# 十五、自編碼器
> 譯者:[@akonwang](https://github.com/wangxupeng)
>
> 校對者:[@飛龍](https://github.com/wizardforcel)、[@yanmengk](https://github.com/yanmengk)
自編碼器是能夠在無監督的情況下學習輸入數據的有效表示(叫做編碼)的人工神經網絡(即,訓練集是未標記)。這些編碼通常具有比輸入數據低得多的維度,使得自編碼器對降維有用(參見第 8 章)。更重要的是,自編碼器可以作為強大的特征檢測器,它們可以用于無監督的深度神經網絡預訓練(正如我們在第 11 章中討論過的)。最后,他們能夠隨機生成與訓練數據非常相似的新數據;這被稱為生成模型。例如,您可以在臉部圖片上訓練自編碼器,然后可以生成新臉部。
令人驚訝的是,自編碼器只需學習將輸入復制到其輸出即可工作。 這聽起來像是一件小事,但我們會看到以各種方式約束網絡可能會讓它變得相當困難。例如,您可以限制內部表示的大小,或者可以向輸入添加噪聲并訓練網絡以恢復原始輸入。這些約束防止自編碼器將輸入直接復制到輸出,這迫使它學習表示數據的有效方法。 簡言之,編碼是自編碼器在某些限制條件下嘗試學習恒等函數的副產品。
在本章中,我們將更深入地解釋自編碼器如何工作,可以施加什么類型的約束以及如何使用 TensorFlow 實現它們,無論是用來降維,特征提取,無監督預訓練還是作為生成式模型。
## 有效的數據表示
您發現以下哪一個數字序列最容易記憶?
* `40, 27, 25, 36, 81, 57, 10, 73, 19, 68`
* `50, 25, 76, 38, 19, 58, 29, 88, 44, 22, 11, 34, 17, 52, 26, 13, 40, 20`
乍一看,第一個序列似乎應該更容易,因為它要短得多。 但是,如果仔細觀察第二個序列,則可能會注意到它遵循兩條簡單規則:偶數是前面數的一半,奇數是前面數的三倍加一(這是一個著名的序列,稱為雹石序列)。一旦你注意到這種模式,第二個序列比第一個更容易記憶,因為你只需要記住兩個規則,第一個數字和序列的長度。 請注意,如果您可以快速輕松地記住非常長的序列,則您不會在意第二個序列中存在的模式。 你只需要了解每一個數字,就是這樣。 事實上,很難記住長序列,因此識別模式非常有用,并且希望能夠澄清為什么在訓練過程中限制自編碼器會促使它發現并利用數據中的模式。
記憶,感知和模式匹配之間的關系在 20 世紀 70 年代早期由 William Chase 和 Herbert Simon 著名研究。 他們觀察到,專家棋手能夠通過觀看棋盤5秒鐘來記憶所有棋子的位置,這是大多數人認為不可能完成的任務。 然而,只有當這些棋子被放置在現實位置(來自實際比賽)時才是這種情況,而不是隨機放置棋子。 國際象棋專家沒有比你更好的記憶,他們只是更容易看到國際象棋模式,這要歸功于他們對比賽的經驗。 注意模式有助于他們有效地存儲信息。
就像這個記憶實驗中的象棋棋手一樣,一個自編碼器會查看輸入信息,將它們轉換為高效的內部表示形式,然后吐出一些(希望)看起來非常接近輸入的東西。 自編碼器總是由兩部分組成:將輸入轉換為內部表示的編碼器(或識別網絡),然后是將內部表示轉換為輸出的解碼器(或生成網絡)(見圖 15-1)。
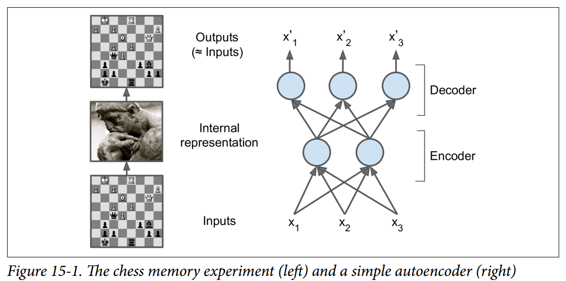
如您所見,自編碼器通常具有與多層感知器(MLP,請參閱第 10 章)相同的體系結構,但輸出層中的神經元數量必須等于輸入數量。 在這個例子中,只有一個由兩個神經元(編碼器)組成的隱藏層和一個由三個神經元(解碼器)組成的輸出層。 由于自編碼器試圖重構輸入,所以輸出通常被稱為重建,并且損失函數包含重建損失,當重建與輸入不同時,重建損失會對模型進行懲罰。
由于內部表示具有比輸入數據更低的維度(它是 2D 而不是 3D),所以自編碼器被認為是不完整的。 不完整的自編碼器不能簡單地將其輸入復制到編碼,但它必須找到一種方法來輸出其輸入的副本。 它被迫學習輸入數據中最重要的特征(并刪除不重要的特征)。
我們來看看如何實現一個非常簡單的不完整的自編碼器,以降低維度。
## 用不完整的線性自編碼器執行 PCA
如果自編碼器僅使用線性激活并且損失函數是均方誤差(MSE),則可以顯示它最終執行主成分分析(參見第 8 章)。
以下代碼構建了一個簡單的線性自編碼器,以在 3D 數據集上執行 PCA,并將其投影到 2D:
```py
import tensorflow as tf
from tensorflow.contrib.layers import fully_connected
n_inputs = 3 # 3D inputs
n_hidden = 2 # 2D codings
n_outputs = n_inputs
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
hidden = fully_connected(X, n_hidden, activation_fn=None)
outputs = fully_connected(hidden, n_outputs, activation_fn=None)
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(reconstruction_loss)
init = tf.global_variables_initializer()
```
這段代碼與我們在過去章節中建立的所有 MLP 沒有什么不同。 需要注意的兩件事是:
* 輸出的數量等于輸入的數量。
* 為了執行簡單的 PCA,我們設置`activation_fn = None`(即,所有神經元都是線性的)
而損失函數是 MSE。 我們很快會看到更復雜的自編碼器。
