# (11) 概率圖模型與軟化增強學習
> 作者:[謝天](https://www.zhihu.com/people/xie-tian-55-77)
>
> 來源:[POST 館](https://zhuanlan.zhihu.com/c_150977189)
## 概率圖模型上的推斷
在前面的筆記中,我們已經學習了如何使用一些常用算法來做出正確決策以優化收益函數。現在,我們轉過頭來關注如何對人類(專家)行為進行建模:這種模型之后的逆增強學習中可以用來使用觀測推斷收益函數是什么。在這里,我們關注一些概率模型來對觀察到的行為進行建模,建立起概率推斷和最優控制、強化學習之間的關系,并從中得出一些新的(稍微不同的)新的增強學習算法。
讓我們考慮人類在各種層面上的行為,如運動、在房間里行動,或者更高層面上的如開車的路徑規劃。一個合理的假設是,人類想要實現某種目標,都是去定義一些收益函數,并基于人類所能做出的行動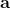和人類對世界和物理的理解(也就是一個人類自以為的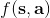),做一些諸如最優控制的規劃行動以實現目的。這個想法非常類似于我們之前的優化形式,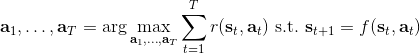,根據不同對象建立起不同的模型(如人的跑步是基于對人身體構造和物理環境的理解,汽車路徑規劃是對交通情況的理解),根據不同目標制定出不同的收益函數。對于一些隨機情況,可能我們需要得到一個最佳策略諸如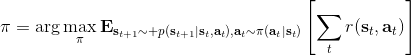來最大化期望收益的期望,然后從中挑選出行動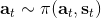。這是基于人的理性決策的假設,因此要研究一個人如何做出決策,如果我們能得到對應的收益函數,那么從某種意義上說就可以用最優控制或者增強學習的框架來解釋或預測在各種場合下這個人的決策。
比如說有一項實驗,使用果子獎勵刺激猴子把場景里一個物體移動到某個指定位置。我們知道最優的移動軌跡必然是兩點連線的直線段,但是猴子可能不會走這樣的直線,總會多多少少有一些彎曲,但同樣能完成任務。這是因為,猴子的決策基本總不是完美的,反正目標能完成就能拿到獎勵,所以**在某些領域有一些誤差其實影響并不大**(走了一條較長的路線差了幾秒鐘猴子可能覺得無所謂,而如果沒有把物體移動到指定位置那么就沒果子吃了,差別很大)。對于猴子來說,行為是隨機的,但是“好的行為”總是有一定相似度的。現在的問題是,如何使用數學的方法來表達,次優的路徑也是可以的但是不達目標的路徑是不行的這個界限,以及如何刻畫這個隨機行為。
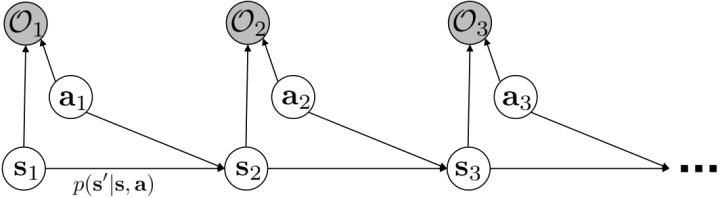
我們考慮使用概率圖模型來表達這個“近似最優的”行為:與之前我們只采取最優策略不同,我們也需要讓一些次優行動有非零概率存在。在之前,我們知道了狀態和行動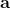通過系統動態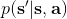共同決定了下一個狀態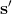。對于這樣的一串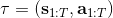,我們應有出現概率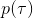,但是只有真實物理場景對猴子進行限制(如猴子不能飛),但沒有對猴子試圖做的最優行為或者意圖進行假設。為了對猴子的意圖進行建模,我們加入了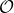元素來代表最優性,也就是說,代表猴子嘗試使用一些最優手段來完成(階段性)目標。簡單起見,我們假設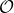元素是一個 0-1 變量,如果猴子沒在完成意圖就是 0,反之是 1,也可以理解成一個事件。接下來我們要做的事情就是來描述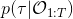。在這里一個重要假設是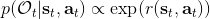,那么條件概率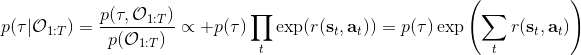,也就是正比于該軌跡實際的發生的概率乘上軌跡總收益的自然指數。因此,收益最大的(可行)軌跡就變得可能性最大;如果有一條軌跡收益也一樣大,物理可能性相同,那么它同樣也很可能發生:如有多條它們將平分可能性。注意在這里,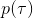只是用于評判給定了所有狀態和行動后,這樣一個序列的可能性,并不去決策。
