# 九、模型驗證
> 作者:[Chris Albon](https://chrisalbon.com/)
>
> 譯者:[飛龍](https://github.com/wizardforcel)
>
> 協議:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
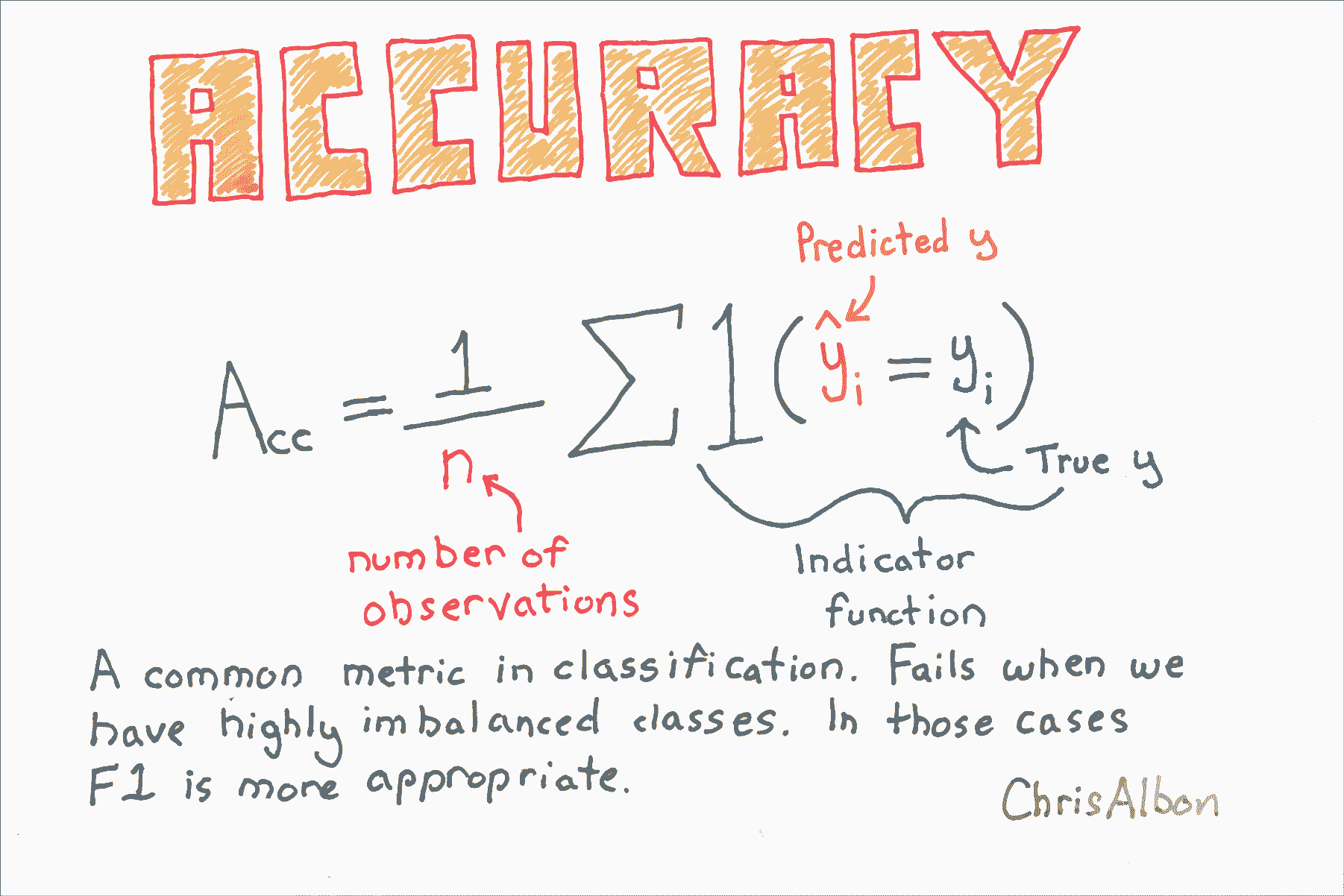
# 準確率
```py
# 加載庫
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
# 生成特征矩陣和目標向量
X, y = make_classification(n_samples = 10000,
n_features = 3,
n_informative = 3,
n_redundant = 0,
n_classes = 2,
random_state = 1)
# 創建邏輯回歸
logit = LogisticRegression()
# 使用準確率交叉驗證模型
cross_val_score(logit, X, y, scoring="accuracy")
# array([ 0.95170966, 0.9580084 , 0.95558223])
```
# 創建基線分類模型
```py
# 加載庫
from sklearn.datasets import load_iris
from sklearn.dummy import DummyClassifier
from sklearn.model_selection import train_test_split
# 加載數據
iris = load_iris()
# 創建特征矩陣和目標向量
X, y = iris.data, iris.target
# 分割為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 創建虛擬分類器
dummy = DummyClassifier(strategy='uniform', random_state=1)
# “訓練”模型
dummy.fit(X_train, y_train)
# DummyClassifier(constant=None, random_state=1, strategy='uniform')
# 獲取準確率得分
dummy.score(X_test, y_test)
# 0.42105263157894735
```
# 創建基線回歸模型
```py
# 加載庫
from sklearn.datasets import load_boston
from sklearn.dummy import DummyRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 加載數據
boston = load_boston()
# 創建特征
X, y = boston.data, boston.target
# 分割訓練和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 創建虛擬回歸器
dummy_mean = DummyRegressor(strategy='mean')
# “訓練”虛擬回歸器
dummy_mean.fit(X_train, y_train)
# DummyRegressor(constant=None, quantile=None, strategy='mean')
# 創建虛擬回歸器
dummy_constant = DummyRegressor(strategy='constant', constant=20)
# “訓練”虛擬回歸器
dummy_constant.fit(X_train, y_train)
# DummyRegressor(constant=array(20), quantile=None, strategy='constant')
# 獲取 R 方得分
dummy_constant.score(X_test, y_test)
# -0.065105020293257265
```
# 交叉驗證流水線
下面的代碼只在幾行中做了很多。 為了有助于解釋,以下是代碼正在執行的步驟:
1. 將原始數據拆分為三個部分。 選擇一個用于測試,兩個用于訓練。
