
[TOC]
目前有很多項目還在使用redis的 setNx 充當分布式鎖,然而這個鎖是有問題的,redisson是java支持redis的redlock的唯一實現,。目前支持集群模式,云托管模式,單Redis節點模式,哨兵模式,主從模式 配置. 支持 可重入鎖,公平鎖,聯鎖,紅鎖,讀寫鎖 鎖定模式
# 1.setNX的坑
## **1. 非原子操作,未設備鎖失效時間**
使用redis的分布式鎖,我們首先想到的可能是setNx命令。
```
if (jedis.setnx(lockKey, val) == 1) {
jedis.expire(lockKey, timeout);
}
```
加鎖操作和后面的設置超時時間是分開的,并非原子操作。
假如加鎖成功,但是設置超時時間失敗了,該lockKey就變成永不失效。假如在高并發場景中,有大量的lockKey加鎖成功了,但不會失效,有可能直接導致redis內存空間不足。
* [ ] 解決辦法
```
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
```
其中:
```
lockKey:鎖的標識
requestId:請求id
NX:只在鍵不存在時,才對鍵進行設置操作。
PX:設置鍵的過期時間為 millisecond 毫秒。
expireTime:過期時間
set命令是原子操作,加鎖和設置超時時間,一個命令就能輕松搞定。
```
## 2. 不能合理釋放鎖
使用set命令加鎖,表面上看起來沒有問題。但如果仔細想想,加鎖之后,每次都要達到了超時時間才釋放鎖,會不會有點不合理?加鎖后,如果不及時釋放鎖,會有很多問題。
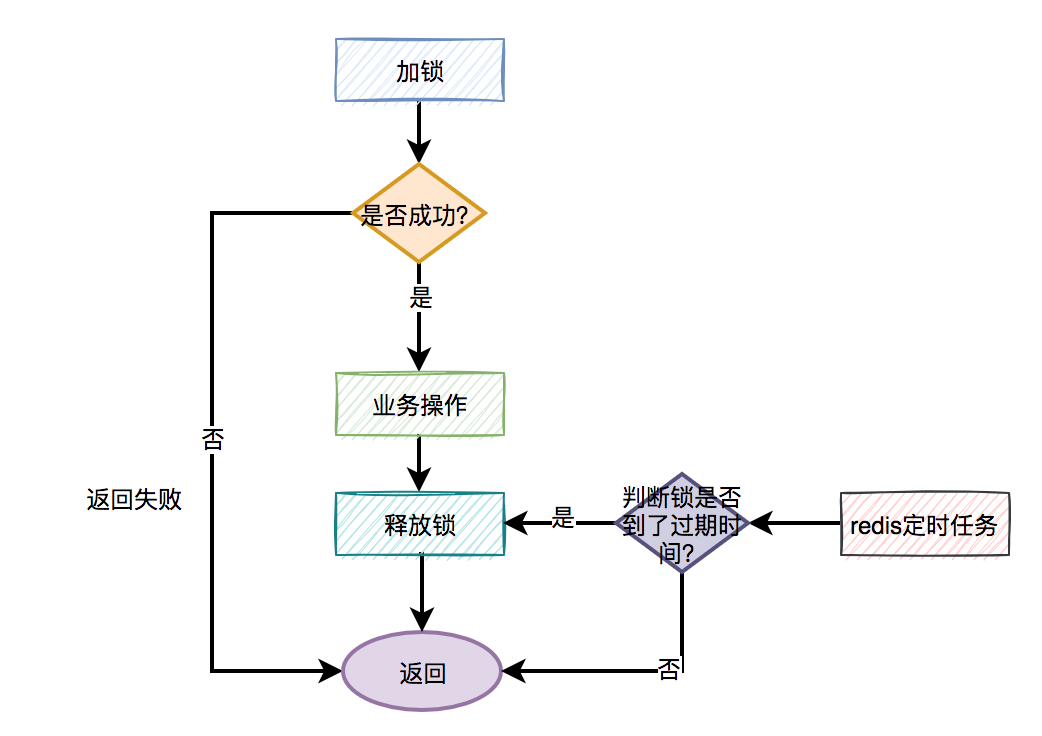
分布式鎖更合理的用法是:
手動加鎖
業務操作
手動釋放鎖
如果手動釋放鎖失敗了,則達到超時時間,redis會自動釋放鎖。
大致流程圖如下
```
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
} finally {
unlock(lockKey);
}
```
需要捕獲業務代碼的異常,然后在finally中釋放鎖。換句話說就是:無論代碼執行成功或失敗了,都需要釋放鎖。
此時,有些朋友可能會問:假如剛好在釋放鎖的時候,系統被重啟了,或者網絡斷線了,或者機房斷點了,不也會導致釋放鎖失敗?
