
[TOC]
## 簡介
java語言提供了一種稍弱的同步機制,即volatile變量,用來確保將變量的更新操作通知到其他線程。
* 當把變量聲明為volatile類型后,編譯器與運行時都會注意到這個變量是共享的,因此不會將該變量上的操作與其他內存操作一起重排序。
* volatile變量不會被緩存在寄存器或者對其他處理器不可見的地方,因此在讀取volatile類型的變量時總會返回最新寫入的值。
當一個變量定義為 volatile 之后,將具備兩種特性:
### 可見性
* 當一個線程修改了這個變量的值,volatile 保證了新值能立即同步到主內存,以及每次使用前立即從主內存刷新。但普通變量做不到這點,普通變量的值在線程間傳遞均需要通過主內存(詳見:Java內存模型)來完成。
* volatile之所以具有可見性,是因為底層中的Lock指令,該指令會將當前處理器緩存行的數據直接寫會到系統內存中,且這個寫回內存的操作會使在其他CPU里緩存了該地址的數據無效。
### 指令重排序優化
* 有volatile修飾的變量,賦值后多執行了一個“load addl $0x0, (%esp)”操作,這個操作相當于一個內存屏障(指令重排序時不能把后面的指令重排序到內存屏障之前的位置),只有一個CPU訪問內存時,并不需要內存屏障;
* 指令重排序:是指CPU采用了允許將多條指令不按程序規定的順序分開發送給各相應電路單元處理
* volatile之所以能防止指令重排序,是因為Java編譯器對于volatile修飾的變量,會插入內存屏障。內存屏障會防止CPU處理指令的時候重排序的問題
## 可見性原理
物理計算機為了處理緩存不一致的問題。提出了緩存一致性的協議,其中緩存一致性的核心思想是:
> 1\. 當CPU寫數據時,如果發現操作的變量是共享變量,即在其他CPU中也存在該變量的副本,會發出信號通知其他CPU將該變量的緩存行置為無效狀態
> 2\. 因此當其他CPU需要讀取這個變量時,發現自己緩存中緩存該變量的緩存行是無效的,那么它就會從內存重新讀取。
既然volatile修飾的變量能具有“可見性”,那么volatile內部肯定是走的底層,同時也肯定滿足緩存一致性原則。
因為涉及到底層匯編,這里我們不要去了解匯編語言,我們只要知道當用volatile修飾變量時,生成的匯編指令會比普通的變量聲明會多一個Lock指令。那么Lock指令會在多核處理器下會做兩件事情:
1. 將當前處理器緩存的數據直接寫會到系統內存中,從Java內存模型來理解,就是將線程中的工作內存的數據直接寫入到主內存中
2. 這個寫回內存的操作會使在其他CPU里緩存了該地址的數據無效。從Java內存模型理解,當線程A將工作內存的數據修改后(新值),同步到主內存中,那么線程B從主內存中初始的值(舊值)就無效了
從某種意義上,它就相當于:聲明變量是 volatile 的,JVM 保證了每次讀變量都從主內存中讀,跳過 CPU cache這一步。
## 防止重排序
在《(2.1.27.2)Java并發編程:JAVA的內存模型》我們已經提及“CPU(處理器)會對沒有數據依賴性的指令進行重排序”在多線程環境中引發的問題,Java內存模型規定了使用volatile來修飾相應變量時,可以防止CPU(處理器)在處理指令的時候禁止重排序。具體如下圖所示
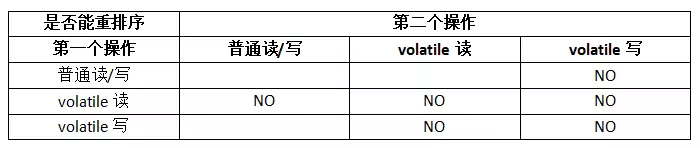
【volatile防止重排序規則】
從上表我們可以看出
1. 當第二個操作是volatile寫時,不管第一個操作是什么,都不能重排序,這個規則確保voatile寫之前的操作不會被編譯器排序到volatile之后。
2. 當第一個操作是volatile讀時,不管第二個操作是什么,都不能重排序。這個規則確保volatile讀之后的操作不會被編譯器重排序到volatile讀之前。
3. 當第一個操作是volatile寫,第二個操作如果是volatile讀時,不能進行重排序。
### 寫內存屏障

storestore屏障:
* 對于這樣的語句store1; storestore; store2,在store2及后續寫入操作執行前,保證store1的寫入操作對其它處理器可見。
* (也就是說如果出現storestore屏障,那么store1指令一定會在store2之前執行,CPU不會store1與store2進行重排序)
storeload屏障:
* 對于這樣的語句store1; storeload; load2,在load2及后續所有讀取操作執行前,保證store1的寫入對所有處理器可見。
* (也就是說如果出現storeload屏障,那么store1指令一定會在load2之前執行,CPU不會對store1與load2進行重排序)
### 讀內存屏障
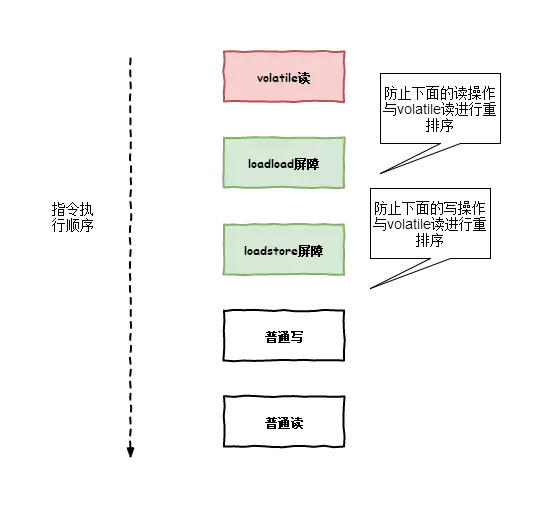
loadload屏障:
* 對于這樣的語句load1; loadload; load2,在load2及后續讀取操作要讀取的數據被訪問前,保證load1要讀取的數據被讀取完畢。
* (也就是說,如果出現loadload屏障,那么load1指令一定會在load2之前執行,CPU不會對load1與load2進行重排序)
loadstore屏障:
* 對于這樣的語句load1; loadstore; store2,在store2及后續寫入操作被刷出前,保證load1要讀取的數據被讀取完畢。
* (也就是說,如果出現loadstore屏障,那么load1指令一定會在load2之前執行,CPU不會對load1與store2進行重排序)
