
# Spark 解釋器
原文鏈接 : [http://zeppelin.apache.org/docs/0.7.2/interpreter/spark.html](http://zeppelin.apache.org/docs/0.7.2/interpreter/spark.html)
譯文鏈接 : [http://www.apache.wiki/pages/viewpage.action?pageId=10030923](http://www.apache.wiki/pages/viewpage.action?pageId=10030923)
貢獻者 : [片刻](/display/~jiangzhonglian) [ApacheCN](/display/~apachecn) [Apache中文網](/display/~apachechina)
## 概述
[Apache Spark](http://spark.apache.org/)是一種快速和通用的集群計算系統。它提供Java,Scala,Python和R中的高級API,以及支持一般執行圖的優化引擎。Zeppelin支持Apache Spark,Spark解釋器組由5個解釋器組成。
| 名稱 | 類 | 描述 |
| --- | --- | --- |
| %spark | SparkInterpreter | 創建一個SparkContext并提供Scala環境 |
| %spark.pyspark | PySparkInterpreter | 提供Python環境 |
| %spark.r | SparkRInterpreter | 提供具有SparkR支持的R環境 |
| %spark.sql | SparkSQLInterpreter | 提供SQL環境 |
| %spark.dep | DepInterpreter | 依賴加載器 |
[?](http://zeppelin.apache.org/docs/0.7.1/interpreter/spark.html#configuration)
## 配置
Spark解釋器可以配置為由Zeppelin提供的屬性。您還可以設置表中未列出的其他Spark屬性。有關其他屬性的列表,請參閱[Spark可用屬性](http://spark.apache.org/docs/latest/configuration.html#available-properties)。
| 屬性 | 默認 | 描述 |
| --- | --- | --- |
| ARGS | ? | Spark命令行參考 |
| master | local[*] | Spark master uri.
例如:spark://masterhost:7077 |
| spark.app.name | Zeppelin | Spark應用的名稱。 |
| spark.cores.max | ? | 要使用的核心總數。
空值使用所有可用的核心。 |
| spark.executor.memory | 1g | 每個worker實例的執行程序內存。
ex)512m,32g |
| zeppelin.dep.additionalRemoteRepository | spark-packages,?
[http://dl.bintray.com/spark-packages/maven](http://dl.bintray.com/spark-packages/maven),?
false; | ?`id,remote-repository-URL,is-snapshot;`
每個遠程存儲庫的列表。 |
| zeppelin.dep.localrepo | local-repo | 依賴加載器的本地存儲庫 |
| zeppelin.pyspark.python | python | Python命令來運行pyspark |
| zeppelin.spark.concurrentSQL | python | 如果設置為true,則同時執行多個SQL。 |
| zeppelin.spark.maxResult | 1000 | 要顯示的Spark SQL結果的最大數量。 |
| zeppelin.spark.printREPLOutput | true | 打印REPL輸出 |
| zeppelin.spark.useHiveContext | true | 如果它是真的,使用HiveContext而不是SQLContext。 |
| zeppelin.spark.importImplicit | true | 導入含義,UDF集合和sql如果設置為true。 |
沒有任何配置,Spark解釋器在本地模式下開箱即用。但是,如果要連接到Spark群集,則需要按照以下兩個簡單步驟進行操作。
### 1.導出SPARK_HOME
在`conf/zeppelin-env.sh`,導出`SPARK_HOME`環境變量與您的Spark安裝路徑。
例如,
```
export SPARK_HOME=/usr/lib/spark?
```
您可以選擇設置更多的環境變量
```
# set hadoop conf dir
export HADOOP_CONF_DIR=/usr/lib/hadoop
# set options to pass spark-submit command
export SPARK_SUBMIT_OPTIONS="--packages com.databricks:spark-csv_2.10:1.2.0"
# extra classpath. e.g. set classpath for hive-site.xml
export ZEPPELIN_INTP_CLASSPATH_OVERRIDES=/etc/hive/conf?
