
[TOC]
# 數據模型
## 主流模型
### 1. 關系數據庫:
<span style='color:blue;background:#ff0;'>關系數據模型</span>通常使用關系數據庫進行存儲,例如MySQL,Oracle,PostgreSQL等。這些數據庫使用表格來表示數據,并使用SQL語言進行查詢和操作。關系數據庫適用于需要支持事務處理和數據一致性的應用場景。
``````
# 在該模型中,電影庫包含多個電影,每個電影有多個演員和多個評論,同時每個評論和電影之間存在評分的關系。
+---------+ +----------+ +--------+
| Movie | | Actor | | Review |
+---------+ +----------+ +--------+
| id | | id | | id |
| title | | name | | movie_id |
| genre | | age | | reviewer|
| release | | movies |<--------| rating |
| reviews |<----------| | | comment|
+---------+ +----------+ +--------+
# 使用Movie類來表示電影的數據結構,其中包含電影ID、電影名稱、電影類型、上映日期和評論列表等字段。使用Actor類來表示演員的數據結構,其中包含演員ID、演員姓名、演員年齡和參演電影列表等字段。使用Review類來表示評論的數據結構,其中包含評論ID、電影ID、評價人、評分和評論等字段。
``````
*****
### 2. 對象數據庫:
<span style='color:blue;background:#ff0;'>物件模型</span>通常使用對象數據庫進行存儲,例如`db4o,Versant,ObjectDB`等。這些數據庫使用類和對象來表示數據,并支持面向對象的查詢語言。對象數據庫適用于需要高度靈活性和可擴展性的應用場景。
``````
# 汽車銷售系統包含多個車型,每個車型有多個配置,每個配置又包含多個零配件。同時,每個車型和配置都可以被多個訂單所使用。
+--------------+ +----------+
| CarSales | | CarModel 車型 |
+--------------+ +----------+
| name | | name |
| description |-----------| price |
| models | | options |
+--------------+
+-----------+ +---------+
| CarModel | | Option 配置|
+-----------+ +---------+
| name | | name |
| price |------------| price |
| options | | parts |
| orders | +---------+
+-----------+
+---------+ +---------+
| Option | | Part 零件 |
+---------+ +---------+
| name | | name |
| price |------------| price |
| parts | | supplier|
+---------+ +---------+
+---------+ +----------+
| Order | | Customer |
+---------+ +----------+
| orderNo | | name |
| date |-----------| email |
| model | | orders |
+---------+ +----------+
``````
*****
### 3. 圖數據庫:
<span style='color:blue;background:#ff0;'>無向圖數據模型</span>通常使用圖數據庫進行存儲,例如Neo4j,ArangoDB,OrientDB等。這些數據庫使用節點和邊來表示數據,并支持圖形查詢和遍歷。圖數據庫適用于需要處理復雜關系和大量數據的應用場景.
``````
# 在該模型中,社交網絡由多個用戶組成,每個用戶可以與其他用戶建立雙向的關注關系。
+-------+ +-------+
| Graph | | User |
+-------+ +-------+
| nodes | | name |
| edges |<-------| posts |
+-------+ | likes |
+-------+
# 使用Graph類來表示無向圖的數據結構,其中包含節點和邊列表等字段。使用User類來表示社交網絡中的用戶,其中包含用戶姓名、帖子列表和點贊列表等字段。使用箭頭來表示類之間的關系和依賴,
``````
*****
### 4. 多重關系數據模型:
<span style='color:blue;background:#ff0;'>多重關系數據模型</span>通常使用關系數據庫進行存儲,例如MySQL,Oracle,PostgreSQL等。這些數據庫使用表格來表示數據,并使用SQL語言進行查詢和操作。此外,一些圖數據庫也支持多重關系數據模型,例如Neo4j。
