
#J2SE
---
##基礎
---
**八種基本數據類型的大小,以及他們的封裝類。**
八種基本數據類型,int ,double ,long ,float, short,byte,character,boolean
對應的封裝類型是:Integer ,Double ,Long ,Float, Short,Byte,Character,Boolean
---
**Switch能否用string做參數?**
在Java 5以前,switch(expr)中,expr只能是byte、short、char、int。從Java 5開始,Java中引入了枚舉類型,expr也可以是enum類型,從Java 7開始,expr還可以是字符串(String),但是長整型(long)在目前所有的版本中都是不可以的。
---
**equals與==的區別。**
== 和 Equals 的區別
1. == 是一個運算符。
2.Equals則是string對象的方法,可以.(點)出來。
我們比較無非就是這兩種 1、基本數據類型比較 2、引用對象比較
1、基本數據類型比較
==和Equals都比較兩個值是否相等。相等為true 否則為false;
2、引用對象比較
==和Equals都是比較棧內存中的地址是否相等 。相等為true 否則為false;
詳解 [http://www.importnew.com/6804.html](http://www.importnew.com/6804.html)
主要區別在于前者是方法后者是操作符。“==”的行為對于每個對象來說與equals()是完全相同的,但是equals()可以基于業務規則的不同而重寫(overridden )。“==”習慣用于原生(primitive)類型之間的比較,而equals()僅用于對象之間的比較。
==與equals的主要區別是:==常用于比較原生類型,而equals()方法用于檢查對象的相等性。另一個不同的點是:如果==和equals()用于比較對象,當兩個引用地址相同,==返回true。而equals()可以返回true或者false主要取決于重寫實現。最常見的一個例子,字符串的比較,不同情況==和equals()返回不同的結果。
---
**Object有哪些公用方法?**
[http://www.cnblogs.com/yumo/p/4908315.html](http://www.cnblogs.com/yumo/p/4908315.html)
1.clone方法
保護方法,實現對象的淺復制,只有實現了Cloneable接口才可以調用該方法,否則拋出CloneNotSupportedException異常。
主要是JAVA里除了8種基本類型傳參數是值傳遞,其他的類對象傳參數都是引用傳遞,我們有時候不希望在方法里講參數改變,這是就需要在類中復寫clone方法。
2.getClass方法
final方法,獲得運行時類型。
3.toString方法
該方法用得比較多,一般子類都有覆蓋。
4.finalize方法
該方法用于釋放資源。因為無法確定該方法什么時候被調用,很少使用。
5.equals方法
該方法是非常重要的一個方法。一般equals和==是不一樣的,但是在Object中兩者是一樣的。子類一般都要重寫這個方法。
6.hashCode方法
該方法用于哈希查找,可以減少在查找中使用equals的次數,重寫了equals方法一般都要重寫hashCode方法。這個方法在一些具有哈希功能的Collection中用到。
一般必須滿足obj1.equals(obj2)==true。可以推出obj1.hash- Code()==obj2.hashCode(),但是hashCode相等不一定就滿足equals。不過為了提高效率,應該盡量使上面兩個條件接近等價。
如果不重寫hashcode(),在HashSet中添加兩個equals的對象,會將兩個對象都加入進去。
7.wait方法
wait方法就是使當前線程等待該對象的鎖,當前線程必須是該對象的擁有者,也就是具有該對象的鎖。wait()方法一直等待,直到獲得鎖或者被中斷。wait(long timeout)設定一個超時間隔,如果在規定時間內沒有獲得鎖就返回。
調用該方法后當前線程進入睡眠狀態,直到以下事件發生。
(1)其他線程調用了該對象的notify方法。
(2)其他線程調用了該對象的notifyAll方法。
(3)其他線程調用了interrupt中斷該線程。
(4)時間間隔到了。
此時該線程就可以被調度了,如果是被中斷的話就拋出一個InterruptedException異常。
8.notify方法
該方法喚醒在該對象上等待的某個線程。
9.notifyAll方法
該方法喚醒在該對象上等待的所有線程。
---
**Java的四種引用,強弱軟虛,用到的場景。**
JDK1.2之前只有強引用,其他幾種引用都是在JDK1.2之后引入的.
