
[TOC]
## 1\. `Http`到底是什么?
`Http`翻譯過來就是超文本傳輸協議,它的主要作用就是在客戶端與服務端之間進行通信
我們平常在瀏覽器查看網頁時就用到了`Http`協議,根據瀏覽器地址欄中指定的`URL`,`Web`瀏覽器從`Web`服務器端獲取文件資源(`resource`)等信息,從而顯示出 `Web` 頁面。
`Http`協議主要具有以下特點
* 無連接:每一次請求都要連接一次,請求結束就會斷掉,不會保持連接
* 無狀態:每一次請求都是獨立的,請求結束不會記錄連接的任何信息,減少了網絡開銷,這是優點也是缺點
* 靈活:通過`http`協議中頭部的`Content-Type`標記,可以傳輸任意數據類型的數據對象(文本、圖片、視頻等等),非常靈活
* 簡單快速:發送請求訪問某個資源時,只需傳送請求方法和`URL`就可以了,使用簡單,正由于`http`協議簡單,使得`http`服務器的程序規模小,因而通信速度很快
當然`Http`協議也有一些缺點
* 無狀態:請求不會記錄任何連接信息,沒有記憶,就無法區分多個請求發起者身份是不是同一個客戶端的,意味著如果后續處理需要前面的信息,則它必須重傳,這樣可能導致每次連接傳送的數據量增大
* 明文傳輸:`Http`報文使用明文傳輸,如果在通信的過程中存在中間人,可以輕易的獲取請求的所有內容
* 隊頭阻塞:當開啟長連接時,多個`Http`請求復用一個`TCP`連接,同一時刻只能處理一個請求,那么當前面的請求耗時過長時,其他請求就只能處于阻塞狀態
## 2\. `Http`協議為什么是無狀態的?
上面我們介紹了`Http`協議是無狀態的,即每次請求都是獨立的,服務端中不保存客戶端的狀態
因此為了區分用戶的身份,我們需要每次都在`Header`中攜帶身份信息(比如`Cookie`),這樣其實導致了每次連接傳送的數據量變大了不少。
**那么為什么`Http`要這樣設計呢?**
1. `http`最初設計成無狀態的是因為只是用來瀏覽靜態文件的,無狀態協議已經足夠,也沒什么其他的負擔。
2. 隨著`web`的發展,它需要變得有狀態,但是不是就要修改`http`協議使之有狀態呢?是不需要的。因為我們經常長時間逗留在某一個網頁,然后才進入到另一個網頁,如果在這兩個頁面之間維持狀態,代價是很高的。
3. 其次,老版本`http`是無狀態的,但是現在對`http`提出了新的要求,按照軟件領域的通常做法是,兼容歷史版本,在`http`協議上再加上一層實現我們的目的。所以引入了`cookie`、`session`等機制來實現這種有狀態的連接。
4. 同時,保存用戶狀態是一個很復雜的過程,而`Http`協議為了更快地處理大量事務,確保協議的可伸縮性,故意把`HTTP`協議設計的比較簡單。因此沒有必要在`Http`協議中引入狀態管理
