
在前面課時中,我們已經學習了解決代碼問題的方法論。宏觀上,它可以分為以下 4 個步驟:
1. 復雜度分析。估算問題中復雜度的上限和下限。
2. 定位問題。根據問題類型,確定采用何種算法思維。
3. 數據操作分析。根據增、刪、查和數據順序關系去選擇合適的數據結構,利用空間換取時間。
4. 編碼實現。
這套方法論的框架,是解決絕大多數代碼問題的基本步驟。其中第 3 步,數據操作分析是數據結構發揮價值的地方。本課時,我們將繼續通過經典真題案例進行數據結構訓練。
#### 數據結構訓練題
**例題 1:反轉字符串中的單詞**
【題目】 給定一個字符串,逐個翻轉字符串中的每個單詞。例如,輸入:"This is a good example",輸出:"example good a is This"。如果有多余的空格需要刪除。
【解析】 在本課時開頭,我們復習了解決代碼問題的方法論,下面我們按照解題步驟進行詳細分析。
首先分析一下復雜度。這里的動作可以分為拆模塊和做翻轉兩部分。在采用比較暴力的方法時,拆模塊使用一個 for 循環,做翻轉也使用一個 for 循環。這樣雙重循環的嵌套,就是 O(n2) 的復雜度。
接下來定位問題。我們可以看到它對數據的順序非常敏感,敏感點一是每個單詞需要保證順序;敏感點二是所有單詞放在一起的順序需要調整為逆序。我們曾學過的關于數據順序敏感的結構有隊列和棧,也許這些結構可以適用在這個問題中。此處需要逆序,棧是有非常大的可能性被使用到的。
然后我們進行數據操作分析。如果要使用棧的話,從結果出發,就需要按照順序,把 This、is、a、good、example 分別入棧。要想把它們正確地入棧,就需要根據空格來拆分原始字符串。
因此,經過分析后,這個例子的解法為:用空格把句子分割成單詞。如果發現了多余的連續空格,需要做一些刪除的額外處理。一邊得到單詞,一邊把單詞放入棧中。直到最后,再把單詞從棧中倒出來,形成結果字符串。

最后,我們按照上面的思路進行編碼開發。代碼如下:
```
public static void main(String[] args) {
String ss = "This is a good example";
System.out.println(reverseWords(ss));
}
private static String reverseWords(String s) {
Stack stack=new Stack();
String temp = "";
for (int i = 0; i < s.length(); i++) {
if (s.charAt(i) != ' ') {
temp += s.charAt(i);
}
else if (temp != ""){
stack.push(temp);
temp = "";
}
else{
continue;
}
}
if (temp != ""){
stack.push(temp);
}
String result = "";
while (!stack.empty()){
result += stack.pop() + " ";
}
return result.substring(0,result.length()-1);
}
```
下面我們對代碼進行解讀。 主函數中,第 1~4 行,不用過多贅述。第 7 行定義了一個棧,第 8 行定義了一個緩存字符串的變量。
接著,在第 9~20 行進入 for 循環。對每個字符分別進行如下判斷:
* 如果字符不是空格,當前單詞還沒有結束,則放在 temp 變量后面;
* 如果字符是空格(10~12 行),說明當前單詞結束了;
* 如果 temp 變量不為空(13~16 行),則入棧;
* 如果字符是空格,但 temp 變量是空的,就說明雖然單詞結束了(17~19 行),但當前并沒有得到新的單詞。也就是連續出現了多個空格的情況。此時用 continue 語句忽略。
然后,再通過 21~23 行,把最后面的一個單詞(它可能沒有最后的空格幫助切分)放到棧內。此時所有的單詞都完成了入棧。
最后,在 24~28 行,讓棧內的字符串先后出棧,并用空格隔離開放在 result 字符串內。最后返回 result 變量。別忘了,最后一次執行 pop 語句時,多給了 result 一個空格,需要將它刪除掉。這樣就完成了這個問題。
