# (2) 模仿學習
> 作者:[謝天](https://www.zhihu.com/people/xie-tian-55-77)
>
> 來源:[POST 館](https://zhuanlan.zhihu.com/c_150977189)
## 序貫決策問題
在這里我們先假設大家都已經對監督學習 (Supervised Learning) 的基本概念非常熟悉了。我們在這里先介紹一下今后要使用到的記號:
跟上一篇一樣,這只是一個有監督學習的例子,把圖像通過某種方式進行分類,譬如在這個例子中將左邊的圖片分類成老虎。我們把圖像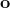稱為**觀測** (observation),而把輸出的結果稱為**行動** (action):系統要做的行動無非是給觀測到的圖像貼上屬性變量的標簽。在從到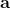的過程中有一個**策略** (policy) 函數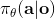,這個函數確定了給定觀測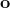之后,行動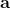的概率分布,這個分布比較常見的方式是通過一個 Softmax 函數來確定。這個策略里面有一個參數,而如果是一個神經網絡,那么這個參數就是神經網絡的權重。在監督學習中,我們的目標是找到一組很好的參數,使得它能很好地完成任務。
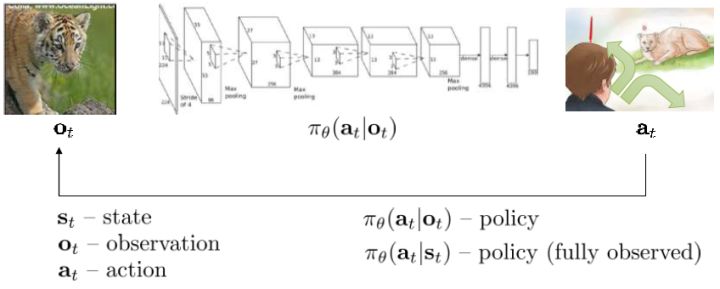
我們將這一設定進一步延伸到序貫決策問題中去,這一問題是由很多時間點的決策問題組成的。首先我們給之前的所有變量都打上下標,以說明這是時刻的決策問題:在時刻,我們觀測到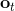,然后做出行動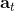。不同于監督學習的獨立同分布假設,在序貫決策問題中認為當期的行動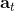會影響到下一期的觀測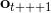。所以當你看到老虎的時候,你需要做出合適的動作,說不定你下一期就不會再看到老虎了;而如果你的動作不正確,也許就會發生慘劇。在這個問題中,我們要做的行動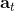就不再是把它標注為老虎了,而是采取的某項真正意義上的動作。這種動作可以是離散意義的,譬如跑掉、忽略或者去撫摸它等,在數學表達上和之前的類似,可以使用 Softmax;也可以是連續的,譬如選擇往哪個方向跑,可能會去用一個高斯分布的均值和方差來表示;當然混合起來也是可以的。
在這邊還出現了一個**狀態** (state) 的概念,通常指真實環境的相關配置全貌,包含了我們去了解這個世界所需要的一切信息,但這些信息不見得能從單一的觀測中得出來。以一個獵豹追逐羚羊的圖片作為例子,這個圖片作為觀測,本身是一個很大的張量;而在圖片背后,其實潛藏著一個真實的物理系統,包含了譬如獵豹和羚羊的坐標、速度以及其他各種量。這樣的系統構成了我們所真正關心的狀態本身。究竟是使用狀態還是觀測,取決于我們能否完全了解到整個情況:我們看到的感受到的,不見得就是整個環境本身,往往是不充分的。如果我們的圖片上獵豹正好被一輛車擋住,此時雖然我們在觀測中看不見獵豹,但它依然是真實存在的;但是對于下圍棋這種例子,棋盤上所有情況都是非常清楚的,因此觀測就是狀態本身了。

