
[TOC]
## 原理
IOCanary 將收集應用的文件中所有 I/O 信息并進行相關統計,再依據一定的算法規則進行檢測,發現問題,將之上報到 Matrix 后臺進行分析展示。流程圖如下:
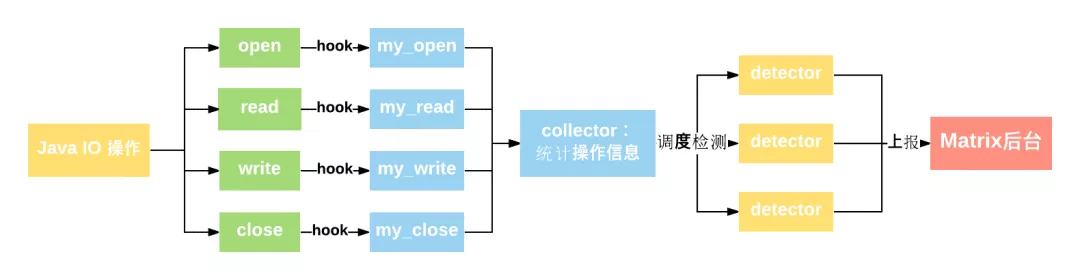
### Hook 方案簡介
IOCanary 采用 hook (ELF hook) 的方案收集 I/O 信息,代碼無侵入,從而使得開發者可以**無感知接入**。方案主要通過 hook os posix 的四個關鍵的文件操作接口:
~~~
int?open(const?char?*pathname,?int?flags,?mode_t?mode);//成功時返回值就是fd
ssize_t?read(int?fd,?void?*buf,?size_t?size);
ssize_t?write(int?fd,?const?void?*buf,?size_t?size);
int?close(int?fd);
~~~
由上得知,通過 hook 這幾個接口,可以拿到大部分關鍵操作信息。這里舉 open 的例子介紹下原理。 簡單起見,只結合**Android M**的代碼以及大家最常用的 FileInputStream 分析。關鍵要找到 posix open 是在哪里被調用。由上往下我們列了大致的調用關系:
~~~
java?:?FileInputStream?->?IoBridge.open?->?Libcore.os.open
->?BlockGuardOs.open?->?Posix.open
? ? ? ? ? ? ? ? ? ? ? ? ? ??↓
jni?:?libcore_io_Posix.cpp
static?jobject?Posix_open(...) {
? ?...
? ?int?fd?=?throwIfMinusOne(env,?"open",?TEMP_FAILURE_RETRY(open(path.c_str(),?flags,?mode)));
? ?...
}
~~~
由上看到, android 框架的 FileInputStream ,最終是在 libcore\_io\_Posix.cpp 那里調到了posix的open接口。
最后我們再找它被編到哪個 so ,通過查閱源碼對應的 NativeCode.mk ,可以找到:
~~~
LOCAL_MODULE := libjavacore
~~~
因此,只要 hook libjavacore.so 的 open 符號就 ok 了。**找到 hook 目標 so 的目的是把 hook 的影響范圍盡可能地降到最小**。同樣, write,read,close 也是大同小異。不同的 Android 版本會有些坑需要填,這里不細述, 目前兼容到Android P。
由此, 通過ELF hook 便可以收集到應用在文件讀寫時的相關信息:**文件路徑、fd、buffer 大小**等,并可以**統計耗時、操作次數**等。基于這些信息,就可以設定一些策略進行檢測判斷。
## 監控問題
### 1\. 主線程 I/O
我不止一次說過,有時候 I/O 的寫入會突然放大,即使是幾百 KB 的數據,還是盡量不要在主線程上操作。在線上也會經常發現一些 I/O 操作明明數據量不大,但是最后還是 ANR 了。
當然如果把所有的主線程 I/O 都收集上來,這個數據量會非常大,所以我會添加“連續讀寫時間超過 100 毫秒”這個條件。之所以使用連續讀寫時間,是因為發現有不少案例是打開了文件句柄,但不是一次讀寫完的。
在上報問題到后臺時,為了能更好地定位解決問題,我通常還會把 CPU 使用率、其他線程的信息以及內存信息一并上報,輔助分析問題。
### 2\. 讀寫 Buffer 過小
我們知道,對于文件系統是以 block 為單位讀寫,對于磁盤是以 page 為單位讀寫,看起來即使我們在應用程序上面使用很小的 Buffer,在底層應該差別不大。那是不是這樣呢?
