# 十一、訓練深層神經網絡
> 譯者:[@akonwang](https://github.com/wangxupeng)、[@飛龍](https://github.com/wizardforcel)
>
> 校對者:[@飛龍](https://github.com/wizardforcel)、[@ZeyuZhong](https://github.com/zhearing)
第 10 章介紹了人工神經網絡,并訓練了我們的第一個深度神經網絡。 但它是一個非常淺的 DNN,只有兩個隱藏層。 如果你需要解決非常復雜的問題,例如檢測高分辨率圖像中的數百種類型的對象,該怎么辦? 你可能需要訓練更深的 DNN,也許有 10 層,每層包含數百個神經元,通過數十萬個連接來連接。 這不會是閑庭信步:
+ 首先,你將面臨棘手的梯度消失問題(或相關的梯度爆炸問題),這會影響深度神經網絡,并使較低層難以訓練。
+ 其次,對于如此龐大的網絡,訓練將非常緩慢。
+ 第三,具有數百萬參數的模型將會有嚴重的過擬合訓練集的風險。
在本章中,我們將依次討論這些問題,并提出解決問題的技巧。 我們將從解釋梯度消失問題開始,并探討解決這個問題的一些最流行的解決方案。 接下來我們將看看各種優化器,與普通梯度下降相比,它們可以加速大型模型的訓練。 最后,我們將瀏覽一些流行的大型神經網絡正則化技術。
使用這些工具,你將能夠訓練非常深的網絡:歡迎來到深度學習的世界!
## 梯度消失/爆炸問題
正如我們在第 10 章中所討論的那樣,反向傳播算法的工作原理是從輸出層到輸入層,傳播誤差的梯度。 一旦該算法已經計算了網絡中每個參數的損失函數的梯度,它就使用這些梯度來用梯度下降步驟來更新每個參數。
不幸的是,梯度往往變得越來越小,隨著算法進展到較低層。 結果,梯度下降更新使得低層連接權重實際上保持不變,并且訓練永遠不會收斂到良好的解決方案。 這被稱為梯度消失問題。 在某些情況下,可能會發生相反的情況:梯度可能變得越來越大,許多層得到了非常大的權重更新,算法發散。這是梯度爆炸的問題,在循環神經網絡中最為常見(見第 14 章)。 更一般地說,深度神經網絡受梯度不穩定之苦; 不同的層次可能以非常不同的速度學習。
雖然這種不幸的行為已經經過了相當長的一段時間的實驗觀察(這是造成深度神經網絡大部分時間都被拋棄的原因之一),但直到 2010 年左右,人們才有了明顯的進步。 Xavier Glorot 和 Yoshua Bengio 發表的題為《Understanding the Difficulty of Training Deep Feedforward Neural Networks》的論文發現了一些疑問,包括流行的 sigmoid 激活函數和當時最受歡迎的權重初始化技術的組合,即隨機初始化時使用平均值為 0,標準差為 1 的正態分布。簡而言之,他們表明,用這個激活函數和這個初始化方案,每層輸出的方差遠大于其輸入的方差。網絡正向,每層的方差持續增加,直到激活函數在頂層飽和。這實際上是因為logistic函數的平均值為 0.5 而不是 0(雙曲正切函數的平均值為 0,表現略好于深層網絡中的logistic函數)
看一下logistic 激活函數(參見圖 11-1),可以看到當輸入變大(負或正)時,函數飽和在 0 或 1,導數非常接近 0。因此,當反向傳播開始時, 它幾乎沒有梯度通過網絡傳播回來,而且由于反向傳播通過頂層向下傳遞,所以存在的小梯度不斷地被稀釋,因此較低層確實沒有任何東西可用。
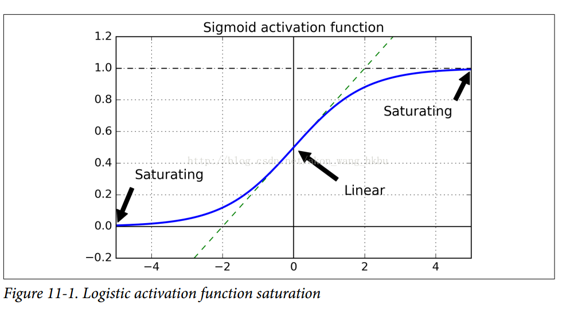
Glorot 和 Bengio 在他們的論文中提出了一種顯著緩解這個問題的方法。 我們需要信號在兩個方向上正確地流動:在進行預測時是正向的,在反向傳播梯度時是反向的。 我們不希望信號消失,也不希望它爆炸并飽和。 為了使信號正確流動,作者認為,我們需要每層輸出的方差等于其輸入的方差。(這里有一個比喻:如果將麥克風放大器的旋鈕設置得太接近于零,人們聽不到聲音,但是如果將麥克風放大器設置得太大,聲音就會飽和,人們就會聽不懂你在說什么。 現在想象一下這樣一個放大器的鏈條:它們都需要正確設置,以便在鏈條的末端響亮而清晰地發出聲音。 你的聲音必須以每個放大器的振幅相同的幅度出來。)而且我們也需要梯度在相反方向上流過一層之前和之后有相同的方差(如果您對數學細節感興趣,請查閱論文)。實際上不可能保證兩者都是一樣的,除非這個層具有相同數量的輸入和輸出連接,但是他們提出了一個很好的折衷辦法,在實踐中證明這個折中辦法非常好:隨機初始化連接權重必須如公式 11-1 所描述的那樣。其中`n_inputs`和`n_outputs`是權重正在被初始化的層(也稱為扇入和扇出)的輸入和輸出連接的數量。 這種初始化策略通常被稱為Xavier初始化(在作者的名字之后),或者有時是 Glorot 初始化。

當輸入連接的數量大致等于輸出連接的數量時,可以得到更簡單的等式 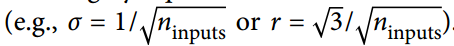 我們在第 10 章中使用了這個簡化的策略。
使用 Xavier 初始化策略可以大大加快訓練速度,這是導致深度學習目前取得成功的技巧之一。 最近的一些論文針對不同的激活函數提供了類似的策略,如表 11-1 所示。 ReLU 激活函數(及其變體,包括簡稱 ELU 激活)的初始化策略有時稱為 He 初始化(在其作者的姓氏之后)。

