
### 請求定位Servlet的過程
一個請求是如何定位到讓哪個`Wrapper`的`Servlet`處理的?答案是,Tomcat 是用 Mapper 組件來完成這個任務的。
`Mapper`組件的功能就是將用戶請求的`URL`定位到一個`Servlet`,它的工作原理是:`Mapper`組件里保存了 Web 應用的配置信息,其實就是**容器組件與訪問路徑的映射關系**,比如`Host`容器里配置的域名、`Context`容器里的`Web`應用路徑,以及`Wrapper`容器里`Servlet`映射的路徑,你可以想象這些配置信息就是一個多層次的`Map`。
當一個請求到來時,`Mapper`組件通過解析請求 URL 里的域名和路徑,再到自己保存的 Map 里去查找,就能定位到一個`Servlet`。請你注意,一個請求 URL 最后只會定位到一個`Wrapper`容器,也就是一個`Servlet`
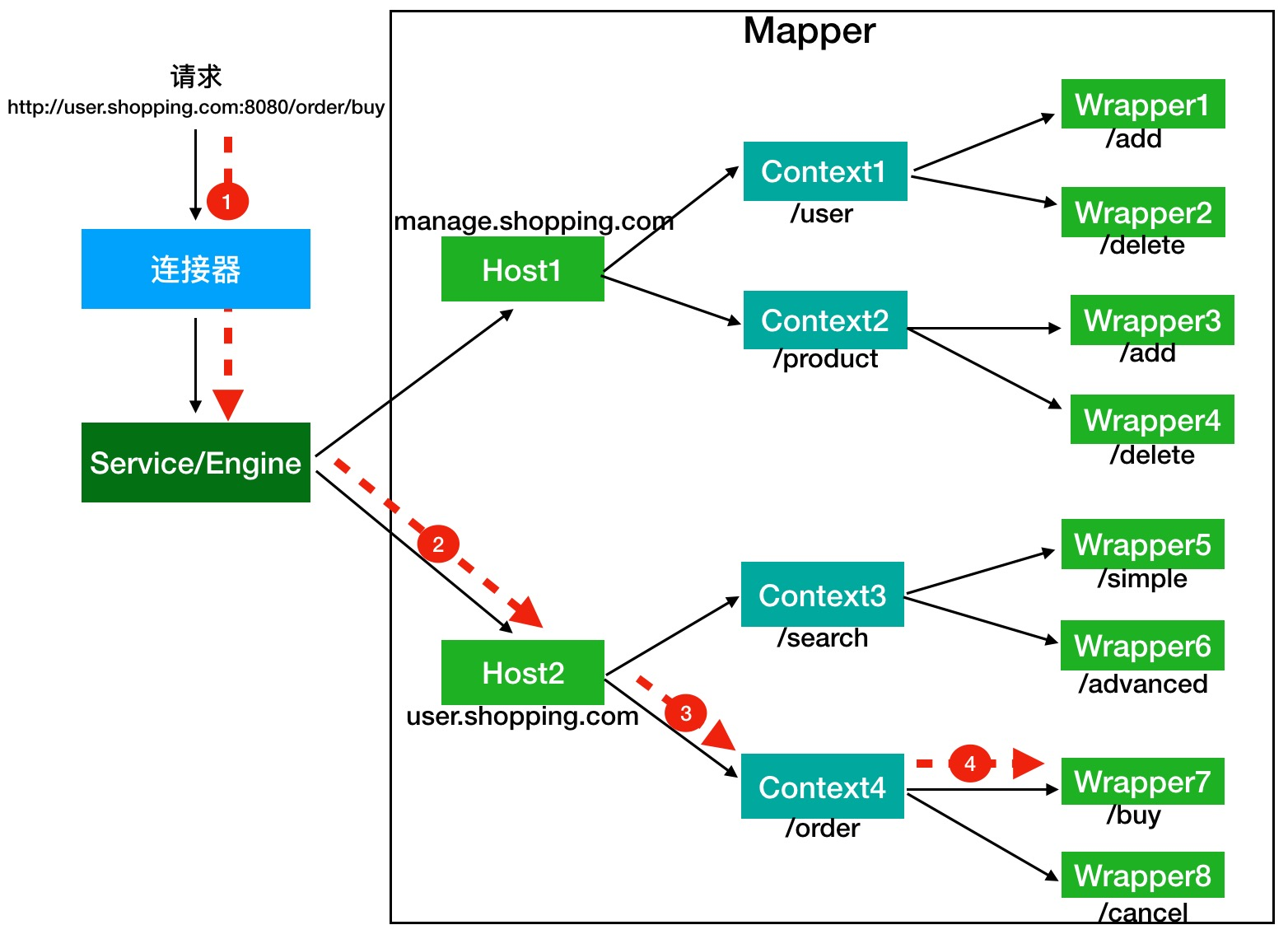
假如有用戶訪問一個 URL,比如圖中的`http://user.shopping.com:8080/order/buy`,Tomcat 如何將這個 URL 定位到一個 Servlet 呢?