這是一個好問題,因為這種小概率問題確實存在。
但還記得前面我們給鎖設置過超時時間嗎?即使出現異常情況造成釋放鎖失敗,但到了我們設定的超時時間,鎖還是會被redis自動釋放。
但只在finally中釋放鎖,就夠了嗎?
## 3 釋放了別人的鎖
做人要厚道,先回答上面的問題:只在finally中釋放鎖,當然是不夠的,因為釋放鎖的姿勢,還是不對。
哪里不對?
答:在多線程場景中,可能會出現釋放了別人的鎖的情況。
有些朋友可能會反駁:假設在多線程場景中,線程A獲取到了鎖,但如果線程A沒有釋放鎖,此時,線程B是獲取不到鎖的,何來釋放了別人鎖之說?
**答:假如線程A和線程B,都使用lockKey加鎖。線程A加鎖成功了,但是由于業務功能耗時時間很長,超過了設置的超時時間。這時候,redis會自動釋放lockKey鎖。此時,線程B就能給lockKey加鎖成功了,接下來執行它的業務操作。恰好這個時候,線程A執行完了業務功能,接下來,在finally方法中釋放了鎖lockKey。這不就出問題了,線程B的鎖,被線程A釋放了。**
不知道你們注意到沒?在使用set命令加鎖時,除了使用lockKey鎖標識,還多設置了一個參數:requestId,為什么要需要記錄requestId呢?
答:requestId是在釋放鎖的時候用的。
偽代碼如下:
```
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
return true;
}
return false;
```
在釋放鎖的時候,先獲取到該鎖的值(之前設置值就是requestId),然后判斷跟之前設置的值是否相同,如果相同才允許刪除鎖,返回成功。如果不同,則直接返回失敗。
換句話說就是:自己只能釋放自己加的鎖,不允許釋放別人加的鎖。
這里為什么要用requestId,用userId不行嗎?
答:如果用userId的話,對于請求來說并不唯一,多個不同的請求,可能使用同一個userId。而requestId是全局唯一的,不存在加鎖和釋放鎖亂掉的情況。
此外,使用lua腳本,也能解決釋放了別人的鎖的問題:
```
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
```
lua腳本能保證查詢鎖是否存在和刪除鎖是原子操作,用它來釋放鎖效果更好一些。
說到lua腳本,其實加鎖操作也建議使用lua腳本:
```
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
```
這是redisson框架的加鎖代碼,寫的不錯,大家可以借鑒一下。
有趣,下面還有哪些好玩的東西?
## 4 大量失敗請求
上面的加鎖方法看起來好像沒有問題,但如果你仔細想想,如果有1萬的請求同時去競爭那把鎖,可能只有一個請求是成功的,其余的9999個請求都會失敗。
在秒殺場景下,會有什么問題?
答:每1萬個請求,有1個成功。再1萬個請求,有1個成功。如此下去,直到庫存不足。這就變成均勻分布的秒殺了,跟我們想象中的不一樣。
如何解決這個問題呢?
此外,還有一種場景:
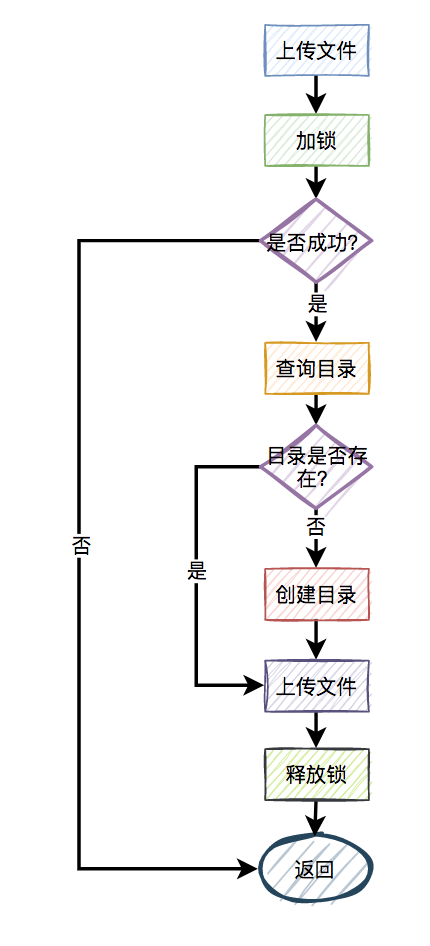
比如,有兩個線程同時上傳文件到sftp,上傳文件前先要創建目錄。假設兩個線程需要創建的目錄名都是當天的日期,比如:20210920,如果不做任何控制,直接并發的創建目錄,第二個線程必然會失敗。
這時候有些朋友可能會說:這還不容易,加一個redis分布式鎖就能解決問題了,此外再判斷一下,如果目錄已經存在就不創建,只有目錄不存在才需要創建。
偽代碼如下:
```
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;
```
一切看似美好,但經不起仔細推敲。
來自靈魂的一問:第二個請求如果加鎖失敗了,接下來,是返回失敗,還是返回成功呢?
