
# 概述
原文鏈接 : [http://zeppelin.apache.org/docs/0.7.2/manual/interpreters.html](http://zeppelin.apache.org/docs/0.7.2/manual/interpreters.html)
譯文鏈接 : [http://www.apache.wiki/pages/viewpage.action?pageId=10030641](http://www.apache.wiki/pages/viewpage.action?pageId=10030641)
貢獻者 : [片刻](/display/~jiangzhonglian) [ApacheCN](/display/~apachecn) [Apache中文網](/display/~apachechina)
在本部分中,我們將解釋在齊柏林的翻譯,解釋器組和解釋器設置的作用。Zeppelin解釋器的概念允許將任何語言/數據處理后端插入到Zeppelin中。
目前,Zeppelin支持許多解釋器,如Scala(使用Apache Spark),Python(帶有Apache Spark),Spark SQL,JDBC,Markdown,Shell等。
## 什么是Zeppelin解釋器
Zeppelin Interpreter是一款插件,可讓Zeppelin用戶使用特定的語言/數據處理后端。例如,要在Zeppelin中使用Scala代碼,您需要`%spark`解釋器。
當您`+Create`在解釋器頁面中單擊按鈕時,解釋器下拉列表框將顯示您的服務器上的所有可用的解釋器。
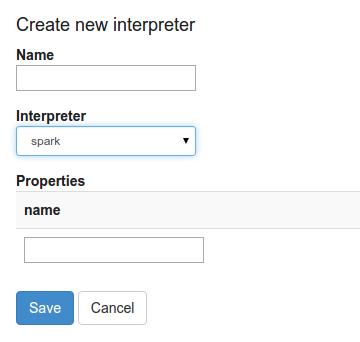
## 什么是解釋器設置?
Zeppelin解釋器設置是Zeppelin服務器上給定解釋器的配置。例如,hive JDBC解釋器連接到Hive服務器需要這些屬性。
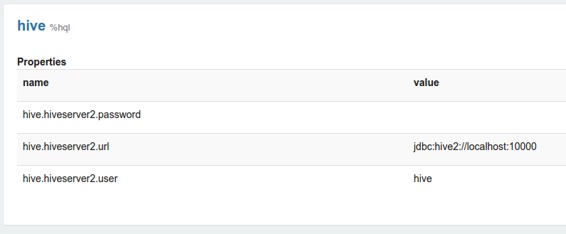
當屬性名稱由高位字符,數字和下劃線組成([A-Z_0-9])時,屬性將導出為環境變量。否則將屬性設置為JVM屬性。
每個筆記本都可以使用筆記本電腦右上角的設置圖標綁定多個解釋器設置。
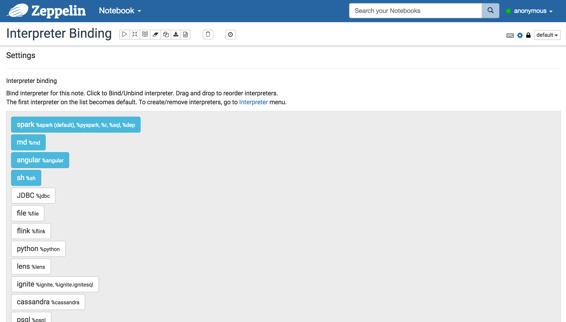
## 什么是解釋器組?
每個解釋器都屬于**解釋器小組**。解釋器組是start/stop解釋器的單位。默認情況下,每個解釋器都屬于單個組,但該組可能包含更多的解釋器。例如,Spark解釋器組包括Spark支持,pySpark,Spark SQL和依賴加載器。
技術上來說,來自同一組的Zeppelin口譯員正在運行在同一個JVM中。有關更多信息,請[在這里](http://zeppelin.apache.org/docs/0.7.1/development/writingzeppelininterpreter.html)檢驗。
每個解釋器都屬于一個單一的團體,并且一起注冊。他們的所有屬性都列在下面的解釋器設置中。
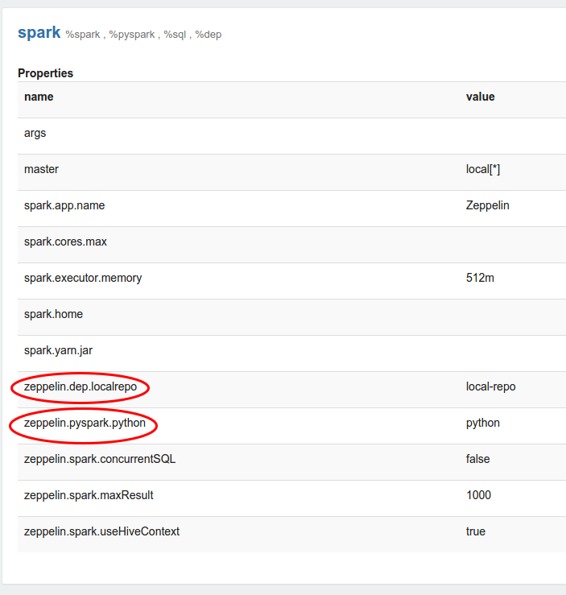
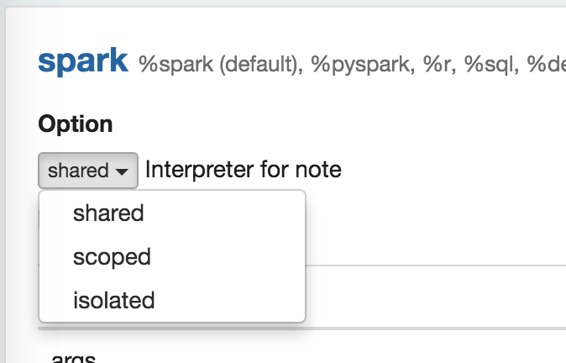
## 解釋器綁定模式
每個解釋器設置可以選擇“共享”,“范圍”,“隔離”解釋器綁定模式之一。在“共享”模式下,綁定到解釋器設置的每個筆記本都將共享單個解釋器實例。在“范圍”模式下,每個筆記本將在相同的解釋器過程中創建新的解釋器實例。在“隔離”模式下,每個筆記本都會創建新的口譯過程。
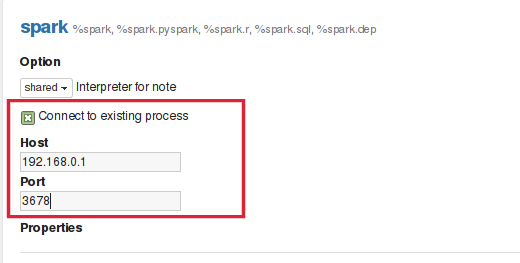
