
## 惰性集合操作:[序列](http://www.kotlincn.net/docs/reference/sequences.html#%E5%BA%8F%E5%88%97)
### 通過序列提高效率
在前面一節中,你看到了許多鏈式集合函數調用的例子,比如map 和filter 。這些函數會及早地創建中間集合,也就是說每一步的中間結果都被存儲在一個臨時列表。序列給了你執行這些操作的另一種選擇,可以避免創建這些臨時中間對象。
```
people.map(Person:: name).filter{ it.startsWith("A")}
```
Kotlin 標準庫參考文檔有說明, filter和map 都會返回一個列表。這意味著上面例子中的**鏈式調用會創建兩個列表: 一個保存filter 函數的結果,另一個保存map 函數的結果。如果源列表只有兩個元素,這不是什么問題,但是如果有一百萬個元素,(鏈式)調用就會變得十分低效**。
為了提高效率, 可以把操作變成使用序列,而不是直接使用集合:

應用這次操作后的結果和前面的例子一模一樣: 一個以字母A 開頭的人名列表。但是第二個例子**沒有創建任何用于存儲元素的中間集合,所以元素數量巨大的情況下性能將顯著提升**。
Kotlin惰性集合操作的入口就是Sequence接口。這個接口表示的就是一個可以逐個列舉元素的元素序列。Sequence只提供了一個方法,iterator ,用來從序列中獲取值。
Sequence 接口的強大之處在于其操作的實現方式。**序列中的元素求值是惰性的。因此,可以使用序列更高效地對集合元素執行鏈式操作,而不需要創建額外的集合來保存過程中產生的中間結果**。
**可以調用擴展函數asSequence 把任意集合轉換成序列,調用toList 來做反向的轉換**。
**為什么需要把序列轉換回集合?用序列代替集合不是更方便嗎**?特別是它們還有這么多優點。答案是:**有時候如果你只需要迭代序列中的元素,可以直接使用序列。如果你要用其他的API方法,比如用下標訪問元素,那么你需要把序列轉換成列表**。
>[info]注意:通常, 需要對一個大型集合執行鏈式操作時要使用序列。以后討論Kotlin 常規集合的及早操作高效的原因,盡管它會創建中間集合。但是如果集合擁有數量巨大的元素元,素為中間結果進行重新分配開銷巨大,所以惰性求值是更好的選擇
因為序列的操作是惰性的,為了執行它們,你需要直接送代序列元素,或者把序列轉換成一個集合。
在Kotlin中,序列中元素的求值是惰性的,這就意味著在利用序列進行鏈式求值的時候,不需要像操作普通集合那樣,每進行一次求值操作,就產生一個新的集合保存中間數據。那么惰性又是什么意思呢?先來看看它的定義:
**在編程語言理論中,惰性求值(Lazy Evaluation)表示一種在需要時才進行求值的計算方式。在使用惰性求值的時候,表達式不在它被綁定到變量之后就立即求值,而是在該值被取用時才去求值。通過這種方式,不僅能得到性能上的提升,還有一個最重要的好處就是它可以構造出一個無限的數據類型**。
通過上面的定義我們可以簡單歸納出**惰性求值的兩個好處,一個是優化性能,另一個就是能夠構造出無限的數據類型**。這里只需要先知道這個概念,在后面我們會詳細介紹。
### 執行序列操作:中間和末端操作
序列操作分為兩類:中間的和末端的。一次中間操作返回的是另一個序列,這個新序列知道如何變換原始序列中的元素。而一次末端操作返回的是一個結果,這個結果可能是集合、元素、數字,或者其他從初始集合的變換序列中獲取的任意對象。
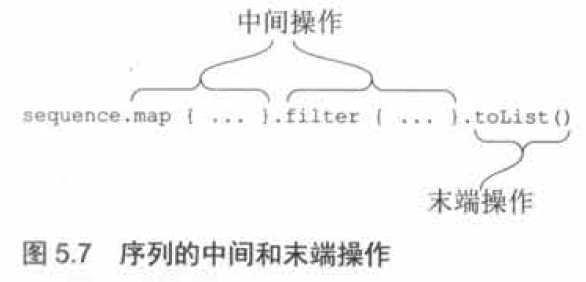
中間操作始終都是惰性的。先看看下面這個缺少了末端操作的例子:
```
