
# **后端開發規范**
```
//待補充
```
## Java開發規范
### **命名**
**【規范】**類名使用UpperCamelCase風格,必須遵從駝峰形式,但以下情形例外: ( 領域模型的相關命名 )DO / BO / DTO / VO 等。
正例: MarcoPolo / UserDO / XmlService / TcpUdpDeal / TaPromotion
反例: macroPolo / UserDo / XMLService / TCPUDPDeal / TAPromotion
**【規范】**方法名、參數名、成員變量、局部變量都統一使用lowerCamelCase風格,必須遵從駝峰形式。
正例: localValue / getHttpMessage() / inputUserId
**【規范】**常量命名全部大寫,單詞間用下劃線隔開,力求語義表達完整清楚,不要嫌名字長。
**【規范】**抽象類命名使用 Abstract 或 Base 開頭 ; 異常類命名使用 Exception 結尾 ; 測試類命名以它要測試的類的名稱開始,以 Test 結尾。枚舉類名建議帶上 Enum 后綴,枚舉成員名稱需要全大寫,單詞間用下劃線隔開。
**【規范】**POJO 類中布爾類型的變量,都不要加 is ,否則部分框架解析會引起序列化錯誤。
**【規范】**各層命名規約:
A) Service / DAO 層方法命名規約
1 ) 獲取單個對象的方法用 get 做前綴。
2 ) 獲取多個對象的方法用 list 做前綴(習慣:getXXXList)。
3 ) 獲取統計值的方法用 count 做前綴。
4 ) 插入的方法用 save( 推薦 ) 或 insert 做前綴。
5 ) 刪除的方法用 remove( 推薦 ) 或 delete 做前綴。
6 ) 修改的方法用 update 做前綴(或modify)。
B) 領域模型命名規約
1 ) 數據對象: xxxDO , xxx 即為數據表名。
2 ) 數據傳輸對象: xxxDTO , xxx 為業務領域相關的名稱。
3 ) 展示對象: xxxVO , xxx 一般為網頁名稱。
4 ) POJO 是 DO / DTO / BO / VO 的統稱,禁止命名成 xxxPOJO 。
### **常量**
**【規范】**不允許任何魔法值( 即未經定義的常量 ) 直接出現在代碼中。
反例: String key =” Id # taobao \_”+ tradeId;
cache . put(key , value);
### **格式規約**
**【風格】**單行太長需換行
**【風格】**方法體內的執行語句組、變量的定義語句組、不同的業務邏輯之間或者不同的語義之間插入一個空行。相同業務邏輯和語義之間不需要插入空行。
### **OOP規約**
**【效率】**避免通過一個類的對象引用訪問此類的靜態變量或靜態方法,無謂增加編譯器解析成本,直接用類名來訪問即可。
**【規范】**所有的覆寫方法,必須加@ Override 注解。
**【規范】**對外暴露的接口簽名,原則上不允許修改方法簽名,避免對接口調用方產生影響。接口過時必須加@Deprecated 注解,并清晰地說明采用的新接口或者新服務是什么。
**【規范】**Object 的 equals 方法容易拋空指針異常,應使用常量或確定有值的對象來調用equals。
正例: ” test ” .equals(object);
反例: object.equals( ” test ” );
**【規范】**所有的相同類型的包裝類對象之間值的比較,全部使用 equals 方法比較。(**注意空指針**)
說明:對于 Integer var =?在-128 至 127 之間的賦值, Integer 對象是在IntegerCache . cache 產生,會復用已有對象,這個區間內的 Integer 值可以直接使用==進行判斷,但是這個區間之外的所有數據,都會在堆上產生,并不會復用已有對象,這是一個大坑,推薦使用 equals 方法進行判斷。
**【規范】**關于基本數據類型與包裝數據類型的使用標準如下:
1 ) 所有的 POJO 類屬性必須使用包裝數據類型。
2 ) RPC 方法的返回值和參數必須使用包裝數據類型。
3 ) 所有的局部變量【推薦】使用基本數據類型。
**【強制】**序列化類新增屬性時,請不要修改 serialVersionUID 字段,避免反序列失敗 ; 如果完全不兼容升級,避免反序列化混亂,那么請修改 serialVersionUID 值。
**【規范】**構造方法里面禁止加入任何業務邏輯,如果有初始化邏輯,請放在 init 方法中。
**【規范】**使用索引訪問用 String 的 split 方法得到的數組時,需做最后一個分隔符后有無內容的檢查,否則會有拋 IndexOutOfBoundsException 的風險。
說明:
String str = “a,b,c,,”;
String\[\] ary = str.split(“,”);
//預期大于 3,結果是 3
System.out.println(ary.length);
**【規范】**當一個類有多個構造方法,或者多個同名方法,這些方法應該按順序放置在一起,便于閱讀。
**【風格】**類內方法定義順序依次是:公有方法或保護方法 > 私有方法 > getter / setter方法。
**【效率】**final 可提高程序響應效率,聲明成 final 的情況:
1 ) 不需要重新賦值的變量,包括類屬性、局部變量。
2 ) 對象參數前加 final ,表示不允許修改引用的指向。
3 ) 類方法確定不允許被重寫。
4 )例子:final boolean existed = (file.open(fileName, “w”) != null) && (…) || (…);
### **集合處理**
**【強制】**關于 hashCode 和 equals 的處理,遵循如下規則:
1) 只要重寫 equals ,就必須重寫 hashCode 。
2) 因為 Set 存儲的是不重復的對象,依據 hashCode 和 equals 進行判斷,所以 Set 存儲的對象必須重寫這兩個方法。
3) 如果自定義對象做為 Map 的鍵,那么必須重寫 hashCode 和 equals 。
**【強制】**不要在 foreach 循環里進行元素的 remove / add 操作。 remove 元素請使用 Iterator方式,如果并發操作,需要對 Iterator 對象加鎖。
反例:
List a = new ArrayList();
a.add(“1”);
a.add(“2”);
for (String temp : a) {
if(“1”.equals(temp)){
a.remove(temp);
}
}
說明:以上代碼的執行結果肯定會出乎大家的意料,那么試一下把“1”換成“2”,會是同樣的結果嗎?(java.util.ConcurrentModificationException)
正例:
Iterator it = a.iterator();
