## 十一、進化
> 原文:[Chapter 11 Evolution](http://greenteapress.com/complexity2/html/thinkcomplexity2012.html)
> 譯者:[飛龍](https://github.com/wizardforcel)
> 協議:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
生物學乃至整個科學最重要的思想,是通過自然選擇的進化論,它聲稱由于自然選擇而創造出新的物種并改變現有的物種。自然選擇是個體間遺傳差異導致生存和繁殖差異的過程。
在了解生物學的人中,進化論被廣泛認為是一個事實,也就是它足以接近事實,如果將來得到糾正,糾正將使中心思想基本保持完整。
盡管如此,許多人并不相信進化論。在皮尤研究中心進行的一項調查中,被調查者被問到,以下哪些斷言更貼近他們的觀點:
+ 人類和其他生物隨時間而進化。
+ 起初,人類和其他生物就以其現在的形式存在。
約有 34% 的美國人選擇了第二個(見 <http://www.thearda.com/Archive/Files/Codebooks/RELLAND14_CB.asp>)。
即使在那些認為生物已經進化的人中,只有一半以上的人認為進化的原因是自然選擇。 換句話說,只有三分之一的美國人相信進化論是真實的。
這怎么可能? 在我看來,促成因素包括:
+ 有些人認為進化論與他們的宗教信仰之間有沖突。 感覺就像他們不得不拒絕一個,他們拒絕了進化論。
+ 其他人經常被第一組成員積極誤導,以至于他們對進化論的許多認識都是錯誤的。
+ 許多人根本就不了解進化。
對于第一組,我可能沒有太多可以做的事,但我認為我可以幫助其他人。 經驗上,進化論很難讓人理解。 同時,它非常簡單:對很多人來說,一旦他們了解進化論,它似乎既明顯又無可辯駁。
為了幫助人們從困惑轉變為清晰,我找到的最強大的工具就是計算。 我們看到,理論上很難理解的想法,在模擬中出現時很容易理解。 這是本章的目標。
本章的代碼位于`chap11.ipynb`中,該書是本書倉庫中的 Jupyter 筆記本。使用此代碼的更多信息,請參見第?節。
## 11.1 簡單的進化
我將從一個簡單的模型開始,演示一種基本的進化形式。 根據該理論,以下特征足以產生進化:
+ 復制者:我們需要一批能夠以某種方式復制的智能體。 我們將以復制者開始,它們生成它們自己的完美的副本。 稍后我們將添加不完美的副本,即突變。
+ 突變:我們還需要一些種群中的變化,也就是個體之間的差異。
+ 生存和繁殖差異:個體之間的差異必須影響其生存或繁殖的能力。
為了模擬這些特征,我們將定義智能體種群,智能體代表個體。 每個智能體都有遺傳信息,稱為基因型,這是智能體繁殖時復制的信息。 在我們的模型中 [1],基因型由`N`個二進制數字(零和一)的序列表示,其中`N`是我們選擇的參數。
> [1] 模型是主要由 Stuart Kauffman 開發的 NK 模型的變體(參見 <https://en.wikipedia.org/wiki/NK_model>)。
為了產生突變,我們創建了具有多種基因型的種群;稍后我們將探討創造或增加突變的機制。
最后,為了產生生存和繁殖差異,我們定義了一個函數,將每個基因型映射為一個適應度,其中適應度是一個數量,有關智能體的生存或繁殖能力。
## 11.2 適應性景觀
將基因型映射為適應性函數,稱為適應性景觀。 在景觀的隱喻中,每個基因型對應于`N`維空間中的一個位置,并且適應性對應于該位置處的景觀的“高度”。對于能夠解釋這個隱喻的可視化,參見 <https://en.wikipedia.org/wiki/Fitness_landscape>。
在生物學術語中,適應性景觀代表一種信息,它是生物體的基因型與其物理形式和能力的關系,后者稱為其表現型,以及表現型如何與其環境相互作用。
在現實世界中,適應性景觀很復雜,但我們不需要建立現實模型。 為了誘導進化,我們需要基因型和適應性之間的某種關系,但事實證明它可以是任何關系。 為了證明它,我們將使用完全隨機的適應性景觀。
這是代表適應性景觀的類的定義:
```py
class FitnessLandscape:
def __init__(self, N):
self.N = N
self.one_values = np.random.random(N)
self.zero_values = np.random.random(N)
def fitness(self, loc):
fs = np.where(loc, self.one_values,
self.zero_values)
return fs.mean()
```
智能體的基因型,對應其在適應性景觀中的位置,由一個 NumPy 的零一數組來表示,稱為`loc`。 給定基因型的適應性,是`N`個適應性貢獻的平均值,`loc`的每個元素都是一個。
為了計算基因型的適應性,`FitnessLandscape`使用兩個數組:`one_values`,其中包含`loc`的每個元素都為 1 時的適應性貢獻,以及`zero_values`,其中包含為 0 時的適應度貢獻。
`fitness`方法使用`np.where`,如果`loc`中的值為 1,它從`one_values`中選擇一個值,如果`loc`中的值為 0,它從`zero_values`中選擇一個值。
