
上一節課,我們講了衡量代碼效率的方法。相信通過前面的學習,拿到一段代碼,你已經能夠衡量出代碼效率的高低,那么,針對這些低效代碼,你知道如何提高它們的效率嗎?接下來我們來一起看一下數據結構對于時間復雜度和空間復雜度之間轉換的內容,以幫助你掌握提高代碼效率方法。
你面試的過程中,常常會遇到考察手寫代碼的場景,通常面試官會追問:“這段代碼的時間復雜度或者空間復雜度,是否還有降低的可能性?”如果沒有經過專門的學習或訓練,應聘者只能在各種漫無目的的嘗試中去尋找答案。
別忘了,代碼效率優化就是要將可行解提高到更優解,最終目標是:要采用盡可能低的時間復雜度和空間復雜度,去完成一段代碼的開發。
你可能會困惑,優化代碼需要積累非常多的實際經驗,初學者通常很難找到最優的編碼解決方案。其實,代碼效率的提高也是有其核心思路的。掌握了下面所講的核心思路后,對于絕大多數的編碼任務,你都能找到最優或者逼近最優的編碼方式。
#### 時間昂貴、空間廉價
一段代碼會消耗計算時間、資源空間,從而產生時間復雜度和空間復雜度,那么你是否嘗試過將時間復雜度和空間復雜進行下對比呢?其實對比過后,你就會發現一個重要的現象。
**假設一段代碼經過優化后,雖然降低了時間復雜度,但依然需要消耗非常高的空間復雜度**。 例如,對于固定數據量的輸入,這段代碼需要消耗幾十 G 的內存空間,很顯然普通計算機根本無法完成這樣的計算。如果一定要解決的話,一個最簡單粗暴的辦法就是,購買大量的高性能計算機,來彌補空間性能的不足。
**反過來,假設一段代碼經過優化后,依然需要消耗非常高的時間復雜度**。 例如,對于固定數據量的輸入,這段代碼需要消耗 1 年的時間去完成計算。如果在跑程序的 1 年時間內,出現了斷電、斷網或者程序拋出異常等預期范圍之外的問題,那很可能造成 1 年時間浪費的慘重后果。很顯然,用 1 年的時間去跑一段代碼,對開發者和運維者而言都是極不友好的。
這告訴我們一個什么樣的現實問題呢?代碼效率的瓶頸可能發生在時間或者空間兩個方面。如果是缺少計算空間,花錢買服務器就可以了。這是個花錢就能解決的問題。相反,如果是缺少計算時間,只能投入寶貴的人生去跑程序。即使你有再多的錢、再多的服務器,也是毫無用處。相比于空間復雜度,時間復雜度的降低就顯得更加重要了。因此,你會發現這樣的結論:空間是廉價的,而時間是昂貴的。