默認情況下,`fully_connected()`函數(在第 10 章中介紹)使用 Xavier 初始化(具有統一的分布)。 你可以通過使用如下所示的`variance_scaling_initializer()`函數來將其更改為 He 初始化:
注意:本書使用`tensorflow.contrib.layers.fully_connected()`而不是`tf.layers.dense()`(本章編寫時不存在)。 現在最好使用`tf.layers.dense()`,因為`contrib`模塊中的任何內容可能會更改或刪除,恕不另行通知。 `dense()`函數幾乎與`fully_connected()`函數完全相同。 與本章有關的主要差異是:
幾個參數被重新命名:范圍變成名字,`activation_fn`變成激活(類似地,`_fn`后綴從諸如`normalizer_fn`之類的其他參數中移除),`weights_initializer`變成`kernel_initializer`等等。默認激活現在是`None`,而不是`tf.nn.relu`。 它不支持`tensorflow.contrib.framework.arg_scope()`(稍后在第 11 章中介紹)。 它不支持正則化的參數(稍后在第 11 章介紹)。
```py
he_init = tf.contrib.layers.variance_scaling_initializer()
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,
kernel_initializer=he_init, name="hidden1")
```
He 初始化只考慮了扇入,而不是像 Xavier 初始化那樣扇入和扇出之間的平均值。 這也是`variance_scaling_initializer()`函數的默認值,但您可以通過設置參數`mode ="FAN_AVG"`來更改它。
## 非飽和激活函數
Glorot 和 Bengio 在 2010 年的論文中的一個見解是,消失/爆炸的梯度問題部分是由于激活函數的選擇不好造成的。 在那之前,大多數人都認為,如果大自然選擇在生物神經元中使用 sigmoid 激活函數,它們必定是一個很好的選擇。 但事實證明,其他激活函數在深度神經網絡中表現得更好,特別是 ReLU 激活函數,主要是因為它對正值不會飽和(也因為它的計算速度很快)。
不幸的是,ReLU激活功能并不完美。 它有一個被稱為 “ReLU 死區” 的問題:在訓練過程中,一些神經元有效地死亡,意味著它們停止輸出 0 以外的任何東西。在某些情況下,你可能會發現你網絡的一半神經元已經死亡,特別是如果你使用大學習率。 在訓練期間,如果神經元的權重得到更新,使得神經元輸入的加權和為負,則它將開始輸出 0 。當這種情況發生時,由于當輸入為負時,ReLU函數的梯度為0,神經元不可能恢復生機。
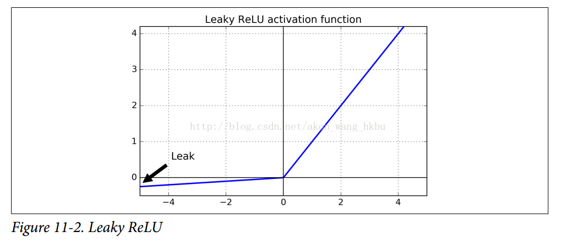
為了解決這個問題,你可能需要使用 ReLU 函數的一個變體,比如 leaky ReLU。這個函數定義為`LeakyReLUα(z)= max(αz,z)`(見圖 11-2)。超參數`α`定義了函數“leaks”的程度:它是`z < 0`時函數的斜率,通常設置為 0.01。這個小斜坡確保 leaky ReLU 永不死亡;他們可能會長期昏迷,但他們有機會最終醒來。最近的一篇論文比較了幾種 ReLU 激活功能的變體,其中一個結論是 leaky Relu 總是優于嚴格的 ReLU 激活函數。事實上,設定`α= 0.2`(巨大 leak)似乎導致比`α= 0.01`(小 leak)更好的性能。他們還評估了隨機化 leaky ReLU(RReLU),其中`α`在訓練期間在給定范圍內隨機挑選,并在測試期間固定為平均值。它表現相當好,似乎是一個正則項(減少訓練集的過擬合風險)。最后,他們還評估了參數 leaky ReLU(PReLU),其中`α`被授權在訓練期間被學習(而不是超參數,它變成可以像任何其他參數一樣被反向傳播修改的參數)。據報道這在大型圖像數據集上的表現強于 ReLU,但是對于較小的數據集,其具有過度擬合訓練集的風險。
最后,Djork-Arné Clevert 等人在 2015 年的一篇論文中提出了一種稱為指數線性單元(exponential linear unit,ELU)的新的激活函數,在他們的實驗中表現優于所有的 ReLU 變體:訓練時間減少,神經網絡在測試集上表現的更好。 如圖 11-3 所示,公式 11-2 給出了它的定義。
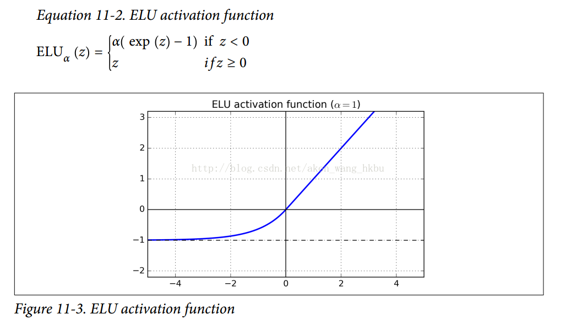
它看起來很像 ReLU 函數,但有一些區別,主要區別在于:
* 首先它在`z < 0`時取負值,這使得該單元的平均輸出接近于 0。這有助于減輕梯度消失問題,如前所述。 超參數`α`定義為當`z`是一個大的負數時,ELU 函數接近的值。它通常設置為 1,但是如果你愿意,你可以像調整其他超參數一樣調整它。
* 其次,它對`z < 0`有一個非零的梯度,避免了神經元死亡的問題。
* 第三,函數在任何地方都是平滑的,包括`z = 0`左右,這有助于加速梯度下降,因為它不會彈回`z = 0`的左側和右側。
ELU 激活函數的主要缺點是計算速度慢于 ReLU 及其變體(由于使用指數函數),但是在訓練過程中,這是通過更快的收斂速度來補償的。 然而,在測試時間,ELU 網絡將比 ReLU 網絡慢。
那么你應該使用哪個激活函數來處理深層神經網絡的隱藏層? 雖然你的里程會有所不同,一般 ELU > leaky ReLU(及其變體)> ReLU > tanh > sigmoid。 如果您關心運行時性能,那么您可能喜歡 leaky ReLU超過ELU。 如果你不想調整另一個超參數,你可以使用前面提到的默認的`α`值(leaky ReLU 為 0.01,ELU 為 1)。 如果您有充足的時間和計算能力,您可以使用交叉驗證來評估其他激活函數,特別是如果您的神經網絡過擬合,則為RReLU; 如果您擁有龐大的訓練數據集,則為 PReLU。
TensorFlow 提供了一個可以用來建立神經網絡的`elu()`函數。 調用`fully_connected()`函數時,只需設置`activation_fn`參數即可:
```py
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.elu, name="hidden1")
```
TensorFlow 沒有針對 leaky ReLU 的預定義函數,但是很容易定義:
```py
def leaky_relu(z, name=None):
return tf.maximum(0.01 * z, z, name=name)
hidden1 = tf.layers.dense(X, n_hidden1, activation=leaky_relu, name="hidden1")
```
## 批量標準化
盡管使用 He初始化和 ELU(或任何 ReLU 變體)可以顯著減少訓練開始階段的梯度消失/爆炸問題,但不保證在訓練期間問題不會回來。
在 2015 年的一篇論文中,Sergey Ioffe 和 Christian Szegedy 提出了一種稱為批量標準化(Batch Normalization,BN)的技術來解決梯度消失/爆炸問題,每層輸入的分布在訓練期間改變的問題,更普遍的問題是當前一層的參數改變,每層輸入的分布會在訓練過程中發生變化(他們稱之為內部協變量偏移問題)。
該技術包括在每層的激活函數之前在模型中添加操作,簡單地對輸入進行zero-centering和規范化,然后每層使用兩個新參數(一個用于尺度變換,另一個用于偏移)對結果進行尺度變換和偏移。 換句話說,這個操作可以讓模型學習到每層輸入值的最佳尺度,均值。為了對輸入進行歸零和歸一化,算法需要估計輸入的均值和標準差。 它通過評估當前小批量輸入的均值和標準差(因此命名為“批量標準化”)來實現。 整個操作在方程 11-3 中。

