# 四、訓練模型
> 譯者:[@C-PIG](https://github.com/C-PIG)
>
> 校對者:[@PeterHo](https://github.com/PeterHo)、[@飛龍](https://github.com/wizardforcel)、[@YuWang](https://github.com/bigeyex)、[@AlecChen](https://github.com/alecchen)
在之前的描述中,我們通常把機器學習模型和訓練算法當作黑箱子來處理。如果你實踐過前幾章的一些示例,你驚奇的發現你可以優化回歸系統,改進數字圖像的分類器,你甚至可以零基礎搭建一個垃圾郵件的分類器,但是你卻對它們內部的工作流程一無所知。事實上,許多場合你都不需要知道這些黑箱子的內部有什么,干了什么。
然而,如果你對其內部的工作流程有一定了解的話,當面對一個機器學習任務時候,這些理論可以幫助你快速的找到恰當的機器學習模型,合適的訓練算法,以及一個好的假設集。同時,了解黑箱子內部的構成,有助于你更好地調試參數以及更有效的誤差分析。本章討論的大部分話題對于機器學習模型的理解,構建,以及神經網絡(詳細參考本書的第二部分)的訓練都是非常重要的。
首先我們將以一個簡單的線性回歸模型為例,討論兩種不同的訓練方法來得到模型的最優解:
+ 直接使用封閉方程進行求根運算,得到模型在當前訓練集上的最優參數(即在訓練集上使損失函數達到最小值的模型參數)
+ 使用迭代優化方法:梯度下降(GD),在訓練集上,它可以逐漸調整模型參數以獲得最小的損失函數,最終,參數會收斂到和第一種方法相同的的值。同時,我們也會介紹一些梯度下降的變體形式:批量梯度下降(Batch GD)、小批量梯度下降(Mini-batch GD)、隨機梯度下降(Stochastic GD),在第二部分的神經網絡部分,我們會多次使用它們。
接下來,我們將研究一個更復雜的模型:多項式回歸,它可以擬合非線性數據集,由于它比線性模型擁有更多的參數,于是它更容易出現模型的過擬合。因此,我們將介紹如何通過學習曲線去判斷模型是否出現了過擬合,并介紹幾種正則化方法以減少模型出現過擬合的風險。
最后,我們將介紹兩個常用于分類的模型:Logistic回歸和Softmax回歸
> 提示
>
> 在本章中包含許多數學公式,以及一些線性代數和微積分基本概念。為了理解這些公式,你需要知道什么是向量,什么是矩陣,以及它們直接是如何轉化的,以及什么是點積,什么是矩陣的逆,什么是偏導數。如果你對這些不是很熟悉的話,你可以閱讀本書提供的 Jupyter 在線筆記,它包括了線性代數和微積分的入門指導。對于那些不喜歡數學的人,你也應該快速簡單的瀏覽這些公式。希望它足以幫助你理解大多數的概念。
## 線性回歸
在第一章,我們介紹了一個簡單的生活滿意度回歸模型:

這個模型僅僅是輸入量`GDP_per_capita`的線性函數, 和  是這個模型的參數,線性模型更一般化的描述指通過計算輸入變量的加權和,并加上一個常數偏置項(截距項)來得到一個預測值。如公式 4-1:
公式 4-1:線性回歸預測模型

+ 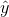 表示預測結果
+ 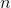 表示特征的個數
+ 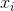 表示第`i`個特征的值
+  表示第`j`個參數(包括偏置項  和特征權重值 )
上述公式可以寫成更為簡潔的向量形式,如公式 4-2:
公式 4-2:線性回歸預測模型(向量形式)

+  表示模型的參數向量包括偏置項  和特征權重值  到 
+  表示向量的轉置(行向量變為了列向量)
+ 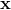 為每個樣本中特征值的向量形式,包括 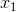 到 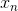,而且  恒為 1
+  表示  和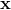 的點積
+  表示參數為  的假設函數
怎么樣去訓練一個線性回歸模型呢?好吧,回想一下,訓練一個模型指的是設置模型的參數使得這個模型在訓練集的表現較好。為此,我們首先需要找到一個衡量模型好壞的評定方法。在第二章,我們介紹到在回歸模型上,最常見的評定標準是均方根誤差(RMSE,詳見公式 2-1)。因此,為了訓練一個線性回歸模型,你需要找到一個  值,它使得均方根誤差(標準誤差)達到最小值。實踐過程中,最小化均方誤差比最小化均方根誤差更加的簡單,這兩個過程會得到相同的 ,因為函數在最小值時候的自變量,同樣能使函數的方根運算得到最小值。
在訓練集  上使用公式 4-3 來計算線性回歸假設  的均方差()。
公式 4-3:線性回歸模型的 MSE 損失函數

公式中符號的含義大多數都在第二章(詳見“符號”)進行了說明,不同的是:為了突出模型的參數向量 ,使用  來代替 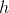。以后的使用中為了公式的簡潔,使用  來代替 。
### 正規方程(The Normal Equation)
為了找到最小化損失函數的  值,可以采用公式解,換句話說,就是可以通過解正規方程直接得到最后的結果。
公式 4-4:正規方程

+  指最小化損失  的值
+  是一個向量,其包含了  到  的值
讓我們生成一些近似線性的數據(如圖 4-1)來測試一下這個方程。
```python
import numpy as np
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
```

圖 4-1:隨機線性數據集
現在讓我們使用正規方程來計算 ,我們將使用 Numpy 的線性代數模塊(`np.linalg`)中的`inv()`函數來計算矩陣的逆,以及`dot()`方法來計算矩陣的乘法。
```python
X_b = np.c_[np.ones((100, 1)), X]
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
```
我們生產數據的函數實際上是 。讓我們看一下最后的計算結果。
```python
>>> theta_best
array([[4.21509616],[2.77011339]])
```
我們希望最后得到的參數為  而不是  (譯者注:我認為應該是 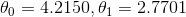)。這已經足夠了,由于存在噪聲,參數不可能達到到原始函數的值。
現在我們能夠使用  來進行預測:
```python
>>> X_new = np.array([[0],[2]])
>>> X_new_b = np.c_[np.ones((2, 1)), X_new]
>>> y_predict = X_new_b.dot(theta_best)
>>> y_predict
array([[4.21509616],[9.75532293]])
```
畫出這個模型的圖像,如圖 4-2
```python
plt.plot(X_new,y_predict,"r-")
plt.plot(X,y,"b.")
plt.axis([0,2,0,15])
plt.show()
```