while(it.hasNext()){
String temp = it.next();
if(刪除元素的條件){
it.remove();
}
}
**【規范】**集合初始化時,盡量指定集合初始值大小。
說明: ArrayList 盡量使用 ArrayList(int initialCapacity) 初始化。
**【規范】**使用 entrySet 遍歷 Map 類集合 KV,而不是 keySet 方式進行遍歷。
說明:keySet 其實是遍歷了 2 次,一次是轉為 Iterator 對象,另一次是從 hashMap 中取出 key 所對應的 value。而 entrySet 只是遍歷了一次就把 key 和 value 都放到了 entry 中,效 率更高。如果是 JDK8,使用 Map.foreach 方法。
Map map = new HashMap();
map.put(“1”, “@@”);
map.put(“2”, “##”);
/\*\*
\* JDK8推薦使用
\*/
map.forEach((K, V) -> {
System.out.println(“Key : ” + K);
System.out.println(“Value : ” + V);
});
/\*\*
\* foreach推薦使用
\*/
for (Map.Entry entry : map.entrySet()) {
System.out.println(“Key : ” + entry.getKey());
System.out.println(“Value : ” + entry.getValue());
}
/\*\*
\* 不推薦使用
\*/
for (String key : map.keySet()) {
System.out.println(“Key : ” + key);
System.out.println(“Value : ” + map.get(key));
}
**【強制】**高度注意 Map 類集合 K/V 能不能存儲 null 值的情況,如下表格:
集合類KeyValueSuper說明Hashtable不允許為 null不允許為 nullDictionary線程安全ConcurrentHashMap不允許為 null不允許為 nullAbstractMap分段鎖技術TreeMap不允許為 null允許為 nullAbstractMap線程不安全HashMap允許為 null允許為 nullAbstractMap線程不安全
### **并發處理**
**【規范】**獲取單例對象需要保證線程安全,其中的方法也要保證線程安全。
說明:資源驅動類、工具類、單例工廠類都需要注意。
**【規范】**創建線程或線程池時請指定有意義的線程名稱,方便出錯時回溯。
正例:
public class TimerTaskThread extends Thread { public TimerTaskThread(){
super.setName(“TimerTaskThread”); … }
**【規范】**線程資源必須通過線程池提供,不允許在應用中自行顯式創建線程。
說明:使用線程池的好處是減少在創建和銷毀線程上所花的時間以及系統資源的開銷,解決資 源不足的問題。如果不使用線程池,有可能造成系統創建大量同類線程而導致消耗完內存或者 “過度切換”的問題。
**【規范】**線程池不允許使用 Executors 去創建,而是通過 ThreadPoolExecutor 的方式,這樣 的處理方式讓寫的同學更加明確線程池的運行規則,規避資源耗盡的風險。 說明:Executors 返回的線程池對象的弊端如下:
1)FixedThreadPool 和 SingleThreadPool:
允許的請求隊列長度為 Integer.MAX\_VALUE,可能會堆積大量的請求,從而導致 OOM。
2)CachedThreadPool 和 ScheduledThreadPool:
允許的創建線程數量為 Integer.MAX\_VALUE,可能會創建大量的線程,從而導致 OOM。
**【效率】**高并發時,同步調用應該去考量鎖的性能損耗。能用無鎖數據結構,就不要用鎖;能 鎖區塊,就不要鎖整個方法體;能用對象鎖,就不要用類鎖。
**【強制】**對多個資源、數據庫表、對象同時加鎖時,需要保持一致的加鎖順序,否則可能會造 成死鎖。
說明:線程一需要對表 A、B、C 依次全部加鎖后才可以進行更新操作,那么線程二的加鎖順序 也必須是 A、B、C,否則可能出現死鎖。
**【規范】**并發修改同一記錄時,避免更新丟失,要么在應用層加鎖,要么在緩存加鎖,要么在 數據庫層使用樂觀鎖,使用 version 作為更新依據。
說明:如果每次訪問沖突概率小于 20%,推薦使用樂觀鎖,否則使用悲觀鎖。樂觀鎖的重試次 數不得小于 3 次。
**【規范】**多線程并行處理定時任務時,Timer運行多個 TimeTask 時,只要其中之一沒有捕獲 拋出的異常,其它任務便會自動終止運行,使用ScheduledExecutorService則沒有這個問題。
**【規范】**HashMap 在容量不夠進行 resize 時由于高并發可能出現死鏈,導致 CPU 飆升,在 開發過程中注意規避此風險。
### **控制語句**
**【規范】**在一個 switch 塊內,每個 case 要么通過 break/return 等來終止,要么注釋說明程 序將繼續執行到哪一個 case 為止;在一個 switch 塊內,都必須包含一個 default 語句并且 放在最后,即使它什么代碼也沒有。
**【規范】**在 if/else/for/while/do 語句中必須使用大括號,即使只有一行代碼,避免使用 下面的形式:if (condition) statements;
**【規范】**推薦盡量少用 else, if-else 的方式可以改寫成:
if(condition){
…
return obj; }
// 接著寫 else 的業務邏輯代碼;
說明:如果非得使用if()…else if()…else…方式表達邏輯,【強制】請勿超過3層,
超過請使用狀態設計模式 或者 衛語句。
衛語句示例:
~~~java
public void today() {
if (isBusy()) {
System.out.println(“change time.”);
return;
}
if (isFree()) {
System.out.println(“go to travel.”);
return;
}
System.out.println(“stay at home to learn Alibaba Java Coding Guidelines.”);
return;
}
~~~
**【規范】**除常用方法(如 getXxx/isXxx)等外,不要在條件判斷中執行其它復雜的語句,將復 雜邏輯判斷的結果賦值給一個有意義的布爾變量名,以提高可讀性。
說明:很多 if 語句內的邏輯相當復雜,閱讀者需要分析條件表達式的最終結果,才能明確什么 樣的條件執行什么樣的語句,那么,如果閱讀者分析邏輯表達式錯誤呢?
