
## 簡介
SparseArray,Android推薦我們使用它用來替代**HashMap** ,這樣更加節省內存空間的使用。
SparseArray內部由兩個數組組成,一個是int\[\]類型的mKeys,用來存放所有的鍵;另一個是Object\[\]類型的mValues,用來存放所有的值。
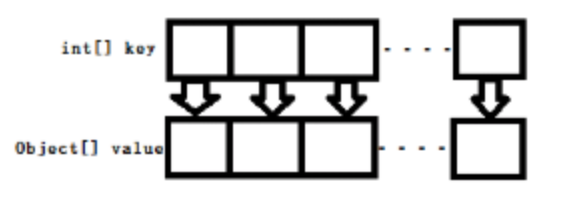
最常見的是拿SparseArray跟HashMap來做對比,由于SparseArray內部組成是兩個數組,所以占用內存比HashMap要小。我們都知道,增刪改查等操作都首先需要找到相應的鍵值對,而SparseArray**內部是通過二分查找來尋址**的,效率很明顯要低于HashMap的常數級別的時間復雜度。提到二分查找,這里還需要提一下的是二分查找的前提是數組已經是排好序的,沒錯,SparseArray中就是**按照key進行升序排列的**。
綜合起來來說,SparseArray所占空間優于HashMap,而效率低于HashMap,是典型的時間換空間,適合較小容量的存儲
## 核心成員變量
~~~
//保存key的數組
private int[] mKeys;
//保存value的數組
private Object[] mValues
//大小
private int mSize;
~~~
## 構造函數
~~~
public SparseArray() {
this(10);
}
public SparseArray(int initialCapacity) {
if (initialCapacity == 0) {
mKeys = EmptyArray.INT;
mValues = EmptyArray.OBJECT;
} else {
mValues = ArrayUtils.newUnpaddedObjectArray(initialCapacity);
mKeys = new int[mValues.length];
}
mSize = 0;
}
~~~
構造函數做就是根據initialCapacity初始化mValues和mKeys
## put
~~~
public void put(int key, E value) {
//使用二分查找在key的位置
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
//找到了直接賦值
mValues[i] = value;
} else {
//找不到,通過非運算符,得到該插入的位置
i = ~i;
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
//mGarbage大概意思是是否存在被刪除的元素(垃圾)
//mSize >= mKeys.length 表示滿了
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}
///其實是把被刪除的元素刪除,其他元素向上擠,爭取騰出位置
private void gc() {
int n = mSize;
int o = 0;
int[] keys = mKeys;
Object[] values = mValues;
for (int i = 0; i < n; i++) {
Object val = values[i];
if (val != DELETED) {
if (i != o) {
keys[o] = keys[i];
values[o] = val;
values[i] = null;
}
o++;
}
}
mGarbage = false;
mSize = o;
}
~~~
## get
~~~
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
return (E) mValues[i];
}
~~~
get的亮點不多,就是一個二分查找找到index,然后返回value
## remove
~~~
public void delete(int key) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
if (mValues[i] != DELETED) {
mValues[i] = DELETED;
mGarbage = true;
}
}
}
~~~
- Java
- Object
- 內部類
- 異常
- 注解
- 反射
- 靜態代理與動態代理
- 泛型
- 繼承
- JVM
- ClassLoader
- String
- 數據結構
- Java集合類
- ArrayList
- LinkedList
- HashSet
- TreeSet
- HashMap
- TreeMap
- HashTable
- 并發集合類
- Collections
- CopyOnWriteArrayList
- ConcurrentHashMap
- Android集合類
- SparseArray
- ArrayMap
- 算法
- 排序
- 常用算法
- LeetCode
- 二叉樹遍歷
- 劍指
- 數據結構、算法和數據操作
- 高質量的代碼
- 解決問題的思路
- 優化時間和空間效率
- 面試中的各項能力
- 算法心得
- 并發
- Thread
- 鎖
- java內存模型
- CAS
- 原子類Atomic
- volatile
- synchronized
- Object.wait-notify
- Lock
- Lock之AQS
- Lock子類
- 鎖小結
- 堵塞隊列
- 生產者消費者模型
- 線程池