# 十四、循環神經網絡
> 譯者:[@akonwang](https://github.com/wangxupeng)、[@alexcheen](https://github.com/alexcheen)、[@飛龍](https://github.com/wizardforcel)
>
> 校對者:[@飛龍](https://github.com/wizardforcel)
擊球手擊出壘球,你會開始預測球的軌跡并立即開始奔跑。你追蹤著它,不斷調整你的移動步伐,最終在觀眾的一片雷鳴聲中抓到它。無論是在聽完朋友的話語還是早餐時預測咖啡的味道,你時刻在做的事就是在預測未來。在本章中,我們將討論循環神經網絡 -- 一類預測未來的網絡(當然,是到目前為止)。它們可以分析時間序列數據,諸如股票價格,并告訴你什么時候買入和賣出。在自動駕駛系統中,他們可以預測行車軌跡,避免發生交通意外。更一般地說,它們可在任意長度的序列上工作,而不是截止目前我們討論的只能在固定長度的輸入上工作的網絡。舉個例子,它們可以把語句,文件,以及語音范本作為輸入,使得它們在諸如自動翻譯,語音到文本或者情感分析(例如,讀取電影評論并提取評論者關于該電影的感覺)的自然語言處理系統中極為有用。
更近一步,循環神經網絡的預測能力使得它們具備令人驚訝的創造力。你同樣可以要求它們去預測一段旋律的下幾個音符,然后隨機選取這些音符的其中之一并演奏它。然后要求網絡給出接下來最可能的音符,演奏它,如此周而復始。在你知道它之前,你的神經網絡將創作一首諸如由谷歌 Magenta 工程所創造的《The one》的歌曲。類似的,循環神經網絡可以生成語句,圖像標注以及更多。目前結果還不能準確得到莎士比亞或者莫扎特的作品,但誰知道幾年后他們能生成什么呢?
在本章中,我們將看到循環神經網絡背后的基本概念,他們所面臨的主要問題(換句話說,在第11章中討論的消失/爆炸的梯度),以及廣泛用于反抗這些問題的方法:LSTM 和 GRU cell(單元)。如同以往,沿著這個方式,我們將展示如何用 TensorFlow 實現循環神經網絡。最終我們將看看及其翻譯系統的架構。
## 循環神經元
到目前為止,我們主要關注的是前饋神經網絡,其中激活僅從輸入層到輸出層的一個方向流動(附錄 E 中的幾個網絡除外)。 循環神經網絡看起來非常像一個前饋神經網絡,除了它也有連接指向后方。 讓我們看一下最簡單的 RNN,它由一個神經元接收輸入,產生一個輸出,并將輸出發送回自己,如圖 14-1(左)所示。 在每個時間步`t`(也稱為一個幀),這個循環神經元接收輸入  以及它自己的前一時間步長  的輸出。 我們可以用時間軸來表示這個微小的網絡,如圖 14-1(右)所示。 這被稱為隨著時間的推移展開網絡。
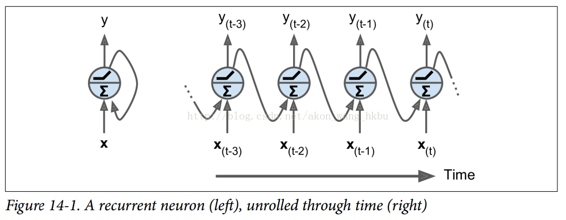
你可以輕松創建一個循環神經元層。 在每個時間步t,每個神經元都接收輸入向量  和前一個時間步  的輸出向量,如圖 14-2 所示。 請注意,輸入和輸出都是向量(當只有一個神經元時,輸出是一個標量)。

每個循環神經元有兩組權重:一組用于輸入 ,另一組用于前一時間步長  的輸出。 我們稱這些權重向量為  和 。如公式 14-1 所示(`b`是偏差項,`φ(·)`是激活函數,例如 ReLU),可以計算單個循環神經元的輸出。

就像前饋神經網絡一樣,我們可以使用上一個公式的向量化形式,對整個小批量計算整個層的輸出(見公式 14-2)。

*  是  矩陣,包含在最小批次中每個實例在時間步`t`處的層輸出(`m`是小批次中的實例數, 是神經元數)。
*  是  矩陣,包含所有實例的輸入的 (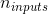 是輸入特征的數量)。
*  是  矩陣,包含當前時間步的輸入的連接權重的。
* 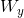 是  矩陣,包含上一個時間步的輸出的連接權重。
* 權重矩陣  和 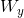 通常連接成單個權重矩陣`W`,形狀為 (見公式 14-2 的第二行)
* `b`是大小為  的向量,包含每個神經元的偏置項。
注意, 是  和  的函數,它是  和  的函數,它是  和  的函數,等等。 這使得  是從時間`t = 0`開始的所有輸入(即 ,,...,)的函數。 在第一個時間步,`t = 0`,沒有以前的輸出,所以它們通常被假定為全零。
## 記憶單元
由于時間`t`的循環神經元的輸出,是由所有先前時間步驟計算出來的的函數,你可以說它有一種記憶形式。一個神經網絡的一部分,跨越時間步長保留一些狀態,稱為存儲單元(或簡稱為單元)。單個循環神經元或循環神經元層是非常基本的單元,但本章后面我們將介紹一些更為復雜和強大的單元類型。
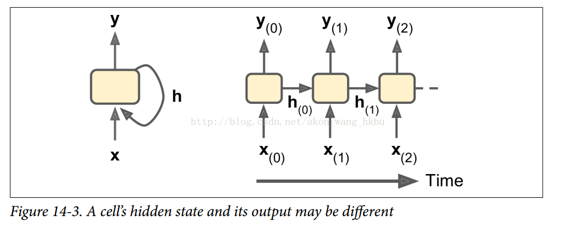
一般情況下,時間步`t`處的單元狀態,記為 (`h`代表“隱藏”),是該時間步的某些輸入和前一時間步的狀態的函數:。 其在時間步`t`處的輸出,表示為 ,也和前一狀態和當前輸入的函數有關。 在我們已經討論過的基本單元的情況下,輸出等于單元狀態,但是在更復雜的單元中并不總是如此,如圖 14-3 所示。
## 輸入和輸出序列
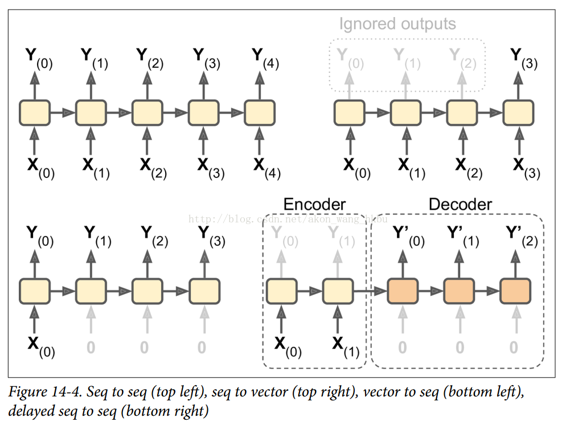
RNN 可以同時進行一系列輸入并產生一系列輸出(見圖 14-4,左上角的網絡)。 例如,這種類型的網絡對于預測時間序列(如股票價格)非常有用:你在過去的`N`天內給出價格,并且它必須輸出向未來一天移動的價格(即從`N - 1`天前到明天)。
或者,你可以向網絡輸入一系列輸入,并忽略除最后一個之外的所有輸出(請參閱右上角的網絡)。 換句話說,這是一個向量網絡的序列。 例如,你可以向網絡提供與電影評論相對應的單詞序列,并且網絡將輸出情感評分(例如,從`-1 [恨]`到`+1 [愛]`)。
相反,你可以在第一個時間步中為網絡提供一個輸入(而在其他所有時間步中為零),然后讓它輸出一個序列(請參閱左下角的網絡)。 這是一個向量到序列的網絡。 例如,輸入可以是圖像,輸出可以是該圖像的標題。
最后,你可以有一個序列到向量網絡,稱為編碼器,后面跟著一個稱為解碼器的向量到序列網絡(參見右下角的網絡)。 例如,這可以用于將句子從一種語言翻譯成另一種語言。 你會用一種語言給網絡喂一個句子,編碼器會把這個句子轉換成單一的向量表示,然后解碼器將這個向量解碼成另一種語言的句子。 這種稱為編碼器 - 解碼器的兩步模型,比用單個序列到序列的 RNN(如左上方所示的那個)快速地進行翻譯要好得多,因為句子的最后一個單詞可以 影響翻譯的第一句話,所以你需要等到聽完整個句子才能翻譯。
## TensorFlow 中的基本 RNN
首先,我們來實現一個非常簡單的 RNN 模型,而不使用任何 TensorFlow 的 RNN 操作,以更好地理解發生了什么。 我們將使用 tanh 激活函數創建由 5 個循環神經元的循環層組成的 RNN(如圖 14-2 所示的 RNN)。 我們將假設 RNN 只運行兩個時間步,每個時間步輸入大小為 3 的向量。 下面的代碼構建了這個 RNN,展開了兩個時間步驟:
```py
n_inputs = 3
n_neurons = 5
X0 = tf.placeholder(tf.float32, [None, n_inputs])
X1 = tf.placeholder(tf.float32, [None, n_inputs])
Wx = tf.Variable(tf.random_normal(shape=[n_inputs, n_neurons], dtype=tf.float32))
Wy = tf.Variable(tf.random_normal(shape=[n_neurons, n_neurons], dtype=tf.float32))
