# (12) 逆增強學習
> 作者:[謝天](https://www.zhihu.com/people/xie-tian-55-77)
>
> 來源:[POST 館](https://zhuanlan.zhihu.com/c_150977189)
## 逆增強學習問題
迄今為止,我們做增強學習的時候都是對特定任務來手工定義收益函數的思路來完成任務。但是要真正實現稍微智能化的目標,我們更傾向于在不知道具體任務的時候,去觀察專家的行為然后推測他想干什么,也就是學習他的收益函數,然后再使用增強學習算法,這也稱為逆增強學習。在這里,我們將利用[上一篇](https://zhuanlan.zhihu.com/p/33534968)中講到的近似最優模型來達成這一學習目的。
收益函數的來源有很多。對于很多(有得分的)游戲來說,我們只是需要讓游戲的得分最大化就行了,收益函數是非常自然的。但是在很多現實世界中的問題中并不是那么簡單,而且原因千奇百怪。比如說有個機器人任務,想讓它拿起壺往杯子里倒水。要讓機器人模仿這個動作倒是不困難,但是如何鑒別水是不是真的倒進去了可能會非常困難(因為機器人并不是拿來喝),手工設置一個這樣的函數也是很煩的。比如說有個對話系統,跟人類交流來做技術支持解決問題,也需要關注用戶是否滿意這樣的互動,體驗好不好,這個其實也很難具體評價。對于自動駕駛,即便是有很多成文條例,但也有很多隱性的不成文的規則、公約和常識要去遵守,做一個文明司機,這個在人工設置的收益函數里面也很難刻畫。這些的特點是,相對手工來做一個收益函數,由人來介紹怎么做會比較容易。
在之前,我們也介紹過[模仿學習](https://zhuanlan.zhihu.com/p/32575824)(行為克隆),也就是直接模仿專家的行為而不需要理解其中原因。這也是實踐中的一個備選項,在有些時候也能滿足要求,尤其是觀測數據很多,且域漂移 (domain shift) 比較小的情況,但不見得能適應廣泛的情況。同時,模仿學習只能捕捉到臺面上的動作:盲目模仿所有的環節,不管重要不重要,如果在教學過程中出現一點錯誤,就會被學進系統中。此外,學習者和教學者可能能力不同,如人倒一杯水的過程可能和機器人的過程不同,如果機器人能學習到目標則它可以自適應做得更好。
從示范中推測收益函數的問題又被稱為**逆最優控制問題** (Inverse Optimal Control, IOC) 或者**逆增強學習問題** (Inverse Reinforcement Learning, IRL) (Kalman, 1964; Ng and Russell, 2000)。在“正”增強學習問題中,我們得到的是狀態空間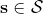,決策空間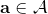,部分基于模型的問題還會給定系統轉移動態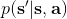,以及收益函數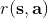:通過這些去求一個最優策略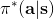。在逆增強學習問題中,我們同樣有狀態空間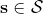,決策空間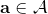,(或有的)系統轉移動態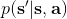,和很多從最優策略下的軌跡分布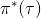中抽取出來的軌跡樣本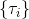:從中學習出一個參數化的收益函數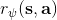,其中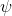是參數,再使用它來學習最優策略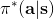。參數化的收益函數簡單形式可以是線性的,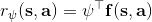,參數是權重向量,對若干個特征函數做一個加權線性組合;也可以是一個復雜的神經網絡。我們先討論線性的,再討論神經網絡。