* 強引用(Strong Reference)
最常用的引用類型,如Object obj = new Object(); 。只要強引用存在則GC時則必定不被回收。
* 軟引用(Soft Reference)
用于描述還有用但非必須的對象,當堆將發生OOM(Out Of Memory)時則會回收軟引用所指向的內存空間,若回收后依然空間不足才會拋出OOM。一般用于實現內存敏感的高速緩存。
當真正對象被標記finalizable以及的finalize()方法調用之后并且內存已經清理, 那么如果SoftReference object還存在就被加入到它的 ReferenceQueue.只有前面幾步完成后,Soft Reference和Weak Reference的get方法才會返回null
* 弱引用(Weak Reference)
發生GC時必定回收弱引用指向的內存空間。
和軟引用加入隊列的時機相同
* 虛引用(Phantom Reference)
又稱為幽靈引用或幻影引用,虛引用既不會影響對象的生命周期,也無法通過虛引用來獲取對象實例,僅用于在發生GC時接收一個系統通知。
當一個對象的finalize方法已經被調用了之后,這個對象的幽靈引用會被加入到隊列中。通過檢查該隊列里面的內容就知道一個對象是不是已經準備要被回收了.
虛引用和軟引用和弱引用都不同,它會在內存沒有清理的時候被加入引用隊列.虛引用的建立必須要傳入引用隊列,其他可以沒有
---
**Hashcode的作用。**
[http://c610367182.iteye.com/blog/1930676](http://c610367182.iteye.com/blog/1930676)
以Java.lang.Object來理解,JVM每new一個Object,它都會將這個Object丟到一個Hash哈希表中去,這樣的話,下次做Object的比較或者取這個對象的時候,它會根據對象的hashcode再從Hash表中取這個對象。這樣做的目的是提高取對象的效率。具體過程是這樣:
1. new Object(),JVM根據這個對象的Hashcode值,放入到對應的Hash表對應的Key上,如果不同的對象確產生了相同的hash值,也就是發生了Hash key相同導致沖突的情況,那么就在這個Hash key的地方產生一個鏈表,將所有產生相同hashcode的對象放到這個單鏈表上去,串在一起。
2. 比較兩個對象的時候,首先根據他們的hashcode去hash表中找他的對象,當兩個對象的hashcode相同,那么就是說他們這兩個對象放在Hash表中的同一個key上,那么他們一定在這個key上的鏈表上。那么此時就只能根據Object的equal方法來比較這個對象是否equal。當兩個對象的hashcode不同的話,肯定他們不能equal.
---
**String、StringBuffer與StringBuilder的區別。**
Java 平臺提供了兩種類型的字符串:String和StringBuffer / StringBuilder,它們可以儲存和操作字符串。其中String是只讀字符串,也就意味著String引用的字符串內容是不能被改變的。而StringBuffer和StringBulder類表示的字符串對象可以直接進行修改。StringBuilder是JDK1.5引入的,它和StringBuffer的方法完全相同,區別在于它是單線程環境下使用的,因為它的所有方面都沒有被synchronized修飾,因此它的效率也比StringBuffer略高。
---
**try catch finally,try里有return,finally還執行么?**
會執行,在方法 返回調用者前執行。Java允許在finally中改變返回值的做法是不好的,因為如果存在finally代碼塊,try中的return語句不會立馬返回調用者,而是紀錄下返回值待finally代碼塊執行完畢之后再向調用者返回其值,然后如果在finally中修改了返回值,這會對程序造成很大的困擾,C#中國就從語法規定不能做這樣的事。
---
**Excption與Error區別**
Error表示系統級的錯誤和程序不必處理的異常,是恢復不是不可能但很困難的情況下的一種嚴重問題;比如內存溢出,不可能指望程序能處理這樣的狀況;Exception表示需要捕捉或者需要程序進行處理的異常,是一種設計或實現問題;也就是說,它表示如果程序運行正常,從不會發生的情況。
