
# Zeppelin on CDH ( Zeppelin 在 CDH 上 )
原文鏈接 : [http://zeppelin.apache.org/docs/0.7.2/install/cdh.html](http://zeppelin.apache.org/docs/0.7.2/install/cdh.html)
譯文鏈接 : [http://www.apache.wiki/pages/viewpage.action?pageId=10031042](http://www.apache.wiki/pages/viewpage.action?pageId=10031042)
貢獻者 : [片刻](/display/~jiangzhonglian) [ApacheCN](/display/~apachecn) [Apache中文網](/display/~apachechina)
### 1.導入Cloudera QuickStart Docker映像
> [Cloudera](http://www.cloudera.com/)已經在自己的容器中正式提供了CDH Docker Hub。請查看[本指南頁面](http://www.cloudera.com/documentation/enterprise/latest/topics/quickstart_docker_container.html#cloudera_docker_container)了解更多信息。
您可以從Cloudera Docker Hub中拉出Docker鏡像。
```
docker pull cloudera/quickstart:latest
```
### 2\. Run docker
```
docker run -it \
-p 80:80 \
-p 4040:4040 \
-p 8020:8020 \
-p 8022:8022 \
-p 8030:8030 \
-p 8032:8032 \
-p 8033:8033 \
-p 8040:8040 \
-p 8042:8042 \
-p 8088:8088 \
-p 8480:8480 \
-p 8485:8485 \
-p 8888:8888 \
-p 9083:9083 \
-p 10020:10020 \
-p 10033:10033 \
-p 18088:18088 \
-p 19888:19888 \
-p 25000:25000 \
-p 25010:25010 \
-p 25020:25020 \
-p 50010:50010 \
-p 50020:50020 \
-p 50070:50070 \
-p 50075:50075 \
-h quickstart.cloudera --privileged=true \
agitated_payne_backup /usr/bin/docker-quickstart;
```
### 3.驗證運行CDH
要驗證應用程序是否正常運行,請檢查Web界面上的HDFS?`http://<hostname>:50070/`和YARN?`http://<hostname>:8088/cluster`。
### 4.在Zeppelin中配置Spark解釋器
設置以下配置`conf/zeppelin-env.sh`。
```
export MASTER=yarn-client
export HADOOP_CONF_DIR=[your_hadoop_conf_path]
export SPARK_HOME=[your_spark_home_path]
```
`HADOOP_CONF_DIR`(Hadoop配置路徑)定義在`/scripts/docker/spark-cluster-managers/cdh/hdfs_conf`。
不要忘記在“Zeppelin?**Interpreters”**設置頁面中設置Spark?`master`,如下所示。`yarn-client`??
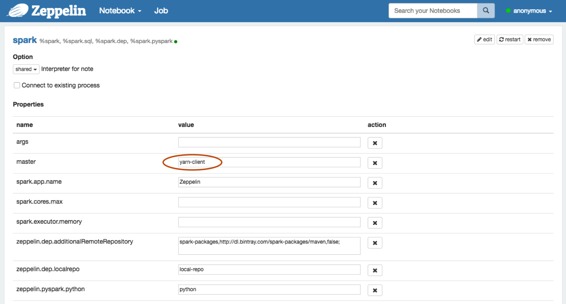
### [使用Spark解釋器運行Zeppelin](http://zeppelin.apache.org/docs/0.7.2/install/cdh.html#5-run-zeppelin-with-spark-interpreter)
在Zeppelin中使用Spark解釋器運行一個段落后,
?瀏覽`http://<hostname>:8088/cluster/apps`檢查Zeppelin應用程序是否運行良好。

- 快速入門
- 什么是Apache Zeppelin?
- 安裝
- 配置
- 探索Apache Zeppelin UI
- 教程
- 動態表單
- 發表你的段落
- 自定義Zeppelin主頁
- 升級Zeppelin版本
- 從源碼編譯
- 使用Flink和Spark Clusters安裝Zeppelin教程
- 解釋器
- 概述
- 解釋器安裝
- 解釋器依賴管理
- 解釋器的模擬用戶
- 解釋員執行Hook(實驗)
- Alluxio 解釋器
- Beam 解釋器
- BigQuery 解釋器
- Cassandra CQL 解釋器
- Elasticsearch 解釋器
- Flink 解釋器
- Geode/Gemfire OQL 解釋器
- HBase Shell 解釋器
- HDFS文件系統 解釋器
- Hive 解釋器
- Ignite 解釋器
- JDBC通用 解釋器
- Kylin 解釋器
- Lens 解釋器
- Livy 解釋器
- Markdown 解釋器
- Pig 解釋器
- PostgreSQL, HAWQ 解釋器
- Python 2&3解釋器
- R 解釋器
- Scalding 解釋器
- Scio 解釋器
- Shell 解釋器
- Spark 解釋器
- 系統顯示
- 系統基本顯示
- 后端Angular API
- 前端Angular API
- 更多
- 筆記本存儲
- REST API
- 解釋器 API
- 筆記本 API
- 筆記本資源 API
- 配置 API
- 憑據 API
- Helium API
- Security ( 安全 )
- Shiro 授權
- 筆記本 授權
- 數據源 授權
- Helium 授權
- Advanced ( 高級 )
- Zeppelin on Vagrant VM ( Zeppelin 在 Vagrant 虛擬機上 )
- Zeppelin on Spark Cluster Mode( Spark 集群模式下的 Zeppelin )
- Zeppelin on CDH ( Zeppelin 在 CDH 上 )
- Contibute ( 貢獻 )
- Writing a New Interpreter ( 寫一個新的解釋器 )
- Writing a new Visualization (Experimental) ( 編寫新的可視化(實驗) )
- Writing a new Application (Experimental) ( 寫一個新的應用程序( 實驗 ) )
- Contributing to Apache Zeppelin ( Code ) ( 向 Apache Zeppelin 貢獻( 代碼 ) )
- Contributing to Apache Zeppelin ( Website ) ( 向 Apache Zeppelin 貢獻(website) )