現在讓我們加載數據集,在訓練集上訓練模型,并使用它來對測試集進行編碼(即將其投影到 2D):
```py
X_train, X_test = [...] # load the dataset
n_iterations = 1000
codings = hidden # the output of the hidden layer provides the codings
with tf.Session() as sess:
init.run()
for iteration in range(n_iterations):
training_op.run(feed_dict={X: X_train}) # no labels (unsupervised)
codings_val = codings.eval(feed_dict={X: X_test})
```
圖 15-2 顯示了原始 3D 數據集(左側)和自編碼器隱藏層的輸出(即編碼層,右側)。 正如您所看到的,自編碼器找到了將數據投影到數據上的最佳二維平面,保留了數據的盡可能多的差異(就像 PCA 一樣)。

## 棧式自編碼器(SAE)
就像我們討論過的其他神經網絡一樣,自編碼器可以有多個隱藏層。 在這種情況下,它們被稱為棧式自編碼器(或深度自編碼器)。 添加更多層有助于自編碼器了解更復雜的編碼。 但是,必須注意不要讓自編碼器功能太強大。 設想一個編碼器非常強大,只需學習將每個輸入映射到一個任意數字(并且解碼器學習反向映射)即可。 很明顯,這樣的自編碼器將完美地重構訓練數據,但它不會在過程中學習到任何有用的數據表示(并且它不可能很好地推廣到新的實例)。
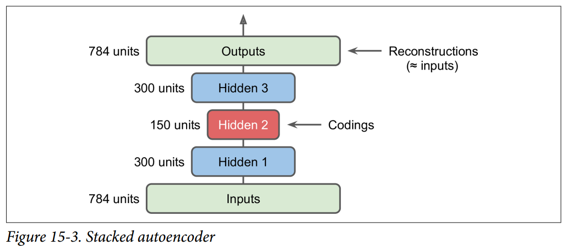
棧式自編碼器的架構關于中央隱藏層(編碼層)通常是對稱的。 簡單來說,它看起來像一個三明治。 例如,一個用于 MNIST 的自編碼器(在第 3 章中介紹)可能有 784 個輸入,其次是一個隱藏層,有 300 個神經元,然后是一個中央隱藏層,有 150 個神經元,然后是另一個隱藏層,有 300 個神經元,輸出層有 784 神經元。 這個棧式自編碼器如圖 15-3 所示。
## TensorFlow實現
您可以像常規深度 MLP 一樣實現棧式自編碼器。 特別是,我們在第 11 章中用于訓練深度網絡的技術也可以應用。例如,下面的代碼使用 He 初始化,ELU 激活函數和 l2 正則化為 MNIST 構建一個棧式自編碼器。 代碼應該看起來很熟悉,除了沒有標簽(沒有`y`):
```py
n_inputs = 28 * 28 # for MNIST
n_hidden1 = 300
n_hidden2 = 150 # codings
n_hidden3 = n_hidden1
n_outputs = n_inputs
learning_rate = 0.01
l2_reg = 0.001
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
with tf.contrib.framework.arg_scope(
[fully_connected],
activation_fn=tf.nn.elu,
weights_initializer=tf.contrib.layers.variance_scaling_initializer(),
weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg)):
hidden1 = fully_connected(X, n_hidden1)
hidden2 = fully_connected(hidden1, n_hidden2) # codings
hidden3 = fully_connected(hidden2, n_hidden3)
outputs = fully_connected(hidden3, n_outputs, activation_fn=None)
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
loss = tf.add_n([reconstruction_loss] + reg_losses)
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
```
然后可以正常訓練模型。 請注意,數字標簽(`y_batch`)未使用:
```py
n_epochs = 5
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
n_batches = mnist.train.num_examples // batch_size
for iteration in range(n_batches):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch})
```
## 關聯權重
當自編碼器整齊地對稱時,就像我們剛剛構建的那樣,一種常用技術是將解碼器層的權重與編碼器層的權重相關聯。 這樣減少了模型中的權重數量,加快了訓練速度,并限制了過度擬合的風險。
具體來說,如果自編碼器總共具有`N`個層(不計入輸入層),并且 ![W^{[L]}](https://img.kancloud.cn/5b/5b/5b5bc77536205d0a4eb017dd5bcae69a_36x17.gif) 表示第`L`層的連接權重(例如,層 1 是第一隱藏層,則層`N / 2`是編碼 層,而層`N`是輸出層),則解碼器層權重可以簡單地定義為:![W^{[N-L + 1]}= W^{[L]T}](https://img.kancloud.cn/9f/81/9f81bcbca55671b1be0a339d374cec23_145x17.gif)(其中`L = 1, 2, ..., N2`)。