``````
# 在該模型中,一個在線商店包含多個商品,每個商品屬于一個類別,有多個客戶可以購買多個商品,每個客戶有多個訂單。同時,每個訂單包含多個商品和一個客戶。
+-------------+ +----------+
| OnlineShop | | Category |
+-------------+ +----------+
| name | | name |
| description |------------| products |
| categories | +----------+
+-------------+
+----------+ +----------+
| Category | | Product |
+----------+ +----------+
| name | | name |
| products |------------| price |
+----------+ | category |
+----------+
+---------+ +----------+
| Customer| | Order |
+---------+ +----------+
| name | | orderNo |
| email | | date |
| orders |------------| customer|
+---------+ | products |
+----------+
``````
*****
### 5. Hierarchical (hier) 數據模型:
<span style='color:blue;background:#ff0;'>Hierarchical數據模型(樹狀)</span>通常使用層次數據庫進行存儲,例如IMS,IDMS等。這些數據庫使用樹形結構來表示數據,其中每個節點都具有一個父節點和零個或多個子節點。此外,一些關系數據庫也支持Hierarchical數據模型,例如Oracle。
``````
# 在該模型中,組織機構由多個部門組成,每個部門包含多個員工。每個員工又擁有自己的屬性,例如姓名、職位、工資等。
+------------------+ +------------+
| Organization | | Department |
+------------------+ +------------+
| name | | name |
| address |-----------| employees |
| phone | +------------+
| departments |
+------------------+
+-------------+ +-----------+
| Department | | Employee |
+-------------+ +-----------+
| name | | name |
| employees |-----------| position |
+-------------+ | salary |
| hireDate |
+-----------+
# 層次模型 Organization組織 -》Department部門 -》 Employee員工
# 使用Organization類來表示組織機構的數據結構,其中包含名稱、地址、電話等字段,以及與部門相關的部門列表。
# 使用Department類來表示部門的數據結構,其中包含名稱和員工列表等字段。
# 使用Employee類來表示員工的數據結構,其中包含姓名、職位、工資、入職日期等字段。
``````
*****
### 6. 文件數據模型(CSV,JSON,XML files , etc.):
<span style='color:blue;background:#ff0;'>文件數據模型</span>通常使用文件系統或NoSQL數據庫進行存儲,例如MongoDB,Couchbase等。這些數據庫可以存儲和管理各種文件格式的數據,例如CSV,JSON和XML文件。此外,一些關系數據庫也支持文件數據模型,例如PostgreSQL。
``````
# 在該模型中,一個電影包含標題、導演、演員、評分等屬性,同時與電影類型和上映時間等信息相關聯。
+-------------+ +-------------+
| Movie | | Type |
+-------------+ +-------------+
| title | | name |
| director |------------| description|
| actors | +-------------+
| rating | | movies |
| type |<-----------| |
| releaseDate | +-------------+
+-------------+
# 使用箭頭來表示Movie類依賴于Type類,并使用Type對象來表示電影類型和電影列表的關系。
``````
*****
## 其它模型
### 1. 網狀數據模型
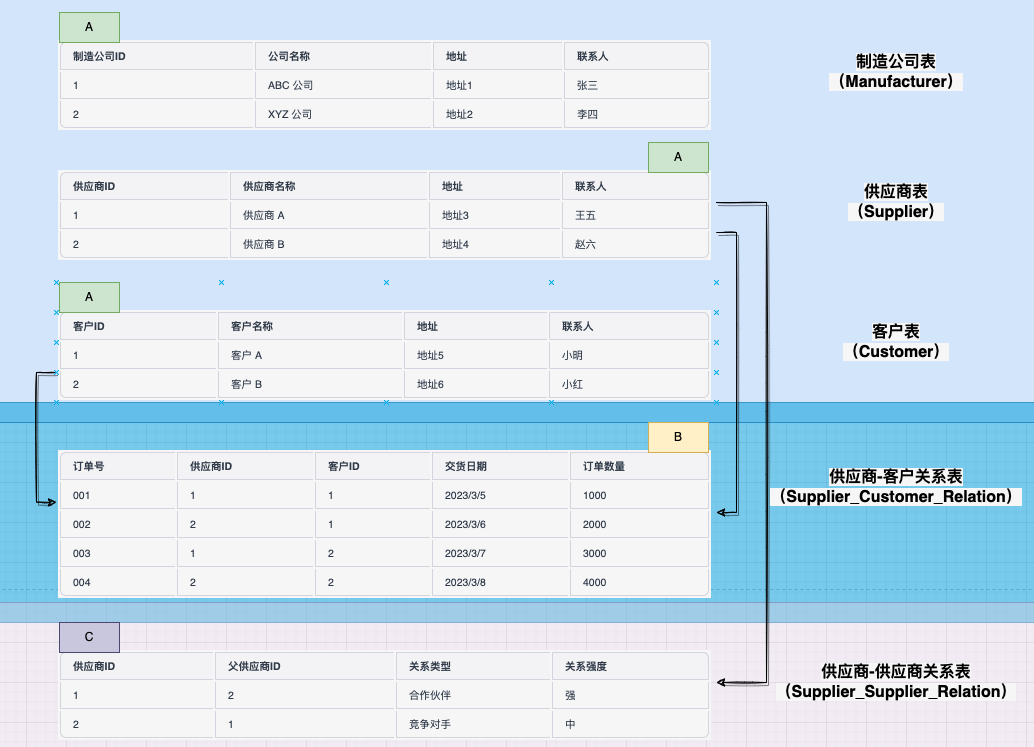
``````