例如,假設`N=3`:
```py
one_values = [0.1, 0.2, 0.3]
zero_values = [0.4, 0.7, 0.9]
```
這種情況下,`loc = [0, 1, 0]`的適應性是`[0.4, 0.2, 0.9]`的均值,為 0.5。
## 11.3 智能體
接下來我們需要智能體,這是類定義:
```py
class Agent:
def __init__(self, loc, fit_land):
self.loc = loc
self.fit_land = fit_land
self.fitness = fit_land.fitness(self.loc)
def copy(self):
return Agent(self.loc, self.fit_land)
```
智能體的屬性是:
`loc`:智能體在適應性景觀中的位置。
`fit_land`:`FitnessLandscape`對象的引用。
`fitness`:智能體在`FitnessLandscape`中的適應性,表示為 0 到 1 之間的數字。
`Agent`的這個定義提供了一種簡單的`copy`方法,可以精確復制基因型;之后,我們將看到一個帶有突變的版本,但突變對于進化來說不是必需的。
## 11.4 模擬
現在我們有了智能體和適應性景觀,我將定義一個名為`Simulation`的類,用于模擬智能體的創建,繁殖和死亡。 為了避免陷入困境,我將在這里提供一個簡化版本的代碼;你可以在本章的筆記本上看到細節。
這是`Simulation`的定義:
```py
class Simulation:
def __init__(self, fit_land, agents):
self.fit_land = fit_land
self.agents = agents
```
`Simulation`的屬性是:
+ `fit_land`:`FitnessLandscape`對象的引用。
+ `agents`:`Agent`對象的數組。
`Simulation`中最重要的函數是`step`,它模擬了單個時間步驟:
```py
# class Simulation:
def step(self):
n = len(self.agents)
fits = self.get_fitnesses()
# see who dies
index_dead = self.choose_dead(fits)
num_dead = len(index_dead)
# replace the dead with copies of the living
replacements = self.choose_replacements(num_dead, fits)
self.agents[index_dead] = replacements
```
在每個時間步驟中,一些智能體死亡,一些智能體繁殖。 `step`使用另外三個方法:
+ `get_fitnesses`返回一個數組,包含每個智能體的適應性,按照它們在智能體數組中出現的順序。
+ `choose_dead`決定哪些智能體在此時間步中死亡,并返回一個數組,包含死亡智能體的索引。
+ `choose_replacements`決定哪些智能體在此時間步中繁殖,在每個智能體上調用`copy`,并返回一個新的`Agent`對象的數組。
在這個版本的模擬中,每個時間步中新智能體的數量等于死亡智能體的數量,所以活動智能體的數量是恒定的。
## 11.5 沒有差異
在我們運行模擬之前,我們必須指定`choose_dead`和`choose_replacements`的行為。 我們將從這些函數的簡單版本開始,它們不依賴于適應性:
```py
# class Simulation
def choose_dead(self, fits):
n = len(self.agents)
is_dead = np.random.random(n) < 0.1
index_dead = np.nonzero(is_dead)[0]
return index_dead
def choose_replacements(self, n, fits):
agents = np.random.choice(self.agents, size=n, replace=True)
replacements = [agent.copy() for agent in agents]
return replacements
```
在`choose_dead`中,`n`是智能體的數量,`is_dead`是一個布爾數組,對于此時間步驟內死亡的智能體為`True`。 在這個版本中,每個智能體都有相同的死亡概率:0.1。 `choose_dead`使用`np.nonzero`來查找`is_dead`的非零元素的索引(`True`被視為非零)。
在`choose_replacements`中,`n`是在此時間步驟中復制的智能體數量。 它使用`np.random.choice`帶替換地選擇`n`個智能體。 然后它在每個上調用`copy`,并返回一個新的`Agent`對象列表。
這些方法不依賴于適應性,所以這種模擬沒有生存或繁殖差異。 因此,我們不應期待看到進化。 但是,我們怎么辨別呢?