b = tf.Variable(tf.zeros([1, n_neurons], dtype=tf.float32))
Y0 = tf.tanh(tf.matmul(X0, Wx) + b)
Y1 = tf.tanh(tf.matmul(Y0, Wy) + tf.matmul(X1, Wx) + b)
init = tf.global_variables_initializer()
```
這個網絡看起來很像一個雙層前饋神經網絡,有一些改動:首先,兩個層共享相同的權重和偏差項,其次,我們在每一層都有輸入,并從每個層獲得輸出。 為了運行模型,我們需要在兩個時間步中都有輸入,如下所示:
```py
# Mini-batch: instance 0,instance 1,instance 2,instance 3
X0_batch = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 0, 1]]) # t = 0
X1_batch = np.array([[9, 8, 7], [0, 0, 0], [6, 5, 4], [3, 2, 1]]) # t = 1
with tf.Session() as sess:
init.run()
Y0_val, Y1_val = sess.run([Y0, Y1], feed_dict={X0: X0_batch, X1: X1_batch})
```
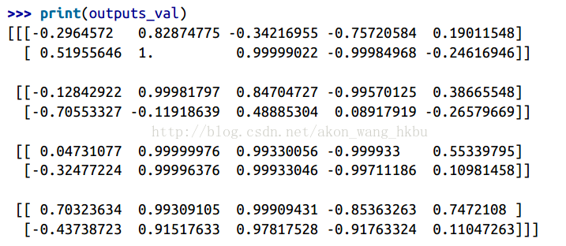
這個小批量包含四個實例,每個實例都有一個由兩個輸入組成的輸入序列。 最后,`Y0_val`和`Y1_val`在所有神經元和小批量中的所有實例的兩個時間步中包含網絡的輸出:
```py
>>> print(Y0_val) # output at t = 0
[[-0.2964572 0.82874775 -0.34216955 -0.75720584 0.19011548] # instance 0
[-0.12842922 0.99981797 0.84704727 -0.99570125 0.38665548] # instance 1
[ 0.04731077 0.99999976 0.99330056 -0.999933 0.55339795] # instance 2
[ 0.70323634 0.99309105 0.99909431 -0.85363263 0.7472108 ]] # instance 3
>>> print(Y1_val) # output at t = 1
[[ 0.51955646 1\. 0.99999022 -0.99984968 -0.24616946] # instance 0
[-0.70553327 -0.11918639 0.48885304 0.08917919 -0.26579669] # instance 1
[-0.32477224 0.99996376 0.99933046 -0.99711186 0.10981458] # instance 2
[-0.43738723 0.91517633 0.97817528 -0.91763324 0.11047263]] # instance 3
```
這并不難,但是當然如果你想能夠運行 100 多個時間步驟的 RNN,這個圖形將會非常大。 現在讓我們看看如何使用 TensorFlow 的 RNN 操作創建相同的模型。
完整代碼
```py
import numpy as np
import tensorflow as tf
if __name__ == '__main__':
n_inputs = 3
n_neurons = 5
X0 = tf.placeholder(tf.float32, [None, n_inputs])
X1 = tf.placeholder(tf.float32, [None, n_inputs])
Wx = tf.Variable(tf.random_normal(shape=[n_inputs, n_neurons], dtype=tf.float32))
Wy = tf.Variable(tf.random_normal(shape=[n_neurons, n_neurons], dtype=tf.float32))
b = tf.Variable(tf.zeros([1, n_neurons], dtype=tf.float32))
Y0 = tf.tanh(tf.matmul(X0, Wx) + b)
Y1 = tf.tanh(tf.matmul(Y0, Wy) + tf.matmul(X1, Wx) + b)
init = tf.global_variables_initializer()
# Mini-batch: instance 0,instance 1,instance 2,instance 3
X0_batch = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 0, 1]]) # t = 0
X1_batch = np.array([[9, 8, 7], [0, 0, 0], [6, 5, 4], [3, 2, 1]]) # t = 1
with tf.Session() as sess:
init.run()
Y0_val, Y1_val = sess.run([Y0, Y1], feed_dict={X0: X0_batch, X1: X1_batch})
print(Y0_val,'\n')
print(Y1_val)
```
## 時間上的靜態展開
`static_rnn()`函數通過鏈接單元來創建一個展開的 RNN 網絡。 下面的代碼創建了與上一個完全相同的模型:
```py
X0 = tf.placeholder(tf.float32, [None, n_inputs])
X1 = tf.placeholder(tf.float32, [None, n_inputs])
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
output_seqs, states = tf.contrib.rnn.static_rnn(basic_cell, [X0, X1],
dtype=tf.float32)
Y0, Y1 = output_seqs
```
首先,我們像以前一樣創建輸入占位符。 然后,我們創建一個`BasicRNNCell`,你可以將其視為一個工廠,創建單元的副本以構建展開的 RNN(每個時間步一個)。 然后我們調用`static_rnn()`,向它提供單元工廠和輸入張量,并告訴它輸入的數據類型(用來創建初始狀態矩陣,默認情況下是全零)。 `static_rnn()`函數為每個輸入調用單元工廠的`__call __()`函數,創建單元的兩個副本(每個單元包含 5 個循環神經元的循環層),并具有共享的權重和偏置項,像前面一樣。`static_rnn()`函數返回兩個對象。 第一個是包含每個時間步的輸出張量的 Python 列表。 第二個是包含網絡最終狀態的張量。 當你使用基本的單元時,最后的狀態就等于最后的輸出。
如果有 50 個時間步長,則不得不定義 50 個輸入占位符和 50 個輸出張量。而且,在執行時,你將不得不為 50 個占位符中的每個占位符輸入數據并且還要操縱 50 個輸出。我們來簡化一下。下面的代碼再次構建相同的 RNN,但是這次它需要一個形狀為`[None,n_steps,n_inputs]`的單個輸入占位符,其中第一個維度是最小批量大小。然后提取每個時間步的輸入序列列表。 `X_seqs`是形狀為`n_steps`的 Python 列表,包含形狀為`[None,n_inputs]`的張量,其中第一個維度同樣是最小批量大小。為此,我們首先使用`transpose()`函數交換前兩個維度,以便時間步驟現在是第一維度。然后,我們使 `unstack()`函數沿第一維(即每個時間步的一個張量)提取張量的 Python 列表。接下來的兩行和以前一樣。最后,我們使用`stack()`函數將所有輸出張量合并成一個張量,然后我們交換前兩個維度得到最終輸出張量,形狀為`[None, n_steps,n_neurons]`(第一個維度是小批量大小)。