fun main(args: Array<String>) {
listOf(1, 2, 3, 4).asSequence()
.map { print("map($it) "); it * it }
.filter { print("filter($it) "); it % 2 == 0 }
}
```
執行這段代碼并不會在控制臺上輸出任何內容。這意味著map 和filter 變換被延期了,它們只有在獲取結果的時候才會被應用( 即末端操作被調用的時候),即惰性求值僅僅在該值被需要的時候才會真正去求值。那么這個“被需要”的狀態該怎么去觸發呢?這就需要另外一個操作了——末端操作。:
#### 末端操作
在對集合進行操作的時候,大部分情況下,我們在意的只是結果,而不是中間過程。末端操作就是一個返回結果的操作,它的返回值不能是序列,必須是一個明確的結果,比如列表、數字、對象等表意明確的結果。末端操作一般都放在鏈式操作的末尾,在執行末端操作的時候,會去觸發中間操作的延遲計算,也就是將“被需要”這個狀態打開了。我們給前面的那個例子加上末端操作:
~~~
fun main(args: Array<String>) {
val list = listOf(1, 2, 3, 4, 5)
list.asSequence().filter {
println("filter($it)")
it > 2
}.map {
println("map($it)")
it * 2
}.toList()
}
~~~
結果
```
filter(1)
filter(2)
filter(3)
map(3)
filter(4)
map(4)
filter(5)
map(5)
```
可以看到,所有的中間操作都被執行了。仔細看看上面的結果,我們可以發現一些有趣的地方。作為對比,我們先來看看上面的操作如果不用序列而用列表來實現會有什么不同之處:
~~~
fun main(args: Array<String>) {
val list = listOf(1, 2, 3, 4, 5)
list.filter {
println("filter($it)")
it > 2
}.map {
println("map($it)")
it * 2
}
}
~~~
輸出結果
```
filter(1)
filter(2)
filter(3)
filter(4)
filter(5)
map(3)
map(4)
map(5)
```
通過對比上面的結果,我們可以發現,普通集合在進行鏈式操作的時候會先在list上調用filter,然后產生一個結果列表,接下來map就在這個結果列表上進行操作。而**序列則不一樣,序列在執行鏈式操作的時候,會將所有的操作都應用在一個元素上,也就是說,第1個元素執行完所有的操作之后,第2個元素再去執行所有的操作,以此類推**。反映到我們這個例子上面,就是第1個元素執行了filter之后再去執行map,然后第2個元素也是這樣。
通過上面序列的返回結果我們還能發現,由于列表中的元素1、2沒有滿足filter操作中大于2的條件,所以接下來的map操作就不會去執行了。所以**當我們使用序列的時候,如果filter和map的位置是可以相互調換的話,應該優先使用filter,這樣會減少一部分開銷**。
下面我們看另一個示例
```
fun main(args: Array<String>) {
listOf(1, 2, 3, 4).asSequence()
.map { print("map($it) "); it * it }
.filter { print("filter($it) "); it % 2 == 0 }
.toList()
}
```
輸出結果
```
map(1) filter(1) map(2) filter(4) map(3) filter(9) map(4) filter(16)