## 11.6 進化的證據
進化的最具包容性的定義是,種群中基因型分布的變化。 進化是一種聚合效應:換句話說,個體不會進化;但種群會。
在這個模擬中,基因型是高維空間中的位置,因此很難將其分布中的變化可視化。 但是,如果基因型改變,我們預計它們的適應性也會改變。 所以我們將將適應性分布的變化用作進化的證據。 具體來說,我們將看看種群中適應性的均值和標準差。
在我們運行模擬之前,我們必須添加一個`Instrument`,它是在每個時間步驟后更新的對象,計算一個感興趣的統計量,并將結果存儲在一個序列中,我們稍后可以繪制它。
這是所有儀器的父類:
```py
class Instrument:
def __init__(self):
self.metrics = []
```
下面是`MeanFitness`的定義,`MeanFitness`是一個儀器,計算每個時間步的種群平均適應性:
```py
class MeanFitness(Instrument):
def update(self, sim):
mean = np.nanmean(sim.get_fitnesses())
self.metrics.append(mean)
```
現在我們準備好運行模擬了。 為了最小化起始種群中隨機變化的影響,我們使用同一組智能體啟動每個模擬。 為了確保我們探索整個適應性景觀,我們由每個位置的一個智能體開始。 以下是創建模擬的代碼:
```py
N = 8
fit_land = FitnessLandscape(N)
agents = make_all_agents(fit_land, Agent)
sim = Simulation(fit_land, agents)
```
`make_all_agents`為每個位置創建一個智能體; 本章的實現在筆記本中。
現在我們可以創建并添加`MeanFitness`儀器,運行模擬并繪制結果:
```py
instrument = MeanFitness()
sim.add_instrument(instrument)
sim.run()
sim.plot(0)
```
模擬維護了`Instrument`對象列表。 在每個時間步之后,它在列表中的每個儀器上調用`update`。
模擬運行后,我們使用`Simulation.plot`繪制結果,它接受索引作為參數,使用索引從列表中選擇一個`Instrument`并繪制結果。 在這個例子中,只有一個`Instrument`,索引為 0。
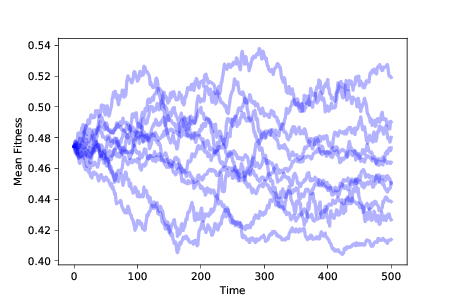
圖 11.1:隨著時間的推移,10 次模擬的平均適應性,沒有生存或繁殖差異
圖?顯示了運行這個模擬 10 次的結果。 種群的平均適應性隨機移動。 由于適應性的分布隨時間變化,我們推斷表現型的分布也在變化。 按照最具包容性的定義,這種隨機游走是一種進化。 但它不是一個特別有趣的類型。
特別是,這種進化并不能解釋生物物種如何隨時間變化,或者如何出現新的物種。 進化論是強大的,因為它解釋了我們在自然界看到的似乎無法解釋的現象:
+ 適應性:物種與其環境的相互作用似乎太復雜,太巧妙,并且偶然發生。 自然系統的許多特征看起來好像是設計出來的。
+ 增加的多樣性:地球上的物種數量隨時間而普遍增加(盡管有幾個時期的大規模滅絕)。
+ 增加的復雜性:地球上的生命史起始于相對簡單的生命形式,后來在地質記錄中出現了更復雜的生物體。
這些是我們想要解釋的現象。 到目前為止,我們的模型并沒有完成這個任務。