圖4-2:線性回歸預測
使用下面的 Scikit-Learn 代碼可以達到相同的效果:
```python
>>> from sklearn.linear_model import LinearRegression
>>> lin_reg = LinearRegression()
>>> lin_reg.fit(X,y)
>>> lin_reg.intercept_, lin_reg.coef_
(array([4.21509616]),array([2.77011339]))
>>> lin_reg.predict(X_new)
array([[4.21509616],[9.75532293]])
```
### 計算復雜度
正規方程需要計算矩陣  的逆,它是一個  的矩陣(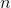 是特征的個數)。這樣一個矩陣求逆的運算復雜度大約在  到  之間,具體值取決于計算方式。換句話說,如果你將你的特征個數翻倍的話,其計算時間大概會變為原來的 5.3()到 8()倍。
> 提示
>
> 當特征的個數較大的時候(例如:特征數量為 100000),正規方程求解將會非常慢。
有利的一面是,這個方程在訓練集上對于每一個實例來說是線性的,其復雜度為 ,因此只要有能放得下它的內存空間,它就可以對大規模數據進行訓練。同時,一旦你得到了線性回歸模型(通過解正規方程或者其他的算法),進行預測是非常快的。因為模型中計算復雜度對于要進行預測的實例數量和特征個數都是線性的。 換句話說,當實例個數變為原來的兩倍多的時候(或特征個數變為原來的兩倍多),預測時間也僅僅是原來的兩倍多。
接下來,我們將介紹另一種方法去訓練模型。這種方法適合在特征個數非常多,訓練實例非常多,內存無法滿足要求的時候使用。
## 梯度下降
梯度下降是一種非常通用的優化算法,它能夠很好地解決一系列問題。梯度下降的整體思路是通過的迭代來逐漸調整參數使得損失函數達到最小值。
假設濃霧下,你迷失在了大山中,你只能感受到自己腳下的坡度。為了最快到達山底,一個最好的方法就是沿著坡度最陡的地方下山。這其實就是梯度下降所做的:它計算誤差函數關于參數向量的局部梯度,同時它沿著梯度下降的方向進行下一次迭代。當梯度值為零的時候,就達到了誤差函數最小值 。
具體來說,開始時,需要選定一個隨機的(這個值稱為隨機初始值),然后逐漸去改進它,每一次變化一小步,每一步都試著降低損失函數(例如:均方差損失函數),直到算法收斂到一個最小值(如圖:4-3)。

圖 4-3:梯度下降
在梯度下降中一個重要的參數是步長,超參數學習率的值決定了步長的大小。如果學習率太小,必須經過多次迭代,算法才能收斂,這是非常耗時的(如圖 4-4)。

圖 4-4:學習率過小
另一方面,如果學習率太大,你將跳過最低點,到達山谷的另一面,可能下一次的值比上一次還要大。這可能使的算法是發散的,函數值變得越來越大,永遠不可能找到一個好的答案(如圖 4-5)。

圖 4-5:學習率過大
最后,并不是所有的損失函數看起來都像一個規則的碗。它們可能是洞,山脊,高原和各種不規則的地形,使它們收斂到最小值非常的困難。 圖 4-6 顯示了梯度下降的兩個主要挑戰:如果隨機初始值選在了圖像的左側,則它將收斂到局部最小值,這個值要比全局最小值要大。 如果它從右側開始,那么跨越高原將需要很長時間,如果你早早地結束訓練,你將永遠到不了全局最小值。

圖 4-6:梯度下降的陷阱
幸運的是線性回歸模型的均方差損失函數是一個凸函數,這意味著如果你選擇曲線上的任意兩點,它們的連線段不會與曲線發生交叉(譯者注:該線段不會與曲線有第三個交點)。這意味著這個損失函數沒有局部最小值,僅僅只有一個全局最小值。同時它也是一個斜率不能突變的連續函數。這兩個因素導致了一個好的結果:梯度下降可以無限接近全局最小值。(只要你訓練時間足夠長,同時學習率不是太大 )。
事實上,損失函數的圖像呈現碗狀,但是不同特征的取值范圍相差較大的時,這個碗可能是細長的。圖 4-7 展示了梯度下降在不同訓練集上的表現。在左圖中,特征 1 和特征 2 有著相同的數值尺度。在右圖中,特征 1 比特征2的取值要小的多,由于特征 1 較小,因此損失函數改變時, 會有較大的變化,于是這個圖像會在軸方向變得細長。

圖 4-7:有無特征縮放的梯度下降
正如你看到的,左面的梯度下降可以直接快速地到達最小值,然而在右面的梯度下降第一次前進的方向幾乎和全局最小值的方向垂直,并且最后到達一個幾乎平坦的山谷,在平坦的山谷走了很長時間。它最終會達到最小值,但它需要很長時間。
> 提示
>
> 當我們使用梯度下降的時候,應該確保所有的特征有著相近的尺度范圍(例如:使用 Scikit Learn 的 `StandardScaler`類),否則它將需要很長的時間才能夠收斂。
這幅圖也表明了一個事實:訓練模型意味著找到一組模型參數,這組參數可以在訓練集上使得損失函數最小。這是對于模型參數空間的搜索,模型的參數越多,參數空間的維度越多,找到合適的參數越困難。例如在300維的空間找到一枚針要比在三維空間里找到一枚針復雜的多。幸運的是線性回歸模型的損失函數是凸函數,這個最優參數一定在碗的底部。
### 批量梯度下降
使用梯度下降的過程中,你需要計算每一個  下損失函數的梯度。換句話說,你需要計算當變化一點點時,損失函數改變了多少。這稱為偏導數,它就像當你面對東方的時候問:"我腳下的坡度是多少?"。然后面向北方的時候問同樣的問題(如果你能想象一個超過三維的宇宙,可以對所有的方向都這樣做)。公式 4-5 計算關于  的損失函數的偏導數,記為 。
公式 4-5: 損失函數的偏導數

為了避免單獨計算每一個梯度,你也可以使用公式 4-6 來一起計算它們。梯度向量記為 ,其包含了損失函數所有的偏導數(每個模型參數只出現一次)。
公式 4-6:損失函數的梯度向量

> 提示
>
> 在這個方程中每一步計算時都包含了整個訓練集 ,這也是為什么這個算法稱為批量梯度下降:每一次訓練過程都使用所有的的訓練數據。因此,在大數據集上,其會變得相當的慢(但是我們接下來將會介紹更快的梯度下降算法)。然而,梯度下降的運算規模和特征的數量成正比。訓練一個數千數量特征的線性回歸模型使用*梯度下降要比使用正規方程快的多。
一旦求得了方向是上山的梯度向量,你就可以向著相反的方向去下山。這意味著從  中減去 。學習率  和梯度向量的積決定了下山時每一步的大小,如公式 4-7。
公式 4-7:梯度下降步長

