# 十、人工神經網絡介紹
> 譯者:[@akonwang](https://github.com/wangxupeng)、[@friedhelm739](https://github.com/friedhelm739)
>
> 校對者:[@飛龍](https://github.com/wizardforcel)、[@YuWang](https://github.com/bigeyex)
鳥類啟發我們飛翔,牛蒡植物啟發了尼龍繩,大自然也激發了許多其他發明。從邏輯上看,大腦是如何構建智能機器的靈感。這是啟發人工神經網絡(ANN)的關鍵思想。然而,盡管飛機受到鳥類的啟發,但它們不必拍動翅膀。同樣的,ANN 逐漸變得與他們的生物表兄弟有很大的不同。一些研究者甚至爭辯說,我們應該完全放棄生物類比(例如,通過說“單位”而不是“神經元”),以免我們把我們的創造力限制在生物學的系統上。
人工神經網絡是深度學習的核心。它們具有通用性、強大性和可擴展性,使得它們能夠很好地解決大型和高度復雜的機器學習任務,例如分類數十億圖像(例如,谷歌圖像),強大的語音識別服務(例如,蘋果的 Siri),通過每天追蹤數百萬的用戶的行為推薦最好的視頻(比如 YouTube),或者通過在游戲中擊敗世界冠軍,通過學習數百萬的游戲,然后與自己對抗(DeepMind 的 AlgFaGo)。
在本章中,我們將介紹人工神經網絡,從快速游覽的第一個ANN架構開始。然后,我們將提出多層感知器(MLP),并基于TensorFlow實現MNIST數字分類問題(在第3章中介紹)。
## 從生物到人工神經元
令人驚訝的是,人工神經網絡已經存在了相當長的一段時間:它們最初是由神經生理學家 Warren McCulloch 和數學家 Walter Pitts 在 1943 提出。McCulloch 和 Pitts 在其里程碑式的論文中提出了“神經活動內在的邏輯演算”,提出了一個簡化的計算模型,即生物神經元如何在動物大腦中協同工作,用邏輯進行復雜的計算。這是第一個人工神經網絡體系結構。從那時起,正如我們將看到的,許多其他的神經元結構已經被發明,
直到 20 世紀 60 年代,ANN 的早期成功才使人們普遍相信我們很快就會與真正的智能機器對話。當顯然的這個承諾將不會被兌現(至少相當長一段時間)時,資金飛向別處,ANN 進入了一個漫長的黑暗時代。20 世紀 80 年代初,隨著新的網絡體系結構的發明和更好的訓練技術的發展,人們對人工神經網絡的興趣也在重新燃起。但到了 20 世紀 90 年代,強大的可替代機器學習技術的,如支持向量機(見第5章)受到大多數研究者的青睞,因為它們似乎提供了更好的結果和更強的理論基礎。最后,我們現在目睹了另一股對 ANN 感興趣的浪潮。這波會像以前一樣消失嗎?有一些很好的理由相信,這一點是不同的,將會對我們的生活產生更深遠的影響:
+ 現在有大量的數據可用于訓練神經網絡,ANN 在許多非常復雜的問題上經常優于其他 ML 技術。
+ 自從 90 年代以來,計算能力的巨大增長使得在合理的時間內訓練大型神經網絡成為可能。這部分是由于穆爾定律,但也得益于游戲產業,它已經產生了數以百萬計的強大的 GPU 顯卡。
+ 改進了訓練算法。公平地說,它們與上世紀 90 年代使用的略有不同,但這些相對較小的調整產生了巨大的正面影響。
+ 在實踐中,人工神經網絡的一些理論局限性是良性的。例如,許多人認為人工神經網絡訓練算法是注定的,因為它們很可能陷入局部最優,但事實證明,這在實踐中是相當罕見的(或者如果它發生,它們也通常相當接近全局最優)。
+ ANN 似乎已經進入了資金和進步的良性循環。基于 ANN 的驚人產品定期成為頭條新聞,吸引了越來越多的關注和資金,導致越來越多的進步,甚至更驚人的產品。
## 生物神經元
在我們討論人工神經元之前,讓我們快速看一個生物神經元(如圖 10-1 所示)。它是一種異常細胞,主要見于動物大腦皮層(例如,你的大腦),由包含細胞核和大多數細胞復雜成分的細胞體組成,許多分支擴展稱為樹突,加上一個非常長的延伸稱為軸突。軸突的長度可能比細胞體長幾倍,或長達幾萬倍。在它的末端附近,軸突分裂成許多稱為 telodendria 的分支,在這些分支的頂端是微小的結構,稱為突觸末端(或簡單的突觸),它們連接到其他神經元的樹突(或直接到細胞體)。生物神經元接收短的電脈沖,稱為來自其他神經元的信號,通過這些突觸。當神經元在幾毫秒內接收到來自其他神經元的足夠數量的信號時,它就發射出自己的信號。
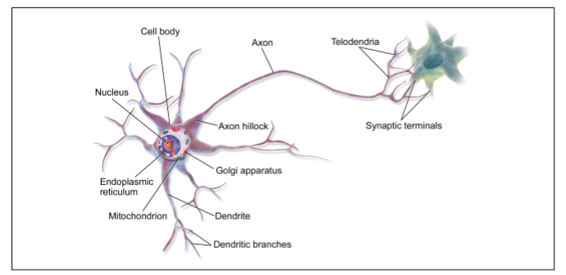
