
# 決策樹
> 原文: [https://pythonbasics.org/decision-tree/](https://pythonbasics.org/decision-tree/)
決策樹是最流行的監督式機器學習算法之一。
是從觀察到結論的預測模型。 觀察結果以分支表示,結論以葉子表示。
如果模型的目標變量可以采用離散值集,則為分類樹。
如果模型的目標變量可以采用連續值,則為回歸樹。
決策樹在統計和數據挖掘中也很常見。 這是一個簡單但有用的機器學習結構。
## 決策樹
### 簡介
如何理解決策樹? 讓我們舉一個二進制的例子!
在計算機科學中,樹木從上到下倒置生長。
最重要的問題是稱為根節點的問題。 就像真正的樹木一樣,一切都從那里開始。
該問題有兩個可能的答案,因此答案(在這種情況下)是從樹中引出的兩個分支節點。
所有不是根或分支的東西都是葉子。 葉子節點可以填充其他答案或條件。 離開也可以稱為決策。
您可以重復此過程,直到“決策樹”完成為止。 從理論上講,就是這么簡單。
### 算法
算法將其處理為:
> 決策樹具有對象,而對象具有語句。
> 每個語句都有特征。
> 特征是對象的屬性。
> 算法會研究此過程,直到完成每個語句和每個特征。
要以編程語言使用決策樹,請執行以下步驟:
1. 呈現數據集。
2. 訓練模型,從描述性特征和目標特征中學習。
3. 繼續樹直到完成一個標準。
4. 創建代表預測的葉節點。
5. 顯示實例并沿著樹運行,直到到達葉節點。
做完了!
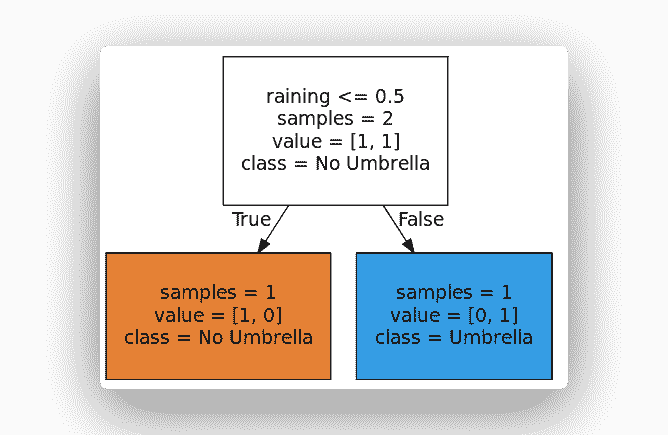
### 數據集
我們從一個數據集開始
| 下雨 | 決策 |
| --- | --- |
| 否 | 不打傘 |
| 是 | 打傘 |
可以簡化為:
| 下雨 | 決策 |
| --- | --- |
| 0 | 0 |
| 1 | 1 |
因此,相應的`X`(特征)和`Y`(決策/標簽)為:
```py
X = [[0], [1]]
Y = [0, 1]
```
### 決策樹代碼
Sklearn 支持開箱即用的決策樹。
然后,您可以運行以下代碼:
```py
from sklearn import tree
from sklearn.model_selection import train_test_split
import numpy as np
# Create Decision Tree
features = ['raining']
X = [[0], [1]]
Y = [0, 1]
clf = tree.DecisionTreeClassifier()
clf.fit(X,Y)
# Visualize Tree
dotfile = open("dtree.dot", 'w')
tree.export_graphviz(clf, out_file = dotfile, feature_names=features, filled=True, round\
ed=True, impurity=False, class_names=['No Umbrella','Umbrella'])
dotfile.close()
```
這將創建樹并輸出一個點文件。 您可以使用 [Webgraphviz](http://webgraphviz.com/) 通過在其中粘貼點代碼來形象化樹。
創建模型將能夠對未知實例進行預測,因為它可以對已知描述性特征與已知目標特征之間的關系進行建模。
```py
print( clf.predict([[0]]) )
```
### 重要概念
最后,快速回顧一下決策樹和機器學習的 4 個重要概念。
1. **期望值**:表示隨機變量的期望值。 對決策樹進行了預期價值分析,以確定風險的嚴重性。 為此,我們必須以 0.0 到 1.0 之間的數字來衡量風險的可能性。
2. **熵**:測量信息。 是指定新實例是否應歸為一個或另一個實例所需的預期信息量。 熵的思想是相對于可能的分類類別量化概率分布的不確定性。
3. **準確性**:是做出的正確預測數除以做出的預測總數。 我們要做的是檢查機器學習模型的準確性。
4. **過擬合**:之所以發生,是因為訓練模型試圖盡可能地擬合訓練數據。 為了防止這種情況,請嘗試減少數據中的噪音。
這就是決策樹和機器學習的基礎知識!