2. 通過縮放訓練特征來預處理數據。
3. 在訓練數據上訓練支持向量分類器。
4. 將分類器應用于測試數據。
5. 記錄準確率得分。
6. 重復步驟 1-5 兩次,每次一個折。
7. 計算所有折的平均得分。
```py
from sklearn.datasets import load_iris
from sklearn.pipeline import make_pipeline
from sklearn import preprocessing
from sklearn import cross_validation
from sklearn import svm
```
在本教程中,我們將使用著名的[鳶尾花數據集](https://en.wikipedia.org/wiki/Iris_flower_data_set)。鳶尾花數據包含 150 種鳶尾花的四個測量值,以及它的品種。 我們將使用支持向量分類器來預測鳶尾花的品種。
```py
# 加載鳶尾花數據
iris = load_iris()
# 查看鳶尾花數據特征的前三行
iris.data[0:3]
array([[ 5.1, 3.5, 1.4, 0.2],
[ 4.9, 3. , 1.4, 0.2],
[ 4.7, 3.2, 1.3, 0.2]])
# 查看鳶尾花數據目標的前三行。0 代表花是山鳶尾。
iris.target[0:3]
# array([0, 0, 0])
```
現在我們為數據創建一個流水線。 首先,流水線通過特征變量的值縮放為零均值和單位方差,來預處理數據。 其次,管道使用`C = 1`訓練數據的支持分類器。 `C`是邊距的成本函數。 `C`越高,模型對于在超平面的錯誤的一側的觀察的容忍度越低。
```py
# 創建縮放數據的流水線,之后訓練支持向量分類器
classifier_pipeline = make_pipeline(preprocessing.StandardScaler(), svm.SVC(C=1))
```
Scikit 提供了一個很好的輔助函數,可以輕松進行交叉驗證。 具體來說,下面的代碼將數據分成三個部分,然后在鳶尾花數據上執行分類器流水線。
來自[ scikit 文檔](http://scikit-learn.org/stable/modules/generated/sklearn.cross_validation.cross_val_score.html#sklearn.cross_validation.cross_val_score)的重要說明:對于整數或者`None`的輸入,如果`y`是二元或多類,使用`StratifiedKFold`。如果估計器是分類器,或者如果`y既`不是二元也不是多類,則使用`KFold`。
```py
# KFold/StratifiedKFold 三折交叉驗證(默認值)
# applying the classifier pipeline to the feature and target data
scores = cross_validation.cross_val_score(classifier_pipeline, iris.data, iris.target, cv=3)
```
這是我們的 3 `KFold`交叉驗證的輸出。 當留出一個不同的折時,每個值都是支持向量分類器的準確率得分。有三個值,因為有三個折。 準確度得分越高越好。
```py
scores
# array([ 0.98039216, 0.90196078, 0.97916667])
```
為了更好地衡量模型的準確率,我們計算了三個得分的平均值。這是我們衡量模型準確率的標準。
```py
scores.mean()
# 0.95383986928104569
```
# 帶有網格搜索參數調優的交叉驗證
在機器學習中,通常在數據流水線中同時完成兩項任務:交叉驗證和(超)參數調整。 交叉驗證是使用一組數據訓練學習器并使用不同的集合對其進行測試的過程。 參數調整是選擇模型參數值的過程,可最大限度地提高模型的準確性。
在本教程中,我們將編寫示例,它使用 Scikit-learn 結合交叉驗證和參數調整。
注意:本教程基于[ scikit-learn 文檔中給出的示例](http://scikit-learn.org/stable/modules/grid_search.html#grid-search)。 我在文檔中結合了一些示例,簡化了代碼,并添加了大量的解釋/代碼注釋。
