
2021-03-28 周天
## 知識點
***2個數據結構(sds,dict),單機數據庫***
### c語言字符串
```
redisLog(warning,'xxx')
```
其中xxx就是用普通字符串類型。
### sds
simple dynamic string - 簡單動態字符串。

1. 存的字符串能被修改時,默認使用sds。(比如strings,hash里的key)
***buf指向一個數組,最后存的是一個'\0'空字符,不計算在len長度內***
2. 緩存區
aof 里的buff也是用sds實現。
### dict
保存鍵值對,也叫做映射,或者關聯。
因為C語言沒有實現這種高級的數據結構,所以redis實現了自己的字典數據結構。
并且基于字典實現了redis數據庫。
應用在hash鍵和數據庫內。
1. dict數據結構
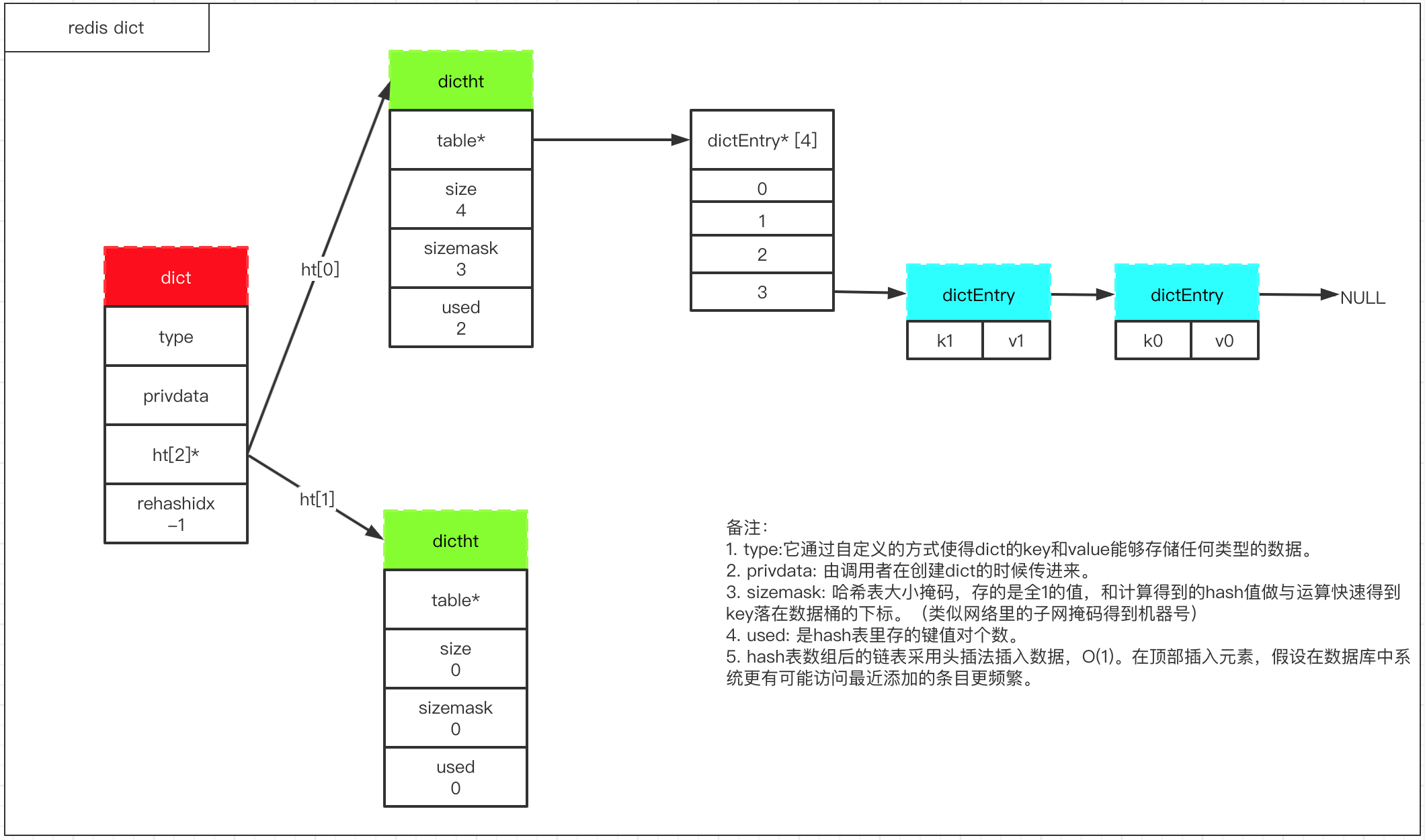
2. hash算法
> Redis不同版本使用的哈希算法并不一樣.