讓我們看一下這個算法的應用:
```python
eta = 0.1 # 學習率
n_iterations = 1000
m = 100
theta = np.random.randn(2,1) # 隨機初始值
for iteration in range(n_iterations):
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
```
這不是太難,讓我們看一下最后的結果 :
```python
>>> theta
array([[4.21509616],[2.77011339]])
```
看!正規方程的表現非常好。完美地求出了梯度下降的參數。但是當你換一個學習率會發生什么?圖 4-8 展示了使用了三個不同的學習率進行梯度下降的前 10 步運算(虛線代表起始位置)。

圖 4-8:不同學習率的梯度下降
在左面的那副圖中,學習率是最小的,算法幾乎不能求出最后的結果,而且還會花費大量的時間。在中間的這幅圖中,學習率的表現看起來不錯,僅僅幾次迭代后,它就收斂到了最后的結果。在右面的那副圖中,學習率太大了,算法是發散的,跳過了所有的訓練樣本,同時每一步都離正確的結果越來越遠。
為了找到一個好的學習率,你可以使用網格搜索(詳見第二章)。當然,你一般會限制迭代的次數,以便網格搜索可以消除模型需要很長時間才能收斂這一個問題。
你可能想知道如何選取迭代的次數。如果它太小了,當算法停止的時候,你依然沒有找到最優解。如果它太大了,算法會非常的耗時同時后來的迭代參數也不會發生改變。一個簡單的解決方法是:設置一個非常大的迭代次數,但是當梯度向量變得非常小的時候,結束迭代。非常小指的是:梯度向量小于一個值 (稱為容差)。這時候可以認為梯度下降幾乎已經達到了最小值。
> 收斂速率:
>
> 當損失函數是凸函數,同時它的斜率不能突變(就像均方差損失函數那樣),那么它的批量梯度下降算法固定學習率之后,它的收斂速率是 。換句話說,如果你將容差  縮小 10 倍后(這樣可以得到一個更精確的結果),這個算法的迭代次數大約會變成原來的 10 倍。
### 隨機梯度下降
批量梯度下降的最要問題是計算每一步的梯度時都需要使用整個訓練集,這導致在規模較大的數據集上,其會變得非常的慢。與其完全相反的隨機梯度下降,在每一步的梯度計算上只隨機選取訓練集中的一個樣本。很明顯,由于每一次的操作都使用了非常少的數據,這樣使得算法變得非常快。由于每一次迭代,只需要在內存中有一個實例,這使隨機梯度算法可以在大規模訓練集上使用。
另一方面,由于它的隨機性,與批量梯度下降相比,其呈現出更多的不規律性:它到達最小值不是平緩的下降,損失函數會忽高忽低,只是在大體上呈下降趨勢。隨著時間的推移,它會非常的靠近最小值,但是它不會停止在一個值上,它會一直在這個值附近擺動(如圖 4-9)。因此,當算法停止的時候,最后的參數還不錯,但不是最優值。

圖4-9:隨機梯度下降
當損失函數很不規則時(如圖 4-6),隨機梯度下降算法能夠跳過局部最小值。因此,隨機梯度下降在尋找全局最小值上比批量梯度下降表現要好。
雖然隨機性可以很好的跳過局部最優值,但同時它卻不能達到最小值。解決這個難題的一個辦法是逐漸降低學習率。 開始時,走的每一步較大(這有助于快速前進同時跳過局部最小值),然后變得越來越小,從而使算法到達全局最小值。 這個過程被稱為模擬退火,因為它類似于熔融金屬慢慢冷卻的冶金學退火過程。 決定每次迭代的學習率的函數稱為`learning schedule`。 如果學習速度降低得過快,你可能會陷入局部最小值,甚至在到達最小值的半路就停止了。 如果學習速度降低得太慢,你可能在最小值的附近長時間擺動,同時如果過早停止訓練,最終只會出現次優解。
下面的代碼使用一個簡單的`learning schedule`來實現隨機梯度下降:
```python
n_epochs = 50
t0, t1 = 5, 50 #learning_schedule的超參數
def learning_schedule(t):
return t0 / (t + t1)
theta = np.random.randn(2,1)
for epoch in range(n_epochs):
for i in range(m):
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2 * xi.T.dot(xi.dot(theta)-yi)
eta = learning_schedule(epoch * m + i)
theta = theta - eta * gradients
```
按習慣來講,我們進行 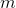 輪的迭代,每一輪迭代被稱為一代。在整個訓練集上,隨機梯度下降迭代了 1000 次時,一般在第 50 次的時候就可以達到一個比較好的結果。
```python
>>> theta
array([[4.21076011],[2.748560791]])
```
圖 4-10 展示了前 10 次的訓練過程(注意每一步的不規則程度)。

圖 4-10:隨機梯度下降的前10次迭代
由于每個實例的選擇是隨機的,有的實例可能在每一代中都被選到,這樣其他的實例也可能一直不被選到。如果你想保證每一代迭代過程,算法可以遍歷所有實例,一種方法是將訓練集打亂重排,然后選擇一個實例,之后再繼續打亂重排,以此類推一直進行下去。但是這樣收斂速度會非常的慢。
通過使用 Scikit-Learn 完成線性回歸的隨機梯度下降,你需要使用`SGDRegressor`類,這個類默認優化的是均方差損失函數。下面的代碼迭代了 50 代,其學習率  為0.1(`eta0=0.1`),使用默認的`learning schedule`(與前面的不一樣),同時也沒有添加任何正則項(`penalty = None`):
```python
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(n_iter=50, penalty=None, eta0=0.1)
sgd_reg.fit(X,y.ravel())
```
你可以再一次發現,這個結果非常的接近正規方程的解:
```
>>> sgd_reg.intercept_, sgd_reg.coef_
(array([4.18380366]),array([2.74205299]))
```
### 小批量梯度下降
最后一個梯度下降算法,我們將介紹小批量梯度下降算法。一旦你理解了批量梯度下降和隨機梯度下降,再去理解小批量梯度下降是非常簡單的。在迭代的每一步,批量梯度使用整個訓練集,隨機梯度時候用僅僅一個實例,在小批量梯度下降中,它則使用一個隨機的小型實例集。它比隨機梯度的主要優點在于你可以通過矩陣運算的硬件優化得到一個較好的訓練表現,尤其當你使用 GPU 進行運算的時候。
小批量梯度下降在參數空間上的表現比隨機梯度下降要好的多,尤其在有大量的小型實例集時。作為結果,小批量梯度下降會比隨機梯度更靠近最小值。但是,另一方面,它有可能陷在局部最小值中(在遇到局部最小值問題的情況下,和我們之前看到的線性回歸不一樣)。 圖4-11顯示了訓練期間三種梯度下降算法在參數空間中所采用的路徑。 他們都接近最小值,但批量梯度的路徑最后停在了最小值,而隨機梯度和小批量梯度最后都在最小值附近擺動。 但是,不要忘記,批量梯度需要花費大量時間來完成每一步,但是,如果你使用了一個較好的`learning schedule`,隨機梯度和小批量梯度也可以得到最小值。