```py
import numpy as np
from sklearn.grid_search import GridSearchCV
from sklearn import datasets, svm
import matplotlib.pyplot as plt
```
在下面的代碼中,我們加載[`digits`數據集](http://scikit-learn.org/stable/auto_examples/datasets/plot_digits_last_image.html),其中包含 64 個特征變量。 每個特征表示手寫數字的 8 乘 8 圖像中的像素的暗度。 我們可以查看第一個觀測的這些特征:
```py
# 加載數字數據
digits = datasets.load_digits()
# 查看第一個觀測的特征
digits.data[0:1]
'''
array([[ 0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13.,
15., 10., 15., 5., 0., 0., 3., 15., 2., 0., 11.,
8., 0., 0., 4., 12., 0., 0., 8., 8., 0., 0.,
5., 8., 0., 0., 9., 8., 0., 0., 4., 11., 0.,
1., 12., 7., 0., 0., 2., 14., 5., 10., 12., 0.,
0., 0., 0., 6., 13., 10., 0., 0., 0.]])
'''
```
目標數據是包含圖像真實數字的向量。 例如,第一個觀測是手寫數字 '0'。
```py
# 查看第一個觀測的標簽
digits.target[0:1]
# array([0])
```
為了演示交叉驗證和參數調整,首先我們要將數字數據分成兩個名為`data1`和`data2`的數據集。 `data1`包含數字數據的前 1000 行,而`data2`包含剩余的約 800 行。 請注意,這個拆分與我們將要進行的交叉驗證是完全相同的,并且完全是為了在本教程的最后展示一些內容。 換句話說,現在不要擔心`data2`,我們會回過頭來看看它。
```py
# 創建數據集 1
data1_features = digits.data[:1000]
data1_target = digits.target[:1000]
# 創建數據集 2
data2_features = digits.data[1000:]
data2_target = digits.target[1000:]
```
在查找哪個參數值組合產生最準確的模型之前,我們必須指定我們想要嘗試的不同候選值。 在下面的代碼中,我們有許多候選參數值,包括`C`(`1,10,100,1000`)的四個不同值,`gamma`(`0.001,0.0001`)的兩個值,以及兩個核 (`linear, rbf`)。 網格搜索將嘗試參數值的所有組合,并選擇提供最準確模型的參數集。
```py
parameter_candidates = [
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]
```
現在我們準備使用 scikit-learn 的`GridSearchCV`進行網格搜索,它代表網格搜索交叉驗證。 默認情況下,`GridSearchCV`的交叉驗證使用 3 折`KFold`或`StratifiedKFold`,取決于具體情況。
```py
# 使用分類器和參數候選創建分類器對象
clf = GridSearchCV(estimator=svm.SVC(), param_grid=parameter_candidates, n_jobs=-1)
# 在 data1 的特征和目標數據上訓練分類器
clf.fit(data1_features, data1_target)
'''
GridSearchCV(cv=None, error_score='raise',
estimator=SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False),
