# 十八、Keras
> 作者:[Chris Albon](https://chrisalbon.com/)
>
> 譯者:[飛龍](https://github.com/wizardforcel)
>
> 協議:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
## 添加丟棄
```py
# 加載庫
import numpy as np
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
from keras import models
from keras import layers
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 設置我們想要的特征數量
number_of_features = 1000
# 從電影評論數據加載數據和目標向量
(train_data, train_target), (test_data, test_target) = imdb.load_data(num_words=number_of_features)
# 將電影評論數據轉換為單熱編碼的特征矩陣
tokenizer = Tokenizer(num_words=number_of_features)
train_features = tokenizer.sequences_to_matrix(train_data, mode='binary')
test_features = tokenizer.sequences_to_matrix(test_data, mode='binary')
```
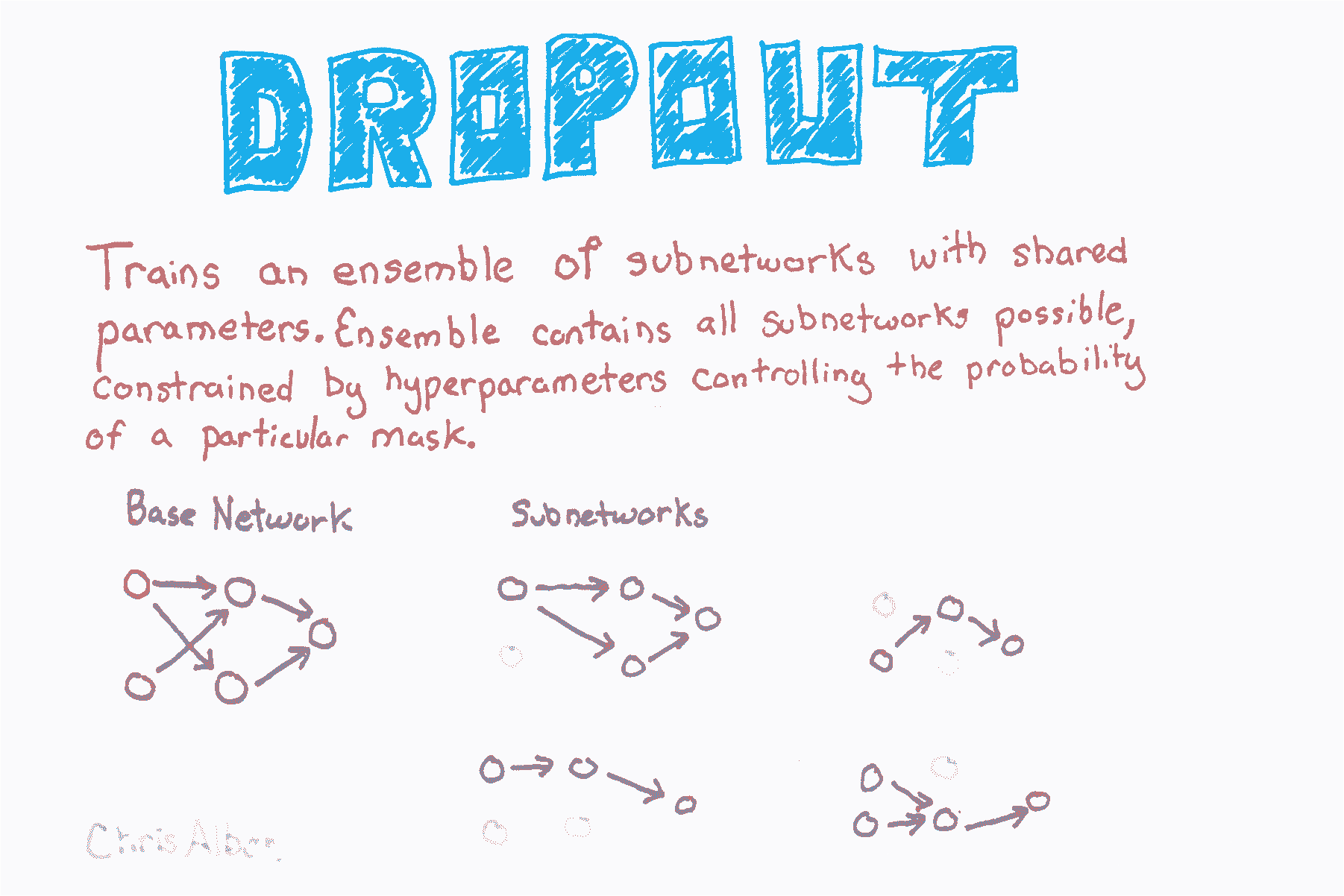
在 Keras 中,我們可以通過在我們的網絡架構中添加`Dropout`層來實現丟棄。 每個`Dropout`層將丟棄每批中的一定數量的上一層單元,它是由用戶定義的超參數。 請記住,在 Keras 中,輸入層被假定為第一層,而不是使用`add`添加。 因此,如果我們想要將丟棄添加到輸入層,我們在其中添加的圖層是一個丟棄層。 該層包含輸入層單元的比例,即`0.2`和`input_shape`,用于定義觀測數據的形狀。 接下來,在每個隱藏層之后添加一個帶有`0.5`的丟棄層。
```py
# 創建神經網絡
network = models.Sequential()
# 為輸入層添加丟棄層
network.add(layers.Dropout(0.2, input_shape=(number_of_features,)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu'))
# 為先前的隱藏層添加丟棄層
network.add(layers.Dropout(0.5))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu'))
# 為先前的隱藏層添加丟棄層
network.add(layers.Dropout(0.5))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))
# 編譯神經網絡
network.compile(loss='binary_crossentropy', # 交叉熵
optimizer='rmsprop', # RMSProp
metrics=['accuracy']) # 準確率表現度量
# 訓練神經網絡
history = network.fit(train_features, # 特征
train_target, # 目標向量
epochs=3, # 迭代數量
verbose=0, # 無輸出
batch_size=100, # 每個批量的觀測數量
validation_data=(test_features, test_target)) # 用于評估的數據
```
## 卷積神經網絡
```py
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.utils import np_utils
from keras import backend as K
# 設置顏色通道值優先
K.set_image_data_format('channels_first')
# 設置種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 設置圖像信息
channels = 1
height = 28
width = 28
# 從 MNIST 數據集加載數據和目標
(train_data, train_target), (test_data, test_target) = mnist.load_data()
# 將訓練圖像數據的形狀變為特征
train_data = train_data.reshape(train_data.shape[0], channels, height, width)
# 將測試圖像數據的形狀變為特征
test_data = test_data.reshape(test_data.shape[0], channels, height, width)
# 將像素縮放到 0 和 1 之間
train_features = train_data / 255
test_features = test_data / 255
# 將目標單熱編碼
train_target = np_utils.to_categorical(train_target)
test_target = np_utils.to_categorical(test_target)
number_of_classes = test_target.shape[1]
```
卷積神經網絡(也稱為 ConvNets)是一種流行的網絡類型,已被證明在計算機視覺上非常有效(例如識別貓狗,飛機甚至熱狗)。前饋神經網絡完全可以在圖像上使用,其中每個像素都是一個特征。 但是,這樣做時我們遇到了兩個主要問題。
首先,前饋神經網絡不考慮像素的空間結構。 例如,在 10x10 的像素圖像中,我們可以將其轉換為 100 個像素特征的矢量,并且在這種情況下,前饋將認為第一特征(例如像素值)與第十個和第十一個特征具有相同的關系。 然而,實際上,第 10 個特征表示第一個特征的遠側的像素,而第 11 個特征表示緊鄰第一個特征的像素。
其次,與之相關,前饋神經網絡學習特征中的全局關系而不是局部規律。 在更實際的術語中,這意味著前饋神經網絡無法檢測到對象,無論它出現在圖像中哪個位置。 例如,假設我們正在訓練神經網絡識別面部,這些面部可能出現在圖像的任何位置,從右上角到中間到左下角。 卷積神經網絡的威力就是它們處理這兩個問題(和其他問題)的能力。