這個模型表達了有些軌跡雖然不是最好的,但是也還不錯的這樣一個特征:猴子的例子告訴我們,在終點有一個巨大的收益,但是在路途中間并沒有什么收益,因此可能有非常非常多的較優路徑存在,但它們最后都指向了同一個終點。在這個模型中,收益最高的行為是最有可能的,當收益下降的時候它的可能性指數下降。有些軌跡雖然可能發生,但是可能性非常低,因此智能體可能不愿意承擔這個風險:因為想去最大化期望收益,智能體可能寧愿選擇收益較低的但是可能性較高的軌跡。這個模型有一些好處。第一點,它可以**對次優行為進行建模**,這個在逆增強學習中非常有意義,用于觀察他人的行為來揣測他的真實目標。第二點,可以**使用一些推斷算法來求解控制規劃問題**。此外,它可以**對為什么會偏好隨機行為(相較于確定性行為)給出解釋**。
我們的推斷 (inference) 問題是,如果執行最優策略,那么在當前狀態下做出某個行動的概率是多少。為了解決這樣的問題,我們需要回答三類問題:第一類是如何計算**后向信息** (backward messages) 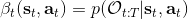;第二類是如何計算**策略** (policy) 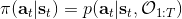;第三類是如何計算**前向信息** (forward messages) 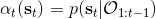。
首先我們來看**后向信息**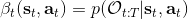,給定某個時間點的狀態和行動,得出未來最優性變量的觀測概率(它不關心過去)。之所以說是后向信息,是它的計算方式類似于 LQR 中的倒推。在遞推邊界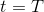時,根據定義有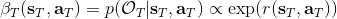,只需要做歸一化;在中間,我們使用全概率公式進行積分,并使用 Markov 性進行概率拆分,得到 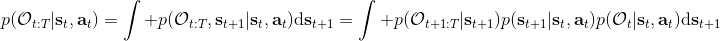。其中我們已知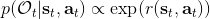和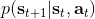,而剩余一塊根據全概率公式有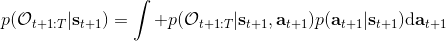,其中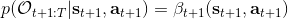;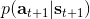比較奇怪,它并不是一個策略函數,**而只是一個給定狀態做出什么決策的先驗概率,在這里我們可以先認為是均勻分布的**,概率密度是一個常數。我們進一步令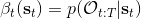,則所有的概率可以由以下倒推過程完成:
> for 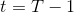 to 1:
> 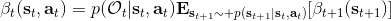 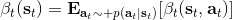
回顧我們的[值函數迭代 (value iteration) 算法](https://zhuanlan.zhihu.com/p/32909860),和這個算法不謀而合。因為這里所有的操作都是乘法形式,我們將其取對數變成加法形式。令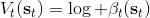,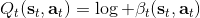。根據第二條關系有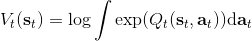。從極限的角度看,隨著 Q 的值變大,顯然會有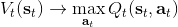,因此前者的這種操作也被稱為 softmax,是 max 函數的一個軟化。根據第一條關系,有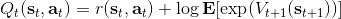。這個形式看起來很奇怪:如果狀態轉移是確定的,那么期望就可以拿掉了,對數和指數就抵消了,有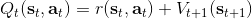,和值函數迭代形式一致;如果狀態轉移是隨機的,那么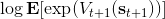就是一個 softmax,最樂觀的轉移。然而,樂觀也不是個好事情,Ziebart et al. (2010) "[Modeling Interaction via the Principle of Maximum Causal Entropy](http://link.zhihu.com/?target=http%3A//www.ri.cmu.edu/pub_files/2010/6/maxCausalEnt.pdf)" 一文提供了一個基于最大因果熵 (maximal causal entropy) 原則的方法,此時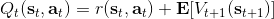。