---
**Excption與Error包結構。OOM你遇到過哪些情況,SOF你遇到過哪些情況。**
[http://www.cnblogs.com/yumo/p/4909617.html](http://www.cnblogs.com/yumo/p/4909617.html)
Java異常架構圖
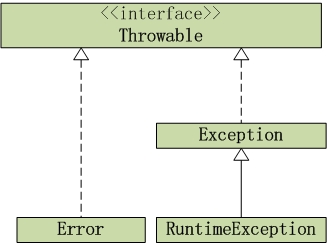
1. Throwable
Throwable是 Java 語言中所有錯誤或異常的超類。
Throwable包含兩個子類: Error 和 Exception 。它們通常用于指示發生了異常情況。
Throwable包含了其線程創建時線程執行堆棧的快照,它提供了printStackTrace()等接口用于獲取堆棧跟蹤數據等信息。
2. Exception
Exception及其子類是 Throwable 的一種形式,它指出了合理的應用程序想要捕獲的條件。
3. RuntimeException
RuntimeException是那些可能在 Java 虛擬機正常運行期間拋出的異常的超類。
編譯器不會檢查RuntimeException異常。 例如,除數為零時,拋出ArithmeticException異常。RuntimeException是ArithmeticException的超類。當代碼發生除數為零的情況時,倘若既"沒有通過throws聲明拋出ArithmeticException異常",也"沒有通過try...catch...處理該異常",也能通過編譯。這就是我們所說的"編譯器不會檢查RuntimeException異常"!
如果代碼會產生RuntimeException異常,則需要通過修改代碼進行避免。 例如,若會發生除數為零的情況,則需要通過代碼避免該情況的發生!
4. Error
和Exception一樣, Error也是Throwable的子類。 它用于指示合理的應用程序不應該試圖捕獲的嚴重問題,大多數這樣的錯誤都是異常條件。
和RuntimeException一樣, 編譯器也不會檢查Error。
Java將可拋出(Throwable)的結構分為三種類型: 被檢查的異常(Checked Exception),運行時異常(RuntimeException)和錯誤(Error)。
(01) 運行時異常
定義 : RuntimeException及其子類都被稱為運行時異常。
特點 : Java編譯器不會檢查它。 也就是說,當程序中可能出現這類異常時,倘若既"沒有通過throws聲明拋出它",也"沒有用try-catch語句捕獲它",還是會編譯通過。例如,除數為零時產生的ArithmeticException異常,數組越界時產生的IndexOutOfBoundsException異常,fail-fail機制產生的ConcurrentModificationException異常等,都屬于運行時異常。
雖然Java編譯器不會檢查運行時異常,但是我們也可以通過throws進行聲明拋出,也可以通過try-catch對它進行捕獲處理。
如果產生運行時異常,則需要通過修改代碼來進行避免。 例如,若會發生除數為零的情況,則需要通過代碼避免該情況的發生!
(02) 被檢查的異常
定義 : Exception類本身,以及Exception的子類中除了"運行時異常"之外的其它子類都屬于被檢查異常。
特點 : Java編譯器會檢查它。 此類異常,要么通過throws進行聲明拋出,要么通過try-catch進行捕獲處理,否則不能通過編譯。例如,CloneNotSupportedException就屬于被檢查異常。當通過clone()接口去克隆一個對象,而該對象對應的類沒有實現Cloneable接口,就會拋出CloneNotSupportedException異常。
被檢查異常通常都是可以恢復的。
(03) 錯誤
定義 : Error類及其子類。
特點 : 和運行時異常一樣,編譯器也不會對錯誤進行檢查。
當資源不足、約束失敗、或是其它程序無法繼續運行的條件發生時,就產生錯誤。程序本身無法修復這些錯誤的。例如,VirtualMachineError就屬于錯誤。
按照Java慣例,我們是不應該是實現任何新的Error子類的!
