
pipeline流水線設計是一種典型的面積換性能的設計。一方面通過對長功能路徑的合理劃分,在同一時間內同時并行多個該功能請求,大大提高了某個功能的吞吐率;另一方面由于長功能路徑被切割成短路徑,可以達到更高的工作頻率,如果不需要提高工作頻率,多出來的提頻空間可以用于降壓降功耗。
1.1 熟悉的經典MIPS五級流水線
在此流水線中一條指令的生命周期分為:
取指:指令取指(Instruction Fetch)是指將指令從存儲器中讀取出來的過程。
譯碼:指令譯碼(Instruction Decode)是指將存儲器中取出的指令進行翻譯的過程。經過譯碼之后得到指令需要的操作數寄存器索引,可以使用此索引從通用寄存器組(Register File,Regfile)中將操作數讀出。
執行:指令譯碼之后所需要進行的計算類型都已得知,并且已經從通用寄存器組中讀取出了所需的操作數,那么接下來便進行指令執行(Instruction Execute)。指令執行是指對指令進行真正運算的過程。如果指令是一條加法運算指令,則對操作數進行加法操作;如果是減法運算指令,則進行減法操作。在“執行”階段的最常見部件為算術邏輯部件運算器(Arithmetic Logical Unit,ALU),作為實施具體運算的硬件功能單元。
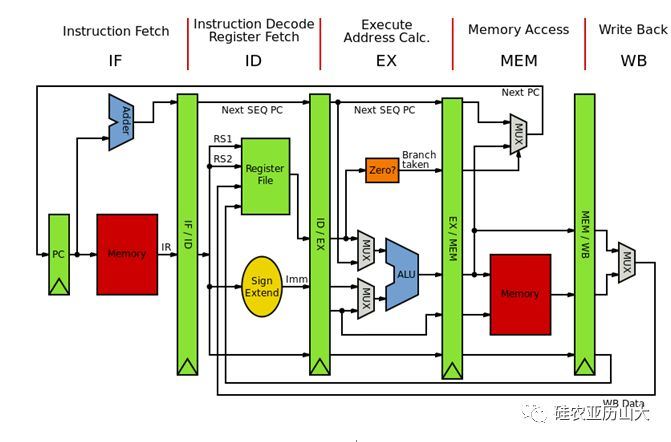
MIPS五級流水線結構圖
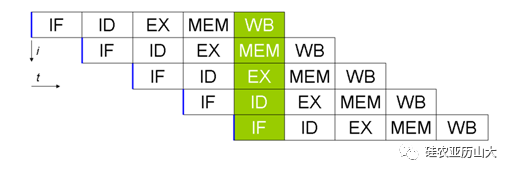
MIPS五級流水線運行圖
訪存:存儲器訪問指令往往是指令集中最重要的指令類型之一,訪存(Memory Access)是指存儲器訪問指令將數據從存儲器中讀出,或者寫入存儲器的過程。
寫回:寫回(Write-Back)是指將指令執行的結果寫回通用寄存器組的過程。如果是普通運算指令,該結果值來自于“執行”階段計算的結果;如果是存儲器讀指令,該結果來自于“訪存”階段從存儲器中讀取出來的數據。
上述的五級流水線為例,由于前一條指令在完成了“取指”進入“譯碼”階段后,下一條指令馬上就可以進入“取指”階段,依次類推,如果流水線沒有停頓,理論上可以取得每個時鐘周期都完成一條指令的性能。
1.2 流水線深度設置的正面意義與反面意義
正面意義:在兩級寄存器(每一級流水線由寄存器組成)之間的硬件邏輯越少,則意味能夠運行到更高的主頻。因此現代的處理器流水線極深主要是由于處理器追求高頻的指標所驅使,高端的ARM Cortex-A系列由于有十幾級的流水線,所以能夠運行到高達2GHz的主頻,而Intel的x86處理器甚至采用幾十級的流水線深度將主頻推到3-4GHz的高度。主頻越高也意味著流水線的吞吐率越高從而性能越高。
反面意義:首先更多的流水線級數要消耗更多的寄存器,也意味著更多的面積開銷。其次同時流水線越深,由于每一級流水線需要進行握手,流水線最后一級的反壓信號可能會一直串擾到最前一級造成嚴重的時序問題,需要使用一些比較高級的技巧來解決此類反壓時序問題。最后在流水線的取指令階段無法得知條件跳轉的結果,因此只能進行預測,到了流水線的末端才能夠通過實際的運算得知該分支是真的該跳還是不該跳,如果發現真實的結果與之前預測的結果不相符,則意味著預測失敗,需要將所有預取的錯誤指令流全部丟棄掉,而重新取正確的指令流,這個過程叫做流水線沖刷(Pipeline Flush)。