#### 數據結構連接時空
假定在不限制時間、也不限制空間的情況下,你可以完成某個任務的代碼的開發。這就是通常我們所說的暴力解法,更是程序優化的起點。
例如,如果要在 100 以內的正整數中,找到同時滿足以下兩個條件的最小數字:
* 能被 3 整除;
* 除 5 余 2。
最暴力的解法就是,從 1 開始到 100,每個數字都做一次判斷。如果這個數字滿足了上述兩個條件,則返回結果。這是一種不計較任何時間復雜度或空間復雜度的、最直觀的暴力解法。
當你有了最暴力的解法后,就需要用上一講的方法評估當前暴力解法的復雜度了。如果復雜度比較低或者可以接受,那自然萬事大吉。可如果暴力解法復雜度比較高的話,那就要考慮采用程序優化的方法去降低復雜度了。
為了降低復雜度,一個直觀的思路是:梳理程序,看其流程中是否有無效的計算或者無效的存儲。
我們需要從時間復雜度和空間復雜度兩個維度來考慮。常用的降低時間復雜度的方法有遞歸、二分法、排序算法、動態規劃等,這些知識我們都會在后續課程中逐一學習,這里我先不講。而降低空間復雜度的方法,就要圍繞數據結構做文章了。
**降低空間復雜度的核心思路就是,能用低復雜度的數據結構能解決問題,就千萬不要用高復雜度的數據結構**。
經過了前面剔除無效計算和存儲的處理之后,如果程序在時間和空間等方面的性能依然還有瓶頸,又該怎么辦呢?前面我們提到過,空間是廉價的,最不濟也是可以通過購買更高性能的計算機進行解決的。然而時間是昂貴的,如果無法降低時間復雜度,那系統的效率就永遠無法得到提高。
這時候,開發者們想到這樣的一個解決思路。如果可以通過某種方式,把時間復雜度轉移到空間復雜度的話,就可以把無價的東西變成有價了。這種時空轉移的思想,在實際生活中也會經常遇到。
例如,馬路上的十字路口,所有車輛在通過紅綠燈時需要分批次通行。這樣,就消耗了所有車輛的通行時間。如果要降低這里的時間損耗,人們就想到了修建立交橋。修建立交橋后,每個可能的轉彎或直行的行進路線,都有專屬的一條公路支持。這樣,車輛就不需要全部去等待紅綠燈分批通行了。最終,實現了用空間換取時間。
