# (3) 增強學習簡介
> 作者:[謝天](https://www.zhihu.com/people/xie-tian-55-77)
>
> 來源:[POST 館](https://zhuanlan.zhihu.com/c_150977189)
## Markov 決策過程與增強學習
在上一篇中,我們已經熟悉了狀態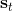、觀測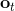、行動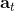、策略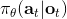或者是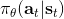的概念,也知道了從包含認知世界所需要的所有信息的狀態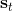得到觀測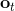,然后使用策略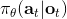做出行動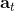,最后由狀態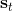和行動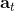經過系統固有的轉移概率分布函數 (dynamics) 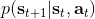得到下一期的狀態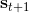這樣周而復始的過程,同樣我們也明白了給定狀態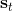,假設之后的狀態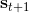和之前的狀態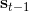等無關的 Markov 性。
我們同樣給出了如果我們有充分的數據,一定程度上可以做監督學習(模仿學習)。但是如果我們沒有數據的話,需要用一些方式來定義這個任務。在上一篇的結尾也提到,一個核心是要去設置一個收益函數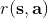,它定義了什么樣的 (狀態, 行為) 二元組是好的,以及什么樣的是不好的。譬如在自動駕駛問題中,如果汽車開得很順利速度很快,收益函數應該很高;而如果和其他車輛撞上了,那么收益函數應該很低。收益函數的目的不是直接告訴你現在應該做什么,只是告訴你哪些結果會被認為是比較好的。而增強學習問題的一大目標就是,弄清楚現在應該做什么,使得未來的結果會更好。這也被稱為延遲收益 (delayed reward) 問題,現在的行為可能不立即產生什么獎懲,而會對將來的結果產生嚴重的影響。
狀態、行動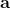、收益函數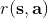和轉移概率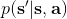共同定義了**Markov 決策過程** (Markov Decision Process, MDP)。
為了描述這一過程,我們先來回顧一下俄羅斯數學家 Andrey Markov 提出的 Markov 鏈。Markov 鏈本身并不是直接與增強學習相關。Markov 鏈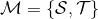由狀態空間 (state space) 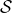和轉移算子 (transition operator) 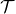共同構成。每一個狀態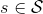可以是離散的分類變量,也可以是連續的數值之類;轉移算子確定了概率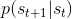,是給定當前狀態轉移到下一個某狀態的轉移概率。該算子其實是一個線性算子。如果狀態是離散的,令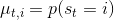為在時刻處于狀態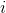的概率,從而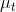是一個加和為 1 的概率分布向量,表示了在時刻的概率分布;令轉移概率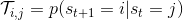,則這些概率組成一個轉移概率矩陣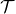,且有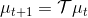的關系。如果狀態是連續的,則無非狀態變成了無數個,轉移概率矩陣無窮大,但還是線性的。Markov 性體現在轉移概率的定義上,當我們知道狀態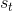了,下一個狀態就不依賴于其他的信息了,分布為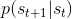。
