是核心了,使用也簡單多了。為了演示其易用性,從一個三次方函數開始:
```py
def cube(x):
return x ** 3
```
可以用一個值調用這個函數,整數、浮點數都成,或者用張量來調用:
```py
>>> cube(2)
8
>>> cube(tf.constant(2.0))
<tf.Tensor: id=18634148, shape=(), dtype=float32, numpy=8.0>
```
現在,使用`tf.function()`將這個 Python 函數變為 TensorFlow 函數:
```py
>>> tf_cube = tf.function(cube)
>>> tf_cube
<tensorflow.python.eager.def_function.Function at 0x1546fc080>
```
可以像原生 Python 函數一樣使用這個 TF 函數,可以返回同樣的結果(張量):
```py
>>> tf_cube(2)
<tf.Tensor: id=18634201, shape=(), dtype=int32, numpy=8>
>>> tf_cube(tf.constant(2.0))
<tf.Tensor: id=18634211, shape=(), dtype=float32, numpy=8.0>
```
`tf.function()`在底層分析了`cube()`函數的計算,然后生成了一個等價的計算圖!可以看到,過程十分簡單(下面會講解過程)。另外,也可以使用`tf.function`作為裝飾器,更常見一些:
```py
@tf.function
def tf_cube(x):
return x ** 3
```
原生的 Python 函數通過 TF 函數的`python_function`屬性仍然可用:
```py
>>> tf_cube.python_function(2)
8
```
TensorFlow 優化了計算圖,刪掉了沒用的節點,簡化了表達式(比如,1 + 2 會替換為 3),等等。當優化好的計算圖準備好之后,TF 函數可以在圖中,按合適的順序高效執行運算(該并行的時候就并行)。作為結果,TF 函數比普通的 Python 函數快的做,特別是在做復雜計算時。大多數時候,根本沒必要知道底層到底發生了什么,如果需要對 Python 函數加速,將其轉換為 TF 函數就行。
另外,當你寫的自定義損失函數、自定義指標、自定義層或任何其它自定義函數,并在 Keras 模型中使用的,Keras 都自動將其轉換成了 TF 函數,不用使用`tf.function()`。
> 提示:創建自定義層或模型時,設置`dynamic=True`,可以讓 Keras 不轉化你的 Python 函數。另外,當調用模型的`compile()`方法時,可以設置`run_eagerly=True`。
默認時,TF 函數對每個獨立輸入的形狀和數據類型的集合,生成了一個新的計算圖,并緩存以備后續使用。例如,如果你調用`tf_cube(tf.constant(10))`,就會生成一個 int32 張量、形狀是[]的計算圖。如果你調用`tf_cube(tf.constant(20))`,會使用相同的計算圖。但如果調用`tf_cube(tf.constant([10, 20]))`,就會生成一個 int32、形狀是[2]的新計算圖。這就是 TF 如何處理多態的(即變化的參數類型和形狀)。但是,這只適用于張量參數:如果你將 Python 數值傳給 TF,就會為每個獨立值創建一個計算圖:比如,調用`tf_cube(10)`和`tf_cube(20)`會產生兩個計算圖。
> 警告:如果用多個不同的 Python 數值調用 TF 函數,就會產生多個計算圖,這樣會減慢程勛,使用很多的內存(必須刪掉 TF 函數才能釋放)。Python 的值應該復賦值給盡量重復的參數,比如超參數,每層有多少個神經元。這可以讓 TensorFlow 更好的優化模型中的變量。