對于上面的3種結構,我們在拋出異常或錯誤時,到底該哪一種?《Effective Java》中給出的建議是: 對于可以恢復的條件使用被檢查異常,對于程序錯誤使用運行時異常。
---
**OOM:**
1. OutOfMemoryError異常
除了程序計數器外,虛擬機內存的其他幾個運行時區域都有發生OutOfMemoryError(OOM)異常的可能,
Java Heap 溢出
一般的異常信息:java.lang.OutOfMemoryError:Java heap spacess
java堆用于存儲對象實例,我們只要不斷的創建對象,并且保證GC Roots到對象之間有可達路徑來避免垃圾回收機制清除這些對象,就會在對象數量達到最大堆容量限制后產生內存溢出異常。
出現這種異常,一般手段是先通過內存映像分析工具(如Eclipse Memory Analyzer)對dump出來的堆轉存快照進行分析,重點是確認內存中的對象是否是必要的,先分清是因為內存泄漏(Memory Leak)還是內存溢出(Memory Overflow)。
如果是內存泄漏,可進一步通過工具查看泄漏對象到GC Roots的引用鏈。于是就能找到泄漏對象時通過怎樣的路徑與GC Roots相關聯并導致垃圾收集器無法自動回收。
如果不存在泄漏,那就應該檢查虛擬機的參數(-Xmx與-Xms)的設置是否適當。
2. 虛擬機棧和本地方法棧溢出
如果線程請求的棧深度大于虛擬機所允許的最大深度,將拋出StackOverflowError異常。
如果虛擬機在擴展棧時無法申請到足夠的內存空間,則拋出OutOfMemoryError異常
這里需要注意當棧的大小越大可分配的線程數就越少。
3. 運行時常量池溢出
異常信息:java.lang.OutOfMemoryError:PermGen space
如果要向運行時常量池中添加內容,最簡單的做法就是使用String.intern()這個Native方法。該方法的作用是:如果池中已經包含一個等于此String的字符串,則返回代表池中這個字符串的String對象;否則,將此String對象包含的字符串添加到常量池中,并且返回此String對象的引用。由于常量池分配在方法區內,我們可以通過-XX:PermSize和-XX:MaxPermSize限制方法區的大小,從而間接限制其中常量池的容量。
4. 方法區溢出
方法區用于存放Class的相關信息,如類名、訪問修飾符、常量池、字段描述、方法描述等。
異常信息:java.lang.OutOfMemoryError:PermGen space
方法區溢出也是一種常見的內存溢出異常,一個類如果要被垃圾收集器回收,判定條件是很苛刻的。在經常動態生成大量Class的應用中,要特別注意這點。
---
**Java面向對象的三個特征與含義。**
繼承:繼承是從已有類得到繼承信息創建新類的過程。提供繼承信息的類被稱為父類(超類、基類);得到繼承信息的類被稱為子類(派生類)。繼承讓變化中的軟件系統有了一定的延續性,同時繼承也是封裝程序中可變因素的重要手段。
封裝:通常認為封裝是把數據和操作數據的方法綁定起來,對數據的訪問只能通過已定義的接口。面向對象的本質就是將現實世界描繪成一系列完全自治、封閉的對象。我們在類中編寫的方法就是對實現細節的一種封裝;我們編寫一個類就是對數據和數據操作的封裝。可以說,封裝就是隱藏一切可隱藏的東西,只向外界提供最簡單的編程接口(可以想想普通洗衣機和全自動洗衣機的差別,明顯全自動洗衣機封裝更好因此操作起來更簡單;我們現在使用的智能手機也是封裝得足夠好的,因為幾個按鍵就搞定了所有的事情)。
多態:多態性是指允許不同子類型的對象對同一消息作出不同的響應。簡單的說就是用同樣的對象引用調用同樣的方法但是做了不同的事情。多態性分為編譯時的多態性和運行時的多態性。如果將對象的方法視為對象向外界提供的服務,那么運行時的多態性可以解釋為:當A系統訪問B系統提供的服務時,B系統有多種提供服務的方式,但一切對A系統來說都是透明的(就像電動剃須刀是A系統,它的供電系統是B系統,B系統可以使用電池供電或者用交流電,甚至還有可能是太陽能,A系統只會通過B類對象調用供電的方法,但并不知道供電系統的底層實現是什么,究竟通過何種方式獲得了動力)。方法重載(overload)實現的是編譯時的多態性(也稱為前綁定),而方法重寫(override)實現的是運行時的多態性(也稱為后綁定)。運行時的多態是面向對象最精髓的東西,要實現多態需要做兩件事:1. 方法重寫(子類繼承父類并重寫父類中已有的或抽象的方法);2. 對象造型(用父類型引用引用子類型對象,這樣同樣的引用調用同樣的方法就會根據子類對象的不同而表現出不同的行為)。
