
[TOC]
# filter
## 1. filter作用
> Logstash過濾器根據規則提取數據
## 2. 過濾器種類
* [ ] date過濾器:獲得時間格式的數據
* [ ] extractnumbers過濾器:從字符串中提取數字
* [ ] grok過濾器:使用grok格式提取數據中的指定內容,比如從一長串的日志中,提取出ip地址
### 2.1 date過濾器
> 用于解析事件中的時間數據,日期過濾器用于解析字段中的日期,然后使用該日期或時間戳作為事件的logstash時間戳。
> 默認情況下如果不加date插件的話,在kibana上創建索引模式的時候,選擇的時間戳字段是logstash處理日志的時間,如果日志輸出不是實時的,顯示日志時間與對應的事件是不符合的(即es存儲日志的時間字段是當前時間,不是log實際發生的時間)
~~~dart
match => ["timestamp", "ISO8601", "dd-MMM-yyyy HH:mm:ss.SSS", "yyyy-MM-dd HH:mm:ss"]
默認target指向的就是@timestamp,意思就是如果timestamp匹配上后面自定義的日志格式,就會替換對應的@times
~~~
可配置的參數:
| 參數 | 作用 | 參數類型 |
| --- | ---| --- |
| locale | 指定用于日期解析的區域設置 |string |
| match| 如何匹配時間格式 |array |
| tag_on_failure | 匹配失敗后追加的內容 | array |
| target | 匹配成功后的內容需要設置的目標字段 | string |
| timezone | 指定用于日期解析的時區規范ID |string |
配置
```
input {
redis {
key => "logstash-date"
host => "localhost"
password => "dailearn"
port => 6379
db => "0"
data_type => "list"
type => "date"
}
}
filter {
date {
match => [ "message", "yyyy-MM-dd HH:mm:ss" ]
locale => "Asia/Shanghai"
timezone => "Europe/Paris"
target => "messageDate"
}
}
output {
stdout { codec => rubydebug }
}
```
測試數據
2020-05-07 23:59:59
控制臺輸出
```
{
"@timestamp" => 2020-05-12T13:47:26.094Z,
"type" => "date",
"tags" => [
[0] "_jsonparsefailure"
],
"@version" => "1",
"message" => "2020-05-07 23:59:59",
"messageDate" => 2020-05-07T21:59:59.000Z
}
```
需要注意我是在2020-05-12 21:47:26發送的消息,而服務器使用的時區為UTC/GMT 0。所以這個時候我插入了2020-05-07 23:59:59的時間,被指定為Europe/Paris時區,所以最后被轉為2020-05-07T21:59:59.000Z
### 2.2 extractnumbers過濾器
注意默認情況下次過濾器為捆綁需要執行bin/logstash-plugin install logstash-filter-extractnumbers操作安裝插件
此過濾器自動提取字符串中找到的所有數字
可配置的參數

配置
```
input {
redis {
key => "logstash-extractnumbers"
host => "localhost"
password => "dailearn"
port => 6379
db => "0"
data_type => "list"
type => "extractnumbers"
}
}
filter {
extractnumbers {
source => "message"
target => "message2"
}
}
```
```
output {
stdout { codec => rubydebug }
}
```
測試數據
zhangSan5,age16 + 0.5 456 789
控制臺輸出
{
"float1" => 0.5,
"int2" => 789,
"int1" => 456,
"@timestamp" => 2020-05-17T03:51:23.695Z,
"@version" => "1",
"type" => "extractnumbers",
"message" => "zhangSan5,age16 + 0.5 456 789",
"tags" => [
[0] "_jsonparsefailure"
]
}
雖然文檔中介紹,此過濾器會嘗試提取出字符串中所有的字段,但是實際中部分和字母結合的字符串結構并沒有被提取出來,而那些被字母和其他符號被包裹起來的數字沒有被完整的提取出來,比如之前測試的時候使用的zhangSan5,age16 + 0.5,456[789],888這樣的數據就沒有任何內容被提取出來。
### 2.3 grok過濾器
> Grok 是 Logstash 最重要的插件。它的主要作用就是將文本格式的字符串,轉換成為具體的結構化的數據,配合正則表達式使用。
下面針對Apache日志來分割處理

下面是apache日志

日志中每個字段之間空格隔開,分別對應message中的字段。
如:%{IPORHOST:addre} ?--> 192.168.10.197 ?