 是整個小批量B的經驗均值
 是經驗性的標準差,也是來評估整個小批量的。
 是小批量中的實例數量。
 是以為零中心和標準化的輸入。
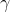 是層的縮放參數。
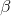 是層的移動參數(偏移量)
 是一個很小的數字,以避免被零除(通常為`10 ^ -3`)。 這被稱為平滑項(拉布拉斯平滑,Laplace Smoothing)。
 是BN操作的輸出:它是輸入的縮放和移位版本。
在測試時,沒有小批量計算經驗均值和標準差,所以您只需使用整個訓練集的均值和標準差。 這些通常在訓練期間使用移動平均值進行有效計算。 因此,總的來說,每個批次標準化的層次都學習了四個參數:`γ`(標度),`β`(偏移),`μ`(平均值)和`σ`(標準差)。
作者證明,這項技術大大改善了他們試驗的所有深度神經網絡。梯度消失問題大大減少了,他們可以使用飽和激活函數,如 tanh 甚至 sigmoid 激活函數。網絡對權重初始化也不那么敏感。他們能夠使用更大的學習率,顯著加快了學習過程。具體地,他們指出,“應用于最先進的圖像分類模型,批標準化用少了 14 倍的訓練步驟實現了相同的精度,以顯著的優勢擊敗了原始模型。[...] 使用批量標準化的網絡集合,我們改進了 ImageNet 分類上的最佳公布結果:達到4.9% 的前5個驗證錯誤(和 4.8% 的測試錯誤),超出了人類評估者的準確性。批量標準化也像一個正則化項一樣,減少了對其他正則化技術的需求(如本章稍后描述的 dropout).
然而,批量標準化的確會增加模型的復雜性(盡管它不需要對輸入數據進行標準化,因為第一個隱藏層會照顧到這一點,只要它是批量標準化的)。 此外,還存在運行時間的損失:由于每層所需的額外計算,神經網絡的預測速度較慢。 所以,如果你需要預測閃電般快速,你可能想要檢查普通ELU + He初始化執行之前如何執行批量標準化。
您可能會發現,訓練起初相當緩慢,而漸變下降正在尋找每層的最佳尺度和偏移量,但一旦找到合理的好值,它就會加速。
使用 TensorFlow 實現批量標準化
TensorFlow 提供了一個`batch_normalization()`函數,它簡單地對輸入進行居中和標準化,但是您必須自己計算平均值和標準差(基于訓練期間的小批量數據或測試過程中的完整數據集) 作為這個函數的參數,并且還必須處理縮放和偏移量參數的創建(并將它們傳遞給此函數)。 這是可行的,但不是最方便的方法。 相反,你應該使用`batch_norm()`函數,它為你處理所有這些。 您可以直接調用它,或者告訴`fully_connected()`函數使用它,如下面的代碼所示:
注意:本書使用`tensorflow.contrib.layers.batch_norm()`而不是`tf.layers.batch_normalization()`(本章寫作時不存在)。 現在最好使用`tf.layers.batch_normalization()`,因為`contrib`模塊中的任何內容都可能會改變或被刪除,恕不另行通知。 我們現在不使用`batch_norm()`函數作為`fully_connected()`函數的正則化參數,而是使用`batch_normalization()`,并明確地創建一個不同的層。 參數有些不同,特別是:
* `decay`更名為`momentum`
* `is_training`被重命名為`training`
* `updates_collections`被刪除:批量標準化所需的更新操作被添加到`UPDATE_OPS`集合中,并且您需要在訓練期間明確地運行這些操作(請參閱下面的執行階段)
* 我們不需要指定`scale = True`,因為這是默認值。
還要注意,為了在每個隱藏層激活函數之前運行批量標準化,我們手動應用 RELU 激活函數,在批量規范層之后。注意:由于`tf.layers.dense()`函數與本書中使用的`tf.contrib.layers.arg_scope()`不兼容,我們現在使用 python 的`functools.partial()`函數。 它可以很容易地創建一個`my_dense_layer()`函數,只需調用`tf.layers.dense()`,并自動設置所需的參數(除非在調用`my_dense_layer()`時覆蓋它們)。 如您所見,代碼保持非常相似。
```py
import tensorflow as tf
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
training = tf.placeholder_with_default(False, shape=(), name='training')
hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1")
bn1 = tf.layers.batch_normalization(hidden1, training=training, momentum=0.9)
bn1_act = tf.nn.elu(bn1)
hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2")
bn2 = tf.layers.batch_normalization(hidden2, training=training, momentum=0.9)
bn2_act = tf.nn.elu(bn2)
logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs")
logits = tf.layers.batch_normalization(logits_before_bn, training=training,
momentum=0.9)
```
```py
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
training = tf.placeholder_with_default(False, shape=(), name='training')
```
為了避免一遍又一遍重復相同的參數,我們可以使用 Python 的`partial()`函數:
```py
from functools import partial
my_batch_norm_layer = partial(tf.layers.batch_normalization,
training=training, momentum=0.9)
hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1")
bn1 = my_batch_norm_layer(hidden1)
bn1_act = tf.nn.elu(bn1)
hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2")
bn2 = my_batch_norm_layer(hidden2)
bn2_act = tf.nn.elu(bn2)
logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs")
logits = my_batch_norm_layer(logits_before_bn)
```
完整代碼
```py
from functools import partial
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
if __name__ == '__main__':
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
mnist = input_data.read_data_sets("/tmp/data/")
batch_norm_momentum = 0.9
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name = 'X')
y = tf.placeholder(tf.int64, shape=None, name = 'y')
training = tf.placeholder_with_default(False, shape=(), name = 'training')#給Batch norm加一個placeholder
with tf.name_scope("dnn"):
he_init = tf.contrib.layers.variance_scaling_initializer()
#對權重的初始化
my_batch_norm_layer = partial(
tf.layers.batch_normalization,
training = training,
momentum = batch_norm_momentum
)
my_dense_layer = partial(
tf.layers.dense,
kernel_initializer = he_init
)
hidden1 = my_dense_layer(X ,n_hidden1 ,name = 'hidden1')
bn1 = tf.nn.elu(my_batch_norm_layer(hidden1))
hidden2 = my_dense_layer(bn1, n_hidden2, name = 'hidden2')
bn2 = tf.nn.elu(my_batch_norm_layer(hidden2))
logists_before_bn = my_dense_layer(bn2, n_outputs, name = 'outputs')
logists = my_batch_norm_layer(logists_before_bn)
with tf.name_scope('loss'):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels = y, logits= logists)
loss = tf.reduce_mean(xentropy, name = 'loss')
with tf.name_scope('train'):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logists, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epoches = 20
batch_size = 200
# 注意:由于我們使用的是 tf.layers.batch_normalization() 而不是 tf.contrib.layers.batch_norm()(如本書所述),
# 所以我們需要明確運行批量規范化所需的額外更新操作(sess.run([ training_op,extra_update_ops], ...)。
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.Session() as sess:
init.run()
for epoch in range(n_epoches):
for iteraton in range(mnist.train.num_examples//batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run([training_op,extra_update_ops],
feed_dict={training:True, X:X_batch, y:y_batch})
accuracy_val = accuracy.eval(feed_dict= {X:mnist.test.images,
y:mnist.test.labels})
print(epoch, 'Test accuracy:', accuracy_val)
```
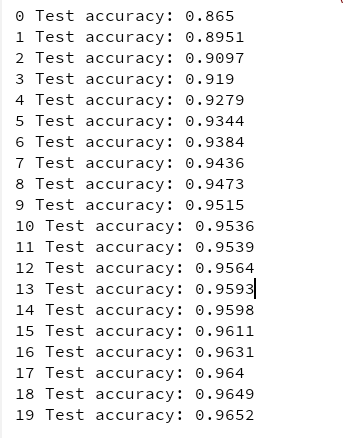
什么!? 這對 MNIST 來說不是一個很好的準確性。 當然,如果你訓練的時間越長,準確性就越好,但是由于這樣一個淺的網絡,批量范數和 ELU 不太可能產生非常積極的影響:它們大部分都是為了更深的網絡而發光。請注意,您還可以訓練操作取決于更新操作:
```py
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(extra_update_ops):
training_op = optimizer.minimize(loss)
```
這樣,你只需要在訓練過程中評估training_op,TensorFlow也會自動運行更新操作:
```py
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})
```
## 梯度裁剪
減少梯度爆炸問題的一種常用技術是在反向傳播過程中簡單地剪切梯度,使它們不超過某個閾值(這對于遞歸神經網絡是非常有用的;參見第 14 章)。 這就是所謂的梯度裁剪。一般來說,人們更喜歡批量標準化,但了解梯度裁剪以及如何實現它仍然是有用的。
在 TensorFlow 中,優化器的`minimize()`函數負責計算梯度并應用它們,所以您必須首先調用優化器的`compute_gradients()`方法,然后使用`clip_by_value()`函數創建一個裁剪梯度的操作,最后 創建一個操作來使用優化器的`apply_gradients()`方法應用裁剪梯度:
```py
threshold = 1.0
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
for grad, var in grads_and_vars]
training_op = optimizer.apply_gradients(capped_gvs)
```
像往常一樣,您將在每個訓練階段運行這個`training_op`。 它將計算梯度,將它們裁剪到 -1.0 和 1.0 之間,并應用它們。 `threhold`是您可以調整的超參數。
## 復用預訓練層
從零開始訓練一個非常大的 DNN 通常不是一個好主意,相反,您應該總是嘗試找到一個現有的神經網絡來完成與您正在嘗試解決的任務類似的任務,然后復用這個網絡的較低層:這就是所謂的遷移學習。這不僅會大大加快訓練速度,還將需要更少的訓練數據。
例如,假設您可以訪問經過訓練的 DNN,將圖片分為 100 個不同的類別,包括動物,植物,車輛和日常物品。 您現在想要訓練一個 DNN 來對特定類型的車輛進行分類。 這些任務非常相似,因此您應該嘗試重新使用第一個網絡的一部分(請參見圖 11-4)。
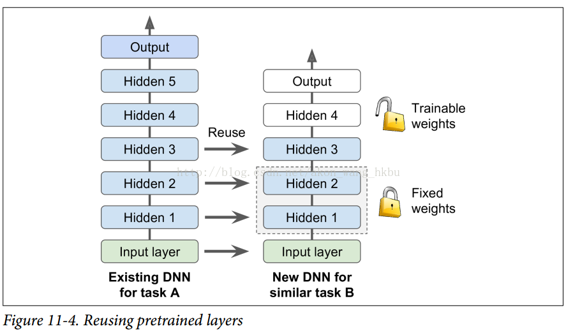
如果新任務的輸入圖像與原始任務中使用的輸入圖像的大小不一致,則必須添加預處理步驟以將其大小調整為原始模型的預期大小。 更一般地說,如果輸入具有類似的低級層次的特征,則遷移學習將很好地工作。
## 復用 TensorFlow 模型
如果原始模型使用 TensorFlow 進行訓練,則可以簡單地將其恢復并在新任務上進行訓練:
```py
[...] # construct the original model
```
```py
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt")
# continue training the model...
```
完整代碼:
```py
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 50
n_hidden3 = 50
n_hidden4 = 50
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3")
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4")
hidden5 = tf.layers.dense(hidden4, n_hidden5, activation=tf.nn.relu, name="hidden5")
logits = tf.layers.dense(hidden5, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
learning_rate = 0.01
threshold = 1.0
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
for grad, var in grads_and_vars]
training_op = optimizer.apply_gradients(capped_gvs)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
```
```py
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_new_model_final.ckpt")
```
但是,一般情況下,您只需要重新使用原始模型的一部分(就像我們將要討論的那樣)。 一個簡單的解決方案是將`Saver`配置為僅恢復原始模型中的一部分變量。 例如,下面的代碼只恢復隱藏的層1,2和3:
```py
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300 # reused
n_hidden2 = 50 # reused
n_hidden3 = 50 # reused
n_hidden4 = 20 # new!
n_outputs = 10 # new!
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1") # reused
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2") # reused
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3") # reused
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4") # new!
logits = tf.layers.dense(hidden4, n_outputs, name="outputs") # new!
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
```
```py
[...] # build new model with the same definition as before for hidden layers 1-3
```
```py
reuse_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
scope="hidden[123]") # regular expression
reuse_vars_dict = dict([(var.op.name, var) for var in reuse_vars])
restore_saver = tf.train.Saver(reuse_vars_dict) # to restore layers 1-3
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
init.run()
restore_saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs): # not shown in the book
for iteration in range(mnist.train.num_examples // batch_size): # not shown
X_batch, y_batch = mnist.train.next_batch(batch_size) # not shown
sess.run(training_op, feed_dict={X: X_batch, y: y_batch}) # not shown
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images, # not shown
y: mnist.test.labels}) # not shown
print(epoch, "Test accuracy:", accuracy_val) # not shown
save_path = saver.save(sess, "./my_new_model_final.ckpt")
```
首先我們建立新的模型,確保復制原始模型的隱藏層 1 到 3。我們還創建一個節點來初始化所有變量。 然后我們得到剛剛用`trainable = True`(這是默認值)創建的所有變量的列表,我們只保留那些范圍與正則表達式`hidden [123]`相匹配的變量(即,我們得到所有可訓練的隱藏層 1 到 3 中的變量)。 接下來,我們創建一個字典,將原始模型中每個變量的名稱映射到新模型中的名稱(通常需要保持完全相同的名稱)。 然后,我們創建一個`Saver`,它將只恢復這些變量,并且創建另一個`Saver`來保存整個新模型,而不僅僅是第 1 層到第 3 層。然后,我們開始一個會話并初始化模型中的所有變量,然后從原始模型的層 1 到 3中恢復變量值。最后,我們在新任務上訓練模型并保存。
任務越相似,您可以重復使用的層越多(從較低層開始)。 對于非常相似的任務,您可以嘗試保留所有隱藏的層,只替換輸出層。
## 復用來自其它框架的模型
如果模型是使用其他框架進行訓練的,則需要手動加載權重(例如,如果使用 Theano 訓練,則使用 Theano 代碼),然后將它們分配給相應的變量。 這可能是相當乏味的。 例如,下面的代碼顯示了如何復制使用另一個框架訓練的模型的第一個隱藏層的權重和偏置:
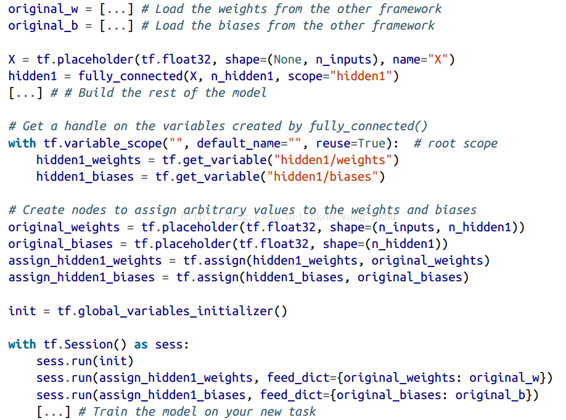
## 凍結較低層
第一個 DNN 的較低層可能已經學會了檢測圖片中的低級特征,這將在兩個圖像分類任務中有用,因此您可以按照原樣重新使用這些層。 在訓練新的 DNN 時,“凍結”權重通常是一個好主意:如果較低層權重是固定的,那么較高層權重將更容易訓練(因為他們不需要學習一個移動的目標)。 要在訓練期間凍結較低層,最簡單的解決方案是給優化器列出要訓練的變量,不包括來自較低層的變量:

第一行獲得隱藏層 3 和 4 以及輸出層中所有可訓練變量的列表。 這留下了隱藏層 1 和 2 中的變量。接下來,我們將這個受限制的可列表變量列表提供給`optimizer`的`minimize()`函數。當當! 現在,層 1 和層 2 被凍結:在訓練過程中不會發生變化(通常稱為凍結層)。
## 緩存凍結層
由于凍結層不會改變,因此可以為每個訓練實例緩存最上面的凍結層的輸出。 由于訓練貫穿整個數據集很多次,這將給你一個巨大的速度提升,因為每個訓練實例只需要經過一次凍結層(而不是每個迭代一次)。 例如,你可以先運行整個訓練集(假設你有足夠的內存):
```py
hidden2_outputs = sess.run(hidden2, feed_dict={X: X_train})
```
然后在訓練過程中,不再對訓練實例建立批次,而是從隱藏層2的輸出建立批次,并將它們提供給訓練操作:
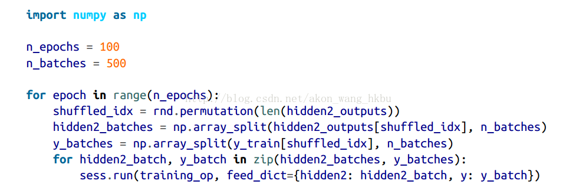
最后一行運行先前定義的訓練操作(凍結層 1 和 2),并從第二個隱藏層(以及該批次的目標)為其輸出一批輸出。 因為我們給 TensorFlow 隱藏層 2 的輸出,所以它不會去評估它(或者它所依賴的任何節點)。
## 調整,刪除或替換較高層
原始模型的輸出層通常應該被替換,因為對于新的任務來說,最有可能沒有用處,甚至可能沒有適合新任務的輸出數量。
類似地,原始模型的較高隱藏層不太可能像較低層一樣有用,因為對于新任務來說最有用的高層特征可能與對原始任務最有用的高層特征明顯不同。 你需要找到正確的層數來復用。
嘗試先凍結所有復制的層,然后訓練模型并查看它是如何執行的。 然后嘗試解凍一個或兩個較高隱藏層,讓反向傳播調整它們,看看性能是否提高。 您擁有的訓練數據越多,您可以解凍的層數就越多。
如果仍然無法獲得良好的性能,并且您的訓練數據很少,請嘗試刪除頂部的隱藏層,并再次凍結所有剩余的隱藏層。 您可以迭代,直到找到正確的層數重復使用。 如果您有足夠的訓練數據,您可以嘗試替換頂部的隱藏層,而不是丟掉它們,甚至可以添加更多的隱藏層。
## Model Zoos
你在哪里可以找到一個類似于你想要解決的任務訓練的神經網絡? 首先看看顯然是在你自己的模型目錄。 這是保存所有模型并組織它們的一個很好的理由,以便您以后可以輕松地檢索它們。 另一個選擇是在模型動物園中搜索。 許多人為了各種不同的任務而訓練機器學習模型,并且善意地向公眾發布預訓練模型。
TensorFlow 在 <https://github.com/tensorflow/models> 中有自己的模型動物園。 特別是,它包含了大多數最先進的圖像分類網絡,如 VGG,Inception 和 ResNet(參見第 13 章,檢查`model/slim`目錄),包括代碼,預訓練模型和 工具來下載流行的圖像數據集。
另一個流行的模型動物園是 Caffe 模型動物園。 它還包含許多在各種數據集(例如,ImageNet,Places 數據庫,CIFAR10 等)上訓練的計算機視覺模型(例如,LeNet,AlexNet,ZFNet,GoogLeNet,VGGNet,開始)。 Saumitro Dasgupta 寫了一個轉換器,可以在 <https://github.com/ethereon/caffetensorflow>。
## 無監督的預訓練
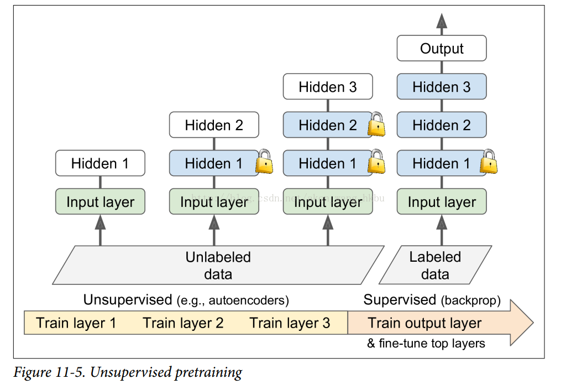
假設你想要解決一個復雜的任務,你沒有太多的標記的訓練數據,但不幸的是,你不能找到一個類似的任務訓練模型。 不要失去所有希望! 首先,你當然應該嘗試收集更多的有標簽的訓練數據,但是如果這太難或太昂貴,你仍然可以進行無監督的訓練(見圖 11-5)。 也就是說,如果你有很多未標記的訓練數據,你可以嘗試逐層訓練層,從最低層開始,然后上升,使用無監督的特征檢測算法,如限制玻爾茲曼機(RBM;見附錄 E)或自動編碼器(見第 15 章)。 每個層都被訓練成先前訓練過的層的輸出(除了被訓練的層之外的所有層都被凍結)。 一旦所有層都以這種方式進行了訓練,就可以使用監督式學習(即反向傳播)對網絡進行微調。
這是一個相當漫長而乏味的過程,但通常運作良好。 實際上,這是 Geoffrey Hinton 和他的團隊在 2006 年使用的技術,導致了神經網絡的復興和深度學習的成功。 直到 2010 年,無監督預訓練(通常使用 RBM)是深度網絡的標準,只有在梯度消失問題得到緩解之后,純訓練 DNN 才更為普遍。 然而,當您有一個復雜的任務需要解決時,無監督訓練(現在通常使用自動編碼器而不是 RBM)仍然是一個很好的選擇,沒有類似的模型可以重復使用,而且標記的訓練數據很少,但是大量的未標記的訓練數據。(另一個選擇是提出一個監督的任務,您可以輕松地收集大量標記的訓練數據,然后使用遷移學習,如前所述。 例如,如果要訓練一個模型來識別圖片中的朋友,你可以在互聯網上下載數百萬張臉并訓練一個分類器來檢測兩張臉是否相同,然后使用此分類器將新圖片與你朋友的每張照片做比較。)
## 在輔助任務上預訓練
最后一種選擇是在輔助任務上訓練第一個神經網絡,您可以輕松獲取或生成標記的訓練數據,然后重新使用該網絡的較低層來完成您的實際任務。 第一個神經網絡的較低層將學習可能被第二個神經網絡重復使用的特征檢測器。
例如,如果你想建立一個識別面孔的系統,你可能只有幾個人的照片 - 顯然不足以訓練一個好的分類器。 收集每個人的數百張照片將是不實際的。 但是,您可以在互聯網上收集大量隨機人員的照片,并訓練第一個神經網絡來檢測兩張不同的照片是否屬于同一個人。 這樣的網絡將學習面部優秀的特征檢測器,所以重復使用它的較低層將允許你使用很少的訓練數據來訓練一個好的面部分類器。
收集沒有標簽的訓練樣本通常是相當便宜的,但標注它們卻相當昂貴。 在這種情況下,一種常見的技術是將所有訓練樣例標記為“好”,然后通過破壞好的訓練樣例產生許多新的訓練樣例,并將這些樣例標記為“壞”。然后,您可以訓練第一個神經網絡 將實例分類為好或不好。 例如,您可以下載數百萬個句子,將其標記為“好”,然后在每個句子中隨機更改一個單詞,并將結果語句標記為“不好”。如果神經網絡可以告訴“The dog sleeps”是好的句子,但“The dog they”是壞的,它可能知道相當多的語言。 重用其較低層可能有助于許多語言處理任務。
另一種方法是訓練第一個網絡為每個訓練實例輸出一個分數,并使用一個損失函數確保一個好的實例的分數大于一個壞實例的分數至少一定的邊際。 這被稱為最大邊際學習.
## 更快的優化器
訓練一個非常大的深度神經網絡可能會非常緩慢。 到目前為止,我們已經看到了四種加速訓練的方法(并且達到更好的解決方案):對連接權重應用良好的初始化策略,使用良好的激活函數,使用批量規范化以及重用預訓練網絡的部分。 另一個巨大的速度提升來自使用比普通漸變下降優化器更快的優化器。 在本節中,我們將介紹最流行的:動量優化,Nesterov 加速梯度,AdaGrad,RMSProp,最后是 Adam 優化。
劇透:本節的結論是,您幾乎總是應該使用`Adam_optimization`,所以如果您不關心它是如何工作的,只需使用`AdamOptimizer`替換您的`GradientDescentOptimizer`,然后跳到下一節! 只需要這么小的改動,訓練通常會快幾倍。 但是,Adam 優化確實有三個可以調整的超參數(加上學習率)。 默認值通常工作的不錯,但如果您需要調整它們,知道他們怎么實現的可能會有幫助。 Adam 優化結合了來自其他優化算法的幾個想法,所以先看看這些算法是有用的。
## 動量優化
想象一下,一個保齡球在一個光滑的表面上平緩的斜坡上滾動:它會緩慢地開始,但是它會很快地達到最終的速度(如果有一些摩擦或空氣阻力的話)。 這是 Boris Polyak 在 1964 年提出的動量優化背后的一個非常簡單的想法。相比之下,普通的梯度下降只需要沿著斜坡進行小的有規律的下降步驟,所以需要更多的時間才能到達底部。
回想一下,梯度下降只是通過直接減去損失函數`J(θ)`相對于權重`θ`的梯度,乘以學習率`η`來更新權重`θ`。 方程是:。它不關心早期的梯度是什么。 如果局部梯度很小,則會非常緩慢。
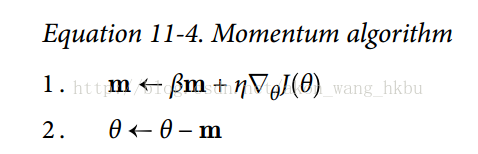
動量優化很關心以前的梯度:在每次迭代時,它將動量矢量`m`(乘以學習率`η`)與局部梯度相加,并且通過簡單地減去該動量矢量來更新權重(參見公式 11-4)。 換句話說,梯度用作加速度,不用作速度。 為了模擬某種摩擦機制,避免動量過大,該算法引入了一個新的超參數`β`,簡稱為動量,它必須設置在 0(高摩擦)和 1(無摩擦)之間。 典型的動量值是 0.9。
您可以很容易地驗證,如果梯度保持不變,則最終速度(即,權重更新的最大大小)等于該梯度乘以學習率`η`乘以`1/(1-β)`。 例如,如果`β = 0.9`,則最終速度等于學習率的梯度乘以 10 倍,因此動量優化比梯度下降快 10 倍! 這使動量優化比梯度下降快得多。 特別是,我們在第四章中看到,當輸入量具有非常不同的尺度時,損失函數看起來像一個細長的碗(見圖 4-7)。 梯度下降速度很快,但要花很長的時間才能到達底部。 相反,動量優化會越來越快地滾下山谷底部,直到達到底部(最佳)。
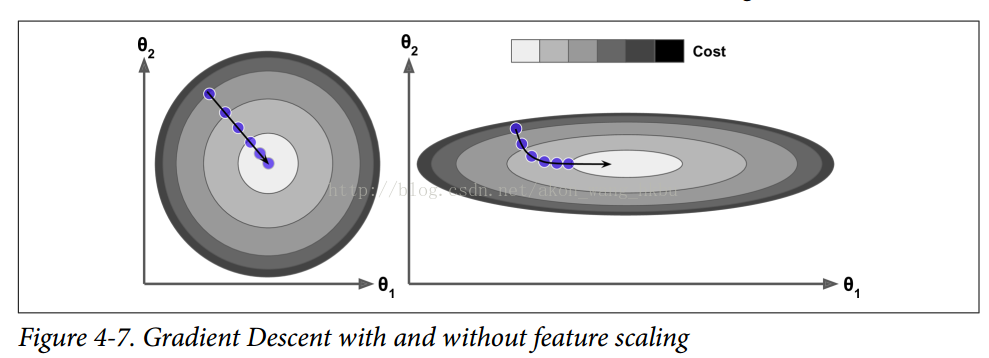
在不使用批標準化的深層神經網絡中,較高層往往會得到具有不同的尺度的輸入,所以使用動量優化會有很大的幫助。 它也可以幫助滾過局部最優值。
由于動量的原因,優化器可能會超調一些,然后再回來,再次超調,并在穩定在最小值之前多次振蕩。 這就是為什么在系統中有一點摩擦的原因之一:它消除了這些振蕩,從而加速了收斂。
在 TensorFlow 中實現動量優化是一件簡單的事情:只需用`MomentumOptimizer`替換`GradientDescentOptimizer`,然后躺下來賺錢!