```py
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
X_seqs = tf.unstack(tf.transpose(X, perm=[1, 0, 2]))
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
output_seqs, states = tf.contrib.rnn.static_rnn(basic_cell, X_seqs,
dtype=tf.float32)
outputs = tf.transpose(tf.stack(output_seqs), perm=[1, 0, 2])
```
現在我們可以通過給它提供一個包含所有小批量序列的張量來運行網絡:
```py
X_batch = np.array([
# t = 0 t = 1
[[0, 1, 2], [9, 8, 7]], # instance 1
[[3, 4, 5], [0, 0, 0]], # instance 2
[[6, 7, 8], [6, 5, 4]], # instance 3
[[9, 0, 1], [3, 2, 1]], # instance 4
])
with tf.Session() as sess:
init.run()
outputs_val = outputs.eval(feed_dict={X: X_batch})
```
我們得到所有實例,所有時間步長和所有神經元的單一`outputs_val`張量:
但是,這種方法仍然會建立一個每個時間步包含一個單元的圖。 如果有 50 個時間步,這個圖看起來會非常難看。 這有點像寫一個程序而沒有使用循環(例如,`Y0 = f(0,X0)`;`Y1 = f(Y0,X1)`;`Y2 = f(Y1,X2)`;...;`Y50 = f(Y49,X50)`)。 如果使用大圖,在反向傳播期間(特別是在 GPU 內存有限的情況下),你甚至可能會發生內存不足(OOM)錯誤,因為它必須在正向傳遞期間存儲所有張量值,以便可以使用它們在反向傳播期間計算梯度。
幸運的是,有一個更好的解決方案:`dynamic_rnn()`函數。
## 時間上的動態展開
`dynamic_rnn()`函數使用`while_loop()`操作,在單元上運行適當的次數,如果要在反向傳播期間將 GPU內 存交換到 CPU 內存,可以設置`swap_memory = True`,以避免內存不足錯誤。 方便的是,它還可以在每個時間步(形狀為`[None, n_steps, n_inputs]`)接受所有輸入的單個張量,并且在每個時間步(形狀`[None, n_steps, n_neurons]`)上輸出所有輸出的單個張量。 沒有必要堆疊,拆散或轉置。 以下代碼使用`dynamic_rnn()`函數創建與之前相同的 RNN。 這太好了!
完整代碼
```py
import numpy as np
import tensorflow as tf
import pandas as pd
if __name__ == '__main__':
n_steps = 2
n_inputs = 3
n_neurons = 5
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
outputs, states = tf.nn.dynamic_rnn(basic_cell, X, dtype=tf.float32)
init = tf.global_variables_initializer()
X_batch = np.array([
[[0, 1, 2], [9, 8, 7]], # instance 1
[[3, 4, 5], [0, 0, 0]], # instance 2
[[6, 7, 8], [6, 5, 4]], # instance 3
[[9, 0, 1], [3, 2, 1]], # instance 4
])
with tf.Session() as sess:
init.run()
outputs_val = outputs.eval(feed_dict={X: X_batch})
print(outputs_val)
```
在反向傳播期間,`while_loop()`操作會執行相應的步驟:在正向傳遞期間存儲每次迭代的張量值,以便在反向傳遞期間使用它們來計算梯度。
## 處理變長輸入序列
到目前為止,我們只使用固定大小的輸入序列(全部正好兩個步長)。 如果輸入序列具有可變長度(例如,像句子)呢? 在這種情況下,你應該在調用`dynamic_rnn()`(或`static_rnn()`)函數時設置`sequence_length`參數;它必須是一維張量,表示每個實例的輸入序列的長度。 例如:
```py
n_steps = 2
n_inputs = 3
n_neurons = 5
reset_graph()
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
```
```py
seq_length = tf.placeholder(tf.int32, [None])
outputs, states = tf.nn.dynamic_rnn(basic_cell, X, dtype=tf.float32,
sequence_length=seq_length)
```
例如,假設第二個輸入序列只包含一個輸入而不是兩個輸入。 為了適應輸入張量`X`,必須填充零向量(因為輸入張量的第二維是最長序列的大小,即 2)
```py
X_batch = np.array([
# step 0 step 1
[[0, 1, 2], [9, 8, 7]], # instance 1
[[3, 4, 5], [0, 0, 0]], # instance 2 (padded with zero vectors)
[[6, 7, 8], [6, 5, 4]], # instance 3
[[9, 0, 1], [3, 2, 1]], # instance 4
])
seq_length_batch = np.array([2, 1, 2, 2])
```
當然,你現在需要為兩個占位符`X`和`seq_length`提供值:
```py
with tf.Session() as sess:
init.run()
outputs_val, states_val = sess.run(
[outputs, states], feed_dict={X: X_batch, seq_length: seq_length_batch})
```
現在,RNN 輸出序列長度的每個時間步都會輸出零向量(查看第二個時間步的第二個輸出):
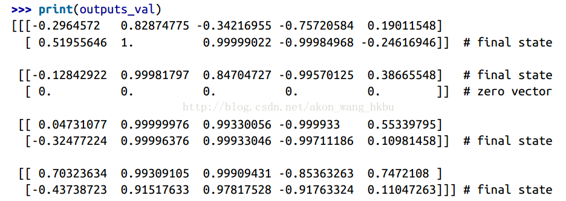
此外,狀態張量包含每個單元的最終狀態(不包括零向量):

## 處理變長輸出序列
如果輸出序列長度不一樣呢? 如果事先知道每個序列的長度(例如,如果知道長度與輸入序列的長度相同),那么可以按照上面所述設置`sequence_length`參數。 不幸的是,通常這是不可能的:例如,翻譯后的句子的長度通常與輸入句子的長度不同。 在這種情況下,最常見的解決方案是定義一個稱為序列結束標記(EOS 標記)的特殊輸出。 任何在 EOS 后面的輸出應該被忽略(我們將在本章稍后討論)。
好,現在你知道如何建立一個 RNN 網絡(或者更準確地說是一個隨著時間的推移而展開的 RNN 網絡)。 但是你怎么訓練呢?