```py
# 創建神經網絡
network = Sequential()
# 添加卷積層,帶有 64 個過濾器
# 5x5 窗口和 ReLU 激活函數
network.add(Conv2D(filters=64, kernel_size=(5, 5), input_shape=(channels, width, height), activation='relu'))
# 添加帶有 2x2 窗口的最大池化層
network.add(MaxPooling2D(pool_size=(2, 2)))
# 添加丟棄層
network.add(Dropout(0.5))
# 添加展開輸入的層
network.add(Flatten())
# 添加帶有 ReLU 激活函數的 128 個單元的全連接層
network.add(Dense(128, activation='relu'))
# 添加丟棄層
network.add(Dropout(0.5))
# 添加帶有 softmax 激活函數的全連接層
network.add(Dense(number_of_classes, activation='softmax'))
# 編譯神經網絡
network.compile(loss='categorical_crossentropy', # 交叉熵
optimizer='rmsprop', # RMSProp
metrics=['accuracy']) # 準確率表現度量
# 訓練神經網絡
network.fit(train_features, # 特征
train_target, # 目標
epochs=2, # 迭代數量
verbose=0, # 不要在每個迭代之后打印描述
batch_size=1000, # 每個批量的觀測數
validation_data=(test_features, test_target)) # 用于評估的數據
# <keras.callbacks.History at 0x103f9b8d0>
```
## 用于二分類的前饋神經網絡
```py
# 加載庫
import numpy as np
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
from keras import models
from keras import layers
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 設置我們希望的特征數
number_of_features = 1000
# 從電影評論數據集加載數據和目標向量
(train_data, train_target), (test_data, test_target) = imdb.load_data(num_words=number_of_features)
# 將電影評論數據轉換為單熱編碼的特征矩陣
tokenizer = Tokenizer(num_words=number_of_features)
train_features = tokenizer.sequences_to_matrix(train_data, mode='binary')
test_features = tokenizer.sequences_to_matrix(test_data, mode='binary')
```
因為這是二元分類問題,所以一種常見的選擇是在單個單元的輸出層中使用 sigmoid 激活函數。
```py
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu', input_shape=(number_of_features,)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu'))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))
# 編譯神經網絡
network.compile(loss='binary_crossentropy', # 交叉熵
optimizer='rmsprop', # RMSProp
metrics=['accuracy']) # 準確率表現度量
```
在Keras,我們使用`fit`方法訓練我們的神經網絡。 需要定義六個重要參數。 前兩個參數是訓練數據的特征和目標向量。
`epochs`參數定義訓練數據時要使用的迭代數。 `verbose`確定在訓練過程中輸出多少信息,`0`沒有輸出,`1`輸出進度條,`2`在每個迭代輸出一行日志。 `batch_size`設置在更新參數之前通過網絡傳播的觀測數。
最后,我們提供了一組用于評估模型的測試數據。 這些測試特征和目標向量可以是`validation_data`的參數,它們將使用它們進行評估。 或者,我們可以使用`validation_split`來定義,我們想要進行評估訓練數據的哪一部分。
在 scikit-learn 中`fit`方法返回一個訓練好的模型,但是在 Keras 中,`fit`方法返回一個`History`對象,包含每個迭代的損失值和表現指標。
```py
# 訓練神經網絡
history = network.fit(train_features, # 特征
train_target, # 目標向量
epochs=3, # 迭代數量
verbose=1, # 每個迭代之后打印描述
batch_size=100, # 每個批量的觀測數
validation_data=(test_features, test_target)) # 用于評估的數據
'''
Train on 25000 samples, validate on 25000 samples
Epoch 1/3
25000/25000 [==============================] - 2s - loss: 0.4215 - acc: 0.8102 - val_loss: 0.3385 - val_acc: 0.8558
Epoch 2/3
25000/25000 [==============================] - 1s - loss: 0.3241 - acc: 0.8646 - val_loss: 0.3261 - val_acc: 0.8626
Epoch 3/3
25000/25000 [==============================] - 2s - loss: 0.3120 - acc: 0.8700 - val_loss: 0.3268 - val_acc: 0.8593