```
末端操作觸發執行了所有的延期計算。
這個例子中另外一件值得注意的重要事情是計算執行的順序。一個笨辦法是先在每個元素上調用map 函數,然后在結果序列的每個元素上再調用filter 函數。map 和filter 對集合就是這樣做的,而序列不一樣。對序列來說,所有操作是按
順序應用在每一個元素上:處理完第一個元素(先映射再過濾),然后完成第二個元素的處理,以此類推。
這種方法意味著部分元素根本不會發生任何變換,如果在輪到它們之前就己經取得了結果。我們來看一個map 和find 的例子。首先把一個數字映射成它的平方,然后找到第一個比數字3 大的條目:
```
println(listOf(1, 2, 3, 4).asSequence().map { it * it }.filter {it >3})//4
```
如果同樣的操作被應用在集合而不是序列上時,那么map 的結果首先被求出來,即變換初始集合中的所有元素。第二步,中間集合中滿足判斷式的一個元素會被找出來。而對于序列來說,惰性方法意味著你可以跳過處理部分元素。下圖闡明了這段代碼兩種求值方式之間的區別, 一種是及早求值(使用集合), 一種是惰性求值(使用序列)。
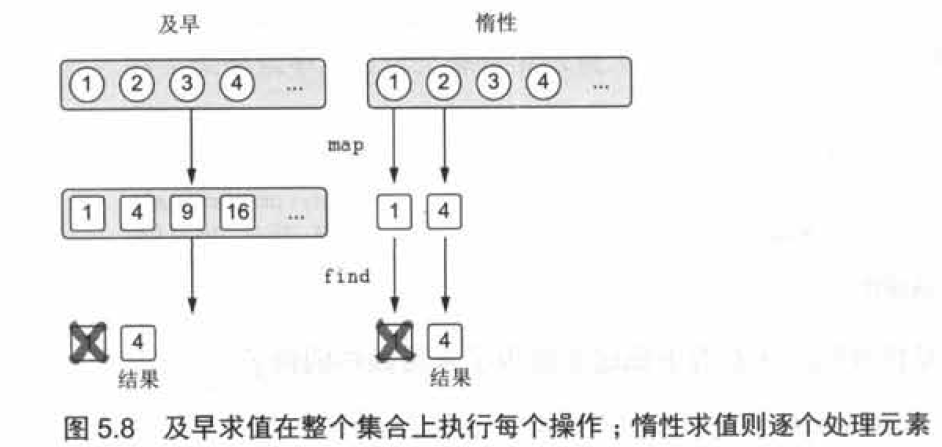
第一種情況,當你使用集合的時候,列表被變換成了另一個列表,所以map 變換應用到每一個元素上,包括了數字3 和4 。然后,第一個滿足判斷式的元素被找到了:數字2 的平方。
第二種情況, find 調用一開始就逐個地處理元素。從原始序列中取一個數字,用map 變換它,然后再檢查它是否滿足傳給find 的判斷式。當進行到數字2 時,發現它的平方己經比數字3 大,就把它作為find 操作結果返回了。不再需要繼續檢查數字3 和4 ,因為這之前你己經找到了結果。
在集合上執行操作的順序也會影響性能。假設你有一個人的集合,想要打印集合中那些長度小于某個限制的人名。你需要做兩件事: 把每個人映射成他們的名字,然后過濾掉其中那些不夠短的名字。這種情況可以用任何順序應用map 和filter操作。兩種順序得到的結果一樣,但它們應該執行的變換總次數是不一樣的,如圖所示。

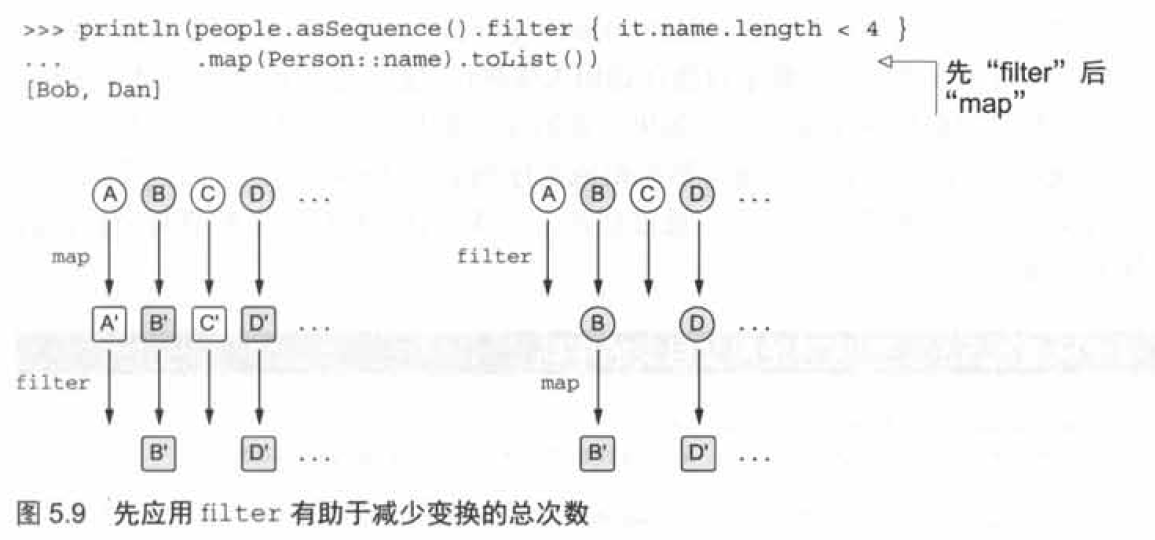
如果map 在前,每個元素都被變換。而如果filter在前,不合適的元素會被盡早地過濾掉且不會發生變換。
### 序列可以是無限的
在介紹惰性求值的時候,我們提到過一點,就是**惰性求值最大的好處是可以構造出一個無限的數據類型**。那么我們能否**使用序列來構造出一個無限的數據類型**呢?答案是肯定的。我們先思考一下,常見的無限的數據類型是什么?我們很容易就能想到數列,比如自然數數列就是一個無限的數列。
那接下來,該怎樣去實現一個自然數數列呢?采用一般的列表肯定是不行的,因為構建一個列表必須列舉出列表中元素,而我們是沒有辦法將自然數全部列舉出來的。
我們知道,自然數是有一定規律的,就是后一個數永遠是前一個數加1的結果,我們**只需要實現一個列表,讓這個列表描述這種規律,那么也就相當于實現了一個無限的自然數數列**。好在Kotlin也給我們提供了這樣一個方法,去**創建無限的數列**:
```
val naturalNumList = generateSequence(0) { it + 1}
```
通過上面這一行代碼,我們就非常簡單地實現了自然數數列。上面我們**調用了一個方法generateSequence來創建序列**。我們知道**序列是惰性求值的,所以上面創建的序列是不會把所有的自然數都列舉出來的,只有在我們調用一個末端操作的時候,才去列舉我們所需要的列表**。比如我們要從這個自然數列表中取出前10個自然數:
```
>>> naturalNumList.takeWhile {it <= 9}.toList()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
```
>[info]注意:關于無限數列這一點,我們不能將一個無限的數據結構通過窮舉的方式呈現出來,而只是實現了一種表示無限的狀態,讓我們在使用時感覺它就是無限的。
### 序列與Java 8 Stream對比
如果你熟悉Java 8的話,當你看到序列的時候,你一定不會陌生。因為序列看上去就和Java 8中的流(Stream)比較類似。這里我們來列舉一些Java 8 Stream中比較常見的特性,并與Kotlin中的序列進行比較
#### 1. Java也能使用函數式風格API
在前面我們介紹了Kotlin中的許多函數式風格API,這些API相比于Java中傳統的集合操作顯得優雅多了。但是當Java 8出來之后,在Java中也能像在Kotlin中那樣操作集合了,比如前面將性別為男的學生篩選出來就可以這樣去做:
```
students.stream().filter (it -> it.sex == "m").collect(toList());
```
在上面的Java代碼中,我們通過使用stream就能夠使用類似于filter這種簡潔的函數式API了。但是相比于Kotlin, Java的這種操作方式還是有些煩瑣,因為如果要對集合使用這種API,就必須先將集合轉換為stream,操作完成之后,還要將stream轉換為List,這種操作有點類似于Kotlin的序列。這是因為Java 8的流和Kotlin中的序列一樣,也是惰性求值的,這就意味著Java 8的流也是存在中間操作和末端操作的(事實也確實如此),所以必須通過上面的一系列轉換才行。
#### 2. Stream是一次性的
與Kotlin的序列不同,Java 8中的流是一次性的。意思就是說,**如果我們創建了一個Stream,我們只能在這個Stream上遍歷一次。這就和迭代器很相似,當你遍歷完成之后,這個流就相當于被消費掉了,你必須再創建一個新的Stream才能再遍歷一次**。
```
Stream<Student> studentsStream = students.stream();
studentsStream.filter (it -> it.sex == "m").collect(toList());
studentsStream.filter (it -> it.sex == "f").collect(toList()); //你不能再繼續在studentsStream上進行這種遍歷操作,否則會報錯
```
#### 3. Stream能夠并行處理數據
Java 8中的流非常強大,其中有一個非常重要的特性就是Java 8 Stream能夠在多核架構上并行地進行流的處理。比如將前面的例子轉換為并行處理的方式如下:
```
students.paralleStream().filter (it -> it.sex == "m").collect(toList());
```
只需要將stream換成paralleStream即可。當然使用流并行處理數據還有許多需要注意的地方,這里只是簡單地介紹一下。并行處理數據這一特性是Kotlin的序列目前還沒有實現的地方,如果我們需要用到處理多線程的集合還需要依賴Java。
>[info]流VS序列
如果你很熟悉Java 8 中的流這個概念,你會發現序列就是它的翻版。Kotlin提供了這個概念自己的版本,原因是Java 8 的流并不支持那些基于Java 老版本的平臺,例如Android。如果你的目標版本是Java 8 ,流提供了一個Kotlin 集合和序列目前還沒有實現的重要特性:在多個CPU 上并行執行流操作(比如map和filter )的能力。可以根據Java 的目標版本和你的特殊要求在流和序列之間做出選擇。
