
### DNS域名解析負載均衡
DNS(Domain Name System)是因特網的一項服務,它作為域名和IP地址相互映射的一個分布式數據庫,能夠使人更方便的訪問互聯網。人們在通過瀏覽器訪問網站時只需要記住網站的域名即可,而不需要記住那些不太容易理解的IP地址。
在DNS系統中有一個比較重要的的資源類型叫做主機記錄也稱為A記錄,A記錄是用于名稱解析的重要記錄,它將特定的主機名映射到對應主機的IP地址上。
如果你有一個自己的域名,那么要想別人能訪問到你的網站,你需要到特定的DNS解析服務商的服務器上填寫A記錄,過一段時間后,別人就能通過你的域名訪問你的網站了
## Domain Name System
一種能進行主機名到IP地址轉換的目錄服務,這就是域名系統(Domain Name System),DNS協議運行在UDP之上,使用端口53
DNS采用分布式設計方案,DNS服務器分為四類:
* 根DNS服務器。
* 頂級域DNS服務器。這些服務器負責頂級域名,如com,org,net,edu和gov以及國家的頂級域名,如uk,fr,ca,jp。
* 權威DNS服務器。這些服務器記錄了主機名到IP地址的映射關系。
* 本地DNS服務器(local DNS server)
DNS查詢有兩種方式:
* 遞歸查詢
* 迭代查詢
從請求主機到本地DNS服務器的查詢是遞歸的,其余的查詢是迭代的
DNS解析過程:
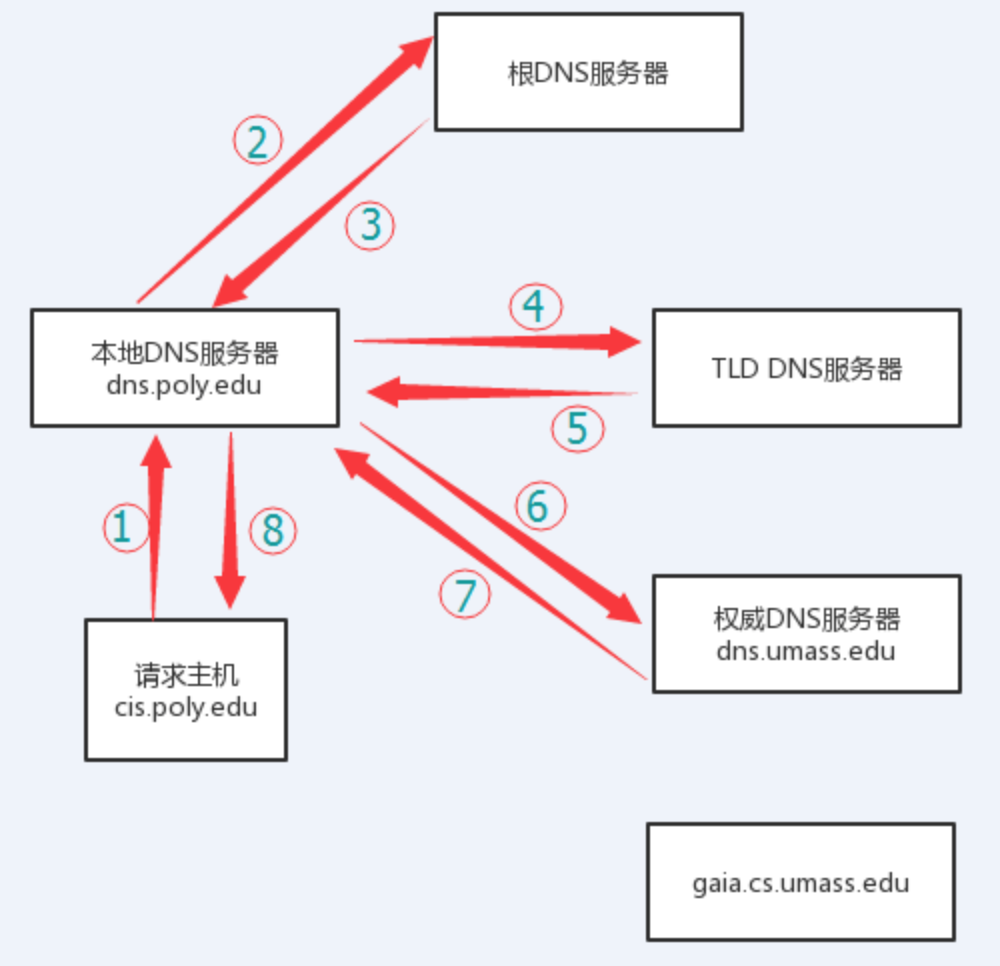
### 神奇的解釋權機制\(SOA\)
根服務器擁有一切域名的起始解釋權,但是如果你去問根服務器它是不會直接告訴你最終答案的。因為如果它要存儲所有的記錄,那它也太累了,這個負載和開銷是驚人的。那它會告訴你什么呢?它會告訴你應該去問誰,也就是它授權下一級服務器來解答你的問題。擬人化這個過程
> 1. 我: root, root 告訴我, segmentfault.com 怎么走?
> 2. root: 呵呵,你可以去問.com的dns服務器,地址是xxxxxx
> 3. 我: .com, .com 告訴我,segmentfault.com 怎么走?
> 4. .com: 呵呵,你可以去問segmentfault.com的dns服務器\(dnspod之類的\),地址是xxxxxx
> 5. 我: dnspod, dnspod 告訴我,segmentfault.com 怎么走?