## 11.7 生存差異
讓我們再添加一種成分,生存差異。 以下是繼承`Simulation`并覆蓋`choose_dead`的類的定義:
```py
class SimWithDiffSurvival(Simulation):
def choose_dead(self, fits):
n = len(self.agents)
is_dead = np.random.random(n) > fits
index_dead = np.nonzero(is_dead)[0]
return index_dead
```
現在生存的概率取決于適應性;事實上,在這個版本中,智能體在每個時間步驟中幸存的概率是其適應性。
由于適應性低的智能體更有可能死亡,因此適應性高的智能體更有可能生存足夠長的時間來繁殖。 我們預計適應性低的智能體的數量會隨時間而減少,適應性高的智能體的數量會增加。
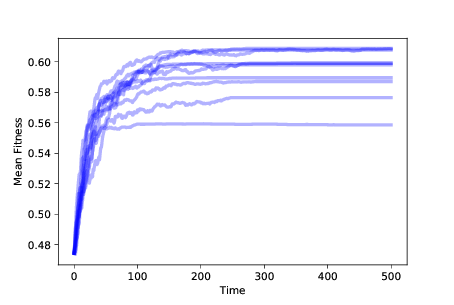
圖 11.2:隨著時間的推移,10 次模擬中的適應性均值,帶有生存差異
圖?顯示了隨著時間的推移,10 次模擬中的適應性均值,帶有生存差異。 平均適應性起初會迅速增加,但會逐漸平穩。
你或許可以弄清楚為什么它會平穩:如果在特定位置只有一個智能體并且它死了,它就會使這個位置變空。沒有突變,就沒有辦法讓它再次被占領。
在`N = 8`的情況下,該模擬以 256 個智能體開始,它們占用了所有可能位置。 占用位置的數量隨時間而減少;如果模擬運行時間足夠長,最終所有智能體將占用相同的位置。
所以這個模擬開始解釋適應性:增加的適應性意味著,物種在它的環境中生存得更好。 但是占用位置的數量隨時間而減少,所以這個模型根本無法解釋增加的多樣性。
在本章的筆記本中,你將看到差異化繁殖的效果。 正如你所預料的那樣,差異化繁殖也會增加平均適應性。但沒有突變,我們仍然沒有看到增加的多樣性。
## 11.8 突變
在目前的模擬中,我們以可能的最大多樣性開始 - 在景觀的每個位置都有一個智能體 - 并以可能的最小多樣性結束,所有智能體都在一個位置。
這與自然界發生的情況幾乎相反,它顯然以單個物種開始,這種物種隨時間而分化為今天的地球上數百萬甚至數十億物種(見 <https://en.wikipedia.org/wiki/Global_biodiversity>)。
使用我們模型的完美復制,我們從未看到增加的多樣性。 但是如果我們加上突變,再加上生存和繁殖差異,我們距離理解自然界的進化就更近了一步。
以下是繼承`Agent`并覆蓋`copy`的類定義:
```py
class Mutant(Agent):
prob_mutate = 0.05
def copy(self):
if np.random.random() > self.prob_mutate:
loc = self.loc.copy()
else:
direction = np.random.randint(self.fit_land.N)
loc = self.mutate(direction)
return Mutant(loc, self.fit_land)
```
在這種突變模型中,每次我們調用`copy`時,都有 5% 的突變機會。 在突變的情況下,我們從當前位置選擇一個隨機方向 - 即基因型中的一個隨機位 - 并翻轉它。 這是`mutate`:
```py
def mutate(self, direction):
new_loc = self.loc.copy()
