[TOC]
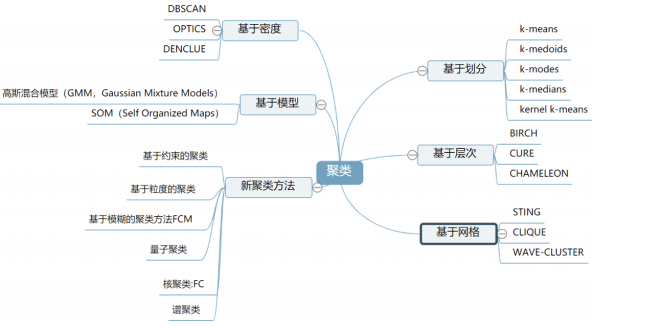
## **1.概念**
聚類(Clustering)分析是依據物以類聚的原理,將沒有類別的對象根據對象的特征自動聚集成不同簇的過程,使得屬于同一個簇的對象之間要盡可能非常相似,屬于不同簇的對象之間要盡可能不相似(簇內相似度高,簇間相似度低)。
聚類算法需要注意的地方:
* 距離/相似度的度量
* 數據的標準化
## **2.聚類的評估**
* 簇內平方和(Inertia)
* 屬性Inertia_
* 輪廓系數
* silhouette_score
* silhouette_score
* 卡林斯基-哈拉巴斯指數
* calinski_harabasz_score
## **3.基于劃分的聚類**
### **1)K-means算法步驟**
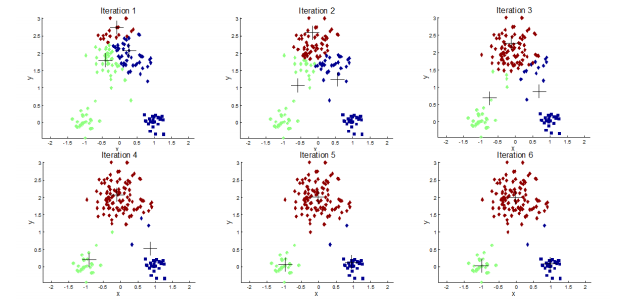
### **2)K-means缺點**
* 需要預先設定K值,對最先的K個點選取很敏感
* 對噪聲和離群值非常敏感
* 只適合對數值型數據聚類
* 不能解決非凸(non-convex)數據
### **3) K-means改進**
* k-means對初始值的設置很敏感,所以有了k-means++、intelligent k-means、genetic kmeans。
* k-means對噪聲和離群值非常敏感,所以有了k-medoids和k-medians。
* k-means只用于numerical類型數據,不適用于categorical類型數據,所以k-modes。
* k-means不能解決非凸(non-convex)數據,所以有了kernel k-means。
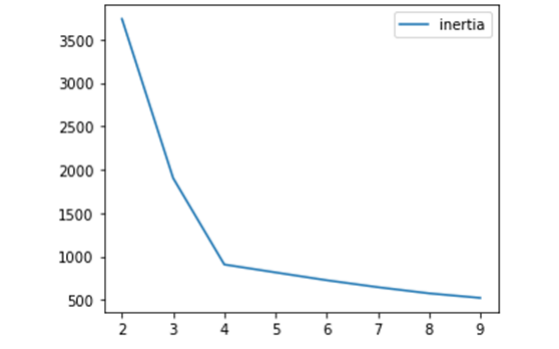
* K值的選擇:**肘點法**
## **4.基于層次的聚類**
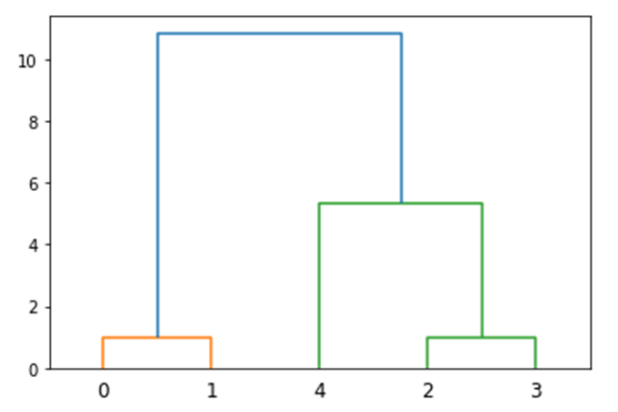
層次聚類(hierarchical clustering)方法將數據對象組成一棵聚類樹
* 分裂法
* 凝聚法
### **1)凝聚法的步驟**
1. 計算各數據間的相似度矩陣
2. 每個數據就是一個簇
3. Repeat。
4. 合并兩個最相似的簇形成新簇
5. 更新相似度矩陣
6. Until只剩一個類簇
### **2)簇間相似度的度量**
* MIN(單連接)
* MAX(全連接)
* Group Average(組平均)
* Distance Between Centroids(質心距離)
### **3)cluster.AgglomerativeClustering**
## **5.基于密度聚類**
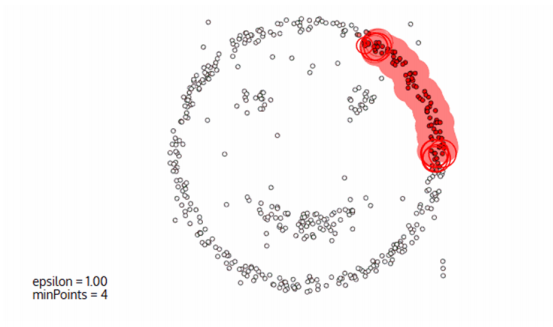
**DBSCAN**(Density-Based Spatial Clustering of Applications with Noise,具有噪聲的基于密度的聚類方法)是一種基于密度的空間聚類算法。該算法將具有足夠密度的區域劃分為簇,并在具有噪聲的空間數據庫中發現任意形狀的簇,它將簇定義為密度相連的點的最大集合。
### **1)概念**
* ?-領域:點x的?-領域是以該對象為中心,?為半徑的空間,?-領域可以寫成NEps(x):NEps(x) : {y belongs to D | dist(y,x) <= Eps}
* 密度:特定半徑內(Eps)數據點的數量
* 核心點(Core Point): 用戶指定一個參數MinPts,即指定稠密區域的密度閾值。如果一個點的?-領域至少包含MinPts個點,則稱該點為核心點
* 邊界點(Border point):對于點p,如果它的?-領域內包含的點少于MinPts個,但落在某個核心點的?-領域內,則稱點p為邊界點
* 噪聲點(Noise):既不是核心點又不是邊界點的任何點
### **2)優點**
* 發現任意形狀的聚類
* 處理噪音
### **3)缺點**
* 參數難以確定
* 效果不佳:
* 密度不均
* 高維數據
### **4)cluster.DBSCAN**