## 3\. 什么是隊頭阻塞問題?
`Http1.0`是無連接的,即每個請求/應答客戶與服務器都要新建一個連接,完成之后立即斷開連接
在`Http1.1`中引入了`Keep-Alive`支持長連接,即多個`Http`請求復用一個`TCP`連接,如下圖所示:
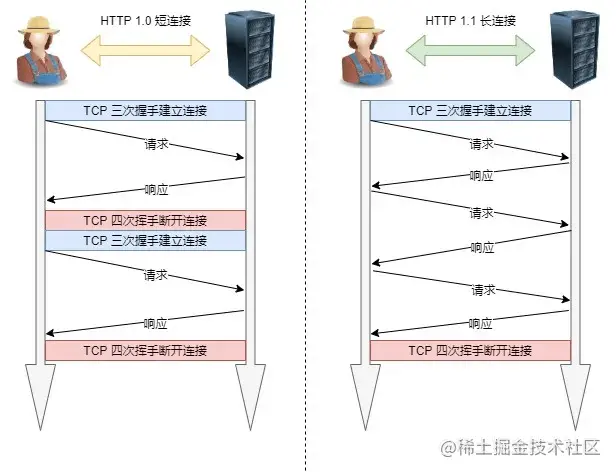
如上所示,使用長連接,可以減少`TCP`握手時間,提高請求速度
但是在長連接下同樣`Http`協議同樣會有隊頭阻塞問題,因為我們雖然可以復用`TCP`連接,但`Http`請求仍然是串行的
> 請求1 -> 響應1 -> 請求2 -> 響應2 -> 請求3 -> 響應3
如上所示,就是這樣一個先進先出的串行隊列,沒有輕重緩急的優先級,只有入隊的先后順序,排在最前面的請求最先處理,就導致如果隊首的請求耗時過長,后面的請求就只能處于阻塞狀態,這就是隊頭阻塞問題
當然我們也可以通過一些方式緩解這個問題
1. 一個域名允許分配多個長連接,就相當于增加了任務隊列,不至于一個隊列里的任務阻塞了其他全部任務。現在的瀏覽器標準中一個域名并發連接可以有`6~8`個(`Chrome`6個/`Firefox`8個)
2. 一個域名最多可以并發`6~8`個,那我們可以使用多個二級域名,當我們訪問服務端時,可以讓不同的資源從不同的二域名中獲取,而它們都指向同一臺服務器,這樣能夠并發更多的長連接了,從而減少隊頭阻塞
## 4\. `GET`,`POST`,`PUT`等方法有什么區別?
### 4.1 `GET`與`POST`的區別
1. `GET` 用于獲取信息,是無副作用的,是冪等的,且可緩存.
2. `POST` 用于修改服務器上的數據,有副作用,非冪等,不可緩存
其實`GET`與`POST`的區別主要就是這些,網上有些文章說`GET`的`URL`長度有限制,`HTTP` 協議沒有`Body` 和 `URL` 的長度限制,對 `URL` 限制的大多是瀏覽器和服務器的原因。
瀏覽器原因就不說了,服務器是因為處理長`URL`要消耗比較多的資源,為了性能和安全(防止惡意構造長`URL`來攻擊)考慮,會給`URL`長度加限制。
### 4.2 `PUT`與`POST`的區別
有人說,`PUT`與`POST`的區別在于`POST`是用來創建數據的,`PUT`是用來更新數據的.
其實`PUT`與`POST`都能創建數據,它們的主要區別是`PUT`是冪等的,而`POST`不是冪等的