1. **首先根據協議和端口號確定 Service 和 Engine**。Tomcat 默認的 HTTP 連接器監聽 8080 端口、默認的 AJP 連接器監聽 8009 端口。上面例子中的 URL 訪問的是 8080 端口,因此這個請求會被 HTTP 連接器接收,而一個連接器是屬于一個 Service 組件的,這樣 Service 組件就確定了。我們還知道一個 Service 組件里除了有多個連接器,還有一個容器組件,具體來說就是一個 Engine 容器,因此 Service 確定了也就意味著 Engine 也確定了。
2. **根據域名選定 Host。**Service 和 Engine 確定后,Mapper 組件通過 URL 中的域名去查找相應的 Host 容器,比如例子中的 URL 訪問的域名是`user.shopping.com`,因此 Mapper 會找到 Host2 這個容器。
3. **根據 URL 路徑找到 Context 組件。**Host 確定以后,Mapper 根據 URL 的路徑來匹配相應的 Web 應用的路徑,比如例子中訪問的是 /order,因此找到了 Context4 這個 Context 容器。
4. **根據 URL 路徑找到 Wrapper(Servlet)。**Context 確定后,Mapper 再根據 web.xml 中配置的 Servlet 映射路徑來找到具體的 Wrapper 和 Servlet
連接器中的 Adapter 會調用容器的 Service 方法來執行 Servlet,最先拿到請求的是 Engine 容器,Engine 容器對請求做一些處理后,會把請求傳給自己子容器 Host 繼續處理,依次類推,最后這個請求會傳給 Wrapper 容器,Wrapper 會調用最終的 Servlet 來處理。那么這個調用過程具體是怎么實現的呢?答案是使用 Pipeline-Valve 管道。
`Pipeline-Valve`是責任鏈模式,責任鏈模式是指在一個請求處理的過程中有很多處理者依次對請求進行處理,每個處理者負責做自己相應的處理,處理完之后將再調用下一個處理者繼續處理,Valve 表示一個處理點(也就是一個處理閥門),因此`invoke`方法就是來處理請求的。
~~~
public interface Valve {
public Valve getNext();