### 自動圖和跟蹤
TensorFlow 是如何生成計算圖的呢?它先分析了 Python 函數源碼,得出所有的數據流控制語句,比如 for 循環,while 循環,if 條件,還有 break、continue、return。這個第一步被稱為自動圖(AutoGraph)。TensorFlow 之所以要分析源碼,試分析 Python 沒有提供任何其它的方式來獲取控制流語句:Python 提供了`__add__()`和`__mul__()`這樣的魔術方法,但沒有`__while__()`或`__if__()`這樣的魔術方法。分析完源碼之后,自動圖中的所有控制流語句都被替換成相應的 TensorFlow 方法,比如`tf.while_loop()`(while 循環)和`tf.cond()`(if 判斷)。例如,見圖 12-4,自動圖分析了 Python 函數`sum_squares()`的源碼,然后變為函數`tf__sum_squares()`。在這個函數中,for 循環被替換成了`loop_body()`(包括原生的 for 循環)。然后是函數`for_stmt()`,調用這個函數會形成運算`tf.while_loop()`。
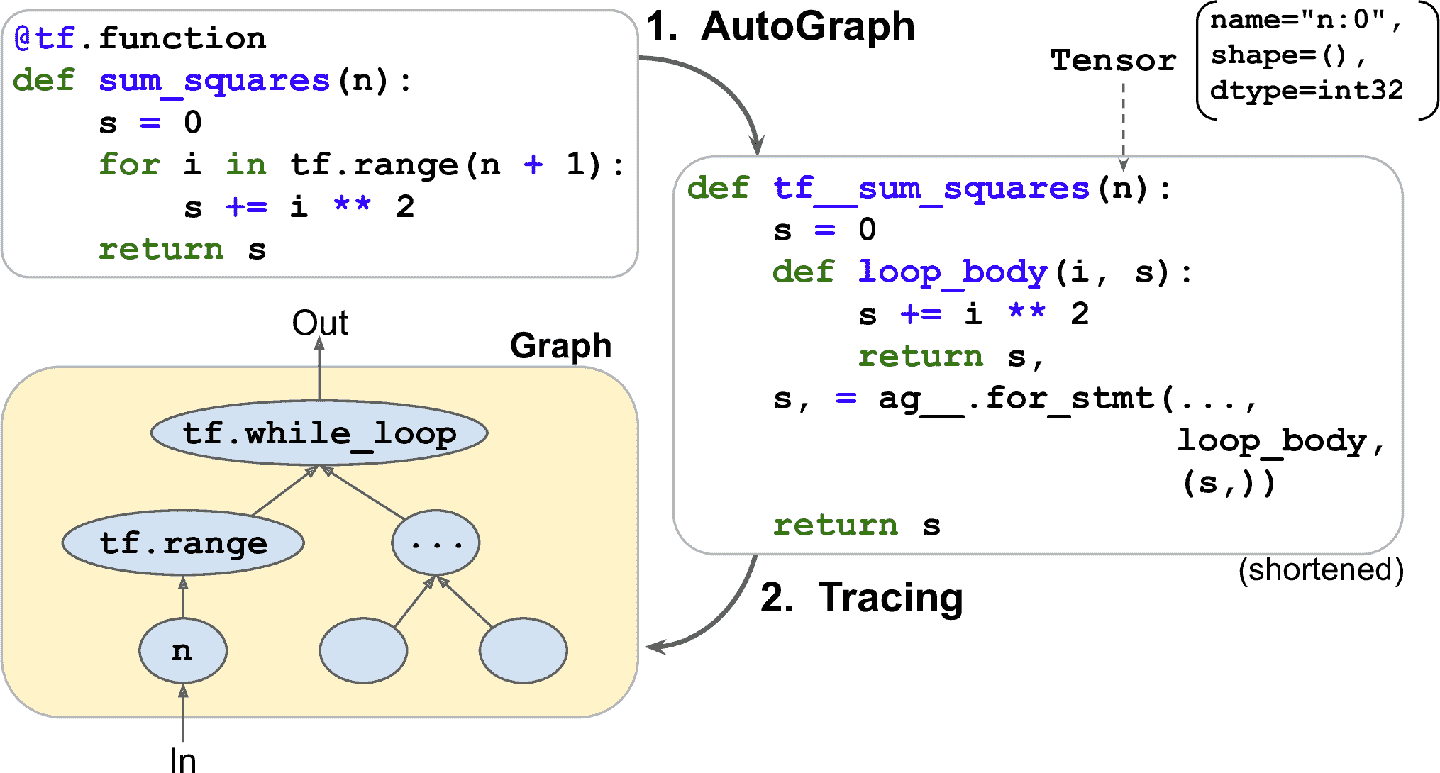圖 12-4 TensorFlow 是如何使用自動圖和跟蹤生成計算圖的?
然后,TensorFlow 調用這個“升級”方法,但沒有向其傳遞參數,而是傳遞一個符號張量(symbolic tensor)——一個沒有任何真實值的張量,只有名字、數據類型和形狀。例如,如果調用`sum_squares(tf.constant(10))`,然后會調用`tf__sum_squares()`,其符號張量的類型是 int32,形狀是[]。函數會以圖模式運行,意味著每個 TensorFlow 運算會在圖中添加一個表示自身的節點,然后輸出`tensor(s)`(與常規模式相對,這被稱為動態圖執行,或動態模式)。在圖模式中,TF 運算不做任何計算。如果你懂 TensorFlow 1,這應該很熟悉,因為圖模式是默認模式。在圖 12-4 中,可以看到`tf__sum_squares()`函數被調用,參數是符號張量,最后的圖是跟蹤中生成的。節點表示運算,箭頭表示張量(生成的函數和圖都簡化了)。
> 提示:想看生成出來的函數源碼的話,可以調用`tf.autograph.to_code(sum_squares.python_function)`。源碼不美觀,但可以用來調試。
### TF 函數規則
大多數時候,將 Python 函數轉換為 TF 函數是瑣碎的:要用`@tf.function`裝飾,或讓 Keras 來負責。但是,也有一些規則:
* 如果調用任何外部庫,包括 NumPy,甚至是標準庫,調用只會在跟蹤中運行,不會是圖的一部分。事實上,TensorFlow 圖只能包括 TensorFlow 的構件(張量、運算、變量、數據集,等等)。因此,要確保使用的是`tf.reduce_sum()`而不是`np.sum()`,使用的是`tf.sort()`而不是內置的`sorted()`,等等。還要注意:
1. 如果定義了一個 TF 函數`f(x)`,它只返回`np.random.rand()`,當函數被追蹤時,生成的是個隨機數,因此`f(tf.constant(2.))`和`f(tf.constant(3.))`會返回同樣的隨機數,但`f(tf.constant([2., 3.]))`會返回不同的數。如果將`np.random.rand()`替換為`tf.random.uniform([])`,每次調用都會返回新的隨機數,因為運算是圖的一部分。
2. 如果你的非 TensorFlow 代碼有副作用(比如日志,或更新 Python 計數器),則 TF 函數被調用時,副作用不一定發生,因為只有函數被追蹤時才有效。
3. 你可以在`tf.py_function()`運算中包裝任意的 Python 代碼,但這么做的話會使性能下降,因為 TensorFlow 不能做任何圖優化。還會破壞移植性,因為圖只能在有 Python 的平臺上跑起來(且安裝上正確的庫)。
