
[TOC]
# 散列
在對某個集合進行查找,列表需要的時間為是O(n),樹查找為O(logN),散列是一種常數平均時間執行。
對于散列,我們要新增或查找某個元素,我們通過把當前元素的關鍵字 通過某個函數映射到數組中的某個位置,通過數組下標一次定位就可完成操作。
**存儲位置 = f(關鍵字)**
其中,這個函數f一般稱為**散列函數**,這個函數的設計好壞會直接影響到**散列表**的優劣。
## 散列函數
好的哈希函數會盡可能地保證?**計算簡單和散列地址分布均勻.**
[Java中String的hash函數分析](https://blog.csdn.net/hengyunabc/article/details/7198533)
[Time33哈希算法](https://blog.csdn.net/fengxinze/article/details/7186765)
## 散列沖突
首先散列函數并不保證計算結果唯一, 通過散列函數得出的實際存儲地址相同怎么辦?也就是說,當我們對某個元素進行哈希運算,得到一個存儲地址,然后要進行插入的時候,發現已經被其他元素占用了,其實這就是所謂的哈希沖突,也叫散列碰撞
散列沖突的解決方案有多種:開放定址法(發生沖突,繼續尋找下一塊未被占用的存儲地址),再散列函數法,鏈地址法,而HashMap即是采用了鏈地址法,也就是數組+鏈表的方式。
# HashMap(基于jdk1.8)
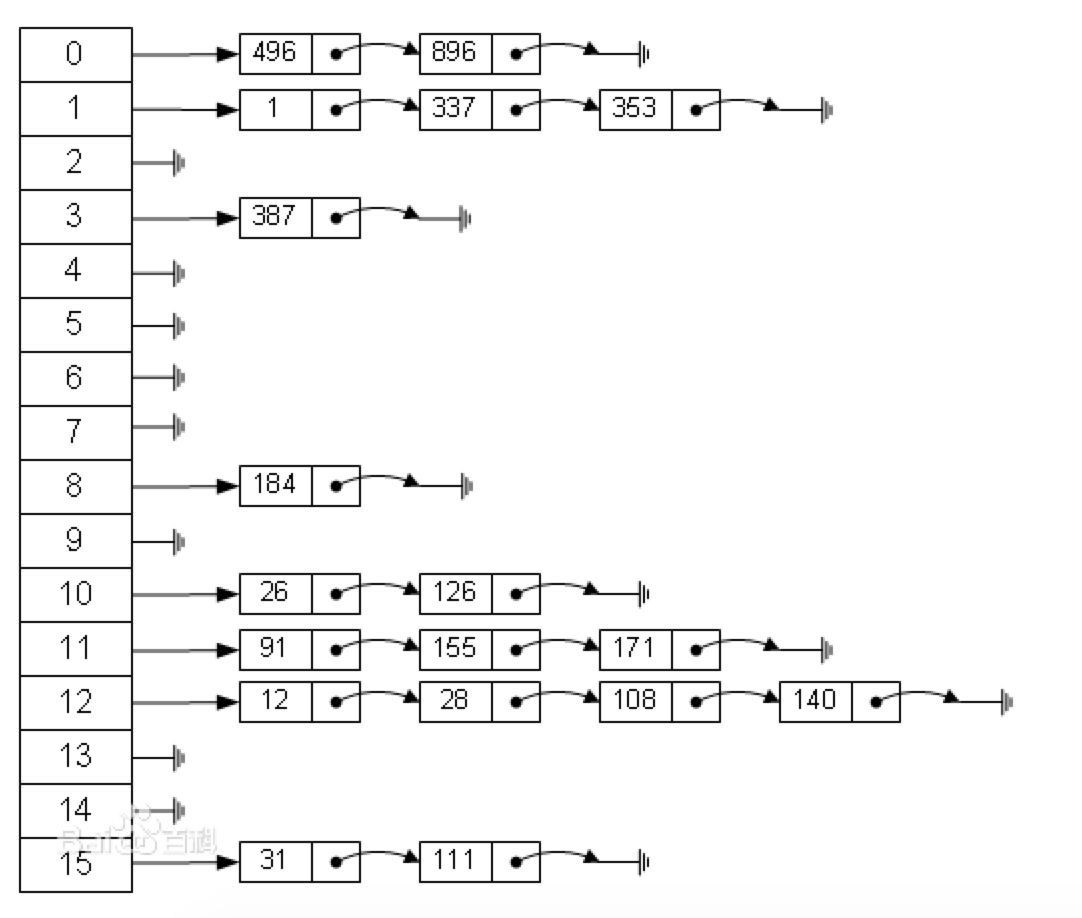
從上圖我們可以看到,HashMap由**鏈表+數組**組成,他的**底層結構是一個數組,而數組的元素是一個單向鏈表(當數量大于8時,切換為紅黑樹)。**
接下來,我們開始分析源碼
## Node
HashMap的主干是一個Node數組。Entry是HashMap的基本組成單元,每一個Entry包含一個key-value鍵值對。
?Node是HashMap中的一個靜態內部類。代碼如下
~~~
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
~~~
## 核心成員變量
~~~
//以Node<K,V>為元素的數組,也就是上圖HashMap的縱向的長鏈數組,起長度必須為2的n次
transient Node<K,V>[] table;
//大小
transient int size
//負載因子,代表了table的填充度有多少,默認是0.75
final float loadFactor;
//擴容的臨界值,或者所能容納的key-value對的極限。當size>threshold的時候就會擴容
int threshold;
~~~
## 構造函數
構造函數并僅僅是做了一些賦值操作
~~~
public HashMap(int initialCapacity, float loadFactor) {
...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
//高效的計算出大于且距離最小的2n這個值
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1
~~~
## 插入
~~~
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//1 處理table為空,未初始化的情況
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//2 算元素所要儲存的位置index((n - 1) & hash)
//2.1 如果該位置沒有值,這直接插入newNode
tab[i] = newNode(hash, key, value, null);
else {
//2.2 如果該位置有值
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//2.2.1 key值相同,直接覆蓋
