
~~~
/*
* 分組的作用
* 1.改變的默認的優先級
* 2.分組捕獲
* 3.分組引用
*/
// let reg = /^18|19$/;
// console.log(reg.test('18'));//=>true
// console.log(reg.test('19'));//=>true
// console.log(reg.test('1819'));//=>true
// console.log(reg.test('189'));//=>true
// console.log(reg.test('181'));//=>true
// console.log(reg.test('819'));//=>true
// console.log(reg.test('119'));//=>true
// reg = /^(18|19)$/;
// console.log(reg.test('18'));//=>true
// console.log(reg.test('19'));//=>true
// console.log(reg.test('1819'));//=>false
// console.log(reg.test('189'));//=>false
// console.log(reg.test('181'));//=>false
// console.log(reg.test('819'));//=>false
// console.log(reg.test('119'));//=>false
// let reg = /^([a-z])([a-z])\2\1$/;//=>正則中出現的\1代表和第一個分組出現一模一樣的內容...
// console.log(reg.test('oppo'));
// console.log(reg.test('poop'));
//=>編寫一個正則匹配身份證號碼
// let reg = /^\d{17}(\d|X)$/;//=>簡單:只能匹配是否符合格式,不能提取出身份證中的一些信息
// '130828199012040617'
//=>130828 地域
//=>19901204 出生年月
//=>0617 倒數第二位:奇數=男 偶數=女
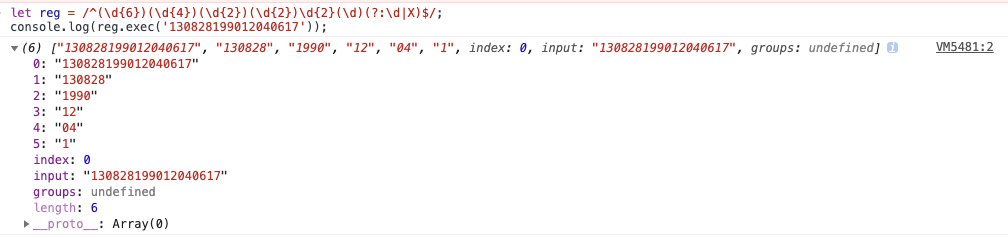
let reg = /^(\d{6})(\d{4})(\d{2})(\d{2})\d{2}(\d)(?:\d|X)$/;
console.log(reg.exec('130828199012040617'));
//=>EXEC實現的是正則捕獲,獲取的結果是一個數組,如果不匹配獲取的結果是null,
// 捕獲的時候不僅把大正則匹配的信息捕獲到,
// 而且每一個小分組中的內容也捕獲到了(分組捕獲)
// : ["130828199012040617", "130828", "1990", "12", "04", "1", index: 0, input: "130828199012040617"]
/*
* 正則捕獲使用的是正則中的EXEC方法
* 1.如果可以匹配獲取的結果是一個數組,如果不能匹配獲取的結果是NULL
* 2.如果我們只在匹配的時候,想要獲取大正則中部分信息,我們可以把這部分使用小括號包起來,形成一個分組,
* 這樣在捕獲的時候,不僅可以把大正匹配的信息捕獲到,
* 而且還單獨的把小分組匹配的部分信息也捕獲到了(分組捕獲)
* 3.有時候寫小分組不是為了捕獲信息,只是為了改變優先級或者進行分組引用,
* 此時我們可以在分組的前面加上“?:”,代表只去匹配,但是不把這個分組內容捕獲
*/
~~~

- 1.變量提升、閉包、THIS、OOP
- 0002.NODE安裝及一些基礎概念
- 0003.常用的DOS命令
- 0004.基于npm包管理器下載所需資源
- 0005.簡單操作一遍gitHub
- 0006.集中式vs分布式版本控制系統
- 0007.簡述git安裝
- 0008.基于git創建一個空倉庫
- git-svn區別
- 0009.git的工作流程
- 0010.完成本地git倉庫個遠程gitHub倉庫的信息同步
- 0011.JS數據渲染機制及堆棧內存
- 0012.變量提升機制
- 0013.帶VAR和不帶的區別
- 0014.作用域鏈的一些擴展
- 0015.變量提升的一些細節問題(關于條件判斷下的處理)
- 0016.條件判斷下的變量提升到底有多坑
- 0017.變量提升機制下重名的處理
- 0018.ES6中的LET不存在變量提升
- 0019.JS中的暫時性死區問題
- 0020.區分私有變量和全局變量
- 0021.有關私有變量和作用域鏈的練習題
- 0022.上級作用域的查找
- 0023.閉包及堆棧內存釋放
- 0024.閉包作用之保護
- 0026.單例設計模式的理論模型
- 0027.強化高級單例模式理論模型
- 0028.實戰項目中的模塊化
- 0029.沒有什么實際意義的工廠模式
- 0030.JS是基于面向對象開發設計的語言
- 0031.創建值的兩種方式以及區別
- 0032.構造函數執行的機制
- 0033.構造函數中的一些細節問題
- 0034.原型鏈和原型鏈的查找機制
- 0045.練習題講解[19]-關于原型重定向問題綜合練習
- 0035.練習題講解[01-05]
- 0036.練習題講解[06~08]-JS中的嚴格模式和ARG的映射機制
- 0037.課件3&練習題講解[09]-邏輯或和邏輯與
- 0038.課件4&練習題講解[10]-有關堆棧內存釋放
- 0039.課件5&練習題講解[11~13]
- 0040.課件6&練習題講解[14]-堆棧內存和this混合應用題
