
[TOC]
## 簡介
HTTP1.0最早在網頁中使用是在1996年,那個時候只是使用一些較為簡單的網頁上和網絡請求上,而HTTP1.1則在1999年才開始廣泛應用于現在的各大瀏覽器網絡請求中,同時HTTP1.1也是當前使用最為廣泛的HTTP協議。 主要區別主要體現在:
1. **緩存處理**,在HTTP1.0中主要使用header里的If-Modified-Since,Expires來做為緩存判斷的標準,HTTP1.1則引入了更多的緩存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供選擇的緩存頭來控制緩存策略。
2. 帶寬優化及網絡連接的使用,HTTP1.0中,存在一些浪費帶寬的現象,例如客戶端只是需要某個對象的一部分,而服務器卻將整個對象送過來了,并且不支持斷點續傳功能,HTTP1.1則在請求頭引入了**range頭域**,它允許只請求資源的某個部分,即返回碼是206(Partial Content),這樣就方便了開發者自由的選擇以便于充分利用帶寬和連接。
3. 錯誤通知的管理,在HTTP1.1中新增了24個錯誤狀態響應碼,如409(Conflict)表示請求的資源與資源的當前狀態發生沖突;410(Gone)表示服務器上的某個資源被永久性的刪除。
4. Host頭處理,在HTTP1.0中認為每臺服務器都綁定一個唯一的IP地址,因此,請求消息中的URL并沒有傳遞主機名(hostname)。但隨著虛擬主機技術的發展,在一臺物理服務器上可以存在多個虛擬主機(Multi-homed Web Servers),并且它們共享一個IP地址。HTTP1.1的請求消息和響應消息都應支持**Host頭域**,且請求消息中如果沒有Host頭域會報告一個錯誤(400 Bad Request)。
5. **長連接,**HTTP 1.1支持長連接(PersistentConnection)和請求的流水線(Pipelining)處理,在一個TCP連接上可以傳送多個HTTP請求和響應,減少了建立和關閉連接的消耗和延遲,在HTTP1.1中默認開啟**Connection: keep-alive**,一定程度上彌補了HTTP1.0每次請求都要創建連接的缺點。
## 緩存
### 強制緩存(不對比緩存)與 對比緩存
**強制緩存:本地有就不對比 對比緩存,每次都對比**
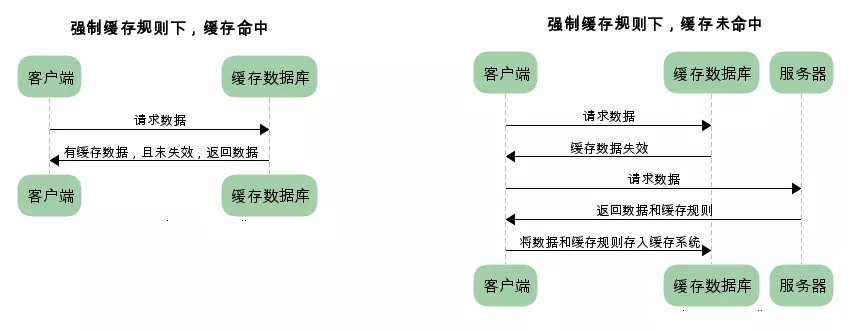
已存在緩存數據時,僅基于強制緩存,請求數據流程如下:
已存在緩存數據時,僅基于對比緩存,請求數據的流程如下:
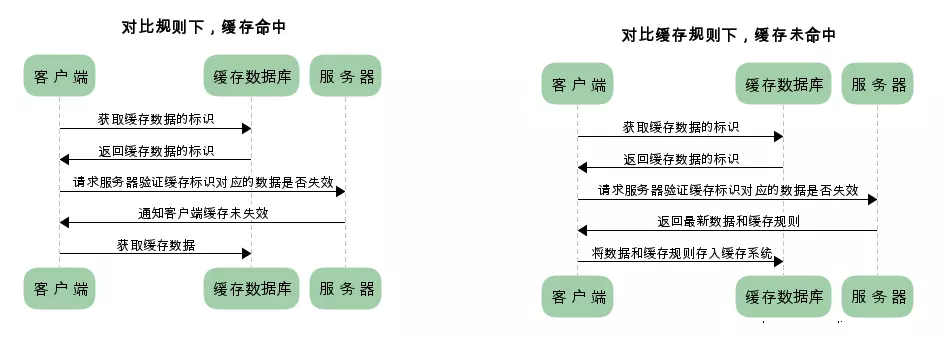
**緩存規則是包含在響應header里面的**
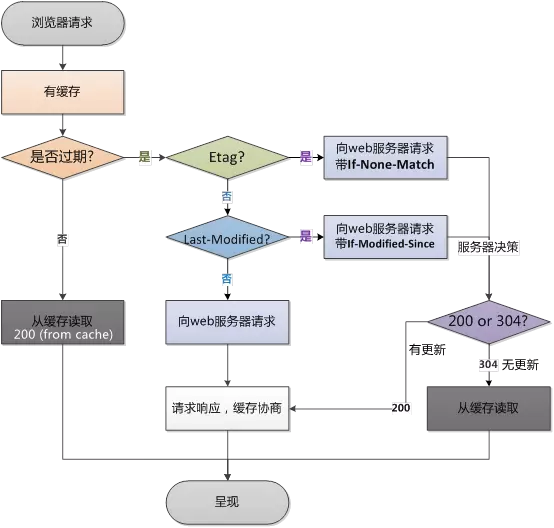
具體步驟如下:
### expires
在HTTP/1.0中expires的值圍服務器端返回的到期時間,即下一次請求時,請求時間小于服務器返回的到期時間,直接使用緩存數據,這里面有個問題,由于到期時間是服務器生成的,但是客戶端的時間可能和服務器有誤差,所以這就會導致誤差,**所以到了HTTP1.1基本上不適用expires了,使用Cache-Control替代了expires**