### 創建序列
前面的例子都是使用同一個方法創建序列: 在集合上調用asSequence()。另一種可能性是**使用generateSequence函數。給定序列中的前一個元素,這個函數會計算出下一個元素**。下面這個例子就是如何使用generateSequence計算100 以內所有自然數之和。
```
fun main(args: Array<String>) {
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo100 = naturalNumbers.takeWhile { it <= 100 }
println(numbersTo100.sum())//當獲取結果sum時,所有被推遲的操作都被執行
//5050
}
```
>[info]注意,這個例子中的naturalNumbers 和numbersTo100都是有延期操作的序列。這些序列中的實際數字直到你調用末端操作(這里是sum )的時候才會求值。
另一種常見的用例是父序列。如果元素的父元素和它的類型相同(比如人類或者Java 文件),你可能會對它所有祖先組成的序列的特質感興趣。下面這個例子可以查詢文件是否放在隱藏目錄中,通過創建一個其父目錄的序列并檢查每個目錄的屬性來實現。
```
import java.io.File
fun File.isInsideHiddenDirectory() =
generateSequence(this) { it.parentFile }.any { it.isHidden }
fun main(args: Array<String>) {
val file = File("/Users/svtk/.HiddenDir/a.txt")
println(file.isInsideHiddenDirectory())//true
}
```
又一次,你生成了一個序列,通過提供第一個元素和獲取每個后續元素的方式來實現。如果把any換成find,你還可以得到想要的那個目錄(對象〉。注意,使用序列允許你找到需要的目錄之后立即停止遍歷父目錄。
- 前言
- Kotlin簡介
- IntelliJ IDEA技巧總結
- idea設置類注釋和方法注釋模板
- 像Android Studion一樣創建工程
- Gradle
- Gradle入門
- Gradle進階
- 使用Gradle創建一個Kotlin工程
- 環境搭建
- Androidstudio平臺搭建
- Eclipse的Kotlin環境配置
- 使用IntelliJ IDEA
- Kotlin學習路線
- Kotlin官方中文版文檔教程
- 概述
- kotlin用于服務器端開發
- kotlin用于Android開發
- kotlin用于JavaScript開發
- kotlin用于原生開發
- Kotlin 用于數據科學
- 協程
- 多平臺
- 新特性
- 1.1的新特性
- 1.2的新特性
- 1.3的新特性
- 開始
- 基本語法
- 習慣用法
- 編碼規范
- 基礎
- 基本類型
- 包與導入
- 控制流
- 返回與跳轉
- 類與對象
- 類與繼承
- 屬性與字段
- 接口
- 可見性修飾符
- 擴展
- 數據類
- 密封類
- 泛型
- 嵌套類
- 枚舉類
- 對象
- 類型別名
- 內嵌類
- 委托
- 委托屬性
- 函數與Lambda表達式
- 函數
- Lambda表達式
- 內聯函數
- 集合
- 集合概述
- 構造集合
- 迭代器
- 區間與數列