'''
```
## 用于多分類的前饋神經網絡
```py
# 加載庫
import numpy as np
from keras.datasets import reuters
from keras.utils.np_utils import to_categorical
from keras.preprocessing.text import Tokenizer
from keras import models
from keras import layers
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 設置我們希望的特征數
number_of_features = 5000
# 加載特征和目標數據
(train_data, train_target_vector), (test_data, test_target_vector) = reuters.load_data(num_words=number_of_features)
# 將特征數據轉換為單熱編碼的特征矩陣
tokenizer = Tokenizer(num_words=number_of_features)
train_features = tokenizer.sequences_to_matrix(train_data, mode='binary')
test_features = tokenizer.sequences_to_matrix(test_data, mode='binary')
# 單熱編碼目標向量來創建目標矩陣
train_target = to_categorical(train_target_vector)
test_target = to_categorical(test_target_vector)
```
在這個例子中,我們使用適合于多類分類的損失函數,分類交叉熵損失函數,`categorical_crossentropy`。
```py
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=100, activation='relu', input_shape=(number_of_features,)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=100, activation='relu'))
# 添加帶有 Softmax 激活函數的全連接層
network.add(layers.Dense(units=46, activation='softmax'))
# 編譯神經網絡
network.compile(loss='categorical_crossentropy', # 交叉熵
optimizer='rmsprop', # RMSProp
metrics=['accuracy']) # 準確率表現度量
# 訓練神經網絡
history = network.fit(train_features, # 特征
train_target, # 目標向量
epochs=3, # 三個迭代
verbose=0, # 沒有輸出
batch_size=100, # 每個批量的觀測數
validation_data=(test_features, test_target)) # 用于評估的數據
```
## 用于回歸的前饋神經網絡
```py
# 加載庫
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras import models
from keras import layers
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 生成特征矩陣和目標向量
features, target = make_regression(n_samples = 10000,
n_features = 3,
n_informative = 3,
n_targets = 1,
noise = 0.0,
random_state = 0)
# 將我們的數據劃分為訓練和測試集
train_features, test_features, train_target, test_target = train_test_split(features,
target,
test_size=0.33,
random_state=0)
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=32, activation='relu', input_shape=(train_features.shape[1],)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=32, activation='relu'))
# 添加沒有激活函數的全連接層
network.add(layers.Dense(units=1))
```
因為我們正在訓練回歸,所以我們應該使用適當的損失函數和評估度量,在我們的例子中是均方誤差:
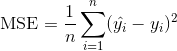
其中 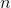 是觀測數量,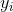 是我們試圖預測的目標  對于觀測 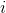 的真實值, 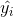 是 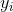 的模型預測值。
```py
# 編譯神經網絡
network.compile(loss='mse', # MSE
optimizer='RMSprop', # 優化算法
metrics=['mse']) # MSE
# 訓練神經網絡
history = network.fit(train_features, # 特征
train_target, # 目標向量
epochs=10, # 迭代數量
verbose=0, # 無輸出
batch_size=100, # 每個批量的觀測數
validation_data=(test_features, test_target)) # 用于評估的數據
```
