[TOC]
## 一、單選題
**1.一般,k-NN最近鄰方法在()的情況下效果較好** B
A.樣本較多但典型性不好
B.樣本較少但典型性好
C.樣本呈團狀分布
D.樣本呈鏈狀分布
**2. bootstrap數據是什么意思?( )** C
A.有放回地從總共M個特征中抽樣m個特征
B.無放回地從總共M個特征中抽樣m個特征
C.有放回地從總共N個樣本中抽樣n個樣本
D.無放回地從總共N個樣本中抽樣n個樣本
**3.對于下圖,一個比較好的主成分選擇是多少?()** B
A. 7
B. 30
C. 35
D.不能確定
**4.數據科學家可能會同時使用多個算法(模型)進行預測, 并且最后把這些算法的結果集成起來進行最后的預測(集成學習),以下對集成學習說法正確的是()** B
A.單個模型之間有高相關性
B.單個模型之間有低相關性
C.在集成學習中使用“平均權重”而不是“投票”會比較好
D.單個模型都是用的一個算法
**5.某超市研究銷售紀錄數據后發現,買啤酒的人很大概率也會購買尿布.這種屬于數據挖掘的哪類問題?( )** A
A、 關聯規則分析
B、 聚類
C、 分類
D、 自然語言處理
**6.當不知道數據所帶標簽時,可以使用哪種技術促使帶同類標簽的數據與帶其他標簽的數據相分離? ( )** B
A、分類
B、聚類
C、關聯規則發現
D、主成分分析
**7. Nave Bayes是一種特殊的Bayes分類器,特征變量是X,類別標簽是C,它的一個假定是( )** C
A、各類別的先驗概率P(C)是相等的
B、以0為均值. sqr(2)/2為標準差的正態分布
C、特征變量X的各個維度是類別條件獨立隨機變量
D、P(X|C)是高斯分布
**8. Lasso回歸與傳統的線性回歸方程區別是( )** A
A、增加L1范數懲罰因子
B、增加L2范數懲罰因子
C、無區別
D、Lasso回歸是線性方程在sigmoid函數上的嵌套
**9.協同過濾算法解決的是數據挖掘中的哪類問題( )** C
A、分類問題
B、聚類問題
C、推薦問題
D、自然語言處理問題
**10.交叉驗證如果設置K=5,會訓練幾次?( )** B
A、4
B、5
C、6
D、7
**11.評估完模型之后,發現模型存在高偏差(high bias),應該如何解決?( )** B
A、 減少模型的特征數量
B、 增加模型的特征數量
C、 增加樣本數量
D、 以上說法都正確
**12.將兩個簇的鄰近度定義為不同簇中任意兩點的最短距離,它是一種( )度量方式。** A
A.單鏈接
B.全鏈接
C.組平均
D.質心距離
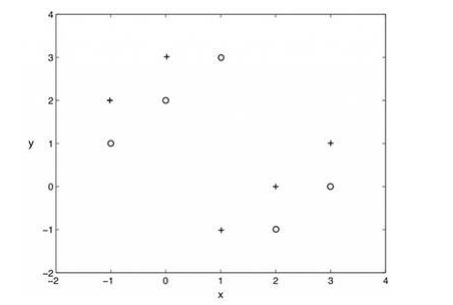
**13.使用k=1的knn算法,下圖二類分類問題, “+”和“o”分別代表兩個類,那么,用僅拿出一個測試樣本的交叉驗證方法,交叉驗證的錯誤率是多少( )** B
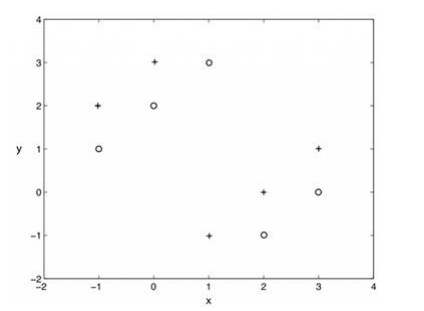
A、0%
B、100%
C、0%到100
D、 以上都不是
**14.下面有關分類算法的準確率,召回率,F1值的描述,錯誤的是( )** C
A、 準確率是檢索出相關文檔數與檢索出的文檔總數的比率,衡量的是檢索系統的查準率
B、 召回率是指檢索出的相關文檔數和文檔庫中所有的相關文檔數的比率,衡量的是檢索系統的查全
率
C、 正確率、召回率和F值取值都在0和1之間,數值越接近0,查準率或查全率就越高
D、 為了解決準確率和召回率沖突問題,引入了F1分數
**15.以下哪個算法是無監督學習算法:( )** C
A、樸素貝葉斯
B、LinearRegression
C、K-Means
D、支持向量機
**16.下面哪個算法可以將文本數據轉換為數值數據?( )** A
A、TF-IDF
B、 決策樹
C、PCA
D、DBSCAN
**17.以下哪個是回歸模型評判的指標?( )** A
A、mean\_squared\_error
B、 準確率
C、 召回率
D、 輪廓系數
**18.如果我使用數據集的全部特征并且能夠達到100%的準確率,但在測試集上僅能達到70%左右,這說明( )** C
A、 欠擬合
B、 模型很棒
C、 過擬合
D、 算法不好
**19.在以下不同的場景中,使用的分析方法不正確的是?( )** B
A.根據商家最近一年的經營及服務數據,用聚類算法判斷出天貓商家在各自主營類目下所屬的商家層級
B.根據商家近幾年的成交數據,用聚類算法擬合出用戶未來一個月可能的消費金額公式
C.用關聯規則算法分析出購買了汽車坐墊的買家,是否適合推薦汽車腳墊
D.根據用戶最近購買的商品信息,用決策樹算法識別出淘寶買家可能是男還是女
**20.將兩個簇的鄰近度定義為不同簇的所有點對的鄰近度的平均值,它是一種( )度量方式。** C
A.單鏈接
B.全鏈接
C.組平均
D.質心距離
**21.以下哪個算法是無監督學習算法( )** A
A. DBSCAN
B. RandomForestRegressor
C. KNN
D. SVC