- 序列
- 操作概述
- 轉換
- 過濾
- 加減操作符
- 分組
- 取集合的一部分
- 取單個元素
- 排序
- 聚合操作
- 集合寫操作
- List相關操作
- Set相關操作
- Map相關操作
- 多平臺程序設計
- 平臺相關聲明
- 以Gradle創建
- 更多語言結構
- 解構聲明
- 類型檢測與轉換
- This表達式
- 相等性
- 操作符重載
- 空安全
- 異常
- 注解
- 反射
- 作用域函數
- 類型安全的構造器
- Opt-in Requirements
- 核心庫
- 標準庫
- kotlin.test
- 參考
- 關鍵字與操作符
- 語法
- 編碼風格約定
- Java互操作
- Kotlin中調用Java
- Java中調用Kotlin
- JavaScript
- 動態類型
- kotlin中調用JavaScript
- JavaScript中調用kotlin
- JavaScript模塊
- JavaScript反射
- JavaScript DCE
- 原生
- 并發
- 不可變性
- kotlin庫
- 平臺庫
- 與C語言互操作
- 與Object-C及Swift互操作
- CocoaPods集成
- Gradle插件
- 調試
- FAQ
- 協程
- 協程指南
- 基礎
- 取消與超時
- 組合掛起函數
- 協程上下文與調度器
- 異步流
- 通道
- 異常處理與監督
- 共享的可變狀態與并發
- Select表達式(實驗性)
- 工具
- 編寫kotlin代碼文檔
- 使用Kapt
- 使用Gradle
- 使用Maven
- 使用Ant
- Kotlin與OSGI
- 編譯器插件
- 編碼規范
- 演進
- kotlin語言演進
- 不同組件的穩定性
- kotlin1.3的兼容性指南
- 常見問題
- FAQ
- 與Java比較
- 與Scala比較(官方已刪除)
- Google開發者官網簡介
- Kotlin and Android
- Get Started with Kotlin on Android
- Kotlin on Android FAQ
- Android KTX
- Resources to Learn Kotlin
- Kotlin樣品
- Kotlin零基礎到進階
- 第一階段興趣入門
- kotlin簡介和學習方法
- 數據類型和類型系統
- 入門
- 分類
- val和var
- 二進制基礎
- 基礎
- 基本語法
- 包
- 示例
- 編碼規范
- 代碼注釋
- 異常
- 根類型“Any”
- Any? 可空類型
- 可空性的實現原理
- kotlin.Unit類型
- kotlin.Nothing類型
- 基本數據類型
- 數值類型
- 布爾類型
- 字符型
- 位運算符
- 變量和常量
- 語法和運算符
- 關鍵字
- 硬關鍵字
- 軟關鍵字
- 修飾符關鍵字
- 特殊標識符
- 操作符和特殊符號
- 算術運算符
- 賦值運算符
- 比較運算符
- 邏輯運算符
- this關鍵字
- super關鍵字
- 操作符重載
- 一元操作符
- 二元操作符
- 字符串
- 字符串介紹和屬性
- 字符串常見方法操作
- 字符串模板
- 數組
- 數組介紹創建及遍歷
- 數組常見方法和屬性
- 數組變化以及下標越界問題
- 原生數組類型
- 區間
- 正向區間
- 逆向區間
- 步長
- 類型檢測與類型轉換
- is、!is、as、as-運算符
- 空安全
- 可空類型變量
- 安全調用符
- 非空斷言
- Elvis操作符
- 可空性深入
- 可空性和Java
- 函數
- 函數式編程概述
- OOP和FOP
- 函數式編程基本特性
- 組合與范疇
- 在Kotlin中使用函數式編程