Markov 決策過程 (MDP) 是將 Markov 鏈放在一個決策環境的擴展產物,在 1950 年代由 Richard Bellman 等人提出。Markov 決策過程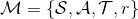相比之前多了一些組件。其中狀態空間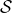保持不變,多了一個行動空間 (action space) 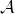,行動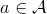同樣可以是離散的也可以是連續的。在這里,轉移概率不僅受到狀態影響,還受到行動影響,因此轉移算子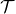在這里變成了一個張量,每個元素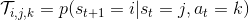。如果令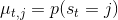,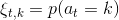的話,同樣存在一個線性關系: 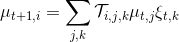。因此下一期的狀態只與當期狀態和當期行動有關系。最后一部分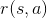是收益函數,是一個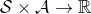的映射。
一個更加廣義的問題被稱為**部分可觀察的 Markov 決策過程** (Partially Observed Markov Decision Process, POMDP)。該過程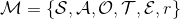新增了兩個組件:觀察空間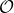 (observation space),同樣是可以離散可以連續的;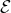為排放概率 (emission probability),決定了給定由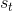后,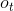的概率分布為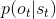。
現在我們來說明增強學習的目標是什么。在這里我們假設的策略函數是清楚的,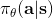可以由一個參數為的深度神經網絡確定(這里先假設完全可觀察)。我們將狀態輸入到深度神經網絡之中,得到行動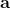,共同輸入給環境。環境通過某些轉移概率函數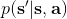(一般我們假設這個是不知道的),得到新的狀態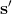,形成一個循環。
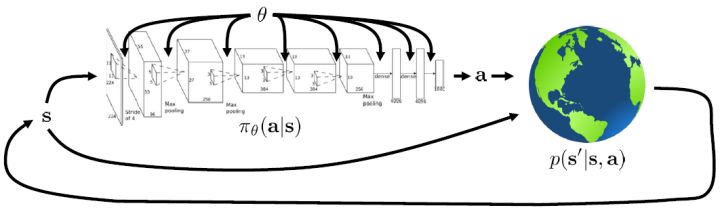
我們考慮一個有限長度的(狀態, 行動)軌跡 (trajectory),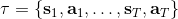。對于這樣的軌跡,發生的概率為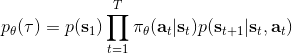。我們通常不能控制初始狀態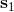,而后面每一期的行動都由當前狀態和策略函數決定,轉移概率具有 Markov 性,故可以表現為這樣乘積的形式。而我們想做的是,選出一組最優的神經網絡參數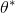,使得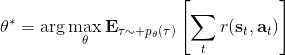,即最大化總收益函數的關于軌跡期望。收益可以非常稀疏,如打一場籃球賽,如果最后時點贏了那么得到收益為 1,此外其他時間的收益都是 0;如果想減少自動駕駛中車禍的數量,也可以設置成一旦發生車禍就給予-1 的收益;總體來說,如何使用收益函數是非常靈活的。