---
**Override和Overload的含義與區別。**
Overload:顧名思義,就是Over(重新)——load(加載),所以中文名稱是重載。它可以表現類的多態性,可以是函數里面可以有相同的函數名但是參數名、類型不能相同;或者說可以改變參數、類型但是函數名字依然不變。
Override:就是ride(重寫)的意思,在子類繼承父類的時候子類中可以定義某方法與其父類有相同的名稱和參數,當子類在調用這一函數時自動調用子類的方法,而父類相當于被覆蓋(重寫)了。
方法的重寫Overriding和重載Overloading是Java多態性的不同表現。重寫Overriding是父類與子類之間多態性的一種表現,重載Overloading是一個類中多態性的一種表現。如果在子類中定義某方法與其父類有相同的名稱和參數,我們說該方法被重寫 (Overriding)。子類的對象使用這個方法時,將調用子類中的定義,對它而言,父類中的定義如同被“屏蔽”了。如果在一個類中定義了多個同名的方法,它們或有不同的參數個數或有不同的參數類型,則稱為方法的重載(Overloading)。Overloaded的方法是可以改變返回值的類型。
---
**Interface與abstract類的區別。**
抽象類和接口都不能夠實例化,但可以定義抽象類和接口類型的引用。一個類如果繼承了某個抽象類或者實現了某個接口都需要對其中的抽象方法全部進行實現,否則該類仍然需要被聲明為抽象類。接口比抽象類更加抽象,因為抽象類中可以定義構造器,可以有抽象方法和具體方法,而接口中不能定義構造器而且其中的方法全部都是抽象方法。抽象類中的成員可以是private、默認、protected、public的,而接口中的成員全都是public的。抽象類中可以定義成員變量,而接口中定義的成員變量實際上都是常量。有抽象方法的類必須被聲明為抽象類,而抽象類未必要有抽象方法。
---
**Static class 與non static class的區別。**
內部靜態類不需要有指向外部類的引用。但非靜態內部類需要持有對外部類的引用。非靜態內部類能夠訪問外部類的靜態和非靜態成員。靜態類不能訪問外部類的非靜態成員。他只能訪問外部類的靜態成員。一個非靜態內部類不能脫離外部類實體被創建,一個非靜態內部類可以訪問外部類的數據和方法,因為他就在外部類里面。
---
**java多態的實現原理。**
[http://blog.csdn.net/zzzhangzhun/article/details/51095075](http://blog.csdn.net/zzzhangzhun/article/details/51095075)
當JVM執行Java字節碼時,類型信息會存儲在方法區中,為了優化對象的調用方法的速度,方法區的類型信息會增加一個指針,該指針指向一個記錄該類方法的方法表,方法表中的每一個項都是對應方法的指針。
方法區:方法區和JAVA堆一樣,是各個線程共享的內存區域,用于存儲已被虛擬機加載的類信息、常量、靜態變量、即時編譯器編譯后的代碼等數據。
運行時常量池:它是方法區的一部分,Class文件中除了有類的版本、方法、字段等描述信息外,還有一項信息是常量池,用于存放編譯器生成的各種符號引用,這部分信息在類加載時進入方法區的運行時常量池中。
方法區的內存回收目標是針對常量池的回收及對類型的卸載。
方法表的構造
由于java的單繼承機制,一個類只能繼承一個父類,而所有的類又都繼承Object類,方法表中最先存放的是Object的方法,接下來是父類的方法,最后是該類本身的方法。如果子類改寫了父類的方法,那么子類和父類的那些同名的方法共享一個方法表項。
由于這樣的特性,使得方法表的偏移量總是固定的,例如,對于任何類來說,其方法表的equals方法的偏移量總是一個定值,所有繼承父類的子類的方法表中,其父類所定義的方法的偏移量也總是一個定值。
實例
假設Class A是Class B的子類,并且A改寫了B的方法的method(),那么B來說,method方法的指針指向B的method方法入口;對于A來說,A的方法表的method項指向自身的method而非父類的。
流程:調用方法時,虛擬機通過對象引用得到方法區中類型信息的方法表的指針入口,查詢類的方法表 ,根據實例方法的符號引用解析出該方法在方法表的偏移量,子類對象聲明為父類類型時,形式上調用的是父類的方法,此時虛擬機會從實際的方法表中找到方法地址,從而定位到實際類的方法。