# 在該模型中,電影推薦系統包含多個用戶和多個電影,每個用戶可以看多個電影,每個電影也可以被多個用戶看。同時,每個電影還包含多個演員和多個導演,每個演員和導演也可以參演多個電影。
+--------+ +---------+ +--------+
| User | | Movie | | Person |
+--------+ +---------+ +--------+
| id | | id | | id |
| name | | title | | name |
| gender | | genre |<-----| type |
| age | | actors()|----->| movies()|
| movies |<------->| | +--------+
+--------+ | |
| |
| |
| |
+---------+
# 使用User類來表示用戶的數據結構,其中包含用戶ID、用戶名、用戶性別和用戶年齡等字段。
# 使用Movie類來表示電影的數據結構,其中包含電影ID、電影標題、電影類型和電影演員列表等字段。
# 使用Person類來表示演員和導演的數據結構,其中包含人員ID、人員姓名、人員類型和參演電影列表等字段。
``````
### 2. EVA數據模型——面向對象模型
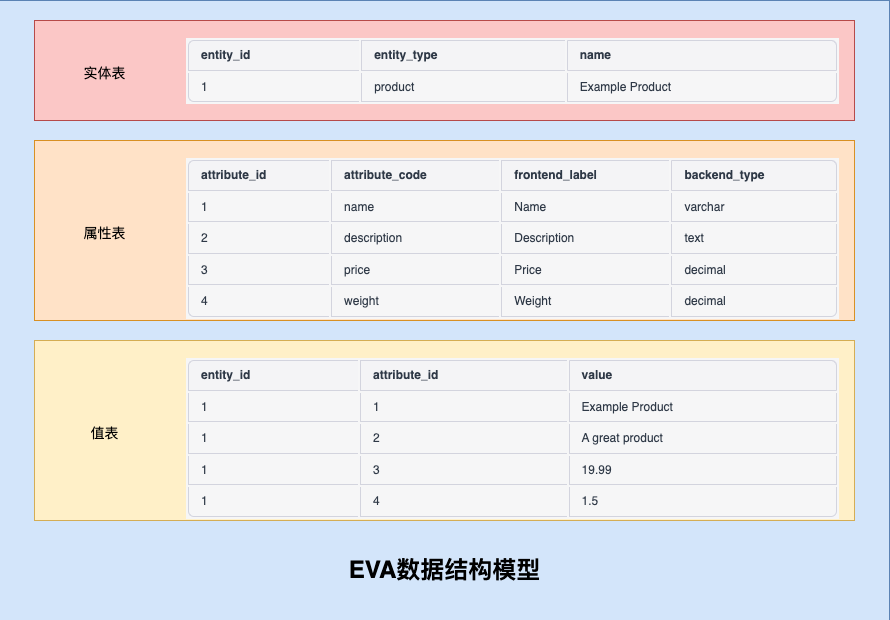
``````
# 在該模型中,電商平臺包含多個產品,每個產品有多個屬性和多個屬性值,同時每個屬性和屬性值之間存在關聯關系。
+---------+ +------------+ +-------------+
| Product | | Attribute | | Value |
+---------+ +------------+ +-------------+
| id | | id | | id |
| name | | name | | value |
| type | | type | | attribute |
| price |<--------->| values() |<-------->| product_id |
| size | | product_id | +-------------+
| color | +------------+
+---------+
# 使用Product類來表示產品的數據結構,其中包含產品ID、產品名稱、產品類型、產品價格和屬性列表等字段。
# 使用Attribute類來表示屬性的數據結構,其中包含屬性ID、屬性名稱、屬性類型和對應的屬性值列表等字段。
# 使用Value類來表示屬性值的數據結構,其中包含屬性值ID、屬性值名稱和對應的屬性ID和產品ID等字段。
``````
### 3. ——面向切面模型
#### 1). 數據攔截器(Data Interceptor)模型:
數據攔截器模型是一種將橫切關注點嵌入到數據訪問層的數據模型。在該模型中,攔截器可以截獲和處理數據層面的操作,
例如查詢、插入、更新和刪除等,從而實現對數據的審計、性能優化和安全控制等功能。Hibernate、Entity Framework是一個使用數據攔截器模型的ORM框架。
``````
# 在該模型中,電商平臺包含多個數據源,例如用戶信息、訂單信息、支付信息等。數據攔截器可以對這些數據源進行攔截和處理,并提供一些數據加工的功能,例如數據過濾、數據轉換、數據聚合等。
+----------------+ +--------------+ +-----------------+
| DataInterceptor| | DataSource | | DataProcessor |
+----------------+ +--------------+ +-----------------+
| intercept() |<>------->| getData() |<--------| process() |
| filter() | | | | transform() |
| transform() | | | | aggregate() |
+----------------+ +--------------+ +-----------------+
# 使用DataInterceptor類來表示數據攔截器的數據結構,其中包含攔截、過濾和轉換等方法。
# 使用DataSource類來表示數據源的數據結構,其中包含獲取數據的方法。
# 使用DataProcessor類來表示數據處理器的數據結構,其中包含處理、轉換和聚合等方法。
``````
>Java:
``````
# 定義一個攔截器類,繼承自Hibernate的Interceptor類。在該類中,可以重寫多個攔截器方法,例如onFlushDirty(),用于在更新操作之前截獲和處理更新請求。
public class AuditInterceptor extends EmptyInterceptor {
@Override
public boolean onFlushDirty(Object entity, Serializable id, Object[] currentState, Object[] previousState, String[] propertyNames, Type[] types) {
if (entity instanceof User) {