用一個圖形來表示它們的關系。我們從狀態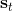中獲得了觀測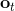(這里假設觀測不完全),并根據策略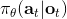來得出行動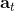。這里有一個轉移概率函數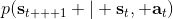(很多文獻中的 dynamics 也通常指的是這類轉移概率),表明了在狀態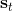下執行行動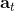所得到的下一個觀測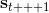的概率分布。這里有一個性質,也就是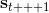被認為僅由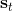和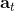影響,而與之前的狀態和行動無關:也就是之前的所有后果全部被包含在狀態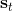之中了,你可以忘掉過去所有的東西,此謂 Markov 性,也是序貫決策問題的重要假設。注意到對于觀測來說,這個性質是不成立的,觀測序列不具有 Markov 性。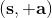的記號最早來源于著名動態規劃開山鼻祖的 Richard Bellman,取 state 和 action 的首字母;在機器人和最優控制領域則常見使用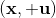來作為記號,來源于最優控制的鼻祖 Lev Pontryagin。
## 模仿學習
我們考慮自動駕駛問題,在這個問題上我們或許可以使用一些監督學習的方法,來根據觀測來預測駕駛員應該要做出的行動。一種可行的思路是,找到成百上千的司機,在他們的車前裝上攝像機,并且以一個固定頻率來記錄他們的動作(如方向盤轉向、油門、剎車操作)。這樣我們就能得到一大堆觀測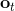和行動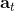,作為我們的訓練樣本數據。我們想要通過這些訓練數據,來訓練一個神經網絡以輸出行動(轉向、油門、剎車)的分布。分布可以是離散的,這時就需要把這些行動離散化;也可以是連續的,如輸出轉向角度和預期速度的高斯分布。將這些訓練數據放入一個監督學習的算法,如帶動量 (momentum) 的 SGD,或者 ADAM 等算法。這時我們得出一個策略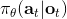,純粹是由監督學習得到的。
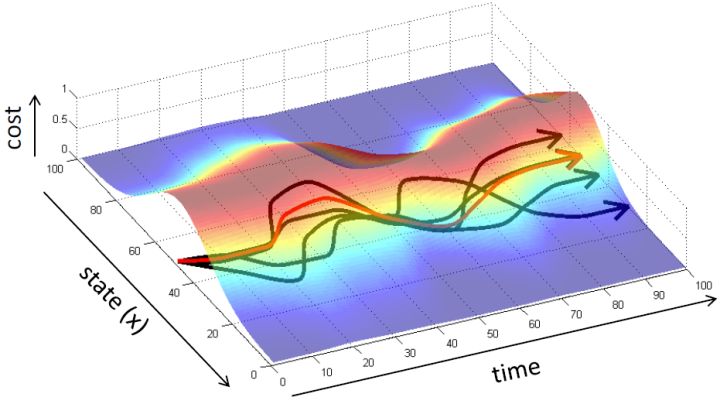
那么這樣做是否有很好的效果?事實上并不然。我們可能不能得到非常充足的數據,以至于很難泛化到新的情形中去。但即便我們的數據已經充足,這個做法也可能會導致很大的問題。下面給一個直觀的例子。圖的黑色線條是我們的訓練軌跡,假設狀態是一維的位置信息。
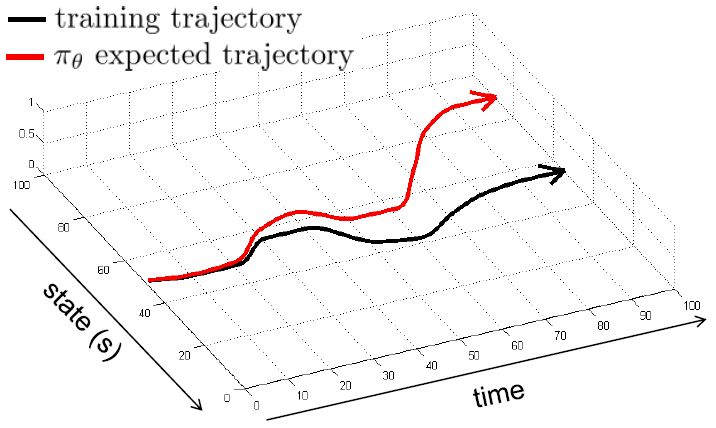
如果我們訓練完畢,期望能夠重新生成這條黑色軌跡。我們的訓練誤差可能被控制得很小,但這種函數的近似手段通常不會是非常完美的。我們使用紅色的線來描繪根據之前策略得到的期望軌跡。如我們在第一個拐彎處出現了一個非常小的失誤(第一次出現夾角處),這時我們的狀態是和訓練軌跡有一個非常小的差距的。這個失誤本身并不嚴重,而麻煩的是,這個失誤導致進入了一個新的狀態,在這個狀態中可能會犯的錯誤比之前的失誤更大。雖然可能只大一點點,但是會導致這個軌跡偏離越偏越大,最后發散到一個很離譜的地方。這本質上是因為序貫決策的特性才導致了這樣的問題:如果只是一個單獨的問題,也許會犯點小錯誤,但這個錯誤是有限的;而這里的決策并不是獨立同分布,每個行動都會影響下一個狀態,這樣錯誤就會被累積起來。
即便前面充滿了對這樣簡單粗暴算法的批判,但是這樣的做法事實上也有人在使用,如 NVIDIA 的一項關于自動駕駛的研究,Bojarski et al. (2016) 收集了 3000 英里的數據后效果一樣不差。他們成功的秘訣主要是使用了一些“黑科技”,下圖是其原理圖。