## LSTM 循環神經網絡
通常我們擁有我們想要分類的文本數據。 雖然可以使用一種卷積網絡,但我們將專注于一種更流行的選擇:循環神經網絡。循環神經網絡的關鍵特征,是信息在網絡中循環。 這為循環神經網絡提供了一種存儲器,可用于更好地理解序列數據。流行的循環神經網絡類型是長期短期記憶(LSTM)網絡,它允許信息在網絡中向后循環。
```py
# 加載庫
import numpy as np
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras import models
from keras import layers
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 設置我們希望的特征數
number_of_features = 1000
# 從電影評論數據集加載數據和目標向量
(train_data, train_target), (test_data, test_target) = imdb.load_data(num_words=number_of_features)
# 使用填充或者截斷,使每個觀測具有 400 個特征
train_features = sequence.pad_sequences(train_data, maxlen=400)
test_features = sequence.pad_sequences(test_data, maxlen=400)
# 查看第一個觀測
print(train_data[0])
'''
[1, 14, 22, 16, 43, 530, 973, 2, 2, 65, 458, 2, 66, 2, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 2, 2, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2, 19, 14, 22, 4, 2, 2, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 2, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2, 2, 16, 480, 66, 2, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 2, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 2, 15, 256, 4, 2, 7, 2, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 2, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2, 56, 26, 141, 6, 194, 2, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 2, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 2, 88, 12, 16, 283, 5, 16, 2, 113, 103, 32, 15, 16, 2, 19, 178, 32]
'''
# 查看第一個觀測
test_features[0]
'''
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 89, 27, 2, 2, 17, 199, 132, 5, 2,
16, 2, 24, 8, 760, 4, 2, 7, 4, 22, 2, 2, 16,
2, 17, 2, 7, 2, 2, 9, 4, 2, 8, 14, 991, 13,
877, 38, 19, 27, 239, 13, 100, 235, 61, 483, 2, 4, 7,
4, 20, 131, 2, 72, 8, 14, 251, 27, 2, 7, 308, 16,
735, 2, 17, 29, 144, 28, 77, 2, 18, 12], dtype=int32)
'''
# 創建神經網絡
network = models.Sequential()
# 添加嵌入層
network.add(layers.Embedding(input_dim=number_of_features, output_dim=128))
# 添加帶有 128 個單元的 LSTM 層
network.add(layers.LSTM(units=128))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))
# 編譯神經網絡
network.compile(loss='binary_crossentropy', # 交叉熵
optimizer='Adam', # Adam 優化
metrics=['accuracy']) # 準確率表現度量
# 訓練神經網絡
history = network.fit(train_features, # 特征
train_target, # 目標
epochs=3, # 迭代數量
verbose=0, # 不在每個迭代之后打印描述
batch_size=1000, # 每個批量的觀測數
validation_data=(test_features, test_target)) # 用于評估的數據
```
## 神經網絡的提前停止
```py
# 加載庫
import numpy as np
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
from keras import models
from keras import layers
from keras.callbacks import EarlyStopping, ModelCheckpoint
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 設置我們希望的特征數
number_of_features = 1000
# 從電影評論數據集加載數據和目標向量
(train_data, train_target), (test_data, test_target) = imdb.load_data(num_words=number_of_features)
# 將電影評論數據轉換為單熱編碼的特征矩陣
tokenizer = Tokenizer(num_words=number_of_features)
train_features = tokenizer.sequences_to_matrix(train_data, mode='binary')