// 獲取當前用戶
User currentUser = getCurrentUser();
// 記錄用戶更新操作
AuditLog log = new AuditLog();
log.setUserId(currentUser.getId());
log.setOperation("update");
log.setEntity("User");
log.setEntityId(id.toString());
log.setTimestamp(new Date());
// 保存操作記錄
saveAuditLog(log);
}
return super.onFlushDirty(entity, id, currentState, previousState, propertyNames, types);
}
// 獲取當前用戶
private User getCurrentUser() {
// TODO: 從當前會話中獲取當前用戶
return null;
}
// 保存操作記錄
private void saveAuditLog(AuditLog log) {
// TODO: 將操作記錄保存到數據庫中
}
}
# 然后,在使用Hibernate進行數據庫操作時,需要將攔截器類傳遞給SessionFactory對象,以便Hibernate在進行數據更新操作時調用攔截器方法。
Configuration configuration = new Configuration();
configuration.setInterceptor(new AuditInterceptor());
SessionFactory sessionFactory = configuration.buildSessionFactory();
Session session = sessionFactory.openSession();
// 更新用戶信息
User user = session.get(User.class, 1L);
user.setName("New Name");
session.update(user);
session.close();
``````
#### 2). 數據管道(Data Pipeline)模型:
數據管道模型是一種將橫切關注點嵌入到數據流程中的數據模型。在該模型中,數據管道可以對數據進行預處理、轉換、驗證和過濾等操作,從而實現對數據的清洗和轉換等功能。Apache Beam是一個使用數據管道模型的分布式數據處理框架。
``````
# 在該模型中,數據處理系統包含多個數據處理單元,每個數據處理單元可以處理數據并將其傳遞給下一個數據處理單元。數據管道模型可以按照一定的順序和規則,對數據進行處理、轉換、聚合等操作,并輸出最終的結果。
+----------+ +----------+ +----------+
| DataSource| | Processor| | Sink |
+----------+ +----------+ +----------+
| getData()|-------->| process()|------->| write() |
+----------+ | | +----------+
+----------+
# 在以上示例中,使用DataSource類來表示數據源的數據結構,其中包含獲取數據的方法。使用Processor類來表示數據處理單元的數據結構,其中包含處理、轉換和聚合等方法。使用Sink類來表示數據輸出單元的數據結構,其中包含將數據寫入輸出目標的方法。
``````
>Java:
``````
# 1. 首先,需要定義一個管道類,使用Apache Flink提供的StreamExecutionEnvironment類來創建數據管道,并定義一系列數據處理步驟。在該類中,可以使用Flink提供的多個轉換函數和操作函數,例如map(),用于對數據進行轉換和操作。
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class UserBehaviorPipeline {
private final String inputTopic;
private final String outputTopic;
public UserBehaviorPipeline(String inputTopic, String outputTopic) {
this.inputTopic = inputTopic;
this.outputTopic = outputTopic;
}
public void run() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 從Kafka主題中讀取用戶行為數據
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(inputTopic, new SimpleStringSchema(), properties);
DataStream<String> userBehavior = env.addSource(consumer);
// 轉換用戶行為數據
DataStream<UserEvent> userEvents = userBehavior