```
對于Windows,確保你`winutils.exe`在`%HADOOP_HOME%\bin`。有關詳細信息,請參閱[在Windows上運行Hadoop的問題](https://wiki.apache.org/hadoop/WindowsProblems)。
### 2.在“解釋器”菜單中設置主機
啟動Zeppelin后,轉到**解釋器**菜單并在Spark解釋器設置中編輯**主**屬性。該值可能因您的Spark群集部署類型而異。
例如,
* **local[*]**? 本地模式
* **spark://master:7077**?standalone?集群模式
* **yarn-client**?Yarn 客戶端模式
* **mesos://host:5050**?Mesos 集群模式
而已。Zeppelin將使用任何版本的Spark和任何部署類型,而不用這種方式重建Zeppelin。有關Spark&Zeppelin版本兼容性的更多信息,請參閱[Zeppelin下載頁面](https://zeppelin.apache.org/download.html)中的“可用的口譯員”部分。
> 請注意,不導出`SPARK_HOME`,它以本地模式運行,包含版本的Spark。附帶的版本可能因構建配置文件而異。
## SparkContext,SQLContext,SparkSession,ZeppelinContext
SparkContext,SQLContext和ZeppelinContext會自動創建并顯示為變量名`sc`,`sqlContext`并`z`分別在Scala,Python和R環境中公開。從0.6.1起,`spark`當您使用Spark 2.x時,SparkSession可以作為變量使用。
> 請注意,Scala / Python / R環境共享相同的SparkContext,SQLContext和ZeppelinContext實例。
## 依賴管理?
在Spark解釋器中加載外部庫有兩種方法。首先是使用解釋器設置菜單,其次是加載Spark屬性。
### 1.通過解釋器設置設置依賴關系
有關詳細信息,請參閱[解釋器依賴管理](http://www.apache.wiki/pages/viewpage.action?pageId=10030743)。
### 2.加載Spark屬性
一旦`SPARK_HOME`被設置`conf/zeppelin-env.sh`,Zeppelin使用`spark-submit`作為Spark解釋賽跑者。`spark-submit`支持兩種方式來加載配置。第一個是命令行選項,如--master和飛艇可以通過這些選項`spark-submit`通過導出`SPARK_SUBMIT_OPTIONS`在`conf/zeppelin-env.sh`。二是從中讀取配置選項`SPARK_HOME/conf/spark-defaults.conf`。用戶可以設置分發庫的Spark屬性有:
| 火花defaults.conf | SPARK_SUBMIT_OPTIONS | 描述 |
| --- | --- | --- |
| spark.jars | --jars | 包含在驅動程序和執行器類路徑上的本地jar的逗號分隔列表。 |
| spark.jars.packages | --packages | 逗號分隔列表,用于包含在驅動程序和執行器類路徑上的jar的maven坐標。將搜索當地的maven repo,然后搜索maven中心和由–repositories提供的任何其他遠程存儲庫。坐標的格式應該是`groupId:artifactId:version`。 |
| spark.files | --files | 要放置在每個執行器的工作目錄中的逗號分隔的文件列表。 |
以下是幾個例子:
* `SPARK_SUBMIT_OPTIONS`?在?`conf/zeppelin-env.sh`
```
export SPARK_SUBMIT_OPTIONS="--packages com.databricks:spark-csv_2.10:1.2.0 --jars /path/mylib1.jar,/path/mylib2.jar --files /path/mylib1.py,/path/mylib2.zip,/path/mylib3.egg"?
```
* `SPARK_HOME/conf/spark-defaults.conf`
```
spark.jars /path/mylib1.jar,/path/mylib2.jar
spark.jars.packages com.databricks:spark-csv_2.10:1.2.0
spark.files /path/mylib1.py,/path/mylib2.egg,/path/mylib3.zip ?