## 訓練 RNN
為了訓練一個 RNN,訣竅是在時間上展開(就像我們剛剛做的那樣),然后簡單地使用常規反向傳播(見圖 14-5)。 這個策略被稱為時間上的反向傳播(BPTT)。
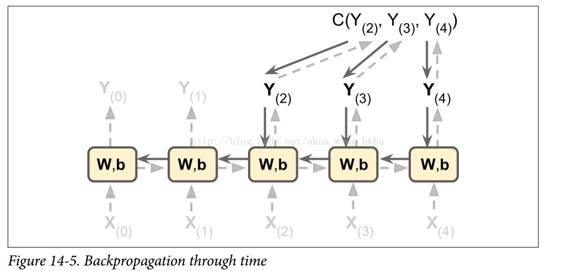
就像在正常的反向傳播中一樣,展開的網絡(用虛線箭頭表示)有第一個正向傳遞。然后使用損失函數評估輸出序列 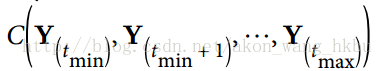(其中  和  是第一個和最后一個輸出時間步長,不計算忽略的輸出),并且該損失函數的梯度通過展開的網絡向后傳播(實線箭頭);最后使用在 BPTT 期間計算的梯度來更新模型參數。 請注意,梯度在損失函數所使用的所有輸出中反向流動,而不僅僅通過最終輸出(例如,在圖 14-5 中,損失函數使用網絡的最后三個輸出 , 和 ,所以梯度流經這三個輸出,但不通過  和 )。 而且,由于在每個時間步驟使用相同的參數`W`和`b`,所以反向傳播將做正確的事情并且總結所有時間步驟。
## 訓練序列分類器
我們訓練一個 RNN 來分類 MNIST 圖像。 卷積神經網絡將更適合于圖像分類(見第 13 章),但這是一個你已經熟悉的簡單例子。 我們將把每個圖像視為 28 行 28 像素的序列(因為每個MNIST圖像是`28×28`像素)。 我們將使用 150 個循環神經元的單元,再加上一個全連接層,其中包含連接到上一個時間步的輸出的 10 個神經元(每個類一個),然后是一個 softmax 層(見圖 14-6)。

建模階段非常簡單, 它和我們在第 10 章中建立的 MNIST 分類器幾乎是一樣的,只是展開的 RNN 替換了隱層。 注意,全連接層連接到狀態張量,其僅包含 RNN 的最終狀態(即,第 28 個輸出)。 另請注意,`y`是目標類的占位符。
```py
n_steps = 28
n_inputs = 28
n_neurons = 150
n_outputs = 10
learning_rate = 0.001
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.int32, [None])
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
outputs, states = tf.nn.dynamic_rnn(basic_cell, X, dtype=tf.float32)
logits = tf.layers.dense(states, n_outputs)
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,
logits=logits)
loss = tf.reduce_mean(xentropy)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(loss)
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
```
現在讓我們加載 MNIST 數據,并按照網絡的預期方式將測試數據重塑為`[batch_size, n_steps, n_inputs]`。 我們之后會關注訓練數據的重塑。
```py
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/")
X_test = mnist.test.images.reshape((-1, n_steps, n_inputs))
y_test = mnist.test.labels
```
現在我們準備訓練 RNN 了。 執行階段與第 10 章中 MNIST 分類器的執行階段完全相同,不同之處在于我們在將每個訓練的批量提供給網絡之前要重新調整。
```py
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
X_batch = X_batch.reshape((-1, n_steps, n_inputs))
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test})
print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)
```
輸出應該是這樣的:

我們獲得了超過 98% 的準確性 - 不錯! 另外,通過調整超參數,使用 He 初始化初始化 RNN 權重,更長時間訓練或添加一些正則化(例如,droupout),你肯定會獲得更好的結果。
你可以通過將其構造代碼包裝在一個變量作用域內(例如,使用`variable_scope("rnn", initializer = variance_scaling_initializer())`來使用 He 初始化)來為 RNN 指定初始化器。
## 為預測時間序列而訓練
現在讓我們來看看如何處理時間序列,如股價,氣溫,腦電波模式等等。 在本節中,我們將訓練一個 RNN 來預測生成的時間序列中的下一個值。 每個訓練實例是從時間序列中隨機選取的 20 個連續值的序列,目標序列與輸入序列相同,除了向后移動一個時間步(參見圖14-7)。
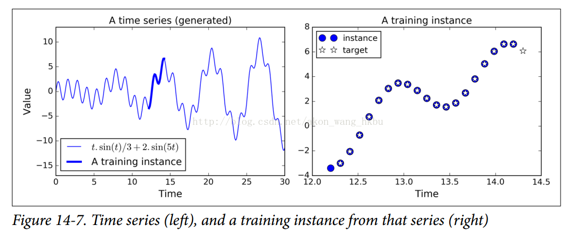
首先,我們來創建一個 RNN。 它將包含 100 個循環神經元,并且我們將在 20 個時間步驟上展開它,因為每個訓練實例將是 20 個輸入那么長。 每個輸入將僅包含一個特征(在該時間的值)。 目標也是 20 個輸入的序列,每個輸入包含一個值。 代碼與之前幾乎相同:
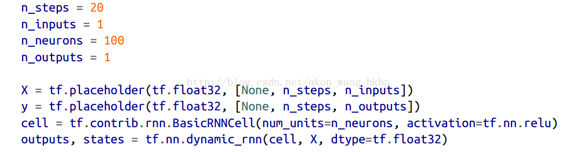
一般來說,你將不只有一個輸入功能。 例如,如果你試圖預測股票價格,則你可能在每個時間步驟都會有許多其他輸入功能,例如競爭股票的價格,分析師的評級或可能幫助系統進行預測的任何其他功能。
在每個時間步,我們現在有一個大小為 100 的輸出向量。但是我們實際需要的是每個時間步的單個輸出值。 最簡單的解決方法是將單元包裝在`OutputProjectionWrapper`中。 單元包裝器就像一個普通的單元,代理每個方法調用一個底層單元,但是它也增加了一些功能。`Out putProjectionWrapper`在每個輸出之上添加一個完全連接的線性神經元層(即沒有任何激活函數)(但不影響單元狀態)。 所有這些完全連接的層共享相同(可訓練)的權重和偏差項。 結果 RNN 如圖 14-8 所示。
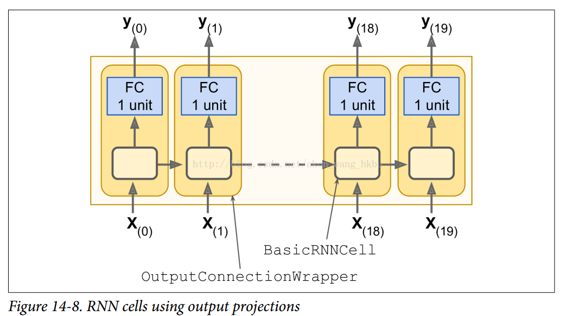
包裝單元是相當容易的。 讓我們通過將`BasicRNNCell`包裝到`OutputProjectionWrapper`中來調整前面的代碼:
```py
cell =tf.contrib.rnn.OutputProjectionWrapper(