**22.在使用sklearn的時候,我們經常使用train\_test\_split函數來切分數據集為訓練數據和測試數據,該函數位于哪個模塊( )** D
A. cluster
B. preprocessing
C. linear\_model
D. model\_selection
**23.以下哪個指標不是用來評估分類模型( )** C
A.準確率(Accuracy)
B.召回率(Recall)
C.輪廓系數(SilhouetteScore)
D. F1-score
**24. “點擊率問題”是這樣一個預測問題, 99%的人是不會點擊的,而1%的人是會點擊進去的,所以這是一個非常不平衡的數據集.假設,現在我們已經建了一個模型來分類,而且有了99%的預測準確率,我們可以下的結論是( )** C
A.模型預測準確率已經很高了,我們不需要做什么了
B.模型預測準確率不高,我們需要做點什么改進模型
C.無法下結論
D.以上都不對
**25.以下哪種算法是關聯規則挖掘( )** B
A. SVC
B. FP-growth
C. OPTICS
D. PCA
**26.為了可以把多個評估器鏈接成一個整體,sklearn中提供了PipeLine機制,下面關于PipeLine描述不正確的是( )** A
A.管道中的最后一個評估器一定要是一個實現了predict方法的學習器
B.管道中的所有評估器,除了最后一個評估器,管道中的所有評估器必須都是轉換器。
C.管道中的評估器參數可以通過\_\_語義來訪問
D.管道中的評估器可以通過索引或名稱訪問
**27.在進行數據挖掘任務的時候,通常面臨樣本數據特征過多的情況,我們可以通過Filter過濾法選擇那些對我們分析任務更有幫助的特征,下列方法哪個不是用來做特征過濾的( )** D
A.卡方檢驗
B. F檢驗
C.互信息法
D.奇異值分解
**28.關于頻繁模式,下面哪一個陳述是正確的( ) C**
A. K項集頻繁則K-1項則必定不頻繁
B. K項集不頻繁則K-1項則必定不頻繁
C. K項集頻繁則K-1項則必定頻繁
D.以上說法都不正確
**29. NaiveBayes是Bayes分類器的一種,如特征變量是X,類別標簽是C,它的假定是( )** C
A.各類別的先驗概率P(C)是相等的
B. X服從以0為均值,1為標準差的正態分布
C.特征變量X的各個維度是類別條件獨立隨機變量
D. P(X|C)是高斯分布
**30. Pandas處理缺失值的函數有( )** A
A. fillna
B. iloc
C. fit
D. transform
**31.決 策 樹 算 法 很 容 易 出 現 過 擬 合 , 我 們 通 常 會 使 用 一 些 剪 枝 手 段 來 改 善 這 一 現 象。 對 于sklearn.tree.DecisionTreeClassifier模型,下面這些參數哪個不能起到剪枝的作用( )** A
A. criterion
B. max\_depth
C. min\_samples\_split
D. min\_impurity\_split
**32.以下哪種算法是關聯規則挖掘( )** C
A. SVC
B. KNN
C. Apriori
D. PCA
**33.如果一個分類模型經訓練后,能在訓練集上達到99%的準確率,但在測試集上僅能達到75%左右,這說明( )** B
A.欠擬合
B.過擬合
C.正常現象
D.模型選擇不合適
**34.在sklearn中,下面哪個類或方法,位于preprocessing模塊( )** B
A. train\_test\_split
B. LabelEncoder
C. accuracy\_score
D. DecisionTreeClassifier
**35.以下哪個指標不是用來評估回歸模型( )** D
A. R2
B. MSE(Mean Squared Error)
C. MAE(Mean Absolute Error)
D. Recall
**36.邏輯回歸適用于以下哪種問題 ( )** B
A.回歸問題
B.二分類問題
C.聚類問題
D.關聯規則
**37. Lasso回歸與傳統的線性回歸最主要的區別是( )** A
A.增加L1正則項
B.增加L2正則項
C.無區別
D. Lasso回歸是線性方程在sigmoid函數上的嵌套
**38.設有如下所示的某商場購物記錄集合,每個購物籃中包含若干商品:**

**現在要基于該數據集進行關聯規則挖掘。如果設置最小支持度為60%,則如下頻繁項集中,符合條件的是()** A
A.啤酒,尿布
B.面包,尿布,牛奶
C.面包,牛奶
D.面包,啤酒,尿布
**39.數據的多重共線性導致我們無法使用最小二乘法求解線性回歸問題,以下哪個算法從根本上解決了這一點( )** A
A. Ridge回歸
B. Lasso回歸
C.邏輯回歸
D.多項式回歸
**40.當數據樣本的特征屬性為自然數時,應采用以下那種算法進行分類( )** B
A.多項式樸素貝葉斯
B.高斯樸素貝葉斯
C.貝努利樸素貝葉斯
D. K均值算法