因此,個體的生物神經元似乎以一種相當簡單的方式運行,但是它們組織在一個巨大的數十億神經元的網絡中,每個神經元通常連接到數千個其他神經元。高度復雜的計算可以由相當簡單的神經元的巨大網絡來完成,就像一個復雜的蟻穴可以由每個螞蟻的努力構造出來。生物神經網絡(BNN)的體系結構仍然是主動研究的主題,但是大腦的某些部分已經被映射,并且似乎神經元經常組織在連續的層中,如圖 10-2 所示。

## 神經元的邏輯計算
Warren McCulloch 和 Pitts 提出一個非常簡單的生物神經元模型,這后來作為一個人工神經元成為眾所周知:它有一個或更多的二進制(ON/OFF)輸入和一個二進制輸出。當超過一定數量的輸入是激活時,人工神經元會激活其輸出。McCulloch 和 Pitts 表明,即使用這樣一個簡化的模型,也有可能建立一個人工神經元網絡來計算任何你想要的邏輯命題。例如,讓我們構建一些執行各種邏輯計算的 ANN(見圖 10-3),假設當至少兩個輸入是激活的時候神經元被激活。
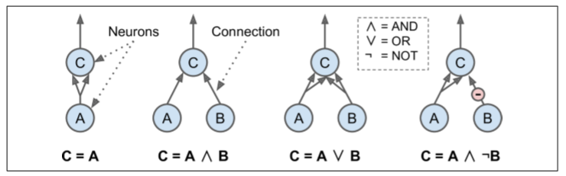
+ 左邊的第一個網絡僅僅是確認函數:如果神經元 A 被激活,那么神經元 C 也被激活(因為它接收來自神經元 A 的兩個輸入信號),但是如果神經元 A 關閉,那么神經元 C 也關閉。
+ 第二網絡執行邏輯 AND:神經元 C 只有在激活神經元 A 和 B(單個輸入信號不足以激活神經元 C)時才被激活。
+ 第三網絡執行邏輯 OR:如果神經元 A 或神經元 B 被激活(或兩者),神經元 C 被激活。
+ 最后,如果我們假設輸入連接可以抑制神經元的活動(生物神經元是這樣的情況),那么第四個網絡計算一個稍微復雜的邏輯命題:如果神經元 B 關閉,只有當神經元A是激活的,神經元 C 才被激活。如果神經元 A 始終是激活的,那么你得到一個邏輯 NOT:神經元 C 在神經元 B 關閉時是激活的,反之亦然。
您可以很容易地想象如何將這些網絡組合起來計算復雜的邏輯表達式(參見本章末尾的練習)。
## 感知器
感知器是最簡單的人工神經網絡結構之一,由 Frank Rosenblatt 發明于 1957。它是基于一種稍微不同的人工神經元(見圖 10-4),稱為線性閾值單元(LTU):輸入和輸出現在是數字(而不是二進制開/關值),并且每個輸入連接都與權重相連。LTU計算其輸入的加權和(`z = W1×1 + W2×2 + ... + + WN×n = Wt·x`),然后將階躍函數應用于該和,并輸出結果:`HW(x) = STEP(Z) = STEP(W^T·x)`。
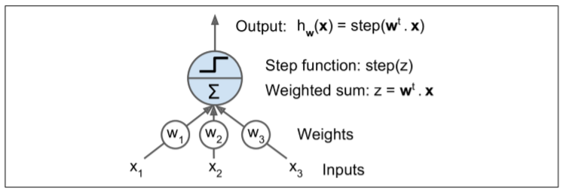
最常見的在感知器中使用的階躍函數是 Heaviside 階躍函數(見方程 10-1)。有時使用符號函數代替。

單一的 LTU 可被用作簡單線性二元分類。它計算輸入的線性組合,如果結果超過閾值,它輸出正類或者輸出負類(就像一個邏輯回歸分類或線性 SVM)。例如,你可以使用單一的 LTU 基于花瓣長度和寬度去分類鳶尾花(也可添加額外的偏置特征`x0=1`,就像我們在前一章所做的)。訓練一個 LTU 意味著去尋找合適的`W0`和`W1`值,(訓練算法稍后提到)。
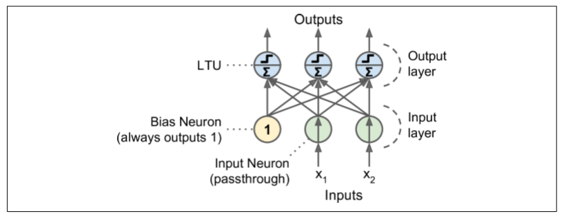
感知器簡單地由一層 LTU 組成,每個神經元連接到所有輸入。這些連接通常用特殊的被稱為輸入神經元的傳遞神經元來表示:它們只輸出它們所輸入的任何輸入。此外,通常添加額外偏置特征(`X0=1`)。這種偏置特性通常用一種稱為偏置神經元的特殊類型的神經元來表示,它總是輸出 1。
圖 10-5 表示具有兩個輸入和三個輸出的感知器。該感知器可以將實例同時分類為三個不同的二進制類,這使得它是一個多輸出分類器。
那么感知器是如何訓練的呢?Frank Rosenblatt 提出的感知器訓練算法在很大程度上受到 Hebb 規則的啟發。在 1949 出版的《行為組織》一書中,Donald Hebb 提出,當一個生物神經元經常觸發另一個神經元時,這兩個神經元之間的聯系就會變得更強。這個想法后來被 Siegrid L?wel 總結為一個吸引人的短語:“一起燃燒的細胞,匯合在一起。”這個規則后來被稱為 Hebb 規則(或 HebBIN 學習);也就是說,當兩個神經元具有相同的輸出時,它們之間的連接權重就會增加。使用這個規則的變體來訓練感知器,該規則考慮了網絡所犯的錯誤;它不加強導致錯誤輸出的連接。更具體地,感知器一次被饋送一個訓練實例,并且對于每個實例,它進行預測。對于每一個產生錯誤預測的輸出神經元,它加強了輸入的連接權重,這將有助于正確的預測。該規則在公式 10-2 中示出。
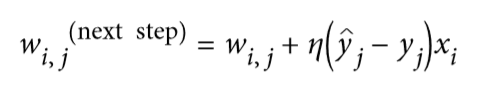