fit_params={}, iid=True, n_jobs=-1,
param_grid=[{'kernel': ['linear'], 'C': [1, 10, 100, 1000]}, {'kernel': ['rbf'], 'gamma': [0.001, 0.0001], 'C': [1, 10, 100, 1000]}],
pre_dispatch='2*n_jobs', refit=True, scoring=None, verbose=0)
'''
```
成功了! 我們得到了結果! 首先,讓我們看一下將模型應用于`data1`的測試數據時的準確率得分。
```py
# 查看準確率得分
print('Best score for data1:', clf.best_score_)
# Best score for data1: 0.942
```
哪個參數最好? 我們可以讓 scikit-learn 顯示它們:
```py
# 查看使用網格搜索發現的模型的最佳參數
print('Best C:',clf.best_estimator_.C)
print('Best Kernel:',clf.best_estimator_.kernel)
print('Best Gamma:',clf.best_estimator_.gamma)
'''
Best C: 10
Best Kernel: rbf
Best Gamma: 0.001
'''
```
這告訴我們最準確的模型使用`C = 10`,`rbf`內核和`gamma = 0.001`。
還記得我們創建的第二個數據集嗎? 現在我們將使用它來證明模型實際使用這些參數。 首先,我們將剛訓練的分類器應用于第二個數據集。 然后我們將使用由網格搜索找到的參數,從頭開始訓練新的支持向量分類器。 對于這兩個模型,我們應該得到相同的結果。
```py
# 將使用 data1 訓練的分類器應用于 data2,并查看準確率得分
clf.score(data2_features, data2_target)
# 0.96988707653701378
# 使用網格搜索找到的最佳參數訓練新的分類器
svm.SVC(C=10, kernel='rbf', gamma=0.001).fit(data1_features, data1_target).score(data2_features, data2_target)
# 0.96988707653701378
```
成功了!
# 交叉驗證
```py
# 加載庫
import numpy as np
from sklearn import datasets
from sklearn import metrics
from sklearn.model_selection import KFold, cross_val_score
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
# 加載數字數據集
digits = datasets.load_digits()
# 創建特征矩陣
X = digits.data
# 創建目標向量
y = digits.target
# 創建標準化器
standardizer = StandardScaler()
# 創建邏輯回歸
logit = LogisticRegression()
# 創建流水線,它標準化并且運行邏輯回歸
pipeline = make_pipeline(standardizer, logit)
# 創建 K 折交叉驗證
kf = KFold(n_splits=10, shuffle=True, random_state=1)
# 執行 K 折交叉驗證
cv_results = cross_val_score(pipeline, # 流水線
X, # 特征矩陣
y, # 目標向量
cv=kf, # 交叉驗證機制
scoring="accuracy", # 損失函數
n_jobs=-1) # 使用所有 CPU
# 計算均值
cv_results.mean()
# 0.96493171942892597
```
# 自定義表現指標
```py
# 加載庫
from sklearn.metrics import make_scorer, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