> 5.0,4.0 版本使用的siphash.
> 3.2, 3.0, 2.8 使用的是murmurhash2.
3. hash沖突解決
因為就算使用了hash算法,數據量大起來后,會用不同的key落在同一個hash桶的同一個下標,于是數組后面掛的是鏈表,這樣就能解決hash沖突。
4. dict rehash
redis的dict rehash采用漸進式的方式,具體請參考[redis中的hash擴容、漸進式rehash過程](https://zhuanlan.zhihu.com/p/258340429)。
注意點:
* `rehash`時`ht[1].size=ht[0].size * 2`。
* hash表的負載因子計算方式(`load_factor = ht[0].used / ht[0].size`)
* 服務端在存在持久化子進程時,load_factor>=5才會擴容;不存在時,load_factor>=1時會擴容;load_factor<=0.1,會縮容。
* rehash過程是漸進式完成的,比如有1萬個key需要轉移,會將整個操作分散到客戶端對該dict的新增,查詢,修改,刪除里,分而治之。
* 在rehash過程中,rehashidx=0開始,直到ht[0].used=0,表示rehash完成,rehashidx重置為-1。
* 在rehash過程中,查詢操作會先查找ht[0],再查詢ht[1];新增操作則直接插入到ht[1]里,保證ht[0].used一直減少。
### redisDb數據庫
1. redisServer 和 redisDb的數據結構
``` c
struct redisServer {
...
redisDb *db; /* 一個數組,保存服務端所有數據庫 */