new_loc[direction] ^= 1
return new_loc
```
運算符`^=`計算“異或”;操作數 1 具有翻轉一位的效果(請參閱 <https://en.wikipedia.org/wiki/Exclusive_or#Bitwise_operation>)。
現在我們有了突變,我們不必在每個位置都放置一個智能體。 相反,我們可以以最小變化開始:所有智能體在同一位置。
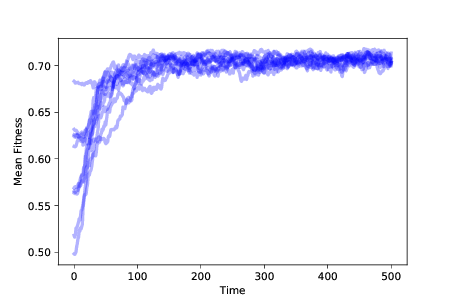
圖 11.3:隨著時間的推移,10 次模擬中的適應性均值,帶有突變、生存繁殖差異
圖?顯示了 10 次模擬的結果,帶有突變和生存繁殖差異。 在任何情況下,種群都會向最大適應性的位置進化。
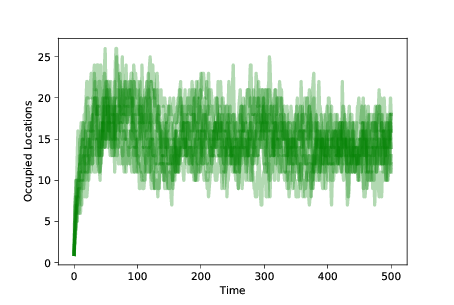
圖 11.4:隨著時間的推移,10 次模擬的占用位置的數量,帶有突變和生存繁殖差異。
為了測量種群的多樣性,我們可以繪制每個時間步后占用位置的數量。 圖?展示了結果。 我們以同一地點的 100 個智能體開始。 隨著突變的發生,占用位置的數量迅速增加。
當智能體發現適應性高的位置時,它更有可能生存和繁殖。 適應性較低的位置上的智能體最終消失。 種群在整個景觀中隨時間而移動,直到大多數智能體處于適合性最高的位置。
此時,系統達到平衡,突變以相同的速率占據新的位置,生存差異導致適合性低的位置清空。
平衡中的占用位置的數量,取決于突變率和生存差異的程度。 在這些模擬中,任何點處的獨特占用位置的數量通常為 10-20。
重要的是要記住,這個模型中的智能體不會移動,就像生物體的基因型沒有改變一樣。 當智能體死亡時,它可能會留下一個空位。 當發生突變時,它可以占據一個新的位置。 當智能體從某些地方消失并出現在其他地方時,種群會在景觀中移動,就像生命游戲中的滑翔機一樣。 但生命體不會進化;但種群可以。
## 11.9 物種形成
進化論說,自然選擇改變了現有的物種并創造了新的物種。 在我們的模型中,我們看到了變化,但我們并沒有看到新的物種。 在模型中,還不清楚新物種是什么樣。
在有性繁殖的物種中,如果兩種生物能夠繁殖并產生豐富的后代,則被視為同一物種。 但是模型中的智能體不會再現性行為,所以這個定義不適用。
在無性繁殖的生物中,如細菌,物種的定義并不明確。 一般來說,如果一個種群的基因型形成一個簇,那么它就被認為是一個物種,也就是說,如果種群內的遺傳差異比種群間的差異小。
在我們可以對新物種建模之前,我們需要能夠識別景觀中的智能體簇,這意味著我們需要定義位置之間的距離。 由于位置是用二進制數字串表示的,因此我們將距離定義為基因型中不同的位數。 `FitnessLandscape`提供了`distance `方法:
```py
# class FitnessLandscape
def distance(self, loc1, loc2):
return np.sum(np.logical_xor(loc1, loc2))
```
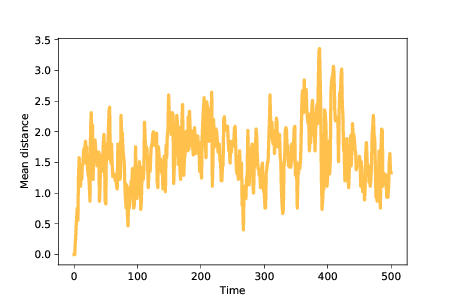
圖 11.5:智能體隨時間變化的平均距離
`logical_xor`函數計算“異或”,不同的元素為`True`,相同的元素為`False`。
為了量化種群的分散,我們可以計算每對智能體之間距離的平均值。 在本章的筆記本中,你會看到`MeanDistance`儀器,它會在每個時間步驟后計算這個度量。