+ 其中`Wi,j`是第`i`輸入神經元與第`J`個輸出神經元之間的連接權重。
+ `xi`是當前訓練實例與輸入值。
+ `Y`帽是當前訓練實例的第`J`個輸出神經元的輸出。
+ `Yj`是當前訓練實例的第`J`個輸出神經元的目標輸出。
+ `ε`是學習率。
每個輸出神經元的決策邊界是線性的,因此感知機不能學習復雜的模式(就像 Logistic 回歸分類器)。然而,如果訓練實例是線性可分離的,Rosenblatt 證明該算法將收斂到一個解。這被稱為感知器收斂定理。
sklearn 提供了一個感知器類,它實現了一個 LTU 網絡。它可以像你所期望的那樣使用,例如在 iris 數據集(第 4 章中介紹):
```python
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
iris = load_iris()
X = iris.data[:, (2, 3)] # 花瓣長度,寬度
y = (iris.target == 0).astype(np.int)
per_clf = Perceptron(random_state=42)
per_clf.fit(X, y)
per_clf.predict([[2, 0.5]])
```
您可能已經認識到,感知器學習算法類似于隨機梯度下降。事實上,sklearn 的感知器類相當于使用具有以下超參數的 SGD 分類器:`loss="perceptron"`,`learning_rate="constant"`(學習率),`eta0=1`,`penalty=None`(無正則化)。
注意,與邏輯斯蒂回歸分類器相反,感知機不輸出類概率,而是基于硬閾值進行預測。這是你喜歡邏輯斯蒂回歸很好的一個理由。
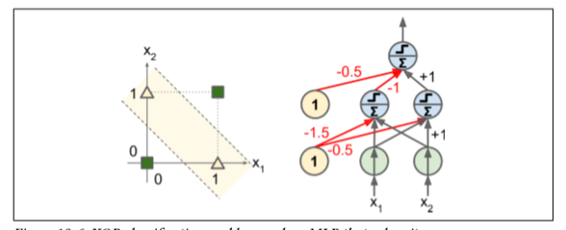
在他們的 1969 個題為“感知者”的專著中,Marvin Minsky 和 Seymour Papert 強調了感知機的許多嚴重缺陷,特別是它們不能解決一些瑣碎的問題(例如,異或(XOR)分類問題);參見圖 10-6 的左側)。當然,其他的線性分類模型(如 Logistic 回歸分類器)也都實現不了,但研究人員期望從感知器中得到更多,他們的失望是很大的:因此,許多研究人員放棄了聯結主義(即神經網絡的研究),這有利于更高層次的問題,如邏輯、問題解決和搜索。
然而,事實證明,感知器的一些局限性可以通過堆疊多個感知器來消除。由此產生的人工神經網絡被稱為多層感知器(MLP)。特別地,MLP 可以解決 XOR 問題,因為你可以通過計算圖 10-6 右側所示的 MLP 的輸出來驗證輸入的每一個組合:輸入`(0, 0)`或`(1, 1)`網絡輸出 0,并且輸入`(0, 1)`或`(1, 0)`它輸出 1。
## 多層感知器與反向傳播
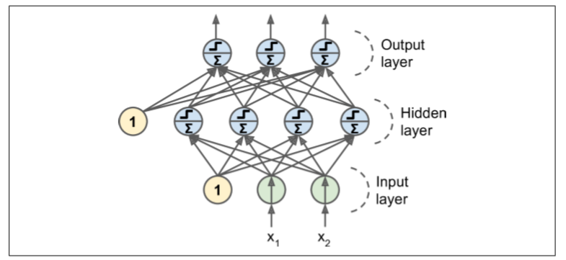
MLP 由一個(通過)輸入層、一個或多個稱為隱藏層的 LTU 組成,一個最終層 LTU 稱為輸出層(見圖 10-7)。除了輸出層之外的每一層包括偏置神經元,并且全連接到下一層。當人工神經網絡有兩個或多個隱含層時,稱為深度神經網絡(DNN)。
多年來,研究人員努力尋找一種訓練 MLP 的方法,但沒有成功。但在 1986,D. E. Rumelhart 等人提出了反向傳播訓練算法。第 9 章我們將其描述為使用反向自動微分的梯度下降(第 4 章討論了梯度下降,第 9 章討論了自動微分)。
對于每個訓練實例,算法將其饋送到網絡并計算每個連續層中的每個神經元的輸出(這是向前傳遞,就像在進行預測時一樣)。然后,它測量網絡的輸出誤差(即,期望輸出和網絡實際輸出之間的差值),并且計算最后隱藏層中的每個神經元對每個輸出神經元的誤差貢獻多少。然后,繼續測量這些誤差貢獻有多少來自先前隱藏層中的每個神經元等等,直到算法到達輸入層。該反向通過有效地測量網絡中所有連接權重的誤差梯度,通過在網絡中向后傳播誤差梯度(也是該算法的名稱)。如果你查看一下附錄 D 中的反向自動微分算法,你會發現反向傳播的正向和反向通過簡單地執行反向自動微分。反向傳播算法的最后一步是使用較早測量的誤差梯度對網絡中的所有連接權值進行梯度下降步驟。
讓我們更簡短一些:對于每個訓練實例,反向傳播算法首先進行預測(前向),測量誤差,然后反向遍歷每個層來測量每個連接(反向傳遞)的誤差貢獻,最后稍微調整連接器權值以減少誤差(梯度下降步長)。
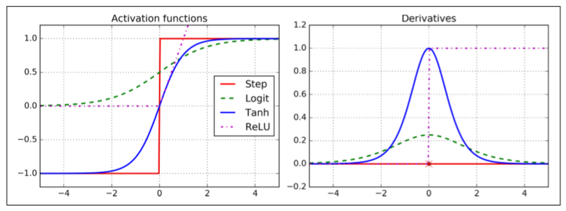