tf.contrib.rnn.BasicRNNCell(num_units=n_neurons,activation=tf.nn.relu),
output_size=n_outputs)
```
到現在為止還挺好。 現在我們需要定義損失函數。 我們將使用均方誤差(MSE),就像我們在之前的回歸任務中所做的那樣。 接下來,我們將像往常一樣創建一個 Adam 優化器,訓練操作和變量初始化操作:
### 生成 RNN
到現在為止,我們已經訓練了一個能夠預測未來時刻樣本值的模型,正如前文所述,可以用模型來生成新的序列。
為模型提供 長度為`n_steps`的種子序列, 比如全零序列,然后通過模型預測下一時刻的值;把該預測值添加到種子序列的末尾,用最后面 長度為`n_steps`的序列做為新的種子序列,做下一次預測,以此類推生成預測序列。
如圖 14-11 所示,這個過程產生的序列會跟原始時間序列相似。

```python
sequence = [0.] * n_steps
for iteration in range(300):
X_batch = np.array(sequence[-n_steps:].reshape(1, n_steps, 1)
y_pred = sess.run(outputs, feed_dict={X: X_batch}
sequence.append(y_pred[0, -1, 0]
```
如果你試圖把約翰·列儂的唱片塞給一個 RNN 模型,看它能不能生成下一張《想象》專輯。
> 注
>
> 約翰·列儂 有一張專輯《Imagine》(1971),這里取其雙關的意思
也許你需要一個更強大的 RNN 網絡,它有更多的神經元,層數也更多。下面來探究一下深度 RNN。
## 深度 RNN
一個樸素的想法就是把一層層神經元堆疊起來,正如圖 14-12 所示的那樣,它呈現了一種深度 RNN。

為了用 TensorFlow 實現深度 RNN,可先創建一些神經單元,然后堆疊進`MultiRNNCell`。
以下代碼中創建了 3 個相同的神經單元(當然也可以用不同類別的、包含不同不同數量神經元的單元)
```python
n_neurons = 100
n_layers = 3
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
multi_layer_cell = tf.contrib.rnn.MultiRNNCell([basic_cell] * n_layers)
outputs, states = tf.nn.dynamic_rnn(multi_layer_cell, X, dtype=tf.float32)
```
這些代碼就完成了這部分堆疊工作。`status`變量包含了每層的一個張量,這個張量就代表了該層神經單元的最終狀態(維度為`[batch_size, n_neurons]`)。
如果在創建`MultiRNNCell`時設置了`state_is_tuple=False`,那么`status`變量就變成了單個張量,它包含了每一層的狀態,其在列的方向上進行了聚合,維度為`[batch_size, n_layers*n_neurons]`。
注意在 TensorFlow 版本 0.11.0 之前,`status`是單個張量是默認設置。
## 在多個 GPU 上分布式部署深度 RNN 網絡
## Dropout 的應用
對于深層深度 RNN,在訓練集上很容易過擬合。Dropout 是防止過擬合的常用技術。
可以簡單的在 RNN 層之前或之后添加一層 Dropout 層,但如果需要在 RNN 層之間應用 Dropout 技術就需要`DropoutWrapper`。
下面的代碼中,每一層的 RNN 的輸入前都應用了 Dropout,Dropout 的概率為 50%。
```python
keep_prob = 0.5
cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
cell_drop = tf.contrib.rnn.DropoutWrapper(cell, input_keep_prob=keep_prob)
multi_layer_cell = tf.contrib.rnn.MultiRNNCell([cell_drop]*n_layers)
rnn_outputs, states = tf.nn.dynamic_rnn(multi_layer_cell, X, dtype=tf.float32)
```
同時也可以通過設置`output_keep_prob`來在輸出應用 Dropout 技術。
然而在以上代碼中存在的主要問題是,Dropout 不管是在訓練還是測試時都起作用了,而我們想要的僅僅是在訓練時應用 Dropout。
很不幸的是`DropoutWrapper`不支持`is_training`這樣一個設置選項。因此必須自己寫 Dropout 包裝類,或者創建兩個計算圖,一個用來訓練,一個用來測試。后則可通過如下面代碼這樣實現。
```python
import sys
is_training = (sys.argv[-1] == "train")
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.float32, [None, n_steps, n_outputs])
cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
if is_training:
cell = tf.contrib.rnn.DropoutWrapper(cell, input_keep_prob=keep_prob)
multi_layer_cell = tf.contrib.rnn.MultiRNNCell([cell]*n_layers)
rnn_outpus, status = tf.nn.dynamic_rnn(multi_layer_cell, X, dtype=tf.float32)
[...] # bulid the rest of the graph
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
if is_training:
init.run()
for iteration in range(n_iterations):
[...] # train the model
save_path = saver.save(sess, "/tmp/my_model.ckpt")
else:
saver.restore(sess, "/tmp/my_model.ckpt")
[...] # use the model
```
通過以上的方法就能夠訓練各種 RNN 網絡了。然而對于長序列的 RNN 訓練還言之過早,事情會變得有一些困難。
那么我們來探討一下究竟這是為什么和怎么應對呢?