# Generate features matrix and target vector
X, y = make_regression(n_samples = 100,
n_features = 3,
random_state = 1)
# 創建訓練和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.10, random_state=1)
# 創建嶺回歸對象
classifier = Ridge()
# 訓練嶺回歸模型
model = classifier.fit(X_train, y_train)
```
在這個例子中,我們只是計算 r 方得分,但我們可以看到可以使用任何計算。
```py
# 創建自定義指標
def custom_metric(y_test, y_pred):
# 計算 r 方得分
r2 = r2_score(y_test, y_pred)
# 返回 r 方得分
return r2
# 創建計分器,定義得分越高越好
score = make_scorer(custom_metric, greater_is_better=True)
# 對嶺回歸應用計分器
score(model, X_test, y_test)
# 0.99979061028820582
```
# F1 得分

```py
# 加載庫
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
# 生成特征矩陣和目標向量
X, y = make_classification(n_samples = 10000,
n_features = 3,
n_informative = 3,
n_redundant = 0,
n_classes = 2,
random_state = 1)
# 創建邏輯回歸
logit = LogisticRegression()
# 使用精確率交叉驗證
cross_val_score(logit, X, y, scoring="f1")
# array([ 0.95166617, 0.95765275, 0.95558223])
```
# 生成表現的文本報告
```py
# 加載庫
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 加載數據
iris = datasets.load_iris()
# 創建特征矩陣
X = iris.data
# 創建目標向量
y = iris.target
# 創建目標分類名稱的列表
class_names = iris.target_names
# 創建訓練和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
# 創建邏輯回歸
classifier = LogisticRegression()
# 訓練模型并作出預測
y_hat = classifier.fit(X_train, y_train).predict(X_test)
# 創建分類報告
print(classification_report(y_test, y_hat, target_names=class_names))
'''
precision recall f1-score support
setosa 1.00 1.00 1.00 13
versicolor 1.00 0.62 0.77 16
virginica 0.60 1.00 0.75 9
avg / total 0.91 0.84 0.84 38
'''
```
注意:支持度是指每個類別中的觀側數量。
# 嵌套交叉驗證
通常我們想調整模型的參數(例如,支持向量機中的`C`)。 也就是說,我們希望找到最小化損失函數的參數值。 最好的方法是交叉驗證:
1. 將要調整的參數設置為某個值。
2. 將數據拆分為 K 折(部分)。
3. 使用參數值使用 K-1 折訓練模型。
4. 在剩余一折上測試你的模型。
5. 重復步驟 3 和 4,使每一折都成為測試數據一次。
6. 對參數的每個可能值重復步驟 1 到 5。
7. 報告產生最佳結果的參數。