為了使算法能夠正常工作,作者對 MLP 的體系結構進行了一個關鍵性的改變:用 Logistic 函數代替了階躍函數,`σ(z) = 1 / (1 + exp(–z))`。這是必要的,因為階躍函數只包含平坦的段,因此沒有梯度來工作(梯度下降不能在平面上移動),而 Logistic 函數到處都有一個定義良好的非零導數,允許梯度下降在每個步上取得一些進展。反向傳播算法可以與其他激活函數一起使用,而不是 Logistic 函數。另外兩個流行的激活函數是:
+ 雙曲正切函數 `tanh (z) = 2σ(2z) – 1`
+ 就像 Logistic 函數,它是 S 形的、連續的、可微的,但是它的輸出值范圍從-1到1(不是在 Logistic 函數的 0 到 1),這往往使每個層的輸出在訓練開始時或多或少都正則化了(即以 0 為中心)。這常常有助于加快收斂速度。
+ Relu 函數(在第 9 章中介紹)
+ `ReLU (z) = max (0, z)`。它是連續的,但不幸的是在`z=0`時不可微(斜率突然改變,這可以使梯度下降反彈)。然而,在實踐中,它工作得很好,并且具有快速計算的優點。最重要的是,它沒有最大輸出值的事實也有助于減少梯度下降期間的一些問題(我們將在第 11 章中回顧這一點)。
這些流行的激活函數及其衍生物如圖 10-8 所示。
MLP 通常用于分類,每個輸出對應于不同的二進制類(例如,垃圾郵件/正常郵件,緊急/非緊急,等等)。當類是多類的(例如,0 到 9 的數字圖像分類)時,輸出層通常通過用共享的 softmax 函數替換單獨的激活函數來修改(見圖 10-9)。第 4 章介紹了 softmax 函數。每個神經元的輸出對應于相應類的估計概率。注意,信號只在一個方向上流動(從輸入到輸出),因此這種結構是前饋神經網絡(FNN)的一個例子。

生物神經元似乎是用 sigmoid(S 型)激活函數活動的,因此研究人員在很長一段時間內堅持 sigmoid 函數。但事實證明,Relu 激活函數通常在 ANN 工作得更好。這是生物研究誤導的例子之一。
## 用 TensorFlow 高級 API 訓練 MLP
與 TensorFlow 一起訓練 MLP 最簡單的方法是使用高級 API TF.Learn,這與 sklearn 的 API 非常相似。`DNNClassifier`可以很容易訓練具有任意數量隱層的深度神經網絡,而 softmax 輸出層輸出估計的類概率。例如,下面的代碼訓練兩個隱藏層的 DNN(一個具有 300 個神經元,另一個具有 100 個神經元)和一個具有 10 個神經元的 SOFTMax 輸出層進行分類:
```python
import tensorflow as tf
feature_columns = tf.contrib.learn.infer_real_valued_columns_from_input(X)
dnn_clf = tf.contrib.learn.DNNClassifier(hidden_units=[300, 100], n_classes=10,
feature_columns=feature_columns)
dnn_clf.fit(x=X, y=y, batch_size=50, steps=40000)
```
如果你在 MNIST 數據集上運行這個代碼(在縮放它之后,例如,通過使用 skLearn 的`StandardScaler`),你實際上可以得到一個在測試集上達到 98.1% 以上精度的模型!這比我們在第 3 章中訓練的最好的模型都要好:
```python
>>> from sklearn.metrics import accuracy_score
>>> y_pred = list(dnn_clf.predict(X_test))
>>> accuracy_score(y_test, y_pred)
0.98180000000000001
```
TF.Learn 學習庫也為評估模型提供了一些方便的功能:
```python
>>> dnn_clf.evaluate(X_test, y_test)
{'accuracy': 0.98180002, 'global_step': 40000, 'loss': 0.073678359}
```
`DNNClassifier`基于 Relu 激活函數創建所有神經元層(我們可以通過設置超參數`activation_fn`來改變激活函數)。輸出層基于 SoftMax 函數,損失函數是交叉熵(在第 4 章中介紹)。
TF.EXCEL API 仍然是更新的,所以在這些例子中使用的一些名稱和函數可能會在你讀這本書的時候發生一些變化。但總的思想是不變。