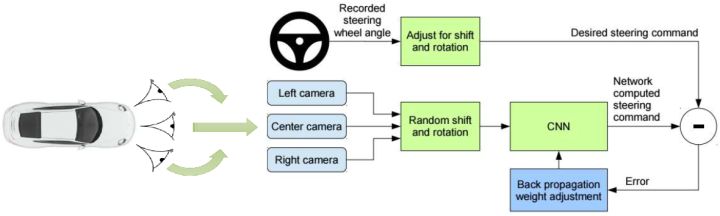
如上圖所示,他們不僅在車正前方裝上了攝像頭,還在車的偏左偏右的兩側同樣裝上,通過這樣獲得增強的訓練數據。這個小技巧就是,收集到了向前的圖像,并將其標注上司機的實際操作方案。與此同時,你也獲得了向左一個角度和向右一個角度的圖像數據:我們可以將左攝像頭得到的圖像所對應的司機操作稍微加一個向右的角度,右攝像頭向左,作為一個簡單的補償。從更廣泛的意義上理解,這樣的做法本質上是一個穩定控制器 (stabilizing controller),對于漂移的情況給出了對于偏差的補償校正方案。即便我們單條的軌跡可能偏離很大,但是整體軌跡的分布還是比較穩定的:不關于一個特定的有界的區域偏離太多。
對于一個軌跡分布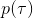,其中軌跡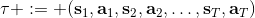,之后的課程中我們可以使用一個類似迭代 LQR 的算法構建一個高斯分布來描述它。轉而從一個概率的角度來看這個問題的話,我們使用策略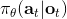來確定行動,訓練的是根據輸入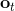來輸出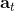的分布的這樣一個監督學習算法。我們的訓練數據中其實是符合一個特定的分布的,稱為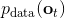。當我們真正運行我們的策略時,因為行動會對將來的觀測產生影響,實際上軌跡路線上看到的數據分布將和訓練數據的分布不同,稱為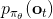,通常與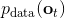不同,除非我們的訓練是完美的,且看到了與訓練數據一模一樣的初始觀測。如果兩個分布不同,那么這將意味著我們將在一個與訓練集有很大差異的測試集上進行測試,這在監督學習中也稱為域轉移 (domain shift),通常機器學習不能保證在測試集有任何的效果。
那么我們如何能做到使得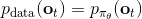呢?一個有趣的想法是,鑒于我們要去讓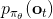去接近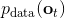可以說是削足適履的,倒不如轉頭去對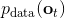做點手腳讓它能貼近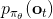,譬如從收集數據的時候就“根據”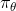去做。這也是 Ross et al. (2011) 提出的算法 DAgger (Dataset Aggregation) 的思想基礎。它的目標是從分布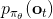收集訓練數據。為了做到這一點,我們只需要去運行策略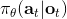來收集一些新的數據就可以了。困難的是,我們需要去對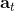進行重新標記:我們不僅僅是需要圖像,更重要的是要給出對應的行動才是。一個簡化版本的 DAgger 算法是這樣的:
1. 從人工提供的數據集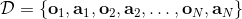中訓練出策略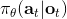;
2. 運行策略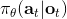來獲得一個新的數據集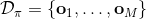;