但問題是IPORHOST又不是正則表達式,怎么能匹配IP地址呢?
因為IPPRHOST是grok表達式,它代表的正則表達式如下:

IPORHOST代表的是ipv4或者ipv6或者HOSTNAME所匹配的grok表達式。
上面的IPORHOST有點復雜,我們來看看簡單點的,如USER
```
USERNAME \[a-zA-Z0-9.\_-\]+ ? ??
```
#USERNAME是匹配由字母,數字,“.”, "\_", "-"組成的任意字符
USER %{USERNAME}
#USER代表USERNAME的正則表達式
第一行,用普通的正則表達式來定義一個 grok 表達式;
第二行,通過打印賦值格式,用前面定義好的 grok 表達式來定義另一個 grok 表達式。
**grok的語法:**
%{syntax:semantic}
syntax代表的是正則表達式替代字段,semantic是代表這個表達式對應的字段名,你可以自由命名。這個命名盡量能簡單易懂的表達出這個字段代表的意思。
logstash安裝時就帶有已經寫好的正則表達式。路徑如下:
/usr/local/logstash-2.3.4/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns
或者直接訪問https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
上面IPORHOST,USER等都是在里面已經定義好的!當然還有其他的,基本能滿足我們的需求
**日志匹配**
當我們拿到一段日志,按照上面的grok表達式一個個去匹配時,我們如何確定我們匹配的是否正確呢?
http://grokdebug.herokuapp.com/ 這個地址可以滿足我們的測試需求。就拿上面apache的日志測試。
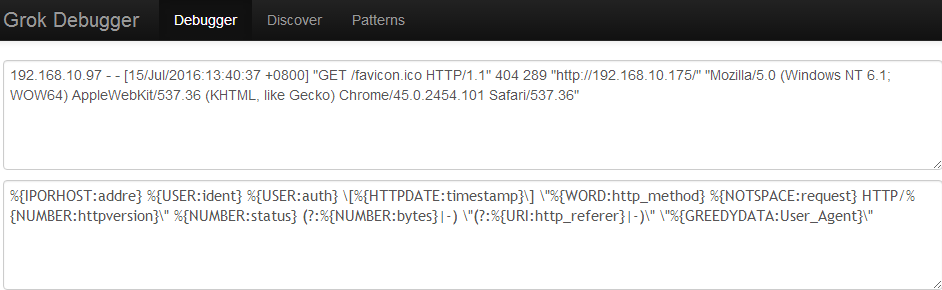
點擊后就出現如下數據,你寫的每個grok表達式都獲取到值了。為了測試準確,可以多測試幾條日志。
~~~
{
??"addre":?[
????[
??????"192.168.10.97"
????]
??],
??"HOSTNAME":?[
????[
??????"192.168.10.97",
??????"192.168.10.175"
????]
...........中間省略多行...........
??"http_referer":?[
????[
??????"http://192.168.10.175/"
????]
??],
??"URIPROTO":?[
????[
??????"http"
????]
??],
??"URIHOST":?[
????[
??????"192.168.10.175"
????]
??],
??"IPORHOST":?[
????[
??????"192.168.10.175"
????]
??],
??"User_Agent":?[
????[
??????"Mozilla/5.0?(Windows?NT?6.1;?WOW64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/45.0.2454.101?Safari/537.36"
????]
??]
}
~~~
每條日志總有些字段是沒有數據顯示,然后以“-”代替的。所有我們在匹配日志的時候也要判斷。
如:(?:%{NUMBER:bytes}|-) ?
