
[TOC]
## 優點
Protobuf 有如 XML,不過它更小、更快、也更簡單。你可以定義自己的數據結構,然后使用代碼生成器生成的代碼來讀寫這個數據結構。你甚至可以在無需重新部署程序的情況下更新數據結構。只需使用 Protobuf 對數據結構進行一次描述,即可利用各種不同語言或從各種不同數據流中對你的結構化數據輕松讀寫。
它有一個非常棒的特性,即“向后”兼容性好,人們不必破壞已部署的、依靠“老”數據格式的程序就可以對數據結構進行升級。這樣您的程序就可以不必擔心因為消息結構的改變而造成的大規模的代碼重構或者遷移的問題。因為添加新的消息中的 field 并不會引起已經發布的程序的任何改變。
Protobuf 語義更清晰,無需類似 XML 解析器的東西(因為 Protobuf 編譯器會將 .proto 文件編譯生成對應的數據訪問類以對 Protobuf 數據進行序列化、反序列化操作)。
使用 Protobuf 無需學習復雜的文檔對象模型,Protobuf 的編程模式比較友好,簡單易學,同時它擁有良好的文檔和示例,對于喜歡簡單事物的人們而言,Protobuf 比其他的技術更加有吸引力。
**包的體積小 解包速度快**
## 不足
由于文本并不適合用來描述數據結構,所以 Protobuf 也不適合用來對基于文本的標記文檔(如 HTML)建模。另外,由于 XML 具有某種程度上的自解釋性,它可以被人直接讀取編輯,在這一點上 Protobuf 不行,它以二進制的方式存儲,除非你有 .proto 定義,否則你沒法直接讀出 Protobuf 的任何內容【 2 】。
**無法直接看懂**
## Encode
### Varint
考察消息結構之前,讓我首先要介紹一個叫做 Varint 的術語。Varint 是一種緊湊的表示數字的方法。它用一個或多個字節來表示一個數字,值越小的數字使用越少的字節數。這能減少用來表示數字的字節數。
比如對于 int32 類型的數字,一般需要 4 個 byte 來表示。但是采用 Varint,對于很小的 int32 類型的數字,則可以用 1 個 byte 來表示。當然凡事都有好的也有不好的一面,采用 Varint 表示法,大的數字則需要 5 個 byte 來表示。從統計的角度來說,一般不會所有的消息中的數字都是大數,因此大多數情況下,采用 Varint 后,可以用更少的字節數來表示數字信息。下面就詳細介紹一下 Varint。
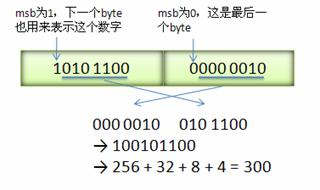
Varint 中的每個 byte 的最高位 bit 有特殊的含義,如果該位為 1,表示后續的 byte 也是該數字的一部分,如果該位為 0,則結束。其他的 7 個 bit 都用來表示數字。因此小于 128 的數字都可以用一個 byte 表示。大于 128 的數字,比如 300,會用兩個字節來表示:1010 1100 0000 0010。下圖演示了 Google Protocol Buffer 如何解析兩個 bytes。注意到最終計算前將兩個 byte 的位置相互交換過一次,這是因為 Google Protocol Buffer 字節序采用 little-endian 的方式。
### zigzag
在計算機內,一個負數一般會被表示為一個很大的整數,因為計算機定義負數的符號位為數字的最高位。如果采用 Varint 表示一個負數,那么一定需要 5 個 byte。為此 Google Protocol Buffer 定義了 sint32 這種類型,采用 zigzag 編碼。
Zigzag 編碼用無符號數來表示有符號數字,正數和負數交錯,這就是 zigzag 這個詞的含義了。
### Key-Value
消息經過序列化后會成為一個二進制數據流,該流中的數據為一系列的 Key-Value 對。如下圖所示。
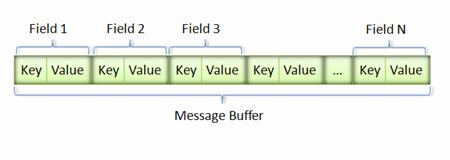
Key 用來標識具體的 field,在解包的時候,Protocol Buffer 根據 Key 就可以知道相應的 Value 應該對應于消息中的哪一個 field。
**key包含 id 以及類型**
**Key 的定義如下:**
```
(field_number << 3) | wire_type
```
可以看到 Key 由兩部分組成。第一部分是 field\_number,比如消息 lm.helloworld 中 field id 的 field\_number 為 1。第二部分為 wire\_type。表示 Value 的傳輸類型。
## 封解包
首先我們來了解一下 XML 的封解包過程。XML 需要從文件中讀取出字符串,再轉換為 XML 文檔對象結構模型。之后,再從 XML 文檔對象結構模型中讀取指定節點的字符串,最后再將這個字符串轉換成指定類型的變量。這個過程非常復雜,其中將 XML 文件轉換為文檔對象結構模型的過程通常需要完成詞法文法分析等大量消耗 CPU 的復雜計算。
反觀 Protobuf,它只需要簡單地將一個二進制序列,按照指定的格式讀取到 C++ 對應的結構類型中就可以了。從上一節的描述可以看到消息的 decoding 過程也可以通過幾個位移操作組成的表達式計算即可完成。速度非常快。
- Android
- 四大組件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介紹
- MessageQueue詳細
- 啟動流程
- 系統啟動流程
- 應用啟動流程
- Activity啟動流程
- View
- view繪制
- view事件傳遞
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大數據
- Binder小結
- Android組件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 遷移與修復
- Sqlite內核
- Sqlite優化v2
- sqlite索引
- sqlite之wal
- sqlite之鎖機制
- 網絡
- 基礎
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP進化圖
- HTTP小結
- 實踐
- 網絡優化
- Json
- ProtoBuffer
- 斷點續傳
- 性能
- 卡頓
- 卡頓監控
- ANR
- ANR監控
- 內存
- 內存問題與優化
- 圖片內存優化
- 線下內存監控
- 線上內存監控
- 啟動優化
- 死鎖監控
- 崩潰監控
- 包體積優化
- UI渲染優化
- UI常規優化
- I/O監控
- 電量監控
- 第三方框架
- 網絡框架
- Volley
- Okhttp
- 網絡框架n問
- OkHttp原理N問
- 設計模式
- EventBus
- Rxjava
- 圖片
- ImageWoker
- Gilde的優化
- APT
- 依賴注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 協程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 運行期Java-hook技術
- 編譯期hook
- ASM
- Transform增量編譯
- 運行期Native-hook技術
- 熱修復
- 插件化
- AAB
- Shadow
- 虛擬機
- 其他
- UI自動化
- JavaParser
- Android Line
- 編譯
- 疑難雜癥
- Android11滑動異常
- 方案
- 工業化
- 模塊化
- 隱私合規
- 動態化
- 項目管理
- 業務啟動優化
- 業務架構設計
- 性能優化case
- 性能優化-排查思路
- 性能優化-現有方案
- 登錄
- 搜索
- C++
- NDK入門
- 跨平臺
- H5
- Flutter
- Flutter 性能優化
- 數據跨平臺