
在備戰公司面試的時候,相信你一定也刷過力扣(leetcode)的題目吧。力扣的題目種類多樣,而且有虛擬社區功能,因此很多同學都喜歡在上面分享習題答案。
毫無疑問,如果你完整地刷過力扣題庫,在一定程度上能夠提高你面試通過的可能性。因此,在本課時,我選擇了不同類型、不同層次的力扣真題,我會通過這些題目進一步講述和分析解決數據結構問題的方法。
#### 力扣真題訓練
在看真題前,我們再重復一遍通用的解題方法論,它可以分為以下 4 個步驟:
1. 復雜度分析。估算問題中復雜度的上限和下限。
2. 定位問題。根據問題類型,確定采用何種算法思維。
3. 數據操作分析。根據增、刪、查和數據順序關系去選擇合適的數據結構,利用空間換取時間。
4. 編碼實現。
**例題 1:刪除排序數組中的重復項**
【題目】 給定一個排序數組,你需要在原地刪除重復出現的元素,使得每個元素只出現一次,返回移除后的數組和新的長度,你不需要考慮數組中超出新長度后面的元素。
要求:空間復雜度為 O(1),即不要使用額外的數組空間。
例如,給定數組 nums = [1,1,2],函數應該返回新的長度 2,并且原數組 nums 的前兩個元素被修改為 1, 2。又如,給定 nums = [0,0,1,1,1,2,2,3,3,4],函數應該返回新的長度 5,并且原數組 nums 的前五個元素被修改為 0, 1, 2, 3, 4。
【解析】 這個題目比較簡單,應該是送分題。不過,面試過程中的送分題也是送命題。這是因為,如果送分題沒有拿下,就會顯得非常說不過去。
我們先來看一下復雜度。這里并沒有限定時間復雜度,僅僅是要求了空間上不能定義新的數組。
然后我們來定位問題。顯然這是一個數據去重的問題。
按照解題步驟,接下來我們需要做數據操作分析。 在一個去重問題中,每次遍歷的新的數據,都需要與已有的不重復數據進行對比。這時候,就需要查找了。整體來看,遍歷嵌套查找,就是 O(n2) 的復雜度。如果要降低時間復雜度,那么可以在查找上入手,比如使用哈希表。不過很可惜,使用了哈希表之后,空間復雜度就是 O(n)。幸運的是,原數組是有序的,這就可以讓查找的動作非常簡單了。
因此,解決方案上就是,一次循環嵌套查找完成。查找不可使用哈希表,但由于數組有序,時間復雜度是 O(1)。因此整體的時間復雜度就是 O(n)。
我們來看一下具體方案。既然是一次循環,那么就需要一個 for 循環對整個數組進行遍歷。每輪遍歷的動作是查找 nums[i] 是否已經出現過。因為數組有序,因此只需要去對比 nums[i] 和當前去重數組的最大值是否相等即可。我們用一個 temp 變量保存去重數組的最大值。
如果二者不等,則說明是一個新的數據。我們就需要把這個新數據放到去重數組的最后,并且修改 temp 變量的值,再修改當前去重數組的長度變量 len。直到遍歷完,就得到了結果。

最后,我們按照上面的思路進行編碼開發,代碼如下:
```
public static void main(String[] args) {
int[] nums = {0,0,1,1,1,2,2,3,3,4};
int temp = nums[0];
int len = 1;
for (int i = 1; i < nums.length; i++) {
if (nums[i] != temp) {