動量優化的一個缺點是它增加了另一個超參數來調整。 然而,0.9 的動量值通常在實踐中運行良好,幾乎總是比梯度下降快。
## Nesterov 加速梯度
Yurii Nesterov 在 1983 年提出的動量優化的一個小變體幾乎總是比普通的動量優化更快。 Nesterov 動量優化或 Nesterov 加速梯度(Nesterov Accelerated Gradient,NAG)的思想是測量損失函數的梯度不是在局部位置,而是在動量方向稍微靠前(見公式 11-5)。 與普通的動量優化的唯一區別在于梯度是在`θ+βm`而不是在`θ`處測量的。

這個小小的調整是可行的,因為一般來說,動量矢量將指向正確的方向(即朝向最優方向),所以使用在該方向上測得的梯度稍微更精確,而不是使用 原始位置的梯度,如圖11-6所示(其中`?1`代表在起點`θ`處測量的損失函數的梯度,`?2`代表位于`θ+βm`的點處的梯度)。
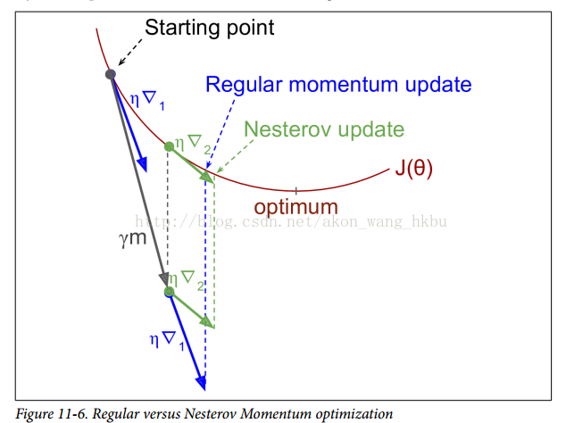
正如你所看到的,Nesterov 更新稍微靠近最佳值。 過了一段時間,這些小的改進加起來,NAG 最終比常規的動量優化快得多。 此外,請注意,當動量推動權重橫跨山谷時,▽1繼續推進越過山谷,而▽2推回山谷的底部。 這有助于減少振蕩,從而更快地收斂。
與常規的動量優化相比,NAG 幾乎總能加速訓練。 要使用它,只需在創建`MomentumOptimizer`時設置`use_nesterov = True`:

## AdaGrad
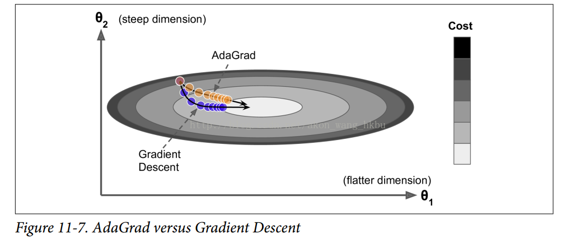
再次考慮細長碗的問題:梯度下降從最陡峭的斜坡快速下降,然后緩慢地下到谷底。 如果算法能夠早期檢測到這個問題并且糾正它的方向來指向全局最優點,那將是非常好的。
AdaGrad 算法通過沿著最陡的維度縮小梯度向量來實現這一點(見公式 11-6):

第一步將梯度的平方累加到矢量`s`中(`?`符號表示單元乘法)。 這個向量化形式相當于向量`s`的每個元素`si`計算 。換一種說法,每個 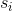 累加損失函數對參數  的偏導數的平方。 如果損失函數沿著第`i`維陡峭,則在每次迭代時,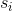 將變得越來越大。
第二步幾乎與梯度下降相同,但有一個很大的不同:梯度矢量按比例縮小 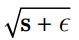(`?`符號表示元素分割,`ε`是避免被零除的平滑項,通常設置為 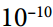。 這個矢量化的形式相當于計算 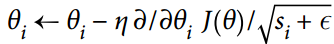 對于所有參數 (同時)。
簡而言之,這種算法會降低學習速度,但對于陡峭的尺寸,其速度要快于具有溫和的斜率的尺寸。 這被稱為自適應學習率。 它有助于將更新的結果更直接地指向全局最優(見圖 11-7)。 另一個好處是它不需要那么多的去調整學習率超參數`η`。
對于簡單的二次問題,AdaGrad 經常表現良好,但不幸的是,在訓練神經網絡時,它經常停止得太早。 學習率被縮減得太多,以至于在達到全局最優之前,算法完全停止。 所以,即使 TensorFlow 有一個`AdagradOptimizer`,你也不應該用它來訓練深度神經網絡(雖然對線性回歸這樣簡單的任務可能是有效的)。
## RMSProp
盡管 AdaGrad 的速度變慢了一點,并且從未收斂到全局最優,但是 RMSProp 算法通過僅累積最近迭代(而不是從訓練開始以來的所有梯度)的梯度來修正這個問題。 它通過在第一步中使用指數衰減來實現(見公式 11-7)。