int dbnum; /* 配置初始化的db數量,默認16 */
...
}
```
``` c
struct redisDb {
dict *dict; /* 數據庫鍵空間 */
dict *expires; /* 鍵的超時時間空間 */
...
int id; /* 數據庫下標 */
...
}
```
2. redisDb里的鍵空間,過期時間空間
redis是一個key-value型數據庫服務器,服務器上的每個數據庫都是由redisDb里的dict字典來保存所有鍵值對,將這個字典稱之為"鍵空間"。
* 鍵空間里的鍵就是數據庫里的key,是字符串對象,用的sds。
* 鍵空間里的值就是數據庫里的value,是redis支持的對象類型,比如字符串,列表,哈希表,集合,有序集合對象中的一種。
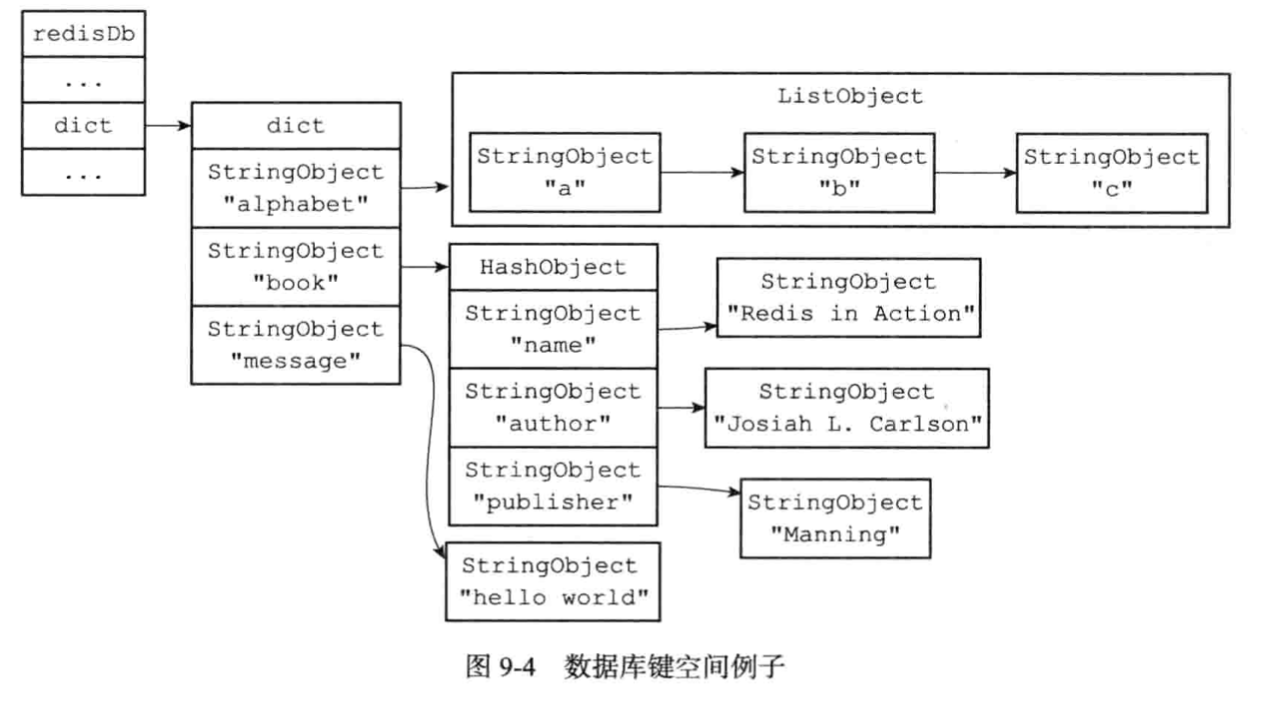
其中超時時間也是用dict字典空間來存儲的,而且存的是計算后的時刻。
TTL - 剩余生存時間。
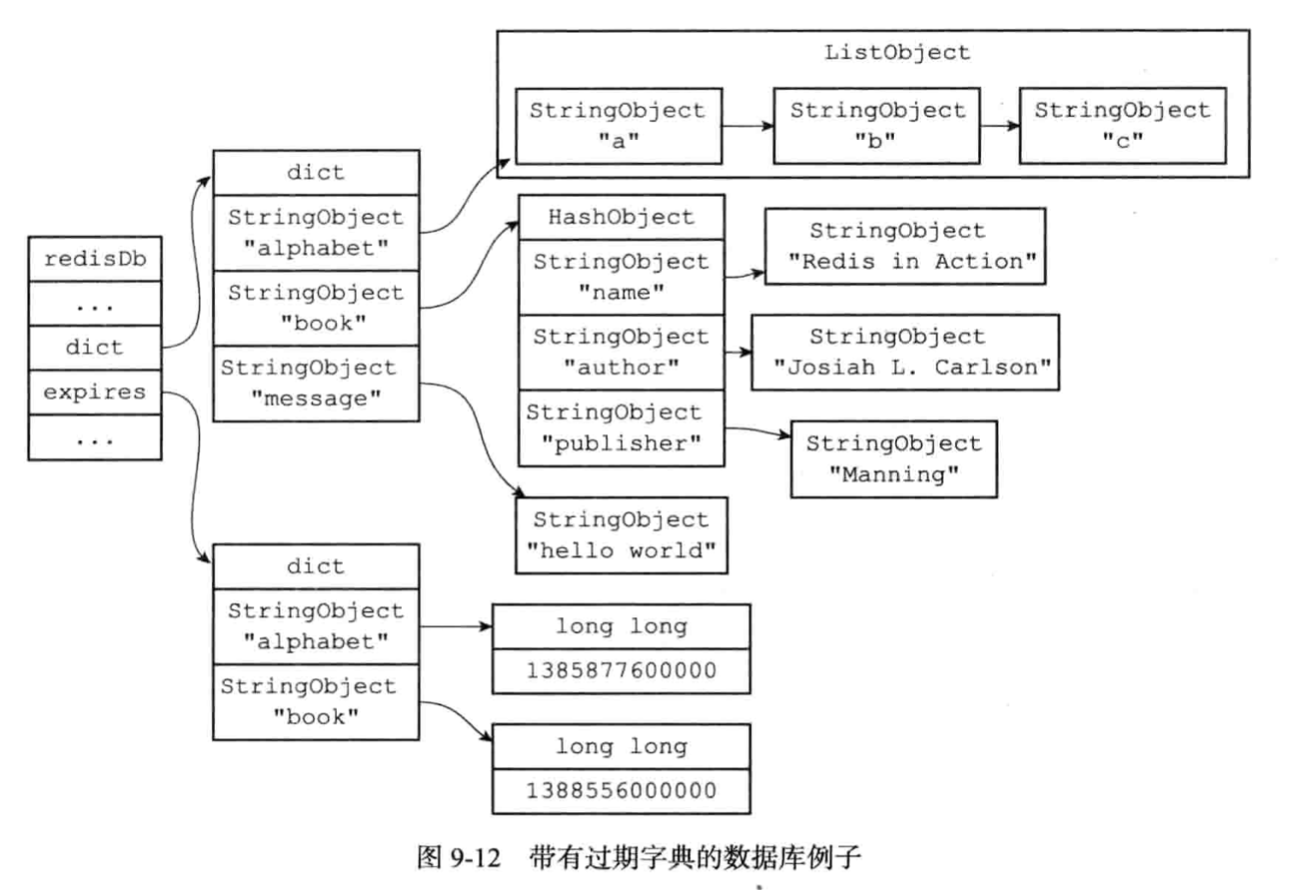
***請參考[info命令統計信息](https://zhuanlan.zhihu.com/p/78297083)***
3. 過期鍵刪除
有如下3種,定時刪除策略,惰性刪除策略,定期刪除策略。
***而redis采用的是惰性刪除和定期刪除策略***
* 惰性刪除實現
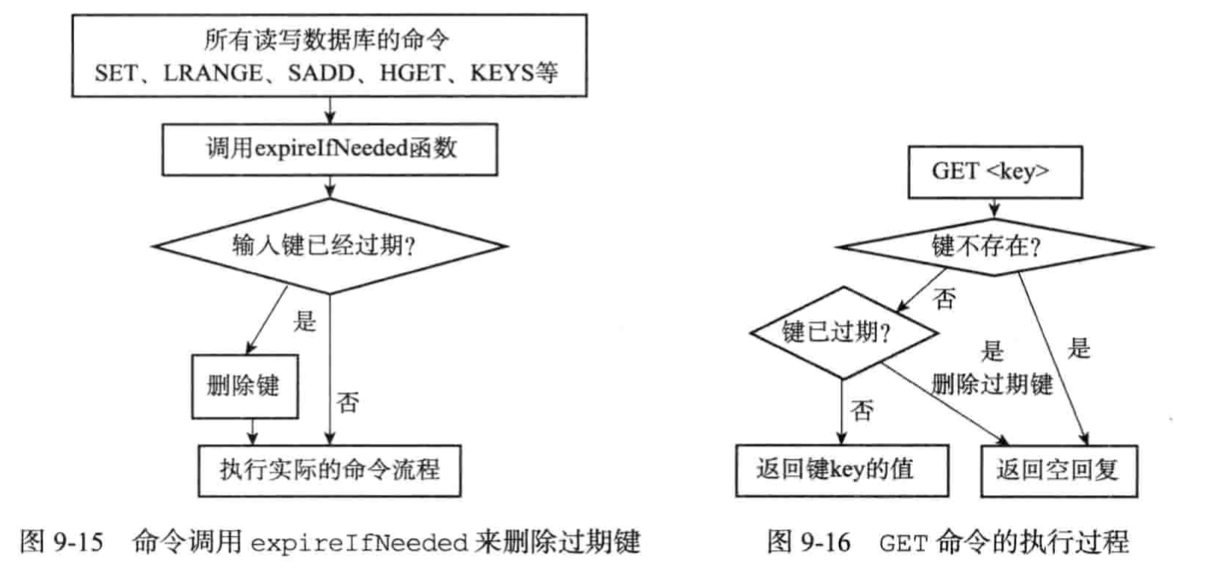
* 定期刪除實現
每當服務端執行serverCron周期性執行函數時,就會執行`activeExpiressCycle`函數

分多次檢查16個數據庫,每個庫20個鍵,如果失效就刪除。沒有執行完就下次接著執行,unsigned long expires\_cursor; /* Cursor of the active expire cycle. */。