但是,正如[ Cawley 和 Talbot ](http://jmlr.org/papers/volume11/cawley10a/cawley10a.pdf)在 2010 年的論文中指出,因為我們使用測試集來選擇參數的值,和驗證模型,我們樂觀地偏向于我們的模型評估。 因此,如果使用測試集來選擇模型參數,那么我們需要一個不同的測試集,來獲得對所選模型的無偏估計。
克服此問題的一種方法是使用嵌套交叉驗證。 首先,內部交叉驗證用于調整參數并選擇最佳模型。 其次,外部交叉驗證用于評估由內部交叉驗證選擇的模型。
```py
# 加載所需的庫
from sklearn import datasets
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.preprocessing import StandardScaler
import numpy as np
from sklearn.svm import SVC
```
本教程的數據是具有 30 個特征和二元目標變量的[乳腺癌數據](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_breast_cancer.html)。
```py
# 加載數據
dataset = datasets.load_breast_cancer()
# 從特征創建 X
X = dataset.data
# 從目標創建 y
y = dataset.target
# 創建縮放器對象
sc = StandardScaler()
# 使縮放器擬合特征數據,并轉換
X_std = sc.fit_transform(X)
```
這是我們的內部交叉驗證。 我們將使用它來尋找`C`的最佳參數,這是誤分類數據點的懲罰。 `GridSearchCV`將執行本教程頂部列出的步驟 1-6。
```py
# 為 C 參數創建 10 個候選值的列表
C_candidates = dict(C=np.logspace(-4, 4, 10))
# 使用支持向量分類器,和 C 值候選,創建網格搜索對象
clf = GridSearchCV(estimator=SVC(), param_grid=C_candidates)
```
使用嵌套交叉驗證進行參數調整時,下面的代碼不是必需的,但為了證明我們的內部交叉驗證網格搜索可以找到參數`C`的最佳值,我們將在此處運行一次:
```py
# 使交叉驗證的網格搜索擬合數據
clf.fit(X_std, y)
# 展示 C 的最佳值
clf.best_estimator_.C
# 2.7825594022071258
```
通過構造內部交叉驗證,我們可以使用`cross_val_score`來評估模型,并進行第二次(外部)交叉驗證。
下面的代碼將數據分成三折,在兩折上運行內部交叉驗證(合并在一起),然后在第三折上評估模型。 這重復三次,以便每折用于測試一次。
```py
cross_val_score(clf, X_std, y)
# array([ 0.94736842, 0.97894737, 0.98412698])
```
上述每個值都是模型準確率的無偏估計,對于三個測試折中的每一折都有一個。 計算平均,它們將代表在內部交叉驗證網格搜索中找到的模型的平均準確度。
# 繪制學習曲線

```py
# 加載庫
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve
# 加載數據
digits = load_digits()
# 創建特征矩陣和目標向量
X, y = digits.data, digits.target
# 為不同訓練集大小創建 CV 訓練和測試得分
train_sizes, train_scores, test_scores = learning_curve(RandomForestClassifier(),
X,
y,
# 交叉驗證的折數
cv=10,
# 評價指標
scoring='accuracy',
# 使用計算機所有核
n_jobs=-1,
# 訓練集的 50 個不同大小
train_sizes=np.linspace(0.01, 1.0, 50))
# 創建訓練集得分的均值和標準差
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
# 創建測試集得分的均值和標準差
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# 繪制直線