圖 4-11:參數空間的梯度下降路徑
讓我比較一下目前我們已經探討過的對線性回歸的梯度下降算法。如表 4-1 所示,其中 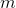 表示訓練樣本的個數,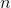 表示特征的個數。
表 4-1:比較線性回歸的不同梯度下降算法

> 提示
>
> 上述算法在完成訓練后,得到的參數基本沒什么不同,它們會得到非常相似的模型,最后會以一樣的方式去進行預測。
## 多項式回歸
如果你的數據實際上比簡單的直線更復雜呢? 令人驚訝的是,你依然可以使用線性模型來擬合非線性數據。 一個簡單的方法是對每個特征進行加權后作為新的特征,然后訓練一個線性模型在這個擴展的特征集。 這種方法稱為多項式回歸。
讓我們看一個例子。 首先,我們根據一個簡單的二次方程(并加上一些噪聲,如圖 4-12)來生成一些非線性數據:
```python
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 0.5 * X**2 + X + 2 + np.random.randn(m, 1)
```

圖 4-12:生產加入噪聲的非線性數據
很清楚的看出,直線不能恰當的擬合這些數據。于是,我們使用 Scikit-Learning 的`PolynomialFeatures`類進行訓練數據集的轉換,讓訓練集中每個特征的平方(2 次多項式)作為新特征(在這種情況下,僅存在一個特征):
```python
>>> from sklearn.preprocessing import PolynomialFeatures
>>> poly_features = PolynomialFeatures(degree=2,include_bias=False)
>>> X_poly = poly_features.fit_transform(X)
>>> X[0]
array([-0.75275929])
>>> X_poly[0]
array([-0.75275929, 0.56664654])
```
`X_poly`現在包含原始特征并加上了這個特征的平方 。現在你可以在這個擴展訓練集上使用`LinearRegression`模型進行擬合,如圖 4-13:
```python
>>> lin_reg = LinearRegression()
>>> lin_reg.fit(X_poly, y)
>>> lin_reg.intercept_, lin_reg.coef_
(array([ 1.78134581]), array([[ 0.93366893, 0.56456263]]))
```

圖 4-13:多項式回歸模型預測
還是不錯的,模型預測函數 ,事實上原始函數為  再加上一些高斯噪聲。
請注意,當存在多個特征時,多項式回歸能夠找出特征之間的關系(這是普通線性回歸模型無法做到的)。 這是因為`LinearRegression`會自動添加當前階數下特征的所有組合。例如,如果有兩個特征 ,使用 3 階(`degree=3`)的`LinearRegression`時,不僅有  以及 ,同時也會有它們的其他組合項 。
> 提示
>
> `PolynomialFeatures(degree=d)`把一個包含 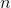 個特征的數組轉換為一個包含  特征的數組, 表示 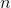 的階乘,等于 。小心大量特征的組合爆炸!
## 學習曲線
如果你使用一個高階的多項式回歸,你可能發現它的擬合程度要比普通的線性回歸要好的多。例如,圖 4-14 使用一個 300 階的多項式模型去擬合之前的數據集,并同簡單線性回歸、2 階的多項式回歸進行比較。注意 300 階的多項式模型如何擺動以盡可能接近訓練實例。

圖 4-14:高階多項式回歸
當然,這種高階多項式回歸模型在這個訓練集上嚴重過擬合了,線性模型則欠擬合。在這個訓練集上,二次模型有著較好的泛化能力。那是因為在生成數據時使用了二次模型,但是一般我們不知道這個數據生成函數是什么,那我們該如何決定我們模型的復雜度呢?你如何告訴我你的模型是過擬合還是欠擬合?
在第二章,你可以使用交叉驗證來估計一個模型的泛化能力。如果一個模型在訓練集上表現良好,通過交叉驗證指標卻得出其泛化能力很差,那么你的模型就是過擬合了。如果在這兩方面都表現不好,那么它就是欠擬合了。這種方法可以告訴我們,你的模型是太復雜還是太簡單了。
另一種方法是觀察學習曲線:畫出模型在訓練集上的表現,同時畫出以訓練集規模為自變量的訓練集函數。為了得到圖像,需要在訓練集的不同規模子集上進行多次訓練。下面的代碼定義了一個函數,用來畫出給定訓練集后的模型學習曲線:
```python
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def plot_learning_curves(model, X, y):
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
train_errors, val_errors = [], []
for m in range(1, len(X_train)):
model.fit(X_train[:m], y_train[:m])
y_train_predict = model.predict(X_train[:m])
y_val_predict = model.predict(X_val)
train_errors.append(mean_squared_error(y_train_predict, y_train[:m]))
val_errors.append(mean_squared_error(y_val_predict, y_val))
plt.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="train")
plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")
```
我們一起看一下簡單線性回歸模型的學習曲線(圖 4-15):
```python
lin_reg = LinearRegression()
plot_learning_curves(lin_reg, X, y)
```