## 使用普通 TensorFlow 訓練 DNN
如果您想要更好地控制網絡架構,您可能更喜歡使用 TensorFlow 的較低級別的 Python API(在第 9 章中介紹)。 在本節中,我們將使用與之前的 API 相同的模型,我們將實施 Minibatch 梯度下降來在 MNIST 數據集上進行訓練。 第一步是建設階段,構建 TensorFlow 圖。 第二步是執行階段,您實際運行計算圖譜來訓練模型。
## 構造階段
開始吧。 首先我們需要導入`tensorflow`庫。 然后我們必須指定輸入和輸出的數量,并設置每個層中隱藏的神經元數量:
```python
import tensorflow as tf
n_inputs = 28*28 # MNIST
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
```
接下來,與第 9 章一樣,您可以使用占位符節點來表示訓練數據和目標。`X`的形狀僅有部分被定義。 我們知道它將是一個 2D 張量(即一個矩陣),沿著第一個維度的實例和第二個維度的特征,我們知道特征的數量將是`28×28`(每像素一個特征) 但是我們不知道每個訓練批次將包含多少個實例。 所以`X`的形狀是`(None, n_inputs)`。 同樣,我們知道`y`將是一個 1D 張量,每個實例有一個入口,但是我們再次不知道在這一點上訓練批次的大小,所以形狀`(None)`。
```python
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
```
現在讓我們創建一個實際的神經網絡。 占位符`X`將作為輸入層; 在執行階段,它將一次更換一個訓練批次(注意訓練批中的所有實例將由神經網絡同時處理)。 現在您需要創建兩個隱藏層和輸出層。 兩個隱藏的層幾乎相同:它們只是它們所連接的輸入和它們包含的神經元的數量不同。 輸出層也非常相似,但它使用 softmax 激活函數而不是 ReLU 激活函數。 所以讓我們創建一個`neuron_layer()`函數,我們將一次創建一個圖層。 它將需要參數來指定輸入,神經元數量,激活函數和圖層的名稱:
```python
def neuron_layer(X, n_neurons, name, activation=None):
with tf.name_scope(name):
n_inputs = int(X.get_shape()[1])
stddev = 2 / np.sqrt(n_inputs)
init = tf.truncated_normal((n_inputs, n_neurons), stddev=stddev)
W = tf.Variable(init, name="weights")
b = tf.Variable(tf.zeros([n_neurons]), name="biases")
z = tf.matmul(X, W) + b
if activation == "relu":
return tf.nn.relu(z)
else:
return z
```
我們逐行瀏覽這個代碼:
1. 首先,我們使用名稱范圍來創建每層的名稱:它將包含該神經元層的所有計算節點。 這是可選的,但如果節點組織良好,則 TensorBoard 圖形將會更加出色。
2. 接下來,我們通過查找輸入矩陣的形狀并獲得第二個維度的大小來獲得輸入數量(第一個維度用于實例)。
3. 接下來的三行創建一個保存權重矩陣的`W`變量。 它將是包含每個輸入和每個神經元之間的所有連接權重的2D張量;因此,它的形狀將是`(n_inputs, n_neurons)`。它將被隨機初始化,使用具有標準差為`2/√n`的截斷的正態(高斯)分布(使用截斷的正態分布而不是常規正態分布確保不會有任何大的權重,這可能會減慢訓練。).使用這個特定的標準差有助于算法的收斂速度更快(我們將在第11章中進一步討論這一點),這是對神經網絡的微小調整之一,對它們的效率產生了巨大的影響)。 重要的是為所有隱藏層隨機初始化連接權重,以避免梯度下降算法無法中斷的任何對稱性。(例如,如果將所有權重設置為 0,則所有神經元將輸出 0,并且給定隱藏層中的所有神經元的誤差梯度將相同。 然后,梯度下降步驟將在每個層中以相同的方式更新所有權重,因此它們將保持相等。 換句話說,盡管每層有數百個神經元,你的模型就像每層只有一個神經元一樣。)
4. 下一行創建一個偏差的`b`變量,初始化為 0(在這種情況下無對稱問題),每個神經元有一個偏置參數。
5. 然后我們創建一個子圖來計算`z = X·W + b`。 該向量化實現將有效地計算輸入的加權和加上層中每個神經元的偏置,對于批次中的所有實例,僅需一次.