### Cache-Control
Cache-Control 是最重要的規則。常見的取值有private、public、no-cache、max-age、no-store、默認是private。
響應頭部意義Cache-Control:public響應被共有緩存,移動端無用Cache-Control:private響應被私有緩存,移動端無用Cache-Control:no-cache不緩存Cache-Control:no-store不緩存Cache-Control:max-age=6060秒之后緩存過期
舉個例子。入下圖:

圖中Cache-Control僅指定了max-age所以默認是private。緩存時間是31536000,也就是說365內的再次請求這條數據,都會直接獲取緩存數據庫中的數據,直接使用。
### Last-Modified/If-Modified-Since
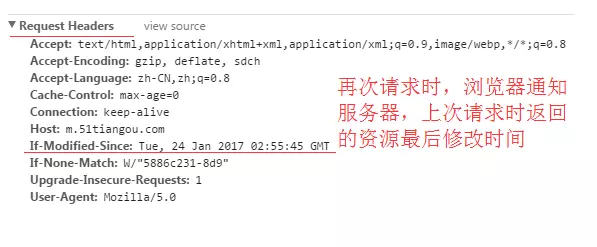
第一次請求時,服務器返回資源的**最后修改時間**,后面請求是帶上最后修改時間。
對比緩存,顧名思義,需要進行比較判斷是否可以使用緩存,客戶端第一次發起請求時,服務器會將緩存標志和數據一起返回給客戶端,客戶端當二者緩存至緩存數據庫中。再次其你去數據時,客戶端將備份的緩存標志發送給服務器,服務器根據標志來進行判斷,判斷成功后,返回304狀態碼,通知客戶端比較成功,可以使用緩存數據。
#### Last-Modified
是通過Last-Modified/If-Modified-Since來實現的,服務器在響應請求時,告訴瀏覽器資源的最后修改時間。

#### If-Modified-Since
再次請求服務器時,通過此字段通知服務器上次請求時,服務器返回最遠的最后修改時間。服務器收到請求后發現有If-Modified-Since則與被請求資源的最后修改時間進行對比。若資源的最后修改時間大于If-Modified-Since,說明資源又被改動過,則響應整個內容,返回狀態碼是200.如果資源的最后修改時間小于或者等于If-Modified-Since,說明資源沒有修改,則響應狀態碼為304,告訴客戶端繼續使用cache.
### ETag/If-None-Match(優先級高于Last-Modified/If-Modified-Since)
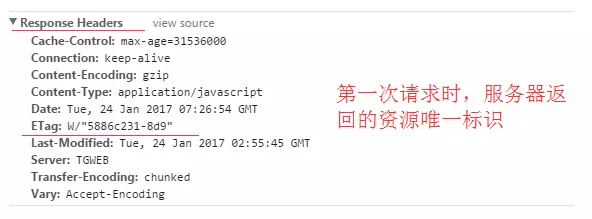
第一次請求時,服務器返回資源的**唯一標記位**,后面請求是帶上最后修改時間。
#### Etag
服務響應請求時,告訴客戶端當前資源在服務器的唯一標識(生成規則由服務器決定)
#### If-None-Match
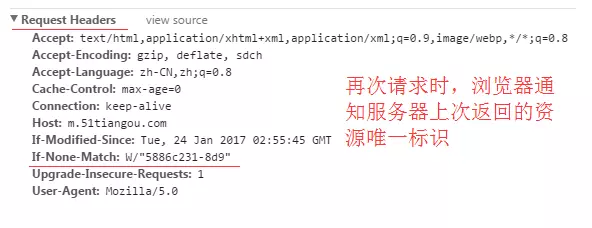
再次請求服務器時,通過此字段通知服務器客戶端緩存數據的唯一標識。服務器收到請求后發現有頭部If-None-Match則與被請求的資源的唯一標識進行對比,不同則說明資源被改過,則響應整個內容,返回狀態碼是200,相同則說明資源沒有被改動過,則響應狀態碼304,告知客戶端可以使用緩存
### Range
如果服務器能夠正常響應的話,服務器會返回?206 Partial Content?的狀態碼及說明.