主要流程圖如下:
答:使用`自旋鎖`。
```
try {
Long start = System.currentTimeMillis();
while(true) {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
long time = System.currentTimeMillis() - start;
if (time>=timeout) {
return false;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} finally{
unlock(lockKey,requestId);
}
return false;
```
在規定的時間,比如500毫秒內,自旋不斷嘗試加鎖(說白了,就是在死循環中,不斷嘗試加鎖),如果成功則直接返回。如果失敗,則休眠50毫秒,再發起新一輪的嘗試。如果到了超時時間,還未加鎖成功,則直接返回失敗。
## 5. 鎖重入問題
我們都知道redis分布式鎖是互斥的。假如我們對某個key加鎖了,如果該key對應的鎖還沒失效,再用相同key去加鎖,大概率會失敗。
假設在某個請求中,需要獲取一顆滿足條件的菜單樹或者分類樹。我們以菜單為例,這就需要在接口中從根節點開始,遞歸遍歷出所有滿足條件的子節點,然后組裝成一顆菜單樹。
需要注意的是菜單不是一成不變的,在后臺系統中運營同學可以動態添加、修改和刪除菜單。為了保證在并發的情況下,每次都可能獲取最新的數據,這里可以加redis分布式鎖。
加redis分布式鎖的思路是對的。但接下來問題來了,在遞歸方法中遞歸遍歷多次,每次都是加的同一把鎖。遞歸第一層當然是可以加鎖成功的,但遞歸第二層、第三層…第N層,不就會加鎖失敗了?
遞歸方法中加鎖的偽代碼如下:
```
private int expireTime = 1000;
public void fun(int level,String lockKey,String requestId){
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(level<=10){
this.fun(++level,lockKey,requestId);
} else {
return;
}
}
return;
} finally {
unlock(lockKey,requestId);
}
}
```
如果你直接這么用,看起來好像沒有問題。但最終執行程序之后發現,等待你的結果只有一個:出現異常。
因為從根節點開始,第一層遞歸加鎖成功,還沒釋放鎖,就直接進入第二層遞歸。因為鎖名為lockKey,并且值為requestId的鎖已經存在,所以第二層遞歸大概率會加鎖失敗,然后返回到第一層。第一層接下來正常釋放鎖,然后整個遞歸方法直接返回了。
這下子,大家知道出現什么問題了吧?
沒錯,遞歸方法其實只執行了第一層遞歸就返回了,其他層遞歸由于加鎖失敗,根本沒法執行。
那么這個問題該如何解決呢?