值得一提的是,這個發生概率其實本質上是一個關于增廣的空間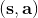的 Markov 鏈。具體來說,可以表示為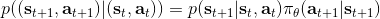。
對于有限長度的軌跡問題,事實上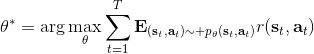,只需要關注這個 Markov 鏈在一個時間點上的邊際分布就可以了。對于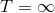的無限長度的問題,由于我們之前已經把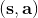的 Markov 鏈化,因此有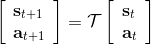,進一步步轉移算子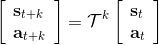。我們考慮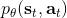是否逐漸收斂到一個平穩分布 (stationary distribution):之所以說平穩分布,是因為經過一次狀態轉移后,分布不發生變化,這樣的分布也就是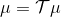,也就是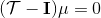,或者說以矩陣特征向量的角度考慮,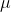是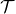特征值為 1 的特征向量。由于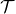是一個隨機矩陣,給定一些正則條件,這樣的向量總是存在的,此時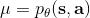是其平穩分布。對于無限長度的問題,我們也可以對目標函數進行平均,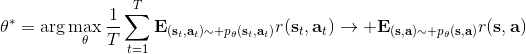,它將完全由平穩分布下的情形所控制。
在增強學習中,我們幾乎只關心期望,而不是個別的值,這是因為這給予了我們很好的數學性質。譬如說在盤山公路上開一輛車,如果正在運行那么收益函數為+1,如果掉下山崖則收益函數為-1。此時,我們的收益函數是不光滑的。假如說我們從非常復雜的系統中提取出了一個概率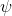,作為掉下的概率,此時如果我們關注期望的話,平穩分布下的收益函數的期望,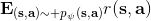則是關于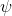光滑的!這一點非常重要,允許我們使用諸如基于梯度的算法來優化非光滑的目標(可能是非光滑的轉移,或者非光滑的收益函數等等導致)。
## 增強學習算法的一般步驟
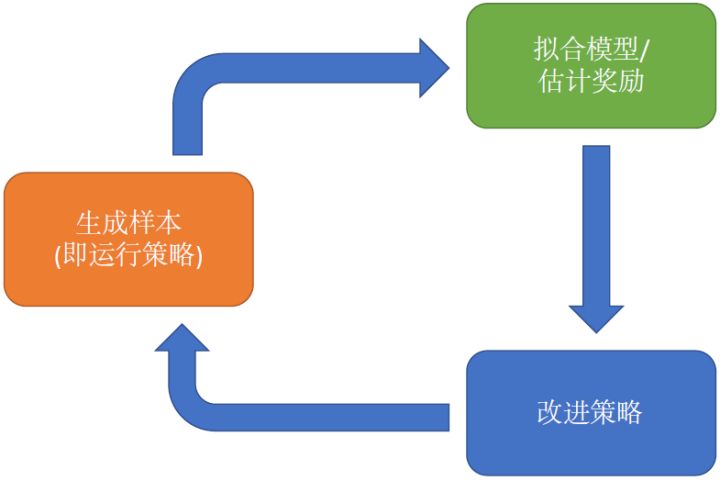
幾乎所有的增強學習算法都會由以上三部分組成,即便可能特定算法會退化掉其中的一部分。
1. 生成樣本。我們在現實世界(或者模擬器)中運行我們的策略,來收集軌跡樣本。有的時候,這個軌跡可以只是一個轉移,這樣就是一個很短的軌跡;也可以是完整的有始有終的一條。
2. 擬合模型/估計收益。對于策略學習算法,則這個部分就是策略評估 (policy evaluation);對于基于模型 (model-based) 的增強學習算法,那么就是模型擬合,等等。這個步驟中并不改變我們的行為,但我們想通過研究我們在第一步中得到的樣本來看發生了什么,當前的策略有多好,或者嘗試去分析物理環境等等。
3. 改進策略 (policy improvement)。根據之前的研究結果,改進策略,再投入到第一步的運行中去。
不同算法在不同步驟要做的事情也差異很大。在綠色方塊的第二步,策略梯度法只需要計算一個求和來得到收益,諸如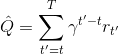; 基于值函數的方法諸如演員-評論家算法和 Q 學習算法則需要去擬合一個用深度神經網絡代表的函數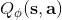;基于模型的方法則需要去估計轉移概率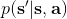。在藍色方塊的第三步,策略梯度法需要對神經網絡的參數進行一個梯度步的調整,諸如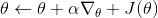;Q 學習法則需要找到一個使得 Q 函數最大的行動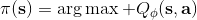;基于模型的方法則需要用諸如反向傳播梯度的方法去優化策略函數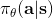。
