# 十七、聚類
> 作者:[Chris Albon](https://chrisalbon.com/)
>
> 譯者:[飛龍](https://github.com/wizardforcel)
>
> 協議:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
## 凝聚聚類

```py
# 加載庫
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering
# 加載數據
iris = datasets.load_iris()
X = iris.data
# 標準化特征
scaler = StandardScaler()
X_std = scaler.fit_transform(X)
```
在 scikit-learn 中,`AgglomerativeClustering`使用`linkage`參數來確定合并策略,來最小化(1)合并簇的方差(`ward`),(2)來自簇對的觀測點的距離均值(`average`) ,或(3)來自簇對的觀測之間的最大距離(`complete`)。
其他兩個參數很有用。 首先,`affinity`參數確定用于`linkage`的距離度量(`minkowski`,`euclidean`等)。 其次,`n_clusters`設置聚類算法將嘗試查找的聚類數。 也就是說,簇被連續合并,直到只剩下`n_clusters`。
```py
# 創建聚類對象
clt = AgglomerativeClustering(linkage='complete',
affinity='euclidean',
n_clusters=3)
# 訓練模型
model = clt.fit(X_std)
# 展示簇的成員
model.labels_
'''
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1,
1, 1, 1, 1, 0, 0, 0, 2, 0, 2, 0, 2, 0, 2, 2, 0, 2, 0, 0, 0, 0, 2, 2,
2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2, 0, 0, 0, 0, 2, 0, 2, 2, 0,
2, 2, 2, 0, 0, 0, 2, 2, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
'''
```
## DBSCAN 聚類

```py
# 加載庫
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import DBSCAN
# 加載數據
iris = datasets.load_iris()
X = iris.data
# 標準化特征
scaler = StandardScaler()
X_std = scaler.fit_transform(X)
```
`DBSCAN`有三個要設置的主要參數:
* `eps`: 觀測到被認為是鄰居的另一個觀測的最大距離
* `min_samples`: 小于上面的`eps`距離的最小觀測數量
* `metric`: `eps`使用的距離度量。 例如,`minkowski`,`euclidean`等(請注意,如果使用 Minkowski 距離,參數`p`可用于設置 Minkowski 度量的指數)
如果我們在訓練數據中查看簇,我們可以看到已經識別出兩個簇,“0”和“1”,而異常觀測被標記為“-1”。
```py
# 創建 DBSCAN 對象
clt = DBSCAN(n_jobs=-1)
# 訓練模型
model = clt.fit(X_std)
```
## 評估聚類
```py
import numpy as np
from sklearn.metrics import silhouette_score
from sklearn import datasets
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 生成特征矩陣
X, _ = make_blobs(n_samples = 1000,
n_features = 10,
centers = 2,
cluster_std = 0.5,
shuffle = True,
random_state = 1)
# 使用 k-means 來對數據聚類
model = KMeans(n_clusters=2, random_state=1).fit(X)
# 獲取預測的類別
y_hat = model.labels_
```
正式地,第 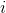 個觀測的輪廓系數是:
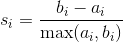
其中 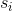 是觀測 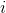 的輪廓系數,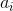 是 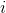 和同類的所有觀測值之間的平均距離,而 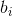 是 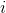 和不同類的所有觀測的平均距離的最小值。`silhouette_score`返回的值是所有觀測值的平均輪廓系數。 輪廓系數介于 -1 和 1 之間,其中 1 表示密集,分離良好的聚類。
```py
# 評估模型
silhouette_score(X, y_hat)
# 0.89162655640721422
```
## 均值移動聚類

```py
# 加載庫
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import MeanShift
# 加載數據
iris = datasets.load_iris()
X = iris.data
# 標準化特征
scaler = StandardScaler()
X_std = scaler.fit_transform(X)
```
`MeanShift`有兩個我們應該注意的重要參數。 首先,`bandwidth`設置區域(即觀測核)半徑,用于確定移動方向。 在我們的比喻中,帶寬是一個人可以在霧中看到的距離。 我們可以手動設置此參數,但默認情況下會自動估算合理的帶寬(計算成本會顯著增加)。 其次,有時在均值移動中,觀測核中沒有其他觀測結果。 也就是說,我們足球上的一個人看不到任何其它人。 默認情況下,`MeanShift`將所有這些“孤例”觀測值分配給最近觀測核。 但是,如果我們想要留出這些孤例,我們可以設置`cluster_all = False`,其中孤例觀測標簽為 -1。
```py
# 創建 MeanShift 對象
clt = MeanShift(n_jobs=-1)
# 訓練模型
model = clt.fit(X_std)
```
## 小批量 KMeans 聚類
小批量 k-means 的工作方式與上一個方案中討論的 k-means 算法類似。 沒有太多細節,不同之處在于,在小批量 k-means中,計算成本最高的步驟僅在隨機的觀測樣本上進行,而不是所有觀測。 這種方法可以顯著減少算法發現收斂(即適合數據)所需的時間,而質量成本很低。
```py
# 加載庫
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import MiniBatchKMeans
# 加載數據
iris = datasets.load_iris()
X = iris.data
# 標準化特征
scaler = StandardScaler()
X_std = scaler.fit_transform(X)
```
`MiniBatchKMeans`與`KMeans`的工作方式類似,有一個顯著性差異:`batch_size`參數。 `batch_size`控制每批中隨機選擇的觀測數。 批量越大,訓練過程的計算成本就越高。
```py
# 創建 KMeans 對象
clustering = MiniBatchKMeans(n_clusters=3, random_state=0, batch_size=100)
# 訓練模型
model = clustering.fit(X_std)
```
## KMeans 聚類

```py
# 加載庫
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
# 加載數據
iris = datasets.load_iris()
X = iris.data
# 標準化特征
scaler = StandardScaler()
X_std = scaler.fit_transform(X)
# 創建 KMeans 對象
clt = KMeans(n_clusters=3, random_state=0, n_jobs=-1)
# 訓練模型
model = clt.fit(X_std)
# 查看預測類別
model.labels_
'''
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 0, 0, 0, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2,
2, 0, 2, 2, 2, 2, 0, 0, 0, 2, 2, 2, 2, 2, 2, 2, 0, 0, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 2, 2,
0, 0, 0, 0, 2, 0, 2, 0, 2, 0, 0, 2, 0, 0, 0, 0, 0, 0, 2, 2, 0, 0, 0,
2, 0, 0, 0, 2, 0, 0, 0, 2, 0, 0, 2], dtype=int32)
'''
# 創建新的觀測
new_observation = [[0.8, 0.8, 0.8, 0.8]]
# 預測觀測的類別
model.predict(new_observation)
# array([0], dtype=int32)
# 查看簇中心
model.cluster_centers_
'''
array([[ 1.13597027, 0.09659843, 0.996271 , 1.01717187],
[-1.01457897, 0.84230679, -1.30487835, -1.25512862],
[-0.05021989, -0.88029181, 0.34753171, 0.28206327]])
'''
```