答:使用可重入鎖。
我們以redisson框架為例,它的內部實現了可重入鎖的功能。
古時候有句話說得好:為人不識陳近南,便稱英雄也枉然。
我說:分布式鎖不識redisson,便稱好鎖也枉然。哈哈哈,只是自娛自樂一下。
由此可見,redisson在redis分布式鎖中的江湖地位很高。
偽代碼如下:
```
private int expireTime = 1000;
public void run(String lockKey) {
RLock lock = redisson.getLock(lockKey);
this.fun(lock,1);
}
public void fun(RLock lock,int level){
try{
lock.lock(5, TimeUnit.SECONDS);
if(level<=10){
this.fun(lock,++level);
} else {
return;
}
} finally {
lock.unlock();
}
}
```
上面的代碼也許并不完美,這里只是給了一個大致的思路,如果大家有這方面需求的話,以上代碼僅供參考。
接下來,聊聊redisson可重入鎖的實現原理。
加鎖主要是通過以下腳本實現的:
```
if (redis.call('exists', KEYS[1]) == 0)
then
redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
```
其中:
KEYS[1]:鎖名
ARGV[1]:過期時間
ARGV[2]:uuid + “:” + threadId,可認為是requestId
先判斷如果鎖名不存在,則加鎖。
接下來,判斷如果鎖名和requestId值都存在,則使用hincrby命令給該鎖名和requestId值計數,每次都加1。注意一下,這里就是重入鎖的關鍵,鎖重入一次值就加1。
如果鎖名存在,但值不是requestId,則返回過期時間。
釋放鎖主要是通過以下腳本實現的:
```
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0)
then
return nil
end
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1)
if (counter > 0)
then
redis.call('pexpire', KEYS[1], ARGV[2]); return 0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
return nil
```
先判斷如果鎖名和requestId值不存在,則直接返回。
如果鎖名和requestId值存在,則重入鎖減1。
如果減1后,重入鎖的value值還大于0,說明還有引用,則重試設置過期時間。
如果減1后,重入鎖的value值還等于0,則可以刪除鎖,然后發消息通知等待線程搶鎖。
再次強調一下,如果你們系統可以容忍數據暫時不一致,有些場景不加鎖也行,我在這里只是舉個例子,本節內容并不適用于所有場景。
## 6 鎖競爭問題
如果有大量需要寫入數據的業務場景,使用普通的redis分布式鎖是沒有問題的。
但如果有些業務場景,寫入的操作比較少,反而有大量讀取的操作。這樣直接使用普通的redis分布式鎖,會不會有點浪費性能?
我們都知道,鎖的粒度越粗,多個線程搶鎖時競爭就越激烈,造成多個線程鎖等待的時間也就越長,性能也就越差。
所以,提升redis分布式鎖性能的第一步,就是要把鎖的粒度變細。
### 6.1 讀寫鎖
眾所周知,加鎖的目的是為了保證,在并發環境中讀寫數據的安全性,即不會出現數據錯誤或者不一致的情況。
但在絕大多數實際業務場景中,一般是讀數據的頻率遠遠大于寫數據。而線程間的并發讀操作是并不涉及并發安全問題,我們沒有必要給讀操作加互斥鎖,只要保證讀寫、寫寫并發操作上鎖是互斥的就行,這樣可以提升系統的性能。