因此`PUT`能用于更新數據,也能用于創建數據,而`POST`只能用于創建數據
如果`POST`兩條相同的數據,則會創建兩條數據
而`PUT`兩條相同的數據,則只會創建一條數據
## 5\. 為什么引入`Https`?
上面說到了`HTTP`是明文傳輸的,在安全方面主要有以下缺點
1. `Http`通信使用明文(不加密),內容可能會被竊聽
2. 不驗證通信方的身份,因此有可能遭遇偽裝
3. 無法證明報文的完整性,所以有可能已遭篡改
正因此才推出了`Https`協議來保證`Client`和`Server`交流的信息不能被其它第三方竊聽及防止篡改與偽裝
`Https`通信的主要過程如圖所示:
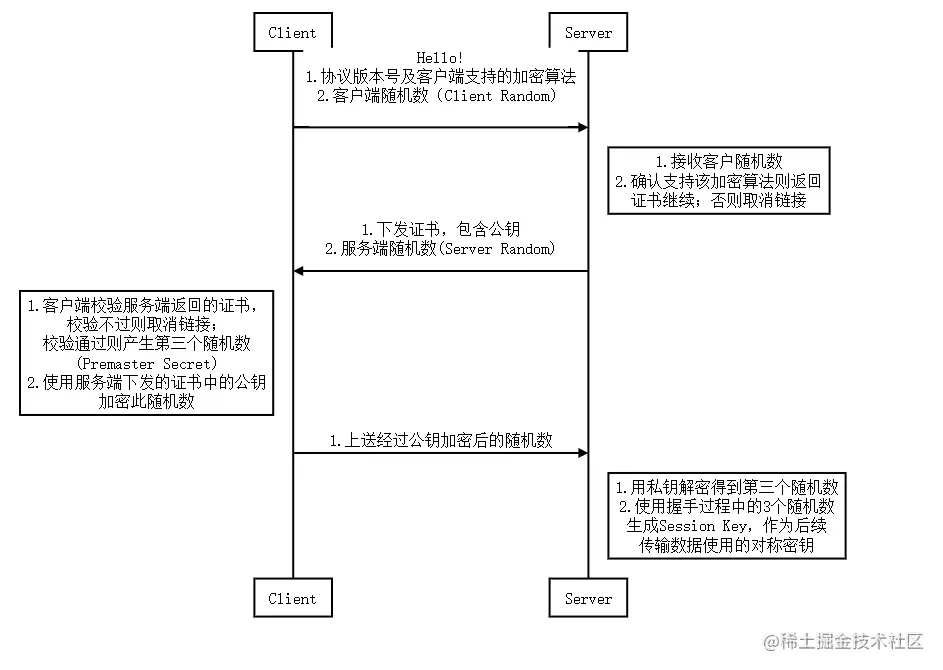
主要做了以下幾件事
1.客戶端&服務端通信,協商加密方式
2.客戶端(`Client`)和服務端(`Server`)互相確認身份
3.雙方安全地交換`https`通信使用的密鑰(`Session Key`)
## 6\. 為什么引入`Http2.0`?
上面我們已經介紹了`Http`協議的主要缺點
1.請求 / 響應頭部(`Header`)未經壓縮就發送,首部信息越多延遲越大。
2.發送冗長的首部。每次互相發送相同的首部造成的浪費較多;
3.服務器是按請求的順序響應的,如果服務器響應慢,會招致客戶端一直請求不到數據,也就是隊頭阻塞;
4.沒有請求優先級控制;
5.請求只能從客戶端開始,服務器只能被動響應
`Http2.0`正是為了解決以上問題才被引入的,相比`Http1.1`,`Http2.0`主要有以下改進
### 6.1 頭部壓縮
`HTTP/2` 會壓縮頭(`Header`)如果你同時發出多個請求,他們的頭是一樣的或是相似的,那么,協議會幫你消除重復的部分。
這就是所謂的`HPACK`算法:在客戶端和服務器同時維護一張頭信息表,所有字段都會存入這個表,生成一個索引號,以后就不發送同樣字段了,只發送索引號,這樣就提高速度了
### 6.2 多路復用
#### 6.2.1 二進制分幀
`HTTP/2` 不再像`HTTP/1.1`里的純文本形式的報文,而是全面采用了二進制格式,頭信息和數據體都是二進制,并且統稱為幀(`frame`):頭信息幀和數據幀。
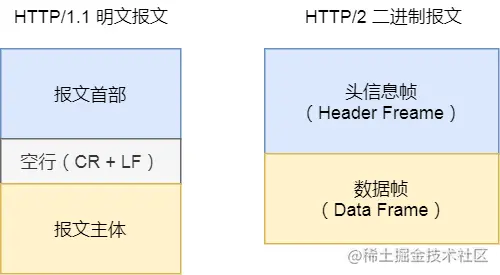