正例:
//偽代碼如下
boolean existed = (file.open(fileName, “w”) != null) && (…) || (…); if (existed) {
… }
反例:
if ((file.open(fileName, “w”) != null) && (…) || (…)) { …
}
**【規范】**方法中需要進行參數校驗的場景:
1) 調用頻次低的方法。
2) 執行時間開銷很大的方法,參數校驗時間幾乎可以忽略不計,但如果因為參數錯誤導致
中間執行回退,或者錯誤,那得不償失。
3) 需要極高穩定性和可用性的方法。
4) 對外提供的開放接口,不管是RPC/API/HTTP接口。
5) 敏感權限入口。
**【規范】**方法中不需要參數校驗的場景:
1) 極有可能被循環調用的方法,不建議對參數進行校驗。但在方法說明里必須注明外部參
數檢查。
2)底層的方法調用頻度都比較高,一般不校驗。畢竟是像純凈水過濾的最后一道,參數錯誤不太可能到底層才會暴露問題。一般 DAO 層與 Service 層都在同一個應用中,部署在同一 臺服務器中,所以 DAO 的參數校驗,可以省略。
3) 被聲明成private只會被自己代碼所調用的方法,如果能夠確定調用方法的代碼傳入參 數已經做過檢查或者肯定不會有問題,此時可以不校驗參數。
### **注釋規約**
**【規范】**類、類屬性、類方法的注釋必須使用 Javadoc 規范,使用/\*\*內容\*/格式,不得使用 //xxx 方式。
**【規范】**所有的抽象方法(包括接口中的方法)必須要用 Javadoc 注釋、除了返回值、參數、 異常說明外,還必須指出該方法做什么事情,實現什么功能。
說明:對子類的實現要求,或者調用注意事項,請一并說明。
**【風格】**方法內部單行注釋,在被注釋語句上方另起一行,使用//注釋。方法內部多行注釋使用/\* \*/注釋,注意與代碼對齊。
**【規范】**所有的枚舉類型字段必須要有注釋,說明每個數據項的用途。
**【規范】**代碼修改的同時,注釋也要進行相應的修改,尤其是參數、返回值、異常、核心邏輯 等的修改。
**【規范】**注釋掉的代碼盡量要配合說明,而不是簡單的注釋掉。
說明:代碼被注釋掉有兩種可能性:
1)后續會恢復此段代碼邏輯。
2)永久不用。前者如果沒 有備注信息,難以知曉注釋動機。
后者建議直接刪掉(代碼倉庫保存了歷史代碼)。
**【風格】**特殊注釋標記,請注明標記人與標記時間。注意及時處理這些標記,通過標記掃描, 經常清理此類標記。線上故障有時候就是來源于這些標記處的代碼。
1)待辦事宜(TODO):( 標記人,標記時間,\[預計處理時間\]) 表示需要實現,但目前還未實現的功能。這實際上是一個 Javadoc 的標簽,目前的 Javadoc
還沒有實現,但已經被廣泛使用。只能應用于類,接口和方法(因為它是一個 Javadoc 標簽)。
2)錯誤,不能工作(FIXME):(標記人,標記時間,\[預計處理時間\])
在注釋中用 FIXME 標記某代碼是錯誤的,而且不能工作,需要及時糾正的情況。
### **異常**
**【規范】**異常不要用來做流程控制,條件控制,因為異常的處理效率比條件分支低。
**【規范】**對大段代碼進行 try-catch,這是不負責任的表現。catch 時請分清穩定代碼和非穩 定代碼,穩定代碼指的是無論如何不會出錯的代碼。對于非穩定代碼的 catch 盡可能進行區分 異常類型,再做對應的異常處理。
**【規范】**捕獲異常是為了處理它,不要捕獲了卻什么都不處理而拋棄之,如果不想處理它,請 將該異常拋給它的調用者。最外層的業務使用者,必須處理異常,將其轉化為用戶可以理解的 內容。
**【強制】**有 try 塊放到了事務代碼中,catch 異常后,如果需要回滾事務,一定要注意手動回 滾事務。
**【規范】**不能在 finally 塊中使用 return,finally 塊中的 return 返回后方法結束執行,不 會再執行 try 塊中的 return 語句。
**【規范】**方法的返回值可以為 null,不強制返回空集合,或者空對象等,必須添加注釋充分 說明什么情況下會返回 null 值。調用方需要進行 null 判斷防止 NPE 問題。
**【規范】**防止 NPE,是程序員的基本修養,注意 NPE 產生的場景:
1) 返回類型為包裝數據類型,有可能是null,返回int值時注意判空。
反例:public int f(){ return Integer 對象}; 如果為 null,自動解箱拋 NPE。
2) 數據庫的查詢結果可能為null。
3) 集合里的元素即使isNotEmpty,取出的數據元素也可能為null。
4) 遠程調用返回對象,一律要求進行NPE判斷。
5) 對于Session中獲取的數據,建議NPE檢查,避免空指針。
6) 級聯調用obj.getA().getB().getC();一連串調用,易產生NPE。