解決反壓信號串擾的問題,可以采用取消反壓信號,加入乒乓緩存,加入前向旁路緩存,基本都是以面積換取性能的方法。
深處種菱淺種稻,不深不淺種荷花,流水線的不同深度皆有其優缺點,需要根據不同的應用背景合理地進行選擇。
1.3 選擇使用流水線設計的理由
使用流水線一般是時序比較緊張,對電路工作頻率較高的時候。
功能模塊之間的流水線,用乒乓 buffer 來交互數據。代價是增加了 memory 的數量,但是和獲得的巨大性能提升相比,可以忽略不計。
I/O 瓶頸,比如某個運算需要輸入 8 個數據,而 memroy 只能同時提供 2 個數據,如果通過適當劃分運算步驟,使用流水線反而會減少面積。
片內 sram 的讀操作,因為 sram 的讀操作本身就是兩極流水線,除非下一步操作依賴讀結果,否則使用流水線是自然而然的事情。
組合邏輯太長,比如(a+b)*c,那么在加法和乘法之間插入寄存器是比較穩妥的做法。
1.4 流水線的stage劃分
一般來說,劃分流水線的考慮因素如下,
如果流水線切割的子功能抽象層次較高,可以按照完整的功能進行流水線劃分。
流水線最好劃分在數據通路上位寬較小的地方,以節省寄存器數量和面積。
流水線每一級的關鍵路徑延時最好接近,利于獲得最大的Timing margin。
簡單的流水線實例參見參考文獻二,pipe line 分割了關鍵路徑延時,提高了整體設計的工作頻率 25.6%。
參考文獻
【1】芯片設計小經驗–流水線設計(微信公眾號:數字IC自修室)
【2】IC設計實例解析之“流水線技術”
【3】名家專欄|你真的懂處理器流水線?
【4】為什么CPU流水線設計的級越長,完成一條指令的速度就越快?
【5】Verilog十大基本功1(流水線設計Pipeline Design)
【6】流水線設計的方法和作用
【7】跟濤哥一起學嵌入式 31:深入淺出CPU流水線工作原理
- 空白目錄
- 流水線
- 流水線性能測評
- 計算機性能測評
- 流水線設計
- 購物車狀態機
- 序列檢測器
- 序列檢測10010
- 序列檢測10010帶圖
- 反相器
- 計數器
- 分頻電路
- 偶數分頻
- 奇數分頻
- 小數分頻
- 同步復位異步釋放all
- 對的-異步復位同步釋放原理
- 同步復位異步釋放
- 異步復位為什么要同步釋放 ?
- FPGA-異步復位同步釋放 通俗解釋
- 同步復位
- 狀態機
- 狀態機的分類
- 狀態機5個要素
- FIFO
- 異步fifo中同步為什么要用兩級觸發器
- 亞穩態
- 亞穩態的產生機理、消除辦法 (可以理解為什么打拍)
- 面向對象思想
- 為什么D觸發器有setup time和hold time的要求
- Tsu,Tco,Th,Tpd的概念
- verilog
- 自啟動
- 毛刺
- 馮諾依曼