哪些步驟昂貴,哪些步驟廉價,實際上取決于選取的算法和要處理的實際問題。就生成樣本而言,如果我們運行諸如汽車、機器人等,需要用到真實物理系統的話,我們只能以 1 倍速度實時收集數據(除非有了時間穿梭手段);當然如果我們有多個物理系統我們可能可以進行并行的數據收集。而如果我們使用諸如 MuJoCo 之類的模擬器,那么我們可以期待有 10000 倍速度的加速。因此取決于我們的具體問題,生成樣本的難度可能會是效果的主要限制因素,當然也可能微不足道。同樣,綠色方塊第二步策略梯度法計算求和很容易,而 Q 學習方法的擬合神經網絡則代價較高而且很難并行。但是,在藍色方塊第三步中,Q 學習方法對應的找到使得 Q 函數最大的行動卻非常容易,而基于模型的方法的反向傳播優化策略則相對很困難。

讓我們來考慮如上的有點像基于模型的增強學習中,用反向傳播來訓練增強學習模型的玩具例子。假設環境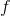是確定性的(非隨機),策略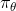用一個神經網絡表示,給定狀態,輸出一個行動。整體形式類似于一個 RNN,優化策略的方法是反向傳播收益函數的梯度。要做這件事情,我們要收集數據(第一步橙色方塊),也要更新模型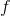,保證模型和實際發生狀態轉移情況一致(第二步綠色方塊)。前向傳播用于計算收益函數,也屬于第二步綠色方塊之中。唯一屬于第三步藍色方塊的是計算梯度并將其反向傳播。當然這個過程也是非常不足的,譬如只處理確定性的環境和策略,只處理連續的狀態和行動,且優化問題也是非常難以求解的。
## Q 函數與值函數
那么如何處理隨機系統呢?因為我們考慮的目標主要還是關于期望,因此條件期望成為一個非常有力的工具。我們想描述一個期望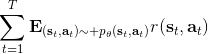,而這個期望則可以由一系列嵌套的條件期望所描述: 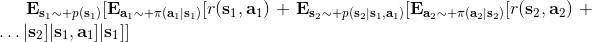 其中第一個狀態是服從于初始分布,在第一個期望內,我們要對第一個行動取期望,是服從于我們的策略的。第二個狀態是以第一個狀態和第一個行動為條件的,依次類推。而我們想做的事情,首先是找到一個非常好的**第一個行動**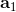。我們把中間的遞歸部分抽離出來,令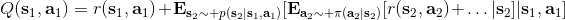 ,如果我們知道這樣一個函數,那么原來的問題就可以被簡寫為 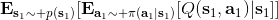 ,我們對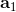的選擇的事實上就不依賴于其他的東西了。我們把這樣的函數稱為**Q 函數** (Q-function),表現為在狀態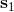下,選擇行動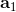所能帶來的收益函數的條件期望。如果 Q 函數已知,那么改進策略將非常容易:我們只需要挑選一個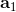,使得 Q 函數最大化就行了,即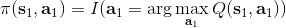。同樣也可以在其他步驟類似這樣做法。
那么我們給幾個重要的概念下定義。
> Q 函數: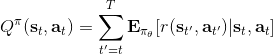,從時刻狀態為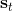起,執行行動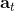,之后根據給定策略決策,未來總收益的條件期望。
> 值函數 (value function):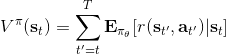,從時刻狀態為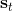起,根據給定策略決策,未來總收益的條件期望。
由于 Q 函數和值函數的特別關系,值函數也可以表示為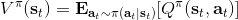。需要注意的是,這樣定義的函數的右上角都有個,指的是它都是關于某個特定的策略函數的。注意,經過這樣的標記后,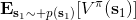正好是增強學習的目標函數。