逆增強學習的主要挑戰是,這個問題可能是定義不足的 (underdefined),因為我們可能已經對這個世界非常了解了,有很多先驗知識,但是事實上機器學習算法啥都不知道:比如一個東西向右移動了,可能是因為它喜歡向右移動,也可能是因為它喜歡的東西在右邊,或者其他什么原因,我們有很多很多選擇去解釋它,答案并不唯一而且是非常模糊的。同樣,我們很難去評判已經學到的收益函數。因為在逆增強學習問題中,我們要嘗試去改進收益函數,然而去評估收益函數的時候,我們要求解類似梯度的東西,這其實是正增強學習問題要做的事情,因此有點類似于正增強學習是逆增強學習內循環中的子問題,在樣本使用和計算上都很困難。實踐中,(人類)專家指導很可能不是精確最優的,這點在[上一篇](https://zhuanlan.zhihu.com/p/33534968)中已經有所討論,這個也造成困難。
一個早期的逆增強學習算法叫做**特征匹配逆增強學習** (Feature matching IRL),可以給我們一些啟發。這里先假定收益函數是若干特征函數的線性組合,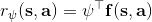。如果這些特征選得比較好,我們只需要選權重的話,我們就會考慮去匹配最優策略下的期望。具體來說,如果對于一個收益函數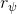,最優策略為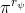,那么我們就希望去找到一組參數,使得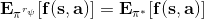,后者是未知的最優專家策略。左邊是邊緣化的期望,或者我們就直接運行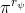,然后抽樣估計特征的期望。最優策略下特征的期望是要用專家給出的樣本來算的。事實上,參數并不是唯一的,我們可以從支持向量機 (SVM) 中借鑒最大間隔 (maximum margin) 原理來得到一個比較靠譜的解,如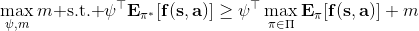,也就是找一個分割超平面把最優解下的期望收益和策略簇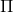內其他所有策略的期望收益相區分開,并且使得間隔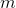最大。這個問題與原問題不同,只是嘗試去這么做。然而不難發現,如果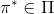,那么最優解落在分割超平面上,這個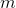總是 0,這個間隔就不起效果了。因此,可能這樣一刀切的間隔是不好的,我們有必要去體現策略不同下期望收益和專家策略有差異(專家策略就應該間距為 0),使得和專家策略相差得越多,策略越糟糕。定義兩個策略的距離為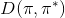,那么使用一個與 SVM 類似的技巧,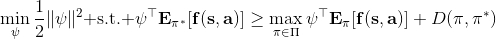。距離可以定義為兩個策略的期望特征的差異。整體來說,這個方法還是問題多多。首先,為了解決不唯一性,做最大間隔的方法看上去不能說不奇怪,**很難說明為什么間距大就代表收益大**,有點隨便。正如很多分類問題根本不是線性可分的一樣,我個人看到這個模型時想到的第一個問題這邊也提到了,**如果專家的策略不是最優的**,可能這個最優化問題根本就無解。如果要強行處理的話,可以通過增加一些帶懲罰的松弛變量來某種程度上緩解這個問題(這也是 SVM 里面的思路了),但這樣做還是很隨意,對專家的非最優行為并沒有清晰的建模,解釋并不能令人滿意。從計算上看,這個帶約束的優化問題也是非常復雜的,即便右邊這個 max 好求(_ 離散的話就是把約束拆開,如果右邊這個 max 問題是強對偶的那么就使用對偶方法轉成 min,就變成了存在性問題 _),**很難應用擴展性好的**如基于隨機梯度等**方法推廣到復雜的非線性神經網絡**。關于這類比較古老的方法,可以參考 Abbeel and Ng (2004) 發表在 ICML 的"[Apprenticeship Learning via Inverse Reinforcement Learning](http://link.zhihu.com/?target=http%3A//robotics.stanford.edu/%7Eang/papers/icml04-apprentice.pdf)"和 Ratliff et al. (2006) 發表在 ICML 的"[Maximum Margin Planning](http://link.zhihu.com/?target=https%3A//www.ri.cmu.edu/pub_files/pub4/ratliff_nathan_2006_1/ratliff_nathan_2006_1.pdf)"。