不幸的是,使用`fully_connected()`函數在 TensorFlow 中實現相關權重有點麻煩;手動定義層實際上更容易。 代碼結尾明顯更加冗長:
```py
activation = tf.nn.elu
regularizer = tf.contrib.layers.l2_regularizer(l2_reg)
initializer = tf.contrib.layers.variance_scaling_initializer()
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
weights1_init = initializer([n_inputs, n_hidden1])
weights2_init = initializer([n_hidden1, n_hidden2])
weights1 = tf.Variable(weights1_init, dtype=tf.float32, name="weights1")
weights2 = tf.Variable(weights2_init, dtype=tf.float32, name="weights2")
weights3 = tf.transpose(weights2, name="weights3") # tied weights
weights4 = tf.transpose(weights1, name="weights4") # tied weights
biases1 = tf.Variable(tf.zeros(n_hidden1), name="biases1")
biases2 = tf.Variable(tf.zeros(n_hidden2), name="biases2")
biases3 = tf.Variable(tf.zeros(n_hidden3), name="biases3")
biases4 = tf.Variable(tf.zeros(n_outputs), name="biases4")
hidden1 = activation(tf.matmul(X, weights1) + biases1)
hidden2 = activation(tf.matmul(hidden1, weights2) + biases2)
hidden3 = activation(tf.matmul(hidden2, weights3) + biases3)
outputs = tf.matmul(hidden3, weights4) + biases4
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X))
reg_loss = regularizer(weights1) + regularizer(weights2)
loss = reconstruction_loss + reg_loss
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
```
這段代碼非常簡單,但有幾件重要的事情需要注意:
* 首先,權重 3 和權重 4 不是變量,它們分別是權重 2 和權重 1 的轉置(它們與它們“綁定”)。
* 其次,由于它們不是變量,所以規范它們是沒有用的:我們只調整權重 1 和權重 2。
* 第三,偏置永遠不會被束縛,并且永遠不會正規化。
## 一次訓練一個自編碼器
我們不是一次完成整個棧式自編碼器的訓練,而是一次訓練一個淺自編碼器,然后將所有這些自編碼器堆疊到一個棧式自編碼器(因此名稱)中,通常要快得多,如圖 15-4 所示。 這對于非常深的自編碼器特別有用。
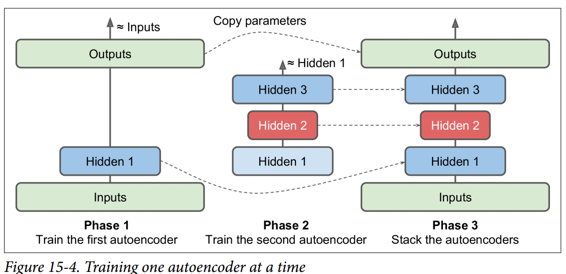
在訓練的第一階段,第一個自編碼器學習重構輸入。 在第二階段,第二個自編碼器學習重構第一個自編碼器隱藏層的輸出。 最后,您只需使用所有這些自編碼器來構建一個大三明治,如圖 15-4 所示(即,您首先將每個自編碼器的隱藏層,然后按相反順序堆疊輸出層)。 這給你最后的棧式自編碼器。 您可以用這種方式輕松地訓練更多的自編碼器,構建一個非常深的棧式自編碼器。
為了實現這種多階段訓練算法,最簡單的方法是對每個階段使用不同的 TensorFlow 圖。 訓練完一個自編碼器后,您只需通過它運行訓練集并捕獲隱藏層的輸出。 這個輸出作為下一個自編碼器的訓練集。 一旦所有自編碼器都以這種方式進行了訓練,您只需復制每個自編碼器的權重和偏置,然后使用它們來構建堆疊的自編碼器。 實現這種方法非常簡單,所以我們不在這里詳細說明,但請查閱 Jupyter notebooks 中的代碼作為示例。
另一種方法是使用包含整個棧式自編碼器的單個圖,以及執行每個訓練階段的一些額外操作,如圖 15-5 所示。
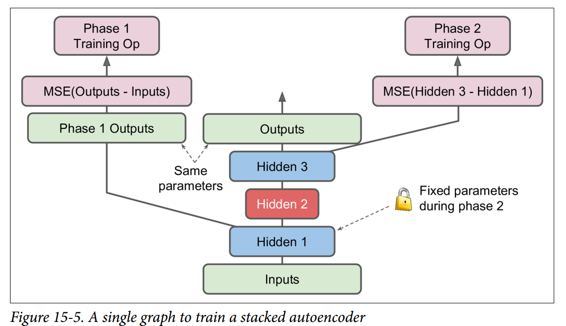
這值得解釋一下:
* 圖中的中央列是完整的棧式自編碼器。這部分可以在訓練后使用。
* 左列是運行第一階段訓練所需的一系列操作。它創建一個繞過隱藏層 2 和 3 的輸出層。該輸出層與堆疊的自編碼器的輸出層共享相同的權重和偏置。此外還有旨在使輸出盡可能接近輸入的訓練操作。因此,該階段將訓練隱藏層1和輸出層(即,第一自編碼器)的權重和偏置。
* 圖中的右列是運行第二階段訓練所需的一組操作。它增加了訓練操作,目的是使隱藏層 3 的輸出盡可能接近隱藏層 1 的輸出。注意,我們必須在運行階段 2 時凍結隱藏層 1。此階段將訓練隱藏層 2 和 3 的權重和偏置(即第二自編碼器)。
TensorFlow 代碼如下所示:
```py
[...] # Build the whole stacked autoencoder normally.