這樣雖然對人不友好,但是對計算機非常友好,因為計算機只懂二進制,那么收到報文后,無需再將明文的報文轉成二進制,而是直接解析二進制報文,這增加了數據傳輸的效率
#### 6.2.2 多路復用解決隊頭阻塞
原來`Headers + Body`的報文格式如今被拆分成了一個個二進制的幀,用`Headers`幀存放頭部字段,`Data`幀存放請求體數據。
分幀之后,服務器看到的不再是一個個完整的 `HTTP` 請求報文,而是一堆亂序的二進制幀。
通信雙方都可以給對方發送二進制幀,這種二進制幀的雙向傳輸的序列,也叫做流(`Stream`)。
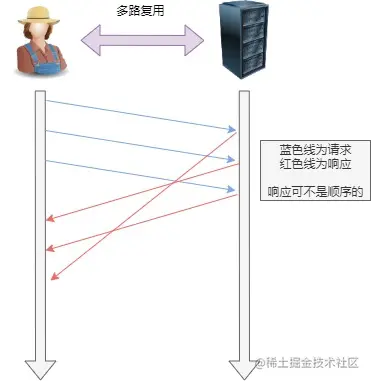
`HTTP/2` 用流(`Stream`)來在一個 `TCP` 連接上來進行多個數據幀的通信,這就是多路復用的概念。
這些二進制幀不存在先后關系,因此也就不會排隊等待,也就沒有了 `HTTP` 的隊頭阻塞問題。
舉例來說,在一個 `TCP` 連接里,服務器收到了客戶端 `A` 和 `B` 的兩個請求,如果發現 `A` 處理過程非常耗時,于是就回應 `A` 請求已經處理好的部分,接著回應 `B` 請求,完成后,再回應 `A` 請求剩下的部分。
### 6.5 服務器推送
`HTTP/2` 還在一定程度上改善了傳統的`「請求 - 應答」`工作模式,服務不再是被動地響應,也可以主動向客戶端發送消息。
舉例來說,在瀏覽器剛請求 `HTML` 的時候,就提前把可能會用到的 `JS`、`CSS` 文件等靜態資源主動發給客戶端,減少延時的等待,也就是服務器推送
## 7\. 為什么引入`Http3.0`?
`Http2.0`還沒學,怎么`Http3.0`又來了?
總得來說,這是因為`Http2.0`還存在一定的缺陷
`HTTP/2` 主要的問題在于,多個 `HTTP` 請求在復用一個 `TCP` 連接,下層的 `TCP` 協議是不知道有多少個 `HTTP` 請求的。
所以一旦發生了丟包現象,就會觸發 `TCP` 的重傳機制,這樣在一個 `TCP` 連接中的所有的 `HTTP` 請求都必須等待這個丟了的包被重傳回來。
`HTTP/2` 多請求復用一個`TCP`連接,一旦發生丟包,就會阻塞住所有的 `HTTP` 請求。
可以看出,這其實不是`Http`協議的問題,而是傳輸層協議的問題
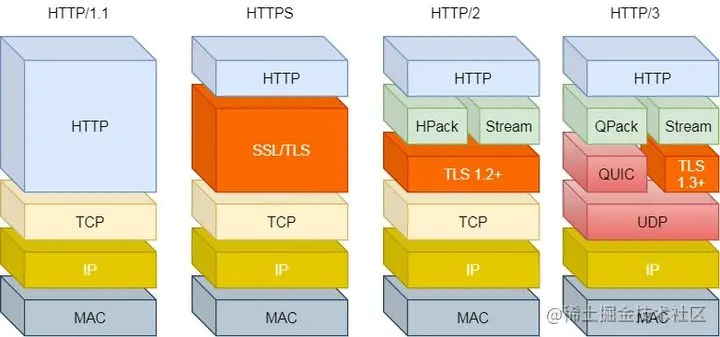
所以 `HTTP/3` 把 `HTTP` 下層的 `TCP` 協議改成了 `UDP`!