test_features = tokenizer.sequences_to_matrix(test_data, mode='binary')
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu', input_shape=(number_of_features,)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu'))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))
# 編譯神經網絡
network.compile(loss='binary_crossentropy', # 交叉熵
optimizer='rmsprop', # RMSProp
metrics=['accuracy']) # 準確率表現度量
```
在 Keras 中,我們可以將提權停止實現為回調函數。 回調是可以在訓練過程的某些階段應用的函數,例如在每個迭代結束時。 具體來說,在我們的解決方案中,我們包含了`EarlyStopping(monitor='val_loss', patience=2)`,來定義我們想要監控每個迭代的測試(驗證)損失,并且在兩個迭代之后如果測試損失沒有改善,訓練就中斷。 但是,由于我們設置了`patience=2`,我們不會得到最好的模型,而是最佳模型兩個時代后的模型。 因此,可選地,我們可以包含第二個操作,`ModelCheckpoint`,它在每個檢查點之后將模型保存到文件中(如果由于某種原因中斷了多天的訓練會話,這可能很有用。如果我們設置`save_best_only = True`,`ModelCheckpoint`將只保存最佳模型,這對我們有幫助。
```py
# 將回調函數設置為提前停止訓練,并保存到目前為止最好的模型
callbacks = [EarlyStopping(monitor='val_loss', patience=2),
ModelCheckpoint(filepath='best_model.h5', monitor='val_loss', save_best_only=True)]
# 訓練神經網絡
history = network.fit(train_features, # 特征
train_target, # 目標向量
epochs=20, # 迭代數量
callbacks=callbacks, # 提前停止
verbose=0, # 每個迭代之后打印描述
batch_size=100, # 每個批量的觀測數
validation_data=(test_features, test_target)) # 用于評估的數據
```
## 神經網絡的參數正則化
```py
# 加載庫
import numpy as np
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
from keras import models
from keras import layers
from keras import regularizers
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 設置我們希望的特征數
number_of_features = 1000
# 從電影評論數據集加載數據和目標向量
(train_data, train_target), (test_data, test_target) = imdb.load_data(num_words=number_of_features)
# 將電影評論數據轉換為單熱編碼的特征矩陣
tokenizer = Tokenizer(num_words=number_of_features)
train_features = tokenizer.sequences_to_matrix(train_data, mode='binary')
test_features = tokenizer.sequences_to_matrix(test_data, mode='binary')
```
在 Keras 中,我們可以通過添加帶有`kernel_regularizer = regularizers.l2(0.01)`的層,來增加權重正則化。 在這個例子中,`0.01`確定我們如何懲罰更高的參數值。
```py
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數和 L2 正則化的全連接層
network.add(layers.Dense(units=16,
activation='relu',
kernel_regularizer=regularizers.l2(0.01),
input_shape=(number_of_features,)))
# 添加帶有 ReLU 激活函數和 L2 正則化的全連接層
network.add(layers.Dense(units=16,
kernel_regularizer=regularizers.l2(0.01),
activation='relu'))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))# 編譯神經網絡
network.compile(loss='binary_crossentropy', # 交叉熵
optimizer='rmsprop', # RMSProp
metrics=['accuracy']) # 準確率表現度量
# 訓練神經網絡
history = network.fit(train_features, # 特征
train_target, # 目標向量
epochs=3, # 迭代數量
verbose=0, # 無輸出
batch_size=100, # 每個批量的觀測數
validation_data=(test_features, test_target)) # 用于評估的數據
```
## 為神經網絡預處理數據
通常,神經網絡的參數被初始化(即,創建)為小的隨機數。 當特征值遠大于參數值時,神經網絡通常表現不佳。 此外,由于觀測的特征值在通過單個單元時將被組合,因此所有特征具有相同的比例是很重要的。
由于這些原因,最佳實踐(盡管并非總是必要的,例如當我們的特征都是二元時)是標準化每個特征,使得特征的值均值為 0 和標準差為 1。這可以使用 scikit-learn 的`StandardScaler`輕松完成。
```py
# 加載庫
from sklearn import preprocessing