# In this example, the weights are not tied.
optimizer = tf.train.AdamOptimizer(learning_rate)
with tf.name_scope("phase1"):
phase1_outputs = tf.matmul(hidden1, weights4) + biases4
phase1_reconstruction_loss = tf.reduce_mean(tf.square(phase1_outputs - X))
phase1_reg_loss = regularizer(weights1) + regularizer(weights4)
phase1_loss = phase1_reconstruction_loss + phase1_reg_loss
phase1_training_op = optimizer.minimize(phase1_loss)
with tf.name_scope("phase2"):
phase2_reconstruction_loss = tf.reduce_mean(tf.square(hidden3 - hidden1))
phase2_reg_loss = regularizer(weights2) + regularizer(weights3)
phase2_loss = phase2_reconstruction_loss + phase2_reg_loss
train_vars = [weights2, biases2, weights3, biases3]
phase2_training_op = optimizer.minimize(phase2_loss, var_list=train_vars)
```
第一階段比較簡單:我們只創建一個跳過隱藏層 2 和 3 的輸出層,然后構建訓練操作以最小化輸出和輸入之間的距離(加上一些正則化)。
第二階段只是增加了將隱藏層 3 和隱藏層 1 的輸出之間的距離最小化的操作(還有一些正則化)。 最重要的是,我們向`minim()`方法提供可訓練變量的列表,確保省略權重 1 和偏差 1;這有效地凍結了階段 2 期間的隱藏層 1。
在執行階段,你需要做的就是為階段 1 一些迭代進行訓練操作,然后階段 2 訓練運行更多的迭代。
由于隱藏層 1 在階段 2 期間被凍結,所以對于任何給定的訓練實例其輸出將總是相同的。 為了避免在每個時期重新計算隱藏層1的輸出,您可以在階段 1 結束時為整個訓練集計算它,然后直接在階段 2 中輸入隱藏層 1 的緩存輸出。這可以得到一個不錯的性能上的提升。
## 可視化重建
確保自編碼器得到適當訓練的一種方法是比較輸入和輸出。 它們必須非常相似,差異應該是不重要的細節。 我們來繪制兩個隨機數字及其重建:
```py
n_test_digits = 2
X_test = mnist.test.images[:n_test_digits]
with tf.Session() as sess:
[...] # Train the Autoencoder
outputs_val = outputs.eval(feed_dict={X: X_test})
def plot_image(image, shape=[28, 28]):
plt.imshow(image.reshape(shape), cmap="Greys", interpolation="nearest")
plt.axis("off")
for digit_index in range(n_test_digits):
plt.subplot(n_test_digits, 2, digit_index * 2 + 1)
plot_image(X_test[digit_index])
plt.subplot(n_test_digits, 2, digit_index * 2 + 2)
plot_image(outputs_val[digit_index])
```

看起來夠接近。 所以自編碼器已經適當地學會了重現它,但是它學到了有用的特性? 讓我們來看看。
## 可視化功能
一旦你的自編碼器學習了一些功能,你可能想看看它們。 有各種各樣的技術。 可以說最簡單的技術是在每個隱藏層中考慮每個神經元,并找到最能激活它的訓練實例。 這對頂層隱藏層特別有用,因為它們通常會捕獲相對較大的功能,您可以在包含它們的一組訓練實例中輕松找到這些功能。 例如,如果神經元在圖片中看到一只貓時強烈激活,那么激活它的圖片最顯眼的地方都會包含貓。 然而,對于較低層,這種技術并不能很好地工作,因為這些特征更小,更抽象,因此很難準確理解神經元正在為什么而興奮。