nums[len] = nums[i];
temp = nums[i];
len++;
}
}
System.out.println(len);
for (int i = 0; i < len; i++) {
System.out.println(nums[i]);
}
}
```
我們對代碼進行解讀。 在這段代碼中,第 3~4 行進行了初始化,得到的 temp 變量是數組第一個元素,len 變量為 1。
接著進入 for 循環。如果當前元素與去重的最大值不等(第 6 行),則新元素放入去重數組中(第 7 行),并且更新去重數組的最大值(第 8 行),再讓去重數組的長度加 1(第 9 行)。最后得到結果后,再打印出來,第 12~15 行。
**例題 2:查找兩個有序數組合并后的中位數**
【題目】 兩個有序數組查找合并之后的中位數。給定兩個大小為 m 和 n 的正序(從小到大)數組 nums1 和 nums2。請你找出這兩個正序數組合在一起之后的中位數,并且要求算法的時間復雜度為 O(log(m + n))。
你可以假設 nums1 和 nums2 不會同時為空,所有的數字全都不相等。還可以再假設,如果數字個數為偶數個,中位數就是中間偏左的那個元素。
例如:nums1 = [1, 3, 5, 7, 9]
nums2 = [2, 4, 8, 12]
輸出 5。
【解析】 這個題目是我個人非常喜歡的,原因是,它所有的解法和思路,都隱含在了題目的描述中。如果你具備很強的分析和解決問題的能力,那么一定可以找到最優解法。
我們先看一下復雜度的分析。這里的 nums1 和 nums2 都是有序的,這讓我們第一時間就想到了歸并排序。方法很簡單,我們把兩個數組合并,就得到了合在一起后的有序數組。這個動作的時間復雜度是 O(m+n)。接著,我們從數組中就可以直接取出中位數了。很可惜,這并不滿足題目的時間復雜度 O(log(m + n)) 的要求。
接著,我們來看一下這個問題的定位。題目中有一個關鍵字,那就是“找出”。很顯然,我們要找的目標就藏在 nums1 或 nums2 中。這明顯就是一個查找問題。而在查找問題中,我們學過的知識是分治法下的二分查找。
回想一下,二分查找適用的重要條件就是,原數組有序。恰好,在這個問題中 nums1 和 nums2 分別都是有序的。而且二分查找的時間復雜度是 O(logn),這和題目中給出的時間復雜度 O(log(m + n)) 的要求也是不謀而合。因此,經過分析,我們可以大膽猜測,此題極有可能要用到二分查找。
我們再來看一下數據結構方面。如果要用二分查找,就需要用到若干個指針,去約束查找范圍。除此以外,并不需要去定義復雜的數據結構。也就是說,空間復雜度是 O(1) 。
好了,接下來,我們就來看一下二分查找如何能解決這個問題。二分查找需要一個分裂點,去把原來的大問題,拆分成兩個部分,并在其中一部分繼續執行二分查找。既然是查找中位數,我們不妨先試試以中位數作為切分點,看看會產生什么結果。如下圖所示:
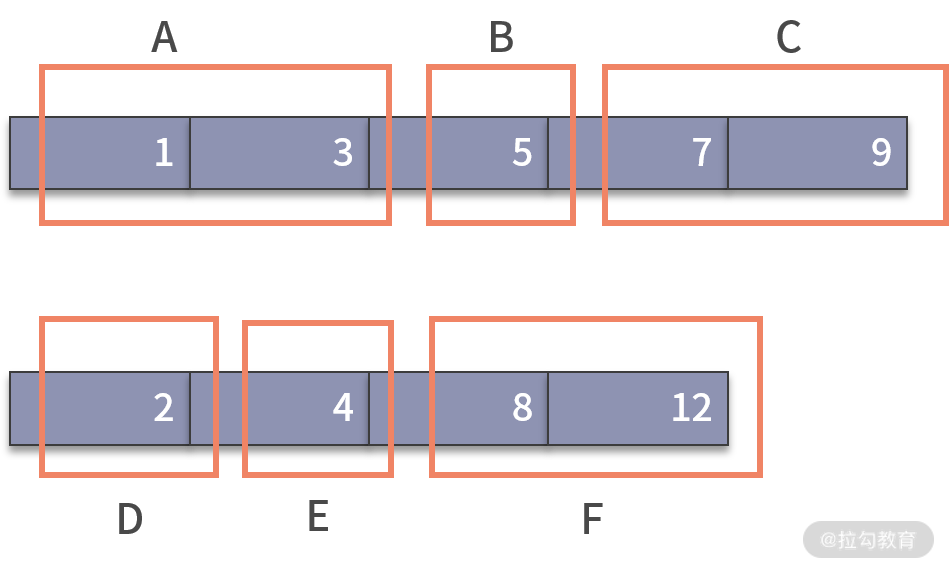
經過切分后,兩個數組分別被拆分為 3 個部分,合在一起是 6 個部分。二分查找的思路是,需要從這 6 個部分中,剔除掉一些,讓查找的范圍縮小。那么,我們來思考一個問題,在這 6 個部分中,目標中位數一定不會發生在哪幾個部分呢?