> 6. dnspod: 拿著 xxxxxx,走你
###
### DNS負載均衡工作原理
利用DNS工作原理處理負載均衡的工作原理圖:

由上圖可以看出,在DNS服務器中應該配置了多個A記錄,如:
```
www.apusapp.com IN A 114.100.20.201;
www.apusapp.com IN A 114.100.20.202;
www.apusapp.com IN A 114.100.20.203;
```
每次域名解析請求都會根據對應的負載均衡算法計算出一個不同的IP地址并返回,這樣A記錄中配置多個服務器就可以構成一個集群,并可以實現負載均衡。上圖中,用戶請求www.apusapp.com,DNS根據A記錄和負載均衡算法計算得到一個IP地址114.100.20.203,并返回給瀏覽器,瀏覽器根據該IP地址,訪問真實的物理服務器114.100.20.203。所有這些操作對用戶來說都是透明的,用戶可能只知道www.apusapp.com這個域名
### 優缺點
**DNS域名解析負載均衡有如下優點:**
> 1. 將負載均衡的工作交給DNS,省去了網站管理維護負載均衡服務器的麻煩。
> 2. 技術實現比較靈活、方便,簡單易行,成本低,使用于大多數TCP/IP應用。
> 3. 對于部署在服務器上的應用來說不需要進行任何的代碼修改即可實現不同機器上的應用訪問。
> 4. 服務器可以位于互聯網的任意位置。
> 5. 同時許多DNS還支持基于地理位置的域名解析,即會將域名解析成距離用戶地理最近的一個服務器地址,這樣就可以加速用戶訪問,改善性能。
**DNS域名解析也存在如下缺點:**
> 1. 目前的DNS是多級解析的,每一級DNS都可能緩存A記錄,當某臺服務器下線之后,即使修改了A記錄,要使其生效也需要較長的時間,這段時間,DNS仍然會將域名解析到已下線的服務器上,最終導致用戶訪問失敗。
> 2. 不能夠按服務器的處理能力來分配負載。DNS負載均衡采用的是簡單的輪詢算法,不能區分服務器之間的差異,不能反映服務器當前運行狀態,所以負載均衡效果并不是太好。
> 3. 可能會造成額外的網絡問題。為了使本DNS服務器和其他DNS服務器及時交互,保證DNS數據及時更新,使地址能隨機分配,一般都要將DNS的刷新時間設置的較小,但太小將會使DNS流量大增造成額外的網絡問題。