import numpy as np
# 創建特征
features = np.array([[-100.1, 3240.1],
[-200.2, -234.1],
[5000.5, 150.1],
[6000.6, -125.1],
[9000.9, -673.1]])
# 創建縮放器
scaler = preprocessing.StandardScaler()
# 轉換特征
features_standardized = scaler.fit_transform(features)
# 展示特征
features_standardized
'''
array([[-1.12541308, 1.96429418],
[-1.15329466, -0.50068741],
[ 0.29529406, -0.22809346],
[ 0.57385917, -0.42335076],
[ 1.40955451, -0.81216255]])
'''
# 打印均值和標準差
print('Mean:', round(features_standardized[:,0].mean()))
print('Standard deviation:', features_standardized[:,0].std())
'''
Mean: 0.0
Standard deviation: 1.0
'''
```
# 保存模型的訓練過程
```py
# 加載庫
import numpy as np
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
from keras import models
from keras import layers
from keras.callbacks import ModelCheckpoint
# 設置隨機數種子
np.random.seed(0)
# 設置我們希望的特征數
number_of_features = 1000
# 從電影評論數據集加載數據和目標向量
(train_data, train_target), (test_data, test_target) = imdb.load_data(num_words=number_of_features)
# 將電影評論數據轉換為單熱編碼的特征矩陣
tokenizer = Tokenizer(num_words=number_of_features)
train_features = tokenizer.sequences_to_matrix(train_data, mode='binary')
test_features = tokenizer.sequences_to_matrix(test_data, mode='binary')
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu', input_shape=(number_of_features,)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu'))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))
# 編譯神經網絡
network.compile(loss='binary_crossentropy', # 交叉熵
optimizer='rmsprop', # RMSProp
metrics=['accuracy']) # 準確率表現度量
```
在每個得帶之后,`ModelCheckpoint`將模型保存到`filepath`參數指定的位置。 如果我們只包含一個文件名(例如`models.hdf5`),那么每個迭代都會用最新的模型覆蓋該文件。 如果我們只想根據某些損失函數的表現保存最佳模型,我們可以設置`save_best_only = True`和`monitor ='val_loss'`,如果模型的測試損失比以前更差,則不覆蓋文件 。 或者,我們可以將每個迭代的模型保存到自己的文件,方法是將迭代編號和測試損失得分包含在文件名本身中。 例如,如果我們將`filepath`設置為`model_{epoch:02d}_{val_loss:.2f}.hdf5`,那么模型的文件名稱為 `model_10_0.35.hdf5`(注意迭代編號的索引從 0 開始),它包含第 11 個迭代之后的測試損失值 0.33。
```py
# 將回調函數設置為提前停止訓練
# 并保存目前為止最好的模型
checkpoint = [ModelCheckpoint(filepath='models.hdf5')]
# 訓練神經網絡
history = network.fit(train_features, # 特征
train_target, # 目標向量
epochs=3, # 迭代數量
callbacks=checkpoint, # Checkpoint
verbose=0, # 無輸出
batch_size=100, # 每個批量的觀測數
validation_data=(test_features, test_target)) # 用于評估的數據
```
# 調優神經網絡超參數
```py
# 加載庫
import numpy as np
from keras import models
from keras import layers
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import make_classification
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 特征數
number_of_features = 100
# 生成特征矩陣和目標向量
features, target = make_classification(n_samples = 10000,
n_features = number_of_features,
n_informative = 3,
n_redundant = 0,
n_classes = 2,
weights = [.5, .5],
random_state = 0)
# 創建返回已編譯網絡的函數
def create_network(optimizer='rmsprop'):
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu', input_shape=(number_of_features,)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu'))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))