我們以redisson框架為例,它內部已經實現了讀寫鎖的功能。
讀鎖的偽代碼如下:
```
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.readLock();
try {
rLock.lock();
//業務操作
} catch (Exception e) {
log.error(e);
} finally {
rLock.unlock();
}
```
寫鎖的偽代碼如下:
```
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.writeLock();
try {
rLock.lock();
//業務操作
} catch (InterruptedException e) {
log.error(e);
} finally {
rLock.unlock();
}
```
將讀鎖和寫鎖分開,最大的好處是提升讀操作的性能,因為讀和讀之間是共享的,不存在互斥性。而我們的實際業務場景中,絕大多數數據操作都是讀操作。所以,如果提升了讀操作的性能,也就會提升整個鎖的性能。
下面總結一個讀寫鎖的特點:
讀與讀是共享的,不互斥
讀與寫互斥
寫與寫互斥
### 6.2 鎖分段
此外,為了減小鎖的粒度,比較常見的做法是將大鎖:分段。
在java中ConcurrentHashMap,就是將數據分為16段,每一段都有單獨的鎖,并且處于不同鎖段的數據互不干擾,以此來提升鎖的性能。
放在實際業務場景中,我們可以這樣做:
比如在秒殺扣庫存的場景中,現在的庫存中有2000個商品,用戶可以秒殺。為了防止出現超賣的情況,通常情況下,可以對庫存加鎖。如果有1W的用戶競爭同一把鎖,顯然系統吞吐量會非常低。
為了提升系統性能,我們可以將庫存分段,比如:分為100段,這樣每段就有20個商品可以參與秒殺。
在秒殺的過程中,先把用戶id獲取hash值,然后除以100取模。模為1的用戶訪問第1段庫存,模為2的用戶訪問第2段庫存,模為3的用戶訪問第3段庫存,后面以此類推,到最后模為100的用戶訪問第100段庫存。
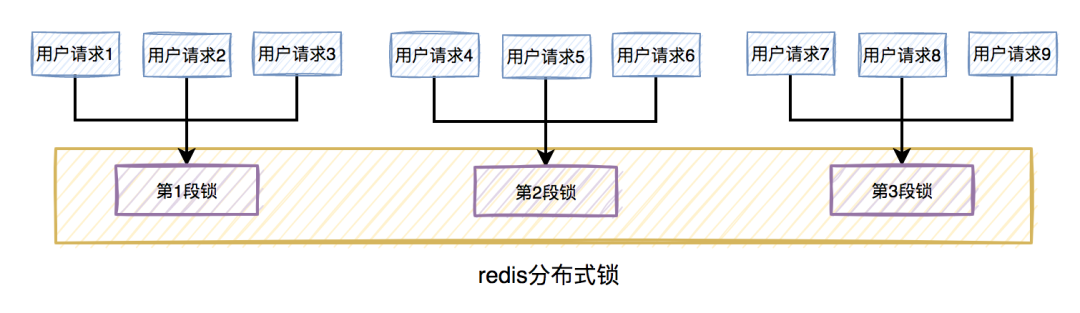
如此一來,在多線程環境中,可以大大的減少鎖的沖突。以前多個線程只能同時競爭1把鎖,尤其在秒殺的場景中,競爭太激烈了,簡直可以用慘絕人寰來形容,其后果是導致絕大數線程在鎖等待。現在多個線程同時競爭100把鎖,等待的線程變少了,從而系統吞吐量也就提升了。
## 7. 鎖超時問題
我在前面提到過,如果線程A加鎖成功了,但是由于業務功能耗時時間很長,超過了設置的超時時間,這時候redis會自動釋放線程A加的鎖。
有些朋友可能會說:到了超時時間,鎖被釋放了就釋放了唄,對功能又沒啥影響。
答:錯,錯,錯。對功能其實有影響。
通常我們加鎖的目的是:為了防止訪問臨界資源時,出現數據異常的情況。比如:線程A在修改數據C的值,線程B也在修改數據C的值,如果不做控制,在并發情況下,數據C的值會出問題。
為了保證某個方法,或者段代碼的互斥性,即如果線程A執行了某段代碼,是不允許其他線程在某一時刻同時執行的,我們可以用synchronized關鍵字加鎖。
但這種鎖有很大的局限性,只能保證單個節點的互斥性。如果需要在多個節點中保持互斥性,就需要用redis分布式鎖。
做了這么多鋪墊,現在回到正題。
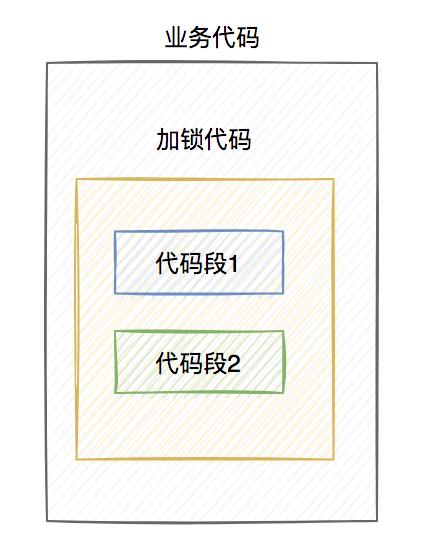
程要執行的業務操作非常耗時,程序在執行完代碼1的時,已經到了設置的超時時間,redis自動釋放了鎖。而代碼2還沒來得及執行。
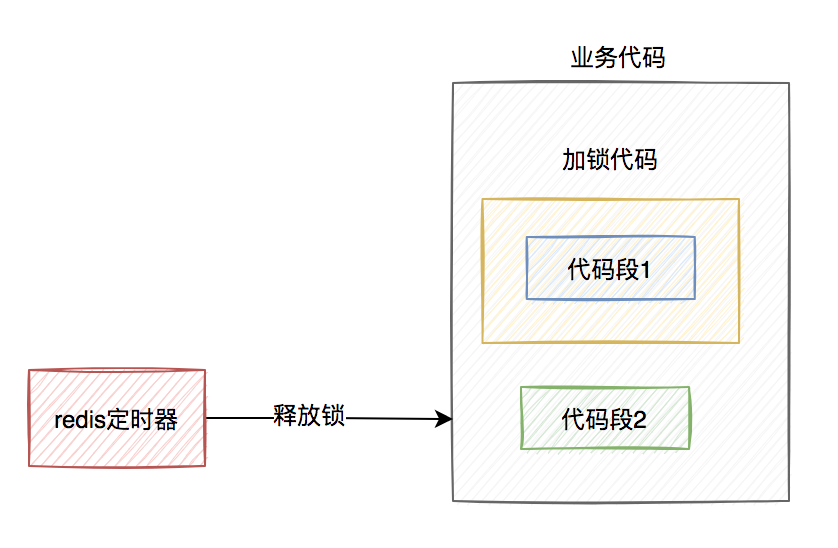
此時,代碼2相當于裸奔的狀態,無法保證互斥性。假如它里面訪問了臨界資源,并且其他線程也訪問了該資源,可能就會出現數據異常的情況。(PS:我說的訪問臨界資源,不單單指讀取,還包含寫入)
那么,如何解決這個問題呢?