* 你可以調用其它 Python 函數或 TF 函數,但是它們要遵守相同的規則,因為 TensorFlow 會在計算圖中記錄它們的運算。注意,其它函數不需要用`@tf.function`裝飾。
* 如果函數創建了一個 TensorFlow 變量(或任意其它靜態 TensorFlow 對象,比如數據集或隊列),它必須在第一次被調用時創建 TF 函數,否則會導致異常。通常,最好在 TF 函數的外部創建變量(比如在自定義層的`build()`方法中)。如果你想將一個新值賦值給變量,要確保調用它的`assign()`方法,而不是使用`=`。
* Python 的源碼可以被 TensorFlow 使用。如果源碼用不了(比如,如果是在 Python shell 中定義函數,源碼就訪問不了,或者部署的是編譯文件`*.pyc`),圖的生成就會失敗或者缺失功能。
* TensorFlow 只能捕獲迭代張量或數據集的 for 循環。因此要確保使用`for i in tf.range(x)`,而不是`for i in range(x)`,否則循環不能在圖中捕獲,而是在會在追蹤中運行。(如果 for 循環使用創建計算圖的,這可能是你想要的,比如創建神經網絡中的每一層)。
* 出于性能原因,最好使用矢量化的實現方式,而不是使用循環。
總結一下,這一章一開始介紹了 TensorFlow,然后是 TensorFlow 的低級 API,包括張量、運算、變量和特殊的數據結構。然后使用這些工具自定義了 tf.keras 中的幾乎每個組件。最后,學習了 TF 函數如何提升性能,計算圖是如何通過自動圖和追蹤生成的,在寫 TF 函數時要遵守什么規則。(附錄 G 介紹了生成圖的內部黑箱)
下一章會學習如何使用 TensorFlow 高效加載和預處理數據。
# 練習
1. 如何用一句話描述 TensorFlow?它的主要特點是什么?能列舉出其它流行的深度學習庫嗎?
2. TensorFlow 是 NumPy 的簡單替換嗎?二者有什么區別?
3. `tf.range(10)`和`tf.constant(np.arange(10))`能拿到相同的結果嗎?
4. 列舉出除了常規張量之外,TensorFlow 的其它六種數據結構?
5. 可以通過函數或創建`keras.losses.Loss`的子類來自定義損失函數。兩種方法各在什么時候使用?
6. 相似的,自定義指標可以通過定義函數或創建`keras.metrics.Metric`的子類。兩種方法各在什么時候使用?
7. 什么時候應該創建自定義層,而不是自定義模型?
8. 什么時候需要創建自定義的訓練循環?
9. 自定義 Keras 組件可以包含任意 Python 代碼嗎,或者 Python 代碼需要轉換為 TF 函數嗎?
10. 如果想讓一個函數可以轉換為 TF 函數,要遵守設么規則?
11. 什么時候需要創建一個動態 Keras 模型?怎么做?為什么不讓所有模型都是動態的?
12. 實現一個具有層歸一化的自定義層(第 15 章會用到):
a. `build()`方法要定義兩個可訓練權重α 和 β,形狀都是`input_shape[-1:]`,數據類型是`tf.float32`。α用 1 初始化,β用 0 初始化。
b. `call()`方法要計算每個實例的特征的平均值μ和標準差σ。你可以使用`tf.nn.moments(inputs, axes=-1, keepdims=True)`,它可以返回平均值μ和方差σ<sup>2</sup>(計算其平方根得到標準差)。函數返回`α?(X - μ)/(σ + ε) + β`,其中`?`表示元素級別懲罰,`ε`是平滑項(避免發生除以 0,而是除以 0.001)。
c. 確保自定義層的輸出和`keras.layers.LayerNormalization`層的輸出一致(或非常接近)。
13. 訓練一個自定義訓練循環,來處理 Fashion MNIST 數據集。
a. 展示周期、迭代,每個周期的平均訓練損失、平均準確度(每次迭代會更新),還有每個周期結束后的驗證集損失和準確度。
b. 深層和淺層使用不同的優化器,不同的學習率。
參考答案見附錄 A。