## 長時訓練的困難
在訓練長序列的 RNN 模型時,那么就需要把 RNN 在時間維度上展開成很深的神經網絡。正如任何深度神經網絡一樣,其面臨著梯度消失/爆炸的問題,使訓練無法終止或收斂。
很多之前討論過的緩解這種問題的技巧都可以應用在深度展開的 RNN 網絡:好的參數初始化方式,非飽和的激活函數(如 ReLU),批量規范化(Batch Normalization), 梯度截斷(Gradient Clipping),更快的優化器。
即便如此, RNN 在處理適中的長序列(如 100 輸入序列)也在訓練時表現的很慢。
最簡單和常見的方法解決訓練時長問題就是在訓練階段僅僅展開限定時間步長的 RNN 網絡,一種稱為截斷時間反向傳播的算法。
在 TensorFlow 中通過截斷輸入序列來簡單實現這種功能。例如在時間序列預測問題上可以在訓練時減小`n_steps`來實現截斷。理所當然這種方法會限制模型在長期模式的學習能力。一種變通方案時確保縮短的序列中包含舊數據和新數據,從而使模型獲得兩者信息(如序列同時包含最近五個月的數據,最近五周的和最近五天的數據)。
問題時如何確保從去年的細分類中獲取的數據有效性呢?這期間短暫但重要的事件對后世的影響,甚至時數年后這種影響是否一定要考慮在內呢(如選舉結果)?這種方案有其先天的不足之處。
在長的時間訓練過程中,第二個要面臨的問題時第一個輸入的記憶會在長時間運行的 RNN 網絡中逐漸淡去。確實,通過變換的方式,數據穿流在 RNN 網絡之中,每個時間步長后都有一些信息被拋棄掉了。那么在一定時間后,第一個輸入實際上會在 RNN 的狀態中消失于無形。
比如說,你想要分析長篇幅的影評的情感類別,影評以`"I love this movie"`開篇,并輔以各種改善影片的一些建議。試想一下,如果 RNN 網絡逐漸忘記了開頭的幾個詞,RNN 網絡的判斷完全有可能會對影評斷章取義。
為了解決其中的問題,各種能夠攜帶長時記憶的神經單元的變體被提出。這些變體是有效的,往往基本形式的神經單元就不怎么被使用了。
首先了解一下最流行的一種長時記憶神經單元:長短時記憶神經單元 LSTM。
## LSTM 單元
長短時記憶單元在 1997 年[由 S.H. 和 J.S. 首次提出](https://goo.gl/j39AGv) [3],并在接下來的幾年內經過 [A.G,H.S](https://goo.gl/6BHh81) [4],[W.Z](https://goo.gl/SZ9kzB) [5] 等數位研究人員的改進逐漸形成。如果把 LSTM 單元看作一個黑盒,從外圍看它和基本形式的記憶單元很相似,但 LSTM 單元會比基本單元性能更好,收斂更快,能夠感知數據的長時依賴。TensorFlow 中通過`BasicLSTMCell`實現 LSTM 單元。
> [3]: "Long Short-Term Memory," S.Hochreiter and J.Schmidhuber(1997)
>
> [4]: "Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling," H.Sak et al.(2014)
>
> [5]: "Recurrent Neural Network Regularization," W.Zaremba et al.(2015)
```python
lstm_cell = tf.contrib.rnn.BasicLSTMCell(num_units=n_neurons)
```
LSTM 單元的工作機制是什么呢?在圖 14-13 中展示了基本 LSTM 單元的結構。

不觀察 LSTM 單元內部,除了一些不同外跟常規 RNN 單元極其相似。這些不同包括 LSTM 單元狀態分為兩個向量: 和 (`c`代表 cell)。可以簡單認為  是短期記憶狀態, 是長期記憶狀態。
好,我們來打開盒子。LSTM 單元的核心思想是其能夠學習從長期狀態中存儲什么,忘記什么,讀取什么。長期狀態  從左向右在網絡中傳播,依次經過遺忘門(forget gate)時丟棄一些記憶,之后加法操作增加一些記憶(從輸入門中選擇一些記憶)。輸出  不經任何轉換直接輸出。每個單位時間步長后,都有一些記憶被拋棄,新的記憶被添加進來。另一方面,長時狀態經過 tanh 激活函數通過輸出門得到短時記憶 ,同時它也是這一時刻的單元輸出結果 。接下來討論一下新的記憶時如何產生的,門的功能是如何實現的。
首先,當前的輸入向量  和前一時刻的短時狀態  作為輸入傳給四個全連接層,這四個全連接層有不同的目的:
- 其中主要的全連接層輸出 ,它的常規任務就是解析當前的輸入  和前一時刻的短時狀態 。在基本形式的 RNN 單元中,就與這種形式一樣,直接輸出了  和 。與之不同的是 LSTM 單元會將一部分  存儲在長時狀態中。
- 其它三個全連接層被稱為門控制器(gate controller)。其采用 Logistic 作為激活函數,輸出范圍在 0 到 1 之間。正如在結構圖中所示,這三個層的輸出提供給了逐元素乘法操作,當輸入為 0 時門關閉,輸出為 1 時門打開。分別為:
- 遺忘門(forget gat)由  控制,來決定哪些長期記憶需要被擦除;
- 輸入門(input gate) 由  控制,它的作用是處理哪部分  應該被添加到長時狀態中,也就是為什么被稱為**部分存儲**。
- 輸出門(output gate)由  控制,在這一時刻的輸出  和  就是由輸出門控制的,從長時狀態中讀取的記憶。
簡要來說,LSTM 單元能夠學習到識別重要輸入(輸入門作用),存儲進長時狀態,并保存必要的時間(遺忘門功能),并學會提取當前輸出所需要的記憶。
這也解釋了 LSTM 單元能夠在提取長時序列,長文本,錄音等數據中的長期模式的驚人成功的原因。