## 連接到現有的遠程解釋器
Zeppelin用戶可以開始在其服務中嵌入解釋器線程。這將為用戶提供靈活性,以便在遠程主機上啟動解釋器。要與您的服務一起開始解釋器,您必須創建一個實例`RemoteInterpreterServer`并啟動它,如下所示:
```
RemoteInterpreterServer interpreter=new RemoteInterpreterServer(3678);
// Here, 3678 is the port on which interpreter will listen.
interpreter.start()
```
```
上面的代碼將會在您的進程中啟動解釋器線程。解釋器啟動后,您可以通過檢查連接到現有進程復選框來配置zeppelin連接到RemoteInterpreter?,然后提供如下圖所示的解釋器進程正在偵聽的主機和端口:
```
- 快速入門
- 什么是Apache Zeppelin?
- 安裝
- 配置
- 探索Apache Zeppelin UI
- 教程
- 動態表單
- 發表你的段落
- 自定義Zeppelin主頁
- 升級Zeppelin版本
- 從源碼編譯
- 使用Flink和Spark Clusters安裝Zeppelin教程
- 解釋器
- 概述
- 解釋器安裝
- 解釋器依賴管理
- 解釋器的模擬用戶
- 解釋員執行Hook(實驗)
- Alluxio 解釋器
- Beam 解釋器
- BigQuery 解釋器
- Cassandra CQL 解釋器
- Elasticsearch 解釋器
- Flink 解釋器
- Geode/Gemfire OQL 解釋器
- HBase Shell 解釋器
- HDFS文件系統 解釋器
- Hive 解釋器
- Ignite 解釋器
- JDBC通用 解釋器
- Kylin 解釋器
- Lens 解釋器
- Livy 解釋器
- Markdown 解釋器
- Pig 解釋器
- PostgreSQL, HAWQ 解釋器
- Python 2&3解釋器
- R 解釋器
- Scalding 解釋器
- Scio 解釋器
- Shell 解釋器
- Spark 解釋器
- 系統顯示
- 系統基本顯示
- 后端Angular API
- 前端Angular API
- 更多
- 筆記本存儲
- REST API
- 解釋器 API
- 筆記本 API
- 筆記本資源 API
- 配置 API
- 憑據 API
- Helium API
- Security ( 安全 )
- Shiro 授權
- 筆記本 授權
- 數據源 授權
- Helium 授權
- Advanced ( 高級 )
- Zeppelin on Vagrant VM ( Zeppelin 在 Vagrant 虛擬機上 )
- Zeppelin on Spark Cluster Mode( Spark 集群模式下的 Zeppelin )
- Zeppelin on CDH ( Zeppelin 在 CDH 上 )
- Contibute ( 貢獻 )
- Writing a New Interpreter ( 寫一個新的解釋器 )
- Writing a new Visualization (Experimental) ( 編寫新的可視化(實驗) )
- Writing a new Application (Experimental) ( 寫一個新的應用程序( 實驗 ) )
- Contributing to Apache Zeppelin ( Code ) ( 向 Apache Zeppelin 貢獻( 代碼 ) )
- Contributing to Apache Zeppelin ( Website ) ( 向 Apache Zeppelin 貢獻(website) )