6. 最后,如果激活參數設置為`relu`,則代碼返回`relu(z)`(即`max(0,z)`),否則它只返回`z`。
好了,現在你有一個很好的函數來創建一個神經元層。 讓我們用它來創建深層神經網絡! 第一個隱藏層以`X`為輸入。 第二個將第一個隱藏層的輸出作為其輸入。 最后,輸出層將第二個隱藏層的輸出作為其輸入。
```python
with tf.name_scope("dnn"):
hidden1 = neuron_layer(X, n_hidden1, "hidden1", activation="relu")
hidden2 = neuron_layer(hidden1, n_hidden2, "hidden2", activation="relu")
logits = neuron_layer(hidden2, n_outputs, "outputs")
```
請注意,為了清楚起見,我們再次使用名稱范圍。 還要注意,logit 是在通過 softmax 激活函數之前神經網絡的輸出:為了優化,我們稍后將處理 softmax 計算。
正如你所期望的,TensorFlow 有許多方便的功能來創建標準的神經網絡層,所以通常不需要像我們剛才那樣定義你自己的`neuron_layer()`函數。 例如,TensorFlow 的`fully_connected()`函數創建一個完全連接的層,其中所有輸入都連接到圖層中的所有神經元。 它使用正確的初始化策略來負責創建權重和偏置變量,并且默認情況下使用 ReLU 激活函數(我們可以使用`activate_fn`參數來更改它)。 正如我們將在第 11 章中看到的,它還支持正則化和歸一化參數。 我們來調整上面的代碼來使用`fully_connected()`函數,而不是我們的`neuron_layer()`函數。 只需導入該功能,并使用以下代碼替換 dnn 構建部分:
```python
from tensorflow.contrib.layers import fully_connected
with tf.name_scope("dnn"):
hidden1 = fully_connected(X, n_hidden1, scope="hidden1")
hidden2 = fully_connected(hidden1, n_hidden2, scope="hidden2")
logits = fully_connected(hidden2, n_outputs, scope="outputs",
activation_fn=None)
```
`tensorflow.contrib`包包含許多有用的功能,但它是一個尚未分級成為主要 TensorFlow API 一部分的實驗代碼的地方。 因此,`full_connected()`函數(和任何其他`contrib`代碼)可能會在將來更改或移動。
使用`dense()`代替`neuron_layer()`
注意:本書使用`tensorflow.contrib.layers.fully_connected()`而不是`tf.layers.dense()`(本章編寫時不存在)。
現在最好使用`tf.layers.dense()`,因為`contrib`模塊中的任何內容可能會更改或刪除,恕不另行通知。`dense()`函數與`fully_connected()`函數幾乎相同,除了一些細微的差別:
幾個參數被重命名:`scope`變為名稱,`activation_fn`變為激活(同樣`_fn`后綴從其他參數(如`normalizer_fn`)中刪除),`weights_initializer`成為`kernel_initializer`等。默認激活現在是無,而不是`tf.nn.relu`。 第 11 章還介紹了更多的差異。
```python
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1",
activation=tf.nn.relu)
hidden2 = tf.layers.dense(hidden1, n_hidden2, name="hidden2",
activation=tf.nn.relu)
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
```
現在我們已經有了神經網絡模型,我們需要定義我們用來訓練的損失函數。 正如我們在第 4 章中對 Softmax 回歸所做的那樣,我們將使用交叉熵。 正如我們之前討論的,交叉熵將懲罰估計目標類的概率較低的模型。 TensorFlow 提供了幾種計算交叉熵的功能。 我們將使用`sparse_softmax_cross_entropy_with_logits()`:它根據“logit”計算交叉熵(即,在通過 softmax 激活函數之前的網絡輸出),并且期望以 0 到 -1 數量的整數形式的標簽(在我們的例子中,從 0 到 9)。 這將給我們一個包含每個實例的交叉熵的 1D 張量。 然后,我們可以使用 TensorFlow 的`reduce_mean()`函數來計算所有實例的平均交叉熵。
```python
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
```
該`sparse_softmax_cross_entropy_with_logits()`函數等同于應用 SOFTMAX 激活函數,然后計算交叉熵,但它更高效,它妥善照顧的邊界情況下,比如 logits 等于 0,這就是為什么我們沒有較早的應用 SOFTMAX 激活函數。 還有稱為`softmax_cross_entropy_with_logits()`的另一個函數,該函數在標簽單熱載體的形式(而不是整數 0 至類的數目減 1)。
我們有神經網絡模型,我們有損失函數,現在我們需要定義一個`GradientDescentOptimizer`來調整模型參數以最小化損失函數。沒什么新鮮的; 就像我們在第 9 章中所做的那樣:
```python
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
```
建模階段的最后一個重要步驟是指定如何評估模型。 我們將簡單地將精度用作我們的績效指標。 首先,對于每個實例,通過檢查最高 logit 是否對應于目標類別來確定神經網絡的預測是否正確。 為此,您可以使用`in_top_k()`函數。 這返回一個充滿布爾值的 1D 張量,因此我們需要將這些布爾值轉換為浮點數,然后計算平均值。 這將給我們網絡的整體準確性.