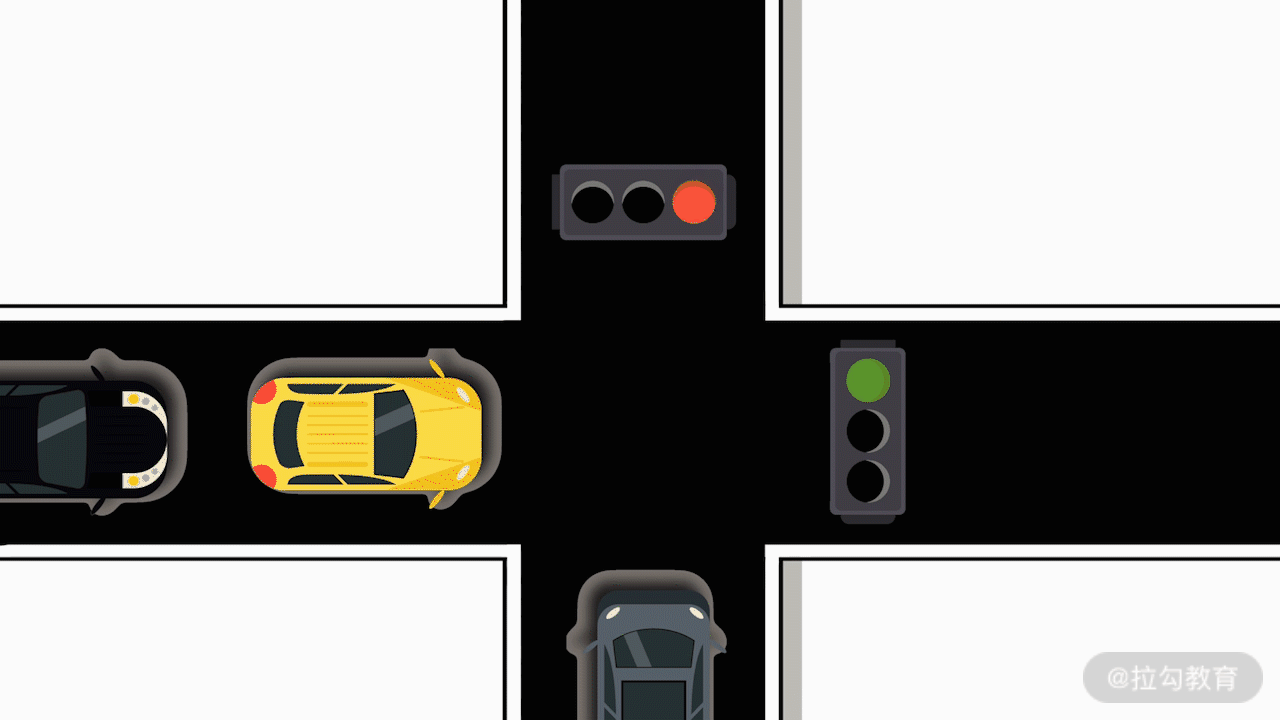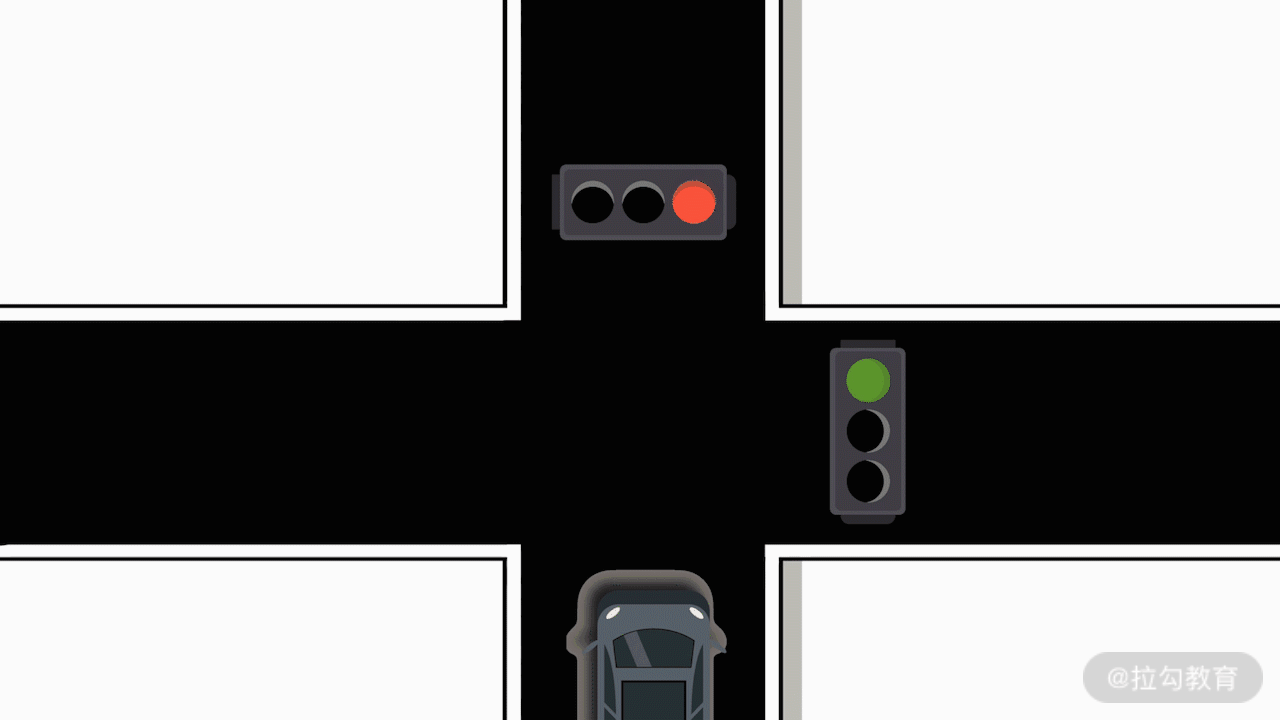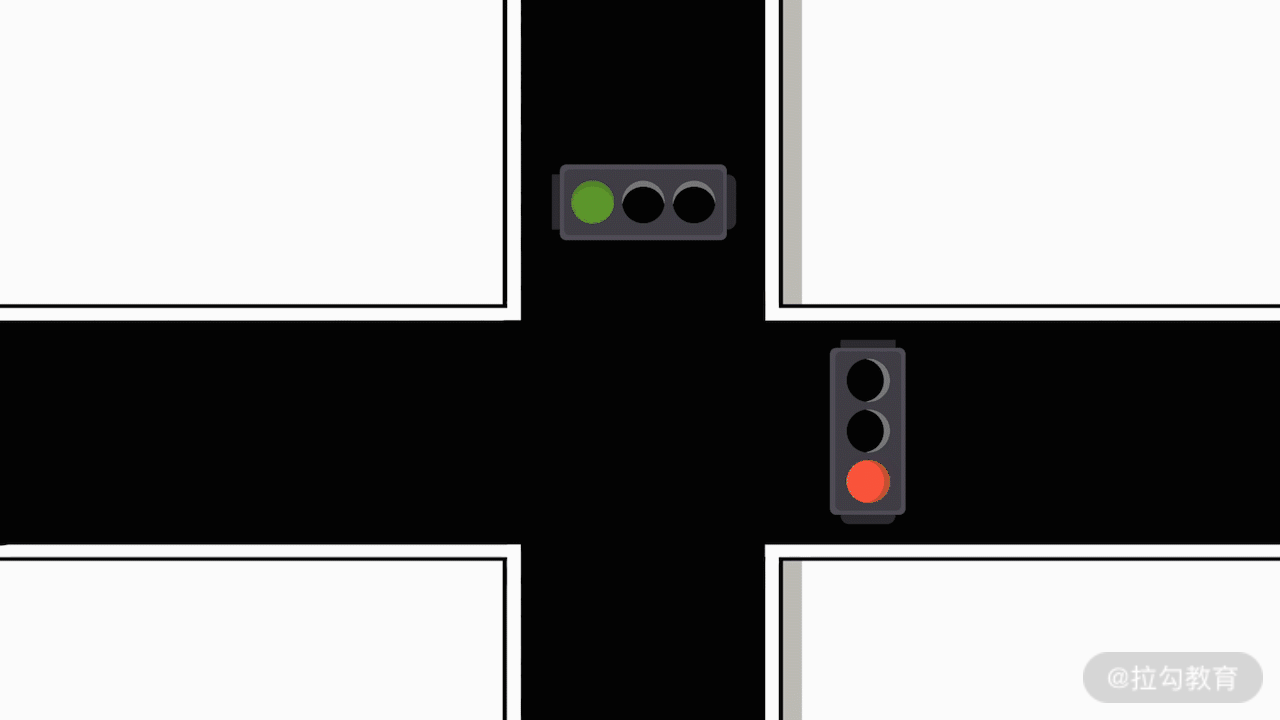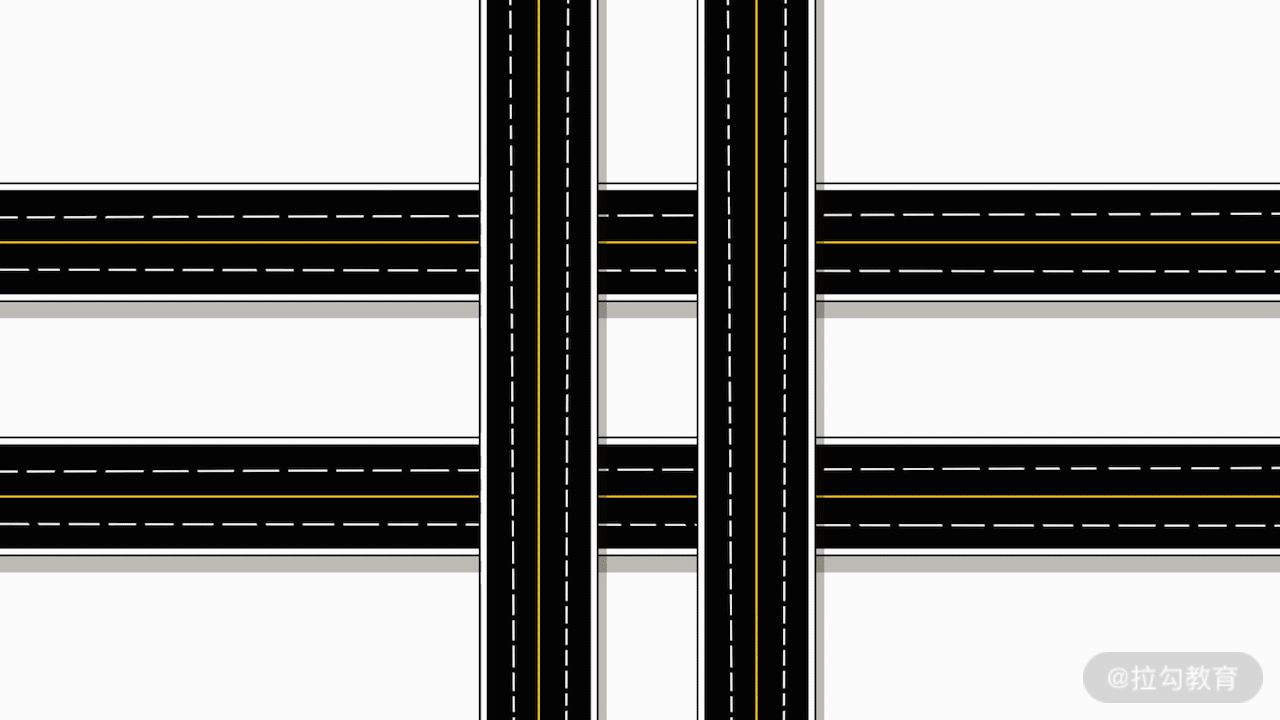
其實,程序開發也是可以借鑒這里的思想的。在程序開發中,連接時間和空間的橋梁就是數據結構。對于一個開發任務,如果你能找到一種高效的數據組織方式,采用合理的數據結構的話,那就可以實現時間復雜度的再次降低。同樣的,這通常會增加數據的存儲量,也就是增加了空間復雜度。
以上就是程序優化的最核心的思路,也是這個專欄的整體框架。我們簡單梳理如下:
* 第一步,暴力解法。在沒有任何時間、空間約束下,完成代碼任務的開發。
* 第二步,無效操作處理。將代碼中的無效計算、無效存儲剔除,降低時間或空間復雜度。
* 第三步,時空轉換。設計合理數據結構,完成時間復雜度向空間復雜度的轉移。
* [ ] 降低復雜度的案例
有了如上的方法論,我們給出幾個例子,幫助你加深理解。
第 1 個例子,假設有任意多張面額為 2 元、3 元、7 元的貨幣,現要用它們湊出 100 元,求總共有多少種可能性。假設工程師小明寫了下面的代碼:
```
public void s2_1() {
int count = 0;
for (int i = 0; i <= (100 / 7); i++) {
for (int j = 0; j <= (100 / 3); j++) {
for (int k = 0; k <= (100 / 2); k++) {
if (i * 7 + j * 3 + k * 2 == 100) {
count += 1;
}
}
}
}
System.out.println(count);
}
```
在這段代碼中,使用了 3 層的 for 循環。從結構上來看,是很顯然的 O( n3 ) 的時間復雜度。然而,仔細觀察就會發現,代碼中最內層的 for 循環是多余的。因為,當你確定了要用 i 張 7 元和 j 張 3 元時,只需要判斷用有限個 2 元能否湊出 `100 - 7* i - 3* j `元就可以了。因此,代碼改寫如下:
```
public void s2_2() {
int count = 0;
for (int i = 0; i <= (100 / 7); i++) {
for (int j = 0; j <= (100 / 3); j++) {
if ((100-i*7-j*3 >= 0)&&((100-i*7-j*3) % 2 == 0)) {
count += 1;
}
}
}
System.out.println(count);
}
```
經過改造后,代碼的結構由 3 層 for 循環,變成了 2 層 for 循環。很顯然,時間復雜度就變成了O(n2) 。這樣的代碼改造,就是利用了方法論中的步驟二,將代碼中的無效計算、無效存儲剔除,降低時間或空間復雜度。
再看第二個例子。查找出一個數組中,出現次數最多的那個元素的數值。例如,輸入數組 a = [1,2,3,4,5,5,6 ] 中,查找出現次數最多的數值。從數組中可以看出,只有 5 出現了 2 次,其余都是 1 次。顯然 5 出現的次數最多,則輸出 5。
工程師小明的解決方法是,采用兩層的 for 循環完成計算。第一層循環,對數組每個元素遍歷。第二層循環,則是對第一層遍歷的數字,去遍歷計算其出現的次數。這樣,全局再同時緩存一個出現次數最多的元素及其次數就可以了。具體代碼如下:
```
public void s2_3() {
int a[] = { 1, 2, 3, 4, 5, 5, 6 };
int val_max = -1;
int time_max = 0;
int time_tmp = 0;
for (int i = 0; i < a.length; i++) {
time_tmp = 0;
for (int j = 0; j < a.length; j++) {
if (a[i] == a[j]) {
time_tmp += 1;
}
if (time_tmp > time_max) {
time_max = time_tmp;
val_max = a[i];