公式 14-3 總結了如何計算單元的長時狀態,短時狀態,和單個輸入情形時每單位步長的輸出(小批量的方程形式與單輸入的形式相似)。

- ,,, 是四個全連接層關于輸入向量  的權重。
- ,,, 是四個全連接層關于上一時刻的短時狀態  的權重。
- 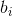,,, 是全連接層的四個偏置項,需要注意的是 TensorFlow 將其初始化為全 1 向量,而非全 0,為了阻止網絡初始訓練狀態下,各個門關閉從而忘記所有記憶。
### 窺孔連接
基本形式的 LSTM 單元中,門的控制僅有當前的輸入  和前一時刻的短時狀態 。不妨讓各個控制門窺視一下長時狀態,獲取一些上下文信息不失為一種嘗試。[該想法](https://goo.gl/ch8xz3)由 F.G.he J.S. 在 2000 年提出。他們提出的 LSTM 的變體擁有叫做窺孔連接的額外連接:把前一時刻的長時狀態  加入遺忘門和輸入門控制的輸入,當前時刻的長時狀態加入輸出門的控制輸入。
TensorFLow 中由`LSTMCell`實現以上變體 LSTM,并設置`use_peepholes=True`。
```python
lstm_cell = tf.contrib.rnn.LSTMCell(num_units=n_neurons, use_peepholes=True)
```
在眾多 LSTM 變體中,一個特別流行的變體就是 GRU 單元。
## GRU 單元

門控循環單元(圖 14-14)在 2014 年的 [K.Cho et al. 的論文](http://goo.gl/ZnAEOZ)中提出,并且此文也引入了前文所述的編解碼網絡。
門控循環單元是 LSTM 單元的簡化版本,能實現同樣的性能,這也說明了為什么它能越來越流行。簡化主要在一下幾個方面:
- 長時狀態和短時狀態合并為一個向量 。
- 用同一個門控制遺忘門和輸入門。如果門控制輸入 1,輸入門打開,遺忘門關閉,反之亦然。也就是說,如果當有新的記憶需要存儲,那么就必須實現在其對應位置事先擦除該處記憶。這也構成了 LSTM 本身的常見變體。
- GRU 單元取消了輸出門,單元的全部狀態就是該時刻的單元輸出。與此同時,增加了一個控制門  來控制哪部分前一時間步的狀態在該時刻的單元內呈現。

公式 14-4 總結了如何計算單個輸入情形時每單位步的單元的狀態。
在 TensoFlow 中創建 GRU 單元很簡單:
```python
gru_cell = tf.contrib.rnn.GRUCell(n_units=n_neurons)
```
LSTM 或 GRU 單元是近年來 RNN 成功背后的主要原因之一,特別是在自然語言處理(NLP)中的應用。
## 自然語言處理
現在,大多數最先進的 NLP 應用(如機器翻譯,自動摘要,解析,情感分析等),現在(至少一部分)都基于 RNN。 在最后一節中,我們將快速了解機器翻譯模型的概況。 TensorFlow 的很厲害的 [Word2Vec](https://goo.gl/edArdi) 和 [Seq2Seq](https://goo.gl/L82gvS) 教程非常好地介紹了這個主題,所以你一定要閱讀一下。
### 單詞嵌入
在我們開始之前,我們需要選擇一個詞的表示形式。 一種選擇可以是,使用單熱向量表示每個詞。 假設你的詞匯表包含 5 萬個單詞,那么第`n`個單詞將被表示為 50,000 維的向量,除了第`n`個位置為 1 之外,其它全部為 0。 然而,對于如此龐大的詞匯表,這種稀疏表示根本就不會有效。 理想情況下,你希望相似的單詞具有相似的表示形式,這使得模型可以輕松地將所學的關于單詞的只是,推廣到所有相似單詞。 例如,如果模型被告知`"I drink milk"`是一個有效的句子,并且如果它知道`"milk"`接近于`"water"`,而不同于`"shoes"`,那么它會知道`"I drink water"` 也許是一個有效的句子,而`"I drink shoes"`可能不是。 但你如何提出這樣一個有意義的表示呢?
最常見的解決方案是,用一個相當小且密集的向量(例如 150 維)表示詞匯表中的每個單詞,稱為嵌入,并讓神經網絡在訓練過程中,為每個單詞學習一個良好的嵌入。 在訓練開始時,嵌入只是隨機選擇的,但在訓練過程中,反向傳播會自動更新嵌入,來幫助神經網絡執行任務。 通常這意味著,相似的詞會逐漸彼此靠近,甚至最終以一種相當有意義的方式組織起來。 例如,嵌入可能最終沿著各種軸分布,它們代表性別,單數/復數,形容詞/名詞。 結果可能真的很神奇。
在TensorFlow中,首先需要創建一個變量來表示詞匯表中每個詞的嵌入(隨機初始化):
```py
vocabulary_size = 50000
embedding_size = 150
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
```
現在假設你打算將句子`"I drink milk"`提供給你的神經網絡。 你應該首先對句子進行預處理并將其分解成已知單詞的列表。 例如,你可以刪除不必要的字符,用預定義的標記詞(如`"[UNK]"`)替換未知單詞,用`"[NUM]"`替換數字值,用`"[URL]"`替換 URL 等。 一旦你有了一個已知單詞列表,你可以在字典中查找每個單詞的整數標識符(從 0 到 49999),例如`[72,3335,288]`。 此時,你已準備好使用占位符將這些單詞標識符提供給 TensorFlow,并應用`embedding_lookup()`函數來獲取相應的嵌入:
```py
train_inputs = tf.placeholder(tf.int32, shape=[None]) # from ids...