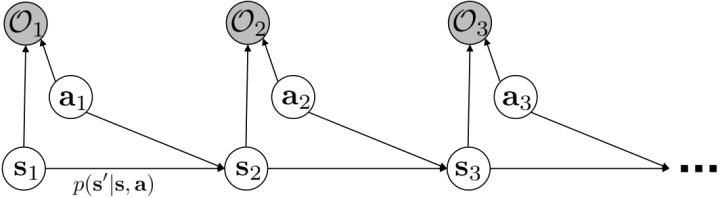
另一種想法的出發點是我們上一篇中講到的對人類次優行為使用概率圖模型建模,使用人類行為數據進行擬合,并推測出收益函數。繼續假設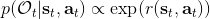,那么軌跡條件概率,正比于該軌跡實際的發生的概率乘上軌跡總收益的自然指數。根據我們的假設也不難看出,使用這個模型去做逆增強學習,本質上是去學習最優性變量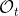的分布。我們把參數化的收益函數的參數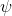放進來, 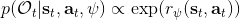,我們要學習的就是這個收益參數,且最優變量取決于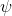;類似地,軌跡條件概率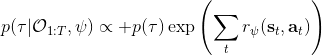。我們現有的數據是從最優策略下的軌跡分布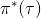中抽樣得到的軌跡樣本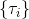。我們的學習可以做最大似然學習,也就是最大化對數似然函數: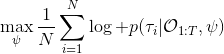。代入上面的條件概率,在這個最大化問題中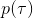是常數可以忽略;如果我們令軌跡收益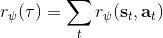,那么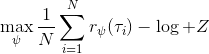,后面多了一項歸一化項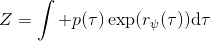,稱為 partition function。
要用梯度法優化參數,我們對這個對數似然函數關于參數求梯度,則根據鏈式法則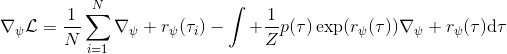。此時我們發現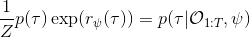,然后第一項也是期望的話,梯度就變成了一個很有趣的差了,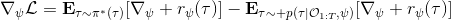,就是**專家策略下的軌跡分布下的收益關于參數的梯度**減去**當前收益函數對應的軟化最優策略下的軌跡分布下的收益關于參數的梯度**。第一塊是關于數據的,第二塊是從當前策略進行采樣。這樣的梯度類似于想要增加數據的概率,也要減少模型的概率。第一塊可以從專家樣本中估計,第二塊更多是一些推斷。
這里我們來討論第二塊期望怎么估計。把第二塊期望的軌跡收益按照時間拆開,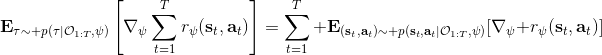。其中狀態行動分布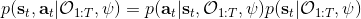。容易發現,前者就是我們上一篇中的策略,后者就是我們上一篇中的路徑概率,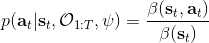,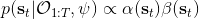。從而,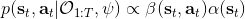,是后向信息和前向信息之積。令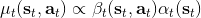作為在時刻狀態行動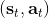訪問概率,那么第二塊的期望就可以寫成一個二重積分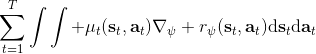,也可以簡寫為一個內積關系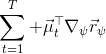。從而,我們填補了梯度公式,并得到了一個**最大熵逆增強學習** (MaxEnt IRL) 算法,循環執行以下步驟:
1. 給定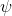,按照[上一篇](https://zhuanlan.zhihu.com/p/33534968)的方法求出對應的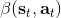和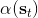。