**【規范】**在代碼中使用“拋異常”還是“返回錯誤碼”,對于公司外的 http/api 開放接口必須 使用“錯誤碼”;而應用內部推薦異常拋出;跨應用間 RPC 調用優先考慮使用 Result 方式,封 裝 isSuccess、“錯誤碼”、“錯誤簡短信息”。
說明:關于 RPC 方法返回方式使用 Result 方式的理由:
1)使用拋異常返回方式,調用方如果沒有捕獲到就會產生運行時錯誤。
2)如果不加棧信息,只是new自定義異常,加入自己的理解的error message,對于調用 端解決問題的幫助不會太多。如果加了棧信息,在頻繁調用出錯的情況下,數據序列化和傳輸 的性能損耗也是問題。
**【規范】**避免出現重復的代碼(Don’t Repeat Yourself),即DRY原則。
### **日志**
**【規范】**應用中不可直接使用日志系統(Log4j、Logback)中的 API,而應依賴使用日志框架
SLF4J 中的 API,使用門面模式的日志框架,有利于維護和各個類的日志處理方式統一。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static final Logger logger = LoggerFactory.getLogger(Abc.class);
**【規范】**日志文件推薦至少保存 15 天,因為有些異常具備以“周”為頻次發生的特點。
**【規范】**應用中的擴展日志(如打點、臨時監控、訪問日志等)命名方式: appName\_logType\_logName.log。
logType:日志類型,推薦分類有 stats/desc/monitor/visit 等;
logName:日志描述。這種命名的好處:通過文件名就可知 道日志文件屬于什么應用,什么類型,什么目的,也有利于歸類查找。
正例:mppserver 應用中單獨監控時區轉換異常,如: mppserver\_monitor\_timeZoneConvert.log
說明:推薦對日志進行分類,錯誤日志和業務日志盡量分開存放,便于開發人員查看,也便于 通過日志對系統進行及時監控。
**【規范】**對 trace/debug/info 級別的日志輸出,必須使用條件輸出形式或者使用占位符的方式。
說明:logger.debug(“Processing trade with id: ” + id + ” symbol: ” + symbol); 如果日志級別是 warn,上述日志不會打印,但是會執行字符串拼接操作,如果 symbol 是對象, 會執行 toString()方法,浪費了系統資源,執行了上述操作,最終日志卻沒有打印。 正例:(條件)
if (logger.isDebugEnabled()) {
logger.debug(“Processing trade with id: ” + id + ” symbol: ” + symbol);
}
正例:(占位符)
logger.debug(“Processing trade with id: {} symbol : {} “, id, symbol);
\* 避免重復打印日志,浪費磁盤空間,務必在 log4j.xml 中設置 additivity=false。
正例:
**【規范】**可以使用warn 日志級別來記錄用戶輸入參數錯誤的情況,避免用戶投訴時,無所適 從。注意日志輸出的級別,error 級別只記錄系統邏輯出錯、異常等重要的錯誤信息。如非必 要,請不要在此場景打出 error 級別。
**【規范】**謹慎地記錄日志。生產環境禁止輸出 debug 日志;有選擇地輸出 info 日志;如果使 用 warn 來記錄剛上線時的業務行為信息,一定要注意日志輸出量的問題,避免把服務器磁盤 撐爆,并記得及時刪除這些觀察日志。
說明:大量地輸出無效日志,不利于系統性能提升,也不利于快速定位錯誤點。記錄日志時請
**思考:**這些日志真的有人看嗎?看到這條日志你能做什么?能不能給問題排查帶來好處?
### **其它**
**【效率】**在使用正則表達式時,利用好其預編譯功能,可以有效加快正則匹配速度。 說明:不要在方法體內定義:Pattern pattern = Pattern.compile(規則);
**【規范】**獲取當前毫秒數 System.currentTimeMillis(); 而不是 new Date().getTime();
說明:如果想獲取更加精確的納秒級時間值,用 System.nanoTime()。在 JDK8 中,針對統計 時間等場景,推薦使用Instant類。
**【規范】**對于“明確停止使用的代碼和配置”,如方法、變量、類、配置文件、動態配置屬性等要堅決從程序中清理出去,避免造成過多垃圾。
## 單元測試
**【強制】**好的單元測試必須遵守 AIR 原則。
**說明:**單元測試在線上運行時,**感覺像空氣(AIR)一樣并不存在**,但在測試質量的保障上,卻是非常關鍵的。好的單元測試宏觀上來說,具有自動化、獨立性、可重復執行的特點。
? A:Automatic(自動化)
? I:Independent(獨立性)
? R:Repeatable(可重復)?