圖 4-15:學習曲線
這幅圖值得我們深究。首先,我們觀察訓練集的表現:當訓練集只有一兩個樣本的時候,模型能夠非常好的擬合它們,這也是為什么曲線是從零開始的原因。但是當加入了一些新的樣本的時候,訓練集上的擬合程度變得難以接受,出現這種情況有兩個原因,一是因為數據中含有噪聲,另一個是數據根本不是線性的。因此隨著數據規模的增大,誤差也會一直增大,直到達到高原地帶并趨于穩定,在之后,繼續加入新的樣本,模型的平均誤差不會變得更好或者更差。我們繼續來看模型在驗證集上的表現,當以非常少的樣本去訓練時,模型不能恰當的泛化,也就是為什么驗證誤差一開始是非常大的。當訓練樣本變多的到時候,模型學習的東西變多,驗證誤差開始緩慢的下降。但是一條直線不可能很好的擬合這些數據,因此最后誤差會到達在一個高原地帶并趨于穩定,最后和訓練集的曲線非常接近。
上面的曲線表現了一個典型的欠擬合模型,兩條曲線都到達高原地帶并趨于穩定,并且最后兩條曲線非常接近,同時誤差值非常大。
> 提示
>
> 如果你的模型在訓練集上是欠擬合的,添加更多的樣本是沒用的。你需要使用一個更復雜的模型或者找到更好的特征。
現在讓我們看一個在相同數據上10階多項式模型擬合的學習曲線(圖 4-16):
```python
from sklearn.pipeline import Pipeline
polynomial_regression = Pipeline((
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("sgd_reg", LinearRegression()),
))
plot_learning_curves(polynomial_regression, X, y)
```
這幅圖像和之前的有一點點像,但是其有兩個非常重要的不同點:
+ 在訓練集上,誤差要比線性回歸模型低的多。
+ 圖中的兩條曲線之間有間隔,這意味模型在訓練集上的表現要比驗證集上好的多,這也是模型過擬合的顯著特點。當然,如果你使用了更大的訓練數據,這兩條曲線最后會非常的接近。

圖4-16:多項式模型的學習曲線
> 提示
>
> 改善模型過擬合的一種方法是提供更多的訓練數據,直到訓練誤差和驗證誤差相等。
> 偏差和方差的權衡
>
> 在統計和機器學習領域有個重要的理論:一個模型的泛化誤差由三個不同誤差的和決定:
>
> + 偏差:泛化誤差的這部分誤差是由于錯誤的假設決定的。例如實際是一個二次模型,你卻假設了一個線性模型。一個高偏差的模型最容易出現欠擬合。
> + 方差:這部分誤差是由于模型對訓練數據的微小變化較為敏感,一個多自由度的模型更容易有高的方差(例如一個高階多項式模型),因此會導致模型過擬合。
> + 不可約誤差:這部分誤差是由于數據本身的噪聲決定的。降低這部分誤差的唯一方法就是進行數據清洗(例如:修復數據源,修復壞的傳感器,識別和剔除異常值)。
## 線性模型的正則化
正如我們在第一和第二章看到的那樣,降低模型的過擬合的好方法是正則化這個模型(即限制它):模型有越少的自由度,就越難以擬合數據。例如,正則化一個多項式模型,一個簡單的方法就是減少多項式的階數。
對于一個線性模型,正則化的典型實現就是約束模型中參數的權重。 接下來我們將介紹三種不同約束權重的方法:Ridge 回歸,Lasso 回歸和 Elastic Net。
### 嶺(Ridge)回歸
嶺回歸(也稱為 Tikhonov 正則化)是線性回歸的正則化版:在損失函數上直接加上一個正則項 。這使得學習算法不僅能夠擬合數據,而且能夠使模型的參數權重盡量的小。注意到這個正則項只有在訓練過程中才會被加到損失函數。當得到完成訓練的模型后,我們應該使用沒有正則化的測量方法去評價模型的表現。
> 提示
>
> 一般情況下,訓練過程使用的損失函數和測試過程使用的評價函數是不一樣的。除了正則化,還有一個不同:訓練時的損失函數應該在優化過程中易于求導,而在測試過程中,評價函數更應該接近最后的客觀表現。一個好的例子:在分類訓練中我們使用對數損失(馬上我們會討論它)作為損失函數,但是我們卻使用精確率/召回率來作為它的評價函數。
超參數  決定了你想正則化這個模型的強度。如果  那此時的嶺回歸便變為了線性回歸。如果  非常的大,所有的權重最后都接近于零,最后結果將是一條穿過數據平均值的水平直線。公式 4-8 是嶺回歸的損失函數:
公式 4-8:嶺回歸損失函數

值得注意的是偏差  是沒有被正則化的(累加運算的開始是  而不是 )。如我定義  作為特征的權重向量( 到 ),那么正則項可以簡寫成 ,其中  表示權重向量的 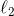 范數。對于梯度下降來說僅僅在均方差梯度向量(公式 4-6)加上一項 。
> 提示
>
> 在使用嶺回歸前,對數據進行放縮(可以使用`StandardScaler`)是非常重要的,算法對于輸入特征的數值尺度(scale)非常敏感。大多數的正則化模型都是這樣的。
圖 4-17 展示了在相同線性數據上使用不同  值的嶺回歸模型最后的表現。左圖中,使用簡單的嶺回歸模型,最后得到了線性的預測。右圖中的數據首先使用 10 階的`PolynomialFearures`進行擴展,然后使用`StandardScaler`進行縮放,最后將嶺模型應用在處理過后的特征上。這就是帶有嶺正則項的多項式回歸。注意當增大的時候,導致預測曲線變得扁平(即少了極端值,多了一般值),這樣減少了模型的方差,卻增加了模型的偏差。
對線性回歸來說,對于嶺回歸,我們可以使用封閉方程去計算,也可以使用梯度下降去處理。它們的缺點和優點是一樣的。公式 4-9 表示封閉方程的解(矩陣  是一個除了左上角有一個 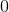 的  的單位矩,這個 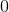 代表偏差項。譯者注:偏差  不被正則化的)。

圖 4-17:嶺回歸
公式 4-9:嶺回歸的封閉方程的解

下面是如何使用 Scikit-Learn 來進行封閉方程的求解(使用 Cholesky 法進行矩陣分解對公式 4-9 進行變形):
```python
>>> from sklearn.linear_model import Ridge
>>> ridge_reg = Ridge(alpha=1, solver="cholesky")
>>> ridge_reg.fit(X, y)
>>> ridge_reg.predict([[1.5]])
array([[ 1.55071465]]
```
使用隨機梯度法進行求解:
```python
>>> sgd_reg = SGDRegressor(penalty="l2")
>>> sgd_reg.fit(X, y.ravel())
>>> sgd_reg.predict([[1.5]])
array([[ 1.13500145]])
```
`penalty`參數指的是正則項的懲罰類型。指定“l2”表明你要在損失函數上添加一項:權重向量 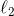 范數平方的一半,這就是簡單的嶺回歸。
### Lasso 回歸
Lasso 回歸(也稱 Least Absolute Shrinkage,或者 Selection Operator Regression)是另一種正則化版的線性回歸:就像嶺回歸那樣,它也在損失函數上添加了一個正則化項,但是它使用權重向量的  范數而不是權重向量 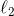 范數平方的一半。(如公式 4-10)
公式 4-10:Lasso 回歸的損失函數