3. 人工來對數據集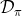進行標注,得到一系列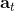;
4. 合并數據集,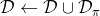。返回第一步。
第一步可以由任意的監督學習算法來完成,第二步我們希望沒有什么意外發生。第三步聽起來有點奇怪,就像找個人來看一個電影,然后指導這個機器應該做些什么;這個事情有的時候簡單,有的時候就非常困難了,但必須得做以獲得標簽。這樣做下來,數據集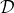就會有越來越多的在線 (on-policy) 數據,該算法所得出的策略結果和人類專家的差異(訓練誤差)就會逐漸收斂到一個有界的情形,從而使得數據集分布收斂到策略分布。這個算法以“向老師請教怎么做”的互動形式模仿老師的工作,而不僅僅是老師拿出一大堆意見的填鴨式灌輸而缺乏互動,我自己感覺這在人類教育中也是很有意思的想法。特別的是,就第二步而言,我們可以運行策略幾分鐘然后馬上找個人來標注數據再重新訓練,也可以運行一年然后再標注,取決于具體的需要。有一個使用 DAgger 訓練的無人機飛行避開樹木的例子,先用一個訓練集來訓練策略,讓它飛一段時間后人工對這些數據進行標注,再重新訓練。
在這個過程中,第三步我們可能會需要很長的人工標注時間(我感覺通常比收集數據本身難多了),而且有相當難度。譬如指導汽車駕駛,如果坐在駕駛位上可能是非常熟練的,但給你圖片讓你給出標注可能就不那么容易了。那么能不能在不用很多數據的時候使得模仿學習成功呢?深度增強學習的理論常常給予否定答復,然而在實踐中往往是可行的。DAgger 算法解決分布“漂移”的問題,而如果我們的模型非常好,不會產生“漂移”,事情就會容易很多。要想做到這點,我們需要去非常精確地去模仿專家的行為,同時也不要過擬合,雖然在很多情況下這個事情很難做到。如果能做到這點,雖然我們不能完全消除累積錯誤,但是一定程度上可以得到緩解。
有兩個原因使得我們經常不能很好地學習專家行為。
第一個是非 Markov 行為,意思是專家所做的行為可能不完全依賴于當前所看到的東西。我們在前面學習的假設中,給定的策略形式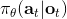假設行動只依賴于當前的觀測。在這樣的假設下,如果我們看到同樣的東西兩次,那么我們也做同樣的行動兩次,和之前是否看見過是沒有關系的。這在一些情況下并不合理,是因為我們只能得到部分觀測 (partially-observed),當前的狀態不能被這個觀測所完全推斷出來。還有一點就是即便是人類,看到同樣的事情兩次會做出一模一樣的行動,通常也是非常不自然的:譬如開車,每次行為都會有些差異,我們也很難理解我們為什么這么做,也不理解到底發生了什么。要想解決這個問題,一個想法是把之前所有的觀測都提供出來,變成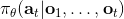:行動依賴于過去所有的觀測,這樣就能處理非 Markov 行為了。那么怎么使用整個歷史呢?在自動駕駛的例子中,如果歷史幀數多的話,權重參數的個數就會增長得很快。在這個時候,通過權重共享等手段,循環卷積神經網絡就可以大顯身手了。訓練的目標是讓輸出的行為概率分布更接近人工操作。對于 RNN 的選擇,通常使用 LSTM 的效果是比較好的。
第二個是多峰 (multimodal) 行為。當我們要駕駛無人機躲避一棵樹的時候,我們可能會向左繞或者向右繞,但如果將這些決策進行平均的話就變成向前飛然后撞上去了,就悲劇了。如果我們采用離散的概率分布,其實問題不大:如果離散成(向左飛,向前飛,向右飛),那么肯定向左向右有一個很大的概率而向前飛概率很低。而如果我們使用連續的概率分布,或者我們將它離散化得非常細,那么概率分布將會一團糟。如果我們使用高斯分布這樣的單峰分布,顯然是不合理的。這只是一個比較簡單的例子,是這類問題的冰山一角,實際中經常發生。那么我們怎么去解決這類問題呢?