**【強制】**單元測試應該是全自動執行的,并且非交互式的。測試框架通常是定期執行的,執行過程必須**完全自動化**才有意義。輸出結果需要人工檢查的測試不是一個好的單元測試。**單元測 試中不準使用 System.out 來進行人肉驗證,必須使用 assert 來驗證。**
**【強制】**保持單元測試的獨立性。為了保證單元測試穩定可靠且便于維護,單元測試用例之間 決不能互相調用,也不能依賴執行的先后次序。
反例:method2 需要依賴 method1 的執行,將執行結果做為 method2 的輸入。
**【強制】**對于單元測試,**要保證測試粒度足夠小,有助于精確定位問題。單測粒度至多是類級別,一般是方法級別。**?
**說明:**只有測試粒度小才能在出錯時盡快定位到出錯位置。單測不負責檢查跨類或者跨系統的 交互邏輯,那是集成測試的領域。
**【強制】****核心業務、核心應用、核心模塊的增量代碼**確保單元測試通過。?
**說明:**新增代碼及時補充單元測試,如果新增代碼影響了原有單元測試,請及時修正。
**【推薦】**單元測試的基本目標:語句覆蓋率達到 70%;核心模塊的語句覆蓋率和分支覆蓋率都 要達到 100%
說明:在工程規約的應用分層中提到的 DAO 層,Manager 層,可重用度高的 Service,都應該 進行單元測試。
**【推薦】**編寫單元測試代碼遵守 BCDE 原則,以保證被測試模塊的交付質量。
? B:Border**,邊界值測試**,包括循環邊界、特殊取值、特殊時間點、數據順序等。
C:Correct,**正確的輸入**,并得到預期的結果。
? D:Design**,與設計文檔相結合,來編寫單元測試**。
? E:Error**,強制錯誤信息輸入(如:非法數據、異常流程、非業務允許輸入等),并得 到預期的結果。**
**【推薦】**和數據庫相關的單元測試,可以設定自動回滾機制,不給數據庫造成臟數據。或者 對單元測試產生的數據有明確的前后綴標識。
正例:在 RDC 內部單元測試中,使用 RDC\_UNIT\_TEST\_的前綴標識數據。
**【推薦】**在設計評審階段,開發人員需要和測試人員一起確定單元測試范圍,單元測試最好 覆蓋所有測試用例(UC)。
**【推薦】**單元測試作為一種質量保障手段,不建議項目發布后補充單元測試用例,建議在項 目提測前完成單元測試。
**【參考】**不要對單元測試存在如下誤解:
? 那是測試同學干的事情。本文是開發手冊,凡是本文內容都是與開發同學強相關的。
單元測試代碼是多余的。汽車的整體功能與各單元部件的測試正常與否是強相關的。 ?
單元測試代碼不需要維護。一年半載后,那么單元測試幾乎處于廢棄狀態。
? 單元測試與線上故障沒有辯證關系。好的單元測試能夠最大限度地規避線上故障。
## **MySQL開發規范**
### **建表規約**
**【規范】**表達是與否概念的字段,必須使用 is\_xxx 的方式命名,數據類型是 unsigned tinyint ( 1表示是,0表示否),此規則同樣適用于odps建表。 說明:任何字段如果為非負數,必須是 unsigned。
**【規范】**表名、字段名必須使用小寫字母或數字;禁止出現數字開頭,禁止兩個下劃線中間只 出現數字。數據庫字段名的修改代價很大,因為無法進行預發布,所以字段名稱需要慎重考慮。
正例:getter\_admin,task\_config,level3\_name
反例:GetterAdmin,taskConfig,level\_3\_name
**【規范】**唯一索引名為 uk\_字段名;普通索引名則為 idx\_字段名。
**【規范】**小數類型為 decimal,禁止使用 float 和 double。
說明:float 和 double 在存儲的時候,存在精度損失的問題,很可能在值的比較時,得到不 正確的結果。如果存儲的數據范圍超過 decimal 的范圍,建議將數據拆成整數和小數分開存儲。
**【規范】**如果存儲的字符串長度幾乎相等,使用 char 定長字符串類型。
**【效率】**varchar 是可變長字符串,不預先分配存儲空間,長度不要超過 5000,如果存儲長 度大于此值,定義字段類型為 text,獨立出來一張表,用主鍵來對應,避免影響其它字段索 引效率。
**【規范】**表的命名最好是加上“業務名稱\_表的作用”。
正例:tiger\_task / tiger\_reader / mpp\_config
**【規范】**庫名與應用名稱盡量一致。
**【規范】**如果修改字段含義或對字段表示的狀態追加時,需要及時更新字段注釋。
**【效率】**字段允許適當冗余,以提高性能,但是必須考慮數據同步的情況。冗余字段應遵循:
1)不是頻繁修改的字段。
2)不是 varchar 超長字段,更不能是 text 字段。 正例:商品類目名稱使用頻率高,字段長度短,名稱基本一成不變,可在相關聯的表中冗余存 儲類目名稱,避免關聯查詢。
**【效率】**單表行數超過 500 萬行或者單表容量超過 2GB,才推薦進行分庫分表。說明:如果預計三年后的數據量根本達不到這個級別,請不要在創建表時就分庫分表。
**【效率】**合適的字符存儲長度,不但節約數據庫表空間、節約索引存儲,更重要的是提升檢 索速度。
正例:人的年齡用 unsigned tinyint(表示范圍 0-255,人的壽命不會超過 255 歲);海龜 就必須是 smallint,但如果是太陽的年齡,就必須是 int;如果是所有恒星的年齡都加起來, 那么就必須使用 bigint。