2. 計算訪問概率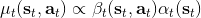。
3. 求解梯度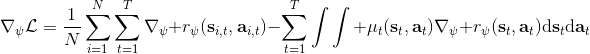。
4. 走一個梯度步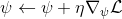。
這個是表格形式的最大熵逆增強學習的算法。該思想由 Ziebart et al. (2008) 發表在 AAAI 上的"[Maximum Entropy Inverse Reinforcement Learning](http://link.zhihu.com/?target=http%3A//www.aaai.org/Papers/AAAI/2008/AAAI08-227.pdf)"提出。之所以稱為最大熵,因為原理其實與上一篇中的熵正則化類似。我們可以說明如果我們的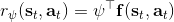是這樣的線性形式,那么其實這樣的算法是在最優化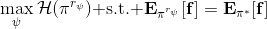,在保證學習的策略的特征和專家策略特征一致的基礎上使得策略的熵最大。
Ziebart et al. (2008) 發表在 AAAI 上的"[Maximum Entropy Inverse Reinforcement Learning](http://link.zhihu.com/?target=http%3A//www.aaai.org/Papers/AAAI/2008/AAAI08-227.pdf)"使用這一套方法用于道路網絡導航的 MDP 問題。根據人類駕駛員的駕駛路徑數據弄出一個 MDP 問題,狀態是在哪個交叉口,行動是在每個交叉口往哪兒走,因此狀態和行動空間都是離散的,雖然很大但是還是可以弄成一個大表的。他們的目標用于看這個人的駕車路線(GPS 等)來實時推測他想去的目的地;也用于找怎么樣的道路是代價更高/低的。他們使用線性代價函數,手工定制了路的類型(高速、主道、輔道)、速度、車道、轉向等特征。這說明在實際問題中這種表格形式也是有一定可行性的。
Wulfmeier et al. (2015) 的"[Maximum Entropy Deep Inverse Reinforcement Learning](http://link.zhihu.com/?target=https%3A//arxiv.org/abs/1507.04888)"及其應用,Wulfmeier et al. (2016) 發表在 IROS 上的"[Watch This: Scalable Cost-Function Learning for Path Planning in Urban Environments](http://link.zhihu.com/?target=https%3A//arxiv.org/abs/1607.02329)"也使用了類似的方法,還是使用了表格的形式,但是收益函數的設置更復雜,是一個**用神經網絡來對若干人工特征進行非線性組合**的形式,算法本質上和最大熵逆增強學習沒有區別,只是需要用神經網絡來計算收益,最后需要用梯度去更新的也是神經網絡。注意這個問題中狀態空間只是一個二維平面,行動空間是離散的方向。該方法的主要局限性是**仍然需要迭代求解 MDP**,而且還**需要假設系統動態是已知的**。

## 深度逆增強學習
前面我們提到了逆增強學習的經典處理方法最大熵逆增強學習法,是一個學習收益函數的概率框架。這類算法的表格實現可以推廣到收益函數是一個使用神經網絡組合特征的非線性形式,但是狀態空間和行動空間都得離散且比較小,因為求解梯度需要枚舉所有狀態-行動對,然后遞推求解幾個動態規劃問題:當狀態空間和行動空間大的時候就不能接受了。要處理深度逆增強學習問題,我們希望能適應**離散較大的甚至是連續的狀態行動空間**,而且我們需要對**系統動態未知**的情況下做有效的學習。在無模型的增強學習算法中我們使用了一些抽樣手段,在這里也希望能用上去。
