[TOC]
## **1.概念**
**關聯分析(Association analysis)**,最早用于分析超市中顧客一次購買的物品之間的關聯性。發現大量數據中隱藏的關聯性和相關性,進而描述出一個事物中某些屬性同時出現的規律和模式,這些規律和模式即關聯規則。
* 項、項集、k項集、頻繁項集
* 支持度、置信度、提升度、杠桿率、確信度
* 關聯規則、強關聯規則
## **2.基本步驟**
(1)頻繁項集的產生
產生所有支持度大于支持度閾值的項集
(2)強關聯規則的產生
從頻繁項集中產生高置信度的規則,即強關聯規則
(3)尋找有用的強關聯規則
## **3. Apriori**
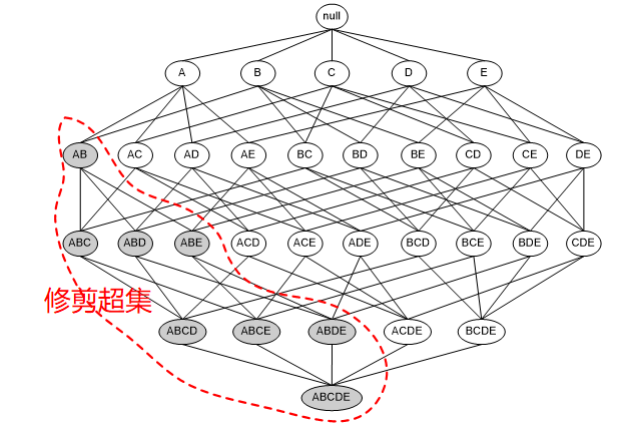
兩條基本規則:
(1)如果一個集合是頻繁項集,則它的所有子集都是頻繁項集。
(2)如果一個集合不是頻繁項集,則它的所有超集都不是頻繁項集。
## **4. FP-Growth**
Han等人提出FP-Growth(頻繁模式增長)算法,通過把交易集D中的信息壓縮到一個FP(Frequent
Pattern)樹結構中,可以在尋找頻繁集的過程中不需要產生候選集,大大減少了掃描全庫的次數,從而
大大提高了運算效率。
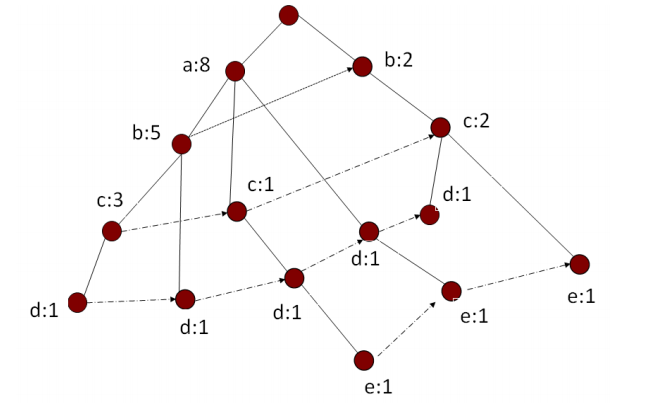
* 相比Apriori算法需要多次掃描數據庫,FPGrowth只需要對數據庫掃描2次。
* 第1次掃描獲得單個項的頻率,去掉不滿足支持度要求的項,并對剩下的項排序。
* 第2次掃描,對于每條數據剔除非頻繁1項集,并按照支持度降序排列。建立FP-Tree。
* 從FP-Tree中抽取頻繁項集,但不能發現數據之間的關聯規則