注:所有引用為父類,但方法區的類型信息中存放的是子類的信息,所以調用的是子類的方法表。
---
**foreach與正常for循環效率對比。**
[http://904510742.iteye.com/blog/2118331](http://904510742.iteye.com/blog/2118331)
直接for循環效率最高,其次是迭代器和 ForEach操作。
作為語法糖,其實 ForEach 編譯成 字節碼之后,使用的是迭代器實現的,反編譯后,testForEach方法如下:
```
public static void testForEach(List list) {
for (Iterator iterator = list.iterator(); iterator.hasNext();) {
Object t = iterator.next();
Object obj = t;
}
}
```
可以看到,只比迭代器遍歷多了生成中間變量這一步,因為性能也略微下降了一些。
---
**反射機制**
JAVA反射機制是在運行狀態中, 對于任意一個類, 都能夠知道這個類的所有屬性和方法; 對于任意一個對象, 都能夠調用它的任意一個方法和屬性; 這種動態獲取的信息以及動態調用對象的方法的功能稱為java語言的反射機制.
主要作用有三:
運行時取得類的方法和字段的相關信息。
創建某個類的新實例(.newInstance())
取得字段引用直接獲取和設置對象字段,無論訪問修飾符是什么。
用處如下:
觀察或操作應用程序的運行時行為。
調試或測試程序,因為可以直接訪問方法、構造函數和成員字段。
通過名字調用不知道的方法并使用該信息來創建對象和調用方法。
---
**String類內部實現,能否改變String對象內容**
[String源碼分析](https://github.com/GeniusVJR/LearningNotes/blob/master/Part2/JavaSE/String源碼分析.md)
[http://blog.csdn.net/zhangjg_blog/article/details/18319521](http://blog.csdn.net/zhangjg_blog/article/details/18319521)
---
**try catch 塊,try里有return,finally也有return,如何執行**
[http://qing0991.blog.51cto.com/1640542/1387200](http://qing0991.blog.51cto.com/1640542/1387200)
---
**泛型的優缺點**
優點:
使用泛型類型可以最大限度地重用代碼、保護類型的安全以及提高性能。
泛型最常見的用途是創建集合類。
缺點:
在性能上不如數組快。
---
**泛型常用特點,List`<String>`能否轉為List`<Object>`**
能,但是利用類都繼承自Object,所以使用是每次調用里面的函數都要通過強制轉換還原回原來的類,這樣既不安全,運行速度也慢。
---
**解析XML的幾種方式的原理與特點:DOM、SAX、PULL。**
[http://www.cnblogs.com/HaroldTihan/p/4316397.html](http://www.cnblogs.com/HaroldTihan/p/4316397.html)
---
**Java與C++對比。**
[http://developer.51cto.com/art/201106/270422.htm](http://developer.51cto.com/art/201106/270422.htm)
---
**Java1.7與1.8新特性。**
[http://blog.chinaunix.net/uid-29618857-id-4416835.html](http://blog.chinaunix.net/uid-29618857-id-4416835.html)
---
**JNI的使用。**
[http://landerlyoung.github.io/blog/2014/10/16/java-zhong-jnide-shi-yong/](http://landerlyoung.github.io/blog/2014/10/16/java-zhong-jnide-shi-yong/)
---
###集合