### **索引規約**
**【效率】**業務上具有唯一特性的字段,即使是組合字段,也必須建成唯一索引。
說明:不要以為唯一索引影響了 insert 速度,這個速度損耗可以忽略,但提高查找速度是明 顯的;另外,即使在應用層做了非常完善的校驗和控制,只要沒有唯一索引,根據墨菲定律, 必然有臟數據產生。
**【規范】**超過三個表禁止 join。需要 join 的字段,數據類型保持絕對一致;多表關聯查詢 時,保證被關聯的字段需要有索引。
說明:即使雙表 join 也要注意表索引、SQL 性能。
**【規范】**在 varchar 字段上建立索引時,必須指定索引長度,沒必要對全字段建立索引,根據 實際文本區分度決定索引長度。
說明:索引的長度與區分度是一對矛盾體,一般對字符串類型數據,長度為 20 的索引,區分 度會高達 90%以上,可以使用 count(distinct left(列名, 索引長度))/count(\*)的區分度 來確定。
**【規范】**頁面搜索嚴禁左模糊或者全模糊,如果需要請走搜索引擎來解決。
說明:索引文件具有 B-Tree 的最左前綴匹配特性,如果左邊的值未確定,那么無法使用此索 引。
**【規范】**如果有 order by 的場景,請注意利用索引的有序性。order by 最后的字段是組合 索引的一部分,并且放在索引組合順序的最后,避免出現 file\_sort 的情況,影響查詢性能。
正例:where a=? and b=? order by c; 索引:a\_b\_c
反例:索引中有范圍查找,那么索引有序性無法利用,如:WHERE a>10 ORDER BY b; 索引 a\_b 無法排序。
**【效率】**利用覆蓋索引來進行查詢操作,來避免回表操作。
說明:如果一本書需要知道第 11 章是什么標題,會翻開第 11 章對應的那一頁嗎?目錄瀏覽 一下就好,這個目錄就是起到覆蓋索引的作用。 正例:能夠建立索引的種類:主鍵索引、唯一索引、普通索引,而覆蓋索引是一種查詢的一種 效果,用explain的結果,extra列會出現:using index。
**【效率】**利用延遲關聯或者子查詢優化超多分頁場景。
說明:MySQL 并不是跳過 offset 行,而是取 offset+N 行,然后返回放棄前 offset 行,返回 N 行,那當 offset 特別大的時候,效率就非常的低下,要么控制返回的總頁數,要么對超過 特定閾值的頁數進行 SQL 改寫。
正例:先快速定位需要獲取的 id 段,然后再關聯:(**優化在可以少查表1的很多字段**)
SELECT a.\* FROM 表 1 a, (select id from 表 1 where 條件 LIMIT 100000,20 ) b where a.id=b.id
**【效率】**SQL 性能優化的目標:至少要達到 range 級別,要求是 ref 級別,如果可以是 consts 最好。
說明:
1)consts 單表中最多只有一個匹配行(主鍵或者唯一索引),在優化階段即可讀取到數據。
2)ref 指的是使用普通的索引(normal index)。
3)range 對索引進行范圍檢索。
反例:explain 表的結果,type=index,索引物理文件全掃描,速度非常慢,這個 index 級 別比較 range 還低,與全表掃描是小巫見大巫。
**【規范】**建組合索引的時候,區分度最高的在最左邊。
正例:如果 where a=? and b=? ,a 列的幾乎接近于唯一值,那么只需要單建 idx\_a 索引即 可。
說明:存在非等號和等號混合判斷條件時,在建索引時,請把等號條件的列前置。如:where a>? and b=? 那么即使 a 的區分度更高,也必須把 b 放在索引的最前列。
**【說明】**創建索引時避免有如下極端誤解:
1)誤認為一個查詢就需要建一個索引。
2)誤認為索引會消耗空間、嚴重拖慢更新和新增速度。
3)誤認為唯一索引一律需要在應用層通過“先查后插”方式解決。
### **SQL規約**
**【規范】**不要使用 count(列名)或 count(常量)來替代 count(\*),count(\*)就是 SQL92 定義 的標準統計行數的語法,跟數據庫無關,跟 NULL 和非 NULL 無關。
說明:count(\*)會統計值為 NULL 的行,而 count(列名)不會統計此列為 NULL 值的行。
**【說明】**count(distinct col) 計算該列除 NULL 之外的不重復數量。注意 count(distinct col1, col2) 如果其中一列全為NULL,那么即使另一列有不同的值,也返回為0。
**【說明】**當某一列的值全是 NULL 時,count(col)的返回結果為 0,但 sum(col)的返回結果為 NULL,因此使用 sum()時需注意 NPE 問題。
正例:可以使用如下方式來避免sum的NPE問題:SELECT IF(ISNULL(SUM(g)),0,SUM(g)) FROM table;
**【說明】**使用 ISNULL()來判斷是否為 NULL 值。注意:NULL 與任何值的直接比較都為 NULL。
說明:
1) NULL<>NULL的返回結果是NULL,而不是false。
2) NULL=NULL的返回結果是NULL,而不是true。
3) NULL<>1的返回結果是NULL,而不是true。
**【規范】**不得使用外鍵與級聯,一切外鍵概念必須在應用層解決。
說明:(概念解釋)學生表中的 student\_id 是主鍵,那么成績表中的 student\_id 則為外鍵。 如果更新學生表中的 student\_id,同時觸發成績表中的 student\_id 更新,則為級聯更新。外鍵與級聯更新適用于單機低并發,不適合分布式、高并發集群;級聯更新是強阻塞,存在數 據庫更新風暴的風險;外鍵影響數據庫的插入速度。