e = p;
else if (p instanceof TreeNode)
//2.2.2 如果是紅黑樹, 插入樹
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//2.2.3 如果是鏈表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//2.2.3.1 如果是鏈表找不到值,newNode
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
//2.2.3.1。1 如果是鏈表過長,轉化為紅黑樹
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
//2.2.3.2 如果是鏈表找到值,直接替換
break;
p = e;
}
}
if (e != null) { // existing mapping for key
//2.2.4 已經存在
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
~~~
## hash 與 index
~~~
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
int index = (n - 1) & hash;
~~~
## 擴容resize
HashMap擴容可以分為三種情況:
第一種:使用默認構造方法初始化HashMap。從前文可以知道HashMap在一開始初始化的時候會返回一個空的table,并且thershold為0。因此第一次擴容的容量為默認值DEFAULT\_INITIAL\_CAPACITY也就是16。同時threshold = DEFAULT\_INITIAL\_CAPACITY \* DEFAULT\_LOAD\_FACTOR = 12。
第二種:指定初始容量的構造方法初始化HashMap。那么從下面源碼可以看到初始容量會等于threshold,接著threshold = 當前的容量(threshold) \* DEFAULT\_LOAD\_FACTOR。
第三種:HashMap不是第一次擴容。如果HashMap已經擴容過的話,那么每次table的容量以及threshold量為原有的兩倍。
~~~
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
~~~
## 參考資料
[JDK8中的HashMap實現原理及源碼分析](https://www.jianshu.com/p/17177c12f849)
- Java
- Object
- 內部類
- 異常
- 注解
- 反射
- 靜態代理與動態代理
- 泛型
- 繼承
- JVM
- ClassLoader
- String
- 數據結構
- Java集合類
- ArrayList
- LinkedList
- HashSet
- TreeSet
- HashMap
- TreeMap
- HashTable
- 并發集合類
- Collections
- CopyOnWriteArrayList
- ConcurrentHashMap
- Android集合類
- SparseArray
- ArrayMap
- 算法
- 排序
- 常用算法
- LeetCode
- 二叉樹遍歷
- 劍指
- 數據結構、算法和數據操作
- 高質量的代碼
- 解決問題的思路
- 優化時間和空間效率
- 面試中的各項能力
- 算法心得
- 并發
- Thread
- 鎖
- java內存模型
- CAS
- 原子類Atomic
- volatile
- synchronized
- Object.wait-notify
- Lock
- Lock之AQS
- Lock子類
- 鎖小結
- 堵塞隊列
- 生產者消費者模型
- 線程池