plt.plot(train_sizes, train_mean, '--', color="#111111", label="Training score")
plt.plot(train_sizes, test_mean, color="#111111", label="Cross-validation score")
# 繪制條形
plt.fill_between(train_sizes, train_mean - train_std, train_mean + train_std, color="#DDDDDD")
plt.fill_between(train_sizes, test_mean - test_std, test_mean + test_std, color="#DDDDDD")
# 創建繪圖
plt.title("Learning Curve")
plt.xlabel("Training Set Size"), plt.ylabel("Accuracy Score"), plt.legend(loc="best")
plt.tight_layout()
plt.show()
```

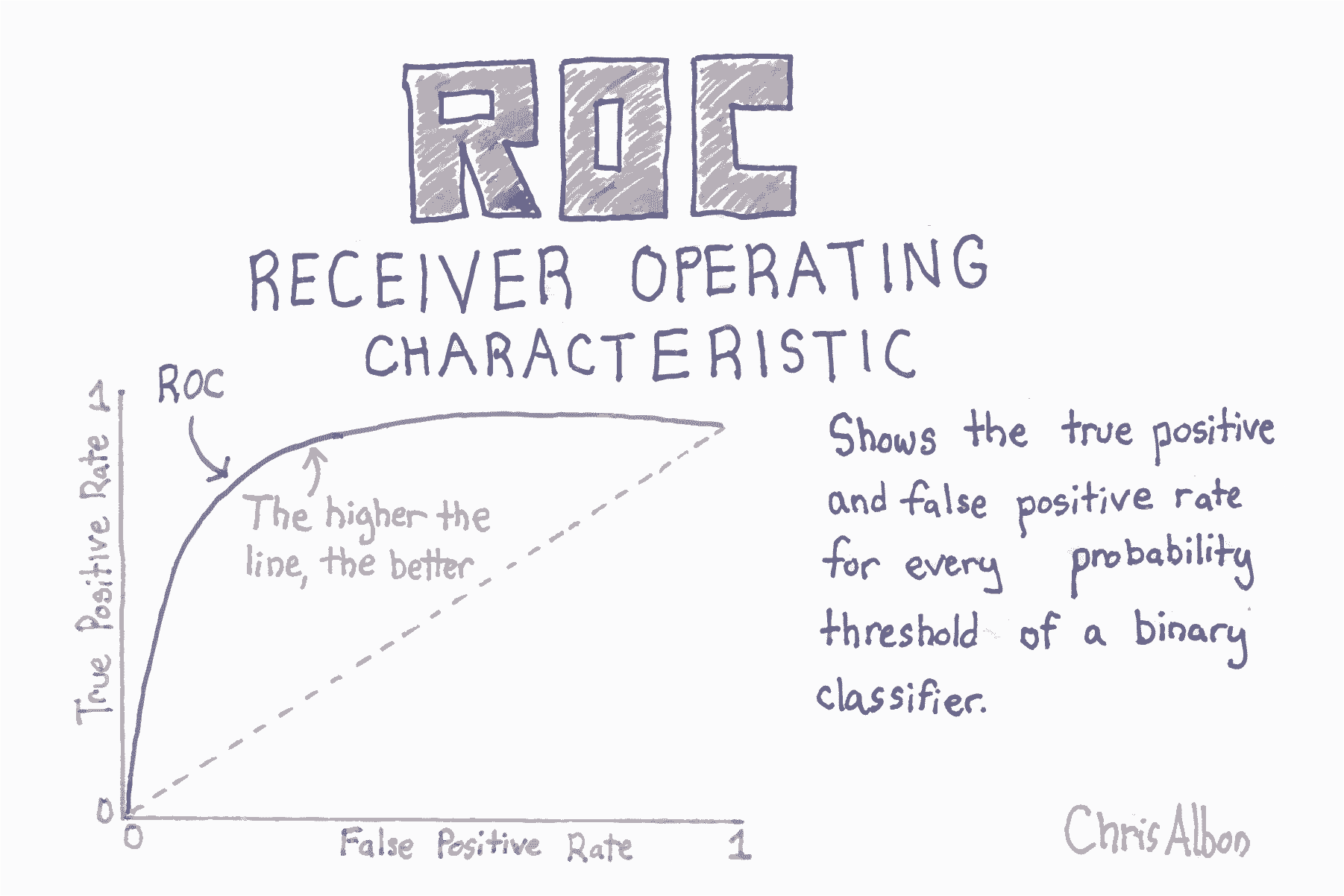
# 繪制 ROC 曲線
```py
# 加載庫
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 創建特征矩陣和目標向量
X, y = make_classification(n_samples=10000,
n_features=10,
n_classes=2,
n_informative=3,
random_state=3)
# 分割為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1)
# 創建分類器
clf = LogisticRegression()
# 訓練模型
clf.fit(X_train, y_train)
'''
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
'''
# 獲取預測概率
y_score = clf.predict_proba(X_test)[:,1]
# 創建真和假正率
false_positive_rate, true_positive_rate, threshold = roc_curve(y_test, y_score)
# 繪制 ROC 曲線
plt.title('Receiver Operating Characteristic')
plt.plot(false_positive_rate, true_positive_rate)
plt.plot([0, 1], ls="--")
plt.plot([0, 0], [1, 0] , c=".7"), plt.plot([1, 1] , c=".7")
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
```

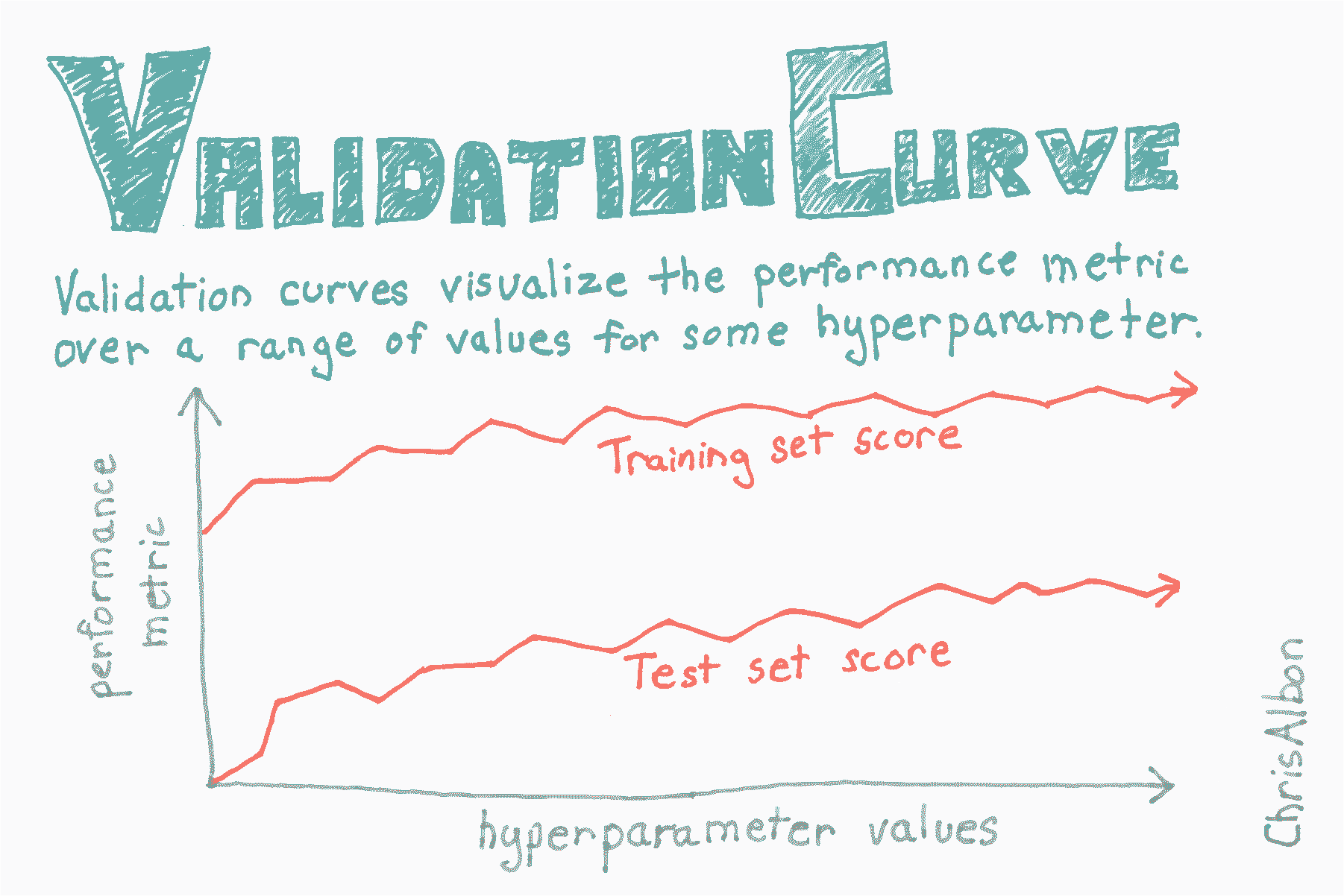
# 繪制驗證曲線
```py
# 加載庫
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import validation_curve
# 加載數據
digits = load_digits()
# 創建特征矩陣和目標向量
X, y = digits.data, digits.target
# 為參數創建值的范圍
param_range = np.arange(1, 250, 2)
# 使用參數值的范圍,在訓練和測試集上計算準確率
train_scores, test_scores = validation_curve(RandomForestClassifier(),
X,
y,
param_name="n_estimators",
param_range=param_range,
cv=3,
scoring="accuracy",
n_jobs=-1)
# 為訓練集得分計算均值和標準差
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