```python
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
```
而且,像往常一樣,我們需要創建一個初始化所有變量的節點,我們還將創建一個`Saver`來將我們訓練有素的模型參數保存到磁盤中:
```python
init = tf.global_variables_initializer()
saver = tf.train.Saver()
```
建模階段結束。 這是不到 40 行代碼,但相當激烈:我們為輸入和目標創建占位符,我們創建了一個構建神經元層的函數,我們用它來創建 DNN,我們定義了損失函數,我們 創建了一個優化器,最后定義了性能指標。 現在到執行階段。
## 執行階段
這部分要短得多,更簡單。 首先,我們加載 MNIST。 我們可以像之前的章節那樣使用 ScikitLearn,但是 TensorFlow 提供了自己的助手來獲取數據,將其縮放(0 到 1 之間),將它洗牌,并提供一個簡單的功能來一次加載一個小批量:
```python
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/")
```
現在我們定義我們要運行的迭代數,以及小批量的大小:
```python
n_epochs = 10001
batch_size = 50
```
現在我們去訓練模型:
```python
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels})
print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)
save_path = saver.save(sess, "./my_model_final.ckpt")
```
該代碼打開一個 TensorFlow 會話,并運行初始化所有變量的`init`節點。 然后它運行的主要訓練循環:在每個時期,通過一些小批次的對應于訓練集的大小的代碼進行迭代。 每個小批量通過`next_batch()`方法獲取,然后代碼簡單地運行訓練操作,為當前的小批量輸入數據和目標提供。 接下來,在每個時期結束時,代碼評估最后一個小批量和完整訓練集上的模型,并打印出結果。 最后,模型參數保存到磁盤。
## 使用神經網絡
現在神經網絡被訓練了,你可以用它進行預測。 為此,您可以重復使用相同的建模階段,但是更改執行階段,如下所示:
```python
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt") # or better, use save_path
X_new_scaled = mnist.test.images[:20]
Z = logits.eval(feed_dict={X: X_new_scaled})
y_pred = np.argmax(Z, axis=1)
```
首先,代碼從磁盤加載模型參數。 然后加載一些您想要分類的新圖像。 記住應用與訓練數據相同的特征縮放(在這種情況下,將其從 0 縮放到 1)。 然后代碼評估對數點節點。 如果您想知道所有估計的類概率,則需要將`softmax()`函數應用于對數,但如果您只想預測一個類,則可以簡單地選擇具有最高 logit 值的類(使用`argmax()`函數做的伎倆)。
## 微調神經網絡超參數
神經網絡的靈活性也是其主要缺點之一:有很多超參數要進行調整。 不僅可以使用任何可想象的網絡拓撲(如何神經元互連),而且即使在簡單的 MLP 中,您可以更改層數,每層神經元數,每層使用的激活函數類型,權重初始化邏輯等等。 你怎么知道什么組合的超參數是最適合你的任務?
當然,您可以使用具有交叉驗證的網格搜索來查找正確的超參數,就像您在前幾章中所做的那樣,但是由于要調整許多超參數,并且由于在大型數據集上訓練神經網絡需要很多時間, 您只能在合理的時間內探索超參數空間的一小部分。 正如我們在第2章中討論的那樣,使用[隨機搜索](http//www.jmlr.org/papers/volume13/bergstra12a/bergstra12a.pdf)要好得多。另一個選擇是使用諸如 Oscar 之類的工具,它可以實現更復雜的算法,以幫助您快速找到一組好的超參數.
它有助于了解每個超級參數的值是合理的,因此您可以限制搜索空間。 我們從隱藏層數開始。
## 隱藏層數量
對于許多問題,您只需從單個隱藏層開始,您將獲得合理的結果。 實際上已經表明,只有一個隱藏層的 MLP 可以建模甚至最復雜的功能,只要它具有足夠的神經元。 長期以來,這些事實說服了研究人員,沒有必要調查任何更深層次的神經網絡。 但是他們忽略了這樣一個事實:深層網絡具有比淺層網絡更高的參數效率:他們可以使用比淺網格更少的神經元來建模復雜的函數,使得訓練更快。
要了解為什么,假設您被要求使用一些繪圖軟件繪制一個森林,但是您被禁止使用復制/粘貼。 你必須單獨繪制每棵樹,每枝分枝,每葉葉。 如果你可以畫一個葉,復制/粘貼它來繪制一個分支,然后復制/粘貼該分支來創建一個樹,最后復制/粘貼這個樹來制作一個林,你將很快完成。 現實世界的數據通常以這樣一種分層的方式進行結構化,DNN 自動利用這一事實:較低的隱藏層模擬低級結構(例如,各種形狀和方向的線段),中間隱藏層將這些低級結構組合到 模型中級結構(例如,正方形,圓形)和最高隱藏層和輸出層將這些中間結構組合在一起,以模擬高級結構(如面)。
這種分層架構不僅可以幫助 DNN 更快地融合到一個很好的解決方案,而且還可以提高其將其推廣到新數據集的能力。 例如,如果您已經訓練了模型以識別圖片中的臉部,并且您現在想要訓練一個新的神經網絡來識別發型,那么您可以通過重新使用第一個網絡的較低層次來啟動訓練。 而不是隨機初始化新神經網絡的前幾層的權重和偏置,您可以將其初始化為第一個網絡的較低層的權重和偏置的值。這樣,網絡將不必從大多數圖片中低結構中從頭學習;它只需要學習更高層次的結構(例如發型)。
總而言之,對于許多問題,您可以從一個或兩個隱藏層開始,它可以正常工作(例如,您可以使用只有一個隱藏層和幾百個神經元,在 MNIST 數據集上容易達到 97% 以上的準確度使用兩個具有相同總神經元數量的隱藏層,在大致相同的訓練時間量中精確度為 98%)。對于更復雜的問題,您可以逐漸增加隱藏層的數量,直到您開始覆蓋訓練集。非常復雜的任務,例如大型圖像分類或語音識別,通常需要具有數十個層(或甚至數百個但不完全相連的網絡)的網絡,正如我們將在第 13 章中看到的那樣),并且需要大量的訓練數據。但是,您將很少從頭開始訓練這樣的網絡:重用預先訓練的最先進的網絡執行類似任務的部分更為常見。訓練將會更快,需要更少的數據(我們將在第 11 章中進行討論)
## 每層隱藏層的神經元數量
顯然,輸入和輸出層中神經元的數量由您的任務需要的輸入和輸出類型決定。例如,MNIST 任務需要`28×28 = 784`個輸入神經元和 10 個輸出神經元。對于隱藏的層次來說,通常的做法是將其設置為形成一個漏斗,每個層面上的神經元越來越少,原因在于許多低級別功能可以合并成更少的高級功能。例如,MNIST 的典型神經網絡可能具有兩個隱藏層,第一個具有 300 個神經元,第二個具有 100 個。但是,這種做法現在并不常見,您可以為所有隱藏層使用相同的大小 - 例如,所有隱藏的層與 150 個神經元:這樣只用調整一次超參數而不是每層都需要調整(因為如果每層一樣,比如 150,之后調就每層都調成 160)。就像層數一樣,您可以嘗試逐漸增加神經元的數量,直到網絡開始過度擬合。一般來說,通過增加每層的神經元數量,可以增加層數,從而獲得更多的消耗。不幸的是,正如你所看到的,找到完美的神經元數量仍然是黑色的藝術.