public void setNext(Valve valve);
public void invoke(Request request, Response response)
}
~~~
繼續看 Pipeline 接口
~~~
public interface Pipeline {
public void addValve(Valve valve);
public Valve getBasic();
public void setBasic(Valve valve);
public Valve getFirst();
}
~~~
`Pipeline`中有`addValve`方法。Pipeline 中維護了`Valve`鏈表,`Valve`可以插入到`Pipeline`中,對請求做某些處理。我們還發現 Pipeline 中沒有 invoke 方法,因為整個調用鏈的觸發是 Valve 來完成的,`Valve`完成自己的處理后,調用`getNext.invoke()`來觸發下一個 Valve 調用。
其實每個容器都有一個 Pipeline 對象,只要觸發了這個 Pipeline 的第一個 Valve,這個容器里`Pipeline`中的 Valve 就都會被調用到。但是,不同容器的 Pipeline 是怎么鏈式觸發的呢,比如 Engine 中 Pipeline 需要調用下層容器 Host 中的 Pipeline。
這是因為`Pipeline`中還有個`getBasic`方法。這個`BasicValve`處于`Valve`鏈表的末端,它是`Pipeline`中必不可少的一個`Valve`,負責調用下層容器的 Pipeline 里的第一個 Valve
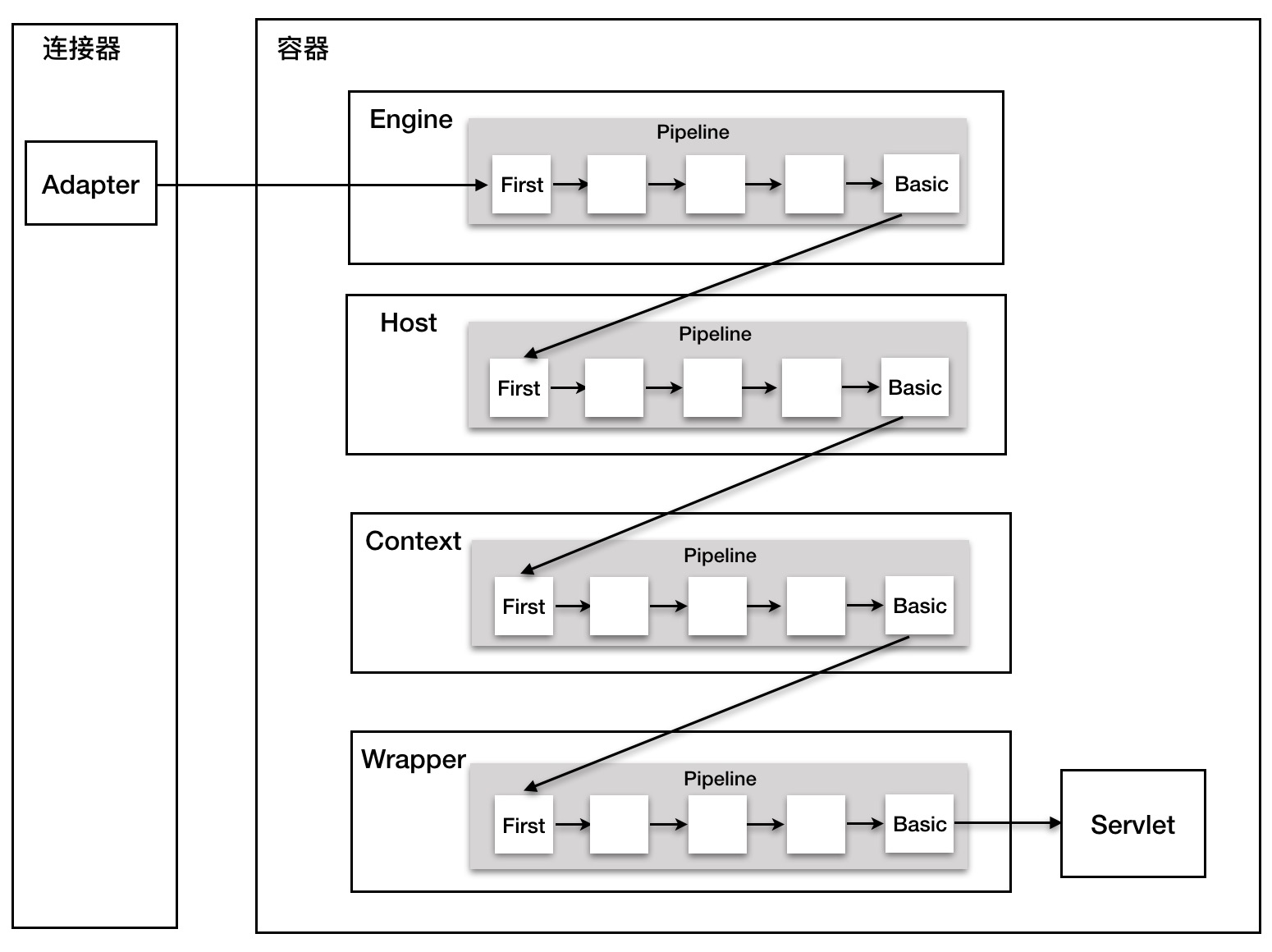
整個過程分是通過連接器中的`CoyoteAdapter`觸發,它會調用 Engine 的第一個 Valve:
```
@Override
public void service(org.apache.coyote.Request req, org.apache.coyote.Response res) {
// 省略其他代碼
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(
request, response);
...