假設我們不知道系統動態,但可以像普通增強學習一樣抽樣。注意到我們前面對數似然函數的梯度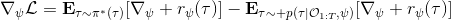,前者是專家樣本數據中得到的,后者是當前收益函數對應最優策略下的。要做到后者,一個比較直接的想法是使用任何最大熵增強學習方法學習出策略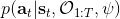,然后根據這個策略來采集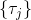。此時,就用專家樣本的結果減掉新抽樣本的結果,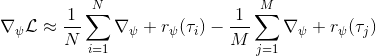來做無偏估計。然而事實上這種學習的做法是代價很高的,因為我們不假定有模型,所以可能要用無模型的增強學習算法,這將使得每一步都花掉很多很多時間。這里我們可以采用一些小技巧,我們可以不用完全地把對應的最優策略學出來,而只是**每次把策略改進一點點**,然后用這個不準確的策略去近似估計梯度。然而現在多出來一個問題,由于我們使用的策略是不正確的(不是最優的策略),因此我們的估計量將不再無偏。對于分布錯誤的問題,一個有力武器是重要性抽樣(我們在[策略梯度法部分](https://zhuanlan.zhihu.com/p/32652178)有過介紹),用其他分布下抽樣結果來得到正確分布下的無偏估計: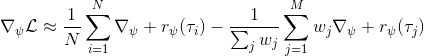,其中權重為 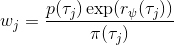,分子正比于收益的指數(_ 我覺得 Levine 教授原文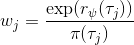少了一個概率,無法推導成下面的形式,或者是可能它的定義和我上面說的不同了,請評論區大神幫忙研究下 _),分母是現在分布的概率。因為我們前面會除以權重之和,就不需要關注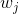歸一化的問題。使用之前策略梯度法一樣的展開,對同一條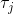,我們得到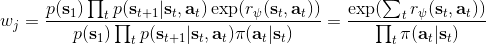這樣比較簡單的形式。進一步,最優下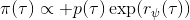,無需做 IS。每一步策略迭代都使我們更接近最優分布,因此事實上是在逐步改進的。
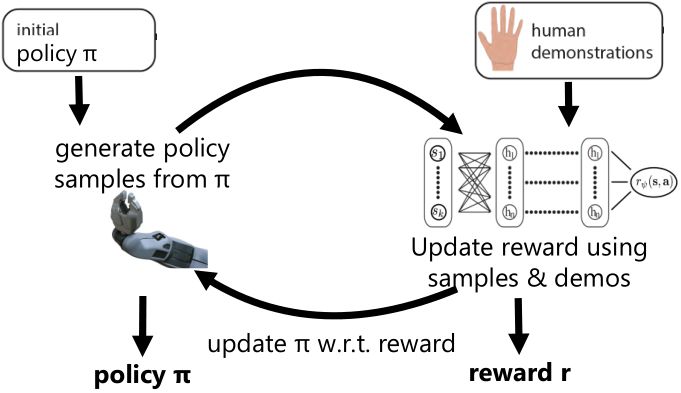
Finn et al. (2016) 發表在 ICML 上的文章"[Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization](http://link.zhihu.com/?target=http%3A//proceedings.mlr.press/v48/finn16.html)" 提出了**引導代價學習** (guided cost learning) 算法。需要給定一些人工的示范,然后算法從一個隨機的策略 開始,通過運行策略去生成隨機樣本,然后使用重要性抽樣和人工示范的方式來更新收益函數,根據收益函數稍微更新一下分布,然后下一階段的分布更好。最后,我們得到了最終的類似于專家的收益函數和對應的策略。事實上,這個文章中使用了基于模型的算法中的 GPS 算法來做策略更新,然而事實上任何改進策略的方法應當都是適用的。她們的文章中使用這樣的方法來“教”機器人完成人工動手的操作如擺放盤子和往目標杯子里倒水。這項工作相對更早期的逆增強學習算法,如 Kalakrishnan et al. (2013) "[Learning Objective Functions for Manipulation](http://link.zhihu.com/?target=https%3A//pdfs.semanticscholar.org/2732/9bc3b6c5a25aeadd3503d01064570b8a4a5c.pdf)" 的路徑積分 IRL (path integral IRL) 和 Boularias et al. (2011) "[Relative Entropy Inverse Reinforcement Learning](http://link.zhihu.com/?target=http%3A//proceedings.mlr.press/v15/boularias11a.html)" 的相對熵 IRL (relative entropy IRL) 的思路的改進主要在于,早期的算法雖然使用了重要性抽樣,但是沒有下面的那個箭頭,**沒有對策略進行更新**,也因此只得到收益函數而不產生最終的策略。但是早期算法如果在初始分布不錯的情況下(要求可能較高),也是可以得到一些不錯效果的。她們比較了手工設計的收益函數,相對熵 IRL 和 GCL 算法的效果。
事實上,很可能我們得到的收益函數不是一個很好的收益函數,但是往往這個策略函數反倒還可以。