讓我們看看另一種技術。 對于第一個隱藏層中的每個神經元,您可以創建一個圖像,其中像素的強度對應于給定神經元的連接權重。 例如,以下代碼繪制了第一個隱藏層中五個神經元學習的特征:
```py
with tf.Session() as sess:
[...] # train autoencoder
weights1_val = weights1.eval()
for i in range(5):
plt.subplot(1, 5, i + 1)
plot_image(weights1_val.T[i])
```
您可能會得到如圖 15-7 所示的低級功能。
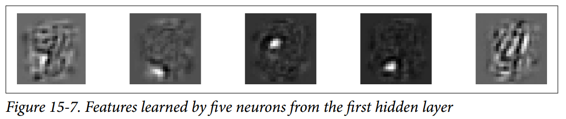
前四個特征似乎對應于小塊,而第五個特征似乎尋找垂直筆劃(請注意,這些特征來自堆疊去噪自編碼器,我們將在后面討論)。
另一種技術是給自編碼器提供一個隨機輸入圖像,測量您感興趣的神經元的激活,然后執行反向傳播來調整圖像,使神經元激活得更多。 如果迭代數次(執行漸變上升),圖像將逐漸變成最令人興奮的圖像(用于神經元)。 這是一種有用的技術,用于可視化神經元正在尋找的輸入類型。
最后,如果使用自編碼器執行無監督預訓練(例如,對于分類任務),驗證自編碼器學習的特征是否有用的一種簡單方法是測量分類器的性能。
## 無監督預訓練使用棧式自編碼器
正如我們在第 11 章中討論的那樣,如果您正在處理復雜的監督任務,但您沒有大量標記的訓練數據,則一種解決方案是找到執行類似任務的神經網絡,然后重新使用其較低層。 這樣就可以僅使用很少的訓練數據來訓練高性能模型,因為您的神經網絡不必學習所有的低級特征;它將重新使用現有網絡學習的特征檢測器。
同樣,如果您有一個大型數據集,但大多數數據集未標記,您可以先使用所有數據訓練棧式自編碼器,然后重新使用較低層為實際任務創建一個神經網絡,并使用標記數據對其進行訓練。 例如,圖 15-8 顯示了如何使用棧式自編碼器為分類神經網絡執行無監督預訓練。 正如前面討論過的,棧式自編碼器本身通常每次都會訓練一個自編碼器。 在訓練分類器時,如果您確實沒有太多標記的訓練數據,則可能需要凍結預訓練層(至少是較低層)。
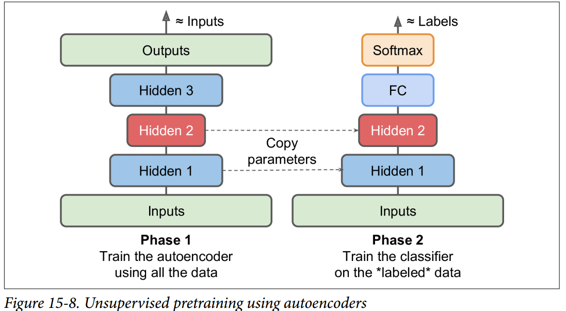
這種情況實際上很常見,因為構建一個大型的無標簽數據集通常很便宜(例如,一個簡單的腳本可以從互聯網上下載數百萬張圖像),但只能由人類可靠地標記它們(例如,將圖像分類為可愛或不可愛)。 標記實例是耗時且昂貴的,因此只有幾千個標記實例是很常見的。
正如我們前面所討論的那樣,當前深度學習海嘯的觸發因素之一是 Geoffrey Hinton 等人在 2006 年的發現,深度神經網絡可以以無監督的方式進行預訓練。 他們使用受限玻爾茲曼機器(見附錄 E),但在 2007 年 Yoshua Bengio 等人表明自編碼器也起作用。
TensorFlow 的實現沒有什么特別之處:只需使用所有訓練數據訓練自編碼器,然后重用其編碼器層以創建一個新的神經網絡(有關如何重用預訓練層的更多詳細信息,請參閱第 11 章或查看 Jupyte notebooks 中的代碼示例)。
到目前為止,為了強制自編碼器學習有趣的特性,我們限制了編碼層的大小,使其不夠完善。 實際上可以使用許多其他類型的約束,包括允許編碼層與輸入一樣大或甚至更大的約束,導致過度完成的自編碼器。 現在我們來看看其中的一些方法。
## 降噪自編碼(DAE)
另一種強制自編碼器學習有用功能的方法是為其輸入添加噪聲,對其進行訓練以恢復原始的無噪聲輸入。 這可以防止自編碼器將其輸入復制到其輸出,因此最終不得不在數據中查找模式。
自 20 世紀 80 年代以來,使用自編碼器消除噪音的想法已經出現(例如,在 Yann LeCun 的 1987 年碩士論文中提到過)。 在 2008 年的一篇論文中,帕斯卡爾文森特等人。 表明自編碼器也可用于特征提取。 在 2010 年的一篇文章中 Vincent 等人引入堆疊降噪自編碼器。
噪聲可以是純粹的高斯噪聲添加到輸入,或者它可以隨機關閉輸入,就像 drop out(在第 11 章介紹)。 圖 15-9 顯示了這兩個選項。
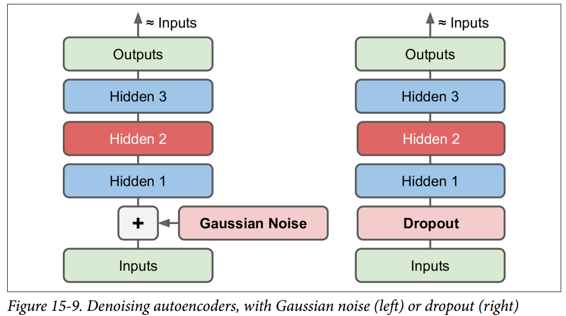
## TensorFlow 實現
在 TensorFlow 中實現去噪自編碼器并不難。 我們從高斯噪聲開始。 這實際上就像訓練一個常規的自編碼器一樣,除了給輸入添加噪聲外,重建損耗是根據原始輸入計算的:
```py
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
X_noisy = X + tf.random_normal(tf.shape(X))
[...]
hidden1 = activation(tf.matmul(X_noisy, weights1) + biases1)
[...]
