[TOC]
## 1.預處理
### 1)數據無量綱化
* 好處:加快求解速度、提高模型精度
* 主要方法:中心化、縮放
1. 歸一化:preprocessing.MinMaxScaler
2. 標準化:
preprocessing.StandardScaler
preprocessing.Normalizer
...
* 基本使用:
1. 實例化對象\-> fit -> transform
2. 簡單使用形式:fit\_transform
3. 逆轉換:
inverse\_transform (Normalizer和KernelCenterer沒有這個方法)
### 2)缺失值
* impute.SimpleImputer
* impute.KNNImputer
* pandas相關方法:dropna、fillna、replace
### 3)處理分類型特征
* 標簽編碼(OrdinalEncoder、LabelEncoder)
* 獨熱編碼(OneHotEncoder、LabelBinarizer)
### 4)處理連續型特征
* Binarizer
* KBinsDiscretizer
## 2.特征選擇
* 模塊:feature\_selection

### 1)過濾法
** (1)如何過濾:**
* 基于單個特征本身的特性過濾
1. 方差過濾: feature\_selection.VarianceThreshold
* 基于特征與標簽的相關性進行過濾
1. 卡方過濾: feature\_selection.chi2
2. 互信息過濾:
(1).feature\_selection.f\_classif(F檢驗分類),用于標簽是離散型變量的數據
(2).feature\_selection.f\_regression(F檢驗回歸),用于標簽是連續型變量的
* F檢驗
1. feature\_selection.mutual\_info\_classif(互信息分類)
2. feature\_selection.mutual\_info\_regression(互信息回歸)
** (2)方法:**
* SelectKBest
* SelectPercentile
* SelectFpr/SelectFdr/SelectFwe
### 2)嵌入法
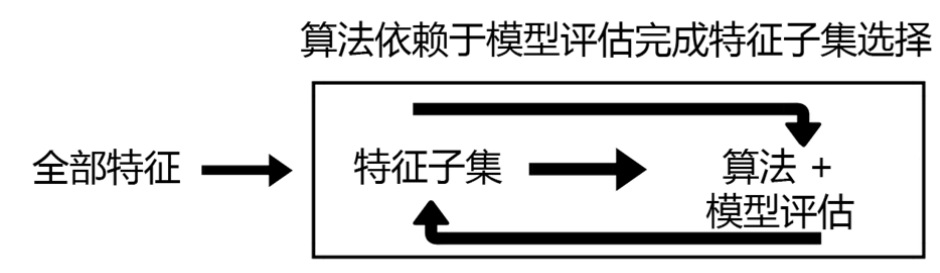
* feature\_selection.SelectFromModel
1. 要求評估器擬合后具有coef\_或者feature\_importances\_屬性
### 3)包裝法
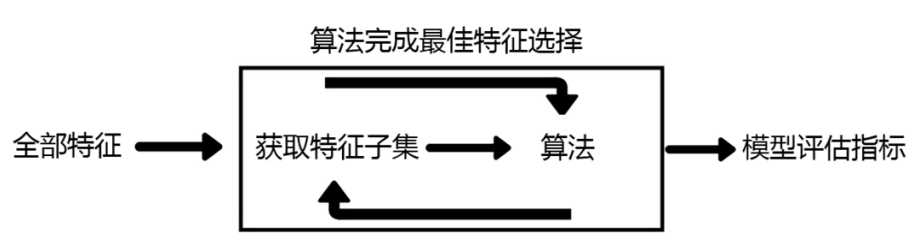
* feature\_selection.RFE
## 3.降維
* 目的:
1. 算法運算更快,效果更好
2. 數據可視化
* **降維的要求:即減少特征的數量,又保留大部分有效信息**
* 信息的度量:方差
* decomposition.PCA
## 4. pipeline
* Pipeline
1. 好處:便捷性和封裝性、聯合的參數選擇、安全性
2. 注意:管道中的所有評估器,除了最后一個評估器,管理的所有評估器必須都是轉換器(要實
3. 現了fit和transform方法),最后一個評估器的類型不限(只需要實現了fit方法)
4. Pipeline構造
5. 嵌套參數: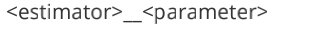
* FeatureUnion
1. 合并了多個轉換器對象形成一個新的轉換器