## 會后討論
* sds vs C字符串
1. sds 長度O(1),C字符串 長度O(n)。
2. sds不需要指定分配長度大小,從而杜絕緩沖區溢出。
3. sds的free實現了空間預分配和惰性釋放2種優化方式減少空間重分配次數。
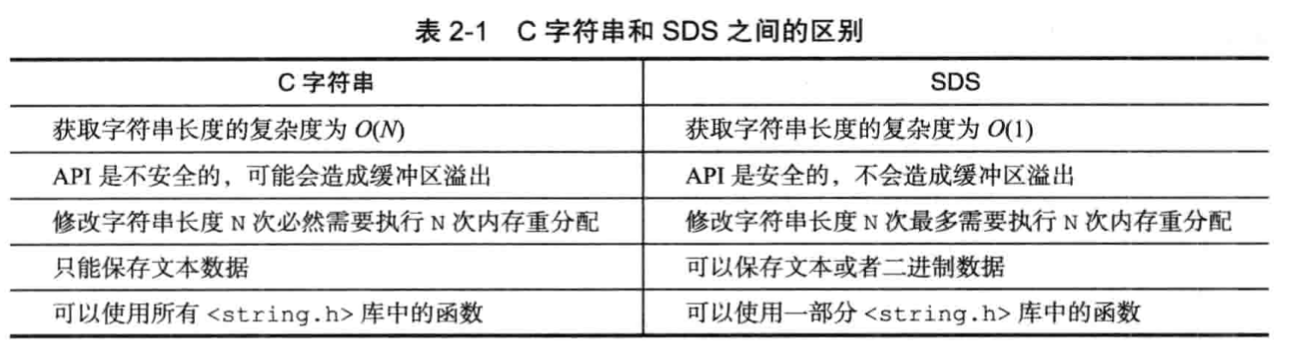
* 二進制安全
sds里存的是字節數組,就是二進制數據。存入什么,讀取什么,不會被篡改。不會因為客戶端編碼異常。
* 序列化
1. 概念
> 序列化:把對象轉化為可傳輸的字節序列過程稱為序列化。
> 反序列化:把字節序列還原為對象的過程稱為反序列化。
2. 目的
序列化最終的目的是為了對象可以跨平臺存儲,和進行網絡傳輸。
3. 場景
凡是需要進行“跨平臺存儲”和”網絡傳輸”的數據,都需要進行序列化。
4. 方式
JDK(不支持跨語言)、JSON、XML、Hessian、Kryo(不支持跨語言)、Thrift、Protostuff、FST(不支持跨語言)
5. Java序列化pk
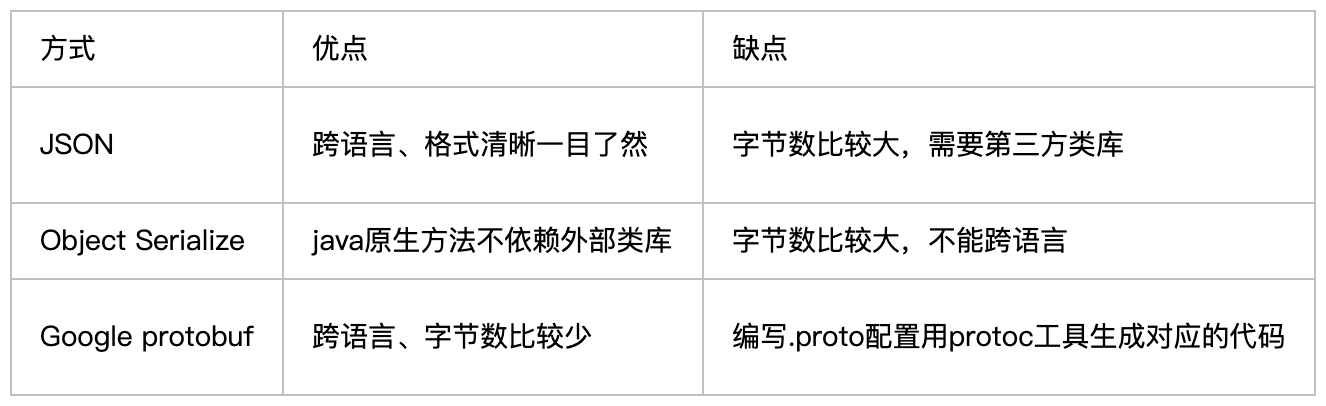
- Redis來回摩擦
- redis的數據結構SDS和DICT
- redis的持久化和事件模型
- Java
- 從何而來之Java IO
- 發布Jar包到公共Maven倉庫
- Java本地方法調用
- 面試突擊
- Linux
- Nginx
- SpringBoot
- Springboot集成Actuator和SpringbootAdminServer監控
- SpringCloud
- Spring Cloud初識
- Spring Cloud的5大核心組件