}
}
}
System.out.println(val_max);
}
```
在這段代碼中,小明采用了兩層的 for 循環,很顯然時間復雜度就是 O(n2)。而且代碼中,幾乎沒有冗余的無效計算。如果還需要再去優化,就要考慮采用一些數據結構方面的手段,來把時間復雜度轉移到空間復雜度了。
我們先想象一下,這個問題能否通過一次 for 循環就找到答案呢?一個直觀的想法是,一次循環的過程中,我們同步記錄下每個元素出現的次數。最后,再通過查找次數最大的元素,就得到了結果。
具體而言,定義一個 k-v 結構的字典,用來存放元素-出現次數的 k-v 關系。那么首先通過一次循環,將數組轉變為元素-出現次數的一個字典。接下來,再去遍歷一遍這個字典,找到出現次數最多的那個元素,就能找到最后的結果了。

具體代碼如下:
```
public void s2_4() {
int a[] = { 1, 2, 3, 4, 5, 5, 6 };
Map<Integer, Integer> d = new HashMap<>();
for (int i = 0; i < a.length; i++) {
if (d.containsKey(a[i])) {
d.put(a[i], d.get(a[i]) + 1);
} else {
d.put(a[i], 1);
}
}
int val_max = -1;
int time_max = 0;
for (Integer key : d.keySet()) {
if (d.get(key) > time_max) {
time_max = d.get(key);
val_max = key;
}
}
System.out.println(val_max);
}
```
我們來計算下這種方法的時空復雜度。代碼結構上,有兩個 for 循環。不過,這兩個循環不是嵌套關系,而是順序執行關系。其中,第一個循環實現了數組轉字典的過程,也就是 O(n) 的復雜度。第二個循環再次遍歷字典找到出現次數最多的那個元素,也是一個 O(n) 的時間復雜度。