1. 第一種方法是使用高斯分布的混合,即把分布表示為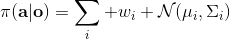這樣的加權線性組合,這樣就可以代表一些多峰分布;這五類方式的主要缺點是需要指出這個分布有多少個峰,如果有十個峰的話可能還是很麻煩的。
2. 第二種是使用隱性密度模型 (Implicit Density Model),這類模型可以表達任意概率分布:雖然它本身還是輸出一個高斯分布或者一個什么其他的簡單分布,甚至可以是一個值。現在我們輸入的不僅僅是一個觀測圖像本身,同樣也輸入一個噪音進去,譬如給定維數的多元高斯噪音,然后得到輸出。這一模型可以學習任何的非線性函數,可以把單峰的噪音變成多峰的輸出。我自己感覺這個模型輸入了一個隨機噪音進去,對應了原分布的某一個位置,有點像概率論里面的分布變換。這種方法的主要問題是這個模型很難訓練。
3. 第三種是使用自回歸離散化 (Autoregressive Discretization)。如果有連續的動作,一個可行的方法是將其離散化;但是如果維度大了,離散化后的聯合分布將維度災難。一個小技巧是避免聯合離散化所有維度。假設我們有三個維度,首先我們離散化維度 1,通過諸如 Softmax 的方法得到維度 1 的幾個離散分類的分布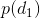。然后我們從這個分布里面進行抽樣,得到維度 1 的值(其實是某個分類),然后把這個值輸送給另一個神經網絡(順便還有圖像或者某些隱藏層數據),這個神經網絡給出離散化后維度 2 的分布,再如此得到維度 3 的分布。這樣做的一個好處是,維度 2 的分布是以維度 1 的樣本為條件的,即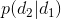。這樣就可以表示出任何的聯合分布,但是在一個時段只需要離散化一個維度。當你訓練這樣的模型時,只需要給每個維度的正確值就可以了,做一個標準的監督學習過程。在測試中,需要依此采樣然后饋入后續網絡之中。
總結來說,模仿學習通常有一定局限性(分布不匹配的問題、誤差累積問題),但有時候能做得不錯,如使用一些穩定控制器,或者從穩定軌跡分布中抽樣,抑或是使用 DAgger 之類的算法增加更多的在線數據,理想化地如使用更好的模型來擬合得更完美。
## 案例
第一個案例是 Giusti et al. (2016),使用一個四旋翼在森林小道里飛。他們的策略與之前 NVIDIA 的相似,也使用了左右攝像頭進行補償。實際上,他們遇到的問題比 NVIDIA 的自動駕駛更為困難:因為森林小道通常是非常凌亂的,很難進行清晰的感知,有些時候給一個圖應該往哪兒飛都得仔細分析一會兒。首先,他們將動作的輸出離散為向前、向左、向右三個;然后訓練深度卷積神經網絡來從圖片得到動作。在這個問題中,收集數據可能是比較困難的,因為四旋翼本身非常續航時間很短,經常需要充電;他們的解決方法是用人頭上綁三個 GoPro 攝像機來收集數據,并認為左中右三個相機拍攝到的圖像應該被分別標為右前左。事實上,這樣做的效果非常好:雖然這樣做會非常尷尬,但每個人都能做到。

第二個案例是 Daftry et al. (2017),同樣是四旋翼控制問題,使用 DAgger 來規避分布不匹配的問題。在 DAgger 的第三步,需要人工參與標注。人類通常比較難看著某些動畫來拉控制桿,因為人類需要一些反饋信息。他們編了一個更直觀的接口,使用了畫圖中紅線的方式,來計算出四旋翼應該調整的角度,這樣對于人工標注的難度就大大降低了。同樣,他們建立了一個深度神經網絡,從一個圖片入手輸出四旋翼指令。他們的數據中有夏天的數據和冬天的數據(兩者看起來差異很大),引入了一個對抗域適應機制,設計一個通用的神經網絡來解決兩個季節問題和不同四旋翼的問題。

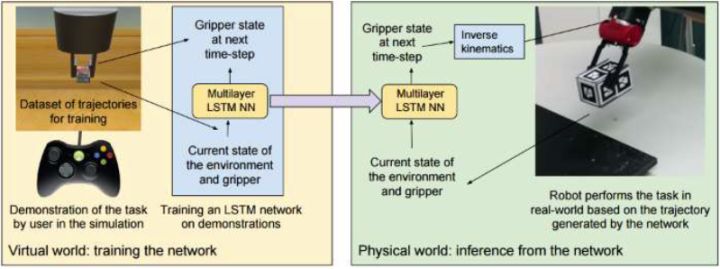
第三個案例是 Rahmatizadeh et al. (2016),使用游戲手柄和模擬器訓練機械臂的運作,把一個盒子(標志物)夾起來放到某個地方去。使用 LSTM 來處理非 Markov 問題,使用混合高斯分布來處理多峰問題。他們在訓練時候也故意會犯一些錯誤,來闡述一些更正手段。當機器人成功后人會把盒子移開,機械臂會再去夾。有趣的是這沒有一個階段性任務的說法,事實上只是一個 LSTM 不停地在運轉而已。Levine 教授推測 LSTM 之所以有意義,很可能是因為人的指導過程會產生非 Markov 的偏差。
