
## 一、修改mmap計數大于等于262144的限制
~~~
#在/etc/sysctl.conf文件最后添加一行
vm.max_map_count=655360
#并執行命令
sysctl -p
~~~
## 二、下載并運行鏡像
~~~
docker run -p 5601:5601 -p 9200:9200 -p 9300:9300 -p 5044:5044 --name elk -d sebp/elk:651
~~~
## 三、準備elasticsearch的配置文件
~~~
mkdir /opt/elk/elasticsearch/conf
#復制elasticsearch的配置出來
docker cp elk:/etc/elasticsearch/elasticsearch.yml /opt/elk/elasticsearch/conf
~~~
## 四、修改elasticsearch.yml配置
* 修改cluster.name參數
~~~
cluster.name: my-es
~~~
* 在最后新增以下三個參數
~~~
thread_pool.bulk.queue_size: 1000
http.cors.enabled: true
http.cors.allow-origin: "*"
~~~
## 五、準備logstash的配置文件
~~~
mkdir /opt/elk/logstash/conf
?
#復制logstash的配置出來
docker cp elk:/etc/logstash/conf.d/. /opt/elk/logstash/conf/
~~~
## 六、準備logstash的patterns文件
* `mkdir /opt/elk/logstash/patterns`
* 新建一個`java`的patterns文件,`vim java`內容如下
~~~
# user-center
MYAPPNAME ([0-9a-zA-Z_-]*)
# RMI TCP Connection(2)-127.0.0.1
MYTHREADNAME ([0-9a-zA-Z._-]|\(|\)|\s)*
~~~
> 就是一個名字叫做**java**的文件,不需要文件后綴
## 七、刪除02-beats-input.conf的最后三句,去掉強制認證
~~~
vim /opt/elk/logstash/conf/02-beats-input.conf
#ssl => true
#ssl_certificate => "/pki/tls/certs/logstash.crt"
#ssl_key => "/pki/tls/private/logstash.key"
~~~
## 八、修改10-syslog.conf配置,改為以下內容
* **注意,下面的logstash結構化配置樣例都是以本工程的日志格式配置,并不是通用的**
~~~
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
syslog_pri { }
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
if [fields][docType] == "sys-log" {
grok {
patterns_dir => ["/opt/elk/logstash/patterns"]
match => { "message" => "\[%{NOTSPACE:appName}:%{NOTSPACE:serverIp}:%{NOTSPACE:serverPort}\] %{TIMESTAMP_ISO8601:logTime} %{LOGLEVEL:logLevel} %{WORD:pid} \[%{MYAPPNAME:traceId}\] \[%{MYTHREADNAME:threadName}\] %{NOTSPACE:classname} %{GREEDYDATA:message}" }
overwrite => ["message"]
}
date {
match => ["logTime","yyyy-MM-dd HH:mm:ss.SSS Z"]
}
date {
match => ["logTime","yyyy-MM-dd HH:mm:ss.SSS"]
target => "timestamp"
locale => "en"
timezone => "+08:00"
}
mutate {
remove_field => "logTime"
remove_field => "@version"
remove_field => "host"
remove_field => "offset"
}
}
if [fields][docType] == "point-log" {
grok {
patterns_dir => ["/opt/elk/logstash/patterns"]
match => {
"message" => "%{TIMESTAMP_ISO8601:logTime}\|%{MYAPPNAME:appName}\|%{WORD:resouceid}\|%{MYAPPNAME:type}\|%{GREEDYDATA:object}"
}
}
kv {
source => "object"
field_split => "&"
value_split => "="
}
date {
match => ["logTime","yyyy-MM-dd HH:mm:ss.SSS Z"]
}
date {
match => ["logTime","yyyy-MM-dd HH:mm:ss.SSS"]
target => "timestamp"
locale => "en"
timezone => "+08:00"
}
mutate {
remove_field => "logTime"
remove_field => "@version"
remove_field => "host"
remove_field => "offset"
}
}
}
~~~
## 九、修改30-output.conf配置,改為以下內容
~~~
output {
if [fields][docType] == "sys-log" {
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "sys-log-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
if [fields][docType] == "point-log" {
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "point-log-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
routing => "%{type}"
}
}
}
~~~
## 十、創建運行腳本
**`vim /opt/elk/start.sh`**
~~~
docker stop elk
docker rm elk
docker run -p 5601:5601 -p 9200:9200 -p 9300:9300 -p 5044:5044 \
-e LS_HEAP_SIZE="1g" -e ES_JAVA_OPTS="-Xms2g -Xmx2g" \
-v $PWD/elasticsearch/data:/var/lib/elasticsearch \
-v $PWD/elasticsearch/plugins:/opt/elasticsearch/plugins \
-v $PWD/logstash/conf:/etc/logstash/conf.d \