他的衰變率`β`通常設定為 0.9。 是的,它又是一個新的超參數,但是這個默認值通常運行良好,所以你可能根本不需要調整它。
正如您所料,TensorFlow 擁有一個`RMSPropOptimizer`類:

除了非常簡單的問題,這個優化器幾乎總是比 AdaGrad 執行得更好。 它通常也比動量優化和 Nesterov 加速梯度表現更好。 事實上,這是許多研究人員首選的優化算法,直到 Adam 優化出現。
## Adam 優化
Adam,代表自適應矩估計,結合了動量優化和 RMSProp 的思想:就像動量優化一樣,它追蹤過去梯度的指數衰減平均值,就像 RMSProp 一樣,它跟蹤過去平方梯度的指數衰減平均值 (見方程式 11-8)。

T 代表迭代次數(從 1 開始)。
如果你只看步驟 1, 2 和 5,你會注意到 Adam 與動量優化和 RMSProp 的相似性。 唯一的區別是第 1 步計算指數衰減的平均值,而不是指數衰減的和,但除了一個常數因子(衰減平均值只是衰減和的`1 - β1`倍)之外,它們實際上是等效的。 步驟 3 和步驟 4 是一個技術細節:由于`m`和`s`初始化為 0,所以在訓練開始時它們會偏向0,所以這兩步將在訓練開始時幫助提高`m`和`s`。
動量衰減超參數`β1`通常初始化為 0.9,而縮放衰減超參數`β2`通常初始化為 0.999。 如前所述,平滑項`ε`通常被初始化為一個很小的數,例如 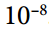。這些是 TensorFlow 的`AdamOptimizer`類的默認值,所以你可以簡單地使用:

實際上,由于 Adam 是一種自適應學習率算法(如 AdaGrad 和 RMSProp),所以對學習率超參數`η`的調整較少。 您經常可以使用默認值`η= 0.001`,使 Adam 更容易使用相對于梯度下降。
迄今為止所討論的所有優化技術都只依賴于一階偏導數(雅可比矩陣)。 優化文獻包含基于二階偏導數(海森矩陣)的驚人算法。 不幸的是,這些算法很難應用于深度神經網絡,因為每個輸出有`n ^ 2`個海森值(其中`n`是參數的數量),而不是每個輸出只有`n`個雅克比值。 由于 DNN 通常具有數以萬計的參數,二階優化算法通常甚至不適合內存,甚至在他們這樣做時,計算海森矩陣也是太慢了。
## 訓練稀疏模型
所有剛剛提出的優化算法都會產生密集的模型,這意味著大多數參數都是非零的。 如果你在運行時需要一個非常快速的模型,或者如果你需要它占用較少的內存,你可能更喜歡用一個稀疏模型來代替。
實現這一點的一個微不足道的方法是像平常一樣訓練模型,然后擺脫微小的權重(將它們設置為 0)。
另一個選擇是在訓練過程中應用強 l1 正則化,因為它會推動優化器盡可能多地消除權重(如第 4 章關于 Lasso 回歸的討論)。
但是,在某些情況下,這些技術可能仍然不足。 最后一個選擇是應用雙重平均,通常稱為遵循正則化領導者(FTRL),一種由尤里·涅斯捷羅夫(Yurii Nesterov)提出的技術。 當與 l1 正則化一起使用時,這種技術通常導致非常稀疏的模型。 TensorFlow 在`FTRLOptimizer`類中實現稱為 FTRL-Proximal 的 FTRL 變體。
## 學習率調整
找到一個好的學習速度可能會非常棘手。 如果設置太高,訓練實際上可能偏離(如我們在第 4 章)。 如果設置得太低,訓練最終會收斂到最佳狀態,但這需要很長時間。 如果將其設置得太高,開始的進度會非常快,但最終會在最優解周圍跳動,永遠不會安頓下來(除非您使用自適應學習率優化算法,如 AdaGrad,RMSProp 或 Adam,但是 即使這樣可能需要時間來解決)。 如果您的計算預算有限,那么您可能必須在正確收斂之前中斷訓練,產生次優解決方案(參見圖 11-8)。
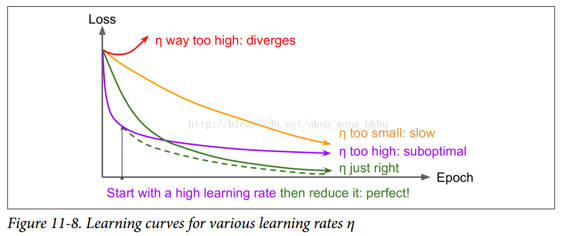
通過使用各種學習率和比較學習曲線,在幾個迭代內對您的網絡進行多次訓練,您也許能夠找到相當好的學習率。 理想的學習率將會快速學習并收斂到良好的解決方案。
然而,你可以做得比不斷的學習率更好:如果你從一個高的學習率開始,然后一旦它停止快速的進步就減少它,你可以比最佳的恒定學習率更快地達到一個好的解決方案。 有許多不同的策略,以減少訓練期間的學習率。 這些策略被稱為學習率調整(我們在第 4 章中簡要介紹了這個概念),其中最常見的是:
預定的分段恒定學習率:
例如,首先將學習率設置為 ,然后在 50 個迭代之后將學習率設置為 。雖然這個解決方案可以很好地工作,但是通常需要弄清楚正確的學習速度以及何時使用它們。
性能調度:
每 N 步測量驗證誤差(就像提前停止一樣),當誤差下降時,將學習率降低一個因子`λ`。
指數調度:
將學習率設置為迭代次數`t`的函數: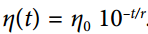。 這很好,但它需要調整`η0`和`r`。 學習率將由每`r`步下降 10 倍。
冪調度:
設學習率為 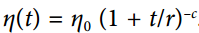。 超參數`c`通常被設置為 1。這與指數調度類似,但是學習率下降要慢得多。
Andrew Senior 等2013年的論文。 比較了使用動量優化訓練深度神經網絡進行語音識別時一些最流行的學習率調整的性能。 作者得出結論:在這種情況下,性能調度和指數調度都表現良好,但他們更喜歡指數調度,因為它實現起來比較簡單,容易調整,收斂速度略快于最佳解決方案。
使用 TensorFlow 實現學習率調整非常簡單:
```py
initial_learning_rate = 0.1
decay_steps = 10000
decay_rate = 1/10
global_step = tf.Variable(0, trainable=False, name="global_step")
learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step,
decay_steps, decay_rate)
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)
training_op = optimizer.minimize(loss, global_step=global_step)
```
設置超參數值后,我們創建一個不可訓練的變量`global_step`(初始化為 0)以跟蹤當前的訓練迭代次數。 然后我們使用 TensorFlow 的`exponential_decay()`函數來定義指數衰減的學習率(`η0= 0.1`和`r = 10,000`)。 接下來,我們使用這個衰減的學習率創建一個優化器(在這個例子中是一個`MomentumOptimizer`)。 最后,我們通過調用優化器的`minimize()`方法來創建訓練操作;因為我們將`global_step`變量傳遞給它,所以請注意增加它。 就是這樣!
由于 AdaGrad,RMSProp 和 Adam 優化自動降低了訓練期間的學習率,因此不需要添加額外的學習率調整。 對于其他優化算法,使用指數衰減或性能調度可顯著加速收斂。
完整代碼:
```py
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 50
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
```
```py
with tf.name_scope("train"): # not shown in the book
initial_learning_rate = 0.1
decay_steps = 10000
decay_rate = 1/10
global_step = tf.Variable(0, trainable=False, name="global_step")
learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step,
decay_steps, decay_rate)
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)
training_op = optimizer.minimize(loss, global_step=global_step)
```
```py
init = tf.global_variables_initializer()
saver = tf.train.Saver()
```
```py
n_epochs = 5
batch_size = 50
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_model_final.ckpt")
```
## 通過正則化避免過擬合
有四個參數,我可以擬合一個大象,五個我可以讓他擺動他的象鼻。
—— John von Neumann,cited by Enrico Fermi in Nature 427
深度神經網絡通常具有數以萬計的參數,有時甚至是數百萬。 有了這么多的參數,網絡擁有難以置信的自由度,可以適應各種復雜的數據集。 但是這個很大的靈活性也意味著它很容易過擬合訓練集。
有了數以百萬計的參數,你可以適應整個動物園。 在本節中,我們將介紹一些最流行的神經網絡正則化技術,以及如何用 TensorFlow 實現它們:早期停止,l1 和 l2 正則化,drop out,最大范數正則化和數據增強。
## 早期停止
為避免過度擬合訓練集,一個很好的解決方案就是盡早停止訓練(在第 4 章中介紹):只要在訓練集的性能開始下降時中斷訓練。
與 TensorFlow 實現方法之一是評估其對設置定期(例如,每 50 步)驗證模型,并保存一個“winner”的快照,如果它優于以前“winner”的快照。 計算自上次“winner”快照保存以來的步數,并在達到某個限制時(例如 2000 步)中斷訓練。 然后恢復最后的“winner”快照。
雖然早期停止在實踐中運行良好,但是通過將其與其他正則化技術相結合,您通常可以在網絡中獲得更高的性能。
## L1 和 L2 正則化
就像你在第 4 章中對簡單線性模型所做的那樣,你可以使用 l1 和 l2 正則化約束一個神經網絡的連接權重(但通常不是它的偏置)。
使用 TensorFlow 做到這一點的一種方法是簡單地將適當的正則化項添加到您的損失函數中。 例如,假設您只有一個權重為`weights1`的隱藏層和一個權重為`weight2`的輸出層,那么您可以像這樣應用 l1 正則化:
我們可以將正則化函數傳遞給`tf.layers.dense()`函數,該函數將使用它來創建計算正則化損失的操作,并將這些操作添加到正則化損失集合中。 開始和上面一樣:
```py
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 50
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
```
接下來,我們將使用 Python `partial()`函數來避免一遍又一遍地重復相同的參數。 請注意,我們設置了內核正則化參數(正則化函數有`l1_regularizer()`,`l2_regularizer()`,`l1_l2_regularizer()`):
```py
scale = 0.001
```
```py
my_dense_layer = partial(
tf.layers.dense, activation=tf.nn.relu,
kernel_regularizer=tf.contrib.layers.l1_regularizer(scale))
with tf.name_scope("dnn"):
hidden1 = my_dense_layer(X, n_hidden1, name="hidden1")
hidden2 = my_dense_layer(hidden1, n_hidden2, name="hidden2")
logits = my_dense_layer(hidden2, n_outputs, activation=None,
name="outputs")
```
該代碼創建了一個具有兩個隱藏層和一個輸出層的神經網絡,并且還在圖中創建節點以計算與每個層的權重相對應的 l1 正則化損失。TensorFlow 會自動將這些節點添加到包含所有正則化損失的特殊集合中。 您只需要將這些正則化損失添加到您的整體損失中,如下所示:
接下來,我們必須將正則化損失加到基本損失上:
```py
with tf.name_scope("loss"): # not shown in the book
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits( # not shown
labels=y, logits=logits) # not shown
base_loss = tf.reduce_mean(xentropy, name="avg_xentropy") # not shown
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
loss = tf.add_n([base_loss] + reg_losses, name="loss")
```
其余的和往常一樣:
```py
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
```
```py
n_epochs = 20
batch_size = 200
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_model_final.ckpt")
```
不要忘記把正則化的損失加在你的整體損失上,否則就會被忽略。
## Dropout
深度神經網絡最流行的正則化技術可以說是 dropout。 它由 GE Hinton 于 2012 年提出,并在 Nitish Srivastava 等人的論文中進一步詳細描述,并且已被證明是非常成功的:即使是最先進的神經網絡,僅僅通過增加丟失就可以提高1-2%的準確度。 這聽起來可能不是很多,但是當一個模型已經具有 95% 的準確率時,獲得 2% 的準確度提升意味著將誤差率降低近 40%(從 5% 誤差降至大約 3%)。
這是一個相當簡單的算法:在每個訓練步驟中,每個神經元(包括輸入神經元,但不包括輸出神經元)都有一個暫時“丟棄”的概率`p`,這意味著在這個訓練步驟中它將被完全忽略, 在下一步可能會激活(見圖 11-9)。 超參數`p`稱為丟失率,通常設為 50%。 訓練后,神經元不會再下降。 這就是全部(除了我們將要討論的技術細節)。