這兩類函數之所以有價值,是因為如果我們已知這兩類函數,那么能夠很方便地做很多事情。譬如:
* 如果我們現在有一個策略,且我們知道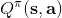,那么我們可以構造一個新的策略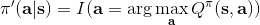,這個策略至少和一樣好(且可能更好),是因為這一個策略最大化未來的收益。這一點與當前的是什么沒有關系。
* 我們可以增加“好的行動”發生的概率。注意到,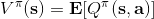代表了在策略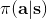下的行動平均水平,所以如果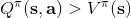,就能說明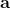是高于平均水平的行動。那么我們便可以改動策略,使得這樣的行動發生的概率上升。
## 增強學習算法的權衡
回顧我們的目標,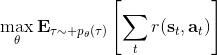。在增強學習中,有以下幾類基本算法:
* **策略梯度法**:這類算法直接對目標函數關于參數求梯度。本質是一階最優化算法,求解無約束優化問題的通用方法。
* **值函數方法**:這類方法嘗試去近似估計**最優策略下的**值函數或 Q 函數,而并不揣測策略函數是什么。注意此時策略并需要不顯式表達出來,只需要選擇使得 Q 函數最大的行動即可(或者值函數類似于動態規劃中的手段)。
* **演員-評論家 (actor-critic) 方法**:這類方法嘗試去近似估計**當前策略下的**值函數或 Q 函數,并用這個信息求一個策略的梯度,改進當前的策略。所以也可以看作是策略梯度法和值函數方法的一個混合體。
* **基于模型 (model-based) 的增強學習方法**與上面的幾類都不同。它需要去**估計轉移概率**來作為模型,描述物理現象或者其他的系統動態。有了模型以后,可以做很多事情。譬如可以做行動的安排(不需要顯式的策略),可以去計算梯度改進策略,也可以結合一些模擬或使用動態規劃來進行無模型訓練。
我們來看基于模型的方法如何分解成三個方塊的步驟。在第二步綠色方塊中,顯然它需要去學習轉移概率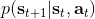。在第三步藍色方塊中,改進策略可能有很多不同的選項。
1. 有了模型,我們可以拋開策略,直接使用模型去模擬安排。對于連續問題,可以用一些軌跡優化和最優控制的方法;對于離散問題,可以使用譬如蒙特卡洛樹搜索 (Monte Carlo Tree Search, MCTS) 的方法來對離散的行動空間進行計劃。
2. 我們可以將梯度反向傳播回策略之中,這通常需要一些技巧來使得它能真正起效。
3. 也可以使用模型來學習值函數和 Q 函數。如果運氣好,在一個空間足夠小的離散環境下可以使用動態規劃,一個更流行的方法是用這個模型生成綜合的“經驗”,然后進行無模型訓練(如 Dyna 算法)。
值函數類算法在綠色方塊中做的是去擬合一個值函數或者 Q 函數,而藍色方塊的策略改進部分則沒有顯式的過程,策略僅僅是去選一個行動使得 Q 函數最大。直接的策略梯度法的綠色方塊做的是計算收益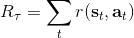,藍色方塊做的是計算一個梯度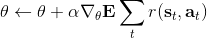,這一點做起來是非常神奇的。演員-評論家算法是兩者的混合,因此這兩個它都做一點:綠色方塊它擬合值函數或者 Q 函數,并用這些函數去評估收益,藍色方塊還是跟策略梯度法做的一樣,走一個梯度步。
為什么我們需要那么多中不同的強化學習算法?在強化學習中,沒有一個單純的算法在所有情形下都表現得很好,因此算法之間需要有很多**權衡點**:首先是**樣本效率** (sample efficiency),就是要有一個不錯的策略效果需要橙色方塊收集多少數據;其次是**穩定性**和**易用性**,主要體現在選擇超參數和學習率等調參的難度,在不同的算法中這個難度可以差別很大。不同的算法也有不同的前提假設:有些算法假設系統動態和策略是隨機的,有些是確定性的;有些連續有些離散;有些有限期 (episodic) 有些無限期。還有一個很現實的問題是,在不同的問題下,要去表示一個東西的難度是不一樣的,譬如有些問題去表示一個策略是比較容易的,而有些問題去擬合模型更容易:因此方法的選擇對于特定問題很有關系。