```
### 3.通過%spark.dep解釋器加載動態依賴關系
> 注:`%spark.dep`解釋負載庫`%spark`和`%spark.pyspark`而不是?`%spark.sql`翻譯。所以我們建議你改用第一個選項。
當你的代碼需要外部庫,而不是下載/復制/重新啟動Zeppelin,你可以使用`%spark.dep`解釋器輕松地完成以下工作。
* 從maven庫遞歸加載庫
* 從本地文件系統加載庫
* 添加額外的maven倉庫
* 自動將庫添加到SparkCluster(可以關閉)
解釋器利用Scala環境。所以你可以在這里編寫任何Scala代碼。需要注意的是`%spark.dep`解釋前應使用`%spark`,`%spark.pyspark`,`%spark.sql`。
這是用法
```
%spark.dep
z.reset() // clean up previously added artifact and repository
// add maven repository
z.addRepo("RepoName").url("RepoURL")
// add maven snapshot repository
z.addRepo("RepoName").url("RepoURL").snapshot()
// add credentials for private maven repository
z.addRepo("RepoName").url("RepoURL").username("username").password("password")
// add artifact from filesystem
z.load("/path/to.jar")
// add artifact from maven repository, with no dependency
z.load("groupId:artifactId:version").excludeAll()
// add artifact recursively
z.load("groupId:artifactId:version")
// add artifact recursively except comma separated GroupID:ArtifactId list
z.load("groupId:artifactId:version").exclude("groupId:artifactId,groupId:artifactId, ...")
// exclude with pattern
z.load("groupId:artifactId:version").exclude(*)
z.load("groupId:artifactId:version").exclude("groupId:artifactId:*")
z.load("groupId:artifactId:version").exclude("groupId:*")
// local() skips adding artifact to spark clusters (skipping sc.addJar())
z.load("groupId:artifactId:version").local()?
```
## ZeppelinContext
Zeppelin?在Scala / Python環境中自動注入`ZeppelinContext`變量`z`。`ZeppelinContext`提供了一些額外的功能和實用程序。
### 對象交換
`ZeppelinContext`擴展地圖,它在Scala和Python環境之間共享。所以你可以把Scala的一些對象從Python中讀出來,反之亦然。
**Scala**
```
// Put object from scala
%spark
val myObject = ...
z.put("objName", myObject)
// Exchanging data frames
myScalaDataFrame = ...
z.put("myScalaDataFrame", myScalaDataFrame)
val myPythonDataFrame = z.get("myPythonDataFrame").asInstanceOf[DataFrame]?
```
**Python** ?展開原碼
```
# Get object from python
%spark.pyspark
myObject = z.get("objName")
# Exchanging data frames
myPythonDataFrame = ...
z.put("myPythonDataFrame", postsDf._jdf)
myScalaDataFrame = DataFrame(z.get("myScalaDataFrame"), sqlContext)?
```
### 表格創作
`ZeppelinContext`提供了創建表單的功能。在Scala和Python環境中,您可以以編程方式創建表單。
**Scala**
```
%spark
/* Create text input form */
z.input("formName")
/* Create text input form with default value */
z.input("formName", "defaultValue")
/* Create select form */
z.select("formName", Seq(("option1", "option1DisplayName"),
("option2", "option2DisplayName")))
/* Create select form with default value*/
z.select("formName", "option1", Seq(("option1", "option1DisplayName"),
("option2", "option2DisplayName")))?
```
```
%spark.pyspark
# Create text input form
z.input("formName")
# Create text input form with default value
z.input("formName", "defaultValue")
# Create select form
z.select("formName", [("option1", "option1DisplayName"),
("option2", "option2DisplayName")])
# Create select form with default value
z.select("formName", [("option1", "option1DisplayName"),
("option2", "option2DisplayName")], "option1")?
```
```
在sql環境中,可以在簡單的模板中創建表單。
```
```
%spark.sql
select * from ${table=defaultTableName} where text like '%${search}%'?