圖 4-18 展示了和圖 4-17 相同的事情,僅僅是用 Lasso 模型代替了 Ridge 模型,同時調小了  的值。

圖 4-18:Lasso回歸
Lasso 回歸的一個重要特征是它傾向于完全消除最不重要的特征的權重(即將它們設置為零)。例如,右圖中的虛線所示(),曲線看起來像一條二次曲線,而且幾乎是線性的,這是因為所有的高階多項特征都被設置為零。換句話說,Lasso回歸自動的進行特征選擇同時輸出一個稀疏模型(即,具有很少的非零權重)。
你可以從圖 4-19 知道為什么會出現這種情況:在左上角圖中,后背景的等高線(橢圓)表示了沒有正則化的均方差損失函數(),白色的小圓圈表示在當前損失函數上批量梯度下降的路徑。前背景的等高線(菱形)表示懲罰,黃色的三角形表示了僅在這個懲罰下批量梯度下降的路徑()。注意路徑第一次是如何到達 ,然后向下滾動直到它到達 。在右上角圖中,等高線表示的是相同損失函數再加上一個  的  懲罰。這幅圖中,它的全局最小值在  這根軸上。批量梯度下降首先到達 ,然后向下滾動直到達到全局最小值。 兩個底部圖顯示了相同的情況,只是使用了 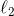 懲罰。 規則化的最小值比非規范化的最小值更接近于 ,但權重不能完全消除。

圖 4-19:Ridge 回歸和 Lasso 回歸對比
> 提示
>
> 在 Lasso 損失函數中,批量梯度下降的路徑趨向與在低谷有一個反彈。這是因為在  時斜率會有一個突變。為了最后真正收斂到全局最小值,你需要逐漸的降低學習率。
Lasso 損失函數在  處無法進行微分運算,但是梯度下降如果你使用子梯度向量  后它可以在任何  的情況下進行計算。公式 4-11 是在 Lasso 損失函數上進行梯度下降的子梯度向量公式。
公式 4-11:Lasso 回歸子梯度向量

下面是一個使用 Scikit-Learn 的`Lasso`類的小例子。你也可以使用`SGDRegressor(penalty="l1")`來代替它。
```python
>>> from sklearn.linear_model import Lasso
>>> lasso_reg = Lasso(alpha=0.1)
>>> lasso_reg.fit(X, y)
>>> lasso_reg.predict([[1.5]])
array([ 1.53788174]
```
### 彈性網絡(ElasticNet)
彈性網絡介于 Ridge 回歸和 Lasso 回歸之間。它的正則項是 Ridge 回歸和 Lasso 回歸正則項的簡單混合,同時你可以控制它們的混合率 ,當 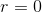 時,彈性網絡就是 Ridge 回歸,當  時,其就是 Lasso 回歸。具體表示如公式 4-12。
公式 4-12:彈性網絡損失函數

那么我們該如何選擇線性回歸,嶺回歸,Lasso 回歸,彈性網絡呢?一般來說有一點正則項的表現更好,因此通常你應該避免使用簡單的線性回歸。嶺回歸是一個很好的首選項,但是如果你的特征僅有少數是真正有用的,你應該選擇 Lasso 和彈性網絡。就像我們討論的那樣,它兩能夠將無用特征的權重降為零。一般來說,彈性網絡的表現要比 Lasso 好,因為當特征數量比樣本的數量大的時候,或者特征之間有很強的相關性時,Lasso 可能會表現的不規律。下面是一個使用 Scikit-Learn `ElasticNet`(`l1_ratio`指的就是混合率 )的簡單樣本:
```python
>>> from sklearn.linear_model import ElasticNet
>>> elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
>>> elastic_net.fit(X, y)
>>> elastic_net.predict([[1.5]])
array([ 1.54333232])
```
### 早期停止法(Early Stopping)
對于迭代學習算法,有一種非常特殊的正則化方法,就像梯度下降在驗證錯誤達到最小值時立即停止訓練那樣。我們稱為早期停止法。圖 4-20 表示使用批量梯度下降來訓練一個非常復雜的模型(一個高階多項式回歸模型)。隨著訓練的進行,算法一直學習,它在訓練集上的預測誤差(RMSE)自然而然的下降。然而一段時間后,驗證誤差停止下降,并開始上升。這意味著模型在訓練集上開始出現過擬合。一旦驗證錯誤達到最小值,便提早停止訓練。這種簡單有效的正則化方法被 Geoffrey Hinton 稱為“完美的免費午餐”

圖 4-20:早期停止法
> 提示
>
> 隨機梯度和小批量梯度下降不是平滑曲線,你可能很難知道它是否達到最小值。 一種解決方案是,只有在驗證誤差高于最小值一段時間后(你確信該模型不會變得更好了),才停止,之后將模型參數回滾到驗證誤差最小值。
下面是一個早期停止法的基礎應用:
```python
from sklearn.base import clone
sgd_reg = SGDRegressor(n_iter=1, warm_start=True, penalty=None,learning_rate="constant", eta0=0.0005)
minimum_val_error = float("inf")
best_epoch = None
best_model = None
for epoch in range(1000):
sgd_reg.fit(X_train_poly_scaled, y_train)
y_val_predict = sgd_reg.predict(X_val_poly_scaled)
val_error = mean_squared_error(y_val_predict, y_val)
if val_error < minimum_val_error:
minimum_val_error = val_error
best_epoch = epoch
best_model = clone(sgd_reg)
```
注意:當`warm_start=True`時,調用`fit()`方法后,訓練會從停下來的地方繼續,而不是從頭重新開始。
## 邏輯回歸
正如我們在第1章中討論的那樣,一些回歸算法也可以用于分類(反之亦然)。 Logistic 回歸(也稱為 Logit 回歸)通常用于估計一個實例屬于某個特定類別的概率(例如,這電子郵件是垃圾郵件的概率是多少?)。 如果估計的概率大于 50%,那么模型預測這個實例屬于當前類(稱為正類,標記為“1”),反之預測它不屬于當前類(即它屬于負類 ,標記為“0”)。 這樣便成為了一個二元分類器。
### 概率估計
那么它是怎樣工作的? 就像線性回歸模型一樣,Logistic 回歸模型計算輸入特征的加權和(加上偏差項),但它不像線性回歸模型那樣直接輸出結果,而是把結果輸入`logistic()`函數進行二次加工后進行輸出(詳見公式 4-13)。
公式 4-13:邏輯回歸模型的概率估計(向量形式)

Logistic 函數(也稱為 logit),用  表示,其是一個 sigmoid 函數(圖像呈 S 型),它的輸出是一個介于 0 和 1 之間的數字。其定義如公式 4-14 和圖 4-21 所示。
公式 4-14:邏輯函數