如果不能處理這種Range的話,就會返回整個資源以及響應狀態碼為?200 OK?.(這個要注意,要分段下載時,要先判斷這個)
響應頭就是?HTTP/1.1 206 Partial Content
#### 請求頭格式
> Range: bytes=start-end
例如:
> Range: bytes=10- :第10個字節及最后個字節的數據
> Range: bytes=40-100 :第40個字節到第100個字節之間的數據.
注意,這個表示\[start,end\],即是包含請求頭的start及end字節的,所以,下一個請求,應該是上一個請求的\[end+1, nextEnd\]
#### 響應頭
* Content-Range
~~~
Content-Range: bytes 0-10/3103
~~~
這個表示,服務器響應了前(0-10)個字節的數據,該資源一共有(3103)個字節大小。
* Content-Type
~~~
Content-Type: image/png
~~~
表示這個資源的類型
* Content-Length
~~~
Content-Length: 11
~~~
表示這次服務器響應了11個字節的數據(0-10)
## Keep-Alive
[http協議里的keep-alive](https://www.jianshu.com/p/347416aafd3f)
[HTTP/1.1 持久連接](https://blog.csdn.net/duan15378766962/article/details/81073050)
我的理解:
1. http1.1協議里增加了 keepalive的支持, 并且默認開啟
2. http1.1開啟keepalive后,可以做到一個tcp上可以完成一個http請求后不會立刻關閉,而是存活一段時間。
3. 在這個時間內,有其他http請求也可以使用這個tcp連接,(但每次只有一個)
4. http2.0才真正做到了多個請求在一個tcp里并發。(每個請求分配一個requestID)
## 參考資料
[OKHttp源碼解析(七)--中階之緩存機制](https://www.jianshu.com/p/a68dc1ca6120)
[一文讀懂http緩存](https://www.jianshu.com/p/227cee9c8d15)
- Android
- 四大組件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介紹
- MessageQueue詳細
- 啟動流程
- 系統啟動流程
- 應用啟動流程
- Activity啟動流程
- View
- view繪制
- view事件傳遞
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大數據
- Binder小結
- Android組件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 遷移與修復
- Sqlite內核
- Sqlite優化v2
- sqlite索引
- sqlite之wal
- sqlite之鎖機制
- 網絡
- 基礎
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP進化圖
- HTTP小結
- 實踐
- 網絡優化
- Json
- ProtoBuffer
- 斷點續傳
- 性能
- 卡頓
- 卡頓監控
- ANR
- ANR監控
- 內存
- 內存問題與優化
- 圖片內存優化
- 線下內存監控
- 線上內存監控
- 啟動優化
- 死鎖監控
- 崩潰監控
- 包體積優化
- UI渲染優化
- UI常規優化
- I/O監控
- 電量監控
- 第三方框架
- 網絡框架
- Volley
- Okhttp
- 網絡框架n問
- OkHttp原理N問
- 設計模式
- EventBus
- Rxjava
- 圖片
- ImageWoker
- Gilde的優化
- APT
- 依賴注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 協程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 運行期Java-hook技術
- 編譯期hook
- ASM
- Transform增量編譯
- 運行期Native-hook技術
- 熱修復
- 插件化
- AAB
- Shadow
- 虛擬機
- 其他
- UI自動化
- JavaParser
- Android Line
- 編譯
- 疑難雜癥
- Android11滑動異常
- 方案
- 工業化
- 模塊化
- 隱私合規
- 動態化
- 項目管理
- 業務啟動優化
- 業務架構設計
- 性能優化case
- 性能優化-排查思路
- 性能優化-現有方案
- 登錄
- 搜索
- C++
- NDK入門
- 跨平臺
- H5
- Flutter
- Flutter 性能優化
- 數據跨平臺