這段代碼采用了一層的 for 循環,顯然它的時間復雜度是 O(n)。相比較于比較暴力的解法,它之所以降低了時間復雜度,就在于它開辟了棧的存儲空間。所以空間復雜度也是 O(n)。
**例題 2:樹的層序遍歷**
【題目】 給定一棵樹,按照層次順序遍歷并打印這棵樹。例如,輸入的樹為:
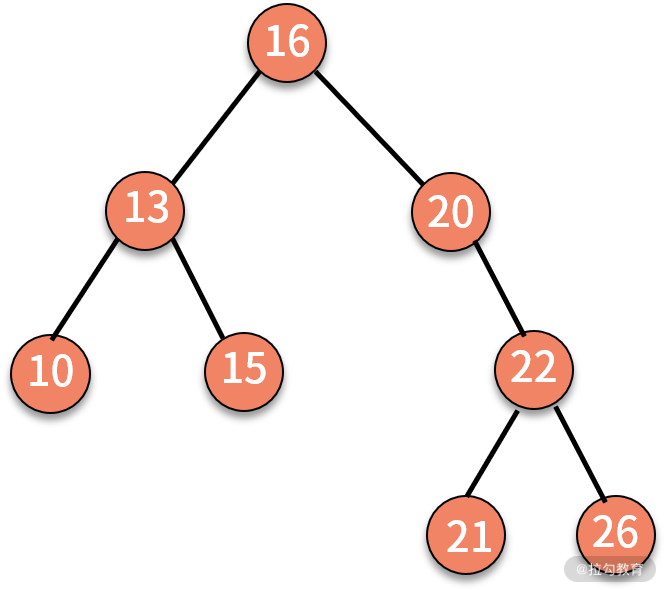
則打印 16、13、20、10、15、22、21、26。格外需要注意的是,這并不是前序遍歷。
【解析】 如果你一直在學習這門課的話,一定對這道題目似曾相識。它是我們在 09 課時中留下的練習題。同時它也是高頻面試題。仔細分析下這個問題,不難發現它是一個關于樹的遍歷問題。理論上是可以在 O(n) 時間復雜度下完成訪問的。
以往我們學過的遍歷方式有前序、中序和后序遍歷,它們的實現方法都是通過遞歸。以前序遍歷為例,遞歸可以理解為,先解決根結點,再解決左子樹一邊的問題,最后解決右子樹的問題。這很像是在用深度優先的原則去遍歷一棵樹。
現在我們的問題要求是按照層次遍歷,這就跟上面的深度優先的原則完全不一樣了,更像是廣度優先。也就是說,從遍歷的順序來看,一會在左子樹、一會在右子樹,會來回跳轉。顯然,這是不能用遞歸來處理的。
那么我們該如何解決呢?
我們從結果來看看這個問題有什么特點。打印的結果是 16、13、20、10、15、22、21、26。
從后往前看,可以發現:打印 21 和 26 之前,會先打印 22。這是一棵樹的上下級關系;打印 10 和 15 之前,會先打印 13,這也是一棵樹的上下級關系。顯然,結果對上下級關系的順序非常敏感。
接著,我們發現 13 和 10、15 之間的打印關系并不連續,夾雜著右邊的結點 20。也就是說,左邊的優先級大于右邊大于下邊。
分析到這里,你應該能找到一些感覺了吧。一個結果序列對順序敏感,而且沒有逆序的操作,滿足這些特點的數據結構只有隊列。所以我們猜測這個問題的解決方案,極有可能要用到隊列。
隊列只有入隊列和出隊列的操作。如果輸出結果就是出隊列的順序,那這個順序必然也是入隊列的順序,原因就在于隊列的出入原則是先進先出。而入隊列的原則是,上層父節點先進,左孩子再進,右孩子最后進。
因此,這道題目的解決方案就是,根結點入隊列,隨后循環執行結點出隊列并打印結果,左孩子入隊列,右孩子入隊列。直到隊列為空。如下圖所示:

這個例子的代碼如下:
```
public static void levelTraverse(Node root) {
LinkedList<Node> queue = new LinkedList<Node>();
Node current = null;
queue.offer(root); // 根結點入隊
while (!queue.isEmpty()) {
current = queue.poll(); // 出隊隊頭元素
System.out.print(current.data);
// 左子樹不為空,入隊
if (current.leftChild != null)
queue.offer(current.leftChild);
// 右子樹不為空,入隊
if (current.rightChild != null)
queue.offer(current.rightChild);
}
}
```
下面我們對代碼進行解讀。在這段代碼中,第 2 行首先定義了一個隊列 queue,并在第 4 行讓根結點入隊列,此時隊列不為空。
接著進入一個 while 循環進行遍歷。當隊列不為空的時候,第 6 行首先執行出隊列操作,并把結果存在 current 變量中。隨后第 7 行打印 current 的數值。如果 current 還有左孩子或右孩子,則分別按順序執行入隊列的操作,這是在第 9~13 行。
經過這段代碼,可以完成的是,所有順序都按照層次順序入隊列,且左孩子優先。這樣就得到了按行打印的結果。時間復雜度是 O(n)。空間復雜度由于定義了 queue 變量,因此也是 O(n)。
**例題 3:查找數據流中的中位數**
【題目】 在一個流式數據中,查找中位數。如果是偶數個,則返回偏左邊的那個元素。