但是有些字符串是在太長,如:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
我們可以使用%{GREEDYDATA browser}. ? ? ? ??
對應的grok表達式: GREEDYDATA ?.\* ??
#GREEDYDATA表達式的意思能匹配任意字符串
**自定義grok表達式**
如果你感覺logstash自帶的grok表達式不能滿足需要,你也可以自己定義
如:

patterns\_dir為自定義的grok表達式的路徑。
自定義的patterns中按照logstash自帶的格式書寫。
APACHE\_LOG %{IPORHOST:addre} %{USER:ident} %{USER:auth} \\\[%{HTTPDATE:timestamp}\\\] \\"%{WORD:http\_method} %{NOTSPACE:request} HTTP/%{NUMBER:httpversion}\\" %{NUMBER:status} (?:%{NUMBER:bytes}|-) \\"(?:%{URI:http\_referer}|-)\\" \\"%{GREEDYDATA:User\_Agent}\\"
我只是把apache日志匹配的grok表達式寫入自定義文件中,簡化conf文件。單個字段的正則表達式匹配你可以自己書寫測試。
### 2.3 提取Java日志字段
一般來說,我們從filebeat或者其他地方拿到下面的日志:
~~~text
2018-04-13 16:03:49.822 INFO o.n.p.j.c.XXXXX - Star Calculator
~~~
然后想把它其中的一些信息提取出來再扔到es中存儲,我們就需要grok match把日志信息切分成[索引數據](https://www.zhihu.com/search?q=%E7%B4%A2%E5%BC%95%E6%95%B0%E6%8D%AE&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22article%22%2C%22sourceId%22%3A37128731%7D)(match本質是一個正則匹配)
[grok match](https://www.zhihu.com/search?q=grok+match&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22article%22%2C%22sourceId%22%3A37128731%7D):
~~~json
match => { "message" => "%{DATA:log_date} %{TIME:log_localtime} %{WORD:log_type} %{JAVAFILE:log_file} - %{GREEDYDATA:log_content}"}
~~~
切出來的數據
~~~json
{
"log_date": [
[
"2018-04-13"
]
],
"log_localtime": [
[
"16:03:49.822"
]
],
"HOUR": [
[
"16"
]
],
"MINUTE": [
[
"03"
]
],
"SECOND": [
[
"49.822"
]
],
"log_type": [
[
"INFO"
]
],
"log_file": [
[
"o.n.p.j.c.XXXX"
]
],
"log_content": [
[
"Star Calculator"
]
]
}
~~~
上面所有切出來的field都是es中[mapping index](https://www.zhihu.com/search?q=mapping+index&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22article%22%2C%22sourceId%22%3A37128731%7D),都可以在用來做條件查詢.
[grokdebug.herokuapp.com](https://link.zhihu.com/?target=http%3A//grokdebug.herokuapp.com/)里面可以做測試.
[grokdebug.herokuapp.com/patterns](https://link.zhihu.com/?target=http%3A//grokdebug.herokuapp.com/patterns)所有可用的patterns都可以在這里查到.
現在我們在用的配置見/logstash/logstash-k8s.conf
Q: 需要指定mapping index的數據類型怎么辦?
A: grok match本質是一個正則匹配,默認出來的數據都是String.有些時候我們知道某個值其實是個數據類型,這時候可以直接指定數據類型. 不過match中僅支持直接轉換成int ,float,語法是 %{NUMBER:response\_time:int}
完整配置:
~~~json
match => {
"message" => "%{DATA:log_date} %{TIME:log_localtime} %{WORD:log_type} %{JAVAFILE:log_file} - %{WORD:method} %{URIPATHPARAM:uri} %{NUMBER:status:int} %{NUMBER:size:int} %{NUMBER:response_time:int}"}
~~~
Q:[索引文件](https://www.zhihu.com/search?q=%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22article%22%2C%22sourceId%22%3A37128731%7D)想需要按日期分別存放,怎么辦?