**【規范】**數據訂正時,刪除和修改記錄時,要先 select,避免出現誤刪除,確認無誤才能執行更新語句。
**【效率】**in 操作能避免則避免,若實在避免不了,需要仔細評估 in 后邊的集合元素數量,控制在 1000 個之內。(可以用用 EXISTS ,NOT EXISTS 或 JOIN代替)
**【規范】**如果有全球化需要,所有的字符存儲與表示,均以 utf-8 編碼,那么字符計數方法 注意:
說明:
SELECT LENGTH(“輕松工作”); 返回為12
SELECT CHARACTER\_LENGTH(“輕松工作”); 返回為4 如果要使用表情,那么使用 utfmb4 來進行存儲,注意它與 utf-8 編碼的區別。
**【規范】**TRUNCATE TABLE 比 DELETE 速度快,且使用的系統和事務日志資源少,但 TRUNCATE無事務且不觸發 trigger,有可能造成事故,故不建議在開發代碼中使用此語句。
說明:TRUNCATE TABLE 在功能上與不帶 WHERE 子句的 DELETE 語句相同。
### **ORM規約**
**【規范】**POJO 類的 boolean 屬性不能加 is,而數據庫字段必須加 is\_,要求在 resultMap 中 進行字段與屬性之間的映射。
說明:參見定義 POJO 類以及數據庫字段定義規定,在 sql.xml 增加映射,是必須的。
**【安全】**配置XML文件時注意SQL注入問題。
**【規范】**不允許直接拿 HashMap 與 Hashtable 作為查詢結果集的輸出。
**【強制】**更新數據表記錄時,必須同時更新記錄對應的 gmt\_modified 字段值為當前時間。
**【規范】**不要寫一個大而全的數據更新接口,傳入為 POJO 類,不管是不是自己的目標更新字 段,都進行 update table set c1=value1,c2=value2,c3=value3; 這是不對的。執行 SQL 時,盡量不要更新無改動的字段,一是易出錯;二是效率低;三是 binlog 增加存儲。
**【規范】**@Transactional 事務不要濫用。事務會影響數據庫的 QPS,另外使用事務的地方需 要考慮各方面的回滾方案,包括緩存回滾、搜索引擎回滾、消息補償、統計修正等。
## **工程規約**
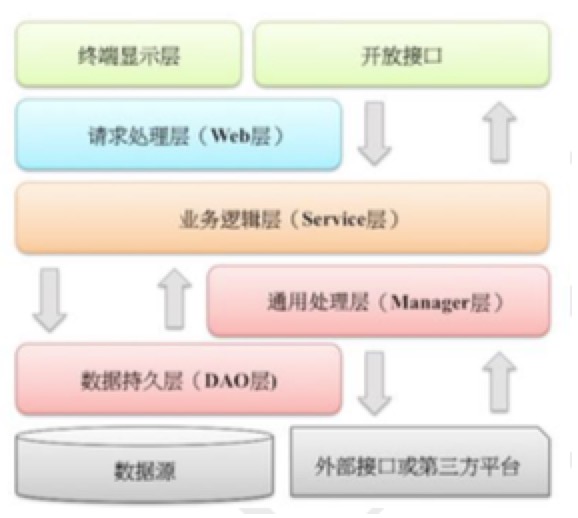
**【說明】**圖中默認上層依賴于下層,箭頭關系表示可直接依賴,如:開放接口層可以依賴于Web 層,也可以直接依賴于 Service 層,依此類推。
? 開放接口層:可直接封裝 Service接口暴露成 RPC 接口;通過 Web 封裝成 http 接口;網關控 制層等。
? 終端顯示層:各個端的模板渲染并執行顯示層。當前主要是 velocity 渲染,JS 渲染,JSP 渲 染,移動端展示層等。
? Web 層:主要是對訪問控制進行轉發,各類基本參數校驗,或者不復用的業務簡單處理等。(Controller)
? Service 層:相對具體的業務邏輯服務層。
? Manager 層:通用業務處理層,它有如下特征:
1)對第三方平臺封裝的層,預處理返回結果及轉化異常信息;
2)對Service層通用能力的下沉,如緩存方案、中間件通用處理;
3)與DAO層交互,對DAO的業務通用能力的封裝。
? DAO 層:數據訪問層,與底層 MySQL、Oracle、Hbase 進行數據交互。
? 外部接口或第三方平臺:包括其它部門 RPC 開放接口,基礎平臺,其它公司的 HTTP 接口。
**【規范】**(分層異常處理規約)在 DAO 層,**產生的異常類型有很多,無法用細粒度的異常進 行catch,使用catch(Exception e)方式**,并throw new DAOException(e),**不需要打印日志,因為日志在 Manager/Service 層一定需要捕獲并打到日志文件中去,如果同臺服務器 再打日志,浪費性能和存儲。**在 Service 層出現異常時,必須記錄出錯日志到磁盤,盡可能帶 上參數信息,相當于保護案發現場。如果 Manager 層與 Service 同機部署,日志方式與 DAO 層處理一致,如果是單獨部署,則采用與 Service 一致的處理方式。**Web 層絕不應該繼續往上拋異常,因為已經處于頂層,如果意識到這個異常將導致頁面無法正常渲染,那么就應該直接跳轉到友好錯誤頁面,加上用戶容易理解的錯誤提示信息。開放接口層要將異常處理成錯誤碼 和錯誤信息方式返回。**
**【規范】**分層領域模型規約:
? DO(Data Object):與數據庫表結構一一對應,通過 DAO 層向上傳輸數據源對象。(Entity)
? DTO(Data Transfer Object):數據傳輸對象,Service 和 Manager 向外傳輸的對象。
? BO(Business Object):業務對象。可以由 Service 層輸出的封裝業務邏輯的對象。
? QUERY:數據查詢對象,各層接收上層的查詢請求。注:超過 2 個參數的查詢封裝,禁止 使用 Map 類來傳輸。
? VO(View Object):顯示層對象,通常是 Web 向模板渲染引擎層傳輸的對象。