因此,總體的時間復雜度為 O(n) + O(n),就是 O(2n),根據復雜度與具體的常系數無關的原則,也就是O(n) 的復雜度。空間方面,由于定義了 k-v 字典,其字典元素的個數取決于輸入數組元素的個數。因此,空間復雜度增加為 O(n)。
這段代碼的開發,就是借鑒了方法論中的步驟三,通過采用更復雜、高效的數據結構,完成了時空轉移,提高了空間復雜度,讓時間復雜度再次降低。
#### 總結
好的,這一節的內容就到這里了。這一節是這門課程的總綱,我們重點學習了程序開發中復雜度降低的核心方法論。很多初學者在面對程序卡死了、運行很久沒有結果這樣的問題時,都會顯得束手無策。
其實,無論什么難題,降低復雜度的方法就是這三個步驟。只要你能深入理解這里的核心思想,就能把問題迎刃而解。
* 第一步,暴力解法。在沒有任何時間、空間約束下,完成代碼任務的開發。
* 第二步,無效操作處理。將代碼中的無效計算、無效存儲剔除,降低時間或空間復雜度。
* 第三步,時空轉換。設計合理數據結構,完成時間復雜度向空間復雜度的轉移。
既然說這是這門專欄的總綱,那么很顯然后續的學習都是在這個總綱體系的框架中。第一步的暴力解法沒有太多的套路,只要圍繞你面臨的問題出發,大膽發揮想象去嘗試解決即可。第二步的無效操作處理中,你需要學會并掌握遞歸、二分法、排序算法、動態規劃等常用的算法思維。第三步的時空轉換,你需要對數據的操作進行細分,全面掌握常見數據結構的基礎知識。再圍繞問題,有針對性的設計數據結構、采用合理的算法思維,去不斷完成時空轉移,降低時間復雜度。
后續的課程,我們會圍繞步驟二和步驟三的知識要點,逐一去深入討論學習。
#### 練習題
下面我們來看一道練習題。在下面這段代碼中,如果要降低代碼的執行時間,第 4 行需要做哪些改動呢?如果做出改動后,是否降低了時間復雜度呢?
```
public void s2_2() {
int count = 0;
for (int i = 0; i <= (100 / 7); i++) {
for (int j = 0; j <= (100 / 3); j++) {
if ((100-i*7-j*3 >= 0)&&((100-i*7-j*3) % 2 == 0)) {
count += 1;
}
}