```
要了解有關動態表單的更多信息,請檢查[Zeppelin 動態表單](http://www.apache.wiki/pages/viewpage.action?pageId=10030585)。
[?](http://zeppelin.apache.org/docs/0.7.1/interpreter/spark.html#matplotlib-integration-pyspark)
## Matplotlib集成(pyspark)
這兩個`python`和`pyspark`解釋器都內置了對內聯可視化的支持`matplotlib`,這是一個流行的python繪圖庫。更多細節可以在[python解釋器文檔中找到](http://zeppelin.apache.org/docs/0.7.1/interpreter/python.html),因為matplotlib的支持是相同的。通過利用齊柏林內置的[角度顯示系統](http://zeppelin.apache.org/docs/0.7.1/displaysystem/back-end-angular.html),可以通過pyspark進行更先進的交互式繪圖,如下所示:

## 解釋器設置選項
您可以選擇其中之一`shared`,`scoped`以及`isolated`配置Spark解釋器的選項。Spark解釋器為每個筆記本創建分離的Scala編譯器,但在`scoped`模式(實驗)中共享一個SparkContext。它在每個筆記本`isolated`模式下創建分離的SparkContext?。
## 用Kerberos設置Zeppelin
使用Zeppelin,Kerberos Key Distribution Center(KDC)和Spark on YARN進行邏輯設置:
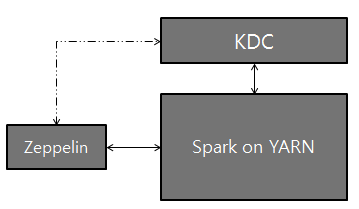
### 配置設置
1. 在安裝Zeppelin的服務器上,安裝Kerberos客戶端模塊和配置,krb5.conf。這是為了使服務器與KDC進行通信。
2. 設置`SPARK_HOME`在`[ZEPPELIN_HOME]/conf/zeppelin-env.sh`使用火花提交(此外,您可能需要設置`export HADOOP_CONF_DIR=/etc/hadoop/conf`)
3. 將以下兩個屬性添加到Spark configuration(`[SPARK_HOME]/conf/spark-defaults.conf`)中:
```
spark.yarn.principal
spark.yarn.keytab
```
> **注意:**如果您沒有訪問以上spark-defaults.conf文件的權限,可以選擇地,您可以通過Zeppelin UI中的“解釋器”選項卡將上述行添加到“Spark Interpreter”設置。
4. 而已。玩Zeppelin!
- 快速入門
- 什么是Apache Zeppelin?
- 安裝
- 配置
- 探索Apache Zeppelin UI
- 教程
- 動態表單
- 發表你的段落
- 自定義Zeppelin主頁
- 升級Zeppelin版本
- 從源碼編譯
- 使用Flink和Spark Clusters安裝Zeppelin教程
- 解釋器
- 概述
- 解釋器安裝
- 解釋器依賴管理
- 解釋器的模擬用戶
- 解釋員執行Hook(實驗)
- Alluxio 解釋器
- Beam 解釋器
- BigQuery 解釋器
- Cassandra CQL 解釋器
- Elasticsearch 解釋器
- Flink 解釋器
- Geode/Gemfire OQL 解釋器
- HBase Shell 解釋器
- HDFS文件系統 解釋器
- Hive 解釋器
- Ignite 解釋器
- JDBC通用 解釋器
- Kylin 解釋器
- Lens 解釋器
- Livy 解釋器
- Markdown 解釋器
- Pig 解釋器
- PostgreSQL, HAWQ 解釋器
- Python 2&3解釋器
- R 解釋器
- Scalding 解釋器
- Scio 解釋器
- Shell 解釋器
- Spark 解釋器
- 系統顯示
- 系統基本顯示
- 后端Angular API
- 前端Angular API
- 更多
- 筆記本存儲
- REST API
- 解釋器 API
- 筆記本 API
- 筆記本資源 API
- 配置 API
- 憑據 API
- Helium API
- Security ( 安全 )
- Shiro 授權
- 筆記本 授權
- 數據源 授權
- Helium 授權
- Advanced ( 高級 )
- Zeppelin on Vagrant VM ( Zeppelin 在 Vagrant 虛擬機上 )
- Zeppelin on Spark Cluster Mode( Spark 集群模式下的 Zeppelin )
- Zeppelin on CDH ( Zeppelin 在 CDH 上 )
- Contibute ( 貢獻 )
- Writing a New Interpreter ( 寫一個新的解釋器 )
- Writing a new Visualization (Experimental) ( 編寫新的可視化(實驗) )
- Writing a new Application (Experimental) ( 寫一個新的應用程序( 實驗 ) )
- Contributing to Apache Zeppelin ( Code ) ( 向 Apache Zeppelin 貢獻( 代碼 ) )
- Contributing to Apache Zeppelin ( Website ) ( 向 Apache Zeppelin 貢獻(website) )