在橙色方塊中,我們主要關心樣本效率。樣本效率意味著我們要得到一個好的策略,需要收集的樣本數量:這決定了我們需要在模擬器或者真實世界運行我們的策略多久才能讓它到一個穩定狀態。最重要的一點是,我們的算法是否是**離線** (off-policy) 的。離線的意義是我們可以在不用現在的策略去生成新樣本的情況下,就能改進我們的策略。其實就是能夠使用其他策略生成過的歷史遺留數據來使得現在的策略更優。**在線** (on-policy) 算法指的是每次策略被更改,即便只改動了一點點,我們也需要去生成新的樣本。在線算法用于梯度法通常會有一些問題,因為梯度算法經常會走梯度步,些許調整策略就得生成大量樣本。
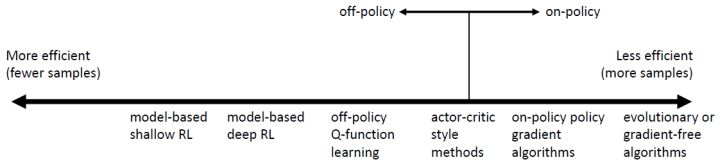
上圖是一個算法間的樣本效率比較圖(是非常粗糙的,具體效果如何其實非常依賴于特定的問題)。以豎線為分界點,離線算法有較高的樣本效率,在線算法則較低。如最右側的進化算法,甚至都不使用梯度信息,只是把參數當成一些黑盒子,使用一些不可微函數的方法來作用在參數上:它們需要最多的樣本,因為它們沒有利用梯度信息。在線的策略梯度法也是在線算法,每次策略更改后需要重新收集數據,但它利用了梯度信息所以會高效一些。演員-評論家算法在兩側都可以有。離線的 Q 學習法,通常學習 Q 函數可以是完全離線的,樣本效率較高。基于模型的深度增強學習方法更有效,更極端的基于模型的淺度增強學習方法不去擬合神經網絡,使用一些更加高效的貝葉斯方法,但通常會引入一些很強的假設來作用于一些特定的問題。
然而樣本效率低并不代表這個方法是“壞”的。為什么我們會用一個樣本效率較低的算法?答案有很多,其中一個答案是現實時間并不與樣本效率相同。如果你有一個很快的模擬器,可能你根本不關心收集樣本所需要的時間;我們關心的是真實發生的時間消耗,優化我們的策略需要花多少時間,其中包含模擬時間和優化神經網絡的時間。有一些時候,將進化算法進行并行是最快的;在線的策略梯度法有時候也很容易做并行,也相當快,如果模擬是相當廉價的。相對的,基于模型的增強學習,即便它們充分利用數據,真實時間也相當慢,因為可能去擬合了很多個不同的神經網絡模型(轉移概率、策略),需要反向傳播很長的序列,有可能更昂貴。
關于穩定性和易用性,我們需要問一系列問題。首先是這樣的算法收斂么?如果收斂的話,收斂到什么地方?它在所有情況都收斂么?至于這為什么會成為問題,我們在監督學習中訓練巨大的模型,在現在技術下通常收斂得不錯。這是因為,在監督學習中,我們采用的基本上都是某種意義上的梯度下降法,而這樣的算法分析起來是相對簡單的,大家對它比較了解,也有很好的讓它收斂的辦法。而增強學習通常不使用梯度下降法,譬如 Q 學習法本質上是一個不動點迭代的過程,在一定條件下收斂;基于模型的增強學習,當我們在優化轉移模型時,它并不優化期望收益函數;策略梯度法是梯度方法,比較好用,但它的樣本效率比前兩者都要低。這些都是權衡,更聰明的算法可能更難用。
很多方法都有缺點,如值函數擬合方法,一般來說我們優化的是它對期望收益函數擬合得多好,但是把這個函數擬合得好并不意味著有一個很好的策略,減少預測誤差不見得最大化期望收益;在更壞的情況下,它什么都不優化,事實上,很多流行的值函數擬合方法在非線性的問題中并不能保證收斂性。基于模型的增強學習方法,立足于減少模型預測誤差,這是一個監督學習問題,一般會收斂;但這不意味著一個更好的模型能得到一個更好的策略。策略梯度法是僅有的關于目標函數使用梯度上升方法的,但也有一些缺點。
不同的方法由不同的假設。**完全的可見性**常常被值函數擬合類方法所假設,可以通過加入 RNN 的方法來緩解;**有限期**被純策略梯度法和一些基于模型的增強學習算法假設,這些方法不用去訓練值函數,對于有些機器人問題中確實是如此的(機器人拼樂高的例子);**連續性和光滑性**也是一些連續的值函數學習法和一些基于模型的增強學習算法(如淺層學習)所假設的,如果知道連續性,那么可以有一些技巧可做。要看問題具體滿足什么樣的假設,然后選取合適的算法。
值函數擬合方法有 Q 學習(深度 Q 網絡 DQN)、時間差分學習、擬合值迭代等,策略梯度法有 REINFORCE、自然策略梯度 (Natural Policy Gradient)、信賴域策略優化 (Trust Region Policy Optimization, TRPO)等,演員-評論家算法如 A3C、基于模型的增強學習算法如 Dyna 和引導策略搜索 (Guided Policy Search)等。
基于值函數方法的一個最經典的例子是使用 DQN 來打 Atari 游戲 (Mnih et al., 2013),使用卷積神經網絡來估計 Q 函數,學習的不是策略而是 Q 函數來預測未來的收益,并由此得到策略。Levine et al. (2016) 使用引導策略搜索 (GPS) 這樣的基于模型的增強學習方法來做基于像素圖像的機器人控制,擬合局部模型。Schulman et al. (2016) 使用加入值函數近似的策略梯度法 (TRPO) 來訓練小人模擬行走,走的時間逐漸變長。