**ArrayList、LinkedList、Vector的底層實現和區別**
* 從同步性來看,ArrayList和LinkedList是不同步的,而Vector是的。所以線程安全的話,可以使用ArrayList或LinkedList,可以節省為同步而耗費的開銷。但在多線程下,有時候就不得不使用Vector了。當然,也可以通過一些辦法包裝ArrayList、LinkedList,使我們也達到同步,但效率可能會有所降低。
* 從內部實現機制來講ArrayList和Vector都是使用Object的數組形式來存儲的。當你向這兩種類型中增加元素的時候,如果元素的數目超出了內部數組目前的長度它們都需要擴展內部數組的長度,Vector缺省情況下自動增長原來一倍的數組長度,ArrayList是原來的50%,所以最后你獲得的這個集合所占的空間總是比你實際需要的要大。如果你要在集合中保存大量的數據,那么使用Vector有一些優勢,因為你可以通過設置集合的初始化大小來避免不必要的資源開銷。
* ArrayList和Vector中,從指定的位置(用index)檢索一個對象,或在集合的末尾插入、刪除一個對象的時間是一樣的,可表示為O(1)。但是,如果在集合的其他位置增加或者刪除元素那么花費的時間會呈線性增長O(n-i),其中n代表集合中元素的個數,i代表元素增加或移除元素的索引位置,因為在進行上述操作的時候集合中第i和第i個元素之后的所有元素都要執行(n-i)個對象的位移操作。LinkedList底層是由雙向循環鏈表實現的,LinkedList在插入、刪除集合中任何位置的元素所花費的時間都是一樣的O(1),但它在索引一個元素的時候比較慢,為O(i),其中i是索引的位置,如果只是查找特定位置的元素或只在集合的末端增加、移除元素,那么使用Vector或ArrayList都可以。如果是對其它指定位置的插入、刪除操作,最好選擇LinkedList。
**HashMap和HashTable的底層實現和區別,兩者和ConcurrentHashMap的區別。**
[http://blog.csdn.net/xuefeng0707/article/details/40834595](http://blog.csdn.net/xuefeng0707/article/details/40834595)
HashTable線程安全則是依靠方法簡單粗暴的sychronized修飾,HashMap則沒有相關的線程安全問題考慮。。
在以前的版本貌似ConcurrentHashMap引入了一個“分段鎖”的概念,具體可以理解為把一個大的Map拆分成N個小的HashTable,根據key.hashCode()來決定把key放到哪個HashTable中。在ConcurrentHashMap中,就是把Map分成了N個Segment,put和get的時候,都是現根據key.hashCode()算出放到哪個Segment中。
通過把整個Map分為N個Segment(類似HashTable),可以提供相同的線程安全,但是效率提升N倍。
---
**HashMap的hashcode的作用?什么時候需要重寫?如何解決哈希沖突?查找的時候流程是如何?**
[從源碼分析HashMap](http://blog.csdn.net/codeemperor/article/details/51351247)
---
**Arraylist和HashMap如何擴容?負載因子有什么作用?如何保證讀寫進程安全?**
[http://m.blog.csdn.net/article/details?id=48956087](http://m.blog.csdn.net/article/details?id=48956087)
[http://hovertree.com/h/bjaf/2jdr60li.htm](http://hovertree.com/h/bjaf/2jdr60li.htm)
ArrayList 本身不是線程安全的。
所以正確的做法是去用 java.util.concurrent 里的 CopyOnWriteArrayList 或者某個同步的 Queue 類。
HashMap實現不是同步的。如果多個線程同時訪問一個哈希映射,而其中至少一個線程從結構上修改了該映射,則它必須 保持外部同步。(結構上的修改是指添加或刪除一個或多個映射關系的任何操作;僅改變與實例已經包含的鍵關聯的值不是結構上的修改。)這一般通過對自然封裝該映射的對象進行同步操作來完成。如果不存在這樣的對象,則應該使用 Collections.synchronizedMap 方法來“包裝”該映射。最好在創建時完成這一操作,以防止對映射進行意外的非同步訪問.