圖? 展示了智能體隨時間的平均距離。 因為我們從相同的突變開始,所以初始距離為 0。隨著突變的發生,平均距離增加,在種群遍布景觀時達到最大值。
一旦智能體發現最佳位置,平均距離就會減小,直到種群達到平衡,由于突變引起的距離增加通過距離的減小而平衡,因為遠離最佳位置的智能體更有可能死亡。 在這些模擬中,平衡時的平均距離接近 1.5;也就是說,大多數智能體距離最佳位置只有 1-2 個突變。
現在我們準備尋找新的物種。 為了模擬一種簡單的物種形成,假設一個種群在不變的環境中演化,直到它達到穩定狀態(就像我們在自然界發現的一些物種,似乎在很長一段時間內變化很小)。
現在假設我們改變環境,或者將種群轉移到新的環境中。 一些舊環境中適應性較高的特性,可能會在新環境中適應性較低,反之亦然。
我們可以通過運行模擬來模擬這些情景,直到種群達到穩定狀態,然后改變適應性景觀,然后恢復模擬,直到種群再次達到穩定狀態。
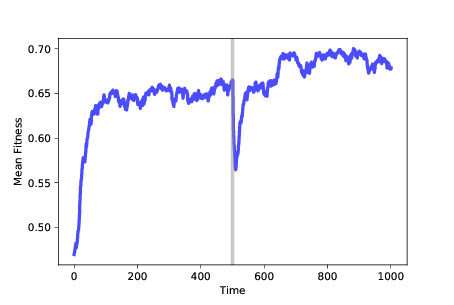
圖 11.6:隨時間變化的適應性均值。在 500 步之后,我們改變了適應性景觀
圖?展示了這樣的模擬結果。 再次,我們從隨機位置開始,使用 100 個相同的突變體,并運行 500 個時間步驟的模擬。 在這個時候,許多智能體處于最佳位置,在這個例子中,其適應性接近 0.65。 智能體的基因型形成一個簇,智能體之間的平均距離接近 1。
經過 500 步之后,我們運行`FitnessLandscape.set_values`,這改變了適應性景觀; 然后我們恢復模擬。 平均適應性會立即下降,因為舊景觀中的最佳位置并不比新景觀中的隨機位置好。
然而,當種群遷移到新景觀時,平均適應性會迅速增加,最終會找到新的最佳值,其適應度接近 0.75(在這個例子中恰好更高,但不一定是)。
一旦種群達到穩定狀態,它就會形成一個新的簇,智能體之間的平均距離再次接近 1。
現在,如果我們計算智能體之前和之后的位置之間的距離,平均而言,它們相差超過 6。 簇之間的距離遠大于每個簇內的距離,因此我們可以將這些簇解釋為不同的物種。
## 11.10 總結
我們已經看到,突變以及生存和繁殖差異,足以導致適應性的增加,多樣性的增加,并產生簡單形式的物種。 這種模型并不是現實的;自然系統中的進化要比這復雜得多。 相反,它意味著一個“充足定理”;也就是說,模型的特征足以產生我們試圖解釋的行為(參見 <https://en.wikipedia.org/wiki/Necessity_and_sufficiency>)。
從邏輯上講,這個“定理”并不能證明,自然界中的進化僅僅由這些機制引起,但是由于這些機制確實以多種形式出現在生物系統中,所以認為它們至少有助于自然進化,是合理的。
同樣,該模型并不能證明這些機制總是會導致進化。 但是我們在這里看到的結果是可靠的:在幾乎所有包含這些特征的模型中 - 不完美的復制者,變異性和繁殖差異 - 發生了進化。
我希望這一觀察有助于揭開進化的神秘面紗。 當我們觀察自然系統時,進化看起來很復雜。 而且由于我們主要看到了進化的結果,而沒有看到這個過程,所以難以想象和相信。
但在模擬中,我們看到整個過程,而不僅僅是結果。 通過包含最少的一系列特征來產生進化 - 暫時忽略了生物生命的巨大復雜性 - 我們可以將進化看作是一個令人驚訝的簡單,不可避免的想法。
## 11.11 練習
本章的代碼位于本書倉庫的 Jupyter 筆記本`chap11.ipynb`中。 打開筆記本,閱讀代碼并運行單元格。 筆記本包含本章的練習。 我的解決方案在`chap11soln.ipynb`中。