- 0041.課件7&練習題講解[15]-構造函數和原型鏈的運行機制
- 0042.課件8&練習題講解[16]-基于閉包解決循環綁定
- 0043.課件9&練習題講解[17]-有關this的兩道面試題
- 0044.課件10&練習題講解[18]-關于原型重定向問題
- 0045.課件11&練習題講解[19]-關于原型重定向問題綜合練習
- 0046.課件12&練習題講解[20]-數組去重引發的基于內置類原型擴展方法,并且實現鏈式調用
- 0047.課件13&練習題講解[其余隨性題]-閉包和團隊協作開發
- 0049.課件1&LESS學習-如何編譯less
- 0050.課件2&LESS學習-less中最常用的一些基礎語法
- 總結
- 數組常用方法
- 2.原型深入、THIS、商城排序、正則
- 0051.原型深入1-函數的三種角色
- 0052.原型深入2-基于阿里的面試題理解函數的三種角色
- 0053.原型深入3-原型鏈機制最終版(Function)
- 0054.原型深入4-深入理解原型和CALL
- 0055.原型深入5-call、apply、bind三者的區別
- 0056.原型深入6-基于APPLY獲取數組中的最大值
- 0057.數組和對象的解構賦值
- 0058.剩余和展開運算符
- 0059.把類數組轉換為數組
- 0060.原型深入8-基于ES6的方式把類數組轉換為數組
- 0061.ES6-箭頭函數
- 0062.課件1&商城排序1-基于AJAX獲取數據(不講AJAX)
- 0063.課件2&商城排序2-把獲取的JSON字符串轉換為對象
- 0064.課件3&商城排序3-基于ES6模板字符串完成數據綁定
- 0065.課件4&商城排序4-按照價格升序排序
- 0066.課件5&商城排序5-簡述DOM映射機制
- 0067.課件6&商城排序6-按照價格升降序切換
- 0068.課件7&商城排序7-實現多列升降序切換
- 0069.課件8&商城排序8-解決多列切換中的一點BUG
- 0070.課件9&商城排序9-如何學習和練習項目案例
- 0071.課件10&復習商城排序1-基于LESS實現樣式
- 0072.課件11&復習商城排序2-高級單例模式框架結構
- 0073.課件12&復習商城排序3-數據獲取和綁定
- 0074.課件13&復習商城排序4-學習DOM映射和告別DOM映射
- 0075.課件14&復習商城排序5-完成事件綁定的邏輯
- 0076.課件15&復習商城排序6-由數據綁定引發的DOM性能優化
- 0077.課件1&正則基礎概念和常用的元字符梳理
- 0078.課件2&中括號的一點特殊細節
- 0079.課件3&分組的三個作用
- 0080.課件4&常用的正則表達式
- 0081.課件5&正則捕獲的懶惰性和解決方案
- 0082.課件6&正則捕獲的貪婪性和分組捕獲
- 0083.課件7&更多的捕獲方式(REPLACE)
- 0084.課件8&處理時間字符串格式化
- 3.Dom盒子模型、JQ
- 0086.課件1&考試題講解-第一次考試題[01~03]
- 0087.課件2&考試題講解-第一次考試題[04]
- 0088.課件3&考試題講解-第一次考試題[05]
- 0089.課件4&考試題講解-第一次考試題[06~08]
- 0090.課件5&考試題講解-第二次考試題[01~05]
- 延時打印-無視頻
- 0091.課件1&DOM盒子模型1-復習常用的DOM操作屬性和方法
- 0092.課件2&DOM盒子模型2-JS盒子模型屬性第一部分
- 0093.課件3&DOM盒子模型3-獲取元素的具體樣式
- 4. 前三周綜合復習
- 0112.課件1&ES6新語法和DOM回流
- 0113.課件2&關于面向對象的理解
- 0114.課件3&關于THIS匯總
- 0115.課件4&作用域鏈和原型鏈
- 0116.課件5&數組去重
- 0117.課件6&遞歸算法和數組扁平化
- 0119.課件8&ES6中的類及繼承
- 0120.課件9&正則的一點應用
- 0121.課件10&關于對閉包的理解
- 0122.課件11&閉包、THIS、面向對象綜合練習題
- 0123.課件12&復雜一些的正則
- 0124.課件13&拿正則搞各種需求
- 0125.課件14&一些雜七雜八的題
- 0126.課件15&圖片延遲加載
- 0127.課件16&柯理化函數編程思想
- 5.定時器、異步、動畫庫、輪播
- 0129.課件1&定時器基礎知識
- 0130.課件2&JS中的同步異步編程核心原理
- 0131.課件3&初識Promise
- 0135.課件7&回調函數原理和實戰
- NODE和PROMISE-34
- 024-[PROMISR A+]-復習PROMISR的使用
- 022-重點***[專題匯總]-JS中的同步異步(宏任務和微任務)
- 6.事件、事件委托、發布訂閱
- 1.事件和事件委托
- 149.課件1&事件的理論基礎
- 150.課件2&事件對象中常用的屬性
- 151.課件3&事件對象的兼容問題
- 152.課件4&默認行為及阻止
- 153.課件5&事件傳播機制(很重要)
- 158.課件10&事件委托
- 161.課件13&基于事件委托實現無限級折疊菜單
- 169.課件8&[拖拽]擴展柯理化函數編程思想
- 2.DOM事件綁定、發布訂閱
- 162.課件1&DOM0和DOM2的運行機制(事件池機制)
- 163.課件2&DOM2事件綁定的兼容問題
- 7.移動端開發
- 8.AJAX
- 226.課件14&14-基于PROMISE解決回調地獄問題
- 9.AXIOS視頻
- node和promise
- 22-[專題匯總]-JS中的同步異步(宏任務和微任務)
- REACT