-v $PWD/logstash/patterns:/opt/logstash/patterns \
-v $PWD/elasticsearch/conf/elasticsearch.yml:/etc/elasticsearch/elasticsearch.yml \
-v $PWD/elasticsearch/log:/var/log/elasticsearch \
-v $PWD/logstash/log:/var/log/logstash \
--name elk \
-d sebp/elk:651
~~~
## 十一、運行鏡像
~~~
sh start.sh
~~~
復制
## 十二、添加索引模板(非必需)
如果是單節點的es需要去掉索引的副本配置,不然會出現`unassigned_shards`
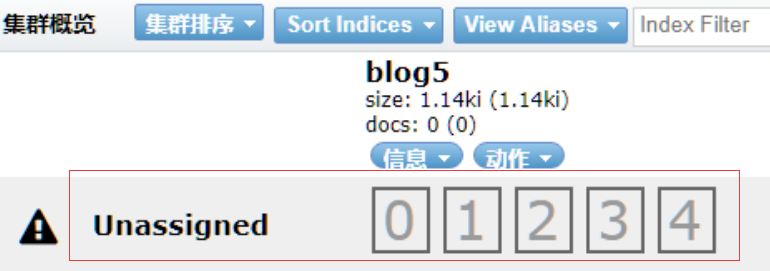
2. 設置索引模板
**系統日志**
~~~
curl -XPUT http://192.168.28.130:9200/_template/template_sys_log -H 'Content-Type: application/json' -d '
{
"index_patterns" : ["sys-log-*"],
"order" : 0,
"settings" : {
"number_of_replicas" : 0
},
"mappings": {
"doc": {
"properties": {
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "ik_max_word"
},
"pid": {
"type": "text"
},
"serverPort": {
"type": "text"
},
"logLevel": {
"type": "text"
},
"traceId": {
"type": "text"
}
}
}
}
}'
~~~
**慢sql日志**
~~~
curl -XPUT http://192.168.28.130:9200/_template/template_sql_slowlog -H 'Content-Type: application/json' -d '
{
"index_patterns" : ["mysql-slowlog-*"],
"order" : 0,
"settings" : {
"number_of_replicas" : 0
},
"mappings": {
"doc": {
"properties": {
"query_str": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "ik_max_word"
}
}
}
}
}'
~~~
**埋點日志**
~~~
curl -XPUT http://192.168.28.130:9200/_template/template_point_log -H 'Content-Type: application/json' -d '
{
"index_patterns" : ["point-log-*"],
"order" : 0,
"settings" : {
"number_of_shards" : 2,
"number_of_replicas" : 0
}
}'
~~~
## 十三、安裝IK分詞器
查詢數據,都是使用的默認的分詞器,分詞效果不太理想,會把text的字段分成一個一個漢字,然后搜索的時候也會把搜索的句子進行分詞,所以這里就需要更加智能的分詞器IK分詞器了
### 1\. 下載
下載地址:[https://github.com/medcl/elasticsearch-analysis-ik/releases](https://github.com/medcl/elasticsearch-analysis-ik/releases)
這里你需要根據你的Es的版本來下載對應版本的IK
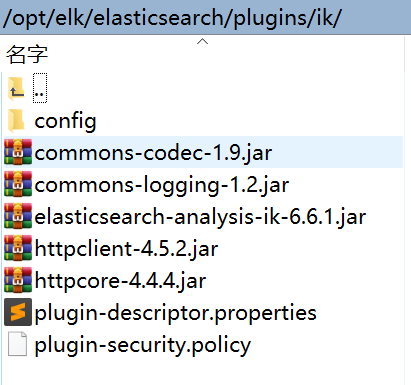
### 2\. 解壓-->將文件復制到 es的安裝目錄/plugin/ik下面即可
完成之后效果如下:
### 3\. 重啟容器并檢查插件是否安裝成功
[http://192.168.28.130:9200/\_cat/plugins](http://192.168.28.130:9200/_cat/plugins)
## 十四、配置樣例
鏈接:[https://pan.baidu.com/s/1Qq3ywAbXMMRYyYxBAViMag](https://pan.baidu.com/s/1Qq3ywAbXMMRYyYxBAViMag)
提取碼: aubp
- springcloud
- springcloud的作用
- springboot服務提供者和消費者
- Eureka
- ribbon
- Feign
- feign在微服務中的使用
- feign充當http請求工具
- Hystrix 熔斷器
- Zuul 路由網關
- Spring Cloud Config 分布式配置中心
- config介紹與配置
- Spring Cloud Config 配置實戰
- Spring Cloud Bus
- gateway
- 概念講解
- 實例
- GateWay
- 統一日志追蹤
- 分布式鎖
- 1.redis
- springcloud Alibaba
- 1. Nacos
- 1.1 安裝
- 1.2 特性
- 1.3 實例
- 1. 整合nacos服務發現
- 2. 整合nacos配置功能
- 1.4 生產部署方案
- 環境隔離
- 原理講解
- 1. 服務發現
- 2. sentinel
- 3. Seata事務
- CAP理論
- 3.1 安裝
- 分布式協議
- 4.熔斷和降級
- springcloud與alibba
- oauth
- 1. abstract
- 2. oauth2 in micro-service
- 微服務框架付費
- SkyWalking
- 介紹與相關資料
- APM系統簡單對比(zipkin,pinpoint和skywalking)
- server安裝部署
- agent安裝
- 日志清理
- 統一日志中心
- docker安裝部署
- 安裝部署
- elasticsearch 7.x
- logstash 7.x
- kibana 7.x
- ES索引管理
- 定時清理數據
- index Lifecycle Management
- 沒數據排查思路
- ELK自身組件監控
- 多租戶方案
- 慢查詢sql
- 日志審計
- 開發
- 登錄認證
- 鏈路追蹤
- elk
- Filebeat
- Filebeat基礎
- Filebeat安裝部署
- 多行消息Multiline
- how Filebeat works
- Logstash
- 安裝
- rpm安裝
- docker安裝Logstash
- grok調試
- Grok語法調試
- Grok常用表達式
- 配置中常見判斷
- filter提取器
- elasticsearch
- 安裝
- rpm安裝
- docker安裝es
- 使用
- 概念
- 基礎
- 中文分詞
- 統計
- 排序
- 倒排與正排索引
- 自定義dynamic
- 練習
- nested object
- 父子關系模型
- 高亮
- 搜索提示
- kibana
- 安裝
- docker安裝
- rpm安裝
- 整合
- 收集日志
- 慢sql
- 日志審計s
- 云
- 分布式架構
- 分布式鎖
- Redis實現
- redisson
- 熔斷和降級