## **服務器規約**
**【效率】**高并發服務器建議調小 TCP 協議的 time\_wait 超時時間。
說明:操作系統默認 240 秒后,才會關閉處于 time\_wait 狀態的連接,在高并發訪問下,服務器端會因為處于 time\_wait 的連接數太多,可能無法建立新的連接,所以需要在服務器上 調小此等待值。
正例:在 linux 服務器上請通過變更/etc/sysctl.conf 文件去修改該缺省值(秒):
net.ipv4.tcp\_fin\_timeout = 30
**【效率】**調大服務器所支持的最大文件句柄數(File Descriptor,簡寫為fd)。
說明:主流操作系統的設計是將 TCP/UDP 連接采用與文件一樣的方式去管理,即一個連接對 應于一個 fd。主流的 linux 服務器默認所支持最大 fd 數量為 1024,當并發連接數很大時很 容易因為 fd 不足而出現“open too many files”錯誤,導致新的連接無法建立。 建議將 linux 服務器所支持的最大句柄數調高數倍(與服務器的內存數量相關)。
**【規范】**給 JVM 設置-XX:+HeapDumpOnOutOfMemoryError 參數,讓 JVM 碰到 OOM 場景時輸出 dump 信息。
說明:OOM 的發生是有概率的,甚至有規律地相隔數月才出現一例,出現時的現場信息對查錯 非常有價值。
**【規范】**服務器內部重定向使用 forward;外部重定向地址使用 URL 拼裝工具類來生成,否則 會帶來 URL 維護不一致的問題和潛在的安全風險。
## **安全規約**
**【安全】**隸屬于用戶個人的頁面或者功能必須進行權限控制校驗。
說明:防止沒有做水平權限校驗就可隨意訪問、操作別人的數據,比如查看、修改別人的訂單。
**【安全】**用戶敏感數據禁止直接展示,必須對展示數據脫敏。
說明:查看個人手機號碼會顯示成:158\*\*\*\*9119,隱藏中間 4 位,防止隱私泄露。
**【安全】**用戶輸入的 SQL 參數嚴格使用參數綁定或者 METADATA 字段值限定,防止 SQL 注入, 禁止字符串拼接 SQL 訪問數據庫。
**【安全】**用戶請求傳入的任何參數必須做有效性驗證。
說明:忽略參數校驗可能導致:
? page size 過大導致內存溢出
? 惡意 order by 導致數據庫慢查詢
? 任意重定向
? SQL 注入
? 反序列化注入
? 正則輸入源串拒絕服務 ReDoS
說明:Java 代碼用正則來驗證客戶端的輸入,有些正則寫法驗證普通用戶輸入沒有問題, 但是如果攻擊人員使用的是特殊構造的字符串來驗證,有可能導致死循環的效果。
**【安全】**禁止向 HTML 頁面輸出未經安全過濾或未正確轉義的用戶數據。
**【安全】**表單、AJAX 提交必須執行 CSRF 安全過濾。
說明:CSRF(Cross-site request forgery)跨站請求偽造是一類常見編程漏洞。對于存在 CSRF 漏洞的應用/網站,攻擊者可以事先構造好 URL,只要受害者用戶一訪問,后臺便在用戶 不知情情況下對數據庫中用戶參數進行相應修改。
**【安全】**在使用平臺資源,譬如短信、郵件、電話、下單、支付,必須實現正確的防重放限制, 如數量限制、疲勞度控制、驗證碼校驗,避免被濫刷、資損。
說明:如注冊時發送驗證碼到手機,如果沒有限制次數和頻率,那么可以利用此功能騷擾到其 它用戶,并造成短信平臺資源浪費。
**【安全】**發貼、評論、發送即時消息等用戶生成內容的場景必須實現防刷、文本內容違禁詞過 濾等風控策略。
- 概要
- 技術介紹
- 框架與環境
- vue開發
- 開發規范
- 前端開發規范
- 總體原則
- HTML規范
- HTML&css規范
- vue編碼規范
- Javascript規范
- 后端開發規范
- cap4
- 自定義控件
- 前端2.0(PC+移動)
- PC前端
- 后端
- 移動端
- 移動端接口
- 低版本協同升級到V5 8.0適配說明
- 自定義按鈕
- 自定義按鈕(無流程)
- 自定義控件(列表插槽)
- 自定義按鈕(篩選條件)
- 低版本協同升級到V5 8.0適配說明
- 門戶空間
- 門戶與欄目掛載
- 欄目開發及流程說明
- 頁面模板
- 客開通路及插件體系
- 表單設計器擴展配置
- 使用步驟
- 配置說明
- 事件API
- Demo示例
- 運行態客開通路
- 插件使用步驟
- 插件接口
- 事件接口
- 鉤子相關接口
- 表單操作接口
- Demo示例
- 插件機制
- 表單運行態接口(舊)
- 白名單插件
- 版本記錄
- vue組件庫
- 開發指南
- 開發文檔規范
- 業務組件介紹
- 業務組件
- table組件
- 分頁組件
- title組件
- 統計排隊組件
- code組件
- 條件篩選
- 批量導入
- 上傳Excel
- 批量更新
- 批量刷新
- UI組件
- 按鈕組件
- 復選組件
- 取色器組件
- 示例組件
- 水平選擇組件
- 選圖標組件
- 提示組件
- 單選組件
- 搜索組件
- 選擇組件
- 穿梭框組件
- 標簽組件
- 文本組件
- 樹組件
- 驗證組件
- 菜單組件
- iframe組件
- toolbar
- 統計組件
- 餅圖
- 柱狀圖
- 圖標
- 業務關系開發指南
- 自定義觸發
- 自定義關聯
- 后端API
- 更新表單數據緩存
- 發起表單流程
- 取得指定表單PDF或截圖
- 無流程批量添加
- 無流程批量刪除
- 無流程批量更新
- 無流程批量導出
- 客開培訓文檔
- Vue基礎培訓
- Vue實戰培訓
- Vue進階培訓
- VueCLI3培訓
- cap3
- 自定義控件
- 后端
- 移動端
- 前端編譯
- 表單運行態接口
- 協同云