在之前,我們還剩余了一個對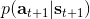的均勻分布的假設。如果這個先驗分布不是均勻分布,值函數將會變成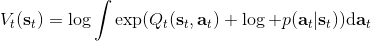,并保持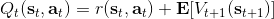不變。如果我們定義一個新的 Q 函數,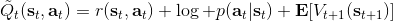,那么值函數又變成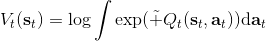了:這說明我們的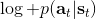項總能和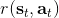項合并到一起去,因此我們在實際求解的時候可以不失一般性地假設這一項不對算法產生任何困難:如果有一個非均勻分布的先驗,就把它放到收益函數里面去就行了。
第二個是**策略**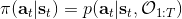,也就是給定當前狀態和所有最優性變量,得出行動的概率。首先根據 Markov 性,有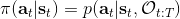。將條件概率進行一步變形,前者就等于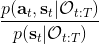。根據貝葉斯公式,又可以變形為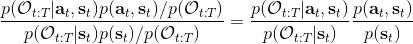。兩個分式相乘,前者為后向信息之比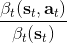,后者為先驗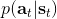,如果我們假設先驗是均勻分布的話那么后者是常數,因此可以去掉。從而,我們有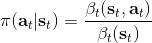。在我們之前的倒推過程中,如果換成 Q 函數和 V 函數的話,就是:
> for 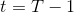 to 1:
> 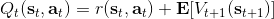 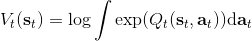
而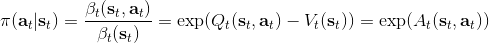,正好是一個優勢函數的指數的概念,也比較符合邏輯。這些函數還有一些變種,如對 Q 函數貼現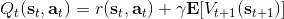就變成了貼現隨機最優控制 (discounted SOC);顯式加入一個溫度(熱力學概念)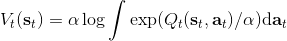,我們的 Q 和 V 都對溫度非常敏感,當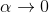時 softmax 就退化成 max,且有溫度時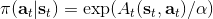。
這樣的策略的一個直接的解釋是,使得“更好的”行動更可能發生。如果有多個性質一樣好的行動,它們的可能性一致,只是一個概率分布的策略只需隨機挑選一個。它和 Boltzmann 探索(見[第六篇](https://zhuanlan.zhihu.com/p/32909860))有很強的相似性。隨著溫度下降,它逐漸逼近與一個貪心的策略。
最后一個推斷問題是**前向信息** (forward messages) 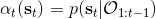,給定之前的所有最優性變量,得出在當前時點到達某狀態的概率。這個對策略來說并不重要,但是在逆增強學習中非常重要。前向信息的邊界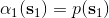,通常認為初始分布是已知的。將該概率進行展開,變成一個二重積分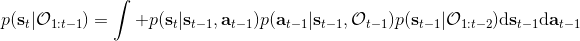。其中第一項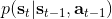我們假設是已知的系統狀態轉移,第三項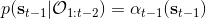。第二項略微復雜,使用貝葉斯定理得到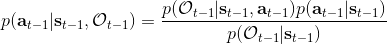,其中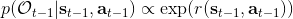,我們假設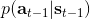是均勻分布,分母也是一個歸一化常數,因此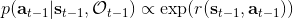。于是就得到一個正向的遞推關系了。