一開始這個技術是相當粗魯,這是相當令人驚訝的。如果一個公司的員工每天早上被告知要擲硬幣來決定是否上班,公司的表現會不會更好呢?那么,誰知道;也許會!公司顯然將被迫適應這樣的組織構架;它不能依靠任何一個人填寫咖啡機或執行任何其他關鍵任務,所以這個專業知識將不得不分散在幾個人身上。員工必須學會與其他的許多同事合作,而不僅僅是其中的一小部分。該公司將變得更有彈性。如果一個人離開了,并沒有什么區別。目前還不清楚這個想法是否真的可以在公司實行,但它確實對于神經網絡是可以的。神經元被dropout訓練不能與其相鄰的神經元共適應;他們必須盡可能讓自己變得有用。他們也不能過分依賴一些輸入神經元;他們必須注意他們的每個輸入神經元。他們最終對輸入的微小變化會不太敏感。最后,你會得到一個更強大的網絡,更好地推廣。
了解 dropout 的另一種方法是認識到每個訓練步驟都會產生一個獨特的神經網絡。 由于每個神經元可以存在或不存在,總共有`2 ^ N`個可能的網絡(其中 N 是可丟棄神經元的總數)。 這是一個巨大的數字,實際上不可能對同一個神經網絡進行兩次采樣。 一旦你運行了 10,000 個訓練步驟,你基本上已經訓練了 10,000 個不同的神經網絡(每個神經網絡只有一個訓練實例)。 這些神經網絡顯然不是獨立的,因為它們共享許多權重,但是它們都是不同的。 由此產生的神經網絡可以看作是所有這些較小的神經網絡的平均集成。
有一個小而重要的技術細節。 假設`p = 50%`,在這種情況下,在測試期間,在訓練期間神經元將被連接到兩倍于(平均)的輸入神經元。 為了彌補這個事實,我們需要在訓練之后將每個神經元的輸入連接權重乘以 0.5。 如果我們不這樣做,每個神經元的總輸入信號大概是網絡訓練的兩倍,這不太可能表現良好。 更一般地說,我們需要將每個輸入連接權重乘以訓練后的保持概率(`1-p`)。 或者,我們可以在訓練過程中將每個神經元的輸出除以保持概率(這些替代方案并不完全等價,但它們工作得同樣好)。
要使用 TensorFlow 實現dropout,可以簡單地將`dropout()`函數應用于輸入層和每個隱藏層的輸出。 在訓練過程中,這個功能隨機丟棄一些節點(將它們設置為 0),并用保留概率來劃分剩余項目。 訓練結束后,這個函數什么都不做。下面的代碼將dropout正則化應用于我們的三層神經網絡:
注意:本書使用`tf.contrib.layers.dropout()`而不是`tf.layers.dropout()`(本章寫作時不存在)。 現在最好使用`tf.layers.dropout()`,因為`contrib`模塊中的任何內容都可能會改變或被刪除,恕不另行通知。`tf.layers.dropout()`函數幾乎與`tf.contrib.layers.dropout()`函數相同,只是有一些細微差別。 最重要的是:
* 您必須指定丟失率(率)而不是保持概率(`keep_prob`),其中`rate`簡單地等于`1 - keep_prob`
* `is_training`參數被重命名為`training`。
```py
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
```
```py
training = tf.placeholder_with_default(False, shape=(), name='training')
dropout_rate = 0.5 # == 1 - keep_prob
X_drop = tf.layers.dropout(X, dropout_rate, training=training)
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X_drop, n_hidden1, activation=tf.nn.relu,
name="hidden1")
hidden1_drop = tf.layers.dropout(hidden1, dropout_rate, training=training)
hidden2 = tf.layers.dense(hidden1_drop, n_hidden2, activation=tf.nn.relu,
name="hidden2")
hidden2_drop = tf.layers.dropout(hidden2, dropout_rate, training=training)
logits = tf.layers.dense(hidden2_drop, n_outputs, name="outputs")
```
```py
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
```
```py
n_epochs = 20
batch_size = 50
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})
acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels})
print(epoch, "Test accuracy:", acc_test)
save_path = saver.save(sess, "./my_model_final.ckpt")
```
你想在`tensorflow.contrib.layers`中使用`dropout()`函數,而不是`tensorflow.nn`中的那個。 第一個在不訓練的時候關掉(沒有操作),這是你想要的,而第二個不是。
如果觀察到模型過擬合,則可以增加 dropout 率(即,減少`keep_prob`超參數)。 相反,如果模型欠擬合訓練集,則應嘗試降低 dropout 率(即增加`keep_prob`)。 它也可以幫助增加大層的 dropout 率,并減少小層的 dropout 率。
dropout 似乎減緩了收斂速度,但通常會在調整得當時使模型更好。 所以,這通常值得花費額外的時間和精力。
Dropconnect是dropout的變體,其中單個連接隨機丟棄而不是整個神經元。 一般而言,dropout表現會更好。
## 最大范數正則化
另一種在神經網絡中非常流行的正則化技術被稱為最大范數正則化:對于每個神經元,它約束輸入連接的權重`w`,使得 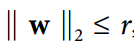,其中`r`是最大范數超參數,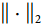 是 l2 范數。
我們通常通過在每個訓練步驟之后計算 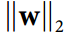 來實現這個約束,并且如果需要的話可以剪切`W` 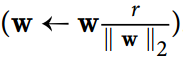。
減少`r`增加了正則化的數量,并有助于減少過擬合。 最大范數正則化還可以幫助減輕梯度消失/爆炸問題(如果您不使用批量標準化)。
讓我們回到 MNIST 的簡單而簡單的神經網絡,只有兩個隱藏層:
```py
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 50
n_outputs = 10
learning_rate = 0.01
momentum = 0.9
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
```
接下來,讓我們來處理第一個隱藏層的權重,并創建一個操作,使用`clip_by_norm()`函數計算剪切后的權重。 然后我們創建一個賦值操作來將權值賦給權值變量:
```py
threshold = 1.0
weights = tf.get_default_graph().get_tensor_by_name("hidden1/kernel:0")
clipped_weights = tf.clip_by_norm(weights, clip_norm=threshold, axes=1)
clip_weights = tf.assign(weights, clipped_weights)
```
我們也可以為第二個隱藏層做到這一點:
```py
weights2 = tf.get_default_graph().get_tensor_by_name("hidden2/kernel:0")
clipped_weights2 = tf.clip_by_norm(weights2, clip_norm=threshold, axes=1)
clip_weights2 = tf.assign(weights2, clipped_weights2)
```
讓我們添加一個初始化器和一個保存器:
```py
init = tf.global_variables_initializer()
saver = tf.train.Saver()
```
現在我們可以訓練模型。 與往常一樣,除了在運行`training_op`之后,我們運行`clip_weights`和`clip_weights2`操作:
```py
n_epochs = 20
batch_size = 50
```
```py
with tf.Session() as sess: # not shown in the book
init.run() # not shown
for epoch in range(n_epochs): # not shown
for iteration in range(mnist.train.num_examples // batch_size): # not shown
X_batch, y_batch = mnist.train.next_batch(batch_size) # not shown
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
clip_weights.eval()
clip_weights2.eval() # not shown
acc_test = accuracy.eval(feed_dict={X: mnist.test.images, # not shown
y: mnist.test.labels}) # not shown
print(epoch, "Test accuracy:", acc_test) # not shown
save_path = saver.save(sess, "./my_model_final.ckpt") # not shown
```
上面的實現很簡單,工作正常,但有點麻煩。 更好的方法是定義一個`max_norm_regularizer()`函數:
```py
def max_norm_regularizer(threshold, axes=1, name="max_norm",
collection="max_norm"):
def max_norm(weights):
clipped = tf.clip_by_norm(weights, clip_norm=threshold, axes=axes)
clip_weights = tf.assign(weights, clipped, name=name)
tf.add_to_collection(collection, clip_weights)
return None # there is no regularization loss term
return max_norm
```
然后你可以調用這個函數來得到一個最大范數調節器(與你想要的閾值)。 當你創建一個隱藏層時,你可以將這個正則化器傳遞給`kernel_regularizer`參數:
```py
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 50
n_outputs = 10
learning_rate = 0.01
momentum = 0.9
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
```
```py
max_norm_reg = max_norm_regularizer(threshold=1.0)
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,
kernel_regularizer=max_norm_reg, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu,
kernel_regularizer=max_norm_reg, name="hidden2")
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
```
```py
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
```
訓練與往常一樣,除了每次訓練后必須運行重量裁剪操作:
請注意,最大范數正則化不需要在整體損失函數中添加正則化損失項,所以`max_norm()`函數返回`None`。 但是,在每個訓練步驟之后,仍需要運行`clip_weights`操作,因此您需要能夠掌握它。 這就是為什么`max_norm()`函數將`clip_weights`節點添加到最大范數剪裁操作的集合中的原因。您需要獲取這些裁剪操作并在每個訓練步驟后運行它們:
```py
n_epochs = 20
batch_size = 50
```
```py
clip_all_weights = tf.get_collection("max_norm")
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
sess.run(clip_all_weights)
acc_test = accuracy.eval(feed_dict={X: mnist.test.images, # not shown in the book
y: mnist.test.labels}) # not shown
print(epoch, "Test accuracy:", acc_test) # not shown
save_path = saver.save(sess, "./my_model_final.ckpt") # not shown
```
## 數據增強
最后一個正則化技術,數據增強,包括從現有的訓練實例中產生新的訓練實例,人為地增加了訓練集的大小。 這將減少過擬合,使之成為正則化技術。 訣竅是生成逼真的訓練實例; 理想情況下,一個人不應該能夠分辨出哪些是生成的,哪些不是生成的。 而且,簡單地加白噪聲也無濟于事。 你應用的修改應該是可以學習的(白噪聲不是)。
例如,如果您的模型是為了分類蘑菇圖片,您可以稍微移動,旋轉和調整訓練集中的每個圖片的大小,并將結果圖片添加到訓練集(見圖 11-10)。 這迫使模型更能容忍圖片中蘑菇的位置,方向和大小。 如果您希望模型對光照條件更加寬容,則可以類似地生成具有各種對比度的許多圖像。 假設蘑菇是對稱的,你也可以水平翻轉圖片。 通過結合這些轉換,可以大大增加訓練集的大小。