- Spring Cloud的注冊中心
- Spring Cloud注冊中心之Eureka
- Spring Cloud注冊中心之Consul
- Spring Cloud注冊中心之Nacos
- Spring Cloud的負載均衡之Ribbon
- Spring Cloud的服務調用之Feign
- Spring Cloud的熔斷器
- Spring Cloud熔斷器之Hystrix
- Spring Cloud的熔斷器監控
- Spring Cloud的網關
- Spring Cloud的網關之Zuul
- Spring Cloud的配置中心
- Spring Cloud配置中心之Config Server
- Spring Cloud Config配置刷新
- Spring Cloud的鏈路跟蹤
- Spring Cloud的鏈路監控之Sleuth
- Spring Cloud的鏈路監控之Zipkin
- Spring Cloud集成Admin Server
- Docker
- docker日常基本使用
- docker-machine的基本使用
- Kubernetes
- kubernetes初識
- kubeadm安裝k8s集群
- minikube安裝k8s集群
- k8s的命令行管理工具
- k8s的web管理工具
- k8s的相關發行版
- k3s初識及安裝
- rancher的安裝及使用
- RaspberryPi
- 運維
- 域名證書更新
- 騰訊云主機組建內網
- IDEA插件開發
- 第一個IDEA插件hello ide開發
- 千呼萬喚始出來的IDEA筆記插件mdNote
- 大剛學算法
- 待整理
- 一些概念和知識點
- 位運算
- 數據結構
- 字符串和數組
- LC242-有效的字母異位詞