# 編譯神經網絡
network.compile(loss='binary_crossentropy', # 交叉熵
optimizer=optimizer, # 優化器
metrics=['accuracy']) # 準確率表現度量
# 返回編譯的網絡
return network
# 包裝 Keras 模型,使其能夠用于 sklearn
neural_network = KerasClassifier(build_fn=create_network, verbose=0)
# 創建超參數空間
epochs = [5, 10]
batches = [5, 10, 100]
optimizers = ['rmsprop', 'adam']
# 創建超參數選項
hyperparameters = dict(optimizer=optimizers, epochs=epochs, batch_size=batches)
# 創建網格搜索
grid = GridSearchCV(estimator=neural_network, param_grid=hyperparameters)
# 擬合網格搜索
grid_result = grid.fit(features, target)
# 查看神經網絡的最佳超參數
grid_result.best_params_
# {'batch_size': 5, 'epochs': 5, 'optimizer': 'rmsprop'}
```
## 可視化損失歷史
```py
# 加載庫
import numpy as np
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
from keras import models
from keras import layers
import matplotlib.pyplot as plt
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 設置我們希望的特征數
number_of_features = 10000
# 從電影評論數據集加載數據和目標向量
(train_data, train_target), (test_data, test_target) = imdb.load_data(num_words=number_of_features)
# 將電影評論數據轉換為單熱編碼的特征矩陣
tokenizer = Tokenizer(num_words=number_of_features)
train_features = tokenizer.sequences_to_matrix(train_data, mode='binary')
test_features = tokenizer.sequences_to_matrix(test_data, mode='binary')
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu', input_shape=(number_of_features,)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu'))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))
# 編譯神經網絡
network.compile(loss='binary_crossentropy', # 交叉熵
optimizer='rmsprop', # RMSProp
metrics=['accuracy']) # 準確率表現度量
# 訓練神經網絡
history = network.fit(train_features, # 特征
train_target, # Target
epochs=15, # 迭代數量
verbose=0, # 無輸出
batch_size=1000, # 每個批量的觀測數
validation_data=(test_features, test_target)) # 用于評估的數據
# 得到訓練和測試損失歷史
training_loss = history.history['loss']
test_loss = history.history['val_loss']
# 創建迭代數量
epoch_count = range(1, len(training_loss) + 1)
# 可視化損失歷史
plt.plot(epoch_count, training_loss, 'r--')
plt.plot(epoch_count, test_loss, 'b-')
plt.legend(['Training Loss', 'Test Loss'])
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show();
```

## 可視化神經網絡架構
```py
# 加載庫
from keras import models
from keras import layers
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
# 使用 TensorFlow 后端
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu', input_shape=(10,)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu'))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))
# 可視化網絡架構
SVG(model_to_dot(network, show_shapes=True).create(prog='dot', format='svg'))
```

```py
# 將繪圖保存到文件
plot_model(network, show_shapes=True, to_file='network.png')
```
## 可視化表現歷史
```py
# 加載庫
import numpy as np
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
from keras import models
from keras import layers
import matplotlib.pyplot as plt