例如:
```
輸入 1,服務端收到 1,返回 1。
輸入 2,服務端收到 1、2,返回 1。
輸入 0,服務端收到 0、1、2,返回 1。
輸入 20,服務端收到 0、1、2、20,返回 1。
輸入 10,服務端收到 0、1、2、10、20,返回 2。
輸入 22,服務端收到 0、1、2、10、20、22,返回 2。
```
【解析】 這道題目依舊是按照解決代碼問題的方法論的步驟進行分析。
先看一下復雜度。顯然,這里的問題定位就是個查找問題。對于累積的客戶端輸入,查找其中位數。中位數的定義是,一組數字按照從小到大排列后,位于中間位置的那個數字。
根據這個定義,最簡單粗暴的做法,就是對服務端收到的數據進行排序得到有序數組,再通過 index 直接取出數組的中位數。排序選擇快排的時間復雜度是 O(nlogn)。
接下來分析一下這個查找問題。該問題有一個非常重要的特點,我們注意到,上一輪已經得到了有序的數組,那么這一輪該如何巧妙利用呢?
舉個例子,如果采用全排序的方法,那么在第 n 次收到用戶輸入時,則需要對 n 個數字進行排序并輸出中位數,此時服務端已經保存了這 n 個數字的有序數組了。而在第 n+1 次收到用戶輸入時,是不需要對 n+1 個數字整體排序的,僅僅通過插入這個數字到一個有序數組中就可以完成排序。顯然,利用這個性質后,時間復雜度可以降低到 O(n)。
接著,我們從數據的操作層面來看,是否仍然有優化的空間。對于這個問題,其目標是輸出中位數。只要你能在 n 個數字中,找到比 x 小的 n/2 個數字和比 x 大的 n/2 個數字,那么 x 就是最終需要返回的結果。
基于這個思想,可以動態的維護一個最小的 n/2 個數字的集合,和一個最大的 n/2 個數字的集合。如果數字是奇數個,就我們就在左邊最小的 n/2 個數字集合中多存一個元素。
例如,當前服務端收到的數字有 0、1、2、10、20。如果用兩個數據結構分別維護 0、1、2 和 10、20,那么當服務端收到 22 時,就可以根據 1、2、10 和 22 的大小關系,判斷出中位數到底是多少了。
具體而言,當前的中位數是 2,額外增加一個數字之后,新的中位數只可能發生在 1、2、10 和新增的一個數字之間。不管中位數發生在哪里,都可以通過一些 if-else 語句進行查找,那么時間復雜度就是 O(1)。
雖然這種方法對于查找中位數的時間復雜度降低到了 O(1),但是它還需要有一些后續的處理,這主要是輔助下一次的請求。
例如,當前用兩個數據結構分別維護著 0、1、2 和 10、20,那么新增了 22 之后,這兩個數據結構如何更新。這就是原問題最核心的瓶頸了。
從結果來看,如果新增的數字比較小,那么就添加到左邊的數據結構,并且把其中最大的 2 新增到右邊,以保證二者數量相同。如果新增的數字比較大,那么就放到右邊的數據結構,以保證二者數量相同。在這里,可能需要的數據操作包括,查找、中間位置的新增、最后位置的刪除。
順著這個思路繼續分析,有序環境中的查找可以采用二分查找,時間復雜度是 O(logn)。最后位置的刪除,并不牽涉到數據的挪移,時間復雜度是 O(1)。中間位置的新增就麻煩了,它需要對數據進行挪移,時間復雜度是 O(n)。如果要降低它的復雜度就需要用一些其他手段了。
在這個問題中,有一個非常重要的信息,那就是題目只要中位數,而中位數左邊和右邊是否有序不重要。于是,我們需要用到這樣的數據結構,大頂堆和小頂堆。
* 大頂堆是一棵完全二叉樹,它的性質是,父結點的數值比子結點的數值大;
* 小頂堆的性質與此相反,父結點的數值比子結點的數值小。
有了這兩個堆之后,我們的操作步驟就是,將中位數左邊的數據都保存在大頂堆中,中位數右邊的數據都保存在小頂堆中。同時,還要保證兩個堆保存的數據個數相等或只差一個。這樣,當有了一個新的數據插入時,插入數據的時間復雜度是 O(logn)。而插入后的中位數,肯定在大頂堆的堆頂元素上,因此,找到中位數的時間復雜度就是 O(1)。
我們把這個思路,用代碼來實現,則有:
```
import java.util.PriorityQueue;
import java.util.Comparator;
public class testj {
int count = 0;