}
```
Wrapper 容器的最后一個 Valve 會創建一個 Filter 鏈,并調用`doFilter()`方法,最終會調到`Servlet`的`service`方法。
前面我們不是講到了`Filter`,似乎也有相似的功能,那`Valve`和`Filter`有什么區別嗎?它們的區別是:
* `Valve`是`Tomcat`的私有機制,與 Tomcat 的基礎架構`API`是緊耦合的。`Servlet API`是公有的標準,所有的 Web 容器包括 Jetty 都支持 Filter 機制。
* 另一個重要的區別是`Valve`工作在 Web 容器級別,攔截所有應用的請求;而`Servlet Filter`工作在應用級別,只能攔截某個`Web`應用的所有請求。如果想做整個`Web`容器的攔截器,必須通過`Valve`來實現
- 概述
- CAP理論
- BASE理論
- ACID
- 分布式系統相關技術
- 主流數據庫連接池
- 基礎
- 系統單點
- 負載均衡
- HTTP重定向負載均衡
- DNS域名解析負載均衡
- 反向代理負載均衡
- IP負載均衡
- 數據鏈路層負載均衡
- 負載均衡算法
- 輪詢法(Round Robin)
- 加權輪詢(Weight Round Robin)
- 隨機算法(Random)
- 源地址Hash算法
- 加權隨機法(Weight Random)
- 最小連接數法(Least Connections)
- 接入層負載均衡
- 軟件架構
- 性能
- 性能測試指標
- 響應時間
- 并發數
- 吞吐量
- 性能計數器
- 性能測試方法
- 性能測試報告
- 性能優化
- Web前端性能優化
- 應用服務器性能優化
- 可用性
- 服務降級
- 伸縮性
- 擴展性
- 事件驅動架構
- 安全性
- 信息加密技術
- 分布式系統概述
- 自動化
- 分布式唯一ID
- 冪等設計
- 分布式鎖
- 腦裂
- 一致性原理
- Paxos
- Zab
- Raft
- 分布式遠程服務調用
- RMI
- Spring RMI
- WebService
- SOA服務架構
- 微服務架構
- 微服務的九大特性
- 服務注冊和發現
- 解決方案及組件
- 分布式網關
- 注冊中心
- Zookeeper
- ZNode
- Watch接口
- 持久節點-配置中心實現原理
- 臨時節點-注冊中心
- Zookeeper選舉
- Zookeeper角色
- ZooKeeper工作原理
- 選主流程
- 同步流程
- Leader工作流程
- Follower工作流程
- 常見限流算法
- 計數器算法
- 漏桶算法
- 令牌桶算法
- 滑動窗口
- 計數器&滑動窗口
- 斷路器
- 大流量高并發高可用
- 高可用
- 高并發/大流量
- 分布式緩存系統
- 基本概念
- 緩存命中率
- 緩存最大元素
- 緩存回收策略
- 回收算法
- 緩存穿透與緩存雪崩
- CDN緩存
- 緩存分類
- memcached
- 客戶端路由原理
- 內存管理機制
- Redis
- Redis數據模型
- redisObject/Redis type/Redis encoding
- 命令的類型檢查和多態
- skiplist跳躍表
- 為什么使用跳躍表
- redis-內存管理機制
- Redis淘汰策略
- Redis持久化策略
- Redis并發競爭
- redis主從復制
- Redis集群實現方案
- Redis Cluster
- redis事務
- Redis-Sentinel
- Redis適用場景
- Redis客戶端
- redis rehash原理
- dict數據結構
- 觸發rehash的條件
- 漸進式rehash
- 漸進式rehash過程
- Redis多線程版本
- 緩存實際應用
- 堆緩存-Guava Cache
- 主要參數
- Caffeine
- Spring注解緩存
- 分布式存儲
- Database
- AUTOCOMMIT
- 臟讀&幻讀&不可重復讀
- 子查詢
- 連接
- 內連接
- 自連接
- 自然連接
- 外連接
- 組合查詢
- 隔離級別
- 數據庫范式
- 索引實現機制
- 數據庫拆分
- 表分區