## 有哪些DNS服務商支持負載均衡呢?
這是一種比較高級的服務,一般域名注冊商的dns服務器不會支持,目前我已知支持它的服務商有
1. [AWS Route 53](http://aws.amazon.com/cn/route53/)
2. [NSONE](https://nsone.net/)
3. [Dyn](http://dyn.com/)
4. [dnspod](https://dnspod.cn/)
5. 萬網——[https://wanwang.aliyun.com/](https://wanwang.aliyun.com/)
- 概述
- CAP理論
- BASE理論
- ACID
- 分布式系統相關技術
- 主流數據庫連接池
- 基礎
- 系統單點
- 負載均衡
- HTTP重定向負載均衡
- DNS域名解析負載均衡
- 反向代理負載均衡
- IP負載均衡
- 數據鏈路層負載均衡
- 負載均衡算法
- 輪詢法(Round Robin)
- 加權輪詢(Weight Round Robin)
- 隨機算法(Random)
- 源地址Hash算法
- 加權隨機法(Weight Random)
- 最小連接數法(Least Connections)
- 接入層負載均衡
- 軟件架構
- 性能
- 性能測試指標
- 響應時間
- 并發數
- 吞吐量
- 性能計數器
- 性能測試方法
- 性能測試報告
- 性能優化
- Web前端性能優化
- 應用服務器性能優化
- 可用性
- 服務降級
- 伸縮性
- 擴展性
- 事件驅動架構
- 安全性
- 信息加密技術
- 分布式系統概述
- 自動化
- 分布式唯一ID
- 冪等設計
- 分布式鎖
- 腦裂
- 一致性原理
- Paxos
- Zab
- Raft
- 分布式遠程服務調用
- RMI
- Spring RMI
- WebService
- SOA服務架構
- 微服務架構
- 微服務的九大特性
- 服務注冊和發現
- 解決方案及組件
- 分布式網關
- 注冊中心
- Zookeeper
- ZNode
- Watch接口
- 持久節點-配置中心實現原理
- 臨時節點-注冊中心
- Zookeeper選舉
- Zookeeper角色
- ZooKeeper工作原理
- 選主流程
- 同步流程
- Leader工作流程
- Follower工作流程
- 常見限流算法
- 計數器算法
- 漏桶算法
- 令牌桶算法
- 滑動窗口
- 計數器&滑動窗口
- 斷路器
- 大流量高并發高可用
- 高可用
- 高并發/大流量
- 分布式緩存系統
- 基本概念
- 緩存命中率
- 緩存最大元素
- 緩存回收策略
- 回收算法
- 緩存穿透與緩存雪崩
- CDN緩存
- 緩存分類
- memcached
- 客戶端路由原理
- 內存管理機制
- Redis
- Redis數據模型
- redisObject/Redis type/Redis encoding
- 命令的類型檢查和多態
- skiplist跳躍表
- 為什么使用跳躍表
- redis-內存管理機制
- Redis淘汰策略
- Redis持久化策略
- Redis并發競爭
- redis主從復制
- Redis集群實現方案
- Redis Cluster
- redis事務
- Redis-Sentinel
- Redis適用場景
- Redis客戶端
- redis rehash原理
- dict數據結構
- 觸發rehash的條件
- 漸進式rehash
- 漸進式rehash過程
- Redis多線程版本
- 緩存實際應用
- 堆緩存-Guava Cache
- 主要參數
- Caffeine
- Spring注解緩存
- 分布式存儲
- Database
- AUTOCOMMIT
- 臟讀&幻讀&不可重復讀
- 子查詢
- 連接
- 內連接
- 自連接
- 自然連接
- 外連接
- 組合查詢
- 隔離級別
- 數據庫范式
- 索引實現機制
- 數據庫拆分
- 表分區
- 分庫
- 分表
- MySQL
- MySQL基礎架構
- 鎖分類
- 排它鎖&獨占鎖