static PriorityQueue<Integer> minHeap = new PriorityQueue<>();
static PriorityQueue<Integer> maxHeap = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
public void Insert(Integer num) {
if (count % 2 == 0) {
minHeap.offer(num);
maxHeap.offer(minHeap.poll());
} else {
maxHeap.offer(num);
minHeap.offer(maxHeap.poll());
}
count++;
System.out.println(testj.GetMedian());
}
public static int GetMedian() {
return maxHeap.peek();
}
public static void main(String[] args) {
testj t = new testj();
t.Insert(1);
t.Insert(2);
t.Insert(0);
t.Insert(20);
t.Insert(10);
t.Insert(22);
}
}
```
我們對代碼進行解讀: 在第 6~12 行,分別定義了最小堆和最大堆。第 5 行的變量,保存的是累積收到的輸入個數,可以用來判斷奇偶。接著我們看主函數的第 30~38 行。在這里,模擬了流式數據,先后輸入了 1、2、0、20、10、22,并調用了 Inset() 函數。
從第 14 行開始,Inset() 函數中,需要判斷 count 的奇偶性:如果 count 是偶數,則新的數據需要先加入最小堆,再彈出最小堆的堆頂,最后把彈出的數據加入最大堆。如果 count 是奇數,則新的數據需要先加入最大堆,再彈出最大堆的堆頂,最后把彈出的數據加入最小堆。
執行完后,count 加 1。然后調用 GetMedian() 函數來尋找中位數,GetMedian() 函數通過 27 行直接返回最大堆的對頂,這是因為我們約定中位數在偶數個的時候,選擇偏左的元素。
最后,我們給出插入 22 的執行過程,如下圖所示:

#### 總結
這一課時主要圍繞數據結構展開問題的分析和討論。對于樹的層次遍歷,我們再拓展一下。
如果要打印的不是層次,而是蛇形遍歷,又該如何實現呢?蛇形遍歷就是 s 形遍歷,即奇數層從左到右,偶數層從右到左。如果是例題 2 的樹,則蛇形遍歷的結果就是 16、20、13、10、15、22、26、21。我們就把這個問題當作本課時的練習題。
- 前言
- 開篇詞
- 數據結構與算法,應該這樣學!
- 模塊一:代碼效率優化方法論
- 01復雜度:如何衡量程序運行的效率?
- 02 數據結構:將“昂貴”的時間復雜度轉換成“廉價”的空間復雜度
- 模塊二:數據結構基礎
- 03 增刪查:掌握數據處理的基本操作,以不變應萬變
- 04 如何完成線性表結構下的增刪查?
- 05 棧:后進先出的線性表,如何實現增刪查?
- 06 隊列:先進先出的線性表,如何實現增刪查?
- 07 數組:如何實現基于索引的查找?
- 08 字符串:如何正確回答面試中高頻考察的字符串匹配算法?
- 09 樹和二叉樹:分支關系與層次結構下,如何有效實現增刪查?
- 10 哈希表:如何利用好高效率查找的“利器”?
- 模塊三:算法思維基礎
- 11 遞歸:如何利用遞歸求解漢諾塔問題?
- 12 分治:如何利用分治法完成數據查找?
- 13 排序:經典排序算法原理解析與優劣對比
- 14 動態規劃:如何通過最優子結構,完成復雜問題求解?
- 模塊四:面試真題 = 實踐問題的“縮影”
- 15 定位問題才能更好地解決問題:開發前的復雜度分析與技術選型
- 16 真題案例(一):算法思維訓練
- 17真題案例(二):數據結構訓練
- 18 真題案例(三):力扣真題訓練
- 19 真題案例(四):大廠真題實戰演練
- 特別放送:面試現場
- 20 代碼之外,技術面試中你應該具備哪些軟素質?
- 21 面試中如何建立全局觀,快速完成優質的手寫代碼?
- 結束語
- 結束語 勤修內功,構建你的核心競爭力