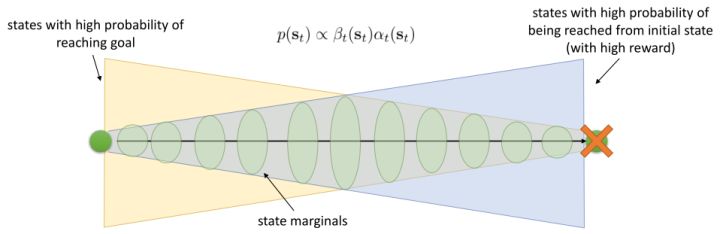
有了前向消息和后向信息之后,給定所有最優性變量,求某時刻的某狀態的發生概率就比較容易了。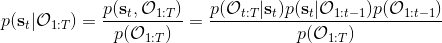,其中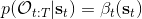,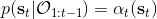,其他可以看作歸一化常數,因此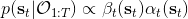,這整個理論和 HMM 很像。注意到這個概率是前向消息和后項消息的乘積,可以說是一個交匯。考慮上圖左邊圓點是起點,右邊叉叉是終點的路徑。黃色錐區域是能夠有高概率到達終點的狀態,藍色錐區域是有高概率從初始狀態以高收益到達的狀態,然后基本上就是兩者的交(概率上相乘)。Li and Todorov (2006) 做了人和猴子類似從一個點到另一個點的實驗,記錄空間位置變化,基本上也是中間部分方差最大。
總結來說,我們這邊用概率圖模型來描述最優控制,而且這個最優控制可以用概率推斷來實現(類似于 HMM 和 EKF),而且與動態規劃、值函數迭代關系非常強(它這里面 max 是軟化的,可以通過降低溫度來使得變成硬性 max)。
## 軟化的增強學習算法
使用之前提到的軟化 max 函數,可以得到很多增強學習算法,例如我們在這里對 Q 學習進行軟化。對于[標準的 Q 學習](https://zhuanlan.zhihu.com/p/32994423),參數的迭代格式為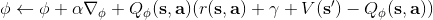,目標值函數為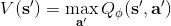。而對于軟化 Q 學習來說,梯度步還是一樣的,但是目標值函數變成了軟化 max 函數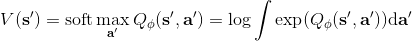。同樣,策略函數也變成了類似 Boltzmann 探索的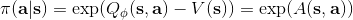。因此,只需要將[DQN](https://zhuanlan.zhihu.com/p/32994423)的第三步中“使用目標網絡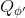計算出目標值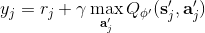”改成 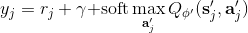 就可以了。第一步的“在環境中執行某個操作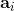,觀察到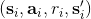”的操作,如果想在線執行(如 SARSA),也需要用軟化 max 來抽取。
策略梯度法也可以進行軟化。Ziebart et al. (2010) "[Modeling Interaction via the Principle of Maximum Causal Entropy](http://link.zhihu.com/?target=http%3A//www.ri.cmu.edu/pub_files/2010/6/maxCausalEnt.pdf)" 一文的一個結論是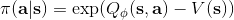最大化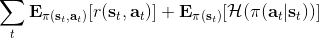。關于該結論的一個比較直觀的理解是,當最小化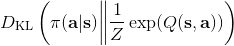時(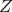為歸一化因子),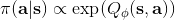。而如果我們展開 KL 距離表達式,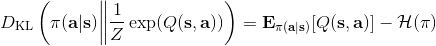,這是因為取完對數正好是這樣。因此,如果要對策略梯度法進行軟化,我們也**只需要在目標函數內,在期望收益之后加上策略函數的熵**就可以了:這個熵給策略一定壓力,使得它不會退化成一個確定性策略。這種方法通常被稱為**熵正則化** (entropy regularized) 策略梯度法,通常用于防止策略過早地熵崩塌 (premature entropy collapse)。這在行動空間是連續的時候尤為重要,如我們之前在[策略梯度法的第二個問題](https://zhuanlan.zhihu.com/p/32652178)中提到,高斯策略下,策略梯度法通常希望減少策略的方差,因為減少方差通常可以導致局部的收益增大,但這同時也會使得策略梯度卡住,改進停止,加入熵也是一個方法。