## volatile的使用條件
現在我們已經了解了volatile的相關特性,那么就來說說,volatile的具體使用場景,因為volatie變量只能保證可見性,并不能保證原子性,這就是說線程能夠自動發現 volatile 變量的最新值。所以在輕量級線程同步中我們可以使用volatile關鍵字。
但是有兩個前提條件:
* 第一個條件:運算結果并不依賴變量的當前值,或者能夠確保只有單一的線程修改變量的值。( 運算不是使 i++ ,而是i = 0)
* 第二個條件:變量不需要與其他的狀態變量共同參與不變約束。(判斷只能有與一個判斷)
## volatile的適用場景
### 模式1:狀態標志
也許實現 volatile 變量的規范使用僅僅是使用一個布爾狀態標志,用于指示發生了一個重要的一次性事件,例如完成初始化或請求停機。
~~~
volatile boolean shutdownRequested;
...
public void shutdown() {
shutdownRequested = true;
}
public void doWork() {
while (!shutdownRequested) {
// do stuff
}
}
~~~
### 模式2:一次性安全發布(one-time safe publication)
在缺乏同步的情況下,可能會遇到某個對象引用的更新值(由另一個線程寫入)和該對象狀態的舊值同時存在。這就是造成著名的雙重檢查鎖定(double-check在缺乏同步的情況下,可能會遇到某個對象引用的更新值(由另一個線程寫入)和該對象狀態的舊值同時存在。這就是造成著名的雙重檢查鎖定(double-checked-locking)問題的根源,其中對象引用在沒有同步的情況下進行讀操作,產生的問題是您可能會看到一個更新的引用,但是仍然會通過該引用看到不完全構造的對象。
~~~
//注意volatile!!!!!!!!!!!!!!!!!
private volatile static Singleton instace;
public static Singleton getInstance(){
//第一次null檢查
if(instance == null){
synchronized(Singleton.class) { //1
//第二次null檢查
if(instance == null){ //2
instance = new Singleton();//3
}
}
}
return instance;
}
~~~
如果不用volatile,則因為內存模型允許所謂的“無序寫入”,可能導致失敗。——某個線程可能會獲得一個未完全初始化的實例。
### 模式3:開銷較低的“讀-寫鎖”策略
如果讀操作遠遠超過寫操作,您可以結合使用內部鎖和 volatile 變量來減少公共代碼路徑的開銷。
如下顯示的線程安全的計數器,使用 synchronized 確保增量操作是原子的,并使用 volatile 保證當前結果的可見性。如果更新不頻繁的話,該方法可實現更好的性能,因為讀路徑的開銷僅僅涉及 volatile 讀操作,這通常要優于一個無競爭的鎖獲取的開銷。
~~~
ThreadSafe
public class CheesyCounter {
// Employs the cheap read-write lock trick
// All mutative operations MUST be done with the 'this' lock held
@GuardedBy("this") private volatile int value;
//讀操作,沒有synchronized,提高性能
public int getValue() {
return value;
}
//寫操作,必須synchronized。因為x++不是原子操作
public synchronized int increment() {
return value++;
}
}
~~~
## 參考資料
[Java并發編程:Volatile](https://blog.csdn.net/fei20121106/article/details/83268153)
- Java
- Object
- 內部類
- 異常
- 注解
- 反射
- 靜態代理與動態代理
- 泛型
- 繼承
- JVM
- ClassLoader
- String
- 數據結構
- Java集合類
- ArrayList
- LinkedList
- HashSet
- TreeSet
- HashMap
- TreeMap
- HashTable
- 并發集合類
- Collections
- CopyOnWriteArrayList
- ConcurrentHashMap
- Android集合類
- SparseArray
- ArrayMap
- 算法
- 排序
- 常用算法
- LeetCode
- 二叉樹遍歷
- 劍指
- 數據結構、算法和數據操作
- 高質量的代碼
- 解決問題的思路
- 優化時間和空間效率
- 面試中的各項能力
- 算法心得
- 并發
- Thread
- 鎖
- java內存模型
- CAS
- 原子類Atomic
- volatile
- synchronized
- Object.wait-notify
- Lock
- Lock之AQS
- Lock子類
- 鎖小結
- 堵塞隊列
- 生產者消費者模型
- 線程池