A: out中指定index格式,如 index=> "k8s-%{+YYYY.MM.dd}"
完整out如下:
~~~json
output {
elasticsearch {
hosts => "${ES_URL}"
manage_template => false
index => "k8s-%{+YYYY.MM.dd}"
}
}
~~~
完整[logstash.conf](https://www.zhihu.com/search?q=logstash.conf&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22article%22%2C%22sourceId%22%3A37128731%7D)
~~~text
input {
beats {
host => "0.0.0.0"
port => 5043
}
}
filter {
if [type] == "kube-logs" {
mutate {
rename => ["log", "message"]
}
date {
match => ["time", "ISO8601"]
remove_field => ["time"]
}
grok {
match => {
"source" => "/var/log/containers/%{DATA:pod_name}_%{DATA:namespace}_%{GREEDYDATA:container_name}-%{DATA:container_id}.log"}
match => {
"message" => "%{DATA:log_date} %{TIME:log_localtime} %{WORD:log_type} %{JAVAFILE:log_file} - %{WORD:method} %{URIPATHPARAM:uri} %{NUMBER:status:int} %{NUMBER:size:int} %{NUMBER:response_time:int}"}
remove_field => ["source"]
break_on_match => false
}
}
}
output {
elasticsearch {
hosts => "${ES_URL}"
manage_template => false
index => "k8s-%{+YYYY.MM.dd}"
}
}
~~~
- springcloud
- springcloud的作用
- springboot服務提供者和消費者
- Eureka
- ribbon
- Feign
- feign在微服務中的使用
- feign充當http請求工具
- Hystrix 熔斷器
- Zuul 路由網關
- Spring Cloud Config 分布式配置中心
- config介紹與配置
- Spring Cloud Config 配置實戰
- Spring Cloud Bus
- gateway
- 概念講解
- 實例
- GateWay
- 統一日志追蹤
- 分布式鎖
- 1.redis
- springcloud Alibaba
- 1. Nacos
- 1.1 安裝
- 1.2 特性
- 1.3 實例
- 1. 整合nacos服務發現
- 2. 整合nacos配置功能
- 1.4 生產部署方案
- 環境隔離
- 原理講解
- 1. 服務發現
- 2. sentinel
- 3. Seata事務
- CAP理論
- 3.1 安裝
- 分布式協議
- 4.熔斷和降級
- springcloud與alibba
- oauth
- 1. abstract
- 2. oauth2 in micro-service
- 微服務框架付費
- SkyWalking
- 介紹與相關資料
- APM系統簡單對比(zipkin,pinpoint和skywalking)
- server安裝部署
- agent安裝
- 日志清理
- 統一日志中心
- docker安裝部署
- 安裝部署
- elasticsearch 7.x
- logstash 7.x
- kibana 7.x
- ES索引管理
- 定時清理數據
- index Lifecycle Management
- 沒數據排查思路
- ELK自身組件監控
- 多租戶方案
- 慢查詢sql
- 日志審計
- 開發
- 登錄認證
- 鏈路追蹤
- elk
- Filebeat
- Filebeat基礎
- Filebeat安裝部署
- 多行消息Multiline
- how Filebeat works
- Logstash
- 安裝
- rpm安裝
- docker安裝Logstash
- grok調試
- Grok語法調試
- Grok常用表達式
- 配置中常見判斷
- filter提取器
- elasticsearch
- 安裝
- rpm安裝
- docker安裝es
- 使用
- 概念
- 基礎
- 中文分詞
- 統計
- 排序
- 倒排與正排索引
- 自定義dynamic
- 練習
- nested object
- 父子關系模型
- 高亮
- 搜索提示
- kibana
- 安裝
- docker安裝
- rpm安裝
- 整合
- 收集日志
- 慢sql
- 日志審計s
- 云
- 分布式架構
- 分布式鎖
- Redis實現
- redisson
- 熔斷和降級