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
[...]
```
由于`X`的形狀只是在構造階段部分定義的,我們不能預先知道我們必須添加到`X`中的噪聲的形狀。我們不能調用`X.get_shape()`,因為這只會返回部分定義的`X`的形狀 (`[None,n_inputs]`)和`random_normal()`需要一個完全定義的形狀,因此會引發異常。 相反,我們調用`tf.shape(X)`,它將創建一個操作,該操作將在運行時返回`X`的形狀,該操作將在此時完全定義。
實施更普遍的 dropout 版本,而且這個版本并不困難:
```py
from tensorflow.contrib.layers import dropout
keep_prob = 0.7
is_training = tf.placeholder_with_default(False, shape=(), name='is_training')
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
X_drop = dropout(X, keep_prob, is_training=is_training)
[...]
hidden1 = activation(tf.matmul(X_drop, weights1) + biases1)
[...]
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
[...]
```
在訓練期間,我們必須使用`feed_dict`將`is_training`設置為`True`(如第 11 章所述):
```py
sess.run(training_op, feed_dict={X: X_batch, is_training: True})
```
但是,在測試期間,不需要將`is_training`設置為`False`,因為我們將其設置為對`placeholder_with_default()`函數調用的默認值。
## 稀疏自編碼器
通常良好特征提取的另一種約束是稀疏性:通過向損失函數添加適當的項,自編碼器被推動以減少編碼層中活動神經元的數量。 例如,它可能被推到編碼層中平均只有 5% 的顯著活躍的神經元。 這迫使自編碼器將每個輸入表示為少量激活的組合。 因此,編碼層中的每個神經元通常都會代表一個有用的特征(如果您每個月只能說幾個字,您可能會試著讓它們值得一聽)。
為了支持稀疏模型,我們必須首先在每次訓練迭代中測量編碼層的實際稀疏度。 我們通過計算整個訓練批次中編碼層中每個神經元的平均激活來實現。 批量大小不能太小,否則平均數不準確。
一旦我們對每個神經元進行平均激活,我們希望通過向損失函數添加稀疏損失來懲罰太活躍的神經元。 例如,如果我們測量一個神經元的平均激活值為 0.3,但目標稀疏度為 0.1,那么它必須受到懲罰才能激活更少。 一種方法可以簡單地將平方誤差`(0.3-0.1)^2`添加到損失函數中,但實際上更好的方法是使用 Kullback-Leibler 散度(在第 4 章中簡要討論),其具有比均方誤差更強的梯度,如圖 15-10 所示。
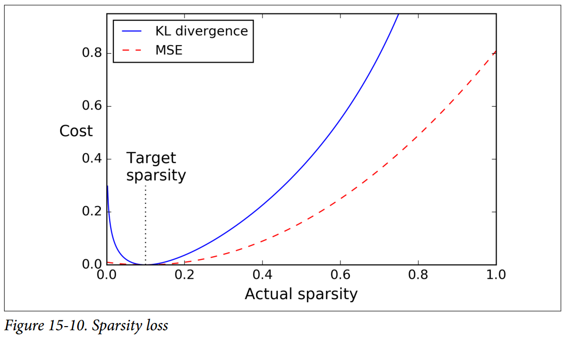
給定兩個離散的概率分布`P`和`Q`,這些分布之間的 KL 散度,記為`Dkl(P || Q)`,可以使用公式 15-1 計算。
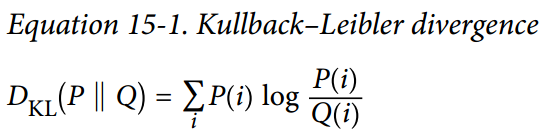
在我們的例子中,我們想要測量編碼層中的神經元將激活的目標概率`p`與實際概率`q`(即,訓練批次上的平均激活)之間的差異。 所以KL散度簡化為公式 15-2。
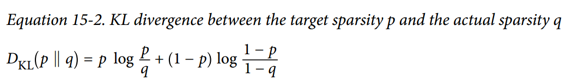
一旦我們已經計算了編碼層中每個神經元的稀疏損失,我們就總結這些損失,并將結果添加到損失函數中。 為了控制稀疏損失和重構損失的相對重要性,我們可以用稀疏權重超參數乘以稀疏損失。 如果這個權重太高,模型會緊貼目標稀疏度,但它可能無法正確重建輸入,導致模型無用。 相反,如果它太低,模型將大多忽略稀疏目標,它不會學習任何有趣的功能。
## TensorFlow 實現
我們現在擁有了使用 TensorFlow 實現稀疏自編碼器所需的全部功能:
```py
def kl_divergence(p, q):
return p * tf.log(p / q) + (1 - p) * tf.log((1 - p) / (1 - q))