---
**TreeMap、HashMap、LinkedHashMap的底層實現區別。**
[http://blog.csdn.net/lolashe/article/details/20806319](http://blog.csdn.net/lolashe/article/details/20806319)
---
**Collection包結構,與Collections的區別。**
Collection是一個接口,它是Set、List等容器的父接口;Collections是一個工具類,提供了一系列的靜態方法來輔助容器操作,這些方法包括對容器的搜索、排序、線程安全化等等。
---
**Set、List之間的區別是什么?**
[http://developer.51cto.com/art/201309/410205_all.htm](http://developer.51cto.com/art/201309/410205_all.htm)
---
**Map、Set、List、Queue、Stack的特點與用法。**
[http://www.cnblogs.com/yumo/p/4908718.html](http://www.cnblogs.com/yumo/p/4908718.html)
Collection 是對象集合, Collection 有兩個子接口 List 和 Set
List 可以通過下標 (1,2..) 來取得值,值可以重復
而 Set 只能通過游標來取值,并且值是不能重復的
ArrayList , Vector , LinkedList 是 List 的實現類
ArrayList 是線程不安全的, Vector 是線程安全的,這兩個類底層都是由數組實現的
LinkedList 是線程不安全的,底層是由鏈表實現的
Map 是鍵值對集合
HashTable 和 HashMap 是 Map 的實現類
HashTable 是線程安全的,不能存儲 null 值
HashMap 不是線程安全的,可以存儲 null 值
Stack類:繼承自Vector,實現一個后進先出的棧。提供了幾個基本方法,push、pop、peak、empty、search等。
Queue接口:提供了幾個基本方法,offer、poll、peek等。已知實現類有LinkedList、PriorityQueue等。
- JavaSE(Java基礎)
- Java基礎知識
- Java中的內存泄漏
- String源碼分析
- Java集合結構
- ArrayList源碼剖析
- HashMap源碼剖析
- Hashtable簡介
- Vector源碼剖析
- LinkedHashMap簡介
- LinkedList簡介
- JVM(Java虛擬機)
- JVM基礎知識
- JVM類加載機制
- Java內存區域與內存溢出
- 垃圾回收算法
- Java并發(JavaConcurrent)
- Java并發基礎知識
- 生產者和消費者問題
- Thread和Runnable實現多線程的區別
- 線程中斷
- 守護線程與阻塞線程的情況
- Synchronized
- 多線程環境中安全使用集合API
- 實現內存可見的兩種方法比較:加鎖和volatile變量
- 死鎖
- 可重入內置鎖
- 使用wait/notify/notifyAll實現線程間通信
- NIO
- 數據結構(DataStructure)
- 數組
- 棧和隊列
- Algorithm(算法)
- 排序
- 選擇排序
- 冒泡排序
- 快速排序
- 歸并排序
- 查找
- 順序查找
- 折半查找
- Network(網絡)
- TCP/UDP
- HTTP
- Socket
- OperatingSystem(操作系統)
- Linux系統的IPC
- android中常用設計模式
- 面向對象六大原則
- 單例模式
- Builder模式
- 原型模式
- 簡單工廠
- 策略模式
- 責任鏈模式
- 觀察者模式
- 代理模式
- 適配器模式
- 外觀模式
- Android(安卓面試點)
- Android基礎知識
- Android內存泄漏總結
- Handler內存泄漏分析及解決
- Android性能優化
- ListView詳解
- RecyclerView和ListView的異同
- AsyncTask源碼分析
- 插件化技術
- 自定義控件
- ANR問題
- Art和Dalvik的區別
- Android關于OOM的解決方案
- Fragment
- SurfaceView
- Android幾種進程
- APP啟動過程
- 圖片三級緩存
- Bitmap的分析與使用
- 熱修復的原理
- AIDL
- Binder機制
- Zygote和System進程的啟動過程
- Android中的MVC,MVP和MVVM
- MVP
- Android開機過程
- EventBus用法詳解
- 查漏補缺
- Git操作