[下載示例和練習](https://gum.co/MnRYU)
- 介紹
- 學習 python 的 7 個理由
- 為什么 Python 很棒
- 學習 Python
- 入門
- 執行 Python 腳本
- 變量
- 字符串
- 字符串替換
- 字符串連接
- 字符串查找
- 分割
- 隨機數
- 鍵盤輸入
- 控制結構
- if語句
- for循環
- while循環
- 數據與操作
- 函數
- 列表
- 列表操作
- 排序列表
- range函數
- 字典
- 讀取文件
- 寫入文件
- 嵌套循環
- 切片
- 多個返回值
- 作用域
- 時間和日期
- try except
- 如何使用pip和 pypi
- 面向對象
- 類
- 構造函數
- 獲取器和設置器
- 模塊
- 繼承
- 靜態方法
- 可迭代對象
- Python 類方法
- 多重繼承
- 高級
- 虛擬環境
- 枚舉
- Pickle
- 正則表達式
- JSON 和 python
- python 讀取 json 文件
- 裝飾器
- 網絡服務器
- 音頻
- 用 Python 播放聲音
- python 文字轉語音
- 將 MP3 轉換為 WAV
- 轉錄音頻
- Tkinter
- Tkinter
- Tkinter 按鈕
- Tkinter 菜單
- Tkinter 標簽
- Tkinter 圖片
- Tkinter 畫布
- Tkinter 復選框
- Tkinter 輸入框
- Tkinter 文件對話框
- Tkinter 框架
- Tkinter 列表框
- Tkinter 消息框
- Tkinter 單選按鈕
- Tkinter 刻度
- 繪圖
- Matplotlib 條形圖
- Matplotlib 折線圖
- Seaborn 分布圖
- Seaborn 繪圖
- Seaborn 箱形圖
- Seaborn 熱力圖
- Seaborn 直線圖
- Seaborn 成對圖
- Seaborn 調色板
- Seaborn Pandas
- Seaborn 散點圖
- Plotly
- PyQt
- PyQt
- 安裝 PyQt
- PyQt Hello World
- PyQt 按鈕
- PyQt QMessageBox
- PyQt 網格
- QLineEdit
- PyQT QPixmap
- PyQt 組合框
- QCheckBox
- QSlider
- 進度條
- PyQt 表格
- QVBoxLayout
- PyQt 樣式
- 編譯 PyQt 到 EXE
- QDial
- QCheckBox
- PyQt 單選按鈕
- PyQt 分組框
- PyQt 工具提示
- PyQt 工具箱
- PyQt 工具欄
- PyQt 菜單欄
- PyQt 標簽小部件
- PyQt 自動補全
- PyQt 列表框
- PyQt 輸入對話框
- Qt Designer Python
- 機器學習
- 數據科學
- 如何從機器學習和 AI 認真地起步
- 為什么要使用 Python 進行機器學習?
- 機器學習庫
- 什么是機器學習?
- 區分機器學習,深度學習和 AI?
- 機器學習
- 機器學習算法比較
- 為什么要使用 Scikit-Learn?
- 如何在 Python 中加載機器學習數據
- 機器學習分類器
- 機器學習回歸
- Python 中的多項式回歸
- 決策樹
- k 最近鄰
- 訓練測試拆分
- 人臉檢測
- 如何為 scikit-learn 機器學習準備數據
- Selenium
- Selenium 瀏覽器
- Selenium Cookie
- Selenium 執行 JavaScript
- Selenium 按 ID 查找元素
- Selenium 無頭 Firefox
- Selenium Firefox
- Selenium 獲取 HTML
- Selenium 鍵盤
- Selenium 最大化
- Selenium 截圖
- Selenium 向下滾動
- Selenium 切換到窗口
- Selenium 等待頁面加載
- Flask 教程
- Flask 教程:Hello World
- Flask 教程:模板
- Flask 教程:路由