答:如果達到了超時時間,但業務代碼還沒執行完,需要給鎖自動續期。
我們可以使用TimerTask類,來實現自動續期的功能:
```
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//自動續期邏輯
}
}, 10000, TimeUnit.MILLISECONDS);
```
獲取鎖之后,自動開啟一個定時任務,每隔10秒鐘,自動刷新一次過期時間。這種機制在redisson框架中,有個比較霸氣的名字:`watch dog`,即傳說中的`看門狗`。
當然自動續期功能,我們還是優先推薦使用lua腳本實現,比如:
```
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end;
return 0;
```
需要注意的地方是:在實現自動續期功能時,還需要設置一個總的過期時間,可以跟redisson保持一致,設置成30秒。如果業務代碼到了這個總的過期時間,還沒有執行完,就不再自動續期了。
如果負責儲存這個分布式鎖的 Redisson 節點宕機以后,而且這個鎖正好處于鎖住的狀態時,這個鎖會出現鎖死的狀態。為了避免這種情況的發生,Redisson內部提供了一個監控鎖的看門狗,它的作用是在Redisson實例被關閉前,不斷的延長鎖的有效期。
默認情況下,看門狗的檢查鎖的超時時間是30秒鐘,也可以通過修改Config.lockWatchdogTimeout來另行指定。
**如果我們未制定 lock 的超時時間,就使用 30 秒作為看門狗的默認時間。只要占鎖成功,就會啟動一個定時任務:每隔 10 秒重新給鎖設置過期的時間,過期時間為 30 秒。**
如下圖所示:
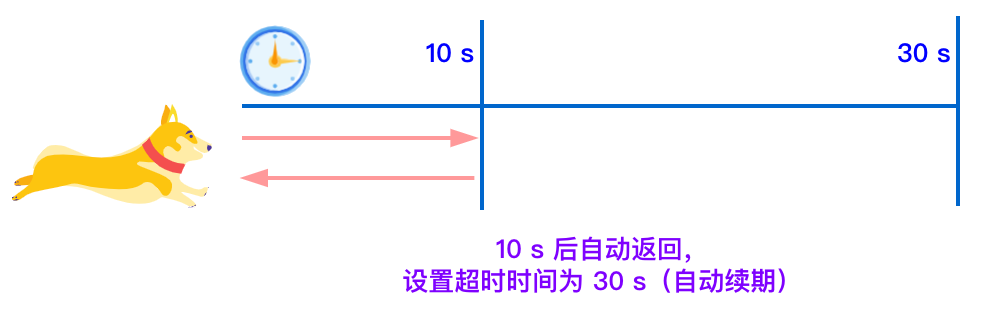
當服務器宕機后,因為鎖的有效期是 30 秒,所以會在 30 秒內自動解鎖。(30秒等于宕機之前的鎖占用時間+后續鎖占用的時間)。
如下圖所示:

### 設置鎖過期時間
我們也可以通過給鎖設置過期時間,讓其自動解鎖。
如下所示,設置鎖 8 秒后自動過期。
~~~
lock.lock(8, TimeUnit.SECONDS);
~~~
如果業務執行時間超過 8 秒,手動釋放鎖將會報錯,如下圖所示
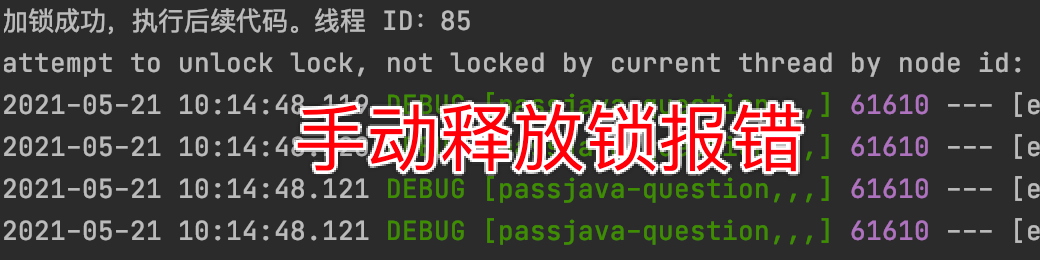
所以我們如果設置了鎖的自動過期時間,則執行業務的時間一定要小于鎖的自動過期時間,否則就會報錯。
8 主從復制的問題
上面花了這么多篇幅介紹的內容,對單個redis實例是沒有問題的。
but,如果redis存在多個實例。比如:做了主從,或者使用了哨兵模式,基于redis的分布式鎖的功能,就會出現問題。
具體是什么問題?