embed = tf.nn.embedding_lookup(embeddings, train_inputs) # ...to embeddings
```
一旦你的模型習得了良好的詞嵌入,它們實際上可以在任何 NLP 應用中高效復用:畢竟,`"milk"`依然接近于`"water"`,而且不管你的應用是什么,它都不同于`"shoes"`。 實際上,你可能需要下載預訓練的單詞嵌入,而不是訓練自己的單詞嵌入。 就像復用預訓練層(參見第 11 章)一樣,你可以選擇凍結預訓練嵌入(例如,使用`trainable=False`創建嵌入變量),或者讓反向傳播為你的應用調整它們。 第一種選擇將加速訓練,但第二種選擇可能會產生稍高的性能。
> 提示
>
> 對于表示可能擁有大量不同值的類別屬性,嵌入也很有用,特別是當值之間存在復雜的相似性的時候。 例如,考慮職業,愛好,菜品,物種,品牌等。
你現在擁有了實現機器翻譯系統所需的幾乎所有的工具。 現在我們來看看它吧。
### 用于機器翻譯的編解碼器網絡
讓我們來看看簡單的機器翻譯模型,它將英語句子翻譯成法語(參見圖 14-15)。
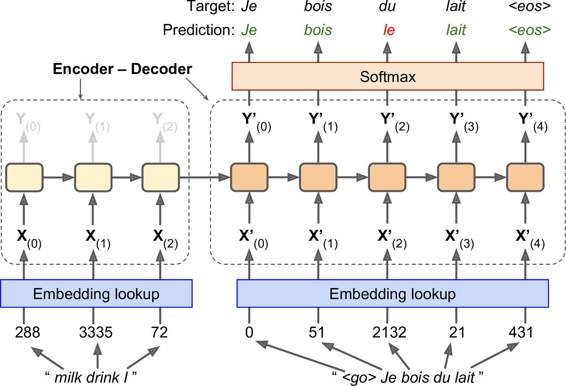
圖 14-15:簡單的機器翻譯模型
英語句子被送進編碼器,解碼器輸出法語翻譯。 請注意,法語翻譯也被用作解碼器的輸入,但后退了一步。 換句話說,解碼器的輸入是它應該在前一步輸出的字(不管它實際輸出的是什么)。 對于第一個單詞,提供了表示句子開始的標記(`"<go>"`)。 解碼器預期以序列末尾標記(EOS)結束句子(`"<eos>"`)。
請注意,英語句子在送入編碼器之前會反轉。 例如,`"I drink milk"`與`"milk drink I"`相反。這確保了英語句子的開頭將會最后送到編碼器,這很有用,因為這通常是解碼器需要翻譯的第一個東西。
每個單詞最初由簡單整數標識符表示(例如,單詞`"milk"`為 288)。 接下來,嵌入查找返回詞的嵌入(如前所述,這是一個密集的,相當低維的向量)。 這些詞的嵌入是實際送到編碼器和解碼器的內容。
在每個步驟中,解碼器輸出輸出詞匯表(即法語)中每個詞的得分,然后 Softmax 層將這些得分轉換為概率。 例如,在第一步中,單詞`"Je"`有 20% 的概率,`"Tu"`有 1% 的概率,以此類推。 概率最高的詞會輸出。 這非常類似于常規分類任務,因此你可以使用`softmax_cross_entropy_with_logits()`函數來訓練模型。
請注意,在推斷期間(訓練之后),你不再將目標句子送入解碼器。 相反,只需向解碼器提供它在上一步輸出的單詞,如圖 14-16 所示(這將需要嵌入查找,它未在圖中顯示)。
圖 14-16:在推斷期間,將之前的輸出單詞提供為輸入
好的,現在你有了大方向。 但是,如果你閱讀 TensorFlow 的序列教程,并查看`rnn/translate/seq2seq_model.py`中的代碼(在 TensorFlow 模型中),你會注意到一些重要的區別:
+ 首先,到目前為止,我們已經假定所有輸入序列(編碼器和解碼器的)具有恒定的長度。但顯然句子長度可能會有所不同。有幾種方法可以處理它 - 例如,使用`static_rnn()`或`dynamic_rnn()`函數的`sequence_length`參數,來指定每個句子的長度(如前所述)。然而,教程中使用了另一種方法(大概是出于性能原因):句子分到長度相似的桶中(例如,句子的單詞 1 到 6 分到一個桶,單詞 7 到 12 分到另一個桶,等等),并且使用特殊的填充標記(例如`"<pad>"`)來填充較短的句子。例如,`"I drink milk"`變成`"<pad> <pad> <pad> milk drink I"`,翻譯成`"Je bois du lait <eos> <pad>"`。當然,我們希望忽略任何 EOS 標記之后的輸出。為此,本教程的實現使用`target_weights`向量。例如,對于目標句子`"Je bois du lait <eos> <pad>"`,權重將設置為`[1.0,1.0,1.0,1.0,1.0,0.0]`(注意權重 0.0 對應目標句子中的填充標記)。簡單地將損失乘以目標權重,將消除對應 EOS 標記之后的單詞的損失。
+ 其次,當輸出詞匯表很大時(就是這里的情況),輸出每個可能的單詞的概率將會非常慢。 如果目標詞匯表包含 50,000 個法語單詞,則解碼器將輸出 50,000 維向量,然后在這樣的大向量上計算 softmax 函數,計算量將非常大。 為了避免這種情況,一種解決方案是讓解碼器輸出更小的向量,例如 1,000 維向量,然后使用采樣技術來估計損失,而不必對目標詞匯表中的每個單詞計算它。 這種采樣 Softmax 技術是由 SébastienJean 等人在 2015 年提出的。在 TensorFlow 中,你可以使用`sampled_softmax_loss()`函數。
+ 第三,教程的實現使用了一種注意力機制,讓解碼器能夠窺視輸入序列。 注意力增強的 RNN 不在本書的討論范圍之內,但如果你有興趣,可以關注機器翻譯,機器閱讀和圖像說明的相關論文。
+ 最后,本教程的實現使用了`tf.nn.legacy_seq2seq`模塊,該模塊提供了輕松構建各種編解碼器模型的工具。 例如,`embedding_rnn_seq2seq()`函數會創建一個簡單的編解碼器模型,它會自動為你處理單詞嵌入,就像圖 14-15 中所示的一樣。 此代碼可能會很快更新,來使用新的`tf.nn.seq2seq`模塊。
你現在擁有了,了解所有 seq2seq 教程的實現所需的全部工具。 將它們取出,并訓練你自己的英法翻譯器吧!
## 練習
1. 你能想象 seq2seq RNN 的幾個應用嗎? seq2vec 的 RNN 呢?vex2seq 的 RNN 呢?
1. 為什么人們使用編解碼器 RNN 而不是簡單的 seq2seq RNN 來自動翻譯?
1. 如何將卷積神經網絡與 RNN 結合,來對視頻進行分類?
1. 使用`dynamic_rnn()`而不是`static_rnn()`構建 RNN 有什么好處?
1. 你如何處理長度可變的輸入序列? 那么長度可變輸出序列呢?
1. 在多個 GPU 上分配深層 RNN 的訓練和執行的常見方式是什么?
1. Hochreiter 和 Schmidhuber 在其關于 LSTM 的文章中使用了嵌入式 Reber 語法。 它們是產生字符串,如`"BPBTSXXVPSEPE"`的人造語法。查看 Jenny Orr 對此主題的[不錯的介紹](https://goo.gl/7CkNRn)。 選擇一個特定的嵌入式 Reber 語法(例如 Jenny Orr 頁面上顯示的語法),然后訓練一個 RNN 來確定字符串是否遵循該語法。 你首先需要編寫一個函數,該函數能夠生成訓練批量,包含大約 50% 遵循語法的字符串,以及 50% 不遵循的字符串。
1. 解決“How much did it rain? II”(下雨下了多久 II)[Kaggle 比賽](https://goo.gl/0DS5Xe)。 這是一個時間序列預測任務:它為你提供極化雷達值的快照,并要求預測每小時降水量。 Luis Andre Dutra e Silva 的[采訪](https://goo.gl/fTA90W)對他在比賽中獲得第二名的技術,提供了一些有趣的見解。 特別是,他使用了由兩個 LSTM 層組成的 RNN。
1. 通過 TensorFlow 的 [Word2Vec](https://goo.gl/edArdi) 教程來創建單詞嵌入,然后通過 [Seq2Seq](https://goo.gl/L82gvS) 教程來訓練英法翻譯系統。
附錄 A 提供了這些練習的答案。