~~~
read(53, "*****************"\.\.\., 1024) = 1024 <0.000447>
read(53, "*****************"\.\.\., 1024) = 1024 <0.000084>
read(53, "*****************"\.\.\., 1024) = 1024 <0.000059>
~~~
雖然后面兩次系統調用的時間的確會少一些,但是也會有一定的耗時。如果我們的 Buffer 太小,會導致多次無用的系統調用和內存拷貝,導致 read/write 的次數增多,從而影響了性能。
那應該選用多大的 Buffer 呢?我們可以跟據文件保存所掛載的目錄的 block size 來確認 Buffer 大小,數據庫中的[pagesize](http://androidxref.com/6.0.1_r10/xref/frameworks/base/core/java/android/database/sqlite/SQLiteGlobal.java#61)就是這樣確定的。
~~~
new StatFs("/data").getBlockSize()
~~~
所以我們最終選擇的判斷條件為:
* buffer size 小于 block size,這里一般為 4KB。
* read/write 的次數超過一定的閾值,例如 5 次,這主要是為了減少上報量。
buffer size 不應該小于 4KB,那它是不是越大越好呢?你可以通過下面的命令做一個簡單的測試,讀取測試應用的 iotest 文件,它的大小是 40M。其中 bs 就是 buffer size,bs 分別使用不同的值,然后觀察耗時。
~~~
// 每次測試之前需要手動釋放緩存
echo 3 > /proc/sys/vm/drop_caches
time dd if=/data/data/com.sample.io/files/iotest of=/dev/null bs=4096
~~~

通過上面的數據大致可以看出來,Buffer 的大小對文件讀寫的耗時有非常大的影響。耗時的減少主要得益于系統調用與內存拷貝的優化,Buffer 的大小一般我推薦使用 4KB 以上。
在實際應用中,ObjectOutputStream 和 ZipOutputStream 都是一個非常經典的例子,ObjectOutputStream 使用的 buffer size 非常小。而 ZipOutputStream 會稍微復雜一些,如果文件是 Stored 方式存儲的,它會使用上層傳入的 buffer size。如果文件是 Deflater 方式存儲的,它會使用 DeflaterOutputStream 的 buffer size,這個大小默認是 512Byte。
**你可以看到,如果使用 BufferInputStream 或者 ByteArrayOutputStream 后整體性能會有非常明顯的提升。**

正如我上一期所說的,準確評估磁盤真實的讀寫次數是比較難的。磁盤內部也會有很多的策略,例如預讀。它可能發生超過你真正讀的內容,預讀在有大量順序讀取磁盤的時候,readahead 可以大幅提高性能。但是大量讀取碎片小文件的時候,可能又會造成浪費。
你可以通過下面的這個文件查看預讀的大小,一般是 128KB。
~~~
/sys/block/[disk]/queue/read_ahead_kb
~~~
一般來說,我們可以利用 /proc/sys/vm/block\_dump 或者[/proc/diskstats](https://www.kernel.org/doc/Documentation/iostats.txt)的信息統計真正的磁盤讀寫次數。
~~~
/proc/diskstats
塊設備名字|讀請求次數|讀請求扇區數|讀請求耗時總和\.\.\.\.
dm-0 23525 0 1901752 45366 0 0 0 0 0 33160 57393
dm-1 212077 0 6618604 430813 1123292 0 55006889 3373820 0 921023 3805823
~~~
### 3\. 重復讀
微信之前在做模塊化改造的時候,因為模塊間徹底解耦了,很多模塊會分別去讀一些公共的配置文件。
有同學可能會說,重復讀的時候數據都是從 Page Cache 中拿到,不會發生真正的磁盤操作。但是它依然需要消耗系統調用和內存拷貝的時間,而且 Page Cache 的內存也很有可能被替換或者釋放。
你也可以用下面這個命令模擬 Page Cache 的釋放。
~~~
echo 3 > /proc/sys/vm/drop_caches
~~~
如果頻繁地讀取某個文件,并且這個文件一直沒有被寫入更新,我們可以通過緩存來提升性能。不過為了減少上報量,我會增加以下幾個條件:
* 重復讀取次數超過 3 次,并且讀取的內容相同。
* 讀取期間文件內容沒有被更新,也就是沒有發生過 write。
加一層內存 cache 是最直接有效的辦法,比較典型的場景是配置文件等一些數據模塊的加載,如果沒有內存 cache,那么性能影響就比較大了。
~~~
public String readConfig() {
if (Cache != null) {
return cache;
}
cache = read("configFile");
return cache;
}
~~~
### 4\. 資源泄漏
在崩潰分析中,我說過有部分的 OOM 是由于文件句柄泄漏導致。資源泄漏是指打開資源包括文件、Cursor 等沒有及時 close,從而引起泄露。這屬于非常低級的編碼錯誤,但卻非常普遍存在。