假設redis現在用的主從模式,1個master節點,3個slave節點。master節點負責寫數據,slave節點負責讀數據
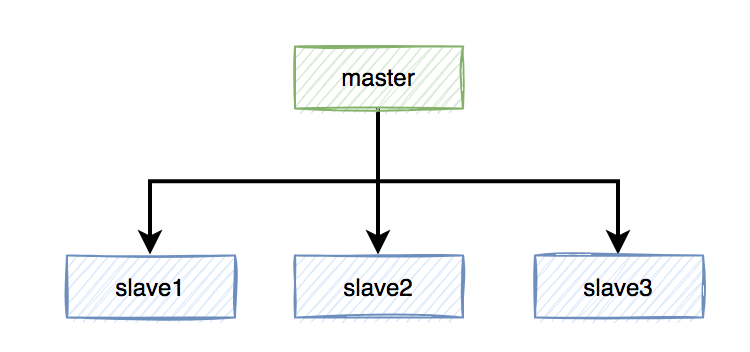
的。redis加鎖操作,都在master上進行,加鎖成功后,再異步同步給所有的slave。
突然有一天,master節點由于某些不可逆的原因,掛掉了。
這樣需要找一個slave升級為新的master節點,假如slave1被選舉出來了。
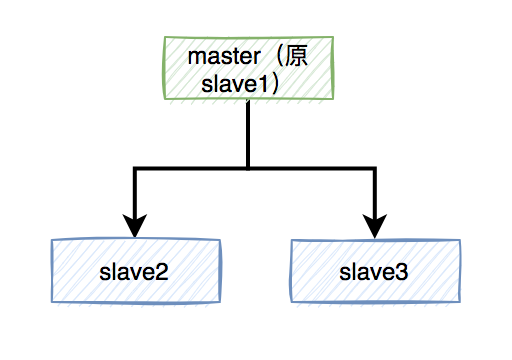
同步到slave1。
這樣會導致新master節點中的鎖A丟失了。后面,如果有新的線程,使用鎖A加鎖,依然可以成功,分布式鎖失效了。
那么,如何解決這個問題呢?
答:redisson框架為了解決這個問題,提供了一個專門的類:RedissonRedLock,使用了Redlock算法。
RedissonRedLock解決問題的思路如下:
需要搭建幾套相互獨立的redis環境,假如我們在這里搭建了5套。
每套環境都有一個redisson node節點。
多個redisson node節點組成了RedissonRedLock。
環境包含:單機、主從、哨兵和集群模式,可以是一種或者多種混合。
在這里我們以主從為例,架構圖如下:
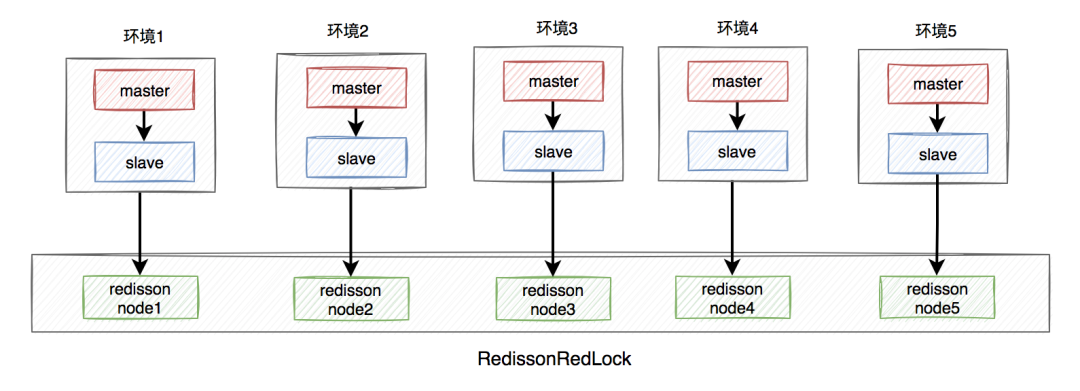
RedissonRedLock加鎖過程如下:
獲取所有的redisson node節點信息,循環向所有的redisson node節點加鎖,假設節點數為N,例子中N等于5。
如果在N個節點當中,有N/2 + 1個節點加鎖成功了,那么整個RedissonRedLock加鎖是成功的。
如果在N個節點當中,小于N/2 + 1個節點加鎖成功,那么整個RedissonRedLock加鎖是失敗的。
如果中途發現各個節點加鎖的總耗時,大于等于設置的最大等待時間,則直接返回失敗。
從上面可以看出,使用Redlock算法,確實能解決多實例場景中,假如master節點掛了,導致分布式鎖失效的問題。
但也引出了一些新問題,比如:
需要額外搭建多套環境,申請更多的資源,需要評估一下成本和性價比。
如果有N個redisson node節點,需要加鎖N次,最少也需要加鎖N/2+1次,才知道redlock加鎖是否成功。顯然,增加了額外的時間成本,有點得不償失。
由此可見,在實際業務場景,尤其是高并發業務中,RedissonRedLock其實使用的并不多。
在分布式環境中,CAP是繞不過去的。
CAP指的是在一個分布式系統中:
一致性(Consistency)
可用性(Availability)
分區容錯性(Partition tolerance)
這三個要素最多只能同時實現兩點,不可能三者兼顧。
如果你的實際業務場景,更需要的是保證數據一致性。那么請使用CP類型的分布式鎖,比如:zookeeper,它是基于磁盤的,性能可能沒那么好,但數據一般不會丟。
如果你的實際業務場景,更需要的是保證數據高可用性。那么請使用AP類型的分布式鎖,比如:redis,它是基于內存的,性能比較好,但有丟失數據的風險。