learning_rate = 0.01
sparsity_target = 0.1
sparsity_weight = 0.2
[...] # Build a normal autoencoder (in this example the coding layer is hidden1)
optimizer = tf.train.AdamOptimizer(learning_rate)
hidden1_mean = tf.reduce_mean(hidden1, axis=0) # batch mean
sparsity_loss = tf.reduce_sum(kl_divergence(sparsity_target, hidden1_mean))
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
loss = reconstruction_loss + sparsity_weight * sparsity_loss
training_op = optimizer.minimize(loss)
```
一個重要的細節是編碼層的激活必須介于 0 和 1 之間(但不等于 0 或 1),否則 KL 散度將返回`NaN`(非數字)。 一個簡單的解決方案是對編碼層使用邏輯激活功能:
```py
hidden1 = tf.nn.sigmoid(tf.matmul(X, weights1) + biases1)
```
一個簡單的技巧可以加速收斂:不是使用 MSE,我們可以選擇一個具有較大梯度的重建損失。 交叉熵通常是一個不錯的選擇。 要使用它,我們必須對輸入進行規范化處理,使它們的取值范圍為 0 到 1,并在輸出層中使用邏輯激活函數,以便輸出也取值為 0 到 1。TensorFlow 的`sigmoid_cross_entropy_with_logits()`函數負責 有效地將 logistic(sigmoid)激活函數應用于輸出并計算交叉熵:
```py
[...]
logits = tf.matmul(hidden1, weights2) + biases2)
outputs = tf.nn.sigmoid(logits)
reconstruction_loss = tf.reduce_sum(
tf.nn.sigmoid_cross_entropy_with_logits(labels=X, logits=logits))
```
請注意,訓練期間不需要輸出操作(我們僅在我們想要查看重建時才使用它)。
## 變分自編碼器(VAE)
Diederik Kingma 和 Max Welling 于 2014 年推出了另一類重要的自編碼器,并迅速成為最受歡迎的自編碼器類型之一:變分自編碼器。
它們與我們迄今為止討論的所有自編碼器完全不同,特別是:
* 它們是概率自編碼器,意味著即使在訓練之后,它們的輸出部分也是偶然確定的(相對于僅在訓練過程中使用隨機性的自編碼器的去噪)。
* 最重要的是,它們是生成自編碼器,這意味著它們可以生成看起來像從訓練集中采樣的新實例。
這兩個屬性使它們與 RBM 非常相似(見附錄 E),但它們更容易訓練,并且取樣過程更快(在 RBM 之前,您需要等待網絡穩定在“熱平衡”之后才能進行取樣一個新的實例)
我們來看看他們是如何工作的。 圖 15-11(左)顯示了一個變分自編碼器。 當然,您可以認識到所有自編碼器的基本結構,編碼器后跟解碼器(在本例中,它們都有兩個隱藏層),但有一個轉折點:不是直接為給定的輸入生成編碼 ,編碼器產生平均編碼`μ`和標準差`σ`。 然后從平均值`μ`和標準差`σ`的高斯分布隨機采樣實際編碼。 之后,解碼器正常解碼采樣的編碼。 該圖的右側部分顯示了一個訓練實例通過此自編碼器。 首先,編碼器產生`μ`和`σ`,隨后對編碼進行隨機采樣(注意它不是完全位于`μ`處),最后對編碼進行解碼,最終的輸出與訓練實例類似。
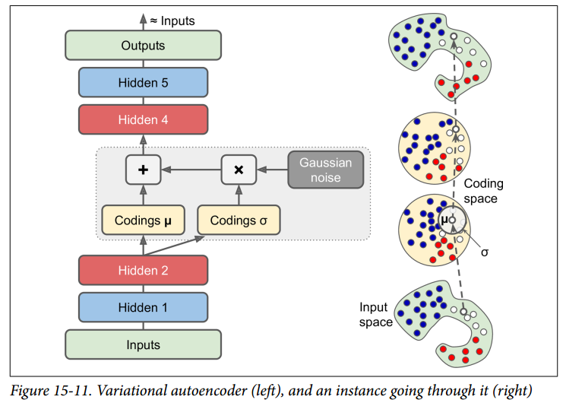
從圖中可以看出,盡管輸入可能具有非常復雜的分布,但變分自編碼器傾向于產生編碼,看起來好像它們是從簡單的高斯分布采樣的:在訓練期間,損失函數(將在下面討論)推動 編碼在編碼空間(也稱為潛在空間)內逐漸遷移以占據看起來像高斯點集成的云的大致(超)球形區域。 一個重要的結果是,在訓練了一個變分自編碼器之后,你可以很容易地生成一個新的實例:只需從高斯分布中抽取一個隨機編碼,對它進行解碼就可以了!