一個更簡單的方法是選擇一個具有比實際需要的更多層次和神經元的模型,然后使用早期停止來防止它過度擬合(以及其他正則化技術,特別是 drop out,我們將在第 11 章中看到)。 這被稱為“拉伸褲”的方法:而不是浪費時間尋找完美匹配您的大小的褲子,只需使用大型伸縮褲,縮小到合適的尺寸。
## 激活函數
在大多數情況下,您可以在隱藏層中使用 ReLU 激活函數(或其中一個變體,我們將在第 11 章中看到)。 與其他激活函數相比,計算速度要快一些,而梯度下降在局部最高點上并不會被卡住,因為它不會對大的輸入值飽和(與邏輯函數或雙曲正切函數相反, 他們容易在 1 飽和)
對于輸出層,softmax 激活函數通常是分類任務的良好選擇(當這些類是互斥的時)。 對于回歸任務,您完全可以不使用激活函數。
這就是人造神經網絡的這個介紹。 在接下來的章節中,我們將討論訓練非常深的網絡的技術,并分發多個服務器和 GPU 的訓練。 然后我們將探討一些其他流行的神經網絡架構:卷積神經網絡,循環神經網絡和自動編碼器。
## 完整代碼
```python
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
from sklearn.metrics import accuracy_score
import numpy as np
if __name__ == '__main__':
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
mnist = input_data.read_data_sets("/tmp/data/")
X_train = mnist.train.images
X_test = mnist.test.images
y_train = mnist.train.labels.astype("int")
y_test = mnist.test.labels.astype("int")
X = tf.placeholder(tf.float32, shape= (None, n_inputs), name='X')
y = tf.placeholder(tf.int64, shape=(None), name = 'y')
with tf.name_scope('dnn'):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu
,name= 'hidden1')
hidden2 = tf.layers.dense(hidden1, n_hidden2, name='hidden2',
activation= tf.nn.relu)
logits = tf.layers.dense(hidden2, n_outputs, name='outputs')
with tf.name_scope('loss'):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels = y,
logits = logits)
loss = tf.reduce_mean(xentropy, name='loss')#所有值求平均
learning_rate = 0.01
with tf.name_scope('train'):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope('eval'):
correct = tf.nn.in_top_k(logits ,y ,1)#是否與真值一致 返回布爾值
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) #tf.cast將數據轉化為0,1序列
init = tf.global_variables_initializer()
n_epochs = 20
batch_size = 50
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op,feed_dict={X:X_batch,
y: y_batch})
acc_train = accuracy.eval(feed_dict={X:X_batch,
y: y_batch})
acc_test = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)
```
## 練習
1. 使用原始的人工神經元(如圖 10-3 中的一個)來計算神經網絡,計算`A ⊕ B `(`⊕`表示 XOR 運算)。提示:`A ⊕ B = (A ∧ ? B) ∨ (? A ∧ B)`。
2. 為什么通常使用邏輯斯蒂回歸分類器而不是經典感知器(即使用感知器訓練算法訓練單層的線性閾值單元)?你如何調整感知器使之等同于邏輯回歸分類器?
3. 為什么激活函數是訓練第一個 MLP 的關鍵因素?
4. 說出三種流行的激活函數。你能畫出它們嗎?
5. 假設有一個 MLP 有一個 10 個神經元組成的輸入層,接著是一個 50 個神經元的隱藏層,最后一個 3 個神經元輸出層。所有人工神經元使用 Relu 激活函數。
+ 輸入矩陣`X`的形狀是什么?
+ 隱藏層的權重向量的形狀以及它的偏置向量的形狀如何?
+ 輸出層的權重向量和它的偏置向量的形狀是什么?
+ 網絡的輸出矩陣`Y`是什么形狀?
+ 寫出計算網絡輸出矩陣的方程
6. 如果你想把電子郵件分類成垃圾郵件或正常郵件,你需要在輸出層中有多少個神經元?在輸出層中應該使用什么樣的激活函數?如果你想解決 MNIST 問題,你需要多少神經元在輸出層,使用什么激活函數?如第 2 章,一樣讓你的網絡預測房屋價格。
7. 什么是反向傳播,它是如何工作的?反向傳播與反向自動微分有什么區別?
8. 你能列出所有可以在 MLP 中調整的超參數嗎?如果 MLP 與訓練數據相匹配,你如何調整這些超參數來解決這個問題?
9. 在 MNIST 數據集上訓練一個深層 MLP 并查看是否可以超過 98% 的精度。就像在第 9 章的最后一次練習中,嘗試添加所有的鈴聲和哨子(即,保存檢查點,在中斷的情況下恢復最后一個檢查點,添加摘要,使用 TensorBoard 繪制學習曲線,等等)。
練習的答案請參照附錄 A