- 函數入門
- 函數作用域
- 函數加強
- 命名參數
- 默認參數
- 可變參數
- 表達式函數體
- 頂層、嵌套、中綴函數
- 尾遞歸函數優化
- 函數重載
- 控制流
- if表達式
- when表達式
- for循環
- while循環
- 循環中的 Break 與 continue
- return返回
- 標簽處返回
- 集合
- list集合
- list集合介紹和操作
- list常見方法和屬性
- list集合變化和下標越界
- set集合
- set集合介紹和常見操作
- set集合常見方法和屬性
- set集合變換和下標越界
- map集合
- map集合介紹和常見操作
- map集合常見方法和屬性
- map集合變換
- 集合的函數式API
- map函數
- filter函數
- “ all ”“ any ”“ count ”和“ find ”:對集合應用判斷式
- 別樣的求和方式:sumBy、sum、fold、reduce
- 根據人的性別進行分組:groupBy
- 扁平化——處理嵌套集合:flatMap、flatten
- 惰性集合操作:序列
- 區間、數組、集合之間轉換
- 面向對象
- 面向對象-封裝
- 類的創建及屬性方法訪問
- 類屬性和字段
- 構造器
- 嵌套類(內部類)
- 枚舉類
- 枚舉類遍歷&枚舉常量常用屬性
- 數據類
- 密封類
- 印章類(密封類)
- 面向對象-繼承
- 類的繼承
- 面向對象-多態
- 抽象類
- 接口
- 接口和抽象類的區別
- 面向對象-深入
- 擴展
- 擴展:為別的類添加方法、屬性
- Android中的擴展應用
- 優化Snackbar
- 用擴展函數封裝Utils
- 解決煩人的findViewById
- 擴展不是萬能的
- 調度方式對擴展函數的影響
- 被濫用的擴展函數
- 委托
- 委托類
- 委托屬性
- Kotlin5大內置委托
- Kotlin-Object關鍵字
- 單例模式
- 匿名類對象
- 伴生對象
- 作用域函數
- let函數
- run函數
- with函數
- apply函數
- also函數
- 標準庫函數
- takeIf 與 takeUnless
- 第二階段重點深入
- Lambda編程
- Lambda成員引用高階函數
- 高階函數
- 內聯函數
- 泛型
- 泛型的分類
- 泛型約束
- 子類和子類型
- 協變與逆變
- 泛型擦除與實化類型
- 泛型類型參數
- 泛型的背后:類型擦除
- Java為什么無法聲明一個泛型數組
- 向后兼容的罪
- 類型擦除的矛盾
- 使用內聯函數獲取泛型
- 打破泛型不變
- 一個支持協變的List
- 一個支持逆變的Comparator
- 協變和逆變
- 第三階段難點突破
- 注解和反射
- 聲明并應用注解
- DSL
- 協程
- 協程簡介
- 協程的基本操作
- 協程取消
- 管道
- 慕課霍丙乾協程筆記
- Kotlin與Java互操作
- 在Kotlin中調用Java
- 在Java中調用Kotlin
- Kotlin與Java中的操作對比
- 第四階段專題練習
- 朱凱Kotlin知識點總結
- Kotlin 基礎
- Kotlin 的變量、函數和類型
- Kotlin 里那些「不是那么寫的」
- Kotlin 里那些「更方便的」
- Kotlin 進階
- Kotlin 的泛型
- Kotlin 的高階函數、匿名函數和 Lambda 表達式
- Kotlin協程
- 初識
- 進階
- 深入
- Kotlin 擴展
- 會寫「18.dp」只是個入門——Kotlin 的擴展函數和擴展屬性(Extension Functions / Properties)
- Kotlin實戰-開發Android