模仿學習在很多其他領域也有應用。如結構預測問題,不僅僅是輸出一個標簽,而是更結構化的輸出。這種預測問題在自然語言處理,如機器翻譯或問答機器人中尤為重要。比如人家提問“Where are you”,回答“I'm at work”。如果像 RNN 一樣一個詞一個詞輸出,如果第二個詞 at 變成了 in,那么第三個詞可能就不能是 work 了,即便和數據本身比較接近,可能說 school 會好一些:第二個詞的選擇會影響第三個詞。因此在結構預測問題中,答案的一部分會影響另一部分,有點類似一個序貫決策問題。因此一些模仿學習方法已經在這個領域中流行了起來:因為通常有訓練數據所以會比較像模仿學習,而且是序貫的。其他的諸如交互和主動學習,要從人的反饋中學習;再就是逆增強學習。
那么模仿學習的最大問題是什么?第一,人類需要提供數據,而人能提供的數據通常是非常有限的,即便如頭戴攝像機這樣相對便宜的手段被開發出來,而深度神經網絡通常需要大量的數據才能把事情做好,此為一大限制。第二,人類不善于提供有些類型的行動指導,原因可能是多種多樣的。第三,人類可以自主學習而機器則不能,自主學習的好處是我們可以通過自己的經驗獲得無限量的數據,看到錯誤可以自我修正,達到連續的自我提升。
## 獎勵/代價函數
要超越模仿學習,我們必須找到我們真正想要的是什么。回到一開始人與老虎的那個例子,讓我們先不考慮策略函數。在這種情況下,我們真正想要做的事情是給出一連串決策,使得被老虎吃掉的概率最小: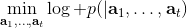。如果我們真的知道被老虎吃掉這個事情怎么用數學形式表示,我們可以把它描述成一個最優化問題。一般來說,我們想做的是最小化一系列的代價函數: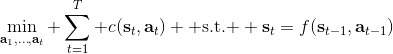。譬如我們可以把被老虎吃掉的概率當成我們的代價函數,或者負的獎勵函數。我們不能選擇最終我們停留在什么狀態,這是由系統轉移的動態決定的;我們能選擇的就是一系列的行動。因此,如果要超越模仿學習,我們需要定義關于代價或者獎勵的目標函數:代價函數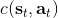或者獎勵函數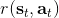,兩者是相反數關系。獎勵函數在動態規劃領域更流行,而代價函數在最優控制領域更流行。
在實踐中,獎勵函數有很多種形式。譬如讓一個機械手抓住一個小球并放到某個指定地點,當然我們可以選擇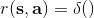這樣簡單的函數,但這樣的函數通常很難幫我們解決增強學習問題:直到你把小球移動到目標位置之前,你真的不知道你應該這樣做。所以通常解決實踐問題,我們會設計一些更循序漸進的獎勵函數,如  之類,我們減少機械臂和小球的距離,也要減少小球和目標的距離,也避免讓動作做得太大。這三個目標都不是我們真正想做的意圖,但能幫助我們做事情。一個使機械小人奔跑的例子也是,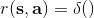這樣的函數并不好,而使用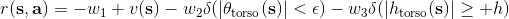之類的函數,要增加小人的運動速度,控制軀干的傾斜角度避免傾倒,保持軀干的高度。
同樣,模仿學習也可以寫出獎勵函數,如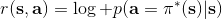,也就是我們策略的行動應該盡量與專家的指導意見一致。事實上 DAgger 算法也在優化這個東西,它能夠逐漸使得這個獎勵函數靠近最優的獎勵函數。
通常我們設計代價和獎勵函數會有一些困難。當我們玩電子游戲的時候,可能會有一個得分顯示在屏幕上,來說明你現在玩得有多好;但在很多現實問題中,并沒有一個顯式的得分這樣的概念,比如一個孩子想要倒一杯水,很難說獎勵函數是什么。Rusu et al. (2016) 用了一種方法把機器人在模擬仿真下學習到的策略轉移到現實控制問題中,但是他們在模擬中可以輕松得到的小紅方塊的位置,在真實情況下就變得不容易光從圖像中感知到位置了:他們需要寫出一個計算機視覺程序來定位這個紅色方塊。這樣一來,他們雖然自稱是從像素中得到數據,但是還是需要用監督學習來確定紅色方塊,是有一些悖論的,也說明了獎勵函數的設計在這個像素級別的問題中不是端到端的。