如何有效的監控資源泄漏?這里我利用了 Android 框架中的 StrictMode,StrictMode 利用[CloseGuard.java](http://androidxref.com/8.1.0_r33/xref/libcore/dalvik/src/main/java/dalvik/system/CloseGuard.java)類在很多系統代碼已經預置了埋點。
到了這里,接下來還是查看源碼尋找可以利用的 Hook 點。這個過程非常簡單,CloseGuard 中的 REPORTER 對象就是一個可以利用的點。具體步驟如下:
* 利用反射,把 CloseGuard 中的 ENABLED 值設為 true。
* 利用動態代理,把 REPORTER 替換成我們定義的 proxy。
雖然在 Android 源碼中,StrictMode 已經預埋了很多的資源埋點。不過肯定還有埋點是沒有的,比如 MediaPlayer、程序內部的一些資源模塊。所以在程序中也寫了一個 MyCloseGuard 類,對希望增加監控的資源,可以手動增加埋點代碼。
## I/O 與啟動優化
通過 I/O 跟蹤,可以拿到整個啟動過程所有 I/O 操作的詳細信息列表。我們需要更加的苛刻地檢查每一處 I/O 調用,檢查清楚是否每一處 I/O 調用都是必不可少的,特別是 write()。
當然主線程 I/O、讀寫 Buffer、重復讀以及資源泄漏是首先需要解決的,特別是重復讀,比如 cpuinfo、手機內存這些信息都應該緩存起來。
對于必不可少的 I/O 操作,我們需要思考是否有其他方式做進一步的優化。
* 對大文件使用 mmap 或者 NIO 方式。[MappedByteBuffer](https://developer.android.com/reference/java/nio/MappedByteBuffer)就是 Java NIO 中的 mmap 封裝,正如上一期所說,對于大文件的頻繁讀寫會有比較大的優化。
* 安裝包不壓縮。對啟動過程需要的文件,我們可以指定在安裝包中不壓縮,這樣也會加快啟動速度,但帶來的影響是安裝包體積增大。事實上 Google Play 非常希望我們不要去壓縮 library、resource、resource.arsc 這些文件,這樣對啟動的內存和速度都會有很大幫助。而且不壓縮文件帶來只是安裝包體積的增大,對于用戶來說,Download size 并沒有增大。
* Buffer 復用。我們可以利用[Okio](https://github.com/square/okio)開源庫,它內部的 ByteString 和 Buffer 通過重用等技巧,很大程度上減少 CPU 和內存的消耗。
* 存儲結構和算法的優化。是否可以通過算法或者數據結構的優化,讓我們可以盡量的少 I/O 甚至完全沒有 I/O。比如一些配置文件從啟動完全解析,改成讀取時才解析對應的項;替換掉 XML、JSON 這些格式比較冗余、性能比較較差的數據結構,當然在接下來我還會對數據存儲這一塊做更多的展開。
- Android
- 四大組件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介紹
- MessageQueue詳細
- 啟動流程
- 系統啟動流程
- 應用啟動流程
- Activity啟動流程
- View
- view繪制
- view事件傳遞
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大數據
- Binder小結
- Android組件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 遷移與修復
- Sqlite內核
- Sqlite優化v2
- sqlite索引
- sqlite之wal
- sqlite之鎖機制
- 網絡
- 基礎
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP進化圖
- HTTP小結
- 實踐
- 網絡優化
- Json
- ProtoBuffer
- 斷點續傳
- 性能
- 卡頓
- 卡頓監控
- ANR
- ANR監控
- 內存
- 內存問題與優化
- 圖片內存優化
- 線下內存監控
- 線上內存監控
- 啟動優化
- 死鎖監控
- 崩潰監控
- 包體積優化
- UI渲染優化
- UI常規優化
- I/O監控
- 電量監控
- 第三方框架
- 網絡框架
- Volley
- Okhttp
- 網絡框架n問
- OkHttp原理N問
- 設計模式
- EventBus
- Rxjava
- 圖片
- ImageWoker
- Gilde的優化
- APT
- 依賴注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 協程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 運行期Java-hook技術
- 編譯期hook
- ASM
- Transform增量編譯
- 運行期Native-hook技術
- 熱修復
- 插件化
- AAB
- Shadow
- 虛擬機
- 其他
- UI自動化
- JavaParser
- Android Line
- 編譯
- 疑難雜癥
- Android11滑動異常
- 方案
- 工業化
- 模塊化
- 隱私合規
- 動態化
- 項目管理
- 業務啟動優化
- 業務架構設計
- 性能優化case
- 性能優化-排查思路
- 性能優化-現有方案
- 登錄
- 搜索
- C++
- NDK入門
- 跨平臺
- H5
- Flutter
- Flutter 性能優化
- 數據跨平臺