圖4-21:邏輯函數
一旦 Logistic 回歸模型估計得到了 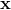 屬于正類的概率 ,那它很容易得到預測結果 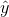(見公式 4-15)。
公式 4-15:邏輯回歸預測模型

注意當  時 ,當 時,因此當 是正數的話,邏輯回歸模型輸出 1,如果它是負數的話,則輸出 0。
### 訓練和損失函數
好,現在你知道了 Logistic 回歸模型如何估計概率并進行預測。 但是它是如何訓練的? 訓練的目的是設置參數向量 ,使得正例()概率增大,負例()的概率減小,其通過在單個訓練實例 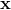 的損失函數來實現(公式 4-16)。
公式 4-16:單個樣本的損失函數

這個損失函數是合理的,因為當  接近 0 時,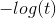 變得非常大,所以如果模型估計一個正例概率接近于 0,那么損失函數將會很大,同時如果模型估計一個負例的概率接近 1,那么損失函數同樣會很大。 另一方面,當  接近于 1 時,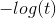 接近 0,所以如果模型估計一個正例概率接近于 0,那么損失函數接近于 0,同時如果模型估計一個負例的概率接近 0,那么損失函數同樣會接近于 0, 這正是我們想的。
整個訓練集的損失函數只是所有訓練實例的平均值。可以用一個表達式(你可以很容易證明)來統一表示,稱為對數損失,如公式 4-17 所示。
公式 4-17:邏輯回歸的損失函數(對數損失)
![J(\theta)=-\frac{1}{m}\sum\limits_{i=1}^m\left[y^{(i)}log\left(\hat{p}^{(i)}\right)+\left(1-y^{(i)}\right)log\left(1-\hat{p}^{(i)}\right)\right]](https://img.kancloud.cn/cc/10/cc105350a3e398e64a8d1fa95ca38d98_424x51.gif)
但是這個損失函數對于求解最小化損失函數的  是沒有公式解的(沒有等價的正規方程)。 但好消息是,這個損失函數是凸的,所以梯度下降(或任何其他優化算法)一定能夠找到全局最小值(如果學習速率不是太大,并且你等待足夠長的時間)。公式 4-18 給出了損失函數關于第 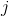 個模型參數  的偏導數。
公式 4-18:邏輯回歸損失函數的偏導數

這個公式看起來非常像公式 4-5:首先計算每個樣本的預測誤差,然后誤差項乘以第 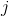 項特征值,最后求出所有訓練樣本的平均值。 一旦你有了包含所有的偏導數的梯度向量,你便可以在梯度向量上使用批量梯度下降算法。 也就是說:你已經知道如何訓練 Logistic 回歸模型。 對于隨機梯度下降,你當然只需要每一次使用一個實例,對于小批量梯度下降,你將每一次使用一個小型實例集。
### 決策邊界
我們使用鳶尾花數據集來分析 Logistic 回歸。 這是一個著名的數據集,其中包含 150 朵三種不同的鳶尾花的萼片和花瓣的長度和寬度。這三種鳶尾花為:Setosa,Versicolor,Virginica(如圖 4-22)。

圖4-22:三種不同的鳶尾花
讓我們嘗試建立一個分類器,僅僅使用花瓣的寬度特征來識別 Virginica,首先讓我們加載數據:
```python
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> list(iris.keys())
['data', 'target_names', 'feature_names', 'target', 'DESCR']
>>> X = iris["data"][:, 3:] # petal width
>>> y = (iris["target"] == 2).astype(np.int)
```
接下來,我們訓練一個邏輯回歸模型:
```python
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X, y)
```
我們來看看模型估計的花瓣寬度從 0 到 3 厘米的概率估計(如圖 4-23):
```python
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
y_proba = log_reg.predict_proba(X_new)
plt.plot(X_new, y_proba[:, 1], "g-", label="Iris-Virginica")
plt.plot(X_new, y_proba[:, 0], "b--", label="Not Iris-Virginica")
```

圖 4-23:概率估計和決策邊界
Virginica 花的花瓣寬度(用三角形表示)在 1.4 厘米到 2.5 厘米之間,而其他種類的花(由正方形表示)通常具有較小的花瓣寬度,范圍從 0.1 厘米到 1.8 厘米。注意,它們之間會有一些重疊。在大約 2 厘米以上時,分類器非常肯定這朵花是Virginica花(分類器此時輸出一個非常高的概率值),而在1厘米以下時,它非常肯定這朵花不是 Virginica 花(不是 Virginica 花有非常高的概率)。在這兩個極端之間,分類器是不確定的。但是,如果你使用它進行預測(使用`predict()`方法而不是`predict_proba()`方法),它將返回一個最可能的結果。因此,在 1.6 厘米左右存在一個決策邊界,這時兩類情況出現的概率都等于 50%:如果花瓣寬度大于 1.6 厘米,則分類器將預測該花是 Virginica,否則預測它不是(即使它有可能錯了):
```python
>>> log_reg.predict([[1.7], [1.5]])
array([1, 0])
```
圖 4-24 表示相同的數據集,但是這次使用了兩個特征進行判斷:花瓣的寬度和長度。 一旦訓練完畢,Logistic 回歸分類器就可以根據這兩個特征來估計一朵花是 Virginica 的可能性。 虛線表示這時兩類情況出現的概率都等于 50%:這是模型的決策邊界。 請注意,它是一個線性邊界。每條平行線都代表一個分類標準下的兩兩個不同類的概率,從 15%(左下角)到 90%(右上角)。越過右上角分界線的點都有超過 90% 的概率是 Virginica 花。

圖 4-24:線性決策邊界
就像其他線性模型,邏輯回歸模型也可以  或者 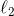 懲罰使用進行正則化。Scikit-Learn 默認添加了 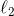 懲罰。
> 注意
>
> 在 Scikit-Learn 的`LogisticRegression`模型中控制正則化強度的超參數不是 (與其他線性模型一樣),而是它的逆: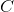。 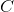 的值越大,模型正則化強度越低。
### Softmax 回歸
Logistic 回歸模型可以直接推廣到支持多類別分類,不必組合和訓練多個二分類器(如第 3 章所述), 其稱為 Softmax 回歸或多類別 Logistic 回歸。
這個想法很簡單:當給定一個實例 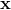 時,Softmax 回歸模型首先計算  類的分數 ,然后將分數應用在`Softmax `函數(也稱為歸一化指數)上,估計出每類的概率。 計算  的公式看起來很熟悉,因為它就像線性回歸預測的公式一樣(見公式 4-19)。
公式 4-19:`k`類的 Softmax 得分