中位數有一個重要的特質,那就是比中位數小的數字個數,和比中位數大的數字個數,是相等的。圍繞這個性質來看,中位數就一定不會發生在 C 和 D 的區間。
如果中位數在 C 部分,那么在 nums1 中,比中位數小的數字就會更多一些。因為 4 < 5(nums2 的中位數小于 nums1 的中位數),所以在 nums2 中,比中位數小的數字也會更多一些(最不濟也就是一樣多)。因此,整體來看,中位數不可能在 C 部分。同理,中位數也不會發生在 D 部分。
接下來,我們就可以在查找范圍內,剔除掉 C 部分(永遠比中位數大的數字)和 D 部分(永遠比中位數小的數字),這樣我們就成功地完成了一次二分動作,縮小了查找范圍。然而這樣并沒結束。剔除掉了 C 和 D 之后,中位數有可能發生改變。這是因為,C 部分的數字個數和 D 部分數字的個數是不相等的。剔除不相等數量的“小數”和“大數”后,會造成中位數的改變。
為了解決這個問題,我們需要對剔除的策略進行修改。一個可行的方法是,如果 C 部分數字更少為 p 個,則剔除 C 部分;并只剔除 D 部分中的 p 個數字。這樣就能保證,經過一次二分后,剔除之后的數組的中位數不變。
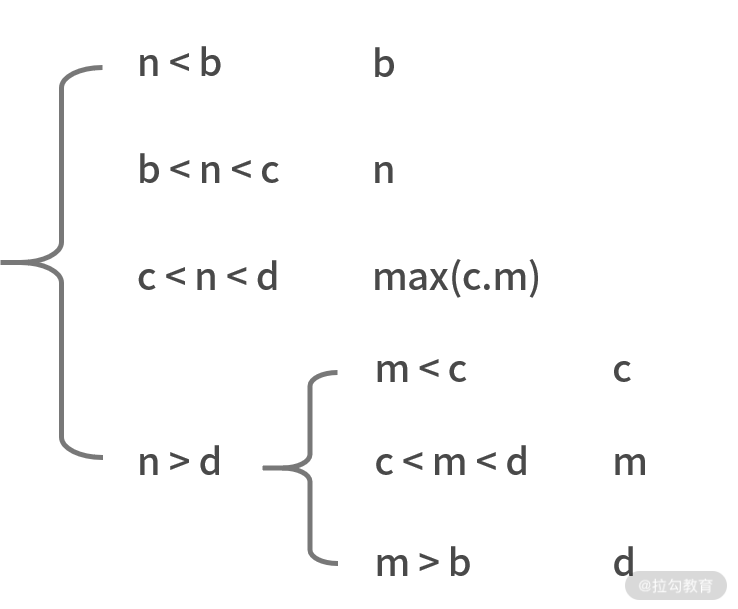
應該剔除 C 部分和 D 部分。但 D 部分更少,因此剔除 D 和 C 中的 9。
二分查找還需要考慮終止條件。對于這個題目,終止條件必然是某個數組小到無法繼續二分的時候。這是因為,每次二分剔除掉的是更少的那個部分。因此,在終止條件中,查找范圍應該是一個大數組和一個只有 1~2 個元素的小數組。這樣就需要根據大數組的奇偶性和小數組的數量,拆開 4 個可能性:
可能性一:nums1 奇數個,nums2 只有 1 個元素。例如,nums1 = [a, b, c, d, e],nums2 = [m]。此時,有以下 3 種可能性:
1. 如果 m < b,則結果為 b;
2. 如果 b < m < c,則結果為 m;
3. 如果 m > c,則結果為 c。
這 3 個情況,可以利用 "A?B:C" 合并為一個表達式,即 m < b ? b : (m < c ? m : c)。
可能性二:nums1 偶數個,nums2 只有 1 個元素。例如,nums1 = [a, b, c, d, e, f],nums2 = [m]。此時,有以下 3 種可能性:
1. 如果 m < c,則結果為 c;
2. 如果 c < m < d,則結果為 m;
3. 如果m > d,則結果為 d。
這 3 個情況,可以利用"A?B:C"合并為一個表達式,即 m < c ? c : (m < d? m : d)。
可能性三:nums1 奇數個,nums2 有 2 個元素。例如,nums1 = [a, b, c, d, e],nums2 = [m,n]。此時,有以下 6 種可能性:
1. 如果 n < b,則結果為 b;
2. 如果 b < n < c,則結果為 n;
3. 如果 c < n < d,則結果為 max(c,m);
4. 如果 n > d,m < c,則結果為 c;
5. 如果 n > d,c < m < d,則結果為 m;
6. 如果 n > d,m > d,則結果為 d。
其中,4~6 可以合并為,如果 n > d,則返回 m < c ? c : (m < d ? m : d)。
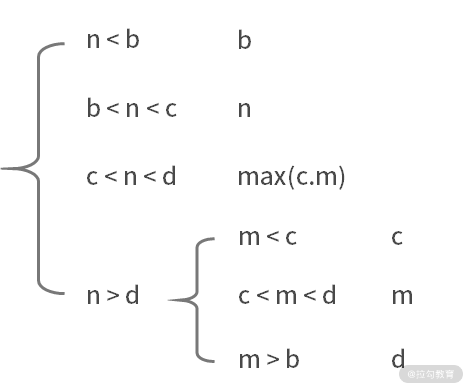
可能性四:nums1 偶數個,nums2 有 2 個元素。例如,nums1 = [a, b, c, d, e, f],nums2 = [m,n]。此時,有以下 6 種可能性:
1. 如果 n < b,則結果為 b;
2. 如果 b < n < c,則結果為 n;