## 與生成對抗網絡 (GAN) 的聯系
Goodfellow et al. (2014) 提出了生成對抗網絡 (Generative Adversarial Networks) 紅遍機器學習界。GAN 是一個生成模型,由兩個神經網絡組成,一個生成網絡,一個判別網絡。判別網絡用于輸入一張圖片,判斷是生成網絡生成的還是數據集里面真實的;而生成網絡則嘗試通過生成類似于數據集里圖片的方式“欺騙”判別網絡。IRL 也和 GAN 有一些相似之處,在我們最大似然估計中,嘗試去增加專家樣本的出現概率,減少當前策略樣本的出現概率。Finn et al. (2016) 發表于 NIPS 的文章 "[A Connection between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models](http://link.zhihu.com/?target=https%3A//arxiv.org/abs/1611.03852)" 進行一個對比,IRL 中的軌跡對應著 GAN 中的樣本,IRL 中的策略對應著 GAN 中的生成器(生成軌跡和樣本),而 IRL 收益函數則對應了 GAN 中的判別器。
事實上,可以令 GAN 的判別器取決于收益的方式來完成類似的目標。假設一個軌跡在專家(數據)分布下的概率是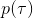,當前策略下的概率是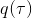,最優判別器應該為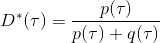。在 IRL 中,我們假設專家分布下的概率是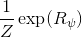,從而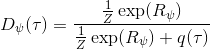。我們的判別器要最小化損失函數 (reward/discriminator optimizaion) 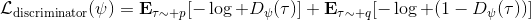,簡單說就是使得對應分布下的似然最大,這也是 IRL 的目標函數。我們的生成器要最小化損失函數 (policy/generator optimization) 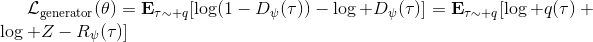,使得在當前分布下判別器盡可能分不清,這個結論和上篇中的熵正則化的增強學習的結論是很相似的。對于未知的系統動態,我們交替進行策略更新來最大化收益函數,然后進行收益更新來提高樣本收益且降低當前策略收益,也是類似這樣的過程。GCL 算法中,機器人嘗試的收益函數是要去最小化的,人類示范的收益函數是要去最大化的,去嘗試學習最大熵模型的分布。此外,一個有趣的交匯是,IRL 也和基于能量的模型 (energy-based models, EBM) 很有關系。
Ho and Ermon (2016) 發表在 NIPS 上的 "[Generative adversarial imitation learning](http://link.zhihu.com/?target=http%3A//papers.nips.cc/paper/6391-generative-adversarial-imitation-learning.pdf)" 一文將 GAN 和模仿學習聯系得更直接,就認為機器人的動作是負樣本,人類示范動作是正樣本,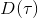是一個二分類器來表示軌跡是一個正樣本的概率,并使用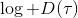作為收益函數。事實上它和 GCL 是差不多的,只是 GCL 的 D 是一個給定的函數形式,而這邊 D 是一個二分類器(因此該算法不是 IRL,但是非常像),總體來說兩個算法都是 GAN 的變種。
總體來說,IRL 是從專家示范中推斷出未知收益函數的手段, 一類比較好用的 IRL 算法是最大熵 IRL,相對類似超平面分割的方法來說可以消除歧義,也解決了人類示范可能不是最優這種情況。這類算法可以用表格動態規劃來實現,比較簡單有效,但是只有在狀態行動空間較小,動態已知的情況下才能應用。有一類微分最大熵 IRL 這邊沒有涉及,它適合于大而連續的空間,但需要知道系統動態。我們這里講的深度 IRL 使用的是基于樣本的最大熵 IRL,可以用于連續空間,可以不假設有模型存在,較廣泛。它的實現可以用 GCL 算法,該算法與 GAN 也有很深的淵源,和它緊密相關的還有生成對抗模仿學習算法(但不是 IRL,不推測收益函數)。
**注:水平有限,本文可能有較多謬誤之處,請評論區大神多多指教!**