- 分庫
- 分表
- MySQL
- MySQL基礎架構
- 鎖分類
- 排它鎖&獨占鎖
- 共享鎖
- 間隙鎖
- 表級鎖
- 存儲引擎
- 磁盤IO
- 磁盤結構圖
- 磁盤數據讀寫原理
- MySQL索引原理
- B+樹索引
- 局部性原理
- 索引數據結構
- 聯合索引
- 最左前綴匹配原則
- 建索引的幾大原則
- 數據文件和索引文件
- 執行計劃explain
- 常見問題
- 數據頁
- MYSQL單表存儲量計算
- 回表
- 索引覆蓋
- 索引下推
- 頁分裂和頁合并
- InnoDB
- innodb索引
- Innodb引擎的底層實現
- MyISAM
- MyISAM引擎的底層實現
- MVCC
- Next-Key Locks
- MySQL索引類型
- MYSQL復制
- 主從復制
- 讀寫分離
- MySQL Dual-Master
- 分庫分表實現方案
- MySQL事務實現原理
- MYSQL調優
- 性能優化
- HBase
- 不停機分庫分表遷移
- RDBMS&NoSQL
- 分布式事務
- 協議或事務模型
- X/Open XA協議
- 分布式事務編程接口規范JTA
- TCC模型
- 解決方案
- 兩階段提交2PC
- 三階段提交3PC
- Seata
- 分布式事務Seata產品模塊
- AT模式
- TCC模式
- Saga模式
- XA模式
- 基于消息中間件的最終一致性事務方案
- 消息隊列
- AMQP
- JMS
- ActiveMQ
- RabbitMQ
- RocketMQ
- RocketMQ基本概念
- 主要特性
- 分區順序消息
- 全局順序消息
- 消息可靠性
- 定時消息
- 消息重試
- 死信隊列
- 分布式事務消息
- RocketMQ架構
- Producer
- Consumer
- NameServer
- Broker
- RocketMQ設計
- 消息存儲
- 頁緩存與內存映射
- 消息刷盤
- 通信機制
- console控制臺
- RocketMQ部署架構
- Kafka
- Pulsar
- MQ消息重復消費與丟失
- 主流消息隊列比較
- 分布式調度系統
- 分布式搜索
- 分布式計算
- 架構案例
- 秒殺業務
- 秒殺整體架構
- 常見的監控系統
- 小米手機搶購秒殺方案
- 架構師領導藝術
- 架構師箴言
- 技術leader核心職責
- WEB服務器
- Servlet
- Servlet實現
- Servlet生命周期
- Servlet容器工作模式
- Servlet工作原理
- servlet線程安全
- CGI&FastCGI
- CGI
- FastCGI
- FastCGI與CGI特點
- CGI與Servlet比較
- HTTP Server
- Nginx
- Apache
- Nginx與Apache比較
- Application Server
- Tomcat
- Tomcat總體架構
- Connector
- 連接器核心功能
- ProtocolHandler
- EndPoint
- Processor
- Adapter
- Container
- 請求定位Servlet的過程
- Lifecycle生命周期
- Tomcat模塊設計
- Tomcat實例
- Tomcat運行原理
- spring & servlet
- Tomcat啟動流程
- Tomcat支持的I/O模型
- Tomcat應用層協議
- Tomcat類加載機制
- Tomcat類加載器
- Tomcat類加載器層次
- Apache+Tomcat
- 序列化
- XML&JSON
- JSON
- JAVA原生序列化
- hessian
- 常見中間件
- Canal
- Databus
- ELK日志套件
- 數據庫連接池
- spring狀態機
- 常見解決方案
- 二維碼掃碼登錄原理
- 前沿技術
- Saas服務
- 服務網格(Service Mesh)
- 云原生
- 常見面試問題
- Redis持久化的幾種方式
- Redis的緩存失效策略
- 附錄
- 二將軍問題
- 常見問題定位步驟
- 如何快速熟悉新系統
- 制定技術方案套路
- NUMA陷阱