其實,在我們絕大多數分布式業務場景中,使用redis分布式鎖就夠了,真的別太較真。因為數據不一致問題,可以通過最終一致性方案解決。但如果系統不可用了,對用戶來說是暴擊一萬點傷害。
- springcloud
- springcloud的作用
- springboot服務提供者和消費者
- Eureka
- ribbon
- Feign
- feign在微服務中的使用
- feign充當http請求工具
- Hystrix 熔斷器
- Zuul 路由網關
- Spring Cloud Config 分布式配置中心
- config介紹與配置
- Spring Cloud Config 配置實戰
- Spring Cloud Bus
- gateway
- 概念講解
- 實例
- GateWay
- 統一日志追蹤
- 分布式鎖
- 1.redis
- springcloud Alibaba
- 1. Nacos
- 1.1 安裝
- 1.2 特性
- 1.3 實例
- 1. 整合nacos服務發現
- 2. 整合nacos配置功能
- 1.4 生產部署方案
- 環境隔離
- 原理講解
- 1. 服務發現
- 2. sentinel
- 3. Seata事務
- CAP理論
- 3.1 安裝
- 分布式協議
- 4.熔斷和降級
- springcloud與alibba
- oauth
- 1. abstract
- 2. oauth2 in micro-service
- 微服務框架付費
- SkyWalking
- 介紹與相關資料
- APM系統簡單對比(zipkin,pinpoint和skywalking)
- server安裝部署
- agent安裝
- 日志清理
- 統一日志中心
- docker安裝部署
- 安裝部署
- elasticsearch 7.x
- logstash 7.x
- kibana 7.x
- ES索引管理
- 定時清理數據
- index Lifecycle Management
- 沒數據排查思路
- ELK自身組件監控
- 多租戶方案
- 慢查詢sql
- 日志審計
- 開發
- 登錄認證
- 鏈路追蹤
- elk
- Filebeat
- Filebeat基礎
- Filebeat安裝部署
- 多行消息Multiline
- how Filebeat works
- Logstash
- 安裝
- rpm安裝
- docker安裝Logstash
- grok調試
- Grok語法調試
- Grok常用表達式
- 配置中常見判斷
- filter提取器
- elasticsearch
- 安裝
- rpm安裝
- docker安裝es
- 使用
- 概念
- 基礎
- 中文分詞
- 統計
- 排序
- 倒排與正排索引
- 自定義dynamic
- 練習
- nested object
- 父子關系模型
- 高亮
- 搜索提示
- kibana
- 安裝
- docker安裝
- rpm安裝
- 整合
- 收集日志
- 慢sql
- 日志審計s
- 云
- 分布式架構
- 分布式鎖
- Redis實現
- redisson
- 熔斷和降級