通常最好在訓練期間生成訓練實例,而不是浪費存儲空間和網絡帶寬。TensorFlow 提供了多種圖像處理操作,例如轉置(移位),旋轉,調整大小,翻轉和裁剪,以及調整亮度,對比度,飽和度和色調(請參閱 API 文檔以獲取更多詳細信息)。 這可以很容易地為圖像數據集實現數據增強。
訓練非常深的神經網絡的另一個強大的技術是添加跳過連接(跳過連接是將層的輸入添加到更高層的輸出時)。 我們將在第 13 章中談論深度殘差網絡時探討這個想法。
## 實踐指南
在本章中,我們已經涵蓋了很多技術,你可能想知道應該使用哪些技術。 表 11-2 中的配置在大多數情況下都能正常工作。

當然,如果你能找到解決類似問題的方法,你應該嘗試重用預訓練的神經網絡的一部分。
這個默認配置可能需要調整:
* 如果你找不到一個好的學習率(收斂速度太慢,所以你增加了訓練速度,現在收斂速度很快,但是網絡的準確性不是最理想的),那么你可以嘗試添加一個學習率調整,如指數衰減。
* 如果你的訓練集太小,你可以實現數據增強。
* 如果你需要一個稀疏的模型,你可以添加 l1 正則化混合(并可以選擇在訓練后將微小的權重歸零)。 如果您需要更稀疏的模型,您可以嘗試使用 FTRL 而不是 Adam 優化以及 l1 正則化。
* 如果在運行時需要快速模型,則可能需要刪除批量標準化,并可能用 leakyReLU 替換 ELU 激活函數。 有一個稀疏的模型也將有所幫助。
有了這些指導方針,你現在已經準備好訓練非常深的網絡 - 好吧,如果你非常有耐心的話,那就是! 如果使用單臺機器,則可能需要等待幾天甚至幾個月才能完成訓練。 在下一章中,我們將討論如何使用分布式 TensorFlow 在許多服務器和 GPU 上訓練和運行模型。
## 練習
1. 使用 He 初始化隨機選擇權重,是否可以將所有權重初始化為相同的值?
1. 可以將偏置初始化為 0 嗎?
1. 說出 ELU 激活功能與 ReLU 相比的三個優點。
1. 在哪些情況下,您想要使用以下每個激活函數:ELU,leaky ReLU(及其變體),ReLU,tanh,logistic 以及 softmax?
1. 使用`MomentumOptimizer`時,如果將`momentum`超參數設置得太接近 1(例如,0.99999),會發生什么情況?
1. 請列舉您可以生成稀疏模型的三種方法。
1. dropout 是否會減慢訓練? 它是否會減慢推斷(即預測新的實例)?
1. 深度學習。
1. 建立一個 DNN,有五個隱藏層,每層 100 個神經元,使用 He 初始化和 ELU 激活函數。
1. 使用 Adam 優化和提前停止,請嘗試在 MNIST 上進行訓練,但只能使用數字 0 到 4,因為我們將在下一個練習中在數字 5 到 9 上進行遷移學習。 您需要一個包含五個神經元的 softmax 輸出層,并且一如既往地確保定期保存檢查點,并保存最終模型,以便稍后再使用它。
1. 使用交叉驗證調整超參數,并查看你能達到什么準確度。
1. 現在嘗試添加批量標準化并比較學習曲線:它是否比以前收斂得更快? 它是否會產生更好的模型?
1. 模型是否過擬合訓練集? 嘗試將 dropout 添加到每一層,然后重試。 它有幫助嗎?
1. 遷移學習。
1. 創建一個新的 DNN,它復制先前模型的所有預訓練的隱藏層,凍結它們,并用新的一層替換 softmax 輸出層。
1. 在數字 5 到 9 訓練這個新的 DNN ,每個數字只使用 100 個圖像,需要多長時間? 盡管樣本這么少,你能達到高準確度嗎?
1. 嘗試緩存凍結的層,并再次訓練模型:現在速度有多快?
1. 再次嘗試復用四個隱藏層而不是五個。 你能達到更高的準確度嗎?
1. 現在,解凍前兩個隱藏層并繼續訓練:您可以讓模型表現得更好嗎?
1. 輔助任務的預訓練。
1. 在本練習中,你將構建一個 DNN,用于比較兩個 MNIST 數字圖像,并預測它們是否代表相同的數字。 然后,你將復用該網絡的較低層,來使用非常少的訓練數據來訓練 MNIST 分類器。 首先構建兩個 DNN(我們稱之為 DNN A 和 B),它們與之前構建的 DNN 類似,但沒有輸出層:每個 DNN 應該有五個隱藏層,每個層包含 100 個神經元,使用 He 初始化和 ELU 激活函數。 接下來,在兩個 DNN 上添加一個輸出層。 你應該使用 TensorFlow 的`concat()函數和`axis = 1`,將兩個 DNN 的輸出沿著橫軸連接,然后將結果輸入到輸出層。 輸出層應該包含單個神經元,使用 logistic 激活函數。
1. 將 MNIST 訓練集分為兩組:第一部分應包含 55,000個 圖像,第二部分應包含 5000 個圖像。 創建一個生成訓練批次的函數,其中每個實例都是從第一部分中挑選的一對 MNIST 圖像。 一半的訓練實例應該是屬于同一類的圖像對,而另一半應該是來自不同類別的圖像。 對于每一對,如果圖像來自同一類,訓練標簽應該為 0;如果來自不同類,則標簽應為 1。
1. 在這個訓練集上訓練 DNN。 對于每個圖像對,你可以同時將第一張圖像送入 DNN A,將第二張圖像送入 DNN B。整個網絡將逐漸學會判斷兩張圖像是否屬于同一類別。
1. 現在通過復用和凍結 DNN A 的隱藏層,并添加 1 0個神經元的 softmax 輸出層來創建一個新的 DNN。 在第二部分上訓練這個網絡,看看你是否可以實現較好的表現,盡管每類只有 500 個圖像。
這些問題的答案在附錄 A 中。