# 為測試集得分計算均值和標準差
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# 為訓練和測試集繪制平均準確率得分
plt.plot(param_range, train_mean, label="Training score", color="black")
plt.plot(param_range, test_mean, label="Cross-validation score", color="dimgrey")
# 為訓練和測試集繪制準確率條形
plt.fill_between(param_range, train_mean - train_std, train_mean + train_std, color="gray")
plt.fill_between(param_range, test_mean - test_std, test_mean + test_std, color="gainsboro")
# 創建繪圖
plt.title("Validation Curve With Random Forest")
plt.xlabel("Number Of Trees")
plt.ylabel("Accuracy Score")
plt.tight_layout()
plt.legend(loc="best")
plt.show()
```

# 精確率

```py
# 加載庫
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
# 生成特征矩陣和目標向量
X, y = make_classification(n_samples = 10000,
n_features = 3,
n_informative = 3,
n_redundant = 0,
n_classes = 2,
random_state = 1)
# 創建邏輯回歸
logit = LogisticRegression()
# 使用精確率來交叉驗證
cross_val_score(logit, X, y, scoring="precision")
# array([ 0.95252404, 0.96583282, 0.95558223])
```
# 召回率

```py
# 加載庫
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
# Generate features matrix and target vector
X, y = make_classification(n_samples = 10000,
n_features = 3,
n_informative = 3,
n_redundant = 0,
n_classes = 2,
random_state = 1)
# 生成特征矩陣和目標向量
logit = LogisticRegression()
# 使用召回率來交叉驗證
cross_val_score(logit, X, y, scoring="recall")
# array([ 0.95080984, 0.94961008, 0.95558223])
```
# 將數據分割為訓練和測試集
```py
# 加載庫
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 加載數字數據集
digits = datasets.load_digits()
# 創建特征矩陣
X = digits.data
# 創建目標向量
y = digits.target
# 創建訓練和測試集
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.1,
random_state=1)
# 創建標準化器
standardizer = StandardScaler()
# 使標準化器擬合訓練集
standardizer.fit(X_train)
# StandardScaler(copy=True, with_mean=True, with_std=True)
# 應用于訓練和測試集
X_train_std = standardizer.transform(X_train)
X_test_std = standardizer.transform(X_test)
```