}
System.out.println(count);
}
```
我們給出一些提示,第 4 行代碼,j 需要遍歷到 33。但很顯然,隨著 i 的變大,j 并不需要遍歷到 33。例如,當 i 為 9 的時候,j 最大也只能取到 12。如果 j 大于 12,則 7*9 + 3*13 > 100。不過,別忘了,即使是這樣,j 的取值范圍也是與 n 線性相關的。哪怕是 O(n/2),其實時間復雜度也并沒有變小。
最后,你在工作過程中有沒有遇到面對代碼無法下手優化的問題嗎?你最終是如何解決的呢?歡迎你在留言區和我分享。
- 前言
- 開篇詞
- 數據結構與算法,應該這樣學!
- 模塊一:代碼效率優化方法論
- 01復雜度:如何衡量程序運行的效率?
- 02 數據結構:將“昂貴”的時間復雜度轉換成“廉價”的空間復雜度
- 模塊二:數據結構基礎
- 03 增刪查:掌握數據處理的基本操作,以不變應萬變
- 04 如何完成線性表結構下的增刪查?
- 05 棧:后進先出的線性表,如何實現增刪查?
- 06 隊列:先進先出的線性表,如何實現增刪查?
- 07 數組:如何實現基于索引的查找?
- 08 字符串:如何正確回答面試中高頻考察的字符串匹配算法?
- 09 樹和二叉樹:分支關系與層次結構下,如何有效實現增刪查?
- 10 哈希表:如何利用好高效率查找的“利器”?
- 模塊三:算法思維基礎
- 11 遞歸:如何利用遞歸求解漢諾塔問題?
- 12 分治:如何利用分治法完成數據查找?
- 13 排序:經典排序算法原理解析與優劣對比
- 14 動態規劃:如何通過最優子結構,完成復雜問題求解?
- 模塊四:面試真題 = 實踐問題的“縮影”
- 15 定位問題才能更好地解決問題:開發前的復雜度分析與技術選型
- 16 真題案例(一):算法思維訓練
- 17真題案例(二):數據結構訓練
- 18 真題案例(三):力扣真題訓練
- 19 真題案例(四):大廠真題實戰演練
- 特別放送:面試現場
- 20 代碼之外,技術面試中你應該具備哪些軟素質?
- 21 面試中如何建立全局觀,快速完成優質的手寫代碼?
- 結束語
- 結束語 勤修內功,構建你的核心競爭力