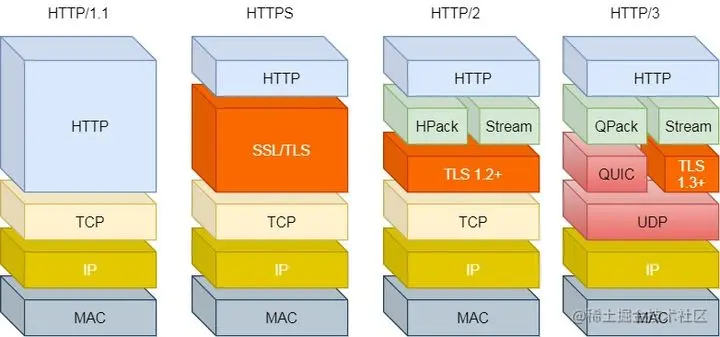
`UDP` 發生是不管順序,也不管丟包的,所以不會出現 `HTTP/1.1` 的隊頭阻塞 和 `HTTP/2` 的一個丟包全部重傳問題。
大家都知道 `UDP` 是不可靠傳輸的,但基于 `UDP` 的 `QUIC` 協議 可以實現類似 `TCP` 的可靠性傳輸。
`QUIC` 是一個在 `UDP` 之上的偽 `TCP` + `TLS` + `HTTP/2` 的多路復用的協議,在這里就不詳細介紹了,有興趣的同學可參考:[QUIC協議連接過程介紹](https://link.juejin.cn?target=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F111716047 "https://zhuanlan.zhihu.com/p/111716047")
總得來說,`QUIC` 是新協議,對于很多網絡設備,根本不知道什么是 `QUIC`,只會當做 `UDP`,這樣會出現新的問題。
所以 `HTTP/3` 現在普及的進度非常的緩慢,大家只做簡單了解即可。
## 8\. 瀏覽器輸入`url`后發生了什么?
這個是面試中的常見問題了,我們在了解了上面的知識點后,再一起來看下這個問題
要回答這個問題,我們需要對`TCP/IP`協議族有一定的了解
### 8.1 `Tcp/IP`協議族
`TCP/IP` 協議族里重要的一點就是分層。
`TCP/IP` 協議族按層次分別分為以下 4 層:應用層、傳輸層、網絡層和數據鏈路層。
把 `TCP/IP` 層次化是有好處的。比如,如果互聯網只由一個協議統籌,某個地方需要改變設計時,就必須把所有部分整體替換掉。
而分層之后只需把變動的層替換掉即可。把各層之間的接口部分規劃好之后,每個層次內部的設計就能夠自由改動了。
值得一提的是,層次化之后,設計也變得相對簡單了。
處于應用層上的應用可以只考慮分派給自己的任務,而不需要弄清對方在地球上哪個地方、對方的傳輸路線是怎樣的、是否能確保傳輸送達等問題。
#### 8.1.1 應用層
應用層決定了向用戶提供應用服務時通信的活動。
`TCP/IP` 協議族內預存了各類通用的應用服務。比如,`FTP`(`File Transfer Protocol`,文件傳輸協議)和 `DNS`(`Domain Name System`,域名系統)服務就是其中兩類。
`HTTP` 協議也處于該層。
#### 8.1.2 傳輸層
傳輸層對上層應用層,**提供處于網絡連接中的兩臺計算機之間的數據傳輸**。
在傳輸層有兩個性質不同的協議:`TCP`(`Transmission ControlProtocol`,傳輸控制協議)和 `UDP`(`User Data Protocol`,用戶數據報協議)。
#### 8.1.3 網絡層
網絡層用來處理在網絡上流動的數據包。數據包是網絡傳輸的最小數據單位。
該層規定了通過怎樣的路徑(所謂的傳輸路線)到達對方計算機,并把數據包傳送給對方。
與對方計算機之間通過多臺計算機或網絡設備進行傳輸時,**網絡層所起的作用就是在眾多的選項內選擇一條傳輸路線**。
`IP`協議就在網絡層
#### 8.1.4 數據鏈路層
**用來處理連接網絡的硬件部分。**
包括控制操作系統、硬件的設備驅動、`NIC`(`Network Interface Card`,網絡適配器,即網卡),及光纖等物理可見部分(還包括連接器等一切傳輸媒介)。
硬件上的范疇均在鏈路層的作用范圍之內。
### 8.2 瀏覽器輸入`url`后大致流程
1. 解析用戶輸入的`Url`
2. 通過`DNS`協議根據域名查詢`ip`地址
3. 客戶端發起請求
4. 服務端接受請求并處理
5. 客戶端接受響應
6. 瀏覽器渲染頁面
這里我們主要關注客戶端發起請求及服務端接受請求的過程,這里就用到了`TCP/IP`協議族
在發送數據時,每層都要對數據進行封裝,在接收數據時,每層都要對數據進行解封,如下圖所示:
簡單來說,就是從應用層發`http`請求,到傳輸層通過三次握手建立`tcp`連接,再到網絡層的`ip`尋址,再經過數據鏈路層與物理層,最后到達服務端。 然后服務端經過相反的過程,在每一層將數據取出來即可。
關于瀏覽器輸入`url`后的流程我們這里沒有講得很詳細,想要了解更多細節的同學可參考:[在瀏覽器輸入 URL 回車之后發生了什么(超詳細版)](https://link.juejin.cn?target=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F80551769 "https://zhuanlan.zhihu.com/p/80551769")
## 總結
本文主要梳理了`Http`協議相關知識點,并回答了以下問題
1. `Http`到底是什么?