3. 如果 c < n < d,則結果為 max(c,m);
4. 如果 n > d,m < c,則結果為 c;
5. 如果 n > d,c < m < d,則結果為 m;
6. 如果 n > d,m > d,則結果為 d。與可能性 3 完全一致。
不難發現,終止條件都是 if 和 else 的判斷,雖然邏輯有點復雜,但時間復雜度是 O(1) 。為了簡便,我們可以假定,nums1 的數字數量永遠是不少于 nums2 的數字數量。
因此,我們可以編寫如下的代碼:
```
public static void main(String[] args) {
int[] nums1 = {1,2,3,4,5};
int[] nums2 = {6,7,8};
int median = getMedian(nums1,0, nums1.length-1, nums2, 0, nums2.length-1);
System.out.println(median);
}
public static int getMedian(int[] a, int begina, int enda, int[] b, int beginb, int endb ) {
if (enda - begina == 0) {
return a[begina] > b[beginb] ? b[beginb] : a[begina];
}
if (enda - begina == 1){
if (a[begina] < b[beginb]) {
return b[beginb] > a[enda] ? a[enda] : b[beginb];
}
else {
return a[begina] < b[endb] ? a[begina] : b[endb];
}
}
if (endb-beginb < 2) {
if ((endb - beginb == 0) && (enda - begina)%2 != 0) {
int m = a[beginb];
int bb = b[(enda + begina)/2 - 1];
int c = b[(enda + begina)/2];
return (m < bb) ? bb : (m < c ? m : c);
}
else if ((endb - beginb == 0) && (enda - begina)%2 == 0) {
int m = a[beginb];
int c = b[(enda + begina)/2];
int d = b[(enda + begina)/2 + 1];
return m < c ? c : (m < d ? m : d);
}
else {
int m = b[beginb];
int n = b[endb];
int bb = a[(enda + begina)/2 - 1];
int c = a[(enda + begina)/2];
int d = a[(enda + begina)/2 + 1];
if (n<bb) {
return bb;
}
else if (n>bb && n < c) {
return n;
}
else if (n > c && n < d) {
return m > c ? m : c;
}
else {
return m < c ? c : (m<d ? m : d);
}
}
}
else {
int mida = (enda + begina)/2;
int midb = (endb + beginb)/2;
if (a[mida] < b[midb]) {
int step = endb - midb;
return getMedian(a,begina + step, enda, b, beginb, endb - step);