注意,每個類都有自己獨一無二的參數向量 。 所有這些向量通常作為行放在參數矩陣 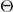 中。
一旦你計算了樣本 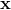 的每一類的得分,你便可以通過`Softmax`函數(公式 4-20)估計出樣本屬于第  類的概率 :通過計算  的  次方,然后對它們進行歸一化(除以所有分子的總和)。
公式 4-20:Softmax 函數

+ 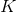 表示有多少類
+  表示包含樣本 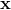 每一類得分的向量
+  表示給定每一類分數之后,實例 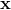 屬于第  類的概率
和 Logistic 回歸分類器一樣,Softmax 回歸分類器將估計概率最高(它只是得分最高的類)的那類作為預測結果,如公式 4-21 所示。
公式 4-21:Softmax 回歸模型分類器預測結果

+ `argmax`運算返回一個函數取到最大值的變量值。 在這個等式,它返回使  最大時的  的值
> 注意
>
> Softmax 回歸分類器一次只能預測一個類(即它是多類的,但不是多輸出的),因此它只能用于判斷互斥的類別,如不同類型的植物。 你不能用它來識別一張照片中的多個人。
現在我們知道這個模型如何估計概率并進行預測,接下來將介紹如何訓練。我們的目標是建立一個模型在目標類別上有著較高的概率(因此其他類別的概率較低),最小化公式 4-22 可以達到這個目標,其表示了當前模型的損失函數,稱為交叉熵,當模型對目標類得出了一個較低的概率,其會懲罰這個模型。 交叉熵通常用于衡量待測類別與目標類別的匹配程度(我們將在后面的章節中多次使用它)
公式 4-22:交叉熵

+ 如果對于第 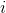 個實例的目標類是 ,那么 ,反之 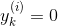。
可以看出,當只有兩個類()時,此損失函數等同于 Logistic 回歸的損失函數(對數損失;請參閱公式 4-17)。
> 交叉熵
>
> 交叉熵源于信息論。假設你想要高效地傳輸每天的天氣信息。如果有八個選項(晴天,雨天等),則可以使用3位對每個選項進行編碼,因為 。但是,如果你認為幾乎每天都是晴天,更高效的編碼“晴天”的方式是:只用一位(0)。剩下的七項使用四位(從 1 開始)。交叉熵度量每個選項實際發送的平均比特數。 如果你對天氣的假設是完美的,交叉熵就等于天氣本身的熵(即其內部的不確定性)。 但是,如果你的假設是錯誤的(例如,如果經常下雨)交叉熵將會更大,稱為 Kullback-Leibler 散度(KL 散度)。
>
> 兩個概率分布 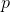 和 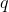 之間的交叉熵定義為:(分布至少是離散的)
這個損失函數關于  的梯度向量為公式 4-23:
公式 4-23:`k`類交叉熵的梯度向量

現在你可以計算每一類的梯度向量,然后使用梯度下降(或者其他的優化算法)找到使得損失函數達到最小值的參數矩陣 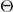。
讓我們使用 Softmax 回歸對三種鳶尾花進行分類。當你使用`LogisticRregression`對模型進行訓練時,Scikit Learn 默認使用的是一對多模型,但是你可以設置`multi_class`參數為“multinomial”來把它改變為 Softmax 回歸。你還必須指定一個支持 Softmax 回歸的求解器,例如“lbfgs”求解器(有關更多詳細信息,請參閱 Scikit-Learn 的文檔)。其默認使用 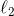 正則化,你可以使用超參數 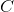 控制它。
```python
X = iris["data"][:, (2, 3)] # petal length, petal width
y = iris["target"]
softmax_reg = LogisticRegression(multi_class="multinomial",solver="lbfgs", C=10)
softmax_reg.fit(X, y)
```
所以下次你發現一個花瓣長為 5 厘米,寬為 2 厘米的鳶尾花時,你可以問你的模型你它是哪一類鳶尾花,它會回答 94.2% 是 Virginica 花(第二類),或者 5.8% 是其他鳶尾花。
```python
>>> softmax_reg.predict([[5, 2]])
array([2])
>>> softmax_reg.predict_proba([[5, 2]])
array([[ 6.33134078e-07, 5.75276067e-02, 9.42471760e-01]])是
```

圖 4-25:Softmax 回歸的決策邊界
圖 4-25 用不同背景色表示了結果的決策邊界。注意,任何兩個類之間的決策邊界是線性的。 該圖的曲線表示 Versicolor 類的概率(例如,用 0.450 標記的曲線表示 45% 的概率邊界)。注意模型也可以預測一個概率低于 50% 的類。 例如,在所有決策邊界相遇的地方,所有類的估計概率相等,分別為 33%。
## 練習
1. 如果你有一個數百萬特征的訓練集,你應該選擇哪種線性回歸訓練算法?
2. 假設你訓練集中特征的數值尺度(scale)有著非常大的差異,哪種算法會受到影響?有多大的影響?對于這些影響你可以做什么?
3. 訓練 Logistic 回歸模型時,梯度下降是否會陷入局部最低點?
4. 在有足夠的訓練時間下,是否所有的梯度下降都會得到相同的模型參數?
5. 假設你使用批量梯度下降法,畫出每一代的驗證誤差。當你發現驗證誤差一直增大,接下來會發生什么?你怎么解決這個問題?
6. 當驗證誤差升高時,立即停止小批量梯度下降是否是一個好主意?
7. 哪個梯度下降算法(在我們討論的那些算法中)可以最快到達解的附近?哪個的確實會收斂?怎么使其他算法也收斂?
8. 假設你使用多項式回歸,畫出學習曲線,在圖上發現學習誤差和驗證誤差之間有著很大的間隙。這表示發生了什么?有哪三種方法可以解決這個問題?
9. 假設你使用嶺回歸,并發現訓練誤差和驗證誤差都很高,并且幾乎相等。你的模型表現是高偏差還是高方差?這時你應該增大正則化參數 ,還是降低它?
10. 你為什么要這樣做:
+ 使用嶺回歸代替線性回歸?
+ Lasso 回歸代替嶺回歸?
+ 彈性網絡代替 Lasso 回歸?
11. 假設你想判斷一副圖片是室內還是室外,白天還是晚上。你應該選擇二個邏輯回歸分類器,還是一個 Softmax 分類器?
12. 在 Softmax 回歸上應用批量梯度下降的早期停止法(不使用 Scikit-Learn)。
附錄 A 提供了這些練習的答案。