同時,這個方法和軟化的 Q 學習也非常有關,詳見 Haarnoja et al. (2017) 的"[Reinforcement Learning with Deep Energy-Based Policies](http://link.zhihu.com/?target=https%3A//arxiv.org/abs/1702.08165)" 和 Schulman et al. (2017) 的"[Equivalence Between Policy Gradients and Soft Q-Learning](http://link.zhihu.com/?target=https%3A//arxiv.org/abs/1704.06440)"。這里給出一個比較簡單的介紹。由于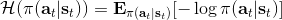,軟化的策略梯度法的目標函數就等于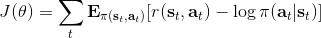。將其關于策略參數取梯度, 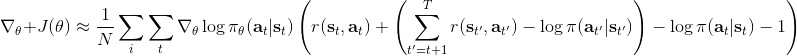 ,最后的那個 1 可以通過基線 (baseline) 拿掉,而中間的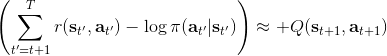。注意到,軟化的 Q 學習中,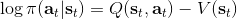,因此代入進去得到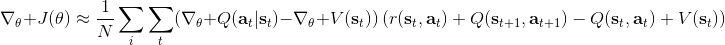,同樣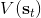 可以拿掉。對于軟化的 Q 學習,它的梯度為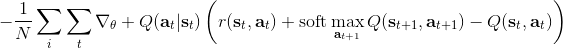,看起來是非常相似的。符號不同是因為 Q 學習是梯度下降,而策略梯度法是梯度上升。
總體來說,軟化方法的好處主要是有以下幾點。首先毫無疑問地,它**增加了探索(類似 Boltzmann 探索)且防止了熵的坍塌**。軟化方法**對狀態的覆蓋面更廣**、**魯棒性增強**,也**更容易對特定的任務進行調參(預訓練)**。對于**并列最優**的情況,軟化 max 得到的是一個分布,幾個選項將等概率選擇,**通過調整溫度參數和收益尺度可以使得軟化 max 變成硬 max**。在之后我們也將體現這個模型**更適合對人類行為建模**。
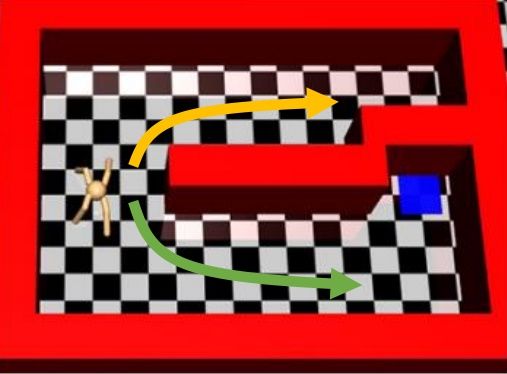
Haarnoja et al. (2017) 的"[Reinforcement Learning with Deep Energy-Based Policies](http://link.zhihu.com/?target=https%3A//arxiv.org/abs/1702.08165)" 使用軟化的 Q 學習方法來進行成功的實踐。用策略梯度法來學習 MuJoCo 小人跑步的任務,超參數稍微進行調整,可能雖然得分都很高但是跑步形態完全不同,這是因為增強學習算法一旦發現一塊比較好的區域,就會去加強這塊區域的利用率,很容易達到局部最優。如上圖中,機器人想到達這個藍塊,代價函數為到這個藍塊的距離。機器人可以選擇黃色或綠色路線,初始看起來可能效果差不多,但是黃色路線實際上是走不通的:軟化的方法可以讓兩條線路有更均衡的被選擇概率,防止某一塊被過度增強,不錯失可能性。這個方法被稱為隨機的基于能量的策略 (stochastic energy-based policy)。要保證所有假設都被驗證,就是用之前介紹過的軟化 Q 學習算法,問題是如何實現從分布中采樣。為了實現這個目標,它們訓練一個隨機網絡來根據狀態和某高斯隨機噪音來得到行動(類似[模仿學習](https://zhuanlan.zhihu.com/p/32575824)中提到過的隱性密度模型),使用[均攤的 SVGD (Stein Variational Gradient Descent)](http://link.zhihu.com/?target=https%3A//arxiv.org/abs/1611.01722) (Wang and Liu, 2017) 來訓練以符合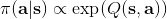,和 GAN 的想法非常接近。
四足動物在一個槽里移動的訓練,在預訓練時,軟化的 Q 學習相比 DDPG(加上-貪心)來說探索覆蓋面更廣(一開始就顯示出了非常強的探索性)。事實上,有預訓練比沒有預訓練效果好很多,而且軟化 Q 學習的預訓練效果比 DDPG 預訓練要好。