那么讓我們看看損失函數。 它由兩部分組成。 首先是通常的重建損失,推動自編碼器重現其輸入(我們可以使用交叉熵來解決這個問題,如前所述)。 第二種是潛在的損失,推動自編碼器使編碼看起來像是從簡單的高斯分布中采樣,為此我們使用目標分布(高斯分布)與編碼實際分布之間的 KL 散度。 數學比以前復雜一點,特別是因為高斯噪聲,它限制了可以傳輸到編碼層的信息量(從而推動自編碼器學習有用的特征)。 幸運的是,這些方程簡化為下面的潛在損失代碼:
```py
eps = 1e-10 # smoothing term to avoid computing log(0) which is NaN
latent_loss = 0.5 * tf.reduce_sum(
tf.square(hidden3_sigma) + tf.square(hidden3_mean)
- 1 - tf.log(eps + tf.square(hidden3_sigma)))
```
一種常見的變體是訓練編碼器輸出`γ= log(σ^2)`而不是`σ`。 只要我們需要`σ`,我們就可以計算`σ= exp(2/γ)`。 這使得編碼器可以更輕松地捕獲不同比例的`σ`,從而有助于加快收斂速度。 潛在損失結束會變得更簡單一些:
```py
latent_loss = 0.5 * tf.reduce_sum(
tf.exp(hidden3_gamma) + tf.square(hidden3_mean) - 1 - hidden3_gamma)
```
以下代碼使用`log(σ^2)`變體構建圖 15-11(左)所示的變分自編碼器:
```py
n_inputs = 28 * 28 # for MNIST
n_hidden1 = 500
n_hidden2 = 500
n_hidden3 = 20 # codings
n_hidden4 = n_hidden2
n_hidden5 = n_hidden1
n_outputs = n_inputs
learning_rate = 0.001
with tf.contrib.framework.arg_scope(
[fully_connected],
activation_fn=tf.nn.elu,
weights_initializer=tf.contrib.layers.variance_scaling_initializer()):
X = tf.placeholder(tf.float32, [None, n_inputs])
hidden1 = fully_connected(X, n_hidden1)
hidden2 = fully_connected(hidden1, n_hidden2)
hidden3_mean = fully_connected(hidden2, n_hidden3, activation_fn=None)
hidden3_gamma = fully_connected(hidden2, n_hidden3, activation_fn=None)
hidden3_sigma = tf.exp(0.5 * hidden3_gamma)
noise = tf.random_normal(tf.shape(hidden3_sigma), dtype=tf.float32)
hidden3 = hidden3_mean + hidden3_sigma * noise
hidden4 = fully_connected(hidden3, n_hidden4)
hidden5 = fully_connected(hidden4, n_hidden5)
logits = fully_connected(hidden5, n_outputs, activation_fn=None)
outputs = tf.sigmoid(logits)
reconstruction_loss = tf.reduce_sum(
tf.nn.sigmoid_cross_entropy_with_logits(labels=X, logits=logits))
latent_loss = 0.5 * tf.reduce_sum(
tf.exp(hidden3_gamma) + tf.square(hidden3_mean) - 1 - hidden3_gamma)
cost = reconstruction_loss + latent_loss
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(cost)
init = tf.global_variables_initializer()
```
## 生成數字
現在讓我們使用這個變分自編碼器來生成看起來像手寫數字的圖像。 我們所需要做的就是訓練模型,然后從高斯分布中對隨機編碼進行采樣并對它們進行解碼。
```py
import numpy as np
n_digits = 60
n_epochs = 50
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
n_batches = mnist.train.num_examples // batch_size
for iteration in range(n_batches):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch})
codings_rnd = np.random.normal(size=[n_digits, n_hidden3])
outputs_val = outputs.eval(feed_dict={hidden3: codings_rnd})
```
現在我們可以看到由autoencoder生成的“手寫”數字是什么樣的(參見圖15-12):
```py
for iteration in range(n_digits):
plt.subplot(n_digits, 10, iteration + 1)
plot_image(outputs_val[iteration])
```

## 其他自編碼器
監督式學習在圖像識別,語音識別,文本翻譯等方面取得的驚人成就在某種程度上掩蓋了無監督學習的局面,但它實際上正在蓬勃發展。 自編碼器和其他無監督學習算法的新體系結構定期發明,以至于我們無法在本書中全面介紹它們。 以下是您可能想要查看的幾種類型的自編碼器的簡要說明(絕非詳盡無遺):
壓縮自編碼器(CAE)
自編碼器在訓練過程中受到約束,因此與輸入有關的編碼的導數很小。 換句話說,兩個類似的輸入必須具有相似的編碼。
棧式卷積自編碼器(SCAE)
學習通過重構通過卷積層處理的圖像來提取視覺特征的自編碼器。
生成隨機網絡(GSN)
消除自編碼器的泛化,增加了生成數據的能力。
贏家通吃(WTA)的自編碼
在訓練期間,在計算編碼層中所有神經元的激活之后,只保留訓練批次上每個神經元的前 k% 激活,其余部分設為零。 自然這導致稀疏的編碼。 而且,可以使用類似的 WTA 方法來產生稀疏卷積自編碼器。
對抗自編碼器(AAE)
一個網絡被訓練來重現它的輸入,同時另一個網絡被訓練去找到第一個網絡不能正確重建的輸入。 這推動了第一個自編碼器學習健壯的編碼。