- 共享鎖
- 間隙鎖
- 表級鎖
- 存儲引擎
- 磁盤IO
- 磁盤結構圖
- 磁盤數據讀寫原理
- MySQL索引原理
- B+樹索引
- 局部性原理
- 索引數據結構
- 聯合索引
- 最左前綴匹配原則
- 建索引的幾大原則
- 數據文件和索引文件
- 執行計劃explain
- 常見問題
- 數據頁
- MYSQL單表存儲量計算
- 回表
- 索引覆蓋
- 索引下推
- 頁分裂和頁合并
- InnoDB
- innodb索引
- Innodb引擎的底層實現
- MyISAM
- MyISAM引擎的底層實現
- MVCC
- Next-Key Locks
- MySQL索引類型
- MYSQL復制
- 主從復制
- 讀寫分離
- MySQL Dual-Master
- 分庫分表實現方案
- MySQL事務實現原理
- MYSQL調優
- 性能優化
- HBase
- 不停機分庫分表遷移
- RDBMS&NoSQL
- 分布式事務
- 協議或事務模型
- X/Open XA協議
- 分布式事務編程接口規范JTA
- TCC模型
- 解決方案
- 兩階段提交2PC
- 三階段提交3PC
- Seata
- 分布式事務Seata產品模塊
- AT模式
- TCC模式
- Saga模式
- XA模式
- 基于消息中間件的最終一致性事務方案
- 消息隊列
- AMQP
- JMS
- ActiveMQ
- RabbitMQ
- RocketMQ
- RocketMQ基本概念
- 主要特性
- 分區順序消息
- 全局順序消息
- 消息可靠性
- 定時消息
- 消息重試
- 死信隊列
- 分布式事務消息
- RocketMQ架構
- Producer
- Consumer
- NameServer
- Broker
- RocketMQ設計
- 消息存儲
- 頁緩存與內存映射
- 消息刷盤
- 通信機制
- console控制臺
- RocketMQ部署架構
- Kafka
- Pulsar
- MQ消息重復消費與丟失
- 主流消息隊列比較
- 分布式調度系統
- 分布式搜索
- 分布式計算
- 架構案例
- 秒殺業務
- 秒殺整體架構
- 常見的監控系統
- 小米手機搶購秒殺方案
- 架構師領導藝術
- 架構師箴言
- 技術leader核心職責
- WEB服務器
- Servlet
- Servlet實現
- Servlet生命周期
- Servlet容器工作模式
- Servlet工作原理
- servlet線程安全
- CGI&FastCGI
- CGI
- FastCGI
- FastCGI與CGI特點
- CGI與Servlet比較
- HTTP Server
- Nginx
- Apache
- Nginx與Apache比較
- Application Server
- Tomcat
- Tomcat總體架構
- Connector
- 連接器核心功能
- ProtocolHandler
- EndPoint
- Processor
- Adapter
- Container
- 請求定位Servlet的過程
- Lifecycle生命周期
- Tomcat模塊設計
- Tomcat實例
- Tomcat運行原理
- spring & servlet
- Tomcat啟動流程
- Tomcat支持的I/O模型
- Tomcat應用層協議
- Tomcat類加載機制
- Tomcat類加載器
- Tomcat類加載器層次
- Apache+Tomcat
- 序列化
- XML&JSON
- JSON
- JAVA原生序列化
- hessian
- 常見中間件
- Canal
- Databus
- ELK日志套件
- 數據庫連接池
- spring狀態機
- 常見解決方案
- 二維碼掃碼登錄原理
- 前沿技術
- Saas服務
- 服務網格(Service Mesh)
- 云原生
- 常見面試問題
- Redis持久化的幾種方式
- Redis的緩存失效策略
- 附錄
- 二將軍問題
- 常見問題定位步驟
- 如何快速熟悉新系統
- 制定技術方案套路
- NUMA陷阱