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 設置我們希望的特征數
number_of_features = 10000
# 從電影評論數據集加載數據和目標向量
(train_data, train_target), (test_data, test_target) = imdb.load_data(num_words=number_of_features)
# 將電影評論數據轉換為單熱編碼的特征矩陣
tokenizer = Tokenizer(num_words=number_of_features)
train_features = tokenizer.sequences_to_matrix(train_data, mode='binary')
test_features = tokenizer.sequences_to_matrix(test_data, mode='binary')
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu', input_shape=(number_of_features,)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu'))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))
# 編譯神經網絡
network.compile(loss='binary_crossentropy', # 交叉熵
optimizer='rmsprop', # RMSProp
metrics=['accuracy']) # 準確率表現度量
# 訓練神經網絡
history = network.fit(train_features, # 特征
train_target, # Target
epochs=15, # 迭代數量
verbose=0, # 無輸出
batch_size=1000, # 每個批量的觀測數
validation_data=(test_features, test_target)) # 用于評估的數據
```
具體來說,我們展示神經網絡在訓練和測試集上的每個迭代的準確率得分。
```py
# 獲取訓練和測試準確率歷史
training_accuracy = history.history['acc']
test_accuracy = history.history['val_acc']
# 創建迭代數量
epoch_count = range(1, len(training_accuracy) + 1)
# 可視化準確率歷史
plt.plot(epoch_count, training_accuracy, 'r--')
plt.plot(epoch_count, test_accuracy, 'b-')
plt.legend(['Training Accuracy', 'Test Accuracy'])
plt.xlabel('Epoch')
plt.ylabel('Accuracy Score')
plt.show();
```

## 神經網絡的 K 折交叉驗證
如果我們擁有較小的數據,那么利用 k 折疊交叉驗證可以最大化我們評估神經網絡表現的能力。 這在 Keras 中是可能的,因為我們可以“包裝”任何神經網絡,使其可以使用 scikit-learn 中可用的評估功能,包括 k-fold 交叉驗證。 為此,我們首先要創建一個返回已編譯神經網絡的函數。 接下來我們使用`KerasClassifier`(這是分類器的情況,如果我們有一個回歸器,我們可以使用`KerasRegressor`)來包裝模型,以便 scikit-learn 可以使用它。 在此之后,我們可以像任何其他 scikit-learn 學習算法一樣使用我們的神經網絡(例如隨機森林,邏輯回歸)。 在我們的解決方案中,我們使用`cross_val_score`在我們的神經網絡上運行三折交叉驗證。
```py
# 加載庫
import numpy as np
from keras import models
from keras import layers
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_classification
# 設置隨機數種子
np.random.seed(0)
# 使用 TensorFlow 后端
# 特征數
number_of_features = 100
# 生成特征矩陣和目標向量
features, target = make_classification(n_samples = 10000,
n_features = number_of_features,
n_informative = 3,
n_redundant = 0,
n_classes = 2,
weights = [.5, .5],
random_state = 0)
# 創建返回已編譯網絡的函數
def create_network():
# 創建神經網絡
network = models.Sequential()
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu', input_shape=(number_of_features,)))
# 添加帶有 ReLU 激活函數的全連接層
network.add(layers.Dense(units=16, activation='relu'))
# 添加帶有 Sigmoid 激活函數的全連接層
network.add(layers.Dense(units=1, activation='sigmoid'))
# 編譯神經網絡
network.compile(loss='binary_crossentropy', # 交叉熵
optimizer='rmsprop', # RMSProp
metrics=['accuracy']) # 準確率表現度量
# 返回編譯的網絡
return network
# 包裝 Keras 模型,使其能夠用于 scikit-learn
neural_network = KerasClassifier(build_fn=create_network,
epochs=10,
batch_size=100,
verbose=0)
# 使用三折交叉驗證評估神經網絡
cross_val_score(neural_network, features, target, cv=3)
# array([ 0.90491901, 0.77827782, 0.87038704])
```