- 鏈表
- LC25-K個一組翻轉鏈表
- LC83-刪除有序單鏈表重復的元素
- 棧
- LC20-有效的括號
- 隊列
- 雙端隊列
- 優先隊列
- 樹
- 二叉樹
- 二叉樹的遍歷
- 二叉樹的遞歸序
- 二叉樹的前序遍歷(遞歸)
- 二叉樹的前序遍歷(非遞歸)
- 二叉樹的中序遍歷(遞歸)
- 二叉樹的中序遍歷(非遞歸)
- 二叉樹的后序遍歷(遞歸)
- 二叉樹的后序遍歷(非遞歸)
- 二叉樹的廣度優先遍歷(BFS)
- 平衡二叉樹
- 二叉搜索樹
- 滿二叉樹
- 完全二叉樹
- 二叉樹的打印(二維數組)
- 樹的序列化和反序列化
- 前綴樹
- 堆
- Java系統堆優先隊列
- 集合數組實現堆
- 圖
- 圖的定義
- 圖的存儲方式
- 圖的Java數據結構(鄰接表)
- 圖的表達方式及對應場景創建
- 圖的遍歷
- 圖的拓撲排序
- 圖的最小生成樹之Prim算法
- 圖的最小生成樹之Kruskal算法
- 圖的最小單元路徑之Dijkstra算法
- 位圖
- Java實現位圖
- 并查集
- Java實現并查集
- 滑動窗口
- 單調棧
- 排序
- 冒泡排序BubbleSort
- 選擇排序SelectSort
- 插入排序InsertSort
- 插入排序InsertXSort
- 歸并排序MergeSort
- 快速排序QuickSort
- 快速排序優化版QuickFastSort
- 堆排序HeapSort
- 哈希Hash
- 哈希函數
- guava中的hash函數
- hutool中的hash函數
- 哈希表實現
- Java之HashMap的實現
- Java之HashSet的實現
- 一致性哈希算法
- 經典問題
- 荷蘭國旗問題
- KMP算法
- Manacher算法
- Go