.map(new ExtractFields())
.filter(new FilterEvents())
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<UserEvent>() {
@Override
public long extractAscendingTimestamp(UserEvent element) {
return element.getTimestamp();
}
});
// 實時處理用戶行為數據
DataStream<Recommendation> recommendations = userEvents
.keyBy(UserEvent::getUserId)
.timeWindow(Time.minutes(10))
.process(new RecommendationProcessFunction());
// 將推薦結果寫入到Kafka主題中
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(outputTopic, new SimpleStringSchema(), properties);
recommendations.map(Recommendation::toJsonString).addSink(producer);
env.execute("UserBehaviorPipeline");
}
}
# 2. 然后,可以定義自定義的數據轉換函數和操作函數,例如ExtractFields()和FilterEvents()函數。這些函數可以根據具體的業務需求進行自定義實現。
public class ExtractFields implements MapFunction<String, UserEvent> {
@Override
public UserEvent map(String value) throws Exception {
// 解析JSON格式的用戶行為數據
JsonObject data = JsonParser.parseString(value).getAsJsonObject();
// 提取用戶行為數據中的關鍵字段
long userId = data.get("user_id").getAsLong();
String eventType = data.get("event_type").getAsString();
long timestamp = data.get("timestamp").getAsLong();
return new UserEvent(userId, eventType, timestamp);
}
}
public class FilterEvents implements FilterFunction<UserEvent> {
@Override
public boolean filter(UserEvent value) throws Exception {
// 過濾掉無用的事件
return value.getEventType().equals("click") || value.getEventType().equals("add_to_cart") || value.getEventType().equals("purchase");
}
}
# 3. 最后,在啟動管道時,需要傳遞輸入和輸出主題的名稱,并調用run()方法啟動數據管道的執行。
String inputTopic = "[INPUT_TOPIC_NAME]";
String outputTopic = "[OUTPUT_TOPIC_NAME]";
UserBehaviorPipeline pipeline= new UserBehaviorPipeline(inputTopic, outputTopic);
pipeline.run();
``````
#### 3). 數據代理(Data Proxy)模型:
數據代理模型是一種將橫切關注點嵌入到數據訪問代理中的數據模型。在該模型中,數據代理可以截獲和處理數據的訪問請求,例如讀取和寫入操作,從而實現對數據的緩存、路由和安全控制等功能。MyBatis是一個使用數據代理模型的ORM框架。
``````
# 在該模型中,數據管理系統包含多個數據源和多個客戶端,數據代理可以作為中介,協調數據源和客戶端之間的數據訪問和交互。數據代理可以提供一些數據管理的功能,例如數據緩存、數據驗證、數據加密等。
+----------------+ +--------------+ +-----------------+
| DataProxy | | DataSource | | Client |
+----------------+ +--------------+ +-----------------+
| cache() |<>------->| getData() |<--------| request() |
| validate() | | | | handleResponse()|
| encrypt() | | | | |
+----------------+ +--------------+ +-----------------+