2. `Http`協議為什么是無狀態的?
3. 什么是隊頭阻塞問題?
4. `GET`,`POST`,`PUT`等方法有什么區別?
5. 為什么引入`Https`?
6. 為什么引入`Http2.0`?
7. 為什么引入`Http3.0`?
8. 瀏覽器輸入`url`后發生了什么?
如果對您有所幫助,歡迎點贊,謝謝~
### 參考資料
[20分鐘助你拿下HTTP和HTTPS,鞏固你的HTTP知識體系](https://juejin.cn/post/6994629873985650696 "https://juejin.cn/post/6994629873985650696")
[Http協議為什么是無狀態的](https://link.juejin.cn?target=https%3A%2F%2Fwww.byway.xyz%2Ftips%2Fhttp.html "https://www.byway.xyz/tips/http.html")
[What is the difference between POST and PUT in HTTP?](https://link.juejin.cn?target=https%3A%2F%2Fstackoverflow.com%2Fquestions%2F630453%2Fwhat-is-the-difference-between-post-and-put-in-http "https://stackoverflow.com/questions/630453/what-is-the-difference-between-post-and-put-in-http")
[圖解網絡: HTTP 常見的面試題](https://link.juejin.cn?target=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F111716047 "https://zhuanlan.zhihu.com/p/111716047")
[在瀏覽器輸入 URL 回車之后發生了什么(超詳細版)](https://link.juejin.cn?target=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F80551769 "https://zhuanlan.zhihu.com/p/80551769")
作者:程序員江同學
鏈接:https://juejin.cn/post/7001839784289108005
來源:稀土掘金
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。
- Android
- 四大組件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介紹
- MessageQueue詳細
- 啟動流程
- 系統啟動流程
- 應用啟動流程
- Activity啟動流程
- View
- view繪制
- view事件傳遞
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大數據
- Binder小結
- Android組件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 遷移與修復
- Sqlite內核
- Sqlite優化v2
- sqlite索引
- sqlite之wal
- sqlite之鎖機制
- 網絡
- 基礎
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP進化圖
- HTTP小結
- 實踐
- 網絡優化
- Json
- ProtoBuffer
- 斷點續傳
- 性能
- 卡頓
- 卡頓監控
- ANR
- ANR監控
- 內存
- 內存問題與優化
- 圖片內存優化
- 線下內存監控
- 線上內存監控
- 啟動優化
- 死鎖監控
- 崩潰監控
- 包體積優化
- UI渲染優化
- UI常規優化
- I/O監控
- 電量監控
- 第三方框架
- 網絡框架
- Volley
- Okhttp
- 網絡框架n問
- OkHttp原理N問
- 設計模式
- EventBus
- Rxjava
- 圖片
- ImageWoker
- Gilde的優化
- APT
- 依賴注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 協程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 運行期Java-hook技術
- 編譯期hook
- ASM
- Transform增量編譯
- 運行期Native-hook技術
- 熱修復
- 插件化
- AAB
- Shadow
- 虛擬機
- 其他
- UI自動化
- JavaParser
- Android Line
- 編譯
- 疑難雜癥
- Android11滑動異常
- 方案
- 工業化
- 模塊化
- 隱私合規
- 動態化
- 項目管理
- 業務啟動優化
- 業務架構設計
- 性能優化case
- 性能優化-排查思路
- 性能優化-現有方案
- 登錄
- 搜索
- C++
- NDK入門
- 跨平臺
- H5
- Flutter
- Flutter 性能優化
- 數據跨平臺