}
else {
int step = midb - beginb;
return getMedian(a,begina,enda - step, b, beginb+ step, endb );
}
}
}
```
我們對代碼進行解讀。在第 1~6 行是主函數,進入 getMedian() 中,入參分別是 nums1 數組,nums1 數組搜索范圍的起止索引;nums2 數組,nums2 數組搜索范圍的起止索引。并進入第 8 行的函數中。
在 getMedian() 函數中,第 53~64 行是二分策略,第 9~52 行是終止條件。我們先看二分部分。通過第 56 行,判斷 a 和 b 的中位數的大小關系,決策剔除哪個部分。并在第 58 行和 62 行,遞歸地執行二分動作縮小范圍。
終止條件的第一種可能性在第 21~26 行,第二種可能性在 27~32 行,第三種和第四種可能性完全一致,在 33~52 行。另外,在 9~19 行中處理了兩個特殊情況,分別是第 9~11 行,處理了兩個數組都只剩 1 個元素的情況;第 12~19 行,處理了兩個數組都只剩 2 個元素的情況。
這段代碼的邏輯并不復雜,但寫起來還是有很多情況需要考慮的。希望你能認真閱讀。
#### 總結
綜合來看,力扣的題目還是比較受到行業的認可的。一方面是它的題庫內題目數量多,另一方面是很多人會在上面提交相同題目的不同解法和答案。但對初學者來說,它還是有一些不友好的。這主要在于,它的定位只是題庫,并不能提供完整的解決問題的思維邏輯和方法論。
本課時,雖然我們只是舉了兩個例題,但其背后解題的思考方法是通用的。建議你能圍繞本課程學到的解題方法,利用空閑時間去把力扣熱門的題目都練習一遍。
練習題
最后,我們再給出一道練習題。給定一個鏈表,刪除鏈表的倒數第 n 個節點。
例如,給定一個鏈表: 1 -> 2 -> 3 -> 4 -> 5, 和 n = 2。當刪除了倒數第二個節點后,鏈表變為 1 -> 2 -> 3 -> 5。
你可以假設,給定的 n 是有效的。額外要求就是,要在一趟掃描中實現,即時間復雜度是 O(n)。這里給你一個提示,可以采用快慢指針的方法。
- 前言
- 開篇詞
- 數據結構與算法,應該這樣學!
- 模塊一:代碼效率優化方法論
- 01復雜度:如何衡量程序運行的效率?
- 02 數據結構:將“昂貴”的時間復雜度轉換成“廉價”的空間復雜度
- 模塊二:數據結構基礎
- 03 增刪查:掌握數據處理的基本操作,以不變應萬變
- 04 如何完成線性表結構下的增刪查?
- 05 棧:后進先出的線性表,如何實現增刪查?
- 06 隊列:先進先出的線性表,如何實現增刪查?
- 07 數組:如何實現基于索引的查找?
- 08 字符串:如何正確回答面試中高頻考察的字符串匹配算法?
- 09 樹和二叉樹:分支關系與層次結構下,如何有效實現增刪查?
- 10 哈希表:如何利用好高效率查找的“利器”?
- 模塊三:算法思維基礎
- 11 遞歸:如何利用遞歸求解漢諾塔問題?
- 12 分治:如何利用分治法完成數據查找?
- 13 排序:經典排序算法原理解析與優劣對比
- 14 動態規劃:如何通過最優子結構,完成復雜問題求解?
- 模塊四:面試真題 = 實踐問題的“縮影”
- 15 定位問題才能更好地解決問題:開發前的復雜度分析與技術選型
- 16 真題案例(一):算法思維訓練
- 17真題案例(二):數據結構訓練
- 18 真題案例(三):力扣真題訓練
- 19 真題案例(四):大廠真題實戰演練
- 特別放送:面試現場
- 20 代碼之外,技術面試中你應該具備哪些軟素質?
- 21 面試中如何建立全局觀,快速完成優質的手寫代碼?
- 結束語
- 結束語 勤修內功,構建你的核心競爭力