# 使用DataProxy類來表示數據代理的數據結構,其中包含緩存、驗證和加密等方法。使用DataSource類來表示數據源的數據結構,其中包含獲取數據的方法。使用Client類來表示客戶端的數據結構,其中包含請求數據和處理響應的方法。
``````
>Java:
``````
# 首先,需要定義一個代理類,使用Spring Boot提供的RestController注解來創建Web服務器,并定義一系列路由和數據處理函數。在該類中,可以使用多個Java庫和工具,例如Retrofit、OkHttp、Gson等,來進行數據處理和控制操作。
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class DeviceDataProxy {
private final String deviceServiceUrl;
public DeviceDataProxy(String deviceServiceUrl) {
this.deviceServiceUrl = deviceServiceUrl;
}
@PostMapping("/device_data")
public String handleDeviceData(@RequestBody String deviceData) throws IOException {
// 向設備服務發送數據請求
OkHttpClient client = new OkHttpClient();
RequestBody body = RequestBody.create(MediaType.parse("application/json"), deviceData);
Request request = new Request.Builder()
.url(deviceServiceUrl)
.post(body)
.build();
Response response = client.newCall(request).execute();
// 返回設備服務的響應結果
return response.body().string();
}
}
# 最后,在啟動數據代理時,需要傳遞代理的地址和端口,并調用run()方法啟動Web服務器的執行。
String deviceServiceUrl = "[DEVICE_SERVICE_URL]";
int port = [PORT];
DeviceDataProxy deviceDataProxy = new DeviceDataProxy(deviceServiceUrl);
SpringApplication app = new SpringApplication(DeviceDataProxy.class);
app.setDefaultProperties(Collections.singletonMap("server.port", port));
app.run();
``````
- 系統設計
- 需求分析
- 概要設計
- 詳細設計
- 邏輯模型設計
- 物理模型設計
- 產品設計
- 數據驅動產品設計
- 首頁
- 邏輯理解
- 微服務架構的關系數據庫優化
- Java基礎架構
- 編程范式
- 面向對象編程【模擬現實】
- 泛型編程【參數化】
- 函數式編程
- 響應式編程【異步流】
- 并發編程【多線程】
- 面向切面編程【代碼復用解耦】
- 聲明式編程【注解和配置】
- 函數響應式編程
- 語法基礎
- 包、接口、類、對象和切面案例代碼
- Springboot按以下步驟面向切面設計程序
- 關鍵詞
- 內部類、匿名類
- 數組、字符串、I/O
- 常用API
- 并發包
- XML
- Maven 包管理
- Pom.xml
- 技術框架
- SpringBoot
- 項目文件目錄
- Vue
- Vue項目文件目錄
- 遠程組件
- 敏捷開發前端應用
- Pinia Store
- Vite
- Composition API
- uniapp
- 本地方法JNI
- 腳本機制
- 編譯器API
- 注釋
- 源碼級注釋
- Javadoc
- 安全
- Swing和圖形化編程
- 國際化
- 精實或精益
- 精實軟件數據庫設計
- 精實的原理與方法
- 項目
- 零售軟件
- 擴展
- 1001_docker 示例
- 1002_Docker 常用命令
- 1003_微服務
- 1004_微服務數據模型范式
- 1005_數據模型
- 1006_springCloud
- AI 流程圖生成
- Wordpress_6
- Woocommerce_7
- WooCommerce常用的API和幫助函數
- WooCommerce的鉤子和過濾器
- REST API
- 數據庫API
- 模板系統
- 數據模型
- 1.Woo主題開發流程
- Filter
- Hook
- 可視編輯區域的函數工具
- 渲染字段函數
- 類庫和框架
- TDD 通過測試來驅動開發
- 編程范式對WordPress開發
- WordPress和WooCommerce的核心代碼類庫組成
- 數據庫修改
- 1.WP主題開發流程與